Advancing Creative Physical Intelligence in Large Multimodal Models
Pith reviewed 2026-06-29 21:07 UTC · model grok-4.3
The pith
Large multimodal models improve at creative tool use when trained to prefer visually grounded affordances over hallucinations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current LMMs often overlook relevant entities, under-examine critical parts, or hallucinate attributes not grounded in the image when attempting creative tool use in visually rich scenes. Affordance-grounded alignment casts the task as a preference learning problem solved with Direct Preference Optimization, encouraging models to prefer attribute-affordance reasoning grounded in visual evidence over hallucinated alternatives while incorporating supervision from an affordance knowledge base to guide entity exploration and multi-turn planning.
What carries the argument
affordance-grounded alignment, which uses Direct Preference Optimization on pairs that contrast grounded visual reasoning against hallucinated alternatives, supplemented by supervision from an affordance knowledge base.
If this is right
- Models select correct entities and parts more reliably across benchmark scenarios.
- Hallucination and grounding-related errors decrease substantially after alignment.
- Creative tool use becomes framed as iterative inspection and preference learning rather than one-shot generation.
- Multi-turn planning improves when guided by the knowledge base for broader entity exploration.
Where Pith is reading between the lines
- The same preference-learning approach could extend to other open-ended visual tasks that require physical feasibility judgments.
- If the knowledge base coverage is limited, performance may degrade on novel object combinations not represented in the supervision.
- Iterative inspection behavior learned here might transfer to robotic manipulation planning that relies on visual affordance detection.
Load-bearing premise
The affordance knowledge base supplies accurate, unbiased supervision that correctly identifies physically feasible creative uses without injecting distorting artifacts into the preference data.
What would settle it
A test set of scene images whose correct creative uses contradict the affordance knowledge base, measuring whether the aligned models still reduce hallucinations relative to baselines.
Figures


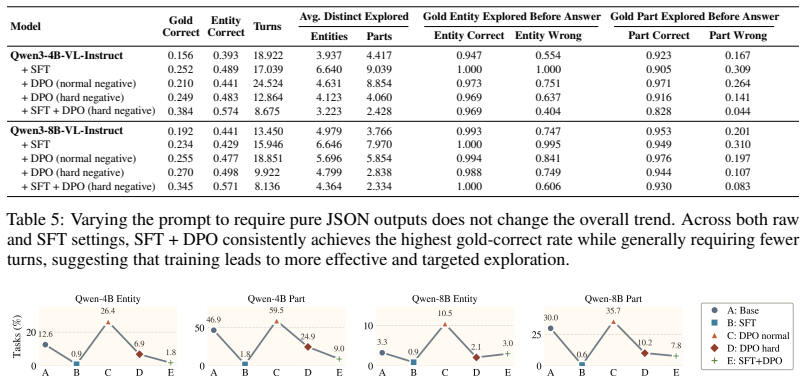
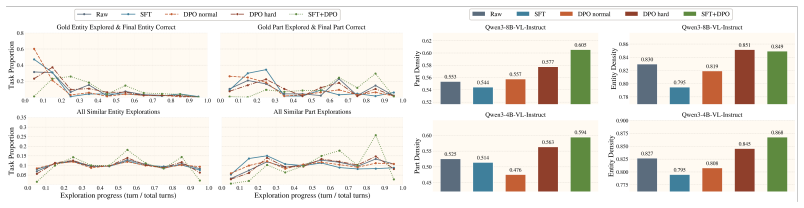
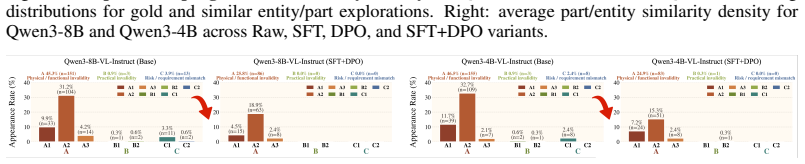
read the original abstract
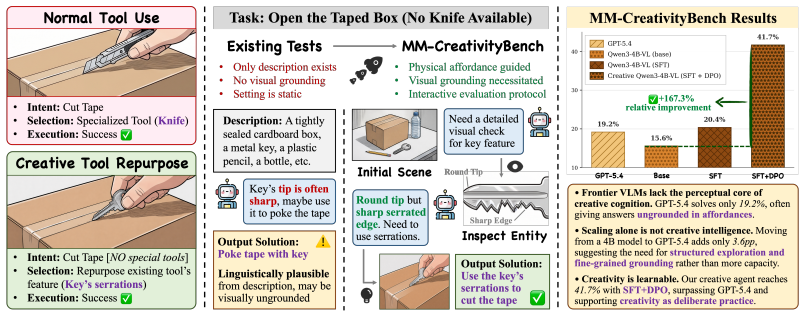
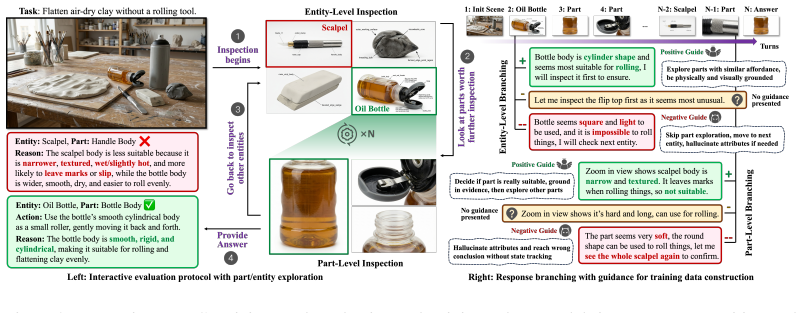
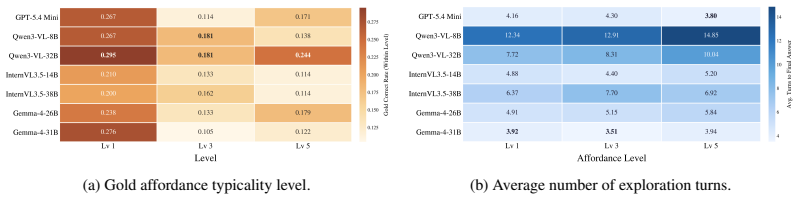
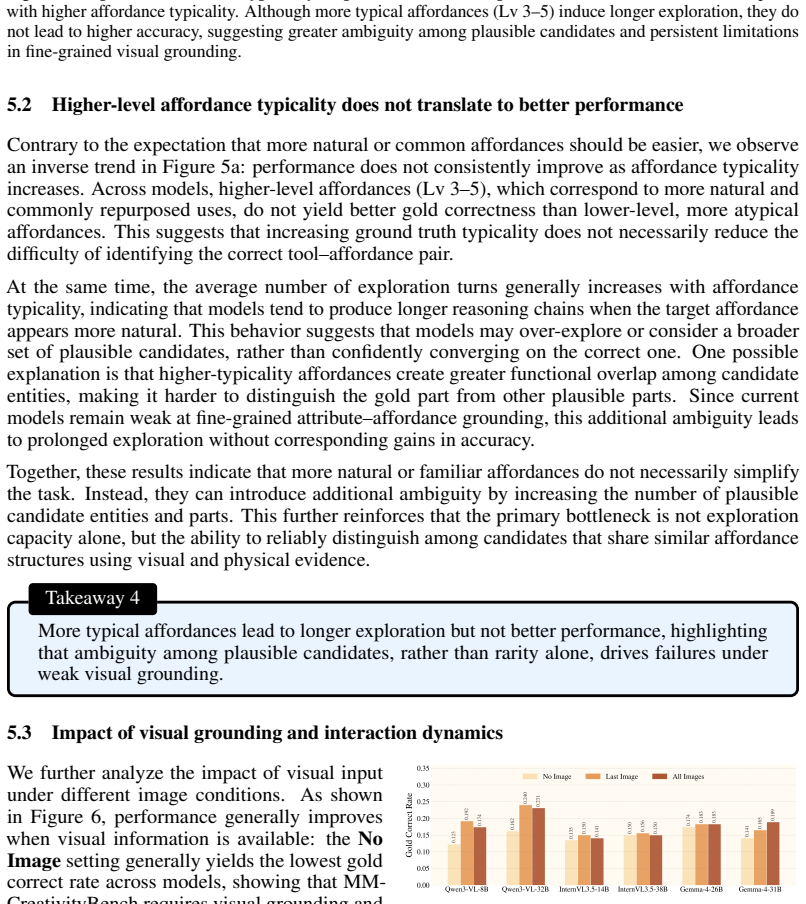
