UniMaia: Steering Chess Policies with Language for Human-like Play
Pith reviewed 2026-06-29 17:45 UTC · model grok-4.3
The pith
A frozen chess policy network can be steered by natural language prompts using a lightweight text encoder and conditioning layer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
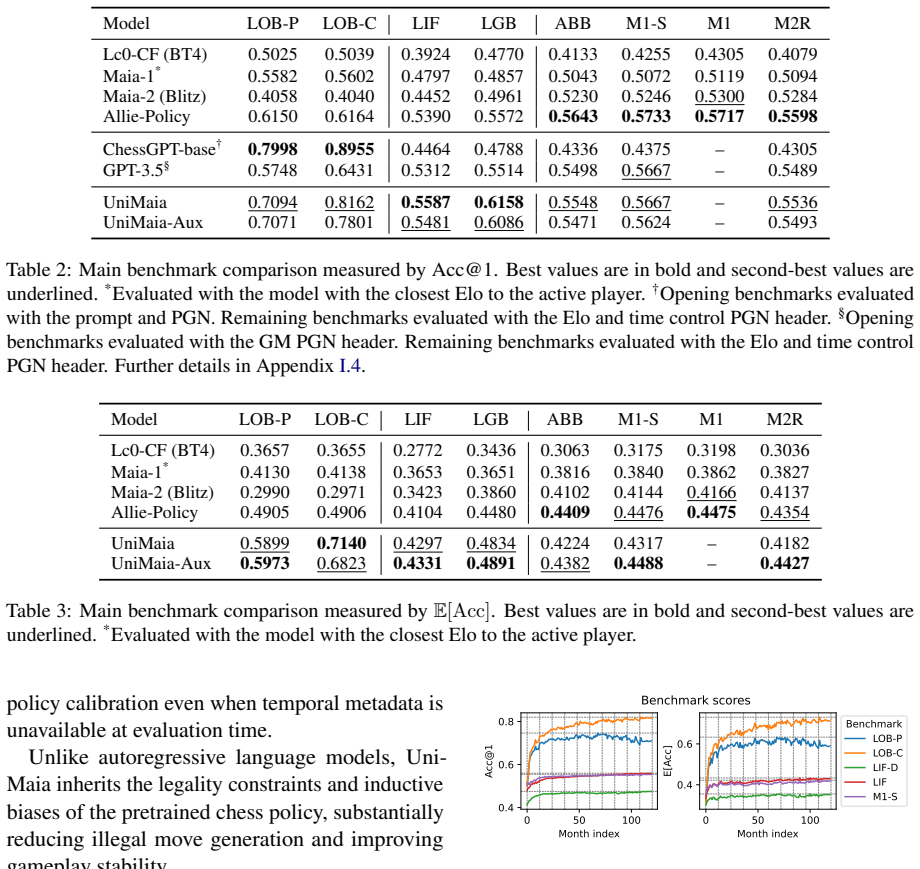
Attaching a parameter-efficient text encoder to a frozen chess policy network and applying a ControlNet-style conditioning mechanism allows natural language prompts to modulate gameplay decisions such as opening selection and strength level. The resulting system reaches state-of-the-art expected accuracy on prompt-conditioned benchmarks and remains competitive with metadata-conditioned baselines on human move prediction tasks, while an auxiliary variant further improves behavioral modeling at a small cost to top-move accuracy.
What carries the argument
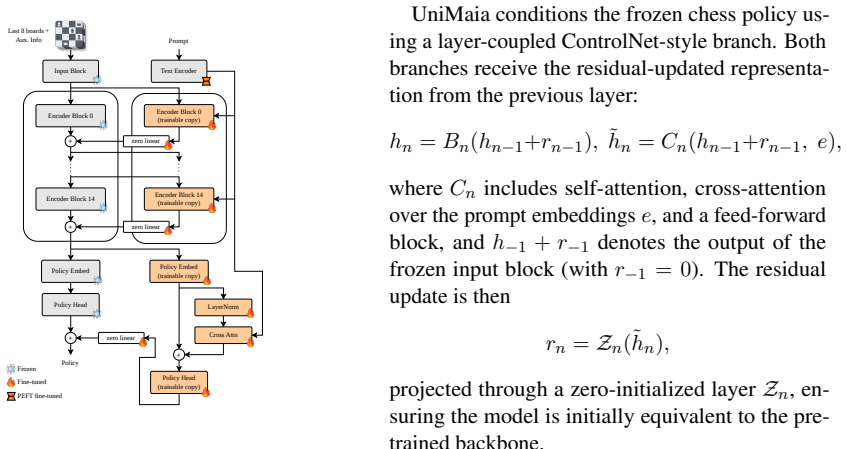
Parameter-efficient text encoder plus ControlNet-style conditioning mechanism that modulates activations inside the frozen policy network according to text input.
If this is right
- Language prompts can select specific chess openings without changing the underlying policy weights.
- Playing strength can be adjusted through text instructions while the model retains its core move-generation capability.
- The same conditioning approach yields competitive results on both prompt-following and general move-prediction benchmarks.
- Auxiliary temporal and behavioral objectives further improve prompt adherence and human-move modeling.
- Trade-offs appear between the degree of controllability gained and raw predictive performance on unprompted positions.
Where Pith is reading between the lines
- The method could extend to other board games or structured decision tasks where a strong policy network already exists.
- For applications that prioritize maximum playing strength over language control, pure metadata conditioning may still be preferable.
- The prompt-generation pipeline and metadata-augmented dataset open the door to systematic testing of controllability across many instruction types.
- If the conditioning mechanism generalizes, similar lightweight adapters might allow language interfaces for other specialized AI systems without joint retraining.
Load-bearing premise
The original chess policy's internal representations remain intact and useful once the text conditioning layer is added on top.
What would settle it
A large drop in move-prediction accuracy on standard chess positions when the conditioning layer is active, even without any prompt, would show the approach fails to preserve domain grounding.
