Uni-LaViRA: Language-Vision-Robot Actions Translation for Unified Embodied Navigation
Pith reviewed 2026-06-29 16:57 UTC · model grok-4.3
The pith
Navigation reduces to translating language and vision into directional commands and visual targets inside pretrained MLLM output space, enabling zero-shot performance across tasks and robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The decision structure of navigation reduces to Language-Vision-Robot Actions Translation in which the language branch emits semantic-level directional commands and the vision branch emits pixel-level visual targets, both of which fall inside the natural output manifold of pretrained multimodal large language models. Uni-LaViRA implements this translation in a unified agentic architecture that extends to VLN-CE, ObjectNav, EQA, and Aerial-VLN while operating on wheeled, quadruped, humanoid, and UAV platforms. Two mechanisms, TODO List Memory that maintains and recites a checklist of sub-goals and Second Chance Backtrack that conditions new plans on failed sub-trajectories, turn single-pass e
What carries the argument
Language-Vision-Robot Actions Translation, which maps language instructions to semantic directional commands and visual observations to pixel-level targets inside the output space of pretrained MLLMs.
If this is right
- One architecture handles four navigation task families without task-specific training or data.
- The same translation applies directly to four heterogeneous robot morphologies in zero-shot deployment.
- TODO List Memory rewrites a structured checklist of pending sub-goals and feeds it back into the agent's attention window at every step.
- Second Chance Backtrack rolls the robot to the pre-error state and conditions the next plan on the failed sub-trajectory.
- Zero-training performance reaches or exceeds that of models trained on millions of robot samples and thousands of GPU-hours.
Where Pith is reading between the lines
- If the translation insight generalizes, similar structural reductions could apply to manipulation or other embodied tasks where outputs remain inside MLLM manifolds.
- The approach implies that large-scale collection of robot trajectories may be unnecessary for navigation once the output manifold assumption is satisfied.
- Iterative self-correction loops could substitute for reinforcement learning in settings where MLLMs already produce the required action tokens.
Load-bearing premise
Semantic directional commands and pixel-level visual targets both lie inside the natural output manifold of pretrained multimodal large language models.
What would settle it
Prompting the underlying MLLM with navigation instructions and observations and finding that it consistently fails to emit valid directional commands or usable target pixels would falsify the central premise.
Figures



read the original abstract
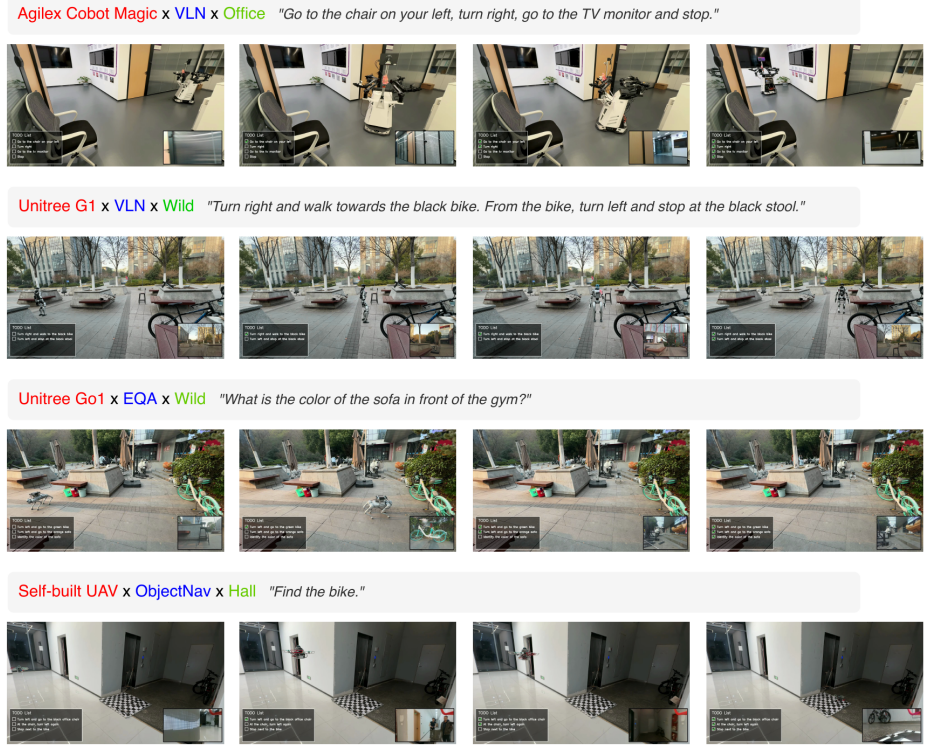
Embodied navigation requires an agent to map language and visual observations to a stream of spatial actions that drive a real robot through environments it has never seen. The dominant approach has been to scale vision-language-action (VLA) foundation models on ever-larger collections of robot trajectories. This paper argues that, for navigation specifically, generality can be obtained structurally, not only through data scale. The underlying decision structure of navigation reduces to a single Language-Vision-Robot Actions Translation. The language action emits semantic-level directional command and the vision action emits a pixel-level visual target. Both outputs lie inside the natural output manifold of pretrained multimodal large language models (MLLMs), so the task can be reasoned