Large multimodal models (LMMs) have rapidly advanced in perception and reasoning; however, it remains unclear whether these capabilities generalize to discovering visually grounded solutions in open-ended environments, beyond pattern recognition. In such settings, intelligence requires more than answering well-posed questions: it involves identifying how elements in a scene can be repurposed in non-obvious yet physically feasible ways. This form of creative problem-solving is central to human intelligence, but remains largely untested in current benchmarks. To evaluate this ability, we introduce MM-CreativityBench, a benchmark for affordance-grounded creative tool use in visually rich, physically constrained environments. Each instance presents a scenario image with structured views of candidate entities and their parts, enabling fine-grained, interactive evaluation of how models iteratively inspect the scene, identify relevant affordances, and compose visually and physically grounded solutions. Our experiments show that current LMMs often fall short, not due to lack of generative capability, but because they do not sustain grounded exploration. Models often overlook relevant entities, under-examine critical parts, or hallucinate attributes not grounded in the image. Motivated by this failure mode, we propose affordance-grounded alignment, which casts creative tool use as a preference learning problem. Using Direct Preference Optimization, we encourage models to prefer attribute-affordance reasoning grounded in visual evidence over hallucinated alternatives. In addition, we incorporate supervision derived from an affordance knowledge base to guide broader entity exploration and multi-turn planning. Our results show consistent gains in selecting the correct entities and parts, while substantially reducing hallucination and grounding-related errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MM-CreativityBench, a new benchmark for evaluating affordance-grounded creative tool use by LMMs in visually rich, physically constrained scenes. It argues that current LMMs fail at sustained grounded exploration (overlooking entities, under-examining parts, hallucinating attributes) rather than lacking generative ability. To address this, the authors propose affordance-grounded alignment: casting the task as a preference learning problem solved via Direct Preference Optimization (DPO), with preferences derived from an affordance knowledge base to encourage visual-evidence-based reasoning, broader entity exploration, and multi-turn planning. Experiments are reported to show consistent gains in correct entity/part selection and reductions in hallucination and grounding errors.
