When Eyes Betray AI: Social Gaze Consistency as a Semantic Cue for AI-Generated Image Detection
Pith reviewed 2026-06-29 17:57 UTC · model grok-4.3
The pith
Social gaze consistency between interacting people serves as a cue to detect AI-generated images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
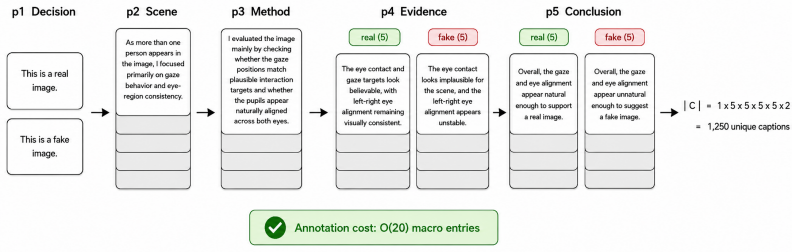
Social Gaze Consistency constitutes a previously underutilized detection axis orthogonal to existing low-level paradigms. A controlled diagnostic dataset with region-specific perturbations and pair-level grouping, combined with Block-Compositional Caption Supervision holding a fixed 5-block reasoning skeleton across 1,250 captions, enables training that improves a vision-language backbone by 3.7 points on the COCOAI Interaction subset and 1.3 points on the Person subset, with parallel gains on a vision-only backbone. The same supervision produces simultaneous rises in real-class and fake-class recall and generalizes from one inpainter to multi-generator suites via paired-edit shortcut blocki
What carries the argument
Social Gaze Consistency, defined as the mutual coherence of gaze direction, head-eye alignment, and pupil placement between interacting individuals.
If this is right
- Detection accuracy rises simultaneously on real and fake classes rather than through a one-sided bias.
- The same supervision improves both vision-language and vision-only backbones, showing backbone-agnostic utility.
- Training on outputs from a single inpainter transfers to multi-generator test suites.
- Hard-to-easy difficulty transfer occurs when the fixed reasoning skeleton is applied across surface-diverse captions.
Where Pith is reading between the lines
- Other high-level consistencies such as pose or expression coherence could be tested as additional orthogonal cues.
- The approach could extend to video sequences where gaze dynamics provide temporal signals.
- Combining the semantic cue with existing low-level detectors might yield hybrid systems robust to both artifact types.
Load-bearing premise
The controlled diagnostic dataset with region-specific perturbations and strict pair-level grouping prevents the model from learning generator-specific fingerprints rather than the intended gaze cue.
What would settle it
Train the supervised model on the gaze-perturbed dataset then test on new generators that render consistent periocular structure; if accuracy gains disappear while low-level cues remain blocked, the semantic-cue claim is falsified.
Figures

read the original abstract
Recent generative models have largely closed the gap on low-level artifacts - pixel fingerprints, frequency anomalies, upsampling traces - particularly in person-centric and partial-edit settings where the manipulated region is small and surrounded by photometrically authentic content. We introduce Social Gaze Consistency, a high-level semantic cue defined as the mutual coherence of gaze direction, head-eye alignment, and pupil placement between interacting individuals, and show that it constitutes a previously underutilized detection axis orthogonal to existing low-level paradigms. We instantiate this insight through three coupled mechanisms: (i) a controlled diagnostic dataset with region-specific perturbations of gaze-consistent imagery, where strict pair-level grouping forecloses generator-fingerprint memorization as an optimization-time shortcut rather than relying on augmentation; (ii) Block-Compositional Caption Supervision, which holds a single 5-block reasoning skeleton invariant across 1,250 macro-combined captions, decoupling reasoning consistency from surface diversity; (iii) Cross-architecture validation showing the same supervision improves a vision-language backbone (FakeVLM) by +3.7 pp on the COCOAI Interaction subset (balanced accuracy 67.8 -> 71.5) and +1.3 pp on the COCOAI Person subset (83.0 -> 84.3), with consistent gains on a vision-only backbone (Effort), evidencing a backbone-agnostic cue. Real- and fake-class recalls rise simultaneously, ruling out a "predict-all-fake" artifact. A four-step mechanistic account - paired-edit shortcut blocking, hard-to-easy difficulty transfer, CLIP prior preservation, and diffusion-family shared spectral weakness in periocular structure - explains why training on a single inpainter (FLUX.1-Fill) transfers to multi-generator suites. We will release the code upon acceptance to facilitate reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Social Gaze Consistency—defined as the mutual coherence of gaze direction, head-eye alignment, and pupil placement between interacting individuals—constitutes an orthogonal high-level semantic cue for detecting AI-generated images. It supports this via a controlled diagnostic dataset using region-specific perturbations of gaze-consistent imagery with strict pair-level grouping on a single inpainter (FLUX.1-Fill), Block-Compositional Caption Supervision holding a fixed 5-block reasoning skeleton, and cross-architecture experiments showing balanced-accuracy gains of +3.7 pp (67.8→71.5) on the COCOAI Interaction subset and +1.3 pp (83.0→84.3) on the Person subset for FakeVLM, with consistent gains on Effort; a four-step mechanistic account is offered to explain transfer to multi-generator suites.
