What-If World: A Causal Benchmark for General World Models in Embodied Scenarios
Pith reviewed 2026-06-29 18:19 UTC · model grok-4.3
The pith
Video generation models fail to adjust outputs correctly when prompts differ by one physical variable, with none exceeding 52% paired accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
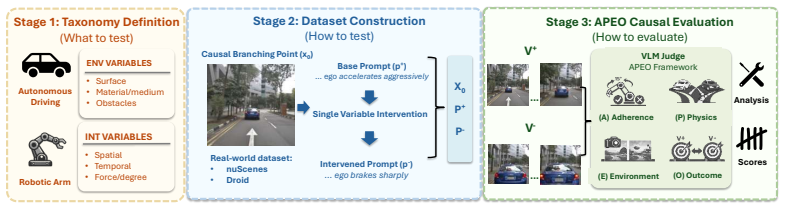
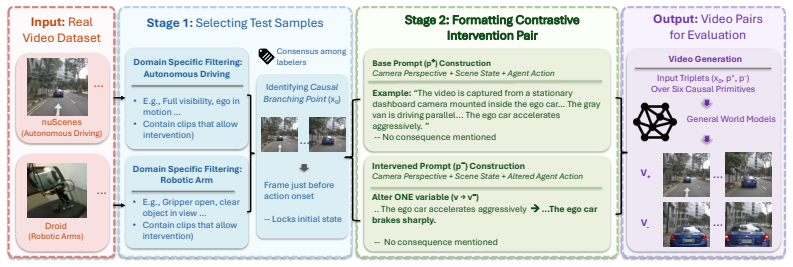
We introduce What-If World, 319 prompt pairs built on real frames, organized by a taxonomy of six physical variables shared across driving and manipulation. Each pair is scored with APEO, a four-part rubric checking whether each video follows its prompt (Adherence), is physically consistent (Physics), preserves the shared scene (Environment), and ends in the correct difference (Outcome). Across nine state-of-the-art models, no system exceeds 52% on the paired score, and open-source models cluster near 28%. Every model tested fails on a large fraction of causal interventions, indicating substantial room before these models can reliably support action-conditioned simulation or model-based plan
What carries the argument
The What-If World benchmark of 319 prompt pairs differing by one physical variable, evaluated via the APEO rubric that detects causal response failures missed by single-video scoring.
If this is right
- No tested model can yet reliably support action-conditioned simulation or model-based planning.
- Every model fails on a large fraction of causal interventions.
- Performance tracks visual prominence of the intervention rather than tractability of the physics.
- Visually subtle interventions score as low as 14.2% while pronounced ones reach 40.4%.
Where Pith is reading between the lines
- The benchmark could be extended to test whether models handle sequences of multiple interventions or longer time horizons.
- Training approaches that explicitly reward correct causal divergence might address the gap between visual plausibility and physical accuracy.
- Success on this paired evaluation would be a necessary condition for using such models in closed-loop control tasks.
Load-bearing premise
The assumption that the APEO rubric and the 319 prompt pairs provide an unbiased measure of causal understanding rather than being driven by visual salience or prompt artifacts.
What would settle it
A model that achieves paired scores above 70% across interventions of varying visual prominence while maintaining high individual video quality would challenge the reported performance limits and failure rates.