Significance. If the central empirical claims hold, the work identifies a concrete failure mode in LMMs for open-ended creative physical reasoning and supplies a targeted alignment method that improves grounding without requiring new architectures. The introduction of a structured, interactive benchmark focused on affordances is a useful contribution to evaluation in multimodal AI. The approach of using KB-derived supervision for DPO is a direct response to the diagnosed failure mode and could generalize to other grounding-sensitive tasks.
major comments (2)
- [affordance-grounded alignment / data construction] The central empirical claim (consistent gains from affordance-grounded DPO) rests on the quality of the affordance knowledge base used to generate preference data. The manuscript does not appear to include validation experiments, inter-annotator agreement, or bias audits for this KB (see the section describing affordance-grounded alignment and the data construction pipeline). Without such evidence, it is difficult to rule out that reported improvements partly reflect artifacts of the KB rather than genuine gains in grounded exploration.
- [experimental setup / results] Evaluation relies on a newly introduced benchmark (MM-CreativityBench) whose preference labels are themselves derived from the same affordance knowledge base and task definition. The paper should include an explicit analysis of whether this introduces circularity or self-reinforcement in the reported metrics (see the experimental setup and results sections).
minor comments (2)
- [abstract / results] The abstract asserts 'consistent gains' and 'substantially reducing' errors but supplies no numerical values, baselines, dataset sizes, or statistical tests. The results section should present these quantities with error bars and significance tests to allow readers to assess the magnitude and reliability of the improvements.
- [method] Notation for the preference pairs and the role of the KB in the DPO loss should be formalized with equations to make the training objective reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the affordance knowledge base and potential evaluation circularity. We address each major comment below with the strongest honest response supported by the manuscript.
read point-by-point responses
-
Referee: [affordance-grounded alignment / data construction] The central empirical claim (consistent gains from affordance-grounded DPO) rests on the quality of the affordance knowledge base used to generate preference data. The manuscript does not appear to include validation experiments, inter-annotator agreement, or bias audits for this KB (see the section describing affordance-grounded alignment and the data construction pipeline). Without such evidence, it is difficult to rule out that reported improvements partly reflect artifacts of the KB rather than genuine gains in grounded exploration.