about by an agent rather than learned from robot data. Therefore, we present Uni-LaViRA, a unified agentic architecture that extends the same insight to four task families (VLN-CE, ObjectNav, EQA, and Aerial-VLN) and to four heterogeneous real robots (Wheeled, Quadruped, Humanoid robot, and a self-built UAV) in a zero-shot manner. Two agent-loop mechanisms make this unification practical. TODO List Memory (TDM) rewrites a structured checklist of pending sub-goals at every step, reciting the unfinished items back into the agent's most recent attention window. Second Chance Backtrack (SCB) rolls the robot back to the pre-error state and conditions the agent's next plan on the failed sub-trajectory, turning single-pass navigation into a self-correcting process. With zero training effort, Uni-LaViRA reaches 60.7% SR on VLN-CE R2R, 51.3% on VLN-CE RxR, 77.7% on HM3D-v2, 60.0% on HM3D-OVON, 54.7% on MP3D-EQA, and 40.0% on OpenUAV, matching or even surpassing recent training navigation foundation models that consume millions of samples and thousands of GPU-hours.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Uni-LaViRA, a unified agentic architecture for embodied navigation that reduces the task to Language-Vision-Robot Actions Translation. It claims that semantic directional commands and pixel-level visual targets both lie in the natural output manifold of pretrained MLLMs, enabling zero-shot operation across VLN-CE, ObjectNav, EQA, and Aerial-VLN tasks on four robot types without any robot data training. Two mechanisms (TODO List Memory and Second Chance Backtrack) are introduced to support this unification, with reported success rates of 60.7% on VLN-CE R2R, 51.3% on VLN-CE RxR, 77.7% on HM3D-v2, 60.0% on HM3D-OVON, 54.7% on MP3D-EQA, and 40.0% on OpenUAV.
Significance. If the results and underlying assumption hold after verification, the work would indicate that navigation generality can be obtained structurally via MLLM reasoning rather than data scaling, offering a lower-cost alternative to training large VLA models on millions of trajectories. No machine-checked proofs or reproducible code are provided to strengthen this assessment.
major comments (2)
- [Abstract] Abstract: The zero-shot performance claims rest on the untested assumption that both semantic directional commands and precise pixel-level visual targets lie inside the natural output manifold of pretrained MLLMs and map directly to robot actions in novel scenes; no evidence, ablation, or test of output reliability is supplied to support this structural claim.
- [Abstract] Abstract: Strong benchmark numbers are stated without any description of action execution pipelines, error handling on real hardware, statistical significance testing, or conversion from pixel targets to motor commands, preventing assessment of whether the reported success rates are supported by the data.
minor comments (2)
- The acronyms TDM and SCB are used in the abstract before any definition or description of their operation.
- The manuscript references four heterogeneous robots but provides no specifics on how the same pixel-level outputs are adapted across wheeled, quadruped, humanoid, and UAV platforms.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications drawn directly from the manuscript and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The zero-shot performance claims rest on the untested assumption that both semantic directional commands and precise pixel-level visual targets lie inside the natural output manifold of pretrained MLLMs and map directly to robot actions in novel scenes; no evidence, ablation, or test of output reliability is supplied to support this structural claim.
