Balancing Plasticity and Stability with Fast and Slow Successor Features
Pith reviewed 2026-06-29 22:13 UTC · model grok-4.3
The pith
Stabilizing successor features with multi-timescale synaptic consolidation outperforms plasticity methods in gradually drifting environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
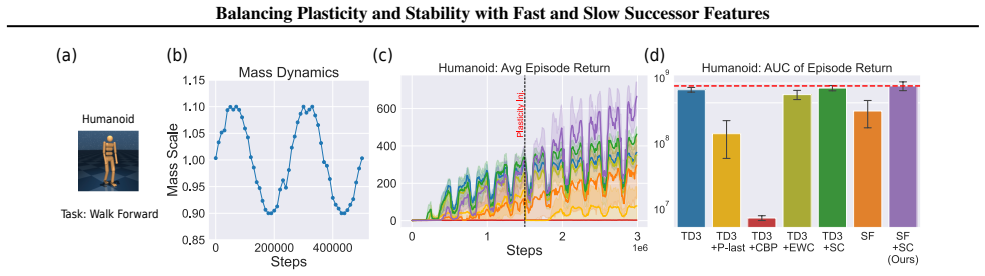
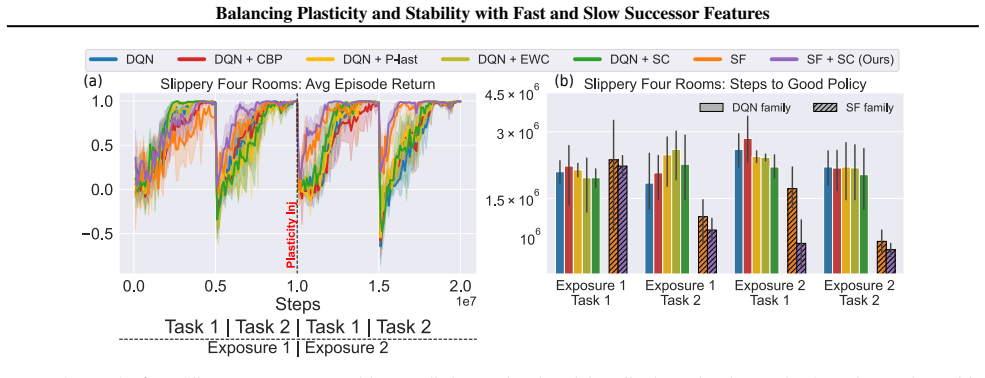
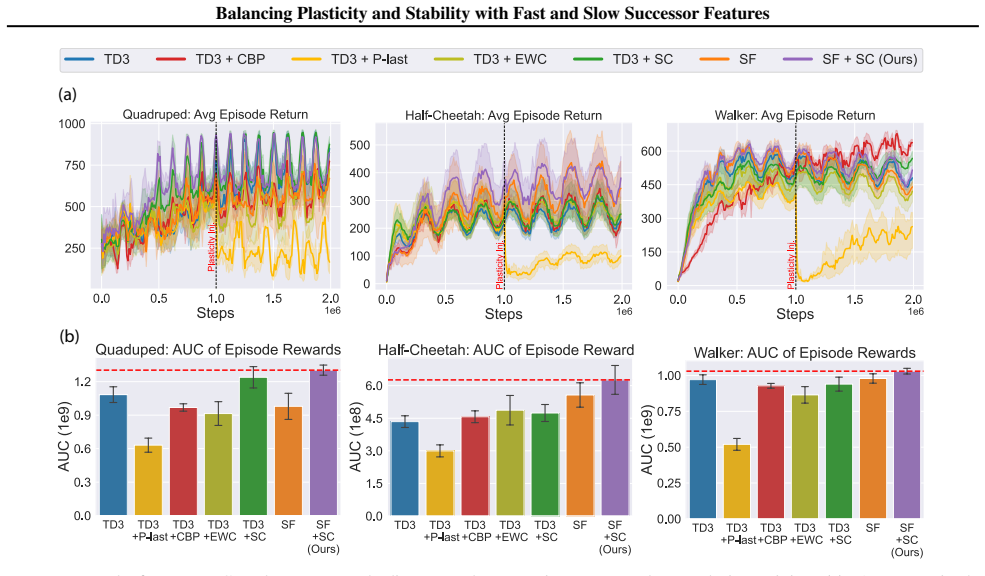