Figures







read the original abstract
Recent advances in large language models have enabled natural language to serve as a flexible interface for controlling complex systems, but often at the cost of large-scale multimodal training or weakened domain-specific inductive biases. In structured decision-making domains such as chess, specialized policy networks achieve strong performance but lack semantic controllability, while prompt-conditioned language models are more flexible yet typically exhibit weaker domain grounding. We propose $\textbf{UniMaia}$, a framework for prompt-conditioned policy modulation that adapts a frozen Lc0-based chess policy network using a parameter-efficient text encoder and a ControlNet-style conditioning mechanism. UniMaia enables semantic control over gameplay, including opening selection and player strength, while preserving the pretrained policy representations. We further introduce $\textbf{UniMaia-Aux}$, which incorporates auxiliary temporal conditioning and behavioral prediction objectives. To support this work, we construct a large-scale metadata-augmented Lichess dataset, develop a semi-automated prompt-generation pipeline, and introduce benchmarks spanning both prompt-conditioned and metadata-conditioned settings. UniMaia achieves state-of-the-art expected accuracy on several prompt-conditioned benchmarks and competitive top-move accuracy on general instruction-following tasks, while remaining competitive with dedicated metadata-conditioned approaches on human move prediction benchmarks. UniMaia-Aux further improves expected accuracy and behavioral modeling across several evaluation settings, with modest trade-offs in top-move accuracy. Overall, our results demonstrate that prompt-conditioned control of domain-specific policy networks is feasible without end-to-end multimodal training, while highlighting trade-offs between controllability and predictive performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniMaia, a framework for prompt-conditioned policy modulation that adapts a frozen Lc0 chess policy network via a parameter-efficient text encoder and ControlNet-style conditioning mechanism. This enables semantic control (e.g., opening selection, player strength) without end-to-end multimodal training. It also introduces UniMaia-Aux with auxiliary temporal conditioning and behavioral prediction objectives, constructs a metadata-augmented Lichess dataset, develops a semi-automated prompt-generation pipeline, and defines new benchmarks for prompt- and metadata-conditioned settings. Results claim SOTA expected accuracy on several prompt-conditioned benchmarks, competitive top-move accuracy on instruction-following tasks, and competitiveness with metadata-conditioned baselines on human move prediction.
Significance. If the results hold, the work demonstrates a viable path to adding natural-language controllability to strong domain-specific policy networks while preserving their pretrained representations and avoiding large-scale multimodal retraining. The construction of the new dataset, prompt pipeline, and benchmarks constitutes a concrete positive contribution that can support future research on controllable agents in structured domains. The explicit discussion of controllability-performance trade-offs is also useful.
major comments (2)
- [§4] §4 (Experimental evaluation): The abstract and results claim SOTA expected accuracy and competitive top-move accuracy, but the provided text supplies no details on dataset splits, error bars, number of runs, or statistical significance testing. This information is load-bearing for verifying the central feasibility claim.
- [§3.2] §3.2 (Conditioning mechanism): The claim that frozen Lc0 representations remain intact and useful after parameter-efficient modulation is central to the approach but is not supported by explicit checks such as policy divergence metrics or unconditioned move-prediction accuracy before versus after adding the text-conditioning module.
minor comments (2)
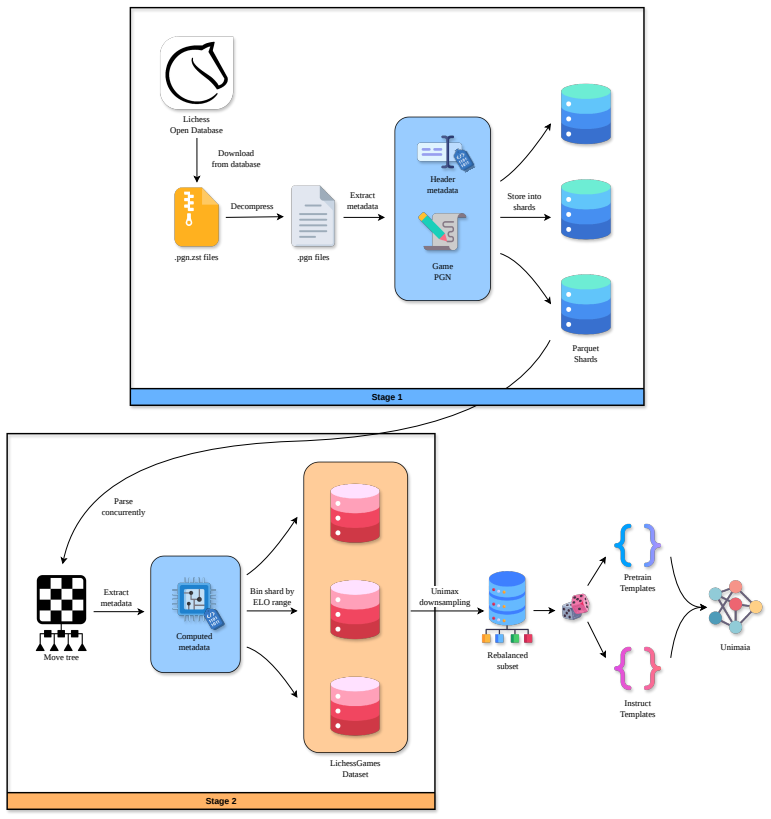
- The description of the prompt-generation pipeline would benefit from one or two concrete examples of input metadata and resulting prompts.
- [Table 2] Table 2 (or equivalent results table): Ensure all compared methods list their trainable parameter counts and whether they use the same frozen Lc0 backbone for fair comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential contribution. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experimental evaluation): The abstract and results claim SOTA expected accuracy and competitive top-move accuracy, but the provided text supplies no details on dataset splits, error bars, number of runs, or statistical significance testing. This information is load-bearing for verifying the central feasibility claim.
Authors: We agree that these experimental details are essential for verifying the claims. In the revised manuscript we will explicitly describe the train/validation/test splits of the metadata-augmented Lichess dataset, report error bars (standard deviation across runs), state the number of independent runs performed for each result, and include statistical significance testing (e.g., paired t-tests) for the reported improvements in expected accuracy. revision: yes
-
Referee: [§3.2] §3.2 (Conditioning mechanism): The claim that frozen Lc0 representations remain intact and useful after parameter-efficient modulation is central to the approach but is not supported by explicit checks such as policy divergence metrics or unconditioned move-prediction accuracy before versus after adding the text-conditioning module.