Authors: The manuscript treats the output-manifold hypothesis as the central structural claim and supplies empirical support through zero-shot success rates across four task families and four robot embodiments (Tables 1-3 and Figures 4-6). These results constitute a direct test of whether MLLM-generated directional commands and pixel targets can be executed in unseen scenes. We acknowledge that an explicit ablation isolating output reliability (e.g., consistency of MLLM generations on held-out prompts) is not present; the revision will add such an ablation together with representative MLLM output traces. revision: partial
-
Referee: [Abstract] Abstract: Strong benchmark numbers are stated without any description of action execution pipelines, error handling on real hardware, statistical significance testing, or conversion from pixel targets to motor commands, preventing assessment of whether the reported success rates are supported by the data.
Authors: The abstract is intentionally concise; the full manuscript details the action-execution pipeline in Section 3.2 (pixel-to-motor conversion via robot-specific inverse kinematics), the SCB error-handling loop in Section 3.3, and statistical reporting (means and standard deviations over five random seeds) in Section 4 and the supplementary material. We will revise the abstract to include a one-sentence pointer to these sections and will ensure all hardware-specific conversion steps are explicitly cross-referenced in the main text. revision: yes
Circularity Check
No circularity; claims rest on external benchmarks and stated architectural insight without self-referential reductions
full rationale
The paper argues that embodied navigation structurally reduces to Language-Vision-Robot Actions Translation whose outputs lie in pretrained MLLM manifolds, enabling zero-shot unification across tasks and robots. No equations, fitted parameters, or derivations appear in the provided text. Performance numbers (e.g., 60.7% SR on VLN-CE R2R) are presented as direct empirical results on external benchmarks rather than predictions derived from internal fits or self-citations. The central premise is an assumption about MLLM output space, not a self-definitional loop or renamed known result. The architecture (TDM, SCB) is described as practical mechanisms, not load-bearing theorems imported from the authors' prior work. This is a standard non-circular empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic directional commands and pixel-level visual targets lie inside the natural output manifold of pretrained MLLMs.
invented entities (2)
-
TODO List Memory (TDM)
no independent evidence
-
Second Chance Backtrack (SCB)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. van den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2018, pp. 3674–3683
2018
-
[2]
Beyond the nav-graph: Vision-and-language navigation in continuous environments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” inProc. European Conf. Computer Vision (ECCV), 2020, pp. 104–120
2020
-
[3]
Room-across- room: Multilingual vision-and-language navigation with dense spa- tiotemporal grounding,
A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge, “Room-across- room: Multilingual vision-and-language navigation with dense spa- tiotemporal grounding,” inProc. Conf. Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[4]
ObjectNav revisited: On evaluation of embodied agents navigating to objects,
D. Batra, A. Gokaslan, A. Kembhavi, O. Maksymets, R. Mottaghi, M. Savva, A. Toshev, and E. Wijmans, “ObjectNav revisited: On evaluation of embodied agents navigating to objects,” inarXiv preprint arXiv:2006.13171, 2020
-
[5]
Habitat-Matterport 3D dataset (HM3D): 1000 large-scale 3D environments for embodied AI,
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Undersander, W. Galuba, A. Westbury, A. X. Chang, M. Savva, Y . Zhao, and D. Batra, “Habitat-Matterport 3D dataset (HM3D): 1000 large-scale 3D environments for embodied AI,” inNeurIPS Datasets and Benchmarks, 2021
2021
-
[6]
HM3D- OVON: A dataset and benchmark for open-vocabulary object goal navigation,
N. Yokoyama, R. Ramrakhya, A. Das, D. Batra, and S. Ha, “HM3D- OVON: A dataset and benchmark for open-vocabulary object goal navigation,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2024
2024
-
[7]
Embodied question answering,
A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra, “Embodied question answering,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[8]
OpenEQA: Embodied question answering in the era of foundation mod- els,
A. Majumdar, A. Ajay, X. Zhang, P. Putta, S. Yenamandra, M. Henaff, S. Silwal, P. Mcvay, O. Maksymets, S. Arnaud, K. Yadav, Q. Li, B. Newman, M. Sharma, V . Berges, S. Li, P. Jain, Y . Bisk, D. Batra, M. Kalakrishnan, F. Meier, C. Paxton, S. Sax, and A. Rajeswaran, “OpenEQA: Embodied question answering in the era of foundation mod- els,” inProc. IEEE/CVF ...
