Do LLMs Build World Models From Text? A Multilingual Diagnostic of Spatial Reasoning
Pith reviewed 2026-06-29 11:59 UTC · model grok-4.3
The pith
LLMs fail to retain even half their atomic spatial accuracy once tasks require viewpoint reasoning from text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
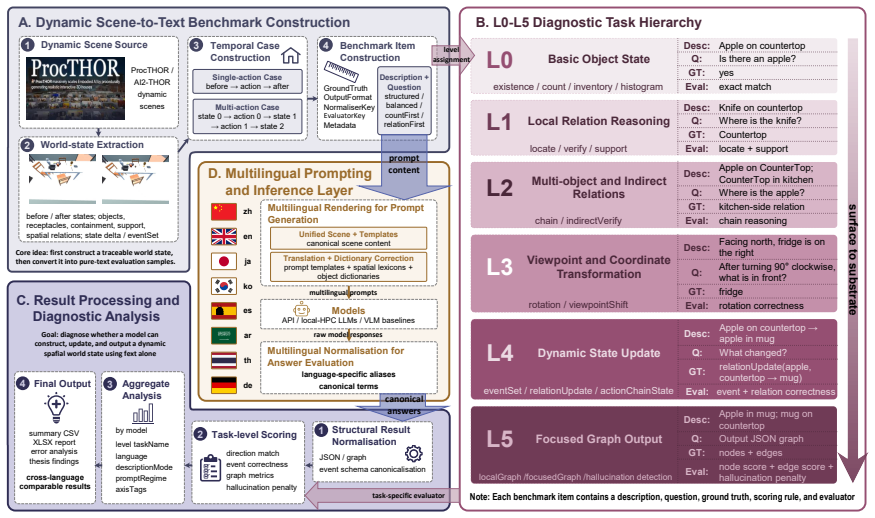
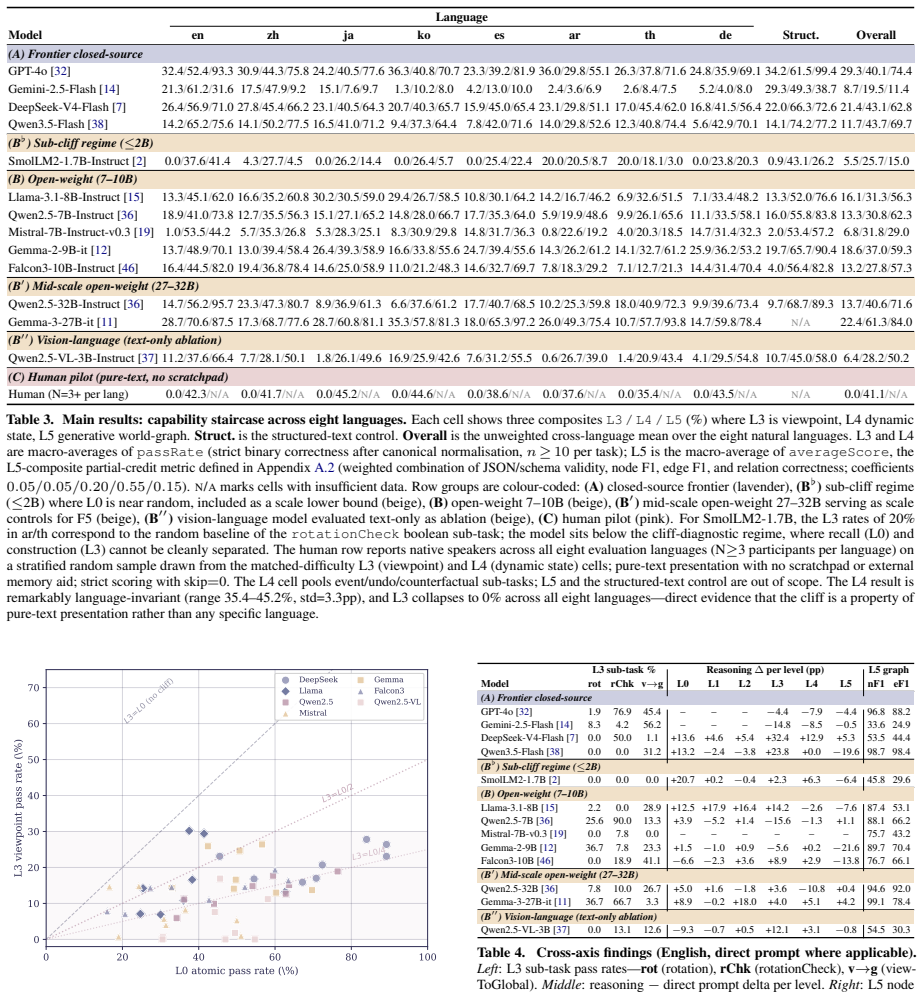
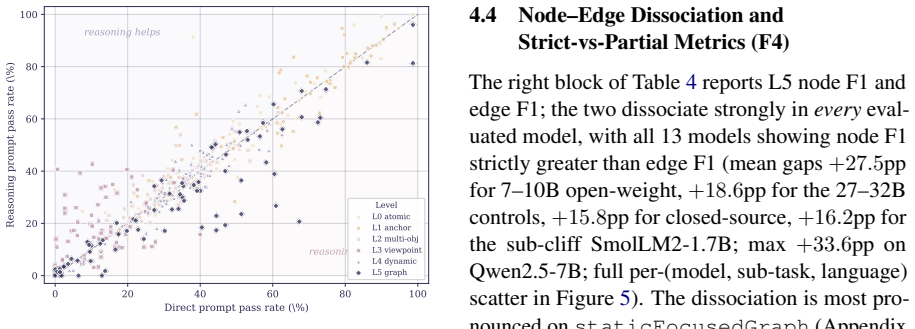
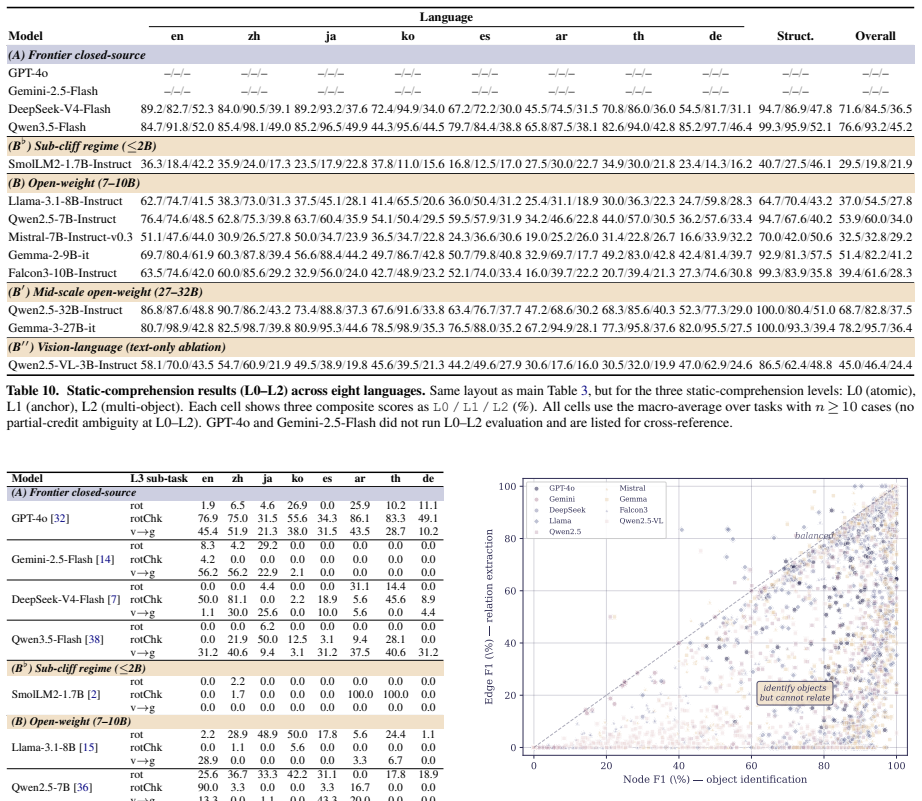
No evaluated LLM retains even half of its L0 performance on viewpoint reasoning tasks once baseline atomic accuracy exceeds 40 percent. The L3 cliff appears uniformly across thirteen models, eight typologically diverse languages, multiple scales, and prompting strategies. Human evaluators under the same pure-text protocol reproduce the identical failure pattern, which the authors attribute to inherent constraints of text-only working memory rather than any model-specific limitation.