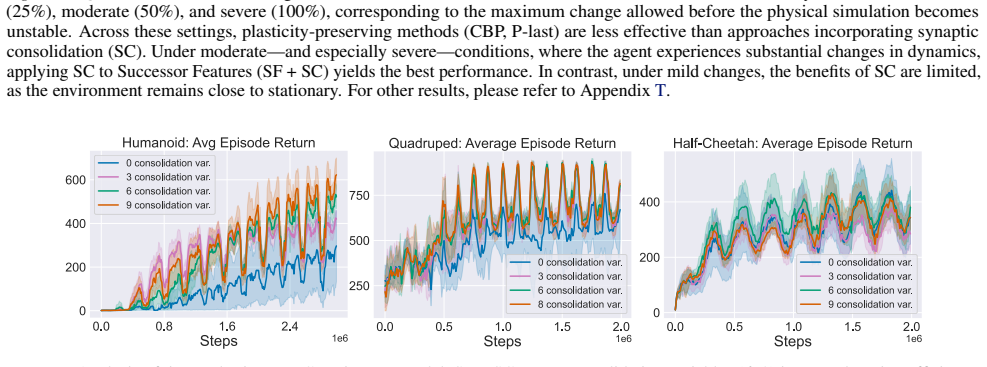
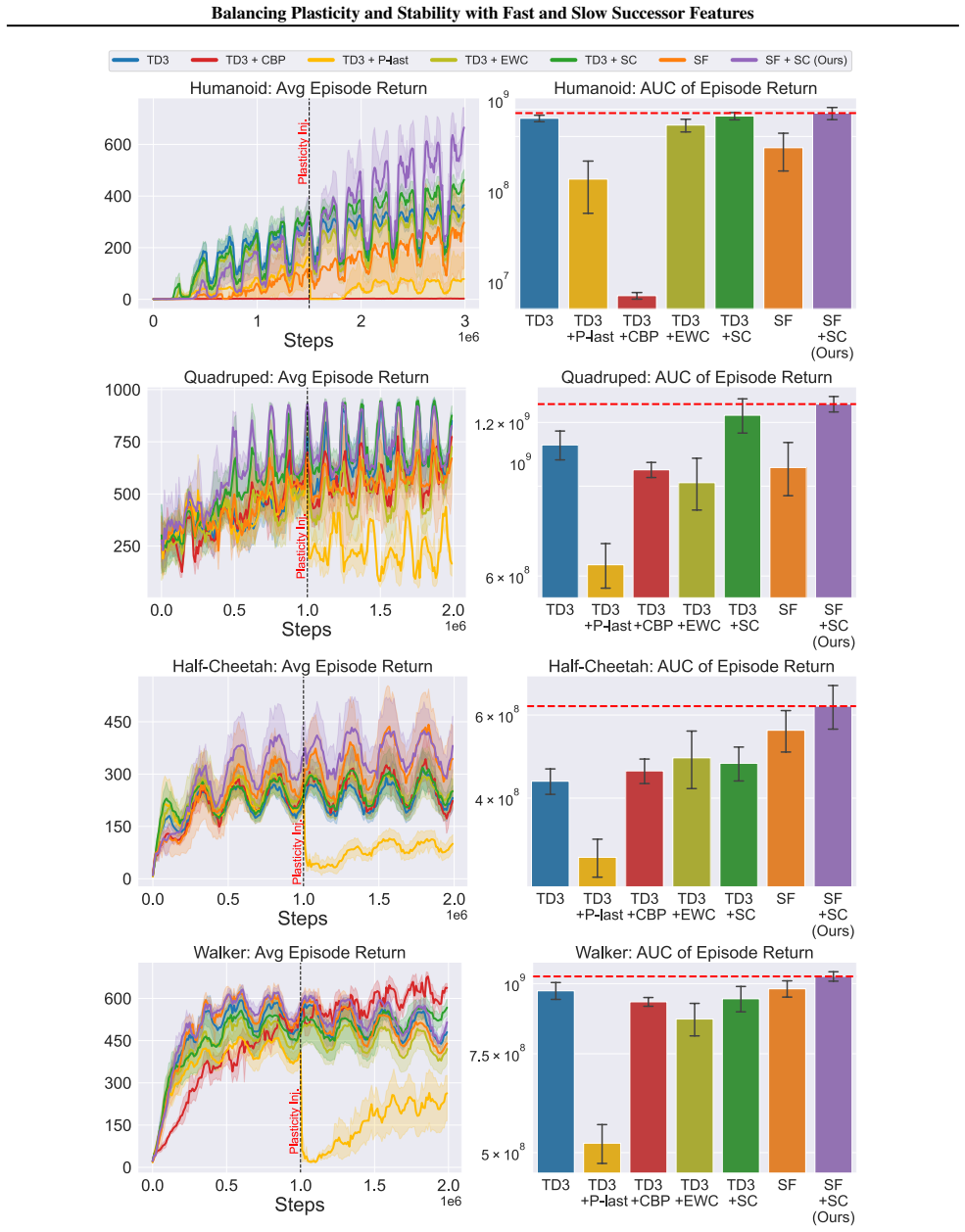
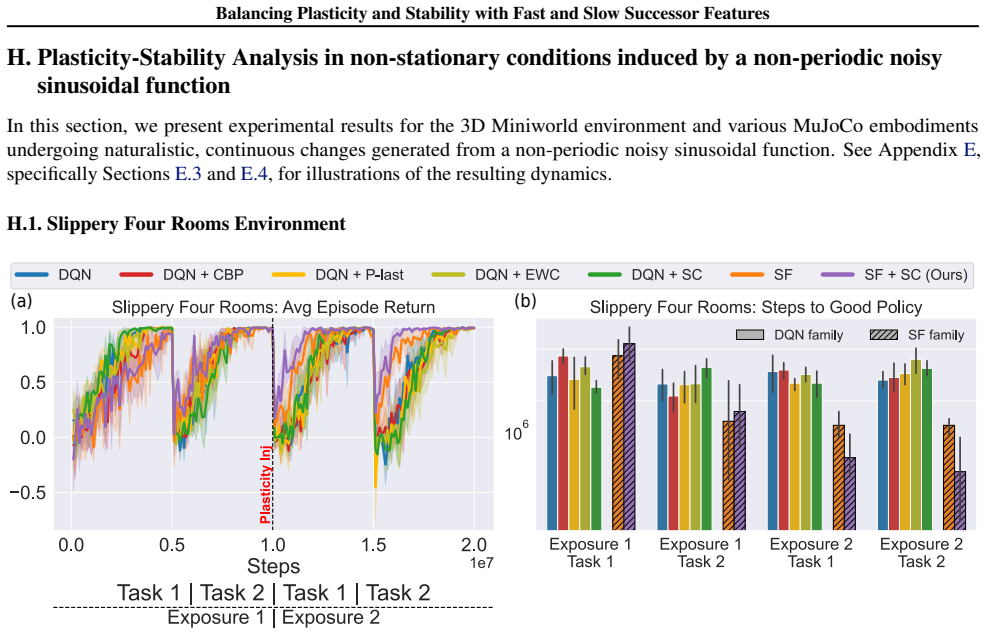
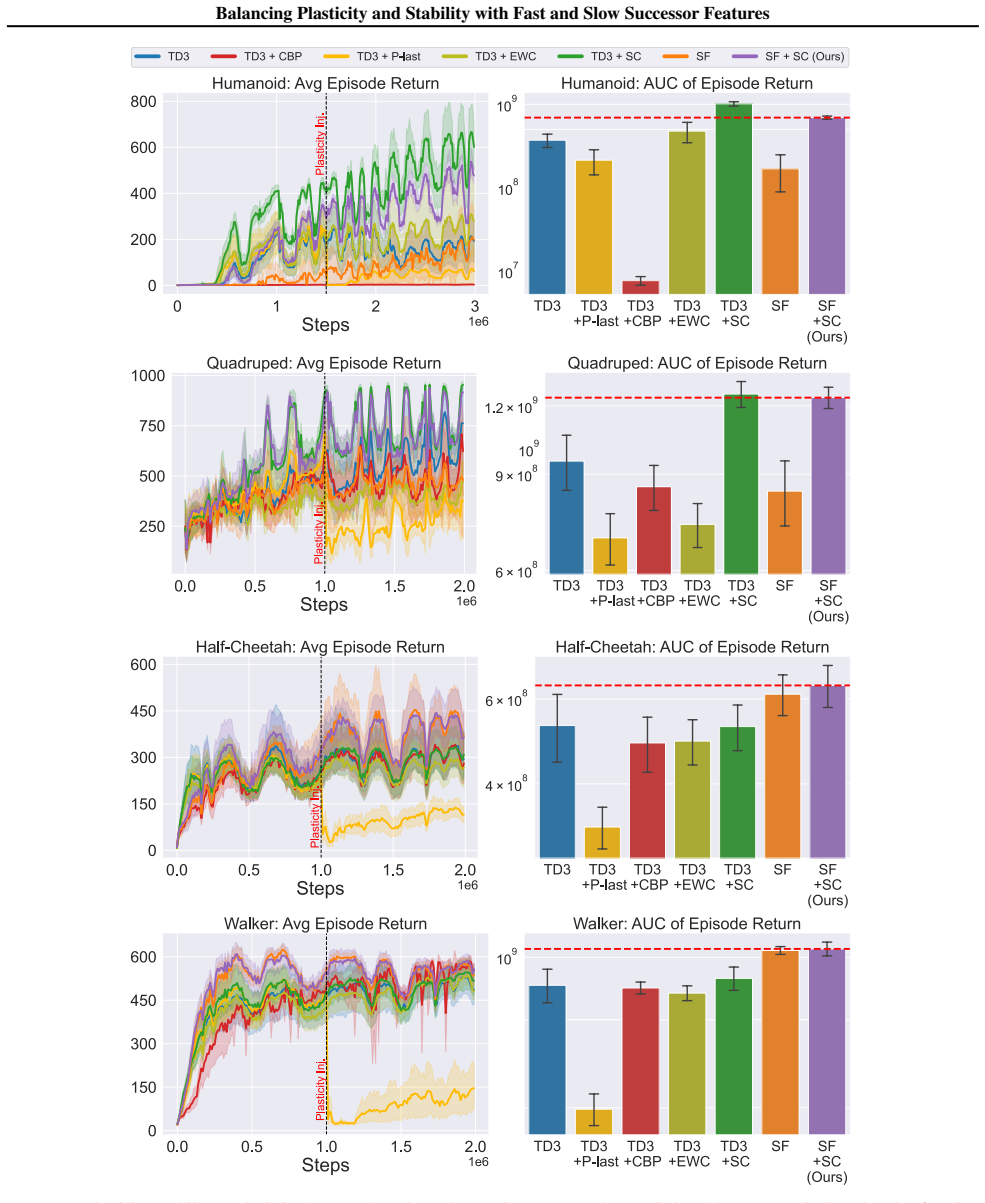
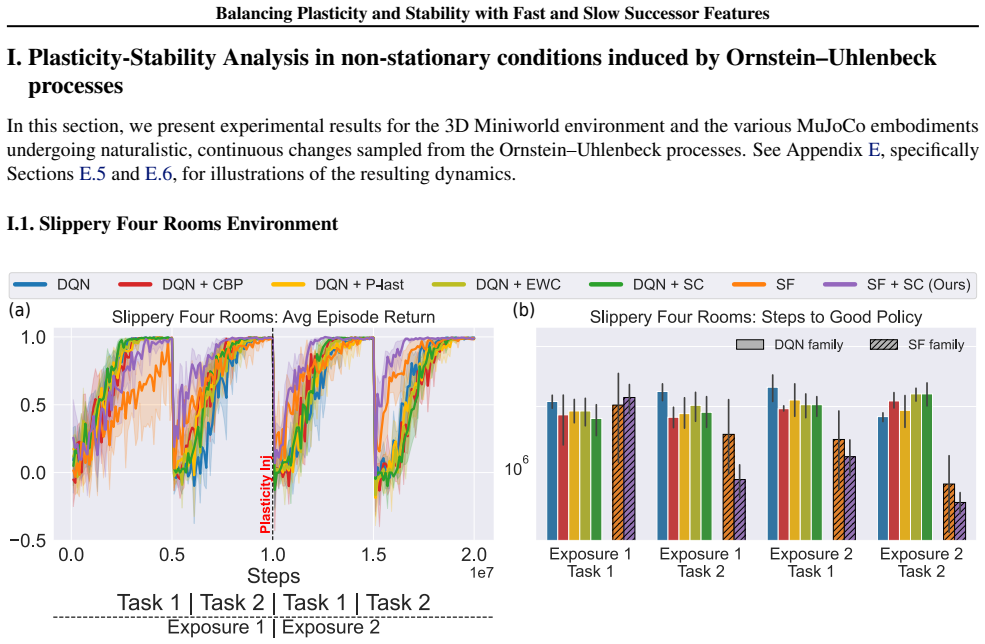
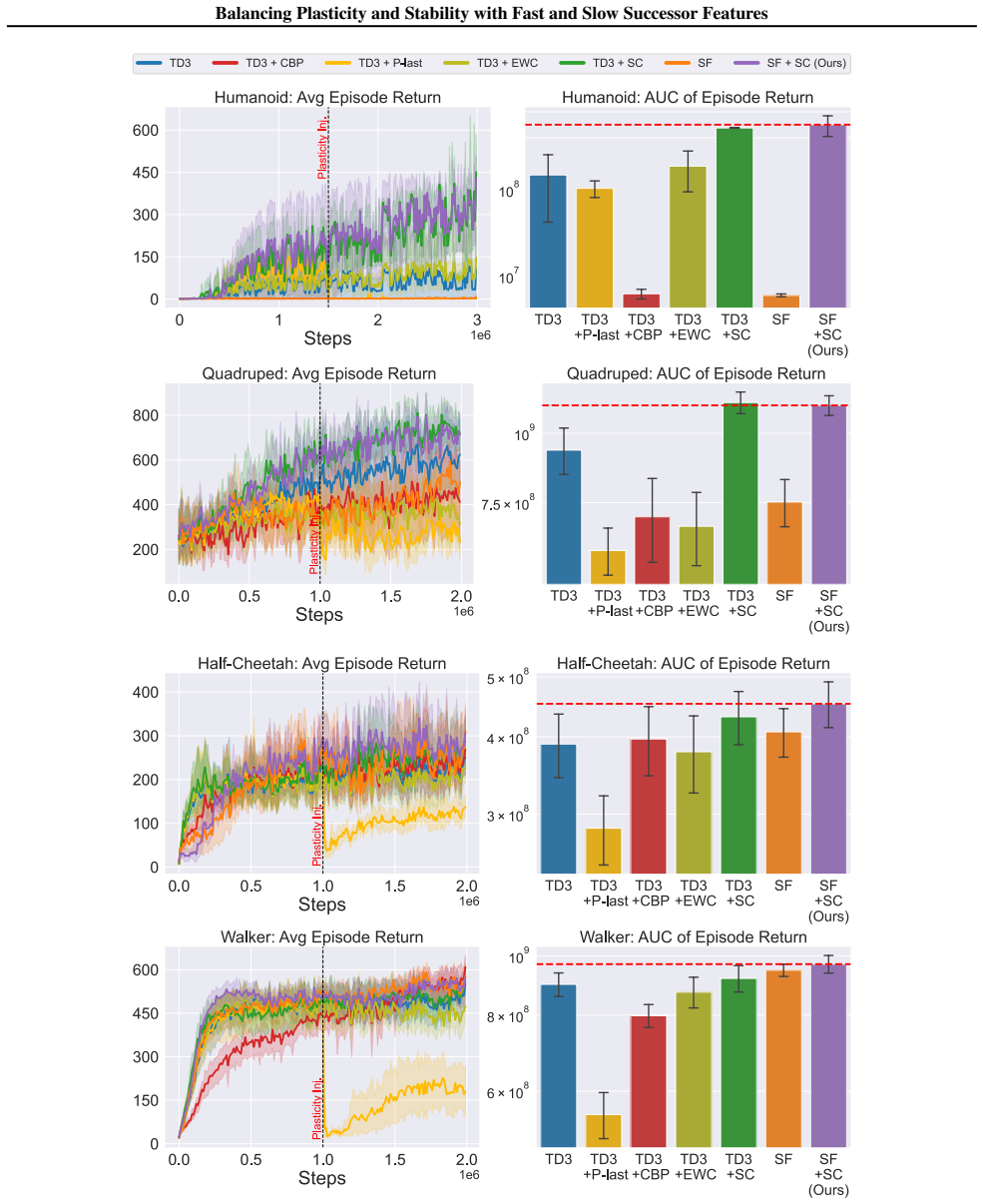
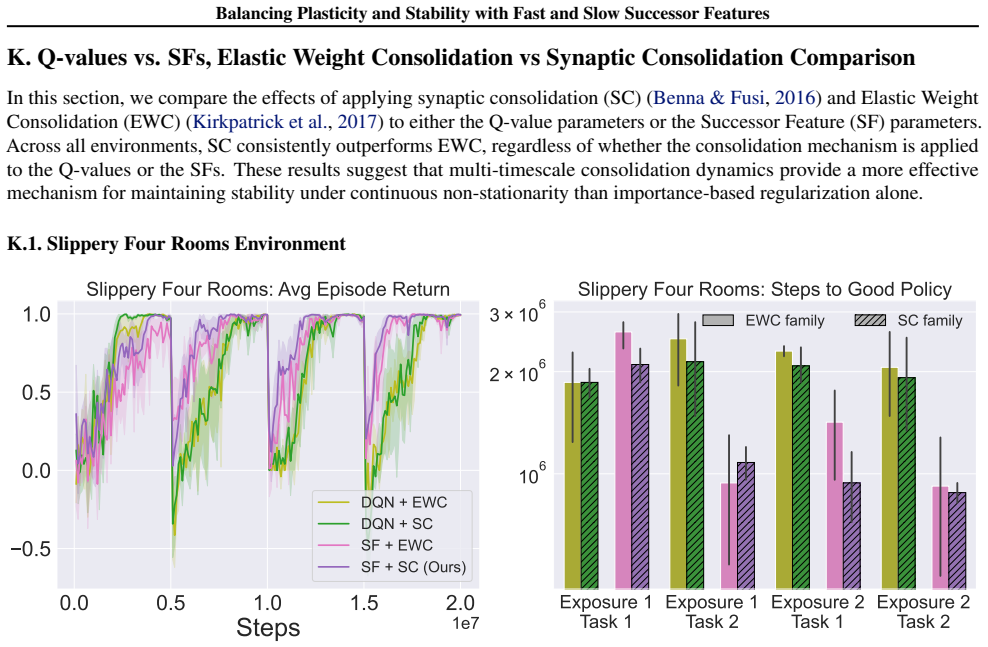
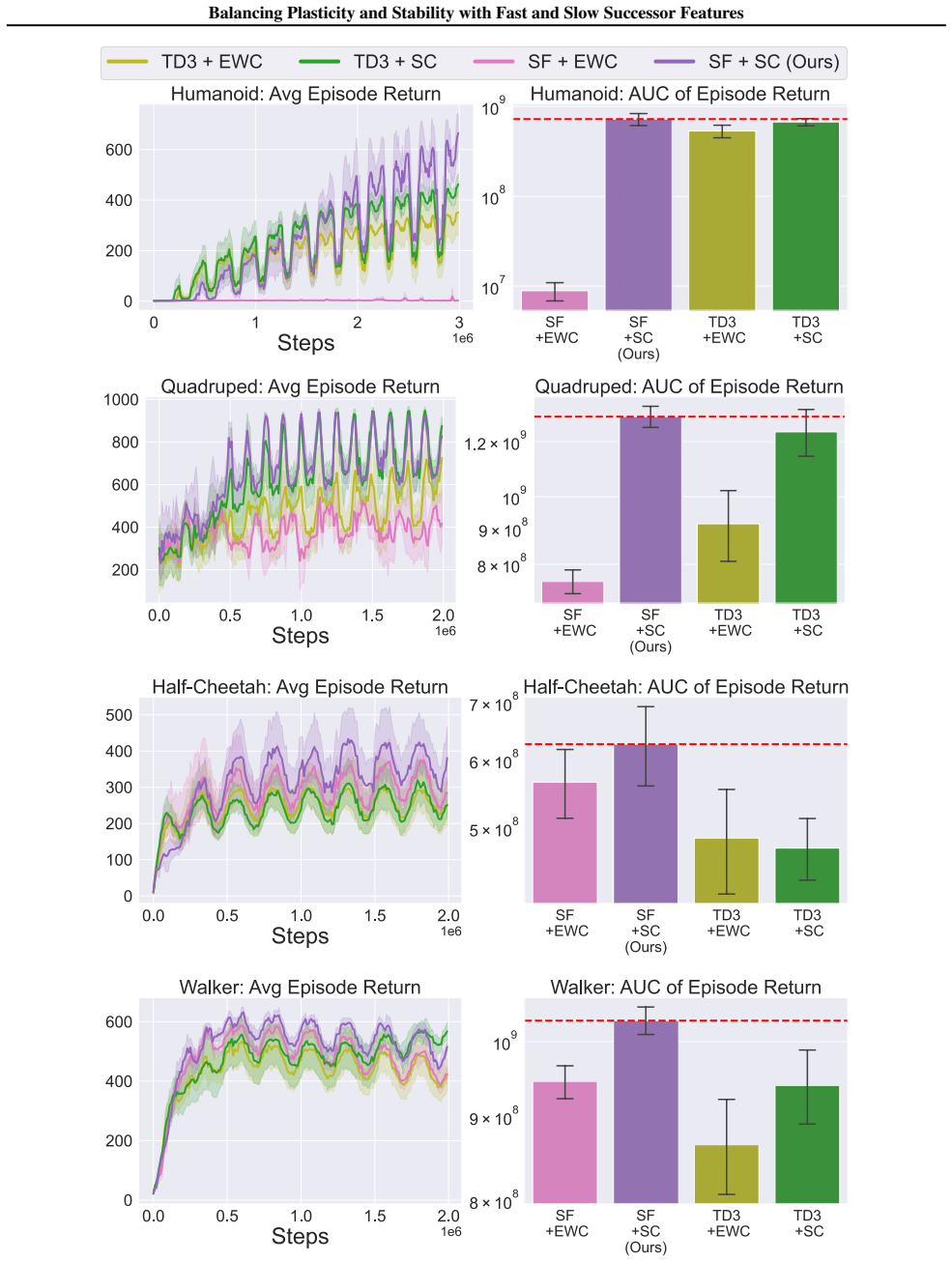
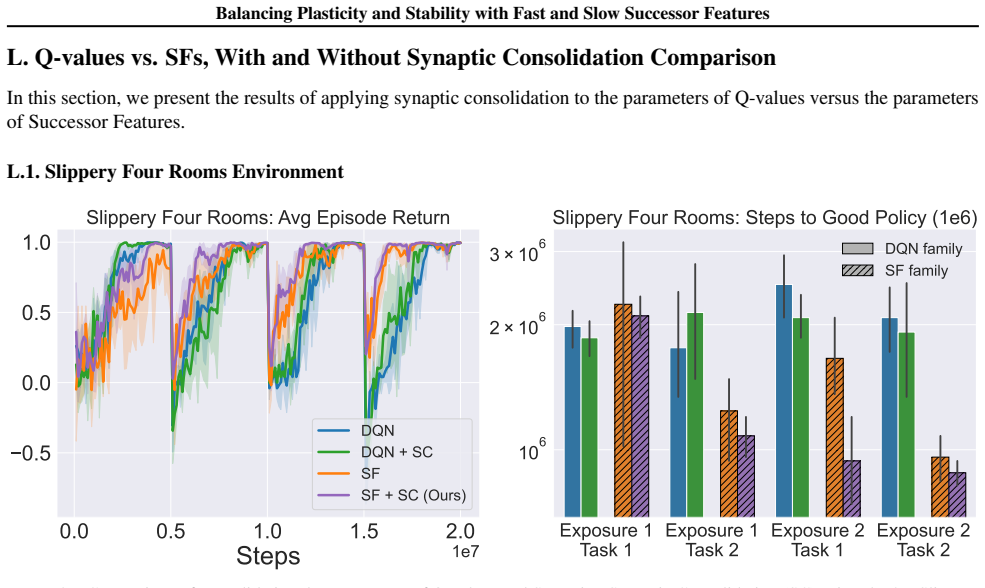
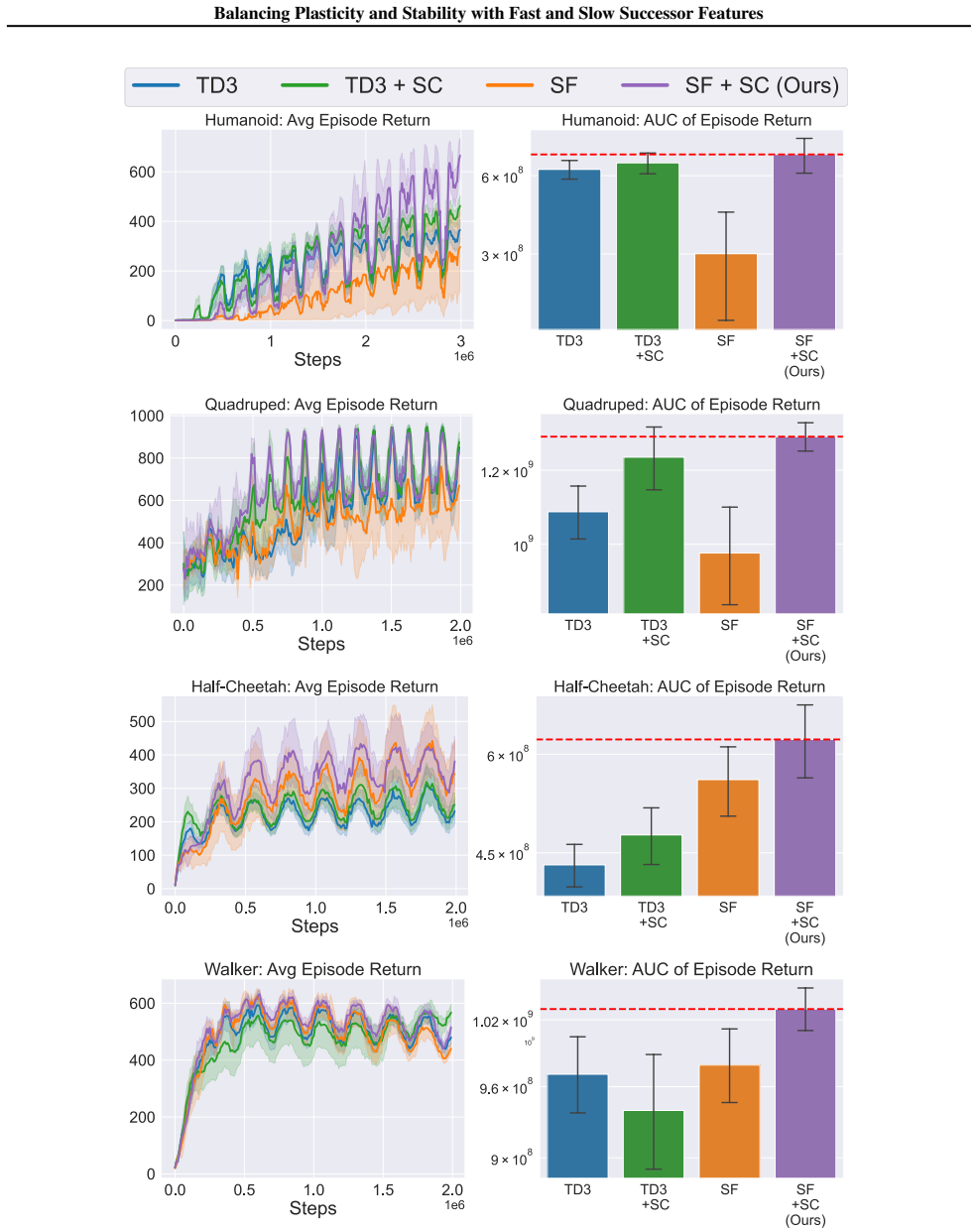
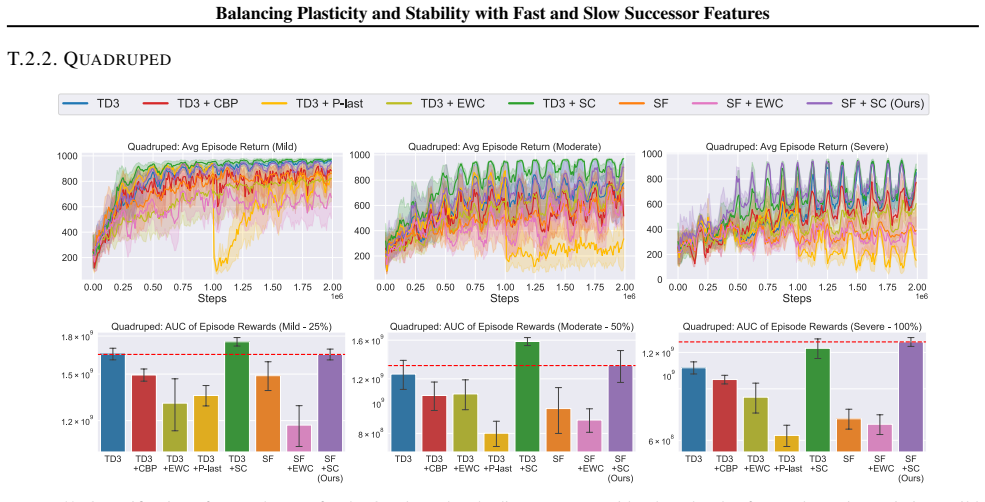
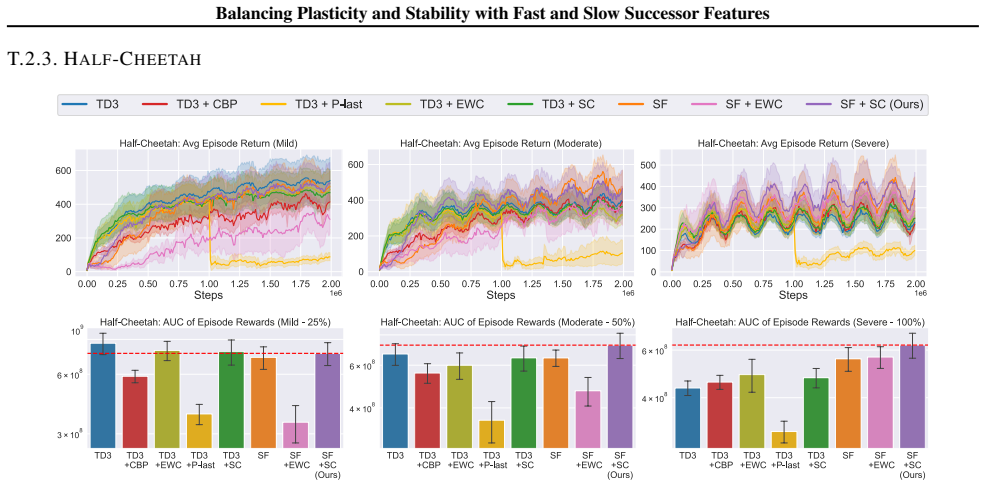