Significance. If the central claim holds, the work supplies a backbone-agnostic semantic detection axis that remains useful in person-centric and partial-edit regimes where low-level fingerprints are diminished. The planned code release and simultaneous rise in real- and fake-class recalls are strengths that would aid reproducibility and rule out trivial artifacts.
major comments (3)
- [Abstract (controlled diagnostic dataset)] Abstract (controlled diagnostic dataset): the orthogonality claim rests on the assertion that strict pair-level grouping 'forecloses generator-fingerprint memorization'; however, the construction uses only FLUX.1-Fill and the mechanistic account itself notes 'diffusion-family shared spectral weakness in periocular structure,' leaving open the possibility that the detector exploits FLUX-specific pupil-placement or eye-alignment traces correlated with the perturbation rather than the intended semantic cue. An ablation or verification that isolates the gaze cue from these traces is required.
- [Abstract (results)] Abstract (results): the reported lifts (+3.7 pp and +1.3 pp) are given without error bars, statistical significance tests, or an ablation that holds caption structure fixed while varying only the gaze-consistency label; without these, it is unclear whether the gains are attributable to the proposed cue or to other factors in the supervision.
- [Abstract (four-step mechanistic account)] Abstract (four-step mechanistic account): the account (paired-edit shortcut blocking, hard-to-easy transfer, CLIP prior preservation, diffusion-family spectral weakness) is presented without quantitative tests or controls for each step, rendering it post-hoc and insufficient to substantiate why training on one inpainter transfers.
minor comments (1)
- The abstract states that code will be released upon acceptance; the release should also include the exact region-specific perturbation protocol and pair-grouping code to allow independent verification of the isolation claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, providing clarifications and indicating where we will revise the manuscript to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract (controlled diagnostic dataset)] Abstract (controlled diagnostic dataset): the orthogonality claim rests on the assertion that strict pair-level grouping 'forecloses generator-fingerprint memorization'; however, the construction uses only FLUX.1-Fill and the mechanistic account itself notes 'diffusion-family shared spectral weakness in periocular structure,' leaving open the possibility that the detector exploits FLUX-specific pupil-placement or eye-alignment traces correlated with the perturbation rather than the intended semantic cue. An ablation or verification that isolates the gaze cue from these traces is required.
Authors: We agree that the single-inpainter construction leaves room for potential generator-specific correlations, even with pair-level grouping. While the grouping ensures that gaze-consistent and gaze-inconsistent pairs share the same generator (preventing direct fingerprint memorization), we will add a targeted ablation in the revised manuscript. This will compare models trained on gaze-perturbed pairs against those trained on non-gaze perturbations (e.g., background or lighting changes) under identical conditions to isolate the contribution of the social gaze cue. revision: yes
-
Referee: [Abstract (results)] Abstract (results): the reported lifts (+3.7 pp and +1.3 pp) are given without error bars, statistical significance tests, or an ablation that holds caption structure fixed while varying only the gaze-consistency label; without these, it is unclear whether the gains are attributable to the proposed cue or to other factors in the supervision.
