TPS-Drive: Task-Guided Representation Purification for VLM-based Autonomous Driving
Pith reviewed 2026-06-29 17:40 UTC · model grok-4.3
The pith
An agent-centric tokenizer uses frozen 3D detection to reallocate codebook capacity from backgrounds to dynamic agents in VLM-based driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
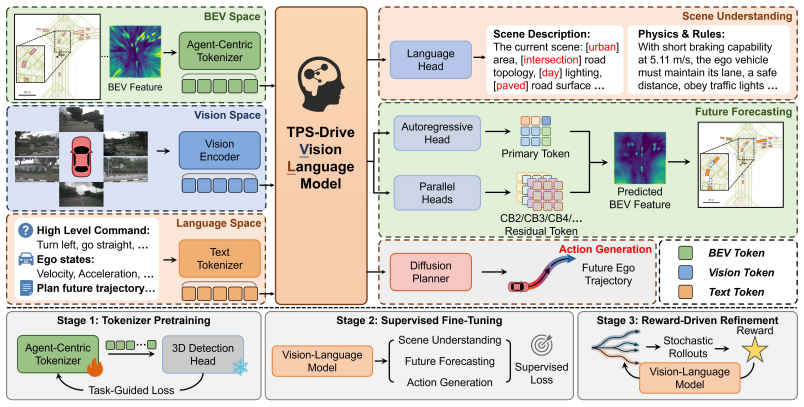
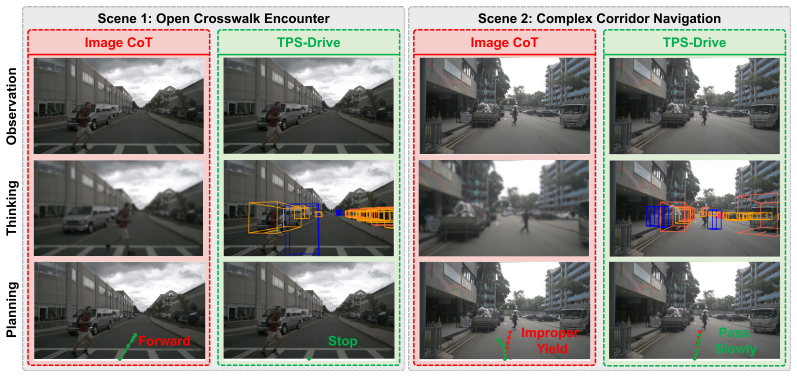
TPS-Drive shows that an Agent-Centric Tokenizer, built on task-guided vector quantization supervised by a frozen 3D detection head, reallocates codebook capacity from pervasive static backgrounds to critical dynamic agents, isolating spatial redundancy and supplying a purified spatial vocabulary that supports a decoupled reasoning pipeline of scene understanding, future forecasting, and action generation, with optimization via three-stage training that ends in reward-driven refinement.
What carries the argument
Agent-Centric Tokenizer: a task-guided vector quantization mechanism supervised by a frozen 3D detection head that reallocates limited codebook capacity to dynamic agents.
If this is right
- Accurate agent spatial state forecasting is achieved in open-loop nuScenes evaluations.
- Collision rates are reduced in those open-loop evaluations.
- New safety records are established on the closed-loop NAVSIMv1 and NAVSIMv2 benchmarks.
- The three-stage training with reward-driven refinement surpasses pure imitation learning.
Where Pith is reading between the lines
- The same purification step could be tested on other VLM tasks that require isolating sparse but critical spatial signals amid heavy background texture.
- If the frozen detector works as supervisor, replacing it with a weaker or noisier head would directly test whether the capacity reallocation depends on high-quality 3D labels.
- The decoupled pipeline separates understanding from forecasting; removing the decoupling and forcing joint prediction would show whether the separation itself contributes to the observed gains.
Load-bearing premise
The frozen 3D detection head can reliably supervise vector quantization to reallocate codebook capacity to dynamic agents without losing critical spatial details or introducing supervision biases that affect downstream planning.
What would settle it
An experiment that applies the same VLM backbone and training stages but replaces the agent-centric tokenizer with standard dense visual tokenization and shows no improvement or a decline in closed-loop safety metrics on NAVSIMv2 would falsify the central claim.