What carries the argument
The MentalMap benchmark, built from 100 ProcTHOR scenes and organized into a six-level hierarchy (L0 atomic facts through L5 generative world-graph construction) plus four diagnostic axes for frame of reference, reading-direction bias, reasoning effort, and hallucination.
If this is right
- Viewpoint reasoning forms a distinct bottleneck separate from atomic spatial fact retrieval.
- The performance cliff cannot be overcome by increasing model scale or changing prompting strategies.
- Structured-output failures and hallucination rates vary by model family while the L3 cliff remains constant.
- Pure-text spatial reasoning must be treated as a multi-axis problem involving reference frames and memory load.
Where Pith is reading between the lines
- Multimodal inputs that supply visual structure could bypass the observed text-only memory limit.
- Analogous cliffs may exist in other domains that require maintaining consistent internal state across transformations, such as causal or temporal reasoning.
- Testing scratchpad or external memory augmentation on the same tasks would directly measure whether the bottleneck is removable.
Load-bearing premise
The six-level hierarchy and thirty-nine task families isolate genuine progressive spatial world-modeling skills without confounds from language structure or task design.
What would settle it
Provide models with an external coordinate grid or diagram of each scene and check whether viewpoint-reasoning accuracy then rises above half the atomic baseline; sustained failure would support the text-memory claim while improvement would falsify it.
Figures

read the original abstract
Whether large language models (LLMs) construct internal spatial world models from pure-text descriptions remains contested, and whether such capabilities transfer across languages has not been systematically studied. We introduce MentalMap, a multilingual diagnostic benchmark with a six-level capability hierarchy (L0-L5) spanning atomic spatial facts to generative world-graph construction, together with four diagnostic axes probing frame of reference, reading-direction bias, reasoning-effort allocation, and hallucination. MentalMap is built from 100 ProcTHOR household scenes, covers eight typologically diverse languages plus a structured-text control, and contains 39 task families across 1,950 evaluation cells. Evaluating thirteen LLMs across scales and model families, we identify a universal L3 reasoning cliff: no model retains even half of its L0 performance on viewpoint reasoning once baseline atomic accuracy exceeds 40%. The cliff persists across languages, scales, and prompting strategies, while structured-output failures and reasoning patterns vary substantially across models. Human evaluation under the identical pure-text protocol reproduces the same failure pattern, suggesting that the bottleneck arises from text-only working memory constraints rather than being specific to current LLM architectures. Our findings reframe pure-text spatial reasoning as a multi-axis world-modeling problem and motivate multimodal and scratchpad-augmented reasoning as future directions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the MentalMap benchmark, a multilingual diagnostic for spatial reasoning in LLMs featuring a six-level hierarchy (L0-L5) from atomic facts to world-graph construction, based on 100 ProcTHOR scenes across eight languages. Evaluating thirteen LLMs, it reports a universal L3 cliff in viewpoint reasoning: no model retains half its L0 performance once atomic accuracy exceeds 40%, persisting across languages, scales, and prompts. Human evaluations replicate the pattern, attributing it to text-only working memory constraints. Diagnostic axes cover frame of reference, reading bias, effort allocation, and hallucination.
Significance. If the L3 cliff is shown to reflect absent world-model construction rather than task-length confounds, the result would be significant for LLM reasoning research by reframing pure-text spatial capabilities as limited by working memory and motivating multimodal or scratchpad methods. The multilingual scope, structured-text control, 39 task families, and human replication under identical protocol are clear strengths that add diagnostic value beyond monolingual English benchmarks.
major comments (2)
- [Abstract] Abstract: the central claim that 'no model retains even half of its L0 performance on viewpoint reasoning once baseline atomic accuracy exceeds 40%' supplies no information on statistical tests, error bars, data exclusion rules, or how the 40% threshold and half-performance criterion were chosen, leaving the universality of the L3 cliff difficult to evaluate.
