Self-Consistency via Marginal Sharpening
Pith reviewed 2026-06-29 14:20 UTC · model grok-4.3
The pith
Shifting the sampling target to the sharpened answer marginal improves language model reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that self-consistency can be realized at inference time by approximately sampling from the sharpened answer marginal using a purely autoregressive parallel procedure, which outperforms standard power sampling on math and coding benchmarks while being orders of magnitude faster.
What carries the argument
The sharpened answer marginal approximated via a purely autoregressive parallel sampling algorithm.
If this is right
- Self-consistency becomes an inference-time objective rather than a post-hoc step.
- The method produces stronger performance on mathematics and coding benchmarks than power sampling.
- Sampling is orders of magnitude faster than standard power sampling.
- Reasoning traces are de-emphasized in favor of answer support across paths.
Where Pith is reading between the lines
- This framing may extend to other tasks where the same final output can arise from multiple generation sequences.
- Future work could explore whether training objectives should also target marginals over answers.
- The speed gain allows allocating more compute to inference without proportional time increases.
Load-bearing premise
The premise that the answer marginal is the correct object to sharpen for eliciting reasoning abilities, rather than the joint distribution over traces and answers.
What would settle it
Measuring the empirical distribution of answers from the algorithm against the true sharpened marginal and finding a mismatch, or observing that benchmark gains vanish when the approximation is replaced by exact marginal sampling.
Figures

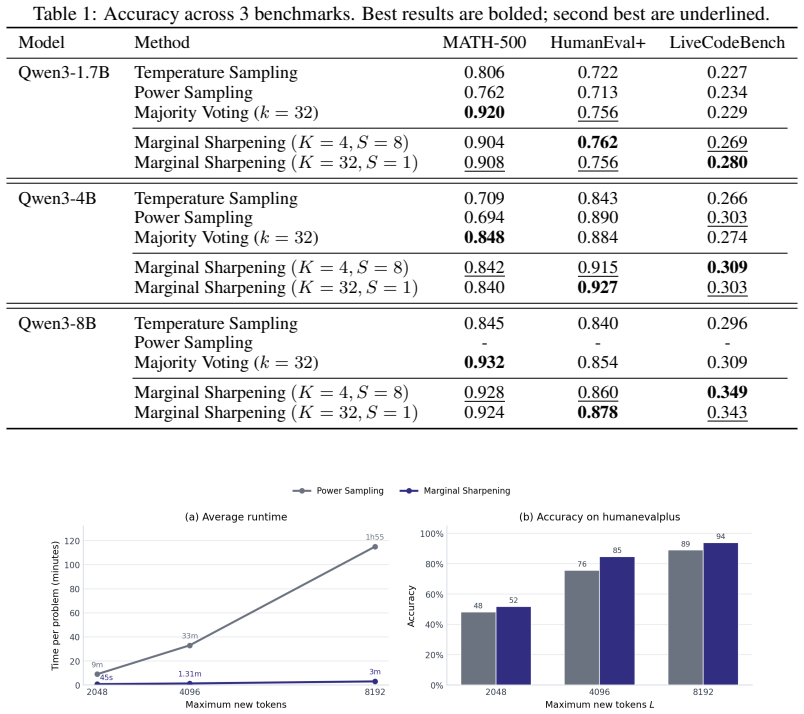
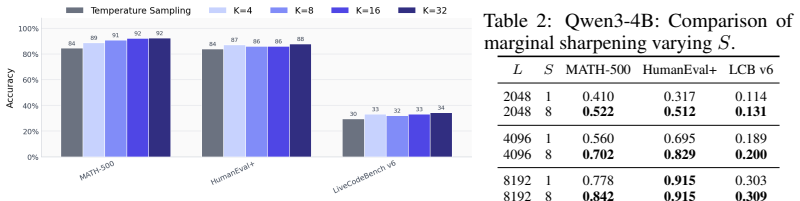
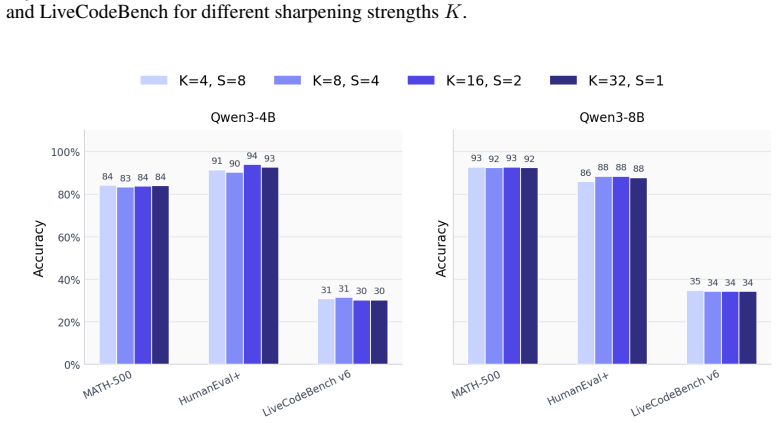
read the original abstract
Inference-time sampling can elicit strong reasoning abilities from language models without additional training. Existing power-sampling methods do so by sharpening the distribution over full generated outputs, favoring completions that are individually likely under the model. We argue that this is the wrong object to target for reasoning: a completion entangles a reasoning trace with a final answer, whereas what matters is whether an answer is supported by many plausible reasoning paths. We therefore shift the target from the full-output distribution to the sharpened answer marginal, making self-consistency an inference-time objective rather than a post-hoc voting criterion. Surprisingly, this marginal target admits an efficient approximation: we propose a simple, purely autoregressive parallel sampling algorithm that approximately samples from the sharpened answer marginal, eliciting stronger performance than standard power sampling on mathematics and coding benchmarks while being orders of magnitude faster.