Figures

read the original abstract
Vision-Language Models (VLMs) provide a promising foundation for autonomous driving planning, yet bridging semantic reasoning and precise 3D spatial forecasting remains a critical challenge. Existing representation strategies generally follow two paths: text-aligned methods flatten continuous spatial states into symbols, which compromises geometric structure and induces "spatial hallucinations"; dense visual methods preserve spatial topology but overwhelm standard tokenizers with redundant background textures, leading to "representation interference". To address these limitations, we introduce TPS-Drive, a novel framework centered on Task-Guided Representation Purification that empowers VLMs to Think in Purified Space. At its core, an Agent-Centric Tokenizer utilizes a task-guided vector quantization mechanism supervised by a frozen 3D detection head, which explicitly reallocates limited codebook capacity from pervasive static backgrounds to critical dynamic agents and effectively isolates spatial redundancy. Leveraging this purified spatial vocabulary, TPS-Drive employs a decoupled reasoning pipeline that sequentially performs scene understanding, future forecasting, and action generation. The framework is optimized via a progressive three-stage training paradigm, culminating in reward-driven refinement that surpasses pure imitation learning. Extensive experiments validate our approach: TPS-Drive achieves accurate agent spatial state forecasting and reduces collision rates in open-loop nuScenes evaluations, while establishing new safety records on the rigorous closed-loop NAVSIMv1 and NAVSIMv2 benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TPS-Drive, a VLM-based autonomous driving framework centered on Task-Guided Representation Purification. Its core is an Agent-Centric Tokenizer that applies task-guided vector quantization supervised by a frozen 3D detection head to reallocate codebook capacity toward dynamic agents, creating a 'purified spatial vocabulary.' This feeds a decoupled reasoning pipeline (scene understanding, future forecasting, action generation) trained via a three-stage progressive paradigm ending in reward-driven refinement. The abstract claims this yields accurate agent spatial state forecasting, reduced collision rates in open-loop nuScenes evaluations, and new safety records on closed-loop NAVSIMv1/v2 benchmarks.
Significance. If the central claims hold, the approach could meaningfully advance VLM integration into autonomous driving by mitigating spatial hallucinations and representation interference through explicit purification of the spatial token space. The three-stage training with reward refinement is a constructive element that moves beyond pure imitation learning.
major comments (2)
- [Abstract] Abstract: The performance claims (accurate forecasting and new safety records on nuScenes/NAVSIM) rest on the assumption that supervision from the frozen 3D detection head produces an unbiased, planning-aligned signal for VQ codebook reallocation. No analysis is provided showing that detector errors (missed agents, inaccurate boxes) do not propagate into the discrete tokens or that the detection objective aligns with downstream planning topology preservation; this is load-bearing for the 'purified spatial vocabulary' claim.
- [Abstract] Abstract: The abstract states that the tokenizer 'explicitly reallocates limited codebook capacity from pervasive static backgrounds to critical dynamic agents' but supplies no quantitative evidence (e.g., codebook utilization statistics, ablation on supervision source, or topology preservation metrics) that the mechanism avoids distribution shift between detection and planning objectives.
minor comments (1)
- The abstract refers to 'extensive experiments' and 'new safety records' without reporting any numerical results, error bars, baseline comparisons, or ablation studies, which hinders assessment of effect sizes.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review of our manuscript on TPS-Drive. The comments correctly identify areas where the abstract claims would benefit from stronger supporting analysis. We address each major comment below and commit to revisions that directly incorporate the requested evidence and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims (accurate forecasting and new safety records on nuScenes/NAVSIM) rest on the assumption that supervision from the frozen 3D detection head produces an unbiased, planning-aligned signal for VQ codebook reallocation. No analysis is provided showing that detector errors (missed agents, inaccurate boxes) do not propagate into the discrete tokens or that the detection objective aligns with downstream planning topology preservation; this is load-bearing for the 'purified spatial vocabulary' claim.
