Colosseum V2: Benchmarking Generalization for Vision Language Action Models
Pith reviewed 2026-06-29 16:28 UTC · model grok-4.3
The pith
Colosseum V2 benchmark demonstrates that current vision-language-action models have significant generalization limitations in robotic manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
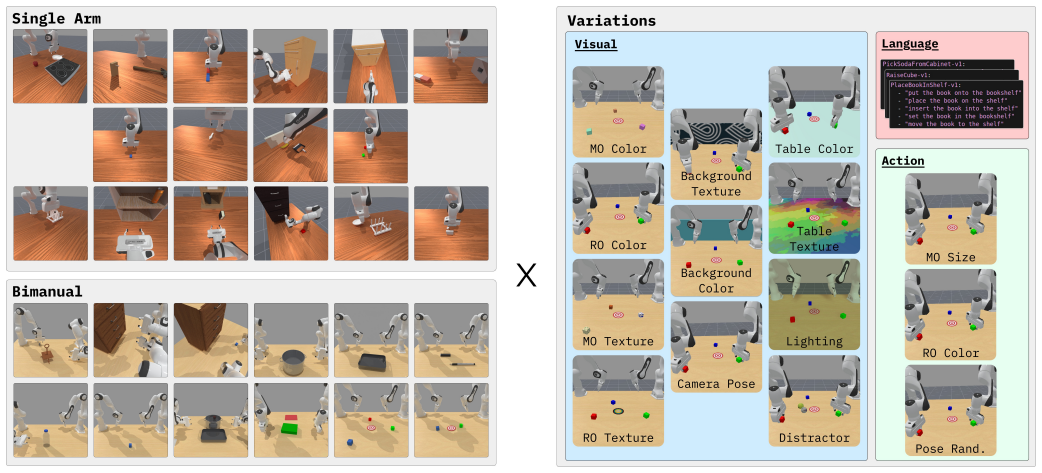
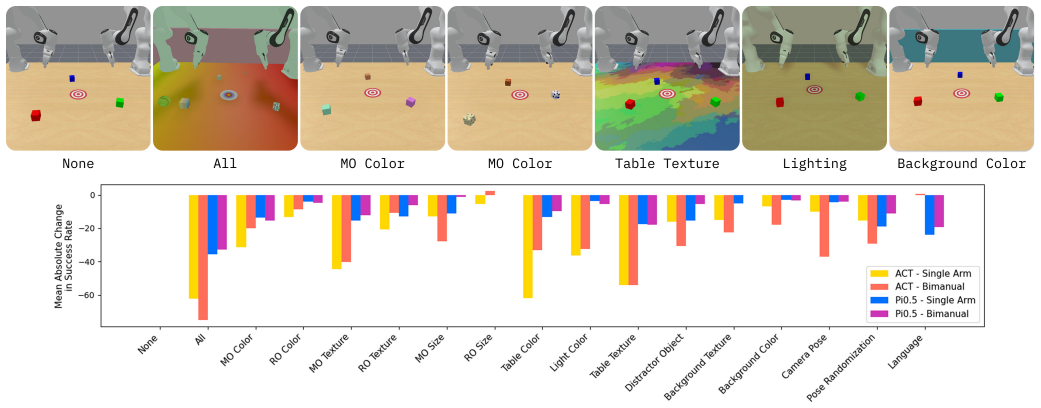
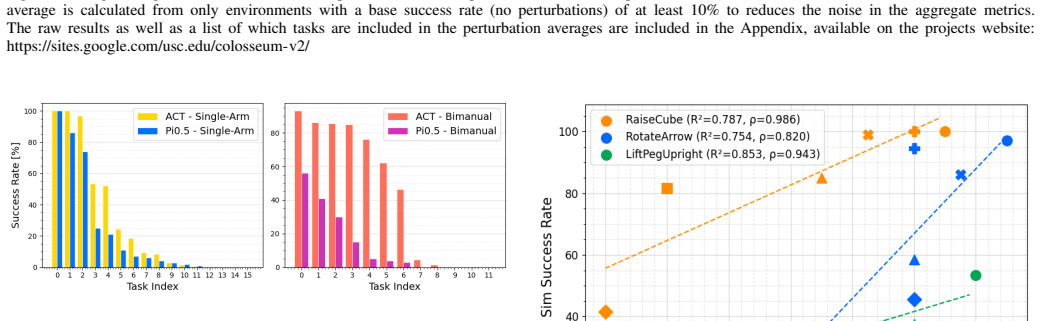
The central discovery is that Colosseum V2, comprising 28 tasks in 13 categories across two robot morphologies, exposes limitations in both the base performance and generalization capabilities of leading VLA methods such as ACT and Pi0.5. Built on the ManiSkill simulator for efficient parallel evaluation, the benchmark supports large-scale in-domain and out-of-domain testing. It further establishes strong correlations between simulation metrics and real-world performance, confirming the benchmark's relevance for assessing generalization in robotic manipulation.