2024
-
[9]
Towards realistic UA V vision-language nav- igation: Platform, benchmark, and methodology,
X. Wang, D. Yang, Z. Wang, H. Kwan, J. Chen, W. Wu, H. Li, Y . Liao, and S. Liu, “Towards realistic UA V vision-language nav- igation: Platform, benchmark, and methodology,” inarXiv preprint arXiv:2410.07087, 2024
-
[10]
NaVid: Video-based VLM plans the next step for vision- and-language navigation,
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang, “NaVid: Video-based VLM plans the next step for vision- and-language navigation,” inProc. Robotics: Science and Systems (RSS), 2024
2024
-
[11]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang, “Uni-NaVid: A video-based vision-language- action model for unifying embodied navigation tasks,” inarXiv preprint arXiv:2412.06224, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Navila: Legged robot vision-language-action model for naviga- tion.arXiv preprint arXiv:2412.04453,
A.-C. Cheng, Y . Ji, Z. Yang, X. Zou, J. Kautz, E. Bıyık, H. Yin, S. Liu, and X. Wang, “NaVILA: Legged robot vision-language-action model for navigation,” inarXiv preprint arXiv:2412.04453, 2024
-
[13]
S. Wei, Z. Wang, Y . Zhang, J. Zhang, and H. Wang, “StreamVLN: Streaming vision-and-language navigation via SlowFast context model- ing,” inarXiv preprint arXiv:2507.05240, 2025
-
[14]
NavFoM: Towards a navigation foundation model for unified embodied navigation,
J. Zhang, Y . Zhang, K. Wang, S. Wei, Z. Wang, and H. Wang, “NavFoM: Towards a navigation foundation model for unified embodied navigation,” inarXiv preprint arXiv:2509.12129, 2025
-
[15]
LaViRA: Language-vision-robot actions translation for zero- shot vision language navigation in continuous environments,
H. Ding, Z. Xu, Y . Fang, Y . Wu, Z. Chen, J. Shi, J. Huo, Y . Zhang, and Y . Gao, “LaViRA: Language-vision-robot actions translation for zero- shot vision language navigation in continuous environments,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), 2026
2026
-
[16]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky, “π 0: A vision-language-action flow model for general robot control,” inarXiv preprint arXiv:2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
OpenVLA: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “OpenVLA: An open-source vision-language-action model,” inCoRL, 2024
2024
-
[18]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inProc. Int. Conf. Learning Representations (ICLR), 2023
2023
-
[19]
Reflexion: Language agents with verbal reinforcement learn- ing,
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learn- ing,” inNeurIPS, 2023
2023
-
[20]
Inner monologue: Em- bodied reasoning through planning with language models,
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y . Chebotaret al., “Inner monologue: Em- bodied reasoning through planning with language models,” inCoRL, 2022
2022
-
[21]
SmartWay: Enhanced waypoint prediction and backtracking for zero- shot vision-and-language navigation,
X. Shi, Z. Zhao, K. Gao, L. Wang, L. Chen, Y . Wang, and M. Liu, “SmartWay: Enhanced waypoint prediction and backtracking for zero- shot vision-and-language navigation,” inProc. IEEE/RSJ Int. Conf. Intelligent Robots and Systems (IROS), 2025
2025
-
[22]
Matterport3d: Learning from RGB-D data in indoor environments,
A. Chang, A. Dai, T. Funkhouser, M. Halber, M. Nießner, M. Savva, S. Song, A. Zeng, and Y . Zhang, “Matterport3d: Learning from RGB-D data in indoor environments,” inInternational Conference on 3D Vision (3DV), 2017
2017
-
[23]
VLN- BERT: A recurrent vision-and-language BERT for navigation,
Y . Hong, Q. Wu, Y . Qi, C. Rodriguez-Opazo, and S. Gould, “VLN- BERT: A recurrent vision-and-language BERT for navigation,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[24]