Authors: We acknowledge that the current manuscript does not report explicit validation experiments, inter-annotator agreement statistics, or formal bias audits for the affordance knowledge base. The KB was assembled from established affordance taxonomies in the robotics and cognitive science literature combined with scene-specific physical constraints defined by the benchmark creators. While this construction process is described in the data pipeline section, we agree that additional transparency would strengthen the paper. The observed gains appear across independent metrics (correct entity selection, part-level inspection depth, and hallucination rate) and hold for multiple LMM backbones, which would be unlikely under pure KB artifact effects. We will revise the manuscript to expand the KB construction description and add any available internal consistency checks. revision: partial
-
Referee: [experimental setup / results] Evaluation relies on a newly introduced benchmark (MM-CreativityBench) whose preference labels are themselves derived from the same affordance knowledge base and task definition. The paper should include an explicit analysis of whether this introduces circularity or self-reinforcement in the reported metrics (see the experimental setup and results sections).
Authors: We recognize the shared provenance between the DPO preference pairs and the benchmark labels. However, the benchmark itself measures interactive, multi-turn behavior (entity exploration order, part examination, and final solution grounding) rather than simple label matching; the reported metrics further incorporate human verification of visual evidence. The DPO objective trains the model to prefer KB-grounded reasoning chains over hallucinated ones, while the evaluation tests whether this preference translates to better exploration policies. This is not self-reinforcement in the sense of training and testing on identical instances. We will add an explicit subsection in the revised experimental setup discussing this relationship and the safeguards against circular evaluation. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces MM-CreativityBench as a new evaluation benchmark and proposes affordance-grounded alignment via DPO using an external knowledge base for preference data. No equations, self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described claims. The central derivation (DPO alignment improving grounded exploration) remains independent of its own outputs and does not reduce to a tautology or author-prior ansatz by construction. This is the expected self-contained case for an empirical methods paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Direct Preference Optimization applied to attribute-affordance reasoning pairs will produce models that prefer grounded visual evidence over hallucinated alternatives.
- domain assumption Supervision derived from an affordance knowledge base can guide broader entity exploration and multi-turn planning without introducing non-physical artifacts.
Reference graph
Works this paper leans on
-
[1]
Storium: A dataset and evaluation platform for machine-in-the-loop story generation
Nader Akoury, Shufan Wang, Josh Whiting, Stephen Hood, Nanyun Peng, and Mohit Iyyer. Storium: A dataset and evaluation platform for machine-in-the-loop story generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6470–6484, 2020
2020
-
[2]
Prost: Physical reasoning about objects through space and time
Stéphane Aroca-Ouellette, Cory Paik, Alessandro Roncone, and Katharina von der Wense. Prost: Physical reasoning about objects through space and time. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4597–4608, 2021
2021
-
[3]
Grounded cognition.Annu
Lawrence W Barsalou. Grounded cognition.Annu. Rev. Psychol., 59(1):617–645, 2008
2008
-
[4]
Piqa: Reasoning about phys- ical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about phys- ical commonsense in natural language. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020
2020
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision- language-action models transfer web knowledge to robotic control, 2023.URL https://arxiv. org/abs/2307.15818, 1:2, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[8]
Large language models as tool makers, 2024
Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, and Denny Zhou. Large language models as tool makers.arXiv preprint arXiv:2305.17126, 2023
-
[9]