Authors: We agree that the abstract does not contain explicit analysis of detector error propagation or alignment between the detection objective and planning topology. The manuscript reports overall performance gains from the task-guided tokenizer but does not isolate the effect of detection inaccuracies on token assignments. In the revised version we will add a new analysis subsection that quantifies token sensitivity to common detector failure modes and introduces topology preservation metrics (e.g., agent-centric IoU between original and tokenized representations) to substantiate the purification claim. revision: yes
-
Referee: [Abstract] Abstract: The abstract states that the tokenizer 'explicitly reallocates limited codebook capacity from pervasive static backgrounds to critical dynamic agents' but supplies no quantitative evidence (e.g., codebook utilization statistics, ablation on supervision source, or topology preservation metrics) that the mechanism avoids distribution shift between detection and planning objectives.
Authors: The experimental section already contains codebook utilization statistics and an ablation on the supervision source. However, these results are not referenced in the abstract, and explicit topology preservation metrics addressing potential distribution shift are absent. We will revise the abstract to cite the existing quantitative results and add topology preservation metrics in the revision to more rigorously demonstrate that the reallocation remains beneficial for downstream planning. revision: partial
Circularity Check
No circularity; abstract provides descriptive framework without equations or self-referential reductions
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters presented as predictions, or self-citations. The framework is introduced at a high level with claims of empirical validation on nuScenes and NAVSIM benchmarks. No load-bearing step reduces by construction to its own inputs, and the derivation chain is not observable in the given text, making the result self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Purified spatial vocabulary
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on vision-language-action models for autonomous driving
Sicong Jiang, Zilin Huang, Kangan Qian, Ziang Luo, Tianze Zhu, Yang Zhong, Yihong Tang, Menglin Kong, Yunlong Wang, Siwen Jiao, et al. A survey on vision-language-action models for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4524–4536, 2025
2025
-
[2]
Vision language models in autonomous driving: A survey and outlook.IEEE Transactions on Intelligent Vehicles, 2024
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Zagar, Walter Zimmer, Hu Cao, and Alois C Knoll. Vision language models in autonomous driving: A survey and outlook.IEEE Transactions on Intelligent Vehicles, 2024
2024
-
[3]
Large (vision) language models for autonomous vehicles: Current trends and future directions.IEEE Transactions on Intelligent Transportation Systems, 27(1):187–210, 2025
Hanlin Tian, Kethan Reddy, Yuxiang Feng, Mohammed Quddus, Yiannis Demiris, and Pana- giotis Angeloudis. Large (vision) language models for autonomous vehicles: Current trends and future directions.IEEE Transactions on Intelligent Transportation Systems, 27(1):187–210, 2025
2025
-
[4]
Jie Wang, Guang Li, Zhijian Huang, Chenxu Dang, Hangjun Ye, Yahong Han, and Long Chen. Vggdrive: Empowering vision-language models with cross-view geometric grounding for autonomous driving.arXiv preprint arXiv:2602.20794, 2026
-
[5]
Vlm4d: Towards spatiotem- poral awareness in vision language models
Shijie Zhou, Alexander Vilesov, Xuehai He, Ziyu Wan, Shuwang Zhang, Aditya Nagachandra, Di Chang, Dongdong Chen, Xin Eric Wang, and Achuta Kadambi. Vlm4d: Towards spatiotem- poral awareness in vision language models. InProceedings of the IEEE/CVF international conference on computer vision, pages 8600–8612, 2025
2025
-
[6]
Xianda Guo, Ruijun Zhang, Yiqun Duan, Yuhang He, Dujun Nie, Wenke Huang, Chenming Zhang, Shuai Liu, Hao Zhao, and Long Chen. Surds: Benchmarking spatial understanding and reasoning in driving scenarios with vision language models.arXiv preprint arXiv:2411.13112, 2024
-