What carries the argument
Colosseum V2, a simulation-based benchmark with standardized tasks and metrics for evaluating VLA generalization under distribution shifts.
If this is right
- State-of-the-art VLA methods exhibit degraded performance under distribution shifts, pointing to the need for improved robustness in translating perception to action.
- Strong correlations between simulation and real-world results validate using the benchmark to predict real robot behavior.
- Unified tasks, metrics, and protocols enable reproducible comparisons and reduce evaluation costs for developing general robot policies.
- Accelerated progress toward general-purpose policies becomes possible through systematic benchmarking of generalization.
Where Pith is reading between the lines
- Researchers could use the benchmark to test whether additional training on diverse simulated variations closes the observed generalization gaps.
- Connections to other robotics benchmarks might reveal if the identified limitations are specific to VLA architectures or common across approaches.
- Extending the benchmark to include more complex long-horizon tasks could uncover additional failure modes not captured in the current 28 tasks.
- If the sim-real correlation holds broadly, it would support greater reliance on simulation for initial model development in robotics.
Load-bearing premise
The 28 tasks and selected distribution shifts capture the key variations relevant to real-world generalization of vision-language-action models.
What would settle it
Finding a vision-language-action model that performs well on Colosseum V2 but shows poor generalization in real-world tests with analogous shifts would indicate that the benchmark does not accurately reflect practical challenges.
Figures



read the original abstract
Vision-Language-Action (VLA) models demonstrate promising generalization in robotic manipulation, driven by advances in large-scale vision and language pre-training. This progress can be misleading. Despite the zero-shot perception and language capabilities of VLAs, their overall task performance often degrades under distribution shifts, revealing gaps in how these systems translate high-level understanding into robust behavior. To systematically study this gap, we introduce Colosseum V2, a large-scale simulation benchmark for evaluating VLA generalization in robot learning across diverse conditions. The benchmark comprises 28 tasks spanning 13 task categories and two robot morphologies, covering a wide range of manipulation primitives and long-horizon behaviors. Built on the ManiSkill simulator, Colosseum V2 enables fast, GPU-parallelized evaluation and supports both in-domain and out-of-domain testing at scale. We evaluate state-of-the-art methods, including Action Chunking Transformers (ACT) and Pi0.5, and reveal limitations in both base performance and generalization. We demonstrate strong correlations between simulation and real-world metrics that support the ecological validity of the benchmark. By standardizing tasks, metrics, and evaluation protocols within a unified benchmark, Colosseum V2 enables reproducible and fair comparisons, reduced evaluation overhead, and accelerated progress toward general-purpose robot policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Colosseum V2, a large-scale ManiSkill-based simulation benchmark comprising 28 tasks across 13 categories and two robot morphologies. It supports GPU-parallelized in-domain and out-of-domain evaluation of Vision-Language-Action models and reports evaluations of ACT and Pi0.5 that reveal limitations in base performance and generalization under distribution shifts, together with strong simulation-to-real correlations supporting ecological validity. The work positions the benchmark as a standardized platform to enable reproducible comparisons and accelerate progress on general-purpose robot policies.
Significance. If the central claims hold, the benchmark offers a scalable, standardized evaluation platform that could meaningfully advance VLA research by exposing generalization gaps in current methods and providing quantitative evidence for sim-to-real transfer. The GPU-parallelized execution and multi-morphology support are concrete strengths that address practical evaluation overhead.
major comments (2)
- [Abstract and §4] Abstract and §4 (Evaluation): the central claim that Colosseum V2 'reveals limitations in both base performance and generalization' of ACT and Pi0.5, and demonstrates 'strong correlations' supporting ecological validity, is presented without quantitative results, error bars, task-level success rates, or correlation coefficients in the abstract; if the corresponding tables or figures in the evaluation section lack these or an accompanying statistical analysis, the empirical grounding for the strongest claims is insufficient.