- [Abstract / hierarchy description] Abstract / hierarchy description: L3 viewpoint-reasoning tasks embed longer chains of relations and more tokens than L0 atomic facts. The persistence across prompting strategies is noted but does not substitute for an explicit ablation that holds chain length and prompt token count fixed while varying only the spatial integration demand; without it the cliff risks being explained by standard transformer working-memory limits rather than missing world-model construction.
minor comments (2)
- Clarify the exact distribution of the 1,950 evaluation cells across the 39 task families, languages, and the four diagnostic axes.
- The abstract could list the specific prompting strategies tested so that the 'persists across prompting strategies' claim can be directly replicated.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our results on the L3 cliff. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'no model retains even half of its L0 performance on viewpoint reasoning once baseline atomic accuracy exceeds 40%' supplies no information on statistical tests, error bars, data exclusion rules, or how the 40% threshold and half-performance criterion were chosen, leaving the universality of the L3 cliff difficult to evaluate.
Authors: We agree the abstract would be strengthened by these details. Error bars appear in all main figures, statistical tests are reported in Section 4.3 and Appendix B, and data exclusion (primarily invalid parses) follows the protocol in Section 3.2. The 40% threshold marks the observed inflection where retention falls below half of L0 across models; the half-performance criterion is a direct relative measure. We will revise the abstract to reference these elements concisely. revision: yes
-
Referee: [Abstract / hierarchy description] Abstract / hierarchy description: L3 viewpoint-reasoning tasks embed longer chains of relations and more tokens than L0 atomic facts. The persistence across prompting strategies is noted but does not substitute for an explicit ablation that holds chain length and prompt token count fixed while varying only the spatial integration demand; without it the cliff risks being explained by standard transformer working-memory limits rather than missing world-model construction.
Authors: This concern is well-taken. While the cliff persists across prompting variants that alter length and structure, and human evaluations under the same pure-text protocol show the identical pattern, we did not include an ablation that holds chain length and token count exactly fixed while isolating spatial integration. We will add a dedicated discussion of this potential confound in the revised manuscript, framing the result as consistent with text-only working-memory limits and outlining how future synthetic-task experiments could further isolate the factors. revision: partial
Circularity Check
Empirical benchmark study with no derivation chain or self-referential reductions
full rationale
The paper introduces MentalMap as a new multilingual benchmark with a six-level hierarchy and reports empirical performance results across 13 LLMs on 39 task families. All central claims (universal L3 cliff once L0 exceeds 40%, persistence across languages and prompts, human-model alignment) are direct observational outcomes from evaluation cells rather than predictions derived from equations, fitted parameters, or self-citations. No load-bearing step reduces by construction to its inputs; the hierarchy functions as a descriptive taxonomy for task design, not a self-defining loop. The work is self-contained against external benchmarks and contains no mathematical derivations that could exhibit circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Loubna Ben Allal, Anton Lozhkov, Elie Bakouch, Cyril Blakeney, Guilherme Penedo, Lewis Pel- letier, Leandro von Werra, and Thomas Wolf. 2025. Smollm2: When smol goes big–data-centric train- ing of a small language model.arXiv preprint arXiv:2502.02737
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
-
[4]
Neil Burgess. 2006. Spatial memory: How egocen- tric and allocentric combine.Trends in Cognitive Sciences, 10(12):551–557
2006
- [5]
-
[6]
Nelson Cowan. 2001. The magical number 4 in short- term memory: A reconsideration of mental storage capacity.Behavioral and Brain Sciences, 24(1):87– 114