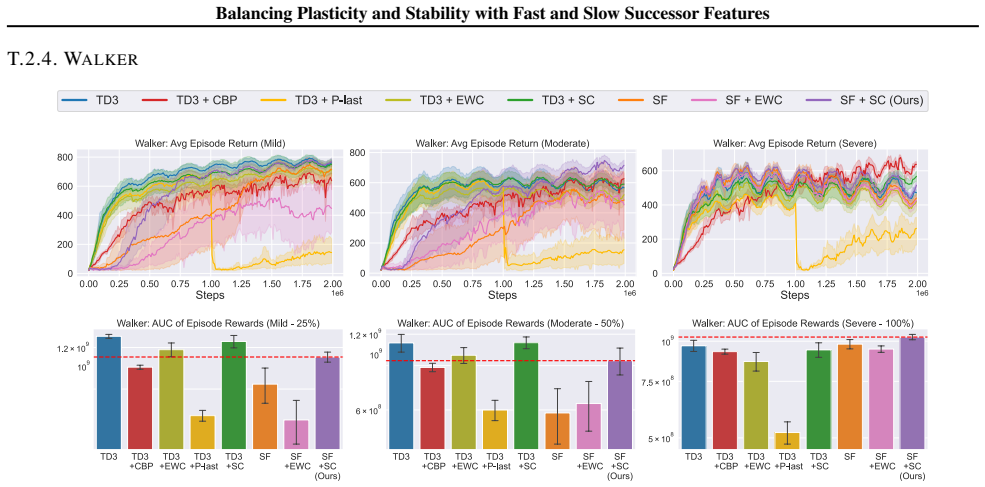
In environments modified to feature gradual continual drift, applying neuro-inspired synaptic consolidation to successor features produces superior performance on continually changing tasks compared with methods that reset parameters or consolidate Q-values directly, with the largest gains arising when consolidation targets operate across multiple timescales that together capture complementary aspects of the drift.