Figures






read the original abstract
Video generation models are increasingly used as world simulators for tasks like driving and robotic manipulation. What matters in these settings is not whether a single video looks right, but whether the model's output changes when its input changes. We test this by giving a model two prompts describing the same scene with one physical detail varied, and checking whether the two videos diverge the way physics predicts. The wording difference between the prompts is small by design, since only one variable is changed, but the correct physical difference is not. A model that misses this can still produce two videos that each look plausible individually, and existing benchmarks score videos one at a time and cannot detect this failure. We introduce What-If World, 319 such prompt pairs built on real frames from nuScenes and DROID, organized by a taxonomy of six physical variables shared across driving and manipulation. Each pair is scored with APEO, a four-part rubric checking whether each video follows its prompt (Adherence), is physically consistent (Physics), preserves the shared scene (Environment), and ends in the correct difference (Outcome). Across nine state-of-the-art models, no system exceeds 52% on the paired score, and open-source models cluster near 28%. Every model tested fails on a large fraction of causal interventions, indicating substantial room before these models can reliably support action-conditioned simulation or model-based planning. Where models do score well, performance appears to track the visual prominence of the intervention rather than the tractability of its underlying physics. Some visually subtle interventions score as low as 14.2%, while visually pronounced ones reach 40.4%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces What-If World, a benchmark of 319 prompt pairs constructed from real frames in nuScenes and DROID, organized by a six-variable taxonomy of physical variables relevant to driving and manipulation. It proposes the APEO four-part rubric (Adherence, Physics, Environment, Outcome) to score whether video generation models produce outputs that correctly diverge under small prompt changes encoding causal interventions. Evaluation across nine state-of-the-art models reports a maximum paired score of 52% (open-source models cluster near 28%), with every model failing on a substantial fraction of interventions; the abstract notes that scores track visual prominence of the change (14.2% subtle vs. 40.4% pronounced) rather than physics tractability.
Significance. If the APEO rubric and paired design can be shown to isolate causal inference from visual salience and prompt artifacts, the benchmark would offer a useful addition to existing single-video evaluation protocols for world models in embodied settings. The use of real-world source frames and the explicit taxonomy provide concrete grounding; the reported performance ceiling and prominence correlation are empirical observations that could guide future model development if the causal interpretation holds after addressing potential confounds.
major comments (2)
- [Abstract] Abstract: The paper states that 'performance appears to track the visual prominence of the intervention rather than the tractability of its underlying physics' and reports 14.2% on subtle vs. 40.4% on pronounced interventions, yet interprets the overall low paired scores (max 52%) as evidence that 'every model tested fails on a large fraction of causal interventions.' This leaves open the alternative that the Outcome component primarily measures change detection rather than causal modeling; without an independent visual-salience baseline or intervention-magnitude metadata from the source datasets, the central claim that the benchmark isolates causal understanding is not fully supported.
- [Abstract and Results] Evaluation protocol: The abstract describes the APEO rubric and aggregate scores but provides no information on inter-rater reliability, how the 319 prompt pairs were validated for physical correctness, or statistical significance testing of the reported differences and the 52% ceiling. These omissions are load-bearing for the reliability of the benchmark results and the claim that open-source models cluster near 28%.
minor comments (2)
- [Abstract] The specific nine models evaluated are referenced only as 'state-of-the-art' in the abstract; naming them and providing per-model breakdowns would improve transparency and allow readers to assess whether the 52% ceiling is driven by particular architectures.
- [Introduction] The six-variable taxonomy is motivated but would benefit from a table listing one concrete prompt-pair example per variable to illustrate the 'small wording change, large physical difference' construction.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that improve the manuscript's rigor without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The paper states that 'performance appears to track the visual prominence of the intervention rather than the tractability of its underlying physics' and reports 14.2% on subtle vs. 40.4% on pronounced interventions, yet interprets the overall low paired scores (max 52%) as evidence that 'every model tested fails on a large fraction of causal interventions.' This leaves open the alternative that the Outcome component primarily measures change detection rather than causal modeling; without an independent visual-salience baseline or intervention-magnitude metadata from the source datasets, the central claim that the benchmark isolates causal understanding is not fully supported.
Authors: The manuscript already reports the prominence correlation as an empirical finding and frames the low paired scores as evidence of failure on causal interventions because the Outcome criterion requires the specific physics-predicted divergence, not merely the presence of change. We nevertheless agree that the current design does not fully exclude a change-detection account. In revision we will (1) add a limitations paragraph explicitly discussing this confound and (2) incorporate any available scene-change metadata from nuScenes and DROID. The abstract will be rephrased to reflect this nuance while retaining the reported numbers. revision: yes
-
Referee: [Abstract and Results] Evaluation protocol: The abstract describes the APEO rubric and aggregate scores but provides no information on inter-rater reliability, how the 319 prompt pairs were validated for physical correctness, or statistical significance testing of the reported differences and the 52% ceiling. These omissions are load-bearing for the reliability of the benchmark results and the claim that open-source models cluster near 28%.