Authors: This observation is correct; the original submission relies on the design of the parameter-efficient adapter but does not provide direct empirical verification. We will add the requested checks in the revision: KL-divergence (or equivalent policy divergence) between the original Lc0 policy and the conditioned policy, plus a direct comparison of unconditioned top-1 move accuracy on held-out positions before versus after the text-conditioning module is attached. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces an architectural framework (frozen Lc0 policy + parameter-efficient text encoder + ControlNet-style modulation) and evaluates it on newly constructed datasets and benchmarks for prompt-conditioned chess move prediction. No equations, first-principles derivations, or fitted-parameter predictions appear in the provided text. Claims of feasibility and trade-offs rest on empirical results from external benchmarks rather than any self-referential reduction, self-citation chain, or ansatz smuggled via prior work. The work is self-contained against its stated evaluation metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Sia- mak Shakeri, Dara Bahri, Tal Schuster, and 1 others
Maia-2: A unified model for human-ai align- ment in chess.Advances in Neural Information Pro- cessing Systems, 37:20919–20944. Yi Tay, Mostafa Dehghani, Vinh Q Tran, Xavier Garcia, Jason Wei, Xuezhi Wang, Hyung Won Chung, Sia- mak Shakeri, Dara Bahri, Tal Schuster, and 1 others
-
[2]
Tran, Dani Yogatama, and Donald Metzler
Ul2: Unifying language learning paradigms. arXiv preprint arXiv:2205.05131. Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, Thomas Mesnard, Geoffrey Cideron, Jean bastien Grill, Sabela Ramos, Edouard Yvinec, Michelle Casbon, Etie...
-
[3]
Generate natural-language prompts condi- tioned on game metadata. 15
-
[4]
Convert metadata spans into parameterized Jinja2 fields
-
[5]
Instantiate templates across many games
-
[6]
A major challenge is maintaining correctness under iterative modifications
Manually review outputs and refine formatting rules. A major challenge is maintaining correctness under iterative modifications. Because templates combine independently generated metadata snip- pets, small changes can introduce grammatical or formatting errors across many instantiations.2 Consequently, some prompts contain minor arti- facts such as duplic...
2048
-
[7]
AdamW:AdamW (Loshchilov and Hutter, 2017), used in our initial experiments
2017
-
[8]
Muon:Muon (Jordan et al., 2024) orthogonal- izes updates for 2D non-embedding and non- output parameters. Following prior work (Jor- dan et al., 2024; Liu et al., 2025), we use AdamW for all remaining parameters. 20 Experiment LOB-P LIF-D M1-S Mean µloss,Dec13 Single-step cross-attention (early fusion)0.4696 0.4176 0.4315 0.4396 1.6685 Per-layer cross-att...
-
[9]
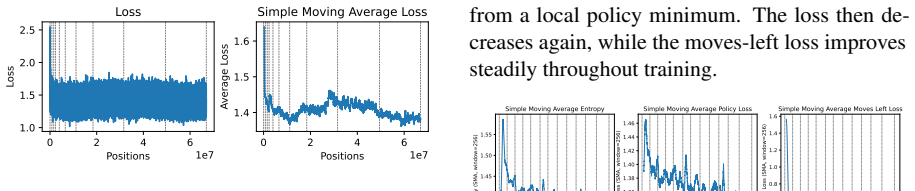
Figure 8 shows the training losses
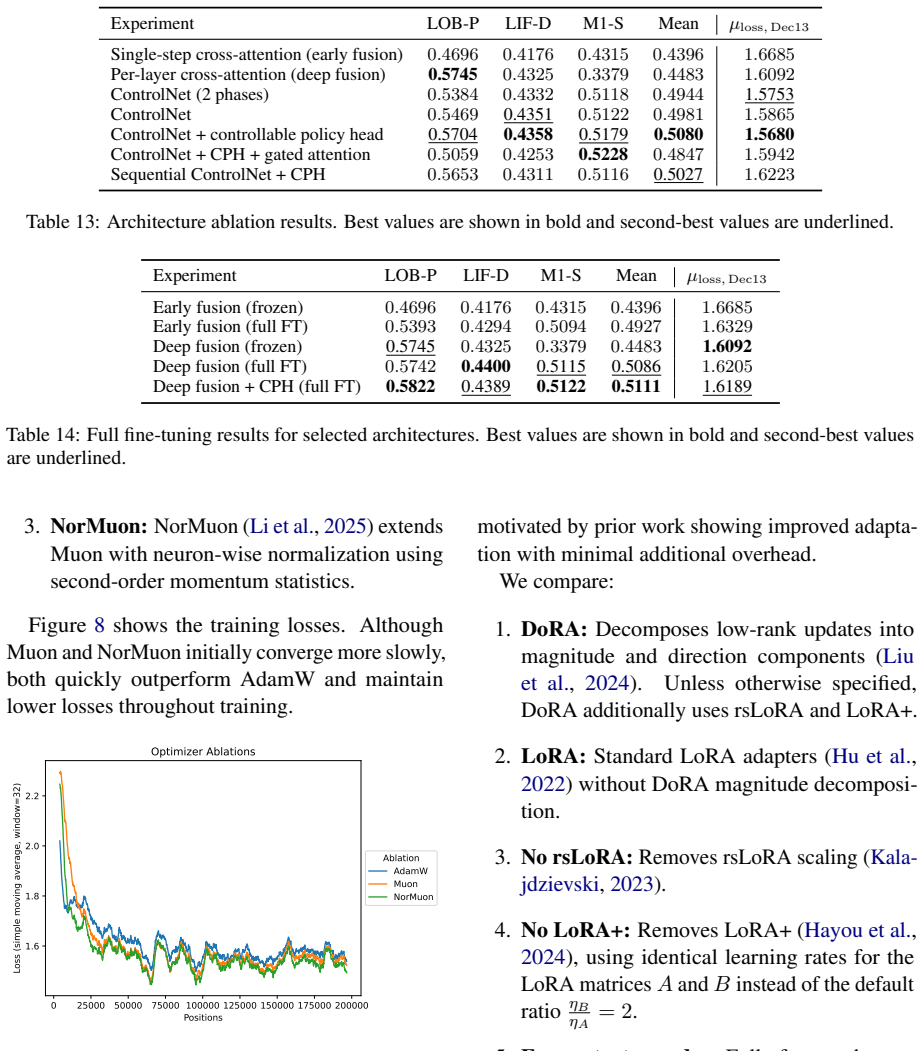
NorMuon:NorMuon (Li et al., 2025) extends Muon with neuron-wise normalization using second-order momentum statistics. Figure 8 shows the training losses. Although Muon and NorMuon initially converge more slowly, both quickly outperform AdamW and maintain lower losses throughout training. 0 25000 50000 75000 100000 125000 150000 175000 200000 Positions 1.6...