Think global, act local: Dual-scale graph transformer for vision-and-language navigation,
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev, “Think global, act local: Dual-scale graph transformer for vision-and-language navigation,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[25]
GridMM: Grid memory map for vision-and-language navigation,
Z. Wang, X. Li, J. Yang, Y . Liu, and S. Jiang, “GridMM: Grid memory map for vision-and-language navigation,” inProc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2023
2023
-
[26]
BEVBert: Multimodal map pre-training for language-guided navigation,
D. An, Y . Qi, Y . Li, Y . Huang, L. Wang, T. Tan, and J. Shao, “BEVBert: Multimodal map pre-training for language-guided navigation,” inProc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2023
2023
-
[27]
ETPNav: Evolving topological planning for vision-language navigation in continuous environments,
D. An, H. Wang, W. Wang, Z. Wang, Y . Huang, K. He, and L. Wang, “ETPNav: Evolving topological planning for vision-language navigation in continuous environments,”IEEE Trans. Pattern Anal. Mach. Intell., 2024
2024
-
[28]
Scaling data generation in vision-and-language navigation,
Z. Wang, J. Li, Y . Hong, Y . Wang, Q. Wu, M. Bansal, S. Gould, H. Tan, and Y . Qiao, “Scaling data generation in vision-and-language navigation,” inProc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2023
2023
-
[29]
BabyWalk: Going farther in vision-and-language navigation by taking baby steps,
W. Zhu, H. Hu, J. Chen, Z. Deng, V . Jain, E. Ie, and F. Sha, “BabyWalk: Going farther in vision-and-language navigation by taking baby steps,” inProc. Annu. Meeting Assoc. Computational Linguistics (ACL), 2020
2020
-
[30]
OmniNav: A unified framework for prospective exploration and visual-language navigation,
X. Xue, J. Hu, M. Luo, S. Xie, J. Chen, Z. Xie, K. Quan, W. Guo, M. Xu, and Z. Chu, “OmniNav: A unified framework for prospective exploration and visual-language navigation,” inarXiv preprint arXiv:2509.25687, 2025
-
[31]
ABot-N0: Technical report on the VLA foundation model for versatile embodied navigation,
Z. Chu, S. Xie, X. Wu, Y . Shen, M. Luoet al., “ABot-N0: Technical report on the VLA foundation model for versatile embodied navigation,” inarXiv preprint arXiv:2602.11598, 2026
-
[32]
Open-Nav: Exploring zero-shot vision-and-language navigation in continuous envi- ronments with open-source LLMs,
Y . Qiao, W. Liu, J. Qin, T. Liu, B. Wang, and Q. Wu, “Open-Nav: Exploring zero-shot vision-and-language navigation in continuous envi- ronments with open-source LLMs,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), 2025
2025
-
[33]
Bridging the gap be- tween learning in discrete and continuous environments for vision-and- language navigation,
Y . Hong, Z. Wang, Q. Wu, and S. Gould, “Bridging the gap be- tween learning in discrete and continuous environments for vision-and- language navigation,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[34]
Constraint-aware zero-shot vision- language navigation in continuous environments,
K. Chen, J. Fu, C. Gao, and N. Sang, “Constraint-aware zero-shot vision- language navigation in continuous environments,” inProc. AAAI Conf. Artificial Intelligence, 2025
2025
-
[35]
InstructNav: Zero- shot system for generic instruction navigation in unexplored environ- ment,
Y . Long, W. Cai, H. Wang, G. Zhan, and H. Dong, “InstructNav: Zero- shot system for generic instruction navigation in unexplored environ- ment,” inCoRL, 2024
2024
-
[36]
VLFM: Vision- language frontier maps for zero-shot semantic navigation,
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher, “VLFM: Vision- language frontier maps for zero-shot semantic navigation,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), 2024