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that power sampling on full model outputs is the wrong target for eliciting reasoning in language models, because outputs entangle traces with answers; instead, it proposes targeting a sharpened marginal distribution over answers alone as an inference-time objective. It introduces a simple autoregressive parallel sampling procedure claimed to approximate samples from this sharpened answer marginal, and reports that the method outperforms standard power sampling on mathematics and coding benchmarks while running orders of magnitude faster.
Significance. If the approximation is sufficiently accurate and the reported gains are robust, the work offers a more principled and computationally efficient way to operationalize self-consistency at inference time. The purely autoregressive design and claimed speed advantage could make marginal sharpening practical for larger models or longer generations where full-output sharpening becomes prohibitive.
major comments (2)
- [§3] §3 (algorithm description): the claim that the parallel autoregressive procedure 'approximately samples from the sharpened answer marginal' is load-bearing for the central performance argument, yet the manuscript supplies neither a derivation of the approximation nor an error analysis or convergence argument relating the procedure to the target marginal; without this, it is unclear whether observed gains arise from marginal sharpening or from incidental properties of the sampling schedule.
- [§4] §4 (experiments): the comparison to power sampling does not isolate the effect of marginal sharpening from other algorithmic differences (e.g., parallelism, temperature schedule, or number of samples); an ablation that holds the number of forward passes fixed while varying only the marginal vs. joint target would be required to substantiate the claim that the marginal objective itself drives the improvement.
minor comments (2)
- [§2] Notation for the sharpened marginal p(a) vs. the joint p(trace, a) is introduced without an explicit equation relating the two; adding a short definitional equation early in §2 would improve clarity.
- [Figure 1] Figure 1 caption does not state the exact temperature or sharpening parameter values used for the visualized trajectories, making it hard to reproduce the qualitative comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for strengthening the presentation and empirical support. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [§3] §3 (algorithm description): the claim that the parallel autoregressive procedure 'approximately samples from the sharpened answer marginal' is load-bearing for the central performance argument, yet the manuscript supplies neither a derivation of the approximation nor an error analysis or convergence argument relating the procedure to the target marginal; without this, it is unclear whether observed gains arise from marginal sharpening or from incidental properties of the sampling schedule.