2025
-
[10]
Unless otherwise specified, DoRA additionally uses rsLoRA and LoRA+
DoRA:Decomposes low-rank updates into magnitude and direction components (Liu et al., 2024). Unless otherwise specified, DoRA additionally uses rsLoRA and LoRA+
2024
-
[11]
LoRA:Standard LoRA adapters (Hu et al.,
-
[12]
without DoRA magnitude decomposi- tion
-
[13]
No rsLoRA:Removes rsLoRA scaling (Kala- jdzievski, 2023)
2023
-
[14]
No LoRA+:Removes LoRA+ (Hayou et al., 2024), using identical learning rates for the LoRA matrices A and B instead of the default ratio ηB ηA = 2
2024
-
[15]
Figure 9 shows that all LoRA-based variants con- verge similarly
Frozen text encoder:Fully freezes the text encoder while retaining the remaining Con- trolNet conditioning architecture. Figure 9 shows that all LoRA-based variants con- verge similarly. Although the frozen text encoder reaches a comparable loss, it consistently under- performs on downstream benchmarks, indicating that adapting the language representation...
-
[16]
t3:A 0.10B-parameter model initialized from t3-512x15x16h-swa-2815000
-
[17]
BT3:A 0.12B-parameter model initialized fromBT3-768x15x24h-swa-2790000
-
[18]
Increasing the backbone width generally im- proves performance
BT4:A 0.21B-parameter model initialized fromBT4-1024x15x32h-swa-5000000. Increasing the backbone width generally im- proves performance. While BT3 achieves the high- est mean benchmark score in this ablation, BT4 attains the lowest loss and remains competitive across all benchmarks. We note that BT3 also outperforms BT4 in the standalone Lc0 evaluation (s...
-
[19]
Group-level balancing: whether to partition games into groups (e.g., by opening or time control) and allocate separate budgets to each group using Unimax
-
[20]
In all settings, plies are sampled uniformly within each game after budgets are assigned
Per-game budget allocation: whether to al- locate plies proportionally to game length or using Unimax, which caps the contribution of long games. In all settings, plies are sampled uniformly within each game after budgets are assigned. Un- less otherwise specified, the baseline uses Unimax grouped by opening. Table 19 shows that balancing across time con-...
2024
-
[21]
WSD-S (monthly):warmup and decay are applied independently each month
-
[22]
WSD-S (annual):a single warmup–stable– decay cycle is applied across all of 2013. Because the original schedule spends nearly all of January 2013 in warmup, we shorten the warmup phase to 512 steps and allocate an additional 512 decay steps, leaving1,024stable-training steps. As shown in Figure 11, the WSD-S schedules reduce loss more rapidly early in tra...
-
[23]
50/50 mixture: sample from both template families with equal probability
-
[24]
Pretrain only: sample exclusively from 24 LICHESSTEMPLATES-PRETRAIN
-
[25]
Using only instruct templates yields the strongest average benchmark performance, while the 50/50 mixture achieves comparable downstream accuracy with lower training loss
Instruct only: sample exclusively from LICHESSTEMPLATES-INSTRUCT. Using only instruct templates yields the strongest average benchmark performance, while the 50/50 mixture achieves comparable downstream accuracy with lower training loss. We therefore adopt the mixed-template configuration in the final model. One possible explanation is that the instruct t...
2024
-
[26]
ChessGPT-play:ChessGPT-base fine- tuned directly for next-move prediction on the 2013 split using the template {prompt}<|endoftext|>{pgn}
2013
-
[27]
ControlNet (ChessGPT-base):The standard ControlNet configuration using the pretrained ChessGPT-base encoder
-
[28]
ControlNet (ChessGPT-play):The same ControlNet configuration, but replacing the text encoder with ChessGPT-play
-
[29]
ChessGPT-play converges rapidly within the first ∼50 steps (Figure 12)
ControlNet (ChessGPT-play), end-of-text PGNs:A variant using the explicit end-of-text separator {prompt}<|endoftext|>{pgn} during ControlNet training to reduce dis- tribution shift relative to ChessGPT-play pretraining. ChessGPT-play converges rapidly within the first ∼50 steps (Figure 12). Interestingly, prediction 25 Experiment LOB-P LIF-D M1-S Mean µlo...
-
[30]
QKV projections:Apply LoRA only to the query, key, and value projections
-
[31]
QKV + O projections:Additionally adapt the output projection
-
[32]
Table 26 shows that all configurations perform similarly
QKV + O + FFN:Further extend LoRA to the feedforward layers. Table 26 shows that all configurations perform similarly. Targeting both QKV and O projections achieves the highest mean score, while adding FFN adapters slightly reduces downstream performance despite a marginally lower loss. The differences are small and likely within the variance induced by r...
-
[33]
for approximating polar(·) occasionally in- troduces gradient spikes in the LoRA adapters, slightly increasing loss and making NaNs more likely in some execution environments. Consis- tent with observations from the Kimi Team (Team et al., 2025b), Muon also produces exploding atten- tion logits more frequently than AdamW. DoRA adapters are generally more ...
-
[34]
within the layer-coupled ControlNet archi- tecture described in Section 4. The frozen Lc0 pol- icy network is conditioned through a text encoder adapted using LoRA with rsLoRA and LoRA+, using rank 16 adapters. Optimization uses NorMuon for all 2D non- embedding, non-output parameters and AdamW for the remaining parameters. We use weight de- cay 0.01, ϵ= ...
-
[35]
Prompt: The prompt followed by the PGN move list without headers: {prompt}\n\n{pgn}
-
[36]
To ensure reliable move extraction, we use outlines (Willard and Louf, 2023) to constrain the generated output with a predefined regular ex- pression
Elo and time control PGN header4: A PGN header describing both players’ Elos and the time control (Appendix J.4), followed by two newlines and the PGN move list. To ensure reliable move extraction, we use outlines (Willard and Louf, 2023) to constrain the generated output with a predefined regular ex- pression. For ChessGPT-base, the move number may optio...