- [§3] §3 (Task Construction): the selection of the 28 tasks, 13 categories, and chosen distribution shifts is load-bearing for interpreting observed performance gaps and sim-real correlations as field-general rather than benchmark-specific, yet no coverage analysis, ablation on omitted factors (contact-rich dynamics, novel geometries, sensor noise), or independent validation that these shifts span the relevant real-world variation space is provided.
minor comments (2)
- [Abstract] Abstract: include at least one key quantitative result (e.g., average success rate or correlation coefficient) to make the summary self-contained.
- [§3] Ensure all task categories and shift types are explicitly enumerated in a table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on strengthening the empirical presentation and task justification. We address each major point below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): the central claim that Colosseum V2 'reveals limitations in both base performance and generalization' of ACT and Pi0.5, and demonstrates 'strong correlations' supporting ecological validity, is presented without quantitative results, error bars, task-level success rates, or correlation coefficients in the abstract; if the corresponding tables or figures in the evaluation section lack these or an accompanying statistical analysis, the empirical grounding for the strongest claims is insufficient.
Authors: We agree the abstract would benefit from quantitative highlights. Section §4 already contains tables reporting task-level success rates for ACT and Pi0.5 on all 28 tasks under in-domain and out-of-domain conditions, plus figures showing performance under shifts. To address the concern directly, we will revise the abstract to include representative success rates and correlation strengths, add error bars to relevant figures, and include explicit correlation coefficients with basic statistical analysis in §4. revision: yes
-
Referee: [§3] §3 (Task Construction): the selection of the 28 tasks, 13 categories, and chosen distribution shifts is load-bearing for interpreting observed performance gaps and sim-real correlations as field-general rather than benchmark-specific, yet no coverage analysis, ablation on omitted factors (contact-rich dynamics, novel geometries, sensor noise), or independent validation that these shifts span the relevant real-world variation space is provided.
Authors: Section §3 motivates the 28 tasks and 13 categories by spanning diverse ManiSkill primitives (including contact-rich and long-horizon behaviors) and two morphologies, with shifts targeting visual, dynamic, and embodiment variations. We acknowledge the absence of a formal coverage analysis or ablations on every omitted factor. We will expand §3 with additional rationale for the selected shifts and their alignment with robotics literature. Comprehensive ablations on all factors (e.g., sensor noise) exceed the current scope; the reported sim-to-real correlations provide empirical support for relevance. revision: partial
Circularity Check
No circularity: benchmark construction and empirical evaluation are independent of fitted self-referential quantities.
full rationale
The paper introduces Colosseum V2 as a new simulation benchmark with 28 tasks, evaluates existing VLA methods (ACT, Pi0.5) on in/out-of-domain shifts, and reports observed performance gaps plus sim-real correlations. No equations, parameter fits, or derivations are present that reduce a claimed result to its own inputs by construction. The central claims rest on direct empirical measurement within the defined benchmark rather than any self-definitional loop, fitted-input prediction, or load-bearing self-citation chain. Representativeness of the task set is an external validity question, not a circularity issue.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Simulation environments can approximate real-world robot dynamics sufficiently for generalization testing.