What carries the argument
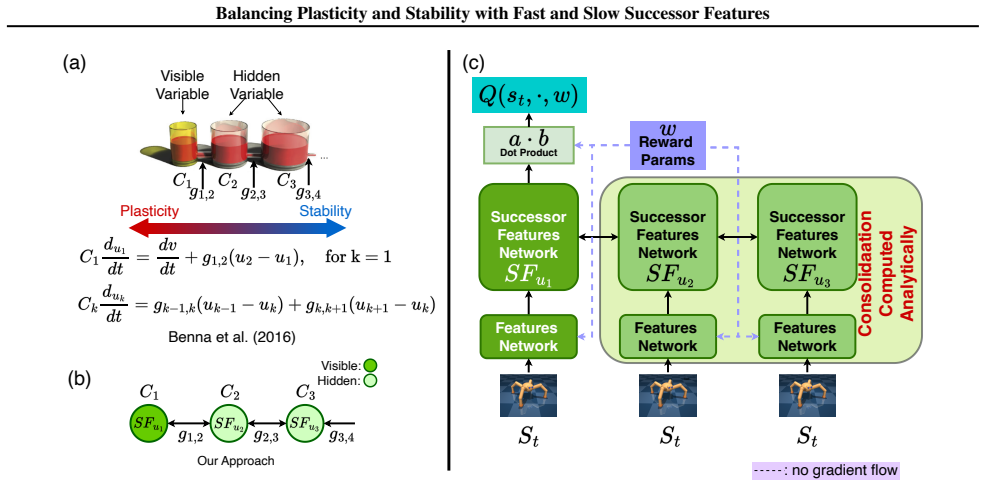
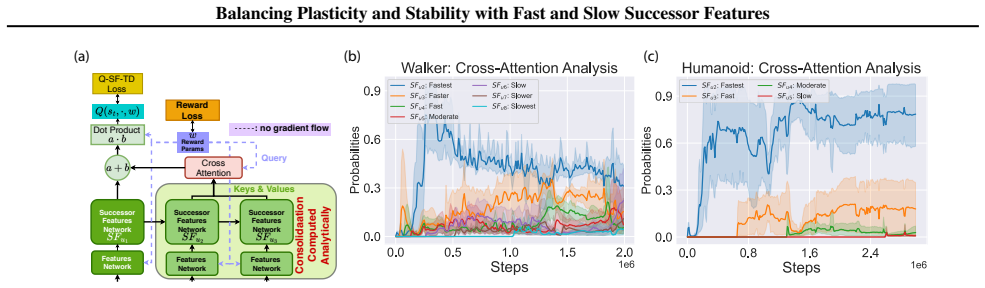
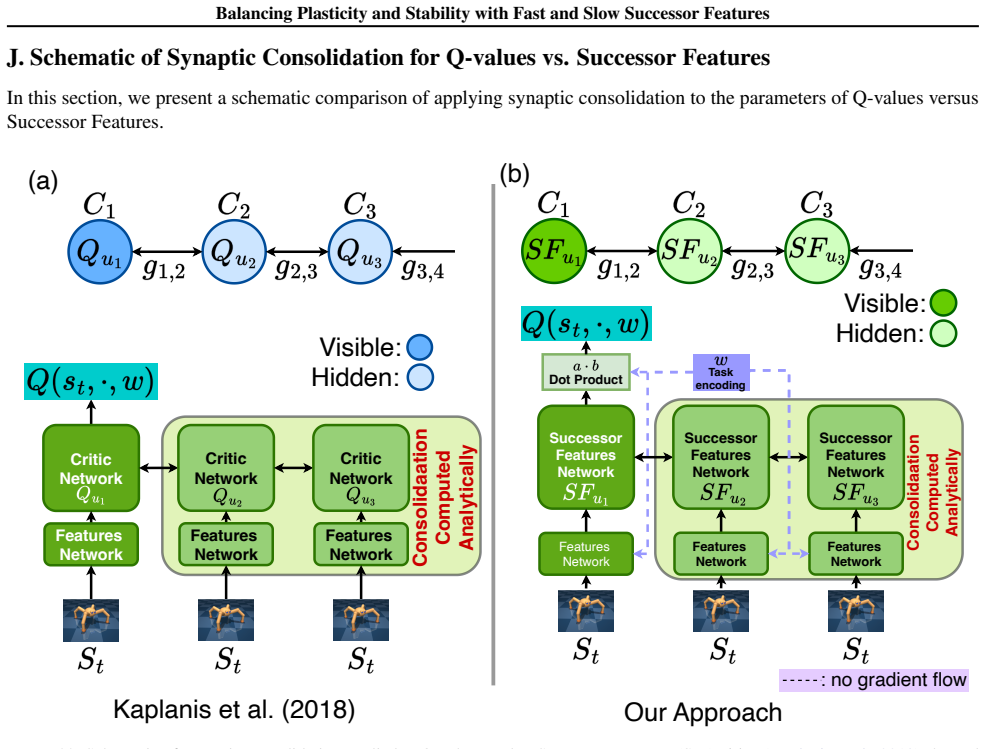
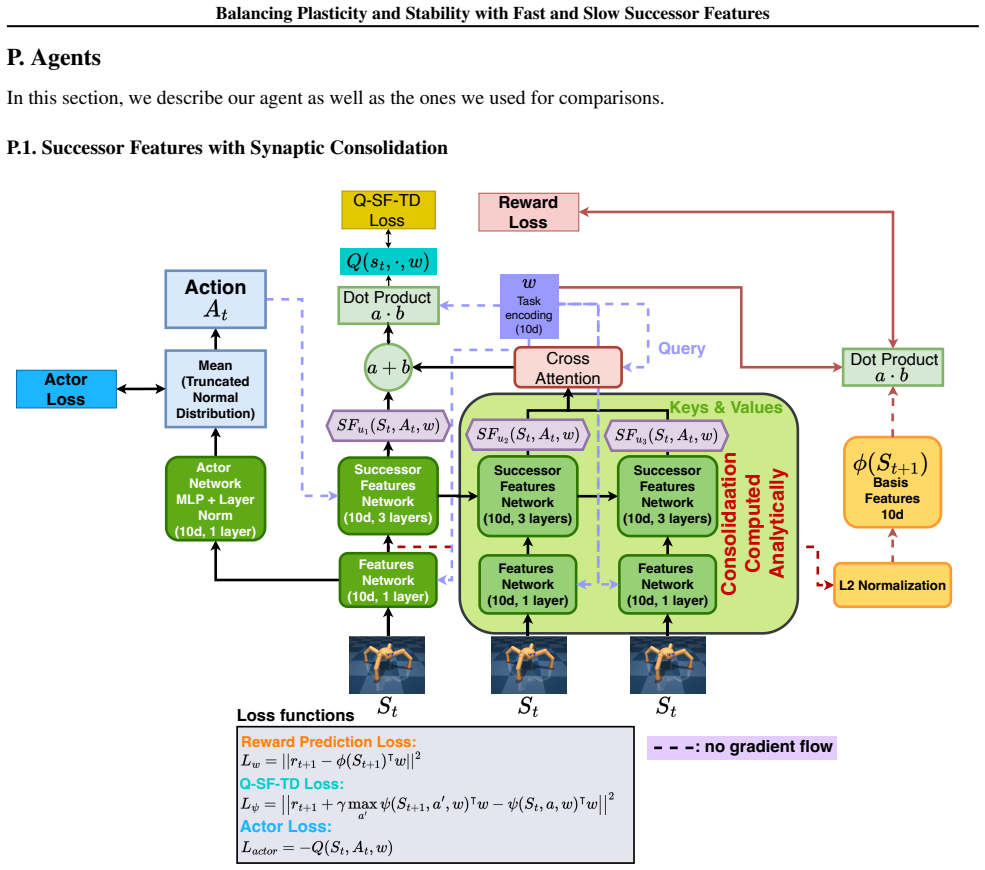
Successor Features stabilized via synaptic consolidation at multiple (fast and slow) timescales
If this is right
- Stability-focused methods outperform plasticity-focused methods when environmental change occurs gradually rather than through discrete jumps.
- Successor features serve as more effective consolidation targets than raw Q-values because they reduce interference across changing conditions.
- Consolidation at multiple timescales captures complementary rates of environmental drift more effectively than any single timescale.
- The performance advantage appears in both discrete navigation and continuous control domains.
Where Pith is reading between the lines
- The same multi-timescale consolidation principle could be tested on other predictive representations such as successor measures or latent dynamics models.
- Robotics or autonomous driving systems that encounter slow seasonal or wear-induced drift might benefit from explicit fast-slow consolidation schedules.
- Benchmarks that rely only on abrupt task boundaries may systematically underestimate the value of stability mechanisms.
Load-bearing premise
The artificial gradual drift added to the modified environments accurately models real-world non-stationarity without introducing implementation artifacts that favor the consolidation methods.
What would settle it
Running the same consolidation experiments but replacing the gradual drift with abrupt task switches and finding that multi-timescale successor-feature consolidation no longer outperforms single-timescale or Q-value consolidation.
Figures

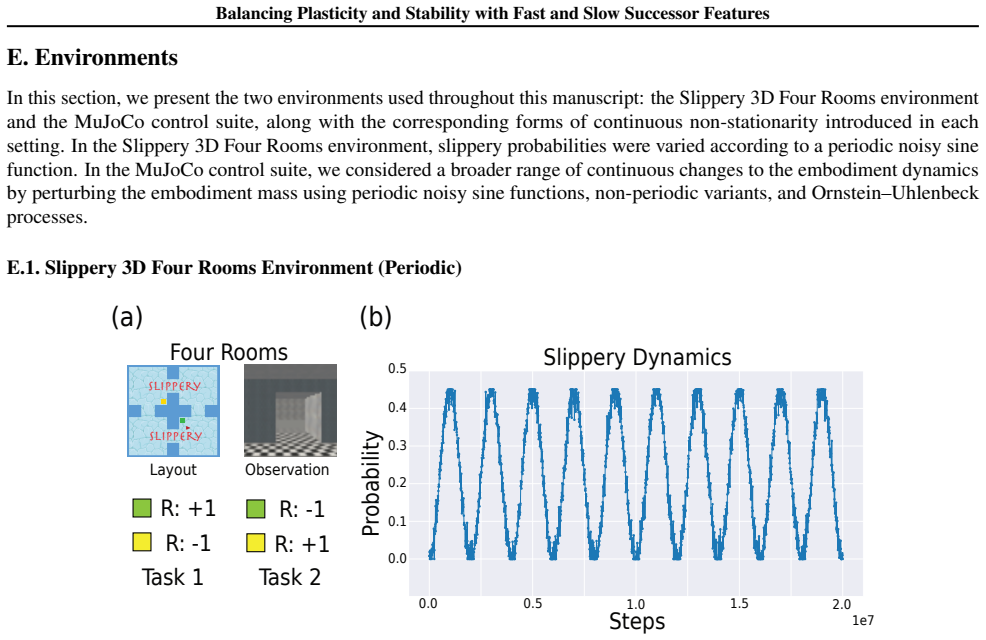
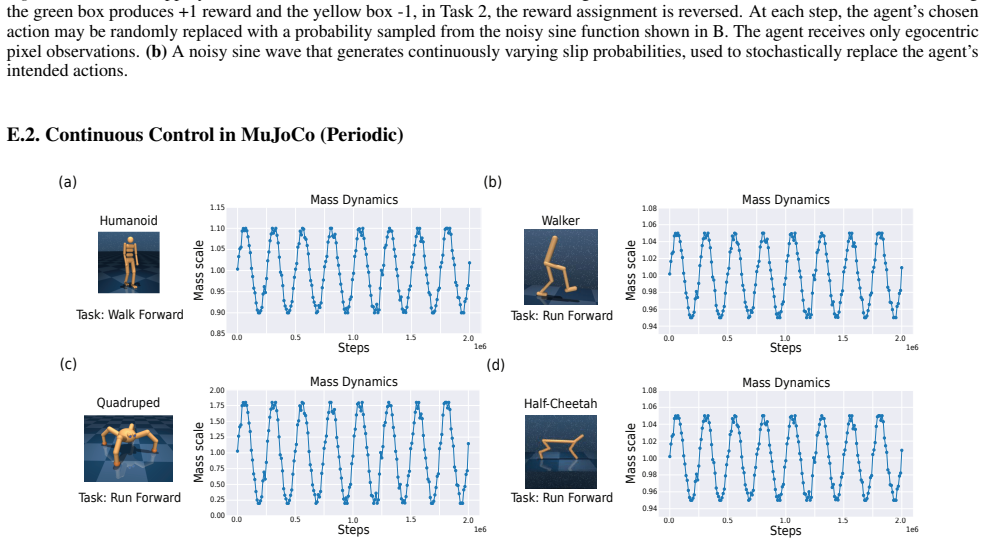
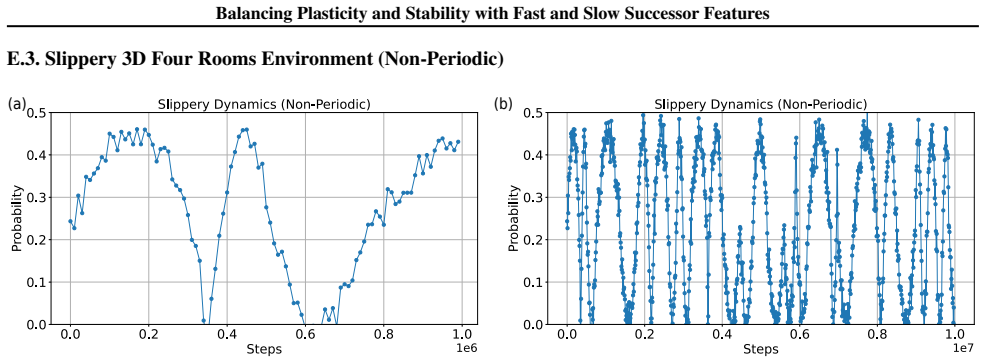
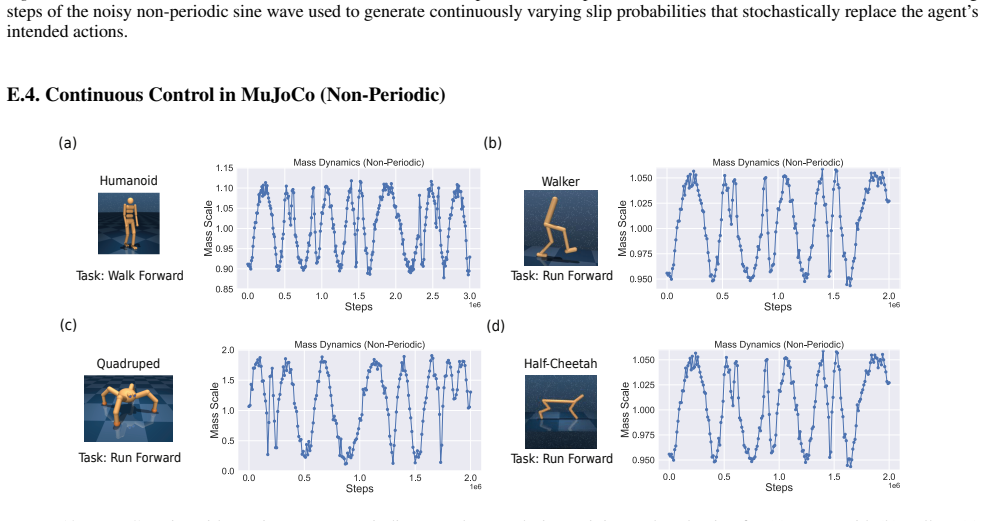