2023
-
[37]
Ap- plying the chat template twice—once without the generation prompt and once with it—improves performance on the Lichess openings benchmark
Simple, duplicate: We prompt ChessGPT-chat with {prompt}\n\nPGN: {pgn}\n\nJust write your move. Ap- plying the chat template twice—once without the generation prompt and once with it—improves performance on the Lichess openings benchmark
-
[38]
Simple, original: The same prompt as above, except the chat template is applied only once with the generation prompt
-
[39]
As with ChessGPT-base, we use outlines (Willard and Louf, 2023) to con- strain generation
General policy: A prompt adapted from Feng et al., consisting of a prompt to play chess in a given position, a PGN header with certain fields masked by “??”, the PGN move list, and a final instruction to produce the next move. As with ChessGPT-base, we use outlines (Willard and Louf, 2023) to con- strain generation. For ChessGPT-chat, the output must matc...
2023
-
[40]
GM PGN header + prompt: A natural- language prompt inserted between the header and the move list
-
[41]
Original PGN header: The original PGN header, followed by the move list
-
[42]
Elo and time control PGN header: A PGN header specifying player ratings and time con- trol (Appendix J.4), followed by the move list. For autoregressive language models, generated moves are constrained to valid chess formats where possible. Illegal moves are replaced with uniformly sampled legal moves during evaluation. I.5 Model Comparison The evaluated ...
-
[43]
Play”, while none begin with “Open
of instruction templates, begin with the verb “Play”, while none begin with “Open”. Many templates instead begin with contextual pre- fixes such as player names or titles. Consequently, prompts that more closely match the training distri- bution tend to produce more stable behavior than semantically equivalent but distributionally differ- ent phrasing. Th...
-
[44]
King’s Pawn Opening: You are an anonymous white player rated {elo}, playing against an anonymous black player rated {elo}, using the King’s Pawn Opening