Reference graph
Works this paper leans on
-
[1]
ChatGPT: Optimizing language models for dialogue,
OpenAI, “ChatGPT: Optimizing language models for dialogue,” https: //openai.com/blog/chatgpt, 2022, accessed: 2024-08-17
2022
-
[2]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer, “SAM 2: Segment anything in images and videos,”arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Rlbench: The robot learning benchmark and learning environment,
S. James, A. J. Davison, and E. Johns, “Rlbench: The robot learning benchmark and learning environment,” inIEEE Robotics and Automa- tion Letters, 2019
2019
-
[4]
Pyrep: Bringing v- rep to deep robot learning,
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison, “Pyrep: Bringing v- rep to deep robot learning,” inConference on Robot Learning (CoRL), 2019
2019
-
[5]
Coppeliasim robot simulator,
Coppelia Robotics, “Coppeliasim robot simulator,” 2022, https://www.coppeliarobotics.com
2022
-
[6]
The colosseum: A benchmark for evaluating generalization for robotic manipulation,
W. Pumacay, I. Singh, J. Duan, R. Krishna, J. Thomason, and D. Fox, “The colosseum: A benchmark for evaluating generalization for robotic manipulation,” inProceedings of Robotics: Science and Systems, 2024
2024
-
[7]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
B. Liuet al., “Libero: Benchmarking knowledge transfer for lifelong robot learning,” inConference on Robot Learning (CoRL), 2023
2023
-
[8]
Libero-para: A diagnostic benchmark and metrics for paraphrase robustness in vla models,
C. Kim, M. Kim, M. Kang, H. Kim, and D. Jung, “Libero-para: A diagnostic benchmark and metrics for paraphrase robustness in vla models,” 2026. [Online]. Available: https://arxiv.org/abs/2603.28301
-
[9]
Roboverse: Towards a unified platform for robotic manipulation,
A. Muraliet al., “Roboverse: Towards a unified platform for robotic manipulation,” inConference on Robot Learning Workshop, 2020
2020
-
[10]
Roboarena: Distributed real-world evaluation of generalist robot policies,
R. Team, “Roboarena: Distributed real-world evaluation of generalist robot policies,” 2024
2024
-
[11]
Robotwin: A platform for scalable robot learning,
——, “Robotwin: A platform for scalable robot learning,” 2024, https://robotwin-platform.github.io
2024
-
[12]
Bimanual manipulation benchmark,
B. B. Team, “Bimanual manipulation benchmark,” 2024, https://bimanual.github.io
2024
-
[13]
Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,”IEEE Robotics and Automation Letters (RA- L), vol. 7, no. 3, pp. 7327–7334, 2022
2022
-
[14]
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, and X. Qiu, “Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks,” 2024. [Online]. Available: https://arxiv.org/abs/2412.18194
-
[15]
Vlmbench: A compositional benchmark for vision-and-language manipulation,
K. Zheng, X. Chen, O. C. Jenkins, and X. E. Wang, “Vlmbench: A compositional benchmark for vision-and-language manipulation,” 2022. [Online]. Available: https://arxiv.org/abs/2206.08522
-
[16]
Manipbench: Benchmarking vision-language models for low-level robot manipulation,
E. Zhao, V . Raval, H. Zhang, J. Mao, Z. Shangguan, S. Nikolaidis, Y . Wang, and D. Seita, “Manipbench: Benchmarking vision-language models for low-level robot manipulation,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09698
-
[17]
R3m: A universal visual representation for robot manipulation,
S. Nairet al., “R3m: A universal visual representation for robot manipulation,” inConference on Robot Learning, 2022
2022
-
[18]
Mvp: Multi-view pretraining for vision-language robotics,
T. Xiaoet al., “Mvp: Multi-view pretraining for vision-language robotics,” inConference on Robot Learning, 2022
2022
-
[19]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Y . J. Ma, S. Sodhani, D. Jayaraman, O. Bastani, V . Kumar, and A. Zhang, “Vip: Towards universal visual reward and representation via value- implicit pre-training,”arXiv preprint arXiv:2210.00030, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Cliport: What and where pathways for robotic manipulation,
M. Shridharet al., “Cliport: What and where pathways for robotic manipulation,” inConference on Robot Learning, 2022
2022
-
[21]
V oxposer: Composable 3d value maps for robotic manipulation with language models,
W. Huanget al., “V oxposer: Composable 3d value maps for robotic manipulation with language models,” inConference on Robot Learning, 2023
2023
-
[22]
C2farm: Coarse-to-fine imitation learning for manipu- lation,
S. Jameset al., “C2farm: Coarse-to-fine imitation learning for manipu- lation,” inConference on Robot Learning, 2022
2022
-
[23]
Kite: Keyframe imitation for task execution,
P. Sundaresanet al., “Kite: Keyframe imitation for task execution,” in Conference on Robot Learning, 2023