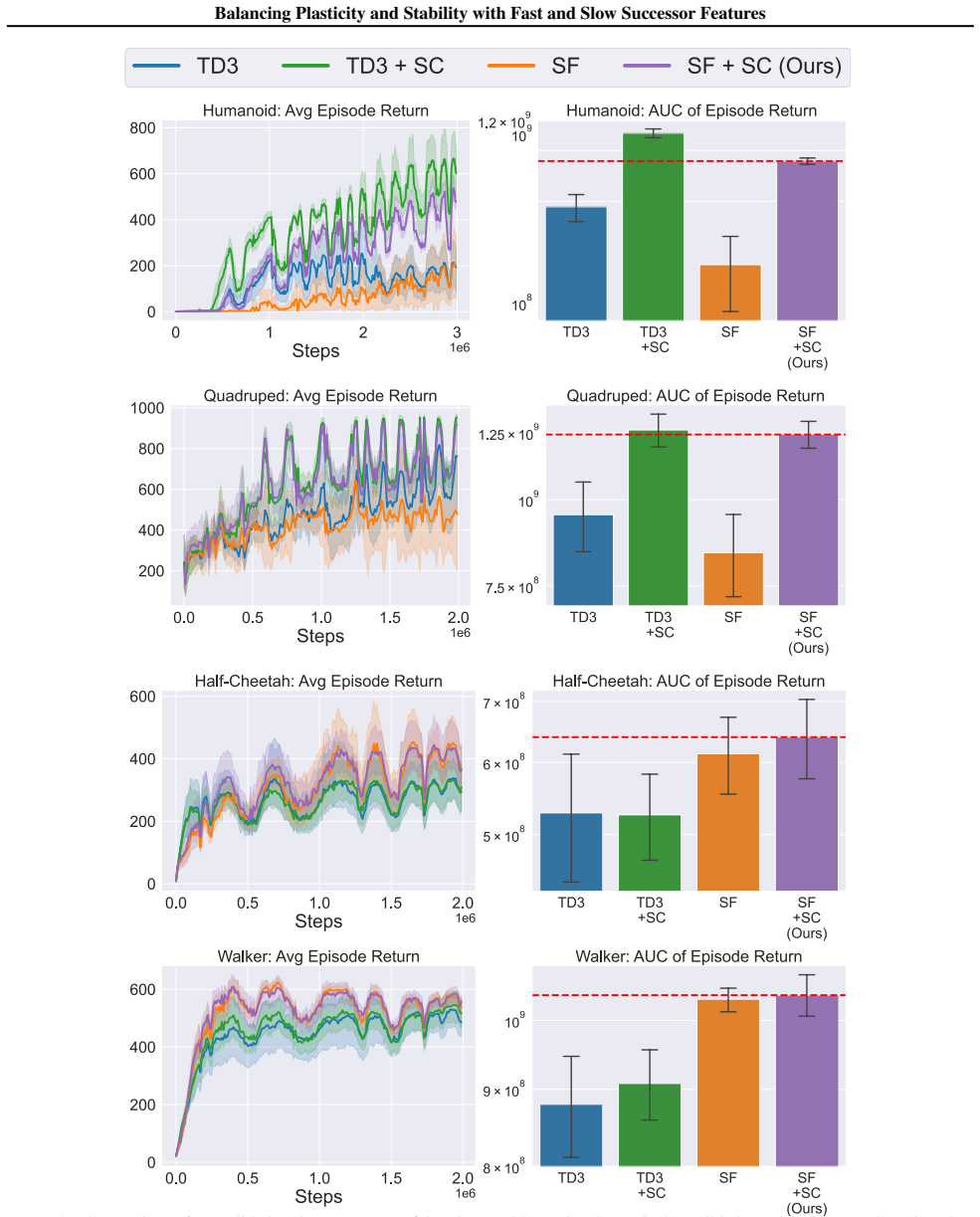
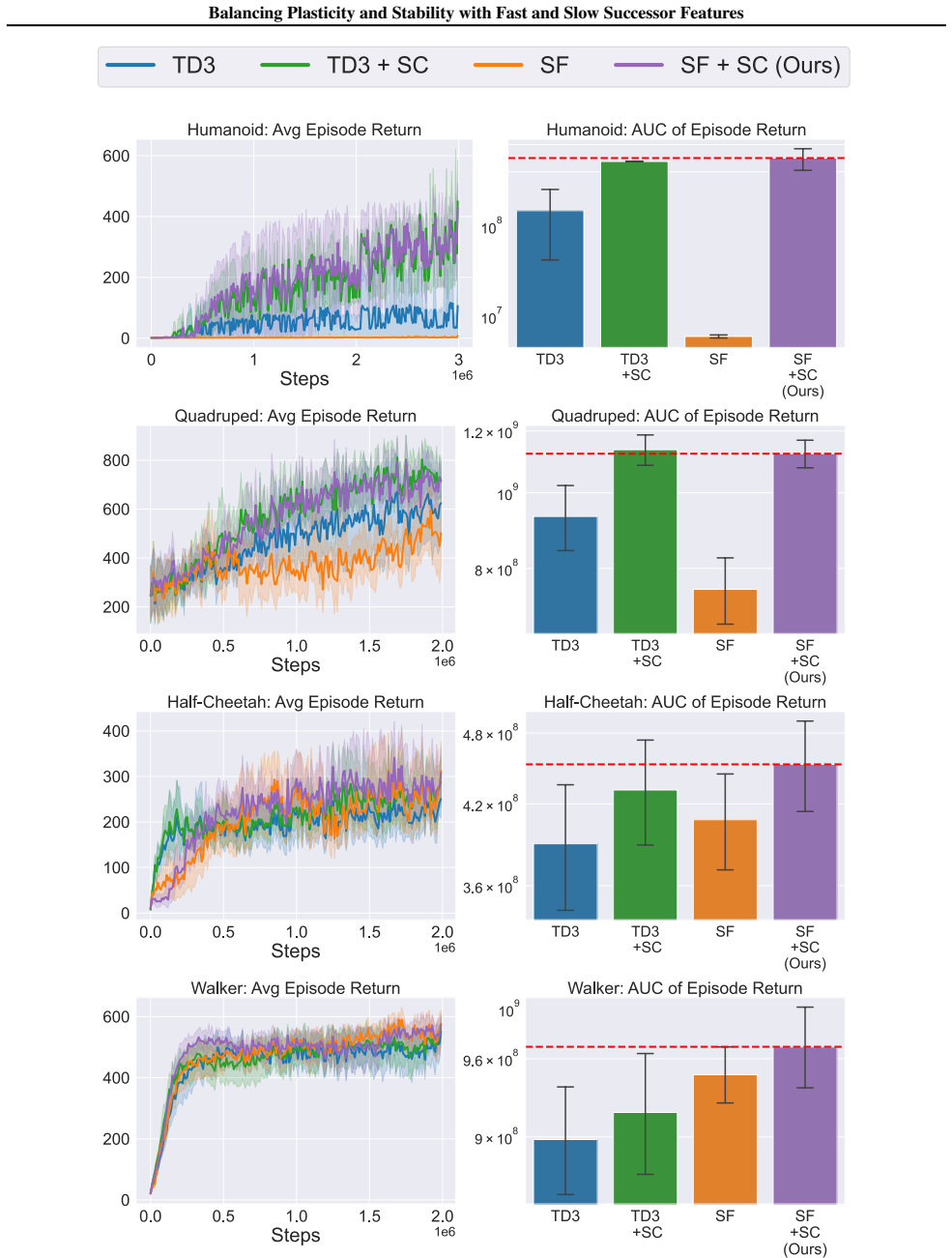
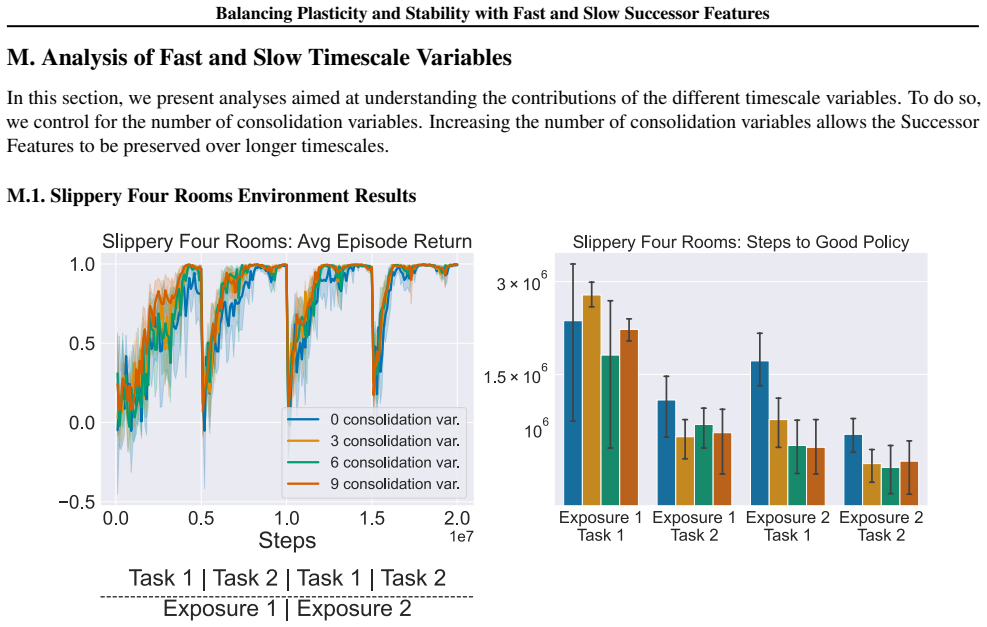
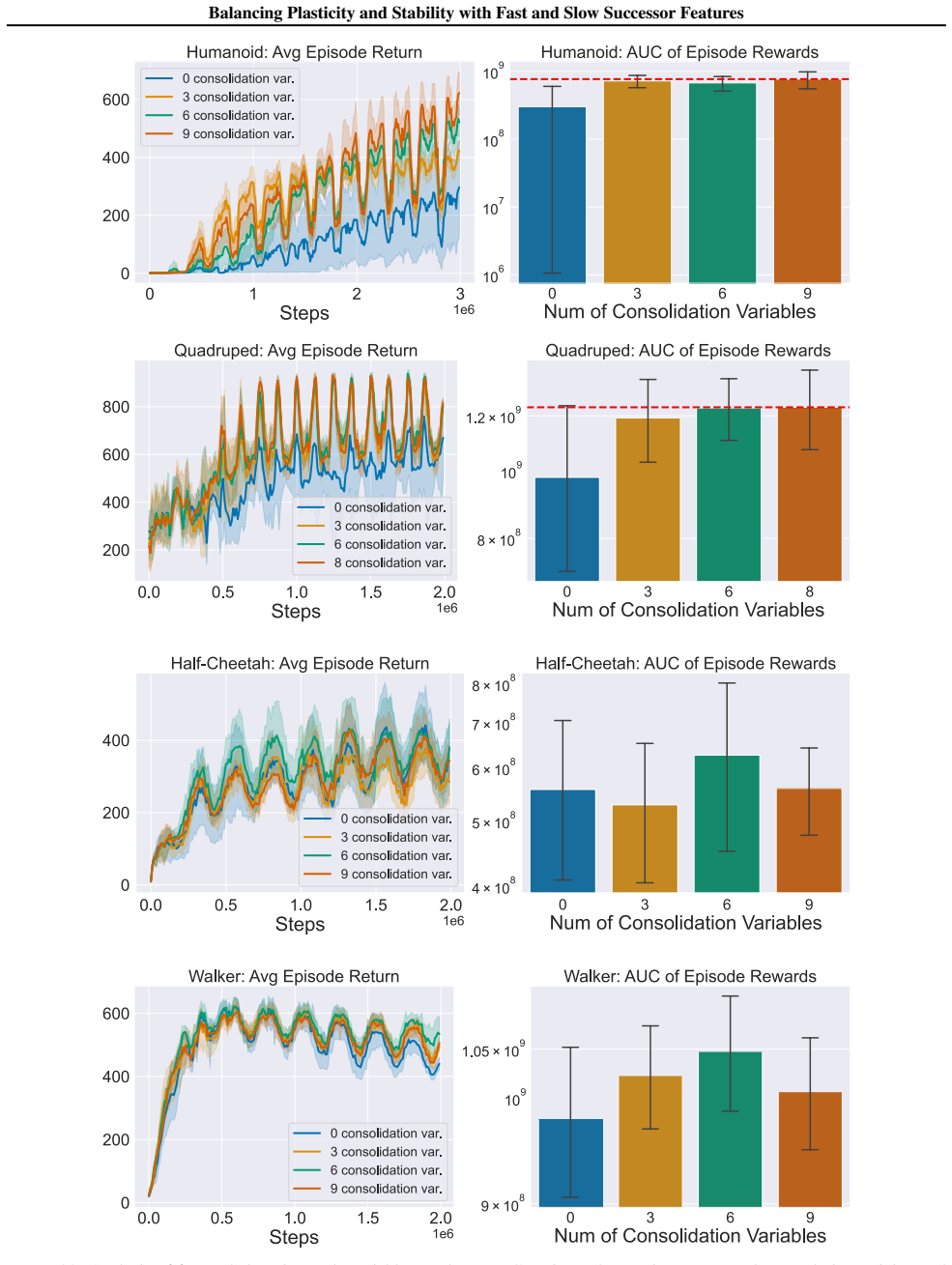
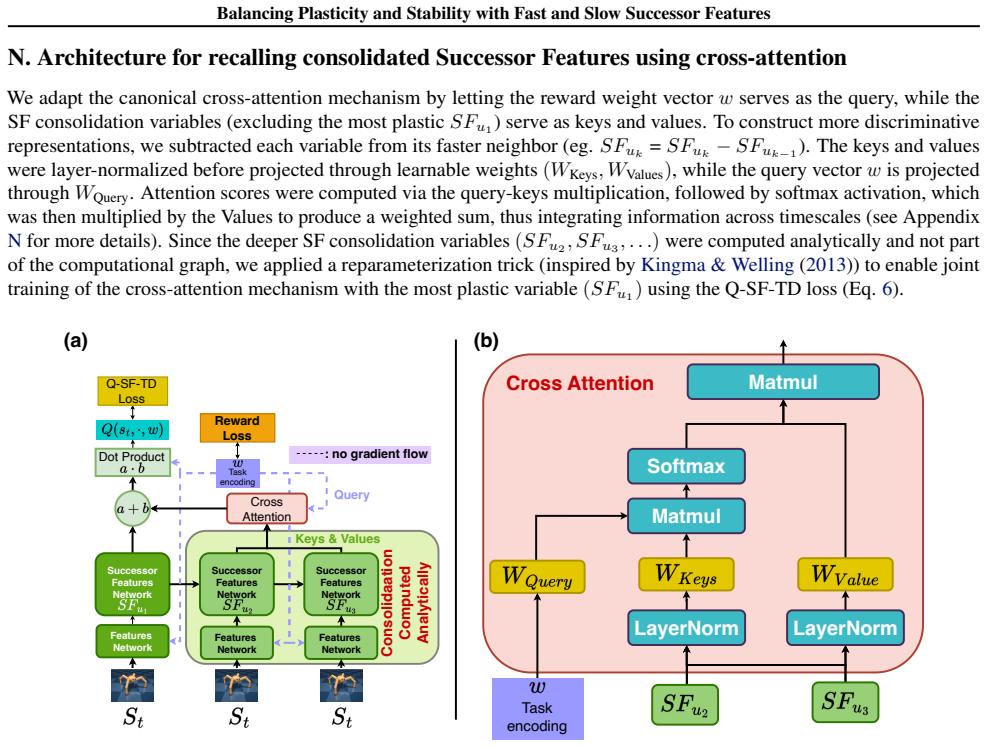
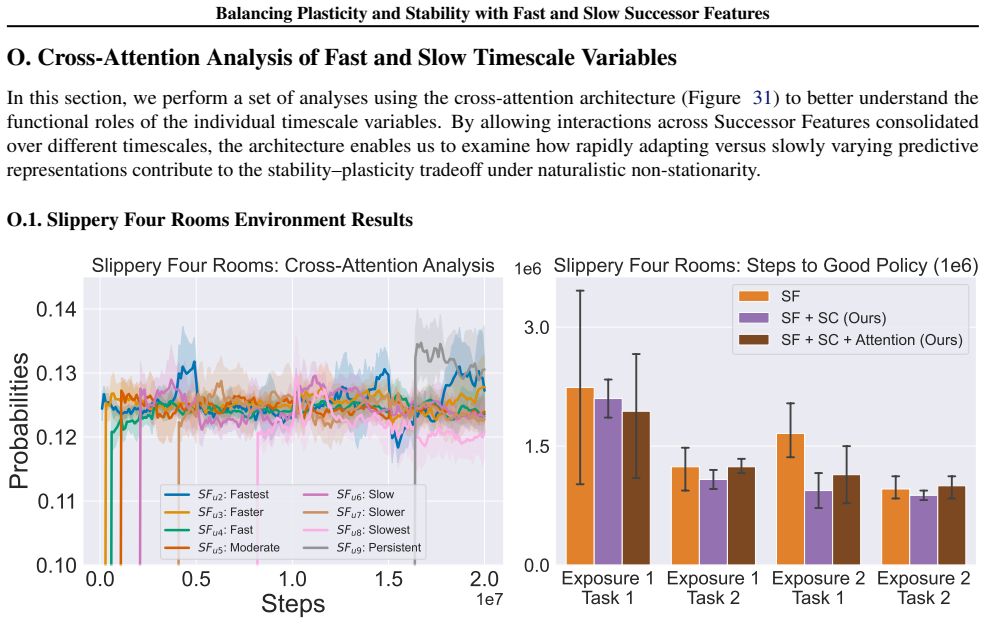
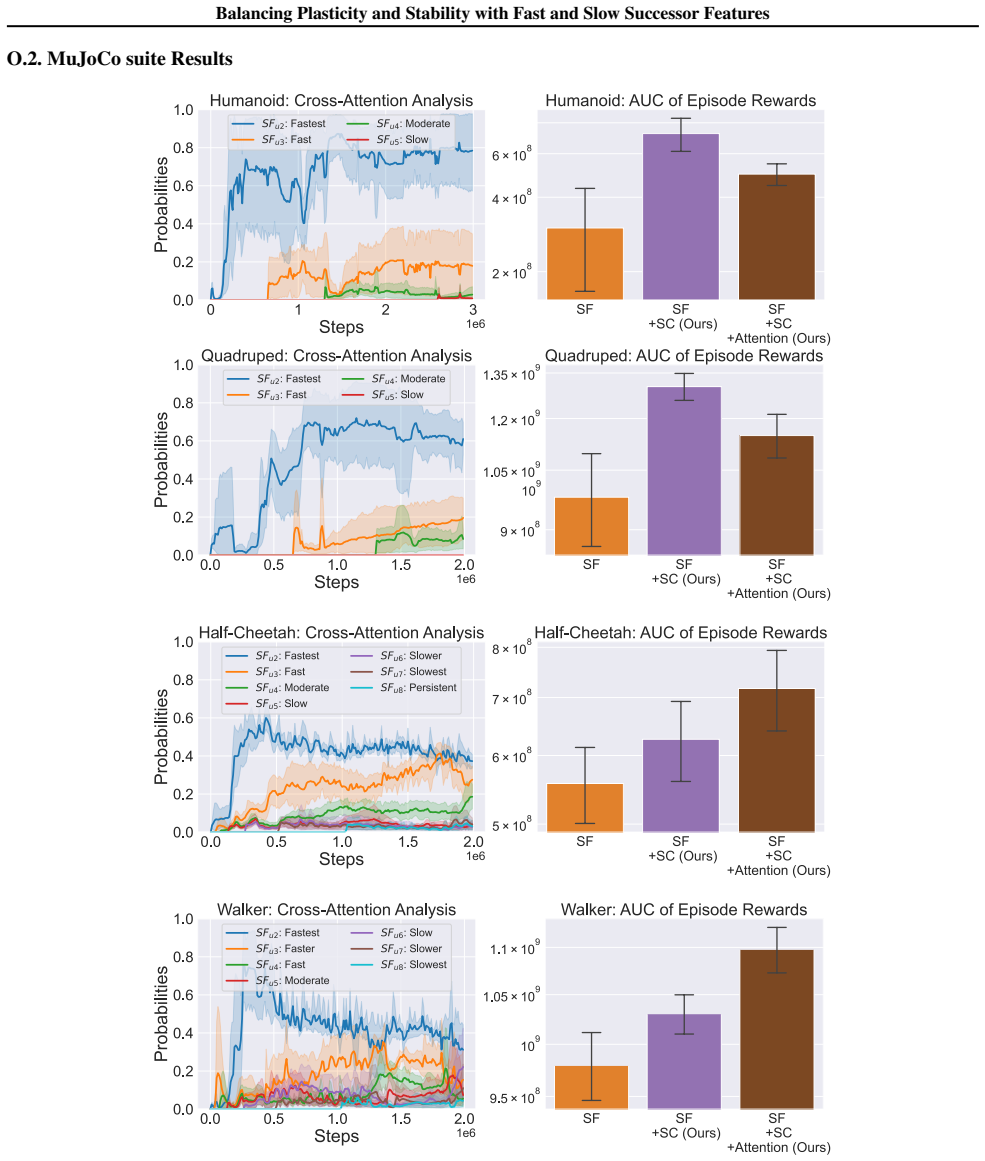
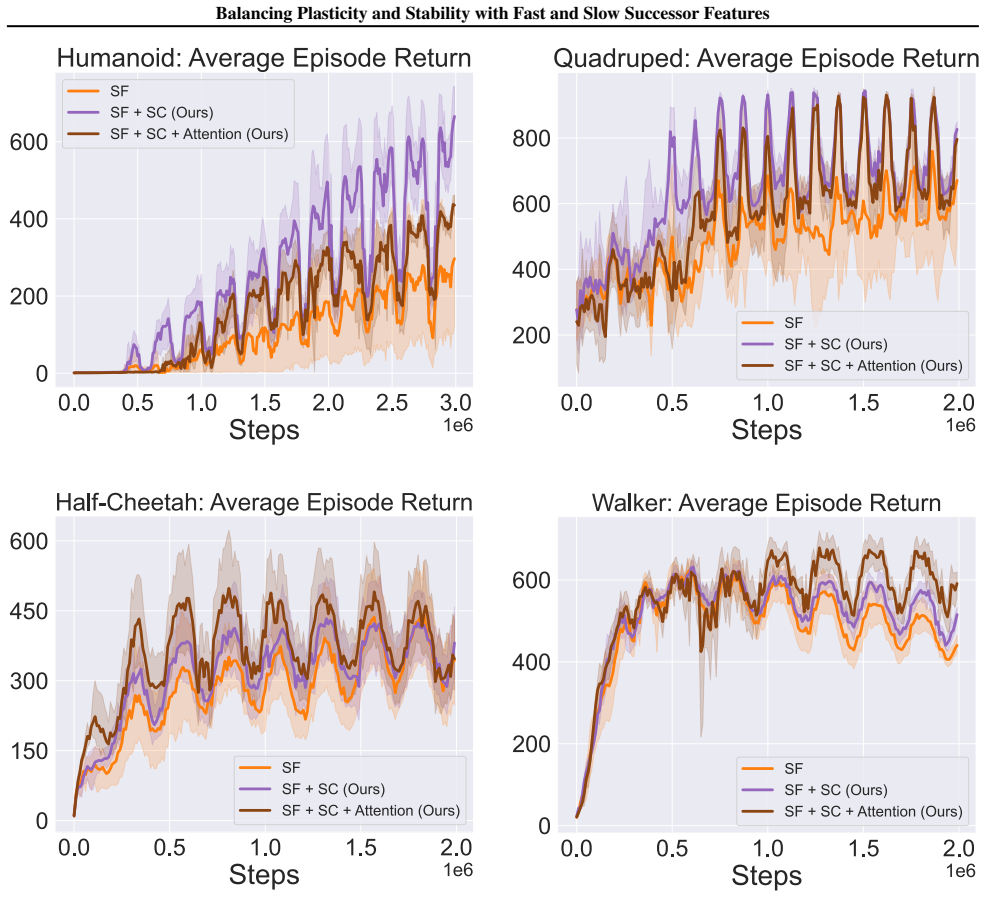
read the original abstract
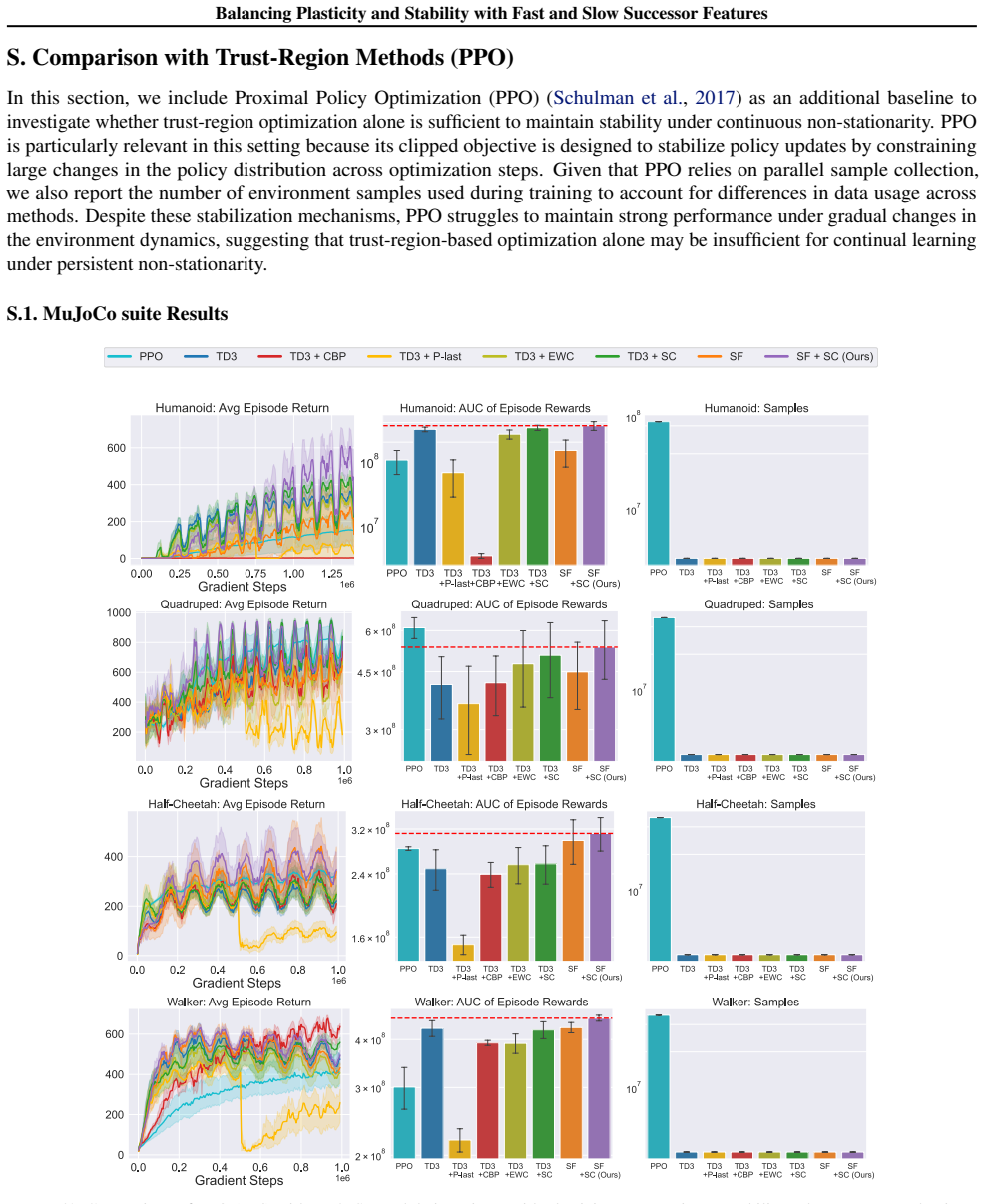
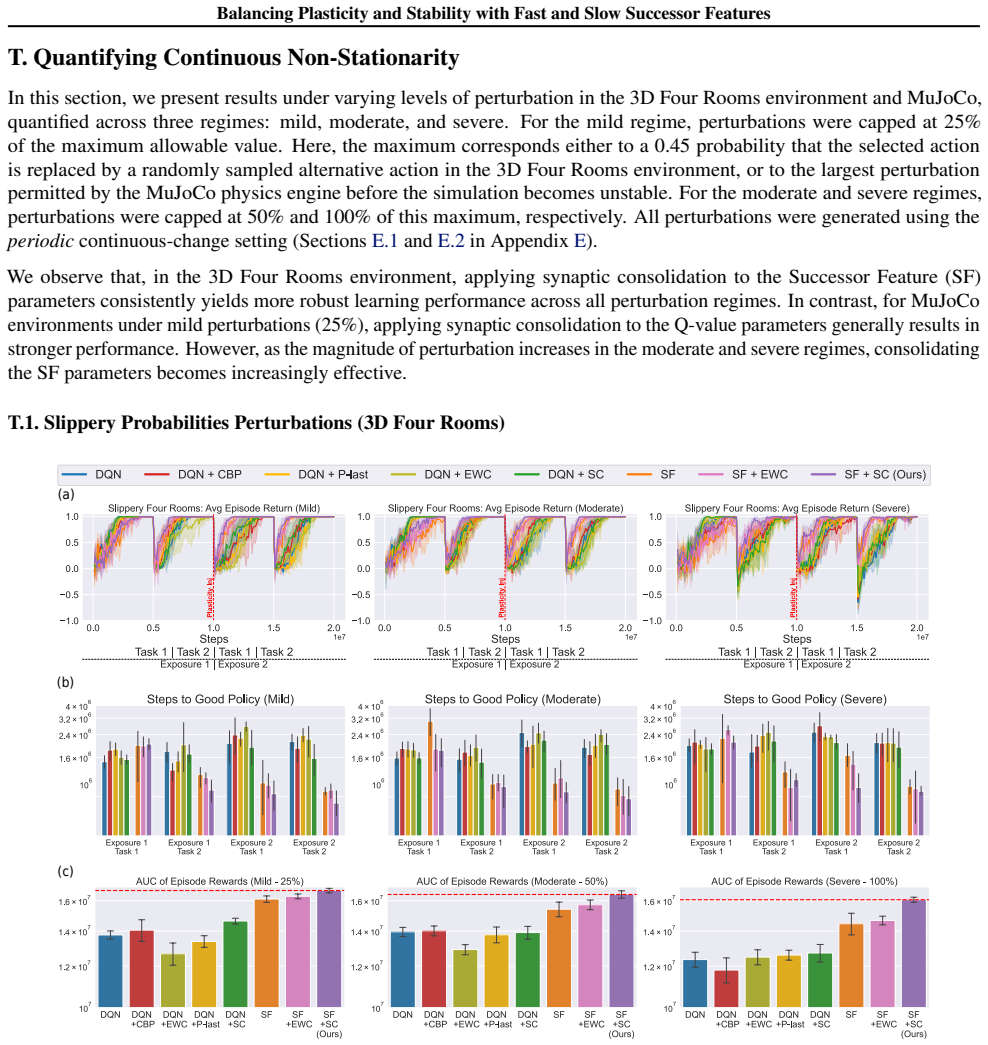
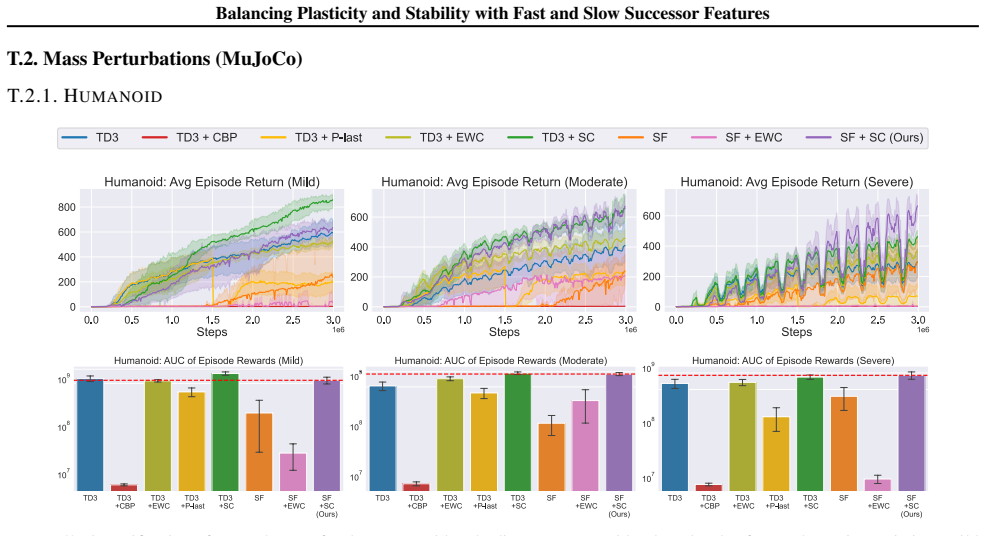
A hallmark of intelligence is the ability to adapt in non-stationary environments, yet deep Reinforcement Learning (RL) agents often struggle in such settings. Prior studies introduce non-stationarity through abrupt shifts in features or dynamics, whereas real-world environments often evolve gradually through continual drift. This distinction has important implications for the "stability-plasticity dilemma" in RL, as abrupt task changes may demand more plasticity than naturalistic settings. To address this, we modify existing 3D Miniworld and MuJoCo environments to incorporate naturalistic, continual non-stationarity, and use them to examine how stability and adaptation affect performance under continuous environmental change. We find that methods favoring stability, such as synaptic consolidation, outperform approaches focused on plasticity, such as parameters resetting. Motivated by this result, and prior evidence that Successor Features (SFs) reduce interference, we investigate whether SFs are better consolidation targets than Q-values. Across both environments, applying neuro-inspired synaptic consolidation to SFs yields superior performance on continually changing settings. Moreover, consolidation is most effective when SFs are stabilized across multiple timescales, which capture complementary aspects of gradual environmental change. Together, these results suggest that stability is more critical in continual learning when changes are gradual, and that multi-timescale