Visdiahalbench: A visual dialogue benchmark for diagnosing hallucination in large vision-language models
Qingxing Cao, Junhao Cheng, Xiaodan Liang, and Liang Lin. Visdiahalbench: A visual dialogue benchmark for diagnosing hallucination in large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12161–12176, 2024
2024
-
[10]
Multi-object hallucination in vision language models.Advances in Neural Information Processing Systems, 37:44393–44418, 2024
Xuweiyi Chen, Ziqiao Ma, Xuejun Zhang, Sihan Xu, Jianing Yang, David F Fouhey, Joyce Chai, and Shengyi Qian. Multi-object hallucination in vision language models.Advances in Neural Information Processing Systems, 37:44393–44418, 2024
2024
-
[11]
Learning affordance segmentation for real- world robotic manipulation via synthetic images.IEEE Robotics and Automation Letters, 4(2): 1140–1147, 2019
Fu-Jen Chu, Ruinian Xu, and Patricio A Vela. Learning affordance segmentation for real- world robotic manipulation via synthetic images.IEEE Robotics and Automation Letters, 4(2): 1140–1147, 2019
2019
-
[12]
Villageragent: A graph- based multi-agent framework for coordinating complex task dependencies in minecraft
Yubo Dong, Xukun Zhu, Zhengzhe Pan, Linchao Zhu, and Yi Yang. Villageragent: A graph- based multi-agent framework for coordinating complex task dependencies in minecraft. In Findings of the Association for Computational Linguistics: ACL 2024, pages 16290–16314, 2024. 16
2024
-
[13]
Creation-mmbench: Assessing context- aware creative intelligence in mllms
Xinyu Fang, Zhijian Chen, Kai Lan, Lixin Ma, Shengyuan Ding, Yingji Liang, Xiangyu Zhao, Farong Wen, Zicheng Zhang, Guofeng Zhang, et al. Creation-mmbench: Assessing context- aware creative intelligence in mllms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 447–456, 2025
2025
-
[14]
Psychology press, 2014
James J Gibson.The ecological approach to visual perception: classic edition. Psychology press, 2014
2014
-
[15]
Synthia: Novel concept de- sign with affordance composition
Hyeonjeong Ha, Xiaomeng Jin, Jeonghwan Kim, Jiateng Liu, Zhenhailong Wang, Khanh Duy Nguyen, Ansel Blume, Nanyun Peng, Kai-Wei Chang, and Heng Ji. Synthia: Novel concept de- sign with affordance composition. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 20939–20958, 2025
2025
-
[16]
A causality-aware paradigm for evaluating creativity of multimodal large language models
Zhongzhan Huang, Shanshan Zhong, Pan Zhou, Shanghua Gao, Marinka Zitnik, and Liang Lin. A causality-aware paradigm for evaluating creativity of multimodal large language models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[17]
Affordances in psychology, neuroscience, and robotics: A survey
Lorenzo Jamone, Emre Ugur, Angelo Cangelosi, Luciano Fadiga, Alexandre Bernardino, Justus Piater, and José Santos-Victor. Affordances in psychology, neuroscience, and robotics: A survey. IEEE Transactions on Cognitive and Developmental Systems, 10(1):4–25, 2016
2016
-
[18]
macmillan, 2011
Daniel Kahneman.Thinking, fast and slow. macmillan, 2011
2011
-
[19]
Visescape: A benchmark for evaluating exploration-driven decision-making in virtual escape rooms
Seungwon Lim, Sungwoong Kim, Jihwan Yu, Sungjae Lee, Jiwan Chung, and Youngjae Yu. Visescape: A benchmark for evaluating exploration-driven decision-making in virtual escape rooms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16031–16058, 2025
2025
-
[20]
Shuo Liu, Kaining Ying, Hao Zhang, Yue Yang, Yuqi Lin, Tianle Zhang, Chuanhao Li, Yu Qiao, Ping Luo, Wenqi Shao, et al. Convbench: A multi-turn conversation evaluation benchmark with hierarchical capability for large vision-language models.arXiv preprint arXiv:2403.20194, 2024
-
[21]
arXiv preprint arXiv:2408.06327 (2024)
Xiao Liu, Tianjie Zhang, Yu Gu, Iat Long Iong, Yifan Xu, Xixuan Song, Shudan Zhang, Hanyu Lai, Xinyi Liu, Hanlin Zhao, et al. Visualagentbench: Towards large multimodal models as visual foundation agents.arXiv preprint arXiv:2408.06327, 2024
-
[22]
arXiv preprint arXiv:2410.17637 (2024)
Ziyu Liu, Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Haodong Duan, Conghui He, Yuanjun Xiong, Dahua Lin, and Jiaqi Wang. Mia-dpo: Multi-image augmented direct preference optimization for large vision-language models.arXiv preprint arXiv:2410.17637, 2024
-
[23]
Teli Ma, Zifan Wang, Jiaming Zhou, Mengmeng Wang, and Junwei Liang. Glover: Gen- eralizable open-vocabulary affordance reasoning for task-oriented grasping.arXiv preprint arXiv:2411.12286, 2024