2023
-
[24]
Learning fine-grained bimanual manipulation with act,
T. Zhaoet al., “Learning fine-grained bimanual manipulation with act,” arXiv preprint, 2023
2023
-
[25]
Peract: Perceiver-actor for 6-dof manipulation,
M. Shridharet al., “Peract: Perceiver-actor for 6-dof manipulation,” in Robotics: Science and Systems, 2022
2022
-
[26]
Rvt: Robotic vision transformer for manipulation,
A. Goyalet al., “Rvt: Robotic vision transformer for manipulation,” in Conference on Robot Learning, 2023
2023
-
[27]
Rvt-2: Scaling vision transformers for robot manipulation,
——, “Rvt-2: Scaling vision transformers for robot manipulation,”arXiv preprint, 2024
2024
-
[28]
Act3d: 3d feature fields for manipulation policies,
T. Gervetet al., “Act3d: 3d feature fields for manipulation policies,” in Conference on Robot Learning, 2023
2023
-
[29]
PaLM-E: An Embodied Multimodal Language Model
D. Driesset al., “Palm-e: An embodied multimodal language model,” arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohanet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,”arXiv preprint arXiv:2307.15818, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
OpenVLA: An Open-Source Vision-Language-Action Model
M. J. Kimet al., “Openvla: Vision-language-action models for robotics,” arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
π0: A vision-language-action model for general robot control,
K. Blacket al., “π0: A vision-language-action model for general robot control,”arXiv preprint arXiv:2405.03854, 2024
-
[33]
π0-fast: Fast vision-language-action models for robotics,
K. Pertschet al., “π0-fast: Fast vision-language-action models for robotics,”arXiv preprint arXiv:2501.00000, 2025
-
[34]
π0.5: Vision-language-action models for open-world robotics,
P. I. Team, “π0.5: Vision-language-action models for open-world robotics,”arXiv preprint, 2025
2025
-
[35]
Open x-embodiment: Robotic learning datasets and rt-x models,
A. Padalkaret al., “Open x-embodiment: Robotic learning datasets and rt-x models,” 2023
2023
-
[36]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf, “Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,” https://github.com/huggingface/lerobot, 2024
2024
-
[37]
Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su, “Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,”Robotics: Science and Systems, 2025
2025
-
[38]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021. [Online]. Available: https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Sigmoid Loss for Language Image Pre-Training
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid loss for language image pre-training,” 2023. [Online]. Available: https://arxiv.org/abs/2303.15343
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[41]
MolmoAct: Action Reasoning Models that can Reason in Space
J. Lee, J. Duan, H. Fang, Y . Deng, S. Liu, B. Li, B. Fang, J. Zhang, Y . R. Wang, S. Lee, W. Han, W. Pumacay, A. Wu, R. Hendrix, K. Farley, E. VanderBilt, A. Farhadi, D. Fox, and R. Krishna, “Molmoact: Action reasoning models that can reason in space,” 2025. [Online]. Available: https://arxiv.org/abs/2508.07917
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Vima: General robot manipulation with multimodal prompts,
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei- Fei, A. Anandkumar, Y . Zhu, and L. Fan, “Vima: General robot manipulation with multimodal prompts,” 2023. [Online]. Available: https://arxiv.org/abs/2210.03094
-
[43]
Learning an actionable discrete diffusion policy via large-scale actionless video pre- training,
H. He, C. Bai, L. Pan, W. Zhang, B. Zhao, and X. Li, “Learning an actionable discrete diffusion policy via large-scale actionless video pre- training,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[45]
S. Li, Y . Gao, D. Sadigh, and S. Song, “Unified video action model,” arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets,
C. Zhu, R. Yu, S. Feng, B. Burchfiel, P. Shah, and A. Gupta, “Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets,” inProceedings of Robotics: Science and Systems (RSS), 2025
2025
-
[47]
Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen, “Video prediction policy: A generalist robot policy with predictive visual representations,”arXiv preprint arXiv:2412.14803, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control,
T. Ma, J. Zheng, Z. Wang, C. Jiang, A. Cui, J. Liang, and S. Yang, “Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.10448
-
[49]
Contrast sets for evaluating language-guided robot policies,
A. Anwar, R. Gupta, and J. Thomason, “Contrast sets for evaluating language-guided robot policies,” 2024. [Online]. Available: https: //arxiv.org/abs/2406.13636
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.