consolidation of predictive representations is an effective approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript modifies 3D Miniworld and MuJoCo environments to include gradual, continual non-stationarity and compares synaptic consolidation applied to successor features (SFs) against plasticity-focused baselines such as parameter resetting. It reports that consolidation on SFs, particularly when performed across multiple timescales, yields superior performance under these drifting conditions and concludes that stability is more critical than plasticity for gradual environmental change.
Significance. If the empirical results are robust, the work supplies concrete evidence that predictive representations such as SFs can serve as effective consolidation targets and that multi-timescale stabilization captures complementary aspects of slow environmental drift. This would strengthen the case for stability-oriented mechanisms in continual RL and motivate further investigation of timescale-separated representations.
major comments (2)
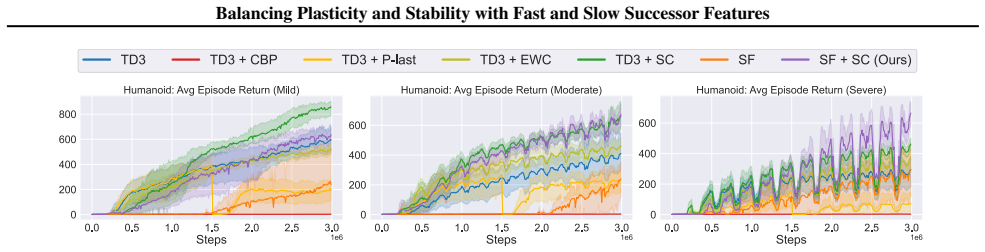
- [Environment modification] Environment modification section: the functional form, rate, and scope of the introduced drift (whether applied to rewards, transitions, or visual features; linear, sinusoidal, or stochastic) are not specified. Because the central claim that multi-timescale SF consolidation outperforms plasticity baselines rests on these environments faithfully instantiating naturalistic gradual change, the absence of this detail leaves open the possibility that observed gains are artifacts of the particular drift implementation.
- [Experimental results] Experimental results: the abstract asserts empirical superiority of consolidation on SFs, yet the manuscript supplies no information on the number of independent runs, statistical tests performed, or controls for confounding implementation choices. Without these, the reported performance differences cannot be assessed as reliable support for the stability-plasticity claim.