-
[24]
Learning object affordances: from sensory–motor coordination to imitation.Ieee transactions on robotics, 24 (1):15–26, 2008
Luis Montesano, Manuel Lopes, Alexandre Bernardino, and José Santos-Victor. Learning object affordances: from sensory–motor coordination to imitation.Ieee transactions on robotics, 24 (1):15–26, 2008
2008
-
[25]
Creator: Tool creation for disentangling abstract and concrete reasoning of large language models
Cheng Qian, Chi Han, Yi Fung, Yujia Qin, Zhiyuan Liu, and Heng Ji. Creator: Tool creation for disentangling abstract and concrete reasoning of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 6922–6939, 2023
2023
-
[26]
Escapebench: Pushing language models to think outside the box.arXiv e-prints, pages arXiv–2412, 2024
Cheng Qian, Peixuan Han, Qinyu Luo, Bingxiang He, Xiusi Chen, Yuji Zhang, Hongyi Du, Jiarui Yao, Xiaocheng Yang, Denghui Zhang, et al. Escapebench: Pushing language models to think outside the box.arXiv e-prints, pages arXiv–2412, 2024
2024
-
[27]
Modelingagent: Bridging llms and mathematical modeling for real-world challenges
Cheng Qian, Hongyi Du, Hongru Wang, Xiusi Chen, Yuji Zhang, Avirup Sil, Chengxiang Zhai, Kathleen McKeown, and Heng Ji. Modelingagent: Bridging llms and mathematical modeling for real-world challenges. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 1599–1633, 2025. 17
2025
-
[28]
CreativityBench: Evaluating Agent Creative Reasoning via Affordance-Based Tool Repurposing
Cheng Qian, Hyeonjeong Ha, Jiayu Liu, Jeonghwan Kim, Jiateng Liu, Bingxuan Li, Aditi Tiwari, Dwip Dalal, Zhenhailong Wang, Xiusi Chen, Mahdi Namazifar, Yunzhu Li, and Heng Ji. Creativitybench: Evaluating agent creative reasoning via affordance-based tool repurposing. arXiv preprint arXiv:2605.02910, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Affordan- cellm: Grounding affordance from vision language models
Shengyi Qian, Weifeng Chen, Min Bai, Xiong Zhou, Zhuowen Tu, and Li Erran Li. Affordan- cellm: Grounding affordance from vision language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7587–7597, 2024
2024
-
[30]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[31]
Routledge, 2017
Robert Shaw and John Bransford.Perceiving, acting and knowing: Toward an ecological psychology. Routledge, 2017
2017
-
[32]
Chenglei Si, Tatsunori Hashimoto, and Diyi Yang
Chenglei Si, Diyi Yang, and Tatsunori Hashimoto. Can llms generate novel research ideas? a large-scale human study with 100+ nlp researchers.arXiv preprint arXiv:2409.04109, 2024
-
[33]
Robert J Sternberg.The triarchic theory of intelligence.The Guilford Press, 1997
1997
-
[34]
Yufei Tian, Abhilasha Ravichander, Lianhui Qin, Ronan Le Bras, Raja Marjieh, Nanyun Peng, Yejin Choi, Thomas L Griffiths, and Faeze Brahman. Macgyver: Are large language models creative problem solvers? InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1...
2024
-
[35]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. Planbench: An extensible benchmark for evaluating large language models on planning and reasoning about change.Advances in Neural Information Processing Systems, 36: 38975–38987, 2023
2023
-
[36]
mdpo: Conditional preference optimization for multimodal large language models
Fei Wang, Wenxuan Zhou, James Y Huang, Nan Xu, Sheng Zhang, Hoifung Poon, and Muhao Chen. mdpo: Conditional preference optimization for multimodal large language models. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8078–8088, 2024
2024
-
[37]
Scimon: Scientific inspiration machines optimized for novelty
Qingyun Wang, Doug Downey, Heng Ji, and Tom Hope. Scimon: Scientific inspiration machines optimized for novelty. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 279–299, 2024
2024
-
[38]
Newton: Are large language models capable of physical reasoning? InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 9743–9758, 2023
Yi Wang, Jiafei Duan, Dieter Fox, and Siddhartha Srinivasa. Newton: Are large language models capable of physical reasoning? InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 9743–9758, 2023
2023
-
[39]
CreativeBench: Benchmarking and Enhancing Machine Creativity via Self-Evolving Challenges
Zi-Han Wang, Lam Nguyen, Zhengyang Zhao, Mengyue Yang, Chengwei Qin, Yujiu Yang, and Linyi Yang. Creativebench: Benchmarking and enhancing machine creativity via self-evolving challenges.arXiv preprint arXiv:2603.11863, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Assoc...