Authors: We agree these details are necessary. The prompt pairs were constructed and cross-checked by the authors against the source frames and the six-variable taxonomy; we will expand the methods section with a precise description of this validation procedure. We will also report inter-rater agreement statistics for the APEO scoring and add statistical tests (bootstrap confidence intervals or appropriate significance tests) for the subtle-versus-pronounced difference and for the model-performance comparisons. revision: yes
Circularity Check
No circularity: empirical benchmark with external data and rubric
full rationale
The paper constructs a benchmark from real video frames (nuScenes, DROID) and applies a fixed four-part APEO rubric to model outputs. No equations, fitted parameters, predictions, or derivations are present. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The evaluation is a direct comparison against external sources and a manually defined scoring protocol; nothing reduces to its own inputs by construction. This is the standard non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Don’t just assume; look and answer: Overcoming priors for visual question answering
Aishwarya Agrawal, Dhruv Batra, Devi Parikh, and Aniruddha Kembhavi. Don’t just assume; look and answer: Overcoming priors for visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4971–4980, 2018
2018
-
[2]
Ossama Ahmed, Frederik Träuble, Anirudh Goyal, Alexander Neitz, Yoshua Bengio, Bern- hard Schölkopf, Manuel Wüthrich, and Stefan Bauer. Causalworld: A robotic manipulation benchmark for causal structure and transfer learning.arXiv preprint arXiv:2010.04296, 2020
-
[3]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
2024
-
[5]
Craft: A benchmark for causal reasoning about forces and interactions
Tayfun Ates, M Ate¸ so˘glu, Ça˘gatay Yi˘git, Ilker Kesen, Mert Kobas, Erkut Erdem, Aykut Erdem, Tilbe Goksun, and Deniz Yuret. Craft: A benchmark for causal reasoning about forces and interactions. InFindings of the Association for Computational Linguistics: ACL 2022, pages 2602–2627, 2022
2022
-
[6]
Video pretraining (vpt): Learning to act by watching unlabeled online videos.Advances in Neural Information Processing Systems, 35:24639–24654, 2022
Bowen Baker, Ilge Akkaya, Peter Zhokov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune. Video pretraining (vpt): Learning to act by watching unlabeled online videos.Advances in Neural Information Processing Systems, 35:24639–24654, 2022
2022
-
[7]
Phyre: A new benchmark for physical reasoning.Advances in Neural Information Processing Systems, 32, 2019
Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Girshick. Phyre: A new benchmark for physical reasoning.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[8]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation.arXiv preprint arXiv:2503.06800, 2025. 10
-
[10]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.arXiv preprint arXiv:2404.08471, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Using thematic analysis in psychology.Qualitative research in psychology, 3(2):77–101, 2006
Virginia Braun and Victoria Clarke. Using thematic analysis in psychology.Qualitative research in psychology, 3(2):77–101, 2006
2006
-
[12]
Tim Brooks, Aleksander Holynski, and Alexei A. Efros. Instructpix2pix: Learning to follow image editing instructions. InCVPR, pages 18392–18402. IEEE, 2023
2023
-
[13]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[14]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[15]
VRAG: Learning World Models for Interactive Video Generation
Taiye Chen, Xun Hu, Zihan Ding, and Chi Jin. Learning world models for interactive video generation.arXiv preprint arXiv:2505.21996, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Unveiling causal reasoning in large language models: Reality or mirage?Advances in Neural Information Processing Systems, 37:96640–96670, 2024
Haoang Chi, He Li, Wenjing Yang, Feng Liu, Long Lan, Xiaoguang Ren, Tongliang Liu, and Bo Han. Unveiling causal reasoning in large language models: Reality or mirage?Advances in Neural Information Processing Systems, 37:96640–96670, 2024