[7]
Language prompt for autonomous driving
Dongming Wu, Wencheng Han, Yingfei Liu, Tiancai Wang, Cheng-zhong Xu, Xiangyu Zhang, and Jianbing Shen. Language prompt for autonomous driving. InProceedings of the AAAI conference on artificial intelligence, volume 39, pages 8359–8367, 2025
2025
-
[8]
Linfeng He, Yiming Sun, Sihao Wu, Jiaxu Liu, and Xiaowei Huang. Integrating object detection modality into visual language model for enhanced autonomous driving agent.arXiv preprint arXiv:2411.05898, 2024
-
[9]
SpaceDrive: Infusing Spatial Awareness into VLM-based Autonomous Driving
Peizheng Li, Zhenghao Zhang, David Holtz, Hang Yu, Yutong Yang, Yuzhi Lai, Rui Song, Andreas Geiger, and Andreas Zell. Spacedrive: Infusing spatial awareness into vlm-based autonomous driving.arXiv preprint arXiv:2512.10719, 2, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Yuechen Luo, Fang Li, Shaoqing Xu, Yang Ji, Zehan Zhang, Bing Wang, Yuannan Shen, Jianwei Cui, Long Chen, Guang Chen, et al. Last-vla: Thinking in latent spatio-temporal space for vision-language-action in autonomous driving.arXiv preprint arXiv:2603.01928, 2026
-
[11]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, Xing Wei, and Ning Guo. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving.arXiv preprint arXiv:2505.17685, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Occworld: Learning a 3d occupancy world model for autonomous driving
Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Borui Zhang, Yueqi Duan, and Jiwen Lu. Occworld: Learning a 3d occupancy world model for autonomous driving. InEuropean conference on computer vision, pages 55–72. Springer, 2024
2024
-
[13]
Fastdrivevla: Efficient end-to-end driving via plug-and-play reconstruction-based token pruning
Jiajun Cao, Qizhe Zhang, Peidong Jia, Xuhui Zhao, Bo Lan, Xiaoan Zhang, Xiaobao Wei, Sixiang Chen, Liyun Li, Xianming Liu, et al. Fastdrivevla: Efficient end-to-end driving via plug-and-play reconstruction-based token pruning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 2571–2579, 2026
2026
-
[14]
Self-supervised multi- modal learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(7):5299–5318, 2024
Yongshuo Zong, Oisin Mac Aodha, and Timothy M Hospedales. Self-supervised multi- modal learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(7):5299–5318, 2024. 10
2024
-
[15]
Scaling laws for native multimodal models
Mustafa Shukor, Enrico Fini, Victor Guilherme Turrisi da Costa, Matthieu Cord, Joshua Susskind, and Alaaeldin El-Nouby. Scaling laws for native multimodal models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–23, 2025
2025
-
[16]
Zhenjie Yang, Xiaosong Jia, Hongyang Li, and Junchi Yan. Llm4drive: A survey of large language models for autonomous driving.arXiv preprint arXiv:2311.01043, 2023
-
[17]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024
2024
-
[18]
arXiv preprint arXiv:2506.06218 (2025) 3, 9
Christian Fruhwirth-Reisinger, Dušan Mali´c, Wei Lin, David Schinagl, Samuel Schulter, and Horst Possegger. Stsbench: A spatio-temporal scenario benchmark for multi-modal large language models in autonomous driving.arXiv preprint arXiv:2506.06218, 2025
-
[19]
How Well Do Vision-Language Models Understand Sequential Driving Scenes? A Sensitivity Study
Roberto Brusnicki, Mattia Piccinini, and Johannes Betz. How well do vision-language models understand sequential driving scenes? a sensitivity study.arXiv preprint arXiv:2604.06750, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Are vision llms road-ready? a comprehensive benchmark for safety-critical driving video understanding
Tong Zeng, Longfeng Wu, Liang Shi, Dawei Zhou, and Feng Guo. Are vision llms road-ready? a comprehensive benchmark for safety-critical driving video understanding. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5972–5983, 2025
2025
-
[21]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters, 9(10):8186–8193, 2024
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model.IEEE Robotics and Automation Letters, 9(10):8186–8193, 2024
2024
-
[22]
Lmdrive: Closed-loop end-to-end driving with large language models