2022
-
[41]
Autohallusion: Auto- matic generation of hallucination benchmarks for vision-language models
Xiyang Wu, Tianrui Guan, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shrivastava, Furong Huang, Jordan Lee Boyd-Graber, et al. Autohallusion: Auto- matic generation of hallucination benchmarks for vision-language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 8395–8419, 2024
2024
-
[42]
Large language models for automated open-domain scientific hypotheses discovery
Zonglin Yang, Xinya Du, Junxian Li, Jie Zheng, Soujanya Poria, and Erik Cambria. Large language models for automated open-domain scientific hypotheses discovery. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13545–13565, 2024. 18
2024
-
[43]
Seqafford: Sequential 3d affordance reasoning via multimodal large language model
Chunlin Yu, Hanqing Wang, Ye Shi, Haoyang Luo, Sibei Yang, Jingyi Yu, and Jingya Wang. Seqafford: Sequential 3d affordance reasoning via multimodal large language model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1691–1701, 2025
2025
-
[44]
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it?arXiv preprint arXiv:2210.01936, 2022
-
[45]
Investigating compositional challenges in vision-language models for visual grounding
Yunan Zeng, Yan Huang, Jinjin Zhang, Zequn Jie, Zhenhua Chai, and Liang Wang. Investigating compositional challenges in vision-language models for visual grounding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14141–14151, 2024. 19 Appendix A Significance, Scope, and Clarifications A.1 Why MM-CreativityBench M...
2024
-
[51]
solvable
If a complete solution is impossible, return the best partial plan and explain why it cannot be completed. TASK DESCRIPTION: {problem} Return JSON: {{ "solvable": "Yes or No", "solvable_explanation": "1-3 sentences about why the given task is solvable or not", "solution_steps": ["Step 1: ...", "Step 2: ...", ...], "final_solution": "One concise paragraph ...
-
[52]
Use only tools/items explicitly available in the input image
-
[53]
Respect physical constraints if the task description restricts physical attributes or image shows physical constraints such as size or state
-
[54]
Invent new tools using tools/items explicitly available in the input image if it is needed
-
[55]
Provide practical steps that can actually be executed
-
[56]
Do not involve any unnecessary steps to achieve the task's goal
-
[57]
Required reasoning procedure:
If a complete solution is impossible, return the best partial plan and explain why it cannot be completed. Required reasoning procedure:
-
[58]
State the task goal and concrete success condition
-
[59]
List all available tools/items from the input image (no additions)
-
[60]
For each relevant tool, identify the key part(s), infer physical properties, and derive part- level affordances useful for this task
-
[61]
Build a step-by-step plan where each step references tool parts and the affordance being used
-
[62]
Validate each step against stated constraints (e.g., broken/unusable items, size mismatch, blocked function, state limitations)
-
[63]
task_goal
Keep the plan practical and minimal with no unnecessary actions. TASK DESCRIPTION: {problem} Return JSON: {{ "task_goal": "...", "success_condition": "...", "identified_constraints": ["...", "..."], "available_tools": [ {{ "tool": "...", "relevant_parts": [ {{ "part": "... or NA", "inferred_physical_properties": ["...", "..."], 23 "affordances_for_task": ...