minor comments (1)
- [Method] Notation for the fast and slow successor-feature components is introduced without an explicit equation relating them to the standard SF definition; adding this would clarify the multi-timescale construction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify areas where additional detail will strengthen the manuscript's clarity and support for its claims. We address each point below and will revise accordingly.
read point-by-point responses
-
Referee: [Environment modification] Environment modification section: the functional form, rate, and scope of the introduced drift (whether applied to rewards, transitions, or visual features; linear, sinusoidal, or stochastic) are not specified. Because the central claim that multi-timescale SF consolidation outperforms plasticity baselines rests on these environments faithfully instantiating naturalistic gradual change, the absence of this detail leaves open the possibility that observed gains are artifacts of the particular drift implementation.
Authors: We agree that precise specification of the drift is essential for reproducibility and to substantiate that the environments capture gradual naturalistic change. In the revised manuscript we will expand the Environment modification section with the exact functional forms, rates, scopes (rewards, transitions, visual features), and any stochastic components used in both the 3D Miniworld and MuJoCo setups. revision: yes
-
Referee: [Experimental results] Experimental results: the abstract asserts empirical superiority of consolidation on SFs, yet the manuscript supplies no information on the number of independent runs, statistical tests performed, or controls for confounding implementation choices. Without these, the reported performance differences cannot be assessed as reliable support for the stability-plasticity claim.