2024
-
[37]
GC-VLN: Instruction as graph constraints for training-free vision-and-language navigation,
Z. Yin, H. Wang, Z. Cheng, Q. Chen, Y . Wang, and H. Dong, “GC-VLN: Instruction as graph constraints for training-free vision-and-language navigation,” inarXiv preprint arXiv:2509.22638, 2025
-
[38]
ESC: Exploration with soft commonsense constraints for zero- shot object navigation,
K. Zhou, K. Zheng, C. Pryor, Y . Shen, H. Jin, L. Getoor, and X. E. Wang, “ESC: Exploration with soft commonsense constraints for zero- shot object navigation,” inProc. Int. Conf. Machine Learning (ICML), 2023
2023
-
[39]
OpenFMNav: Towards open-set zero- shot object navigation via vision-language foundation models,
Y . Kuang, H. Lin, and M. Jiang, “OpenFMNav: Towards open-set zero- shot object navigation via vision-language foundation models,” inarXiv preprint arXiv:2402.10670, 2024
-
[40]
NavGPT: Explicit reasoning in vision- and-language navigation with large language models,
G. Zhou, Y . Hong, and Q. Wu, “NavGPT: Explicit reasoning in vision- and-language navigation with large language models,” inProc. AAAI Conf. Artificial Intelligence, 2024
2024
-
[41]
MapGPT: Map-guided prompting with adaptive path planning for vision-and-language navigation,
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . K. Wong, “MapGPT: Map-guided prompting with adaptive path planning for vision-and-language navigation,” inProc. Annu. Meeting Assoc. Com- putational Linguistics (ACL), 2024
2024
-
[42]
Discuss before moving: Visual language navigation via multi-expert discussions,
Y . Long, X. Li, W. Cai, and H. Dong, “Discuss before moving: Visual language navigation via multi-expert discussions,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), 2024
2024
-
[43]
GOAT: GO to any thing,
M. Chang, T. Gervet, M. Khanna, S. Yenamandra, D. Shah, S. Y . Min, K. Shah, C. Paxton, S. Gupta, D. Batra, R. Mottaghi, J. Malik, and D. S. Chaplot, “GOAT: GO to any thing,” inProc. Robotics: Science and Systems (RSS), 2024
2024
-
[44]
GOAT-Bench: A benchmark for multi-modal lifelong navigation,
N. Khanna, R. Yokoyama, D. Batra, A. Rai, and S. Ha, “GOAT-Bench: A benchmark for multi-modal lifelong navigation,” inCVPR, 2024
2024
-
[45]
S. Zeng, D. Qi, X. Chang, F. Xiong, S. Xie, X. Wu, S. Liang, M. Xu, X. Wei, and N. Guo, “JanusVLN: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation,” inarXiv preprint arXiv:2509.22548, 2025
-
[46]
M. Wei, C. Wan, J. Peng, X. Yu, Y . Yang, D. Feng, W. Cai, C. Zhu, T. Wang, J. Pang, and X. Liu, “Ground slow, move fast: A dual-system foundation model for generalizable vision-and-language navigation,” in arXiv preprint arXiv:2512.08186, 2025
-
[47]
Do as i can, not as i say: Grounding language in robotic affordances,
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzoget al., “Do as i can, not as i say: Grounding language in robotic affordances,” inCoRL, 2022
2022
-
[48]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng, “Code as policies: Language model programs for embodied control,” inProc. IEEE Int. Conf. Robotics and Automation (ICRA), 2023
2023
-
[49]
V oyager: An open-ended embodied agent with large language models,
G. Wang, Y . Xie, Y . Jiang, A. Mandlekar, C. Xiao, Y . Zhu, L. Fan, and A. Anandkumar, “V oyager: An open-ended embodied agent with large language models,”Trans. Mach. Learn. Res., 2024
2024
-
[50]
Agent-S: An open agentic framework that uses computers like a human,
S. Agashe, J. Han, S. Gan, J. Yang, A. Li, and X. E. Wang, “Agent-S: An open agentic framework that uses computers like a human,” inProc. Int. Conf. Learning Representations (ICLR), 2025
2025
-
[51]
Dynamic programming,
R. Bellman, “Dynamic programming,”Science, vol. 153, no. 3731, pp. 34–37, 1966
1966
-
[52]