-
[64]
win" if solution1_score > solution2_score -
Determine winner: - "win" if solution1_score > solution2_score - "lose" if solution2_score > solution1_score - "tie" if both are equal
-
[65]
correctness
Give a short rationale (1-2 sentences). TASK DESCRIPTION: {problem} GROUND-TRUTH SOLUTION: {ground_truth_solution} CANDIDATE SOLUTION1 (DEFAULT PROMPT OUTPUT): {solution1} CANDIDATE SOLUTION2 (COT PROMPT OUTPUT): {solution2} Return STRICT JSON: {{ "correctness": {{ "winner": "win or lose or tie", "rationale": "1-2 sentences." }}, 24 "feasibility": {{ "win...
-
[66]
Target affordance to naturally reason toward: <TARGET_AFFORDANCE>
Start naturally by thinking about what kind of affordance the task needs. Target affordance to naturally reason toward: <TARGET_AFFORDANCE>
-
[67]
Express these as if you are inferring them yourself
Continue by thinking about the core attributes that would enable that affordance. Express these as if you are inferring them yourself. - <ATTRIBUTE_1> 30 - <ATTRIBUTE_2> -
-
[68]
Then naturally transition your reasoning into inspecting the environment
-
[69]
Go through all listed entities with no overlap and nothing left behind
-
[70]
For each entity, say where it is in the image if visible, then give a brief grounded description focused on visible physical and state cues
-
[71]
After covering all entities, name up to three candidate entities, explain briefly why they look promising, and show your intention to inspect those top candidates first and then continue through every other entity as well
-
[74]
Behave as if you are reasoning normally from the task and image; never mention hidden guidance, gold data, or prompt references
-
[77]
[ENTITY FEEDBACK PROMPT] ## Feedback Basis ENTITY INSPECTION: <ENTITY_NAME> This entity includes these exact part names: <PART_NAME_1>, <PART_NAME_2>,
The top_candidates field is required in the JSON for this round. [ENTITY FEEDBACK PROMPT] ## Feedback Basis ENTITY INSPECTION: <ENTITY_NAME> This entity includes these exact part names: <PART_NAME_1>, <PART_NAME_2>, ... ## Guidance on Reasoning Please perform visual grounding for each part first and explain in your own words why it may or may not achieve ...
-
[78]
Observe and reason about all parts with no overlap and nothing left behind
-
[79]
Base your reasoning on visible cues and the provided reference, but do not copy the reference text verbatim
-
[80]
Keep the reasoning natural and coherent, as if you are figuring it out normally
-
[82]
reasoning
Copy part or entity names exactly. (If this is the last exploration step, use:) This is the last exploration step. Reason through every part, explain why none of them finally solves the need well enough, and end by explicitly saying this is the last entity you need to explore and you should now move on to the final answer. Do not output any JSON in this t...
-
[83]
Keep the reasoning grounded; do not copy the reference dictionaries directly
-
[86]
enable_affordance
If this is the last exploration step, the final JSON must contain only enable_affordance. Otherwise, copy the next part or entity name exactly when you emit JSON. (If inspecting gold part, insert:) Note that the part you are inspecting now is the gold part of the gold entity. Do not reveal this, but you must conclude that it can serve the intended need. (...
-
[88]
reasoning
Part name: <CANDIDATE_PART_NAME_2>, belongs to entity <CANDIDATE_ENTITY_NAME_2> ... Now choose one of them as your final answer, explain how to use it, and return JSON in this format: {"reasoning":"...","action":"answer","answer_entity":"<exact entity name>","answer_part":"<exact part name>","answer_how_to_use":"..."} ## Guidance on Reasoning Gold entity ...
-
[89]
Naturally list all the promising candidate parts as shown above
-
[90]
Explicitly choose the best one; your final answer must be the provided gold entity and gold part
-
[91]
If no other candidate parts are listed above, skip comparison naturally
Compare the gold part only against the other candidate parts listed above, one by one. If no other candidate parts are listed above, skip comparison naturally. 32
-
[92]
prepare_use_condition
Then explain how to use the gold part in a concrete, comprehensive way. Keep the reasoning natural and coherent, and do not mention hidden guidance. Write full prose reasoning first. Then start the final JSON on a new line. The JSON must appear only once, at the very end. Inside the JSON, the reasoning field should be only a very brief summary. Make answe...
-
[93]
Target affordance to loosely reason around: <TARGET_AFFORDANCE>
Start naturally by thinking about what kind of affordance the task seems to need. Target affordance to loosely reason around: <TARGET_AFFORDANCE>
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.