Authors: Error bars and significance tests appear in the full experimental results (Section 4), but we acknowledge their absence from the abstract. We will revise the abstract to report these details. We will also add an explicit ablation that holds the 5-block caption skeleton fixed while varying only the gaze-consistency label, directly addressing whether the gains derive from the proposed cue. revision: yes
-
Referee: [Abstract (four-step mechanistic account)] Abstract (four-step mechanistic account): the account (paired-edit shortcut blocking, hard-to-easy transfer, CLIP prior preservation, diffusion-family spectral weakness) is presented without quantitative tests or controls for each step, rendering it post-hoc and insufficient to substantiate why training on one inpainter transfers.
Authors: The four-step account is offered as an explanatory synthesis of the observed transfer across generators and architectures rather than a fully quantified causal model. We will expand the relevant section with additional quantitative controls, including metrics for difficulty transfer and CLIP prior preservation, to provide stronger substantiation for the transfer mechanism. revision: partial
Circularity Check
No significant circularity; cue and validation remain independent of inputs
full rationale
The paper defines Social Gaze Consistency explicitly as mutual coherence of gaze direction, head-eye alignment, and pupil placement between individuals. It constructs a diagnostic dataset via region-specific perturbations on gaze-consistent imagery plus strict pair-level grouping, then reports empirical gains on two backbones (FakeVLM +3.7 pp, Effort consistent) with simultaneous real/fake recall rise. No equations exist that equate the cue to any fitted parameter or training objective. No self-citations are invoked as load-bearing uniqueness theorems. The orthogonality claim rests on the dataset construction and cross-architecture transfer results rather than any definitional reduction or renaming of known patterns. This is the common case of an empirical contribution that does not collapse by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, Wesam Manassra, Prafulla Dhariwal, Casey Chu, Yunxin Jiao, and Aditya Ramesh. Improving image generation with better captions. Technical report, OpenAI, 2023
2023
-
[2]
Flux.1 fill [dev]
Black Forest Labs. Flux.1 fill [dev]. Technical report, Black Forest Labs, 2024
2024
-
[3]
K. H. Brodersen et al. The balanced accuracy and its posterior distribution. InInternational Conference on Pattern Recognition, 2010
2010
- [4]
-
[5]
Eunji Chong, Yongxin Wang, Nataniel Ruiz, and James M. Rehg. Detecting attended visual targets in video. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[6]
Dettmers et al
T. Dettmers et al. Qlora: Efficient finetuning of quantized llms. InAdvances in Neural Information Processing Systems, 2023
2023
-
[7]
B. Doosti et al. Boosting image-based mutual gaze detection using pseudo 3d gaze. InAAAI Conference on Artificial Intelligence, 2021. arXiv:2010.07811
-
[8]
Watch your up-convolution: CNN based generative deep neural networks are failing to reproduce spectral distributions
Ricard Durall, Margret Keuper, and Janis Keuper. Watch your up-convolution: CNN based generative deep neural networks are failing to reproduce spectral distributions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[9]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. InInternational Conference on Machine Learning, 2024
2024
-
[10]
Leveraging frequency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Schönherr, Asja Fischer, Dorothea Kolossa, and Thorsten Holz. Leveraging frequency analysis for deep fake image recognition. InInternational Conference on Machine Learning, 2020
2020
-
[11]
Gebru, J
T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. D. Iii, and K. Crawford. Datasheets for datasets.Communications of the ACM, 64(12):86–92, 2021
2021
-
[12]
H. Guo, S. Hu, X. Wang, M.-C. Chang, and S. Lyu. Eyes tell all: Irregular pupil shapes reveal GAN- generated faces. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022
2022
-
[13]
E. J. Hu et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Exposing GAN-generated faces using inconsistent corneal specular highlights
Shu Hu, Yuezun Li, and Siwei Lyu. Exposing GAN-generated faces using inconsistent corneal specular highlights. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2500–2504, 2021. 10
2021
-
[15]
Huang et al