Authors: We acknowledge that reporting the number of independent runs, statistical tests, and controls is required to evaluate reliability. The revised manuscript will include these details (number of random seeds, statistical tests with p-values, and controls for implementation choices) in the Experimental results section and figure captions. revision: yes
Circularity Check
No significant circularity; paper is purely empirical.
full rationale
The manuscript contains no derivations, equations, or fitted parameters presented as predictions. All claims rest on experimental comparisons of consolidation methods versus baselines in modified environments. These results are externally falsifiable through replication and do not reduce to self-definition, self-citation load-bearing, or renaming of known results. The central premise (superiority of multi-timescale SF consolidation under gradual drift) is supported by performance metrics rather than by construction from its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abbas, Z., Zhao, R., Modayil, J., White, A., and Machado, M. C. Loss of plasticity in continual deep reinforcement learning. In Conference on lifelong learning agents, pp.\ 620--636. PMLR, 2023
2023
-
[2]
P., and Singh, S
Abel, D., Barreto, A., Van Roy, B., Precup, D., van Hasselt, H. P., and Singh, S. A definition of continual reinforcement learning. Advances in Neural Information Processing Systems, 36: 0 50377--50407, 2023
2023
-
[3]
and Precup, D
Anand, N. and Precup, D. Prediction and control in continual reinforcement learning. Advances in Neural Information Processing Systems, 36: 0 63779--63817, 2023
2023
-
[4]
J., Schaul, T., van Hasselt, H
Barreto, A., Dabney, W., Munos, R., Hunt, J. J., Schaul, T., van Hasselt, H. P., and Silver, D. Successor features for transfer in reinforcement learning. Advances in neural information processing systems, 30, 2017
2017
-
[5]
G., Naddaf, Y., Veness, J., and Bowling, M
Bellemare, M. G., Naddaf, Y., Veness, J., and Bowling, M. The arcade learning environment: An evaluation platform for general agents. Journal of artificial intelligence research, 47: 0 253--279, 2013
2013
-
[6]
K., Kolouri, S., and Soltoggio, A
Ben-Iwhiwhu, E., Nath, S., Pilly, P. K., Kolouri, S., and Soltoggio, A. Lifelong reinforcement learning with modulating masks. arXiv preprint arXiv:2212.11110, 2022
-
[7]
Benna, M. K. and Fusi, S. Computational principles of synaptic memory consolidation. Nature neuroscience, 19 0 (12): 0 1697--1706, 2016
2016
-
[8]
Experiment tracking with weights and biases, 2020
Biewald, L. Experiment tracking with weights and biases, 2020. URL https://www.wandb.com/. Software available from wandb.com
2020
-
[9]
Universal Successor Features Approximators
Borsa, D., Barreto, A., Quan, J., Mankowitz, D., Munos, R., Van Hasselt, H., Silver, D., and Schaul, T. Universal successor features approximators. arXiv preprint arXiv:1812.07626, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
J., Leary, C., Maclaurin, D., Necula, G., Paszke, A., Vander P las, J., Wanderman- M ilne, S., and Zhang, Q
Bradbury, J., Frostig, R., Hawkins, P., Johnson, M. J., Leary, C., Maclaurin, D., Necula, G., Paszke, A., Vander P las, J., Wanderman- M ilne, S., and Zhang, Q. JAX : composable transformations of P ython+ N um P y programs, 2018. URL http://github.com/google/jax
2018
-
[11]
Task-agnostic continual reinforcement learning: Gaining insights and overcoming challenges
Caccia, M., Mueller, J., Kim, T., Charlin, L., and Fakoor, R. Task-agnostic continual reinforcement learning: Gaining insights and overcoming challenges. In Conference on Lifelong Learning Agents, pp.\ 89--119. PMLR, 2023
2023
-
[12]
Chevalier-Boisvert, M., Dai, B., Towers, M., de Lazcano, R., Willems, L., Lahlou, S., Pal, S., Castro, P. S., and Terry, J. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. CoRR, abs/2306.13831, 2023
-
[13]
A., and Precup, D
Chua, R., Ghosh, A., Kaplanis, C., Richards, B. A., and Precup, D. Learning successor features the simple way. Advances in Neural Information Processing Systems, 37: 0 49957--50030, 2024
2024
-
[14]
F., Lan, Q., Rahman, P., Mahmood, A
Dohare, S., Hernandez-Garcia, J. F., Lan, Q., Rahman, P., Mahmood, A. R., and Sutton, R. S. Loss of plasticity in deep continual learning. Nature, 632 0 (8026): 0 768--774, 2024
2024
-
[15]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
French, R. M. Catastrophic forgetting in connectionist networks. Trends in cognitive sciences, 3 0 (4): 0 128--135, 1999
1999
-
[17]
Addressing function approximation error in actor-critic methods, 2018
Fujimoto, S., van Hoof, H., and Meger, D. Addressing function approximation error in actor-critic methods, 2018
2018
-
[18]
J raph: A library for graph neural networks in jax., 2020
Godwin*, J., Keck*, T., Battaglia, P., Bapst, V., Kipf, T., Li, Y., Stachenfeld, K., Veli c kovi\' c , P., and Sanchez-Gonzalez, A. J raph: A library for graph neural networks in jax., 2020. URL http://github.com/deepmind/jraph
2020
-
[19]
F lax: A neural network library and ecosystem for JAX , 2024
Heek, J., Levskaya, A., Oliver, A., Ritter, M., Rondepierre, B., Steiner, A., and van Z ee, M. F lax: A neural network library and ecosystem for JAX , 2024. URL http://github.com/google/flax
2024
-
[20]
Hunter, J. D. Matplotlib: A 2d graphics environment. Computing in Science & Engineering, 9 0 (3): 0 90--95, 2007. doi:10.1109/MCSE.2007.55
-
[21]
Continual reinforcement learning with complex synapses
Kaplanis, C., Shanahan, M., and Clopath, C. Continual reinforcement learning with complex synapses. In International Conference on Machine Learning, pp.\ 2497--2506. PMLR, 2018
2018
-
[22]
Policy Consolidation for Continual Reinforcement Learning
Kaplanis, C., Shanahan, M., and Clopath, C. Policy consolidation for continual reinforcement learning. arXiv preprint arXiv:1902.00255, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[23]
Kaplanis, C., Clopath, C., and Shanahan, M. Continual reinforcement learning with multi-timescale replay (2020). DOI: https://doi. org/10.48550/arXiv, 2020
work page internal anchor Pith review doi:10.48550/arxiv 2020
-
[24]
Towards continual reinforcement learning: A review and perspectives
Khetarpal, K., Riemer, M., Rish, I., and Precup, D. Towards continual reinforcement learning: A review and perspectives. Journal of Artificial Intelligence Research, 75: 0 1401--1476, 2022
2022
-
[25]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[26]
Kingma, D. P. and Welling, M. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[27]
A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., et al. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114 0 (13): 0 3521--3526, 2017
2017
-
[28]
Jupyter notebooks -- a publishing format for reproducible computational workflows
Kluyver, T., Ragan-Kelley, B., P \'e rez, F., Granger, B., Bussonnier, M., Frederic, J., Kelley, K., Hamrick, J., Grout, J., Corlay, S., Ivanov, P., Avila, D., Abdalla, S., and Willing, C. Jupyter notebooks -- a publishing format for reproducible computational workflows. In Loizides, F. and Schmidt, B. (eds.), Positioning and Power in Academic Publishing:...
2016
-
[29]
Slow and steady wins the race: Maintaining plasticity with hare and tortoise networks
Lee, H., Cho, H., Kim, H., Kim, D., Min, D., Choo, J., and Lyle, C. Slow and steady wins the race: Maintaining plasticity with hare and tortoise networks. arXiv preprint arXiv:2406.02596, 2024
-
[30]
Continuous control with deep reinforcement learning
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N., Erez, T., Tassa, Y., Silver, D., and Wierstra, D. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
Disentangling the causes of plasticity loss in neural networks
Lyle, C., Zheng, Z., Khetarpal, K., van Hasselt, H., Pascanu, R., Martens, J., and Dabney, W. Disentangling the causes of plasticity loss in neural networks. arXiv preprint arXiv:2402.18762, 2024
-
[32]
L., McNaughton, B
McClelland, J. L., McNaughton, B. L., and O'Reilly, R. C. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychological review, 102 0 (3): 0 419, 1995
1995
-
[33]
and Cohen, N
McCloskey, M. and Cohen, N. J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of learning and motivation, volume 24, pp.\ 109--165. Elsevier, 1989
1989
-
[34]
The primacy bias in deep reinforcement learning
Nikishin, E., Schwarzer, M., D’Oro, P., Bacon, P.-L., and Courville, A. The primacy bias in deep reinforcement learning. In International conference on machine learning, pp.\ 16828--16847. PMLR, 2022
2022
-
[35]
Deep reinforcement learning with plasticity injection
Nikishin, E., Oh, J., Ostrovski, G., Lyle, C., Pascanu, R., Dabney, W., and Barreto, A. Deep reinforcement learning with plasticity injection. Advances in Neural Information Processing Systems, 36: 0 37142--37159, 2023
2023
-
[36]
Pytorch: An imperative style, high-performance deep learning library
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019
2019
-
[37]
Self-activating neural ensembles for continual reinforcement learning
Powers, S., Xing, E., and Gupta, A. Self-activating neural ensembles for continual reinforcement learning. In Conference on Lifelong Learning Agents, pp.\ 683--704. PMLR, 2022
2022
-
[38]
Learning to Learn without Forgetting by Maximizing Transfer and Minimizing Interference
Riemer, M., Cases, I., Ajemian, R., Liu, M., Rish, I., Tu, Y., and Tesauro, G. Learning to learn without forgetting by maximizing transfer and minimizing interference. arXiv preprint arXiv:1810.11910, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Experience replay for continual learning
Rolnick, D., Ahuja, A., Schwarz, J., Lillicrap, T., and Wayne, G. Experience replay for continual learning. Advances in neural information processing systems, 32, 2019
2019
-
[40]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[41]
W., Pascanu, R., and Hadsell, R
Schwarz, J., Czarnecki, W., Luketina, J., Grabska-Barwinska, A., Teh, Y. W., Pascanu, R., and Hadsell, R. Progress & compress: A scalable framework for continual learning. In International conference on machine learning, pp.\ 4528--4537. PMLR, 2018
2018
-
[42]
and Sutton, R
Silver, D. and Sutton, R. S. Welcome to the era of experience. Google AI, 1, 2025
2025
-
[43]
Deterministic policy gradient algorithms
Silver, D., Lever, G., Heess, N., Degris, T., Wierstra, D., and Riedmiller, M. Deterministic policy gradient algorithms. In International conference on machine learning, pp.\ 387--395. Pmlr, 2014
2014
-
[44]
S., and Evci, U
Sokar, G., Agarwal, R., Castro, P. S., and Evci, U. The dormant neuron phenomenon in deep reinforcement learning. In International Conference on Machine Learning, pp.\ 32145--32168. PMLR, 2023
2023
-
[45]
Sutton, R. S. and Barto, A. G. Reinforcement learning: An introduction. MIT press, 2018
2018
-
[46]
Mujoco: A physics engine for model-based control
Todorov, E., Erez, T., and Tassa, Y. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems, pp.\ 5026--5033. IEEE, 2012
2012
-
[47]
dm\_control: Software and tasks for continuous control
Tunyasuvunakool, S., Muldal, A., Doron, Y., Liu, S., Bohez, S., Merel, J., Erez, T., Lillicrap, T., Heess, N., and Tassa, Y. dm\_control: Software and tasks for continuous control. Software Impacts, 6: 0 100022, 2020
2020
-
[48]
Deep reinforcement learning with double q-learning
Van Hasselt, H., Guez, A., and Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI conference on artificial intelligence, 2016
2016
-
[49]
and Drake, F
Van Rossum, G. and Drake, F. L. Python 3 Reference Manual. CreateSpace, Scotts Valley, CA, 2009. ISBN 1441412697
2009
-
[50]
Waskom, M. L. seaborn: statistical data visualization. Journal of Open Source Software, 6 0 (60): 0 3021, 2021. doi:10.21105/joss.03021. URL https://doi.org/10.21105/joss.03021
-
[51]
Deep reinforcement learning amidst lifelong non-stationarity
Xie, A., Harrison, J., and Finn, C. Deep reinforcement learning amidst lifelong non-stationarity. arXiv preprint arXiv:2006.10701, 2020
-
[52]
Hydra - a framework for elegantly configuring complex applications
Yadan, O. Hydra - a framework for elegantly configuring complex applications. Github, 2019. URL https://github.com/facebookresearch/hydra
2019
-
[53]
Mastering visual continuous control: Improved data-augmented reinforcement learning
Yarats, D., Fergus, R., Lazaric, A., and Pinto, L. Mastering visual continuous control: Improved data-augmented reinforcement learning. arXiv preprint arXiv:2107.09645, 2021
-
[54]
Continual learning through synaptic intelligence
Zenke, F., Poole, B., and Ganguli, S. Continual learning through synaptic intelligence. In International conference on machine learning, pp.\ 3987--3995. PMLR, 2017
2017
-
[55]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.