Hao Shao, Yuxuan Hu, Letian Wang, Guanglu Song, Steven L Waslander, Yu Liu, and Hong- sheng Li. Lmdrive: Closed-loop end-to-end driving with large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15120–15130, 2024
2024
-
[23]
Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driving.Advances in Neural Information Processing Systems, 37:819–844, 2024
2024
-
[24]
Bench2drive-vl: Benchmarks for closed-loop autonomous driving with vision-language models
Xiaosong Jia, Yuqian Shao, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive-vl: Benchmarks for closed-loop autonomous driving with vision-language models. arXiv preprint arXiv:2604.01259, 2026
-
[25]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InConference on robot learning, pages 1–16. PMLR, 2017
2017
-
[26]
Drivemlm: aligning multi-modal large language models with behavioral planning states for autonomous driving.Visual Intelligence, 3(1):22, 2025
Erfei Cui, Wenhai Wang, Zhiqi Li, Jiangwei Xie, Haoming Zou, Hanming Deng, Gen Luo, Lewei Lu, Xizhou Zhu, and Jifeng Dai. Drivemlm: aligning multi-modal large language models with behavioral planning states for autonomous driving.Visual Intelligence, 3(1):22, 2025
2025
-
[27]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InProceedings of the computer vision and pattern recognition conference, pages 22442–22452, 2025
2025
-
[28]
Bevdriver: Leveraging bev maps in llms for robust closed-loop driving
Katharina Winter, Mark Azer, and Fabian B Flohr. Bevdriver: Leveraging bev maps in llms for robust closed-loop driving. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 20379–20385. IEEE, 2025
2025
-
[29]
Ruixun Liu, Lingyu Kong, Derun Li, and Hang Zhao. Occvla: Vision-language-action model with implicit 3d occupancy supervision.arXiv preprint arXiv:2509.05578, 2025
-
[30]
Yuchen Li, Amanmeet Garg, Shalini Chaudhuri, Rui Zhao, and Garin Kessler. Perceptio: Perception enhanced vision language models via spatial token generation.arXiv preprint arXiv:2603.18795, 2026. 11
-
[31]
3D-VCD: Hallucination Mitigation in 3D-LLM Embodied Agents through Visual Contrastive Decoding
Makanjuola Ogunleye, Eman Abdelrahman, and Ismini Lourentzou. 3d-vcd: Hallucination mitigation in 3d-llm embodied agents through visual contrastive decoding.arXiv preprint arXiv:2604.08645, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Jiaqi Fan, Jianhua Wu, Hongqing Chu, Quanbo Ge, and Bingzhao Gao. Hallucination elimi- nation and semantic enhancement framework for vision-language models in traffic scenarios. arXiv preprint arXiv:2412.07518, 2024
-
[33]
Task interference in vlms for autonomous driving: When better perception hurts planning
Sai Bhargav Rongali, Aadya Pipersenia, and Kenji Okuma. Task interference in vlms for autonomous driving: When better perception hurts planning. InAAAI 2026 Workshop on Assessing and Improving Reliability of Foundation Models in the Real World
2026
-
[34]
DynFlowDrive: Flow-Based Dynamic World Modeling for Autonomous Driving
Xiaolu Liu, Yicong Li, Song Wang, Junbo Chen, Angela Yao, and Jianke Zhu. Dynflowdrive: Flow-based dynamic world modeling for autonomous driving.arXiv preprint arXiv:2603.19675, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Sifan Tu, Xin Zhou, Dingkang Liang, Xingyu Jiang, Yumeng Zhang, Xiaofan Li, and Xiang Bai. The role of world models in shaping autonomous driving: A comprehensive survey.arXiv preprint arXiv:2502.10498, 2025
-
[36]
World4drive: End-to-end autonomous driving via intention-aware physical latent world model
Yupeng Zheng, Pengxuan Yang, Zebin Xing, Qichao Zhang, Yuhang Zheng, Yinfeng Gao, Pengfei Li, Teng Zhang, Zhongpu Xia, Peng Jia, et al. World4drive: End-to-end autonomous driving via intention-aware physical latent world model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 28632–28642, 2025
2025
-
[37]
A survey of world models for autonomous driving
Tuo Feng, Wenguan Wang, and Yi Yang. A survey of world models for autonomous driving. arXiv preprint arXiv:2501.11260, 2025
-
[38]
Dio: Decomposable implicit 4d occupancy-flow world model
Christopher Diehl, Quinlan Sykora, Ben Agro, Thomas Gilles, Sergio Casas, and Raquel Urtasun. Dio: Decomposable implicit 4d occupancy-flow world model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27456–27466, 2025