Between MDPs and semi- MDPs: A framework for temporal abstraction in reinforcement learning,
R. S. Sutton, D. Precup, and S. Singh, “Between MDPs and semi- MDPs: A framework for temporal abstraction in reinforcement learning,” Artificial Intelligence, vol. 112, no. 1–2, pp. 181–211, 1999
1999
-
[53]
Adaptive zone-aware hierarchical planner for vision-language navigation,
X. Liu, J. Lin, Y . Hu, Y . Zhu, and R. Xu, “Adaptive zone-aware hierarchical planner for vision-language navigation,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[54]
NavA3: Understanding any instruction, navigating anywhere, finding anything,
L. Zhang, Z. Zhang, W. Liu, H. Wang, Z. Lin, Y . Wang, and R. Xu, “NavA3: Understanding any instruction, navigating anywhere, finding anything,” inarXiv preprint arXiv:2508.04598, 2025
-
[55]
MemGPT: Towards LLMs as Operating Systems
C. Packer, S. Wooders, K. Lin, V . Fang, S. G. Patil, I. Stoica, and J. E. Gonzalez, “MemGPT: Towards LLMs as operating systems,”arXiv preprint arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Generative agents: Interactive simulacra of human behavior,
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” inProc. ACM Symposium on User Interface Software and Technology (UIST), 2023
2023
-
[57]
MemoryBank: Enhancing large language models with long-term memory,
W. Zhong, L. Guo, Q. Gao, H. Ye, and Y . Wang, “MemoryBank: Enhancing large language models with long-term memory,” inProc. AAAI Conf. Artificial Intelligence, 2024
2024
-
[58]
M. Zhang, Y . Du, C. Wu, J. Zhou, Z. Qi, J. Ma, and B. Zhou, “ApexNav: An adaptive exploration strategy for zero-shot object navigation with target-centric semantic fusion,” inarXiv preprint arXiv:2504.14478, 2025
-
[59]
Move to Understand a 3D Scene: Bridging visual ground- ing and exploration for efficient and versatile embodied navigation,
Z. Zhuet al., “Move to Understand a 3D Scene: Bridging visual ground- ing and exploration for efficient and versatile embodied navigation,” in Proc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2025
2025
-
[60]
AerialVLA: A vision- language-action model for UA V navigation via minimalist end-to-end control,
P. Xu, Z. Deng, J. Deng, Z. Gu, and S. Wan, “AerialVLA: A vision- language-action model for UA V navigation via minimalist end-to-end control,”arXiv preprint arXiv:2603.14363, 2026
-
[61]
Habitat-Matterport 3D semantics dataset,
K. Yadav, R. Ramrakhya, S. K. Ramakrishnan, T. Gervet, J. Turner, A. Gokaslan, N. Maestre, A. Chang, D. Batra, M. Savva, A. X. Chang, and D. S. Chaplot, “Habitat-Matterport 3D semantics dataset,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[62]
Habitat: A platform for embodied AI research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik, D. Parikh, and D. Batra, “Habitat: A platform for embodied AI research,” inProc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2019
2019
-
[63]
SPAN-Nav: Generalized spatial awareness for versatile vision-language navigation,
J. Liu, T. Xu, J. Chen, L. Yue, J. Zhang, Z. Wang, M. Li, Z. Zhang, and H. Wang, “SPAN-Nav: Generalized spatial awareness for versatile vision-language navigation,” inarXiv preprint arXiv:2603.09163, 2026
-
[64]
K. Lyu, K. Wu, P. Li, X. Hu, Q. Si, C. Miao, N. Yang, Z. Wang, L. Xiao, L. Hu, J. Sun, and C. Hao, “HiMemVLN: Enhancing reliability of open-source zero-shot vision-and-language navigation with hierarchical memory system,”arXiv preprint arXiv:2603.14807, 2026
-
[65]
Three-Step Nav: A Hierarchical Global-Local Planner for Zero-Shot Vision-and-Language Navigation
W. Zheng, Y . Ge, and L. Itti, “Three-step nav: A hierarchical global-local planner for zero-shot vision-and-language navigation,”arXiv preprint arXiv:2604.26946, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