2024
-
[17]
Veo 3.1 technical report
Google DeepMind. Veo 3.1 technical report. Technical report, Google DeepMind, 2025. URL https://storage.googleapis.com/deepmind-media/veo/Veo-3-Tech-Report. pdf
2025
-
[18]
Worldscore: A unified evaluation benchmark for world generation
Haoyi Duan, Hong-Xing Yu, Sirui Chen, Li Fei-Fei, and Jiajun Wu. Worldscore: A unified evaluation benchmark for world generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27713–27724, 2025
2025
- [19]
-
[20]
Physically grounded vision-language models for robotic manipulation
Jensen Gao, Bidipta Sarkar, Fei Xia, Ted Xiao, Jiajun Wu, Brian Ichter, Anirudha Majumdar, and Dorsa Sadigh. Physically grounded vision-language models for robotic manipulation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pages 12462–12469. IEEE, 2024
2024
-
[21]
Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability.Advances in Neural Information Processing Systems, 37:91560–91596, 2024
2024
-
[22]
Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks.Nature Machine Intelligence, 2(11):665–673, 2020
2020
-
[23]
Rohit Girdhar and Deva Ramanan. Cater: A diagnostic dataset for compositional actions and temporal reasoning.arXiv preprint arXiv:1910.04744, 2019
-
[24]
Genie 3: A new frontier for world models
Google DeepMind. Genie 3: A new frontier for world models. https://deepmind.google/ blog/genie-3-a-new-frontier-for-world-models/, 2025. Accessed: 2026-05-06
2025
-
[25]
Agqa: A benchmark for compositional spatio-temporal reasoning
Madeleine Grunde-McLaughlin, Ranjay Krishna, and Maneesh Agrawala. Agqa: A benchmark for compositional spatio-temporal reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11287–11297, 2021
2021
-
[26]
Tarun Gupta, Wenbo Gong, Chao Ma, Nick Pawlowski, Agrin Hilmkil, Meyer Scetbon, Marc Rigter, Ade Famoti, Ashley Juan Llorens, Jianfeng Gao, et al. The essential role of causality in foundation world models for embodied ai.arXiv preprint arXiv:2402.06665, 2024. 11
-
[27]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Comprehensive benchmark suite for video generative models. InCVPR, pages 21807–21818. IEEE, 2024
2024
-
[30]
Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. Vbench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[31]
How far is video generation from world model: A physical law perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective. InICML, Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025
2025
-
[32]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Kie.ai ai model api platform, 2026
Kie.ai. Kie.ai ai model api platform, 2026. URL https://kie.ai/. Unified API for video, image, music and LLM models
2026
-
[34]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Causalvlbench: Benchmarking visual causal reasoning in large vision-language models
Aneesh Komanduri, Karuna Bhaila, and Xintao Wu. Causalvlbench: Benchmarking visual causal reasoning in large vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30648–30668, 2025
2025
-
[36]
Dacheng Li, Yunhao Fang, Yukang Chen, Shuo Yang, Shiyi Cao, Justin Wong, Michael Luo, Xiaolong Wang, Hongxu Yin, Joseph E Gonzalez, et al. Worldmodelbench: Judging video generation models as world models.arXiv preprint arXiv:2502.20694, 2025
-
[37]
Zhiyuan Li, Heng Wang, Dongnan Liu, Chaoyi Zhang, Ao Ma, Jieting Long, and Weidong Cai. Multimodal causal reasoning benchmark: Challenging vision large language models to discern causal links across modalities.arXiv preprint arXiv:2408.08105, 2024
-
[38]
Physgen: Rigid-body physics-grounded image-to-video generation
Shaowei Liu, Zhongzheng Ren, Saurabh Gupta, and Shenlong Wang. Physgen: Rigid-body physics-grounded image-to-video generation. InEuropean Conference on Computer Vision, pages 360–378. Springer, 2024
2024
-
[39]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 2511–2522, 2023
2023
-
[40]
Evalcrafter: Benchmarking and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. Evalcrafter: Benchmarking and evaluating large video generation models. InCVPR, pages 22139–22149. IEEE, 2024