2025
-
[39]
ProDrive: Proactive Planning for Autonomous Driving via Ego-Environment Co-Evolution
Chuyao Fu, Shengzhe Gan, Zhuoli Ouyang, Yuhan Rui, Xiaowei Chi, Sirui Han, Jiankun Wang, and Hong Zhang. Prodrive: Proactive planning for autonomous driving via ego-environment co-evolution.arXiv preprint arXiv:2604.25329, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Visual point cloud forecasting enables scalable autonomous driving
Zetong Yang, Li Chen, Yanan Sun, and Hongyang Li. Visual point cloud forecasting enables scalable autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14673–14684, 2024
2024
-
[41]
Uno: Unsu- pervised occupancy fields for perception and forecasting
Ben Agro, Quinlan Sykora, Sergio Casas, Thomas Gilles, and Raquel Urtasun. Uno: Unsu- pervised occupancy fields for perception and forecasting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14487–14496, 2024
2024
-
[42]
Songen Gu, Wei Yin, Bu Jin, Xiaoyang Guo, Junming Wang, Haodong Li, Qian Zhang, and Xiaoxiao Long. Dome: Taming diffusion model into high-fidelity controllable occupancy world model.arXiv preprint arXiv:2410.10429, 2024
-
[43]
Driveworld: 4d pre-trained scene understanding via world models for autonomous driving
Chen Min, Dawei Zhao, Liang Xiao, Jian Zhao, Xinli Xu, Zheng Zhu, Lei Jin, Jianshu Li, Yulan Guo, Junliang Xing, et al. Driveworld: 4d pre-trained scene understanding via world models for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15522–15533, 2024
2024
-
[44]
Smart: Scalable multi-agent real-time motion generation via next-token prediction.Advances in Neural Information Processing Systems, 37:114048–114071, 2024
Wei Wu, Xiaoxin Feng, Ziyan Gao, and Yuheng Kan. Smart: Scalable multi-agent real-time motion generation via next-token prediction.Advances in Neural Information Processing Systems, 37:114048–114071, 2024
2024
-
[45]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[46]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Model-based imitation learning for urban driving.Advances in Neural Information Processing Systems, 35:20703–20716, 2022
Anthony Hu, Gianluca Corrado, Nicolas Griffiths, Zachary Murez, Corina Gurau, Hudson Yeo, Alex Kendall, Roberto Cipolla, and Jamie Shotton. Model-based imitation learning for urban driving.Advances in Neural Information Processing Systems, 35:20703–20716, 2022
2022
-
[48]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[49]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021
2021
-
[51]
Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, and Xiaojuan Qi. Unitok: A unified tokenizer for visual generation and understanding.arXiv preprint arXiv:2502.20321, 2025
-
[52]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
2024
-
[53]
Jiacheng Hua, Yishu Yin, Yuhang Wu, Tai Wang, Yifei Huang, and Miao Liu. Unleashing spatial reasoning in multimodal large language models via textual representation guided reasoning. arXiv preprint arXiv:2603.23404, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Boosting MLLM Spatial Reasoning with Geometrically Referenced 3D Scene Representations
Jiangye Yuan, Gowri Kumar, and Baoyuan Wang. Boosting mllm spatial reasoning with geometrically referenced 3d scene representations.arXiv preprint arXiv:2603.08592, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Gaussianvlm: Scene-centric 3d vision-language models using language-aligned gaussian splats for embodied reasoning and beyond.IEEE Robotics and Automation Letters, 2025
Anna-Maria Halacheva, Jan-Nico Zaech, Xi Wang, Danda Pani Paudel, and Luc Van Gool. Gaussianvlm: Scene-centric 3d vision-language models using language-aligned gaussian splats for embodied reasoning and beyond.IEEE Robotics and Automation Letters, 2025
2025
-
[56]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. Advances in Neural Information Processing Systems, 37:135062–135093, 2024
2024
-
[57]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[58]
Julong Wei, Shanshuai Yuan, Pengfei Li, Qingda Hu, Zhongxue Gan, and Wenchao Ding. Occllama: An occupancy-language-action generative world model for autonomous driving. arXiv preprint arXiv:2409.03272, 2024
-