Authors: We agree that a formal derivation and error analysis would strengthen the central claim. The current manuscript presents the procedure as an efficient approximation without a detailed proof relating the parallel autoregressive schedule to the target sharpened marginal. In the revision we will add a derivation in §3 that shows how the procedure iteratively updates the answer marginal under a sharpening operator while preserving the autoregressive factorization, along with a first-order error bound based on the total variation distance between the joint and marginal distributions. revision: yes
-
Referee: [§4] §4 (experiments): the comparison to power sampling does not isolate the effect of marginal sharpening from other algorithmic differences (e.g., parallelism, temperature schedule, or number of samples); an ablation that holds the number of forward passes fixed while varying only the marginal vs. joint target would be required to substantiate the claim that the marginal objective itself drives the improvement.
Authors: The referee correctly identifies that the existing experiments do not fully isolate the marginal objective from confounding factors such as parallelism and sampling schedule. We will add a controlled ablation in §4 that fixes the total number of model forward passes and directly compares (i) standard power sampling on full outputs versus (ii) the proposed marginal-sharpening procedure under identical computational budgets. This will provide clearer evidence that performance differences are attributable to the choice of target distribution. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's core move is a conceptual re-targeting from the joint distribution over traces+answers to the sharpened answer marginal, followed by the direct proposal of a new autoregressive parallel sampling procedure as an approximation to that marginal. No equations, fitted parameters, or self-citations are visible in the supplied text that would make any claimed result equivalent to its own inputs by construction. The argument is therefore self-contained as an algorithmic suggestion rather than a closed definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
2022
-
[2]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 22199–22213. Curran Associates, Inc., 2022
2022
-
[3]
STar: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. STar: Bootstrapping reasoning with reasoning. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022
2022
-
[4]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Openai o1 system card, 2026
OpenAI. Openai o1 system card, 2026
2026
-
[7]
Deductive beam search: Decoding deducible rationale for chain-of-thought reasoning
Tinghui Zhu, Kai Zhang, Jian Xie, and Yu Su. Deductive beam search: Decoding deducible rationale for chain-of-thought reasoning. InFirst Conference on Language Modeling, 2024
2024
-
[8]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2023
2023
-
[9]
Reasoning with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[11]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute op- timally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Universal self-consistency for large language models
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language models. InICML 2024 Workshop on In-Context Learning, 2024
2024
-
[14]
Integrative decoding: Improving factuality via implicit self-consistency
Yi Cheng, Xiao Liang, Yeyun Gong, Wen Xiao, Song Wang, Yuji Zhang, Wenjun Hou, Kaishuai Xu, Wenge Liu, Wenjie Li, Jian Jiao, Qi Chen, Peng CHENG, and Wayne Xiong. Integrative decoding: Improving factuality via implicit self-consistency. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[15]
Reasoning with Sampling: Your Base Model is Smarter Than You Think
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Seyedarmin Azizi, Erfan Baghaei Potraghloo, Minoo Ahmadi, Souvik Kundu, and Massoud Pedram. Power-SMC: Low-latency sequence-level power sampling for training-free LLM reasoning.arXiv preprint arXiv:2602.10273, 2026
-
[17]
Xiaotong Ji, Rasul Tutunov, Matthieu Zimmer, and Haitham Bou Ammar. Scalable power sampling: Unlocking efficient, training-free reasoning for LLMs via distribution sharpening. arXiv preprint arXiv:2601.21590, 2026
-
[18]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
SmolLM3: smol, multilingual, long-context reasoner.https://huggingface.co/blog/smollm3, 2025
Elie Bakouch, Carlos Miguel Patiño, Anton Lozhkov, et al. SmolLM3: smol, multilingual, long-context reasoner.https://huggingface.co/blog/smollm3, 2025
2025
-
[20]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi Team, Angang Du, Bofei Gao, et al. Kimi k1.5: Scaling reinforcement learning with LLMs.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
Math-Verify: Math verification library
Hynek Kydlí ˇcek. Math-Verify: Math verification library. https://github.com/ huggingface/Math-Verify, 2025. Software
2025
-
[23]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[24]
Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[25]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contam- ination free evaluation of large language models for code.arXiv preprint arXiv:2403.07974, 2024. 11 A Broader impact Marginal sharpening improves the inference-time reasoning ability of ex...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.