2024
-
[41]
Com- positional causal reasoning evaluation in language models.arXiv preprint arXiv:2503.04556, 2025
Jacqueline RMA Maasch, Alihan Hüyük, Xinnuo Xu, Aditya V Nori, and Javier Gonzalez. Com- positional causal reasoning evaluation in language models.arXiv preprint arXiv:2503.04556, 2025
-
[42]
Towards world simulator: Crafting physical commonsense-based benchmark for video generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Quanfeng Lu, Wenqi Shao, Kaipeng Zhang, Yu Cheng, Dianqi Li, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation. InICML, Proceedings of Machine Learning Research. PMLR / OpenReview.net, 2025. 12
2025
-
[43]
Do gener- ative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do gener- ative video models understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
2026
-
[44]
Counterfactual vqa: A cause-effect look at language bias
Yulei Niu, Kaihua Tang, Hanwang Zhang, Zhiwu Lu, Xian-Sheng Hua, and Ji-Rong Wen. Counterfactual vqa: A cause-effect look at language bias. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12700–12710, 2021
2021
-
[45]
Video generation models as world simulators
OpenAI. Video generation models as world simulators. https://openai.com/index/ video-generation-models-as-world-simulators/, 2024. Accessed: 2026-05-06
2024
-
[46]
Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x- embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
2024
-
[47]
Paritosh Parmar, Eric Peh, Ruirui Chen, Ting En Lam, Yuhan Chen, Elston Tan, and Basura Fernando. Causalchaos! dataset for comprehensive causal action question answering over longer causal chains grounded in dynamic visual scenes.Advances in Neural Information Processing Systems, 37:92769–92802, 2024
2024
-
[48]
Cripp-vqa: Counterfactual reasoning about implicit physical properties via video question answering
Maitreya Patel, Tejas Gokhale, Chitta Baral, and Yezhou Yang. Cripp-vqa: Counterfactual reasoning about implicit physical properties via video question answering. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9856–9870, 2022
2022
-
[49]
Cambridge university press, 2009
Judea Pearl.Causality. Cambridge university press, 2009
2009
-
[50]
Yiran Qin, Zhelun Shi, Jiwen Yu, Xijun Wang, Enshen Zhou, Lijun Li, Zhenfei Yin, Xihui Liu, Lu Sheng, Jing Shao, et al. Worldsimbench: Towards video generation models as world simulators.arXiv preprint arXiv:2410.18072, 2024
-
[51]
Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
2021
-
[52]
Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Team Seedance, Heyi Chen, Siyan Chen, Xin Chen, Yanfei Chen, Ying Chen, Zhuo Chen, Feng Cheng, Tianheng Cheng, Xinqi Cheng, et al. Seedance 1.5 pro: A native audio-visual joint generation foundation model.arXiv preprint arXiv:2512.13507, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Seedance 2.0: Advancing Video Generation for World Complexity
Team Seedance, De Chen, Liyang Chen, Xin Chen, Ying Chen, Zhuo Chen, Zhuowei Chen, Feng Cheng, Tianheng Cheng, Yufeng Cheng, et al. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2604.14148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
-
[55]
T2v- compbench: A comprehensive benchmark for compositional text-to-video generation
Kaiyue Sun, Kaiyi Huang, Xian Liu, Yue Wu, Zihan Xu, Zhenguo Li, and Xihui Liu. T2v- compbench: A comprehensive benchmark for compositional text-to-video generation. InCVPR, pages 8406–8416. Computer Vision Foundation / IEEE, 2025
2025
-
[56]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Kling Team. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025. URL https://arxiv.org/abs/2512.16776
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022. 13
2022
-
[59]
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Josh Tenenbaum, Dan Yamins, Judith Fan, and Kevin Smith. Physion++: Evaluating physical scene understanding that requires online inference of different physical properties.Advances in Neural Information Processing Systems, 36:67048–67068, 2023
2023
-