[59]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020– 2036, 2024
2020
-
[60]
Center-based 3d object detection and track- ing
Tianwei Yin, Xingyi Zhou, and Philipp Krahenbuhl. Center-based 3d object detection and track- ing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11784–11793, 2021
2021
-
[61]
V oxelnet: End-to-end learning for point cloud based 3d object detection
Yin Zhou and Oncel Tuzel. V oxelnet: End-to-end learning for point cloud based 3d object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4490–4499, 2018
2018
-
[62]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[63]
Traffic scene perception via multimodal large language model with data augmentation and efficient training strategy.Applied Soft Computing, 177:113210, 2025
Shuo Liu, Lei Shi, Yucheng Shi, Yufei Gao, and Xiaole Sun. Traffic scene perception via multimodal large language model with data augmentation and efficient training strategy.Applied Soft Computing, 177:113210, 2025. 13
2025
-
[64]
Implementation of image generative models using imagegpt
Payel Dutta and Kaustuv Kunal. Implementation of image generative models using imagegpt. In 2023 International Conference on New Frontiers in Communication, Automation, Management and Security (ICCAMS), volume 1, pages 1–6. IEEE, 2023
2023
-
[65]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[66]
Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36:67195–67212, 2023
Bingyi Kang, Xiao Ma, Chao Du, Tianyu Pang, and Shuicheng Yan. Efficient diffusion policies for offline reinforcement learning.Advances in Neural Information Processing Systems, 36:67195–67212, 2023
2023
-
[67]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[68]
St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning
Shengchao Hu, Li Chen, Penghao Wu, Hongyang Li, Junchi Yan, and Dacheng Tao. St-p3: End-to-end vision-based autonomous driving via spatial-temporal feature learning. InEuropean Conference on Computer Vision, pages 533–549. Springer, 2022
2022
-
[69]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[70]
Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
2024
-
[71]
Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving
Ziying Song, Caiyan Jia, Lin Liu, Hongyu Pan, Yongchang Zhang, Junming Wang, Xingyu Zhang, Shaoqing Xu, Lei Yang, and Yadan Luo. Don’t shake the wheel: Momentum-aware planning in end-to-end autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22432–22441, 2025
2025
-
[72]
He-drive: Human-like end-to-end driving with vision language models
Junming Wang, Xingyu Zhang, Zebin Xing, Xiaoyang Guo, Yang Hu, Ziying Song, Qian Zhang, Xiaoxiao Long, Wei Yin, et al. He-drive: Human-like end-to-end driving with vision language models. 2024
2024
-
[73]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[74]
Prix: learning to plan from raw pixels for end-to-end autonomous driving.IEEE Robotics and Automation Letters, 11(5):6400– 6407, 2026
Maciej Wozniak, Lianhang Liu, Yixi Cai, and Patric Jensfelt. Prix: learning to plan from raw pixels for end-to-end autonomous driving.IEEE Robotics and Automation Letters, 11(5):6400– 6407, 2026
2026
-
[75]
Making large language models better planners with reasoning-decision alignment
Zhijian Huang, Tao Tang, Shaoxiang Chen, Sihao Lin, Zequn Jie, Lin Ma, Guangrun Wang, and Xiaodan Liang. Making large language models better planners with reasoning-decision alignment. InEuropean Conference on Computer Vision, pages 73–90. Springer, 2024
2024
-
[76]
Doe-1: Closed-loop autonomous driving with large world model.arXiv preprint arXiv:2412.09627, 2024
Wenzhao Zheng, Zetian Xia, Yuanhui Huang, Sicheng Zuo, Jie Zhou, and Jiwen Lu. Doe-1: Closed-loop autonomous driving with large world model.arXiv preprint arXiv:2412.09627, 2024
-
[77]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[78]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers
Yuntao Chen, Yuqi Wang, and Zhaoxiang Zhang. Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26890–26900, 2025
2025
-
[80]
End-to-end driving with online trajectory evaluation via bev world model
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27137–27146, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.