LongFly: Long-horizon UA V vision-and-language navigation with spatiotemporal context integration,
W. Jiang, L. Wang, K. Huang, W. Fan, J. Liu, S. Liu, H. Duan, B. Xu, and X. Ji, “LongFly: Long-horizon UA V vision-and-language navigation with spatiotemporal context integration,”arXiv preprint arXiv:2512.22010, 2025
-
[67]
W. Jiang, K. Huang, L. Wang, W. Xu, W. Fan, J. Liu, S. Liu, H. Liang, H. Duan, and B. Xu, “SpatialFly: Geometry-guided representation align- ment for UA V vision-and-language navigation in urban environments,” arXiv preprint arXiv:2603.21046, 2026
-
[68]
DD-PPO: Learning near-perfect pointgoal navigators from 2.5 billion frames,
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra, “DD-PPO: Learning near-perfect pointgoal navigators from 2.5 billion frames,” inProc. Int. Conf. Learning Representations (ICLR), 2020
2020
-
[69]
Habitat-Web: Learning embodied object-search strategies from human demonstrations at scale,
R. Ramrakhya, E. Undersander, D. Batra, and A. Das, “Habitat-Web: Learning embodied object-search strategies from human demonstrations at scale,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[70]
PIRLNav: Pretrain- ing with imitation and RL finetuning for ObjectNav,
R. Ramrakhya, D. Batra, E. Wijmans, and A. Das, “PIRLNav: Pretrain- ing with imitation and RL finetuning for ObjectNav,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[71]
OVRL-V2: A simple state- of-art baseline for ImageNav and ObjectNav,
K. Yadav, A. Majumdar, R. Ramrakhya, N. Yokoyama, A. Baevski, Z. Kira, O. Maksymets, and D. Batra, “OVRL-V2: A simple state- of-art baseline for ImageNav and ObjectNav,” inarXiv preprint arXiv:2303.07798, 2023
-
[72]
Towards learning a generalist model for embodied navigation,
D. Zheng, S. Huang, L. Zhao, Y . Zhong, and L. Wang, “Towards learning a generalist model for embodied navigation,” inProc. IEEE/CVF Conf. Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[73]
FiLM-Nav: Efficient and Generalizable Navigation via VLM Fine-tuning
N. Yokoyama and S. Ha, “FiLM-Nav: Efficient and generalizable navigation via VLM fine-tuning,” inarXiv preprint arXiv:2509.16445, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
L3MVN: Leveraging large language models for visual target navigation,
B. Yu, H. Kasaei, and M. Cao, “L3MVN: Leveraging large language models for visual target navigation,” inIROS, 2023
2023
-
[75]
SG-Nav: Online 3D scene graph prompting for LLM-based zero-shot object navigation,
H. Yin, X. Xu, Z. Wu, J. Zhou, and J. Lu, “SG-Nav: Online 3D scene graph prompting for LLM-based zero-shot object navigation,” in NeurIPS, 2024
2024
-
[76]
DSCD-Nav: Dual-stance cooperative debate for object navigation,
W. Anet al., “DSCD-Nav: Dual-stance cooperative debate for object navigation,”arXiv preprint arXiv:2601.21409, 2026
-
[77]
ReMemNav: A Rethinking and Memory-Augmented Framework for Zero-Shot Object Navigation
F. Wuet al., “ReMemNav: A rethinking and memory-augmented frame- work for zero-shot object navigation,”arXiv preprint arXiv:2603.26788, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[78]
NavDP: Learning sim-to-real navigation diffusion policy with privileged information guidance,
W. Cai, J. Peng, Y . Yang, Y . Zhang, M. Wei, H. Wang, Y . Chen, T. Wang, and J. Pang, “NavDP: Learning sim-to-real navigation diffusion policy with privileged information guidance,”arXiv preprint arXiv:2505.08712, 2025
-
[79]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick, “Segment anything,” inProc. IEEE/CVF Int. Conf. Computer Vision (ICCV), 2023
2023
-
[80]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang, “Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,” inProc. European Conf. Computer Vision (ECCV), 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.