Z. Huang et al. Sida: Social media image deepfake detection, localization and explanation with large mul- timodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,
-
[16]
Kellnhofer, A
P. Kellnhofer, A. Recasens, S. Stent, W. Matusik, and A. Torralba. Gaze360: Physically unconstrained gaze estimation in the wild. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2019
2019
-
[17]
Ouxiang Li, Jiayin Cai, Yanbin Hao, Xiaolong Jiang, Yao Hu, and Fuli Feng. Improving synthetic image detection towards generalization: An image transformation perspectives.arXiv preprint arXiv:2408.06741, 2024
-
[18]
Li, M.-C
Y . Li, M.-C. Chang, and S. Lyu. In ictu oculi: Exposing ai generated fake face videos by detecting eye blinking. InIEEE International Workshop on Information Forensics and Security (WIFS), 2018
2018
-
[19]
H. Liu et al. Visual instruction tuning. InAdvances in Neural Information Processing Systems, 2023. Oral, arXiv:2304.08485
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Improved Baselines with Visual Instruction Tuning
H. Liu et al. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024. arXiv:2310.03744
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019
2019
-
[22]
RePaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. RePaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[23]
M. J. Marín-Jiménez et al. Laeo-net: Revisiting people looking at each other in videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019
2019
-
[24]
GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models. InInternational Conference on Machine Learning, 2022
2022
-
[25]
Towards universal fake image detectors that generalize across generative models, 2024
U. Ojha et al. Towards universal fake image detectors that generalize across generative models. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023. arXiv:2302.10174
-
[26]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, 2021. arXiv:2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[27]
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
S. Rajbhandari et al. Zero: Memory optimizations toward training trillion parameter models. InIn- ternational Conference for High Performance Computing, Networking, Storage and Analysis, 2020. arXiv:1910.02054
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[28]
Where are they looking? In Advances in Neural Information Processing Systems, 2015
Adrià Recasens, Aditya Khosla, Carl V ondrick, and Antonio Torralba. Where are they looking? In Advances in Neural Information Processing Systems, 2015
2015
-
[29]
A Comprehensive Dataset for Human vs. AI Generated Image Detection
R. Roy et al. A comprehensive dataset for human vs. ai generated image detection.arXiv preprint arXiv:2601.00553, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [30]
-
[31]
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A. Efros. CNN-generated images are surprisingly easy to spot... for now. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[32]
Wen et al
J. Wen et al. Spot the fake: Large multimodal model-based synthetic image detection with artifact explanation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[33]
Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection
Z. Yan et al. Orthogonal subspace decomposition for generalizable ai-generated image detection. In International Conference on Machine Learning, 2025. Oral, arXiv:2411.15633
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [34]
-
[35]
DeepfakeBench: A comprehensive benchmark of deepfake detection
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. DeepfakeBench: A comprehensive benchmark of deepfake detection. InAdvances in Neural Information Processing Systems Datasets and Benchmarks Track, 2023
2023
- [36]
-
[37]
black-forest-labs/FLUX.1-Fill-dev
X. Zhang, S. Park, T. Beeler, D. Bradley, S. Tang, and O. Hilliges. ETH-XGaze: A large scale dataset for gaze estimation under extreme head pose and gaze variation. InProceedings of the European Conference on Computer Vision, 2020. 12 A Datasets: Custom Gaze and COCOAI This appendix provides datasheets for both datasets used in the paper: the proposedCust...
2020
-
[38]
a group of zebras
Pair-level grouping is essential for the shortcut-blocking mechanism: with identity-grouped splits, Table 9: Custom Gaze splits. Pair count equals real count equals fake count by construction (each pair contributes exactly one real and one fake image); Total=Real+Fake= 2×Pairs. Split Pairs Real Fake Total Train (80%)18,732 18,732 18,732 37,464 Val (10%)2,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.