-
[45]
Queen’s Pawn Opening: You are an anonymous white player rated {elo}, playing against an anonymous black player rated {elo}, using the Queen’s Pawn Opening
-
[46]
English Opening: You are an anonymous white player rated {elo}, playing against an anonymous black player rated {elo}, using the English Opening
-
[47]
Both top-move and expected accuracy generally increase with player Elo, reflecting the greater con- sistency of higher-rated play
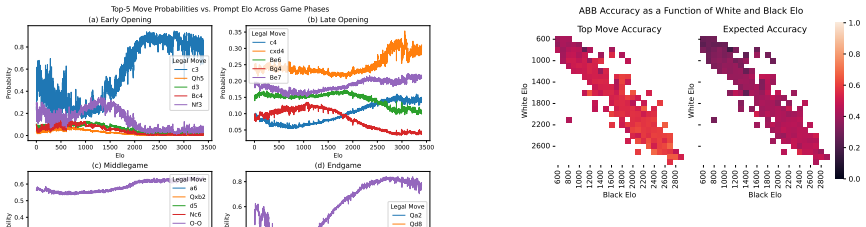
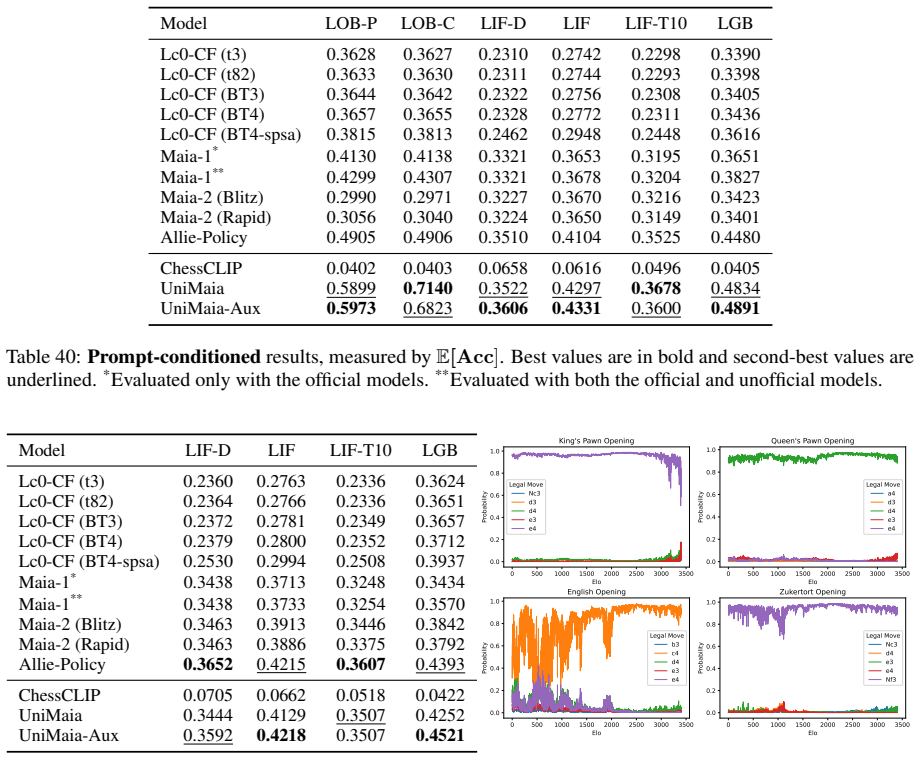
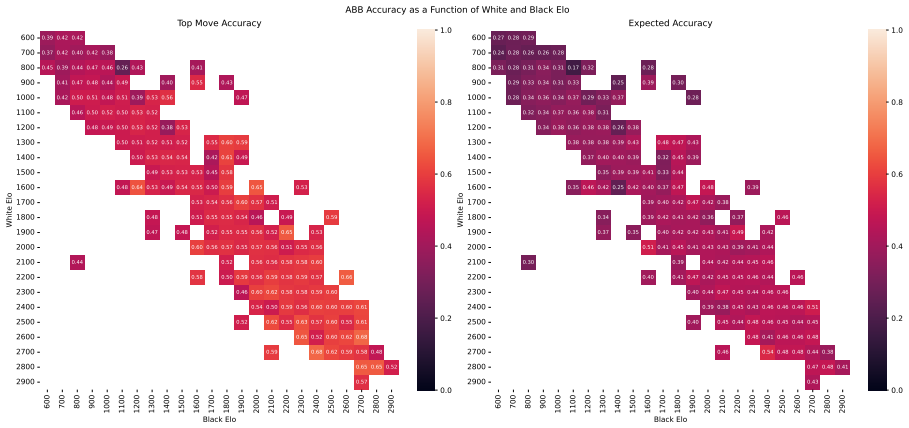
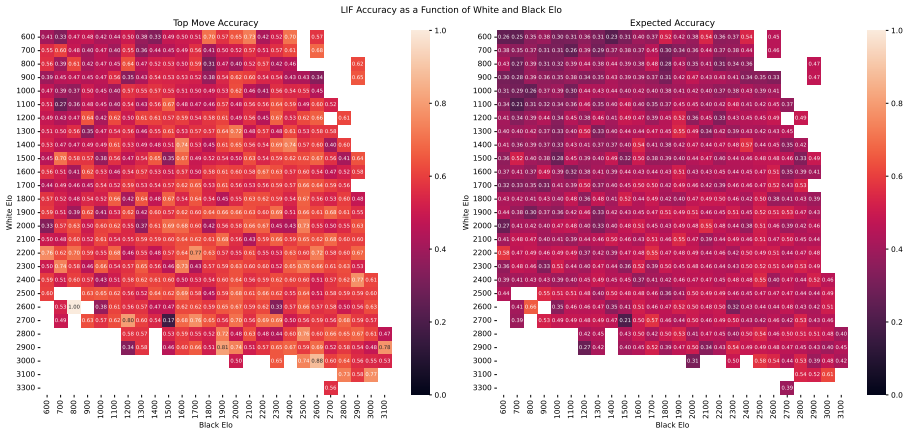
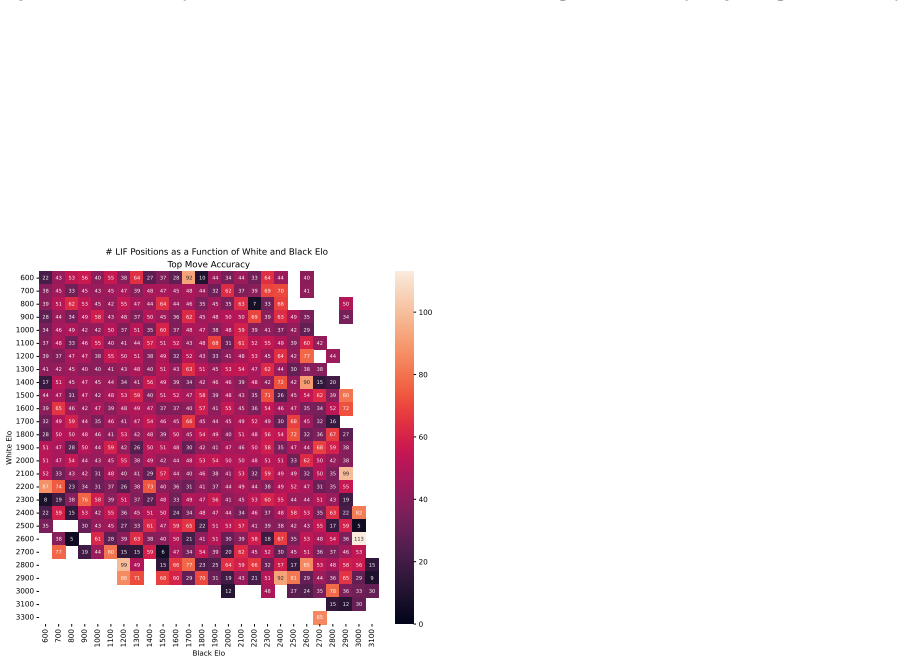
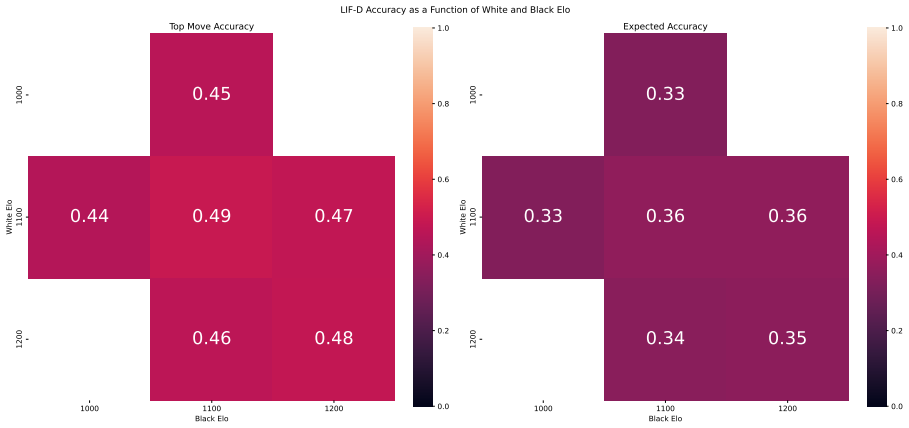
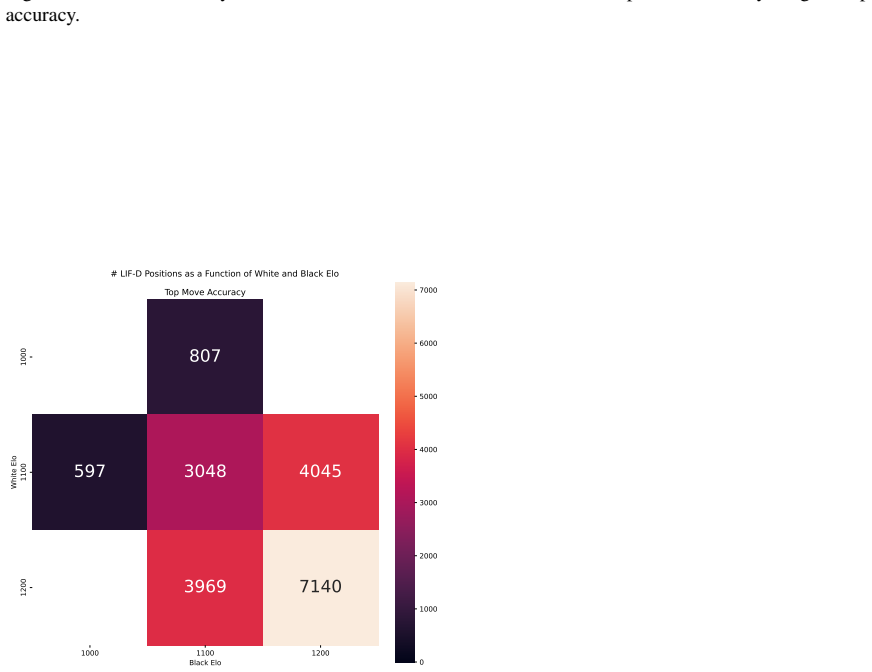
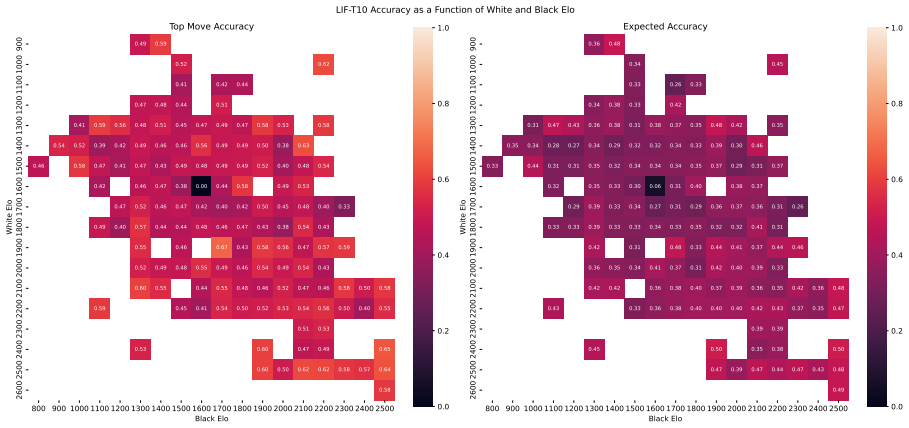
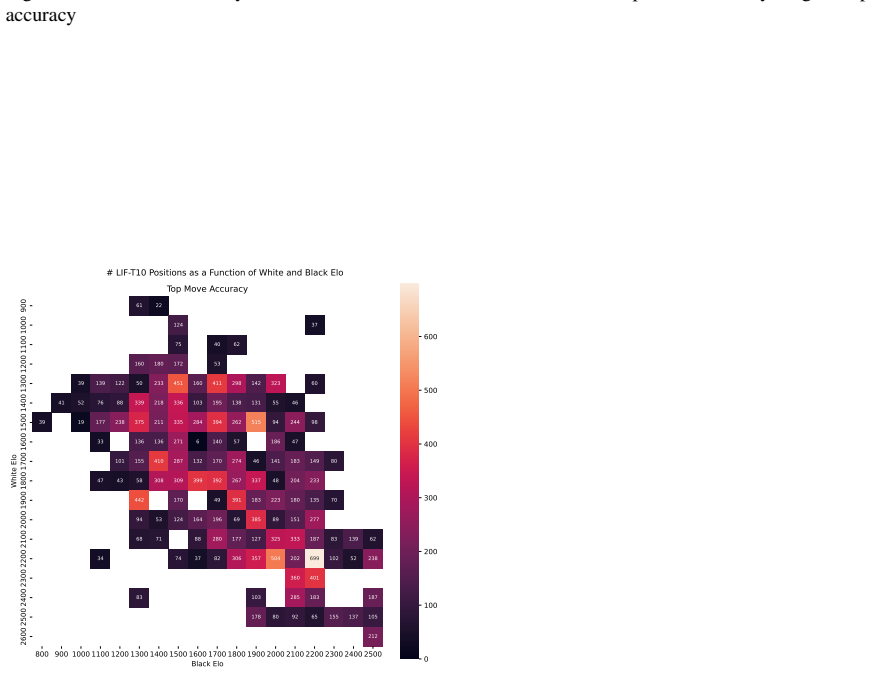
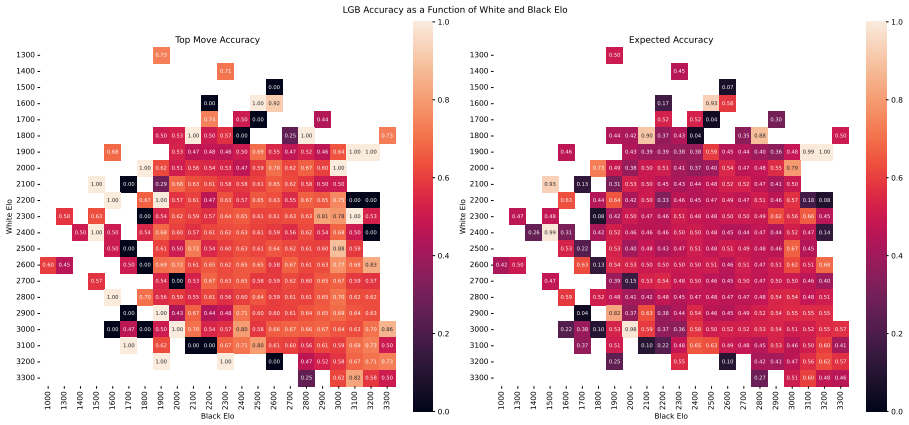
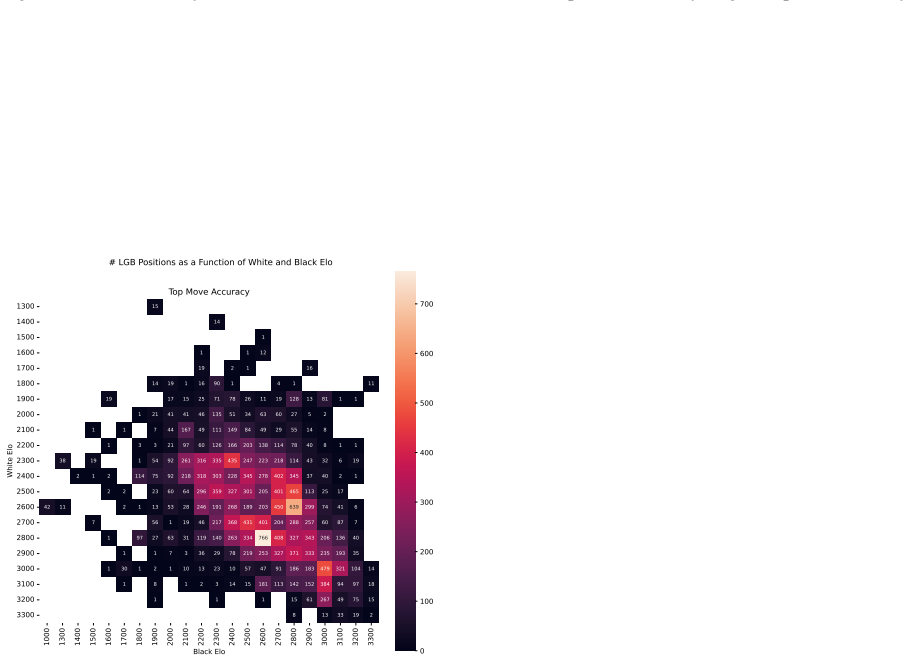
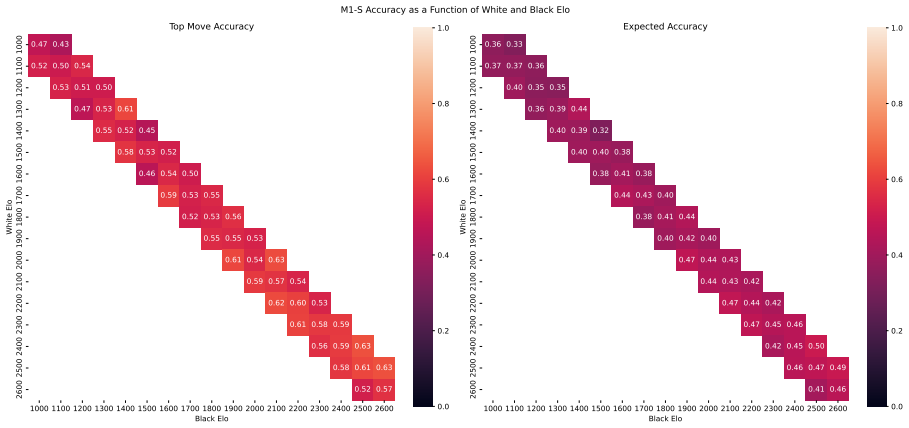
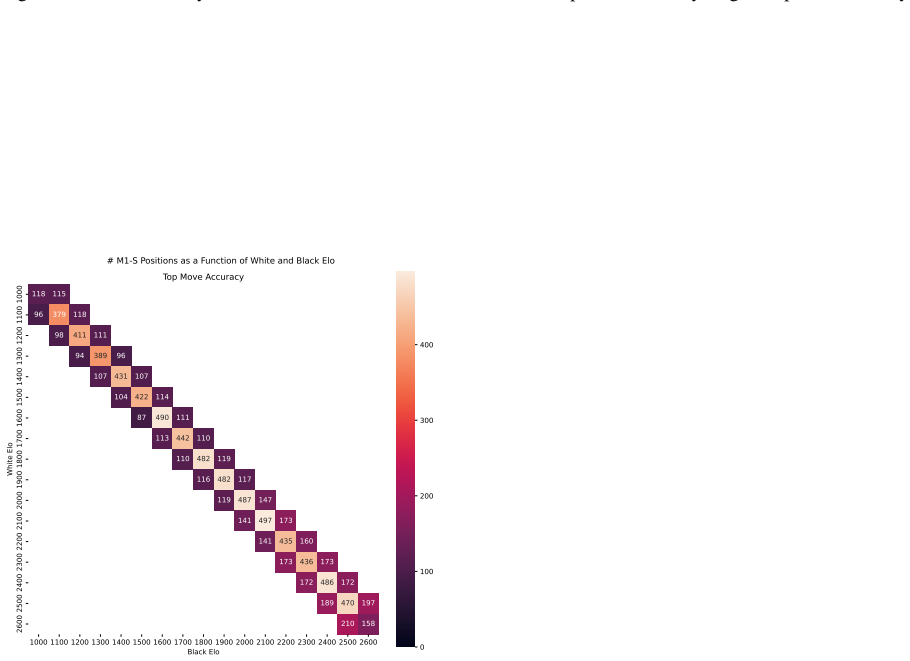
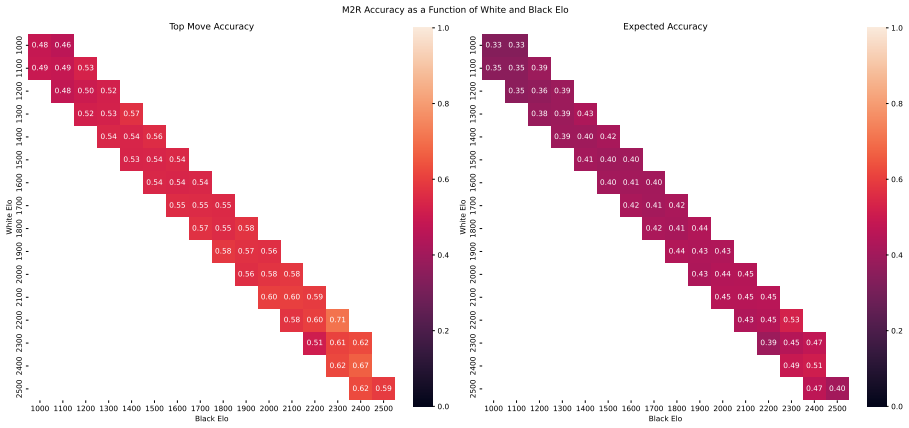
Zukertort Opening: You are an anonymous white player rated {elo}, playing against an anonymous black player rated {elo}, using the Zukertort Opening N Performance by Elo Range Figures 31 and 33 show benchmark performance as a function of White and Black Elo. Both top-move and expected accuracy generally increase with player Elo, reflecting the greater con...
-
[48]
Qb3 Qc7 27
Bxd5 exd5 26. Qb3 Qc7 27. Rxd5 Rfd8
-
[49]
h3 Rd2 30
Rxd8+ Rxd8 29. h3 Rd2 30. Qe3 Qd8
-
[50]
Rxd1 Qxd1+ 33
Qxa7 Rd1 32. Rxd1 Qxd1+ 33. Kh2 Qd6+ 34. g3 Qf6 35. Qe3 Qd6 36. Qc5 Qd2
-
[51]
300+0." Playing with the white pieces was a player using the username
a5 Kg7 38. Kg2 Kf6 39. Qb6+ Kg7 40. Qxb7 h5 41. a6 The game in question was a rated blitz chess match hosted on the online chess platform Lichess.org on January 1, 2023. The match featured a rapid time control of five minutes with no additional time per move, denoted as "300+0." Playing with the white pieces was a player using the username "Talca" who hel...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.