[60]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Lirui Wang, Yiyang Ling, Zhecheng Yuan, Mohit Shridhar, Chen Bao, Yuzhe Qin, Bailin Wang, Huazhe Xu, and Xiaolong Wang. Gensim: Generating robotic simulation tasks via large language models.arXiv preprint arXiv:2310.01361, 2023
-
[62]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, et al. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9440–9450, 2024
2024
-
[63]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InProceedings of the computer vision and pattern recognition conference, pages 22442–22452, 2025
2025
-
[64]
Drive- dreamer: Towards real-world-drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drive- dreamer: Towards real-world-drive world models for autonomous driving. InEuropean confer- ence on computer vision, pages 55–72. Springer, 2024
2024
-
[65]
Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Dia- mond, Yifan Ding, Wenhao Ding, et al. Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail.arXiv preprint arXiv:2511.00088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Causalbench: A comprehensive benchmark for evaluating causal reasoning capabilities of large language models
Zeyu Wang. Causalbench: A comprehensive benchmark for evaluating causal reasoning capabilities of large language models. InProceedings of the 10th SIGHAN Workshop on Chinese Language Processing (SIGHAN-10), pages 143–151, 2024
2024
-
[67]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, et al. Hunyuanvideo 1.5 technical report.arXiv preprint arXiv:2511.18870, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Star: A benchmark for situated reasoning in real-world videos.ArXiv, abs/2405.09711, 2024
Bo Wu, Shoubin Yu, Zhenfang Chen, Joshua B Tenenbaum, and Chuang Gan. Star: A benchmark for situated reasoning in real-world videos.arXiv preprint arXiv:2405.09711, 2024
-
[69]
arXiv preprint arXiv:2506.05284 , year=
Tong Wu, Shuai Yang, Ryan Po, Yinghao Xu, Ziwei Liu, Dahua Lin, and Gordon Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
-
[70]
Grok imagine: Multimodal image and video generation model, 2025
xAI. Grok imagine: Multimodal image and video generation model, 2025. URL https: //x.ai/grok
2025
-
[71]
Next-qa: Next phase of question- answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question- answering to explaining temporal actions. InCVPR, pages 9777–9786. Computer Vision Foundation / IEEE, 2021
2021
-
[72]
Unisim: A neural closed-loop sensor simulator
Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. Unisim: A neural closed-loop sensor simulator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1389–1399, 2023
2023
-
[73]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Tenenbaum
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B. Tenenbaum. CLEVRER: collision events for video representation and reasoning. InICLR. OpenReview.net, 2020. 14
2020
-
[75]
Chronomagic-bench: A benchmark for metamorphic evaluation of text-to-time-lapse video generation.Advances in Neural Information Processing Systems, 37:21236–21270, 2024
Shenghai Yuan, Jinfa Huang, Yongqi Xu, Yaoyang Liu, Shaofeng Zhang, Yujun Shi, Ruijie Zhu, Xinhua Cheng, Jiebo Luo, and Li Yuan. Chronomagic-bench: A benchmark for metamorphic evaluation of text-to-time-lapse video generation.Advances in Neural Information Processing Systems, 37:21236–21270, 2024
2024
-
[76]
Magicbrush: A manually annotated dataset for instruction-guided image editing
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing. InNeurIPS, 2023
2023
-
[77]
Tesseract: Learning 4d embodied world models.arXiv preprint arXiv:2504.20995, 2025
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: learning 4d embodied world models.arXiv preprint arXiv:2504.20995, 2025
-
[78]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[80]
Zhicheng Zheng, Xin Yan, Zhenfang Chen, Jingzhou Wang, Qin Zhi Eddie Lim, Joshua B Tenenbaum, and Chuang Gan. Contphy: Continuum physical concept learning and reasoning from videos.arXiv preprint arXiv:2402.06119, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.