2001
-
[7]
DeepSeek-AI. 2025. DeepSeek-R1: Incentiviz- ing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Jordi Salvador, Kiana Ehsani, Winson Han, Eric Kolve, Ali Farhadi, Aniruddha Kembhavi, and Roozbeh Mottaghi. 2022. ProcTHOR: Large-scale embodied AI using procedural generation. InAd- vances in Neural Information Processing Systems (NeurIPS). Outstanding Paper Award
2022
- [9]
-
[10]
Mike Farmer, Abhinav Kochar, and Yugyung Lee
-
[11]
The α-law of observable belief revision in large language model inference.arXiv preprint arXiv:2603.19262. University of Missouri–Kansas City
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Gemma Team. 2025. Gemma 3 technical report. https://goo.gle/Gemma3Report
2025
-
[13]
Gemma Team, Google DeepMind. 2024. Gemma 2: Improving open language models at a practical size. arXiv:2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Saibo Geng, Martin Josifoski, Maxime Peyrard, and Robert West. 2023. Grammar-constrained decoding for structured NLP tasks without finetuning. InPro- ceedings of the 2023 Conference on Empirical Meth- ods in Natural Language Processing. Association for Computational Linguistics
2023
-
[15]
Google. 2025. Gemini 2.5 Pro
2025
-
[16]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, and 1 others. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Zhongbin Guo, Zhen Yang, Yushan Li, and 1 others
-
[18]
Beijing Institute of Tech- nology
Can LLMs see without pixels? benchmarking spatial intelligence from textual descriptions.arXiv preprint arXiv:2601.03590. Beijing Institute of Tech- nology
-
[19]
Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. 2023. Reasoning with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing. Association for Computational Linguistics
2023
-
[20]
Mengkang Hu, Tianxing Chen, Yifan Zou, Yuheng Lei, Qiguang Chen, Ming Li, Hongyuan Zhang, Wenqi Lu, and Ping Luo. 2025. TEXT2WORLD: Benchmarking large language models for symbolic world model generation. InFindings of the Associa- tion for Computational Linguistics: ACL
2025
-
[21]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, and 1 others. 2023. Mistral 7b.arXiv preprint arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [22]
-
[23]
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Daniel Gor- don, Yuke Zhu, Abhinav Gupta, and Ali Farhadi
-
[24]
AI2-THOR: An interactive 3D environment for visual AI.Preprint, arXiv:1712.05474
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Maria Kozhevnikov and Mary Hegarty. 2001. A dis- sociation between object manipulation spatial ability and spatial orientation ability.Memory & Cognition, 29(5):745–756
2001
-
[26]
Gon- zalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gon- zalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serv- ing with PagedAttention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP)
2023
-
[27]
Levinson
Stephen C. Levinson. 2003.Space in Language and Cognition: Explorations in Cognitive Diversity. Lan- guage Culture and Cognition. Cambridge University Press
2003
-
[28]
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li Erran Li, Ruohan Zhang, Weiyu Liu, Percy Liang, Li Fei-Fei, Jiayuan Mao, and Jiajun Wu. 2024. Embodied agent interface: Benchmarking LLMs for embodied decision making. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmark...
2024
-
[29]
Weijiang Li and 1 others. 2026. Do LLMs build spa- tial world models? evidence from grid-world maze tasks.arXiv preprint arXiv:2604.10690
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Mehta, and Yiding Wu
Yuxi Li, Shuyuan Niu, Sze Chai Wong, Mo Yu, San- jeev J. Mehta, and Yiding Wu. 2024. Do large lan- guage models build internal world representations? probing through the lens of state abstraction. InPro- ceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing. Association for Computational Linguistics. 10
2024
-
[31]
Chih-Ting Liao, Xi Xiao, Chunlei Meng, Zhangquan Chen, Yitong Qiao, Weilin Zhou, Tianyang Wang, Xu Zheng, and Xin Cao. 2026. Spamem: Benchmarking dynamic spatial reasoning via perception-memory integration in embodied environments.arXiv preprint arXiv:2604.22409
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Asifa Majid, Melissa Bowerman, Sotaro Kita, Daniel B. M. Haun, and Stephen C. Levinson. 2004. Can language restructure cognition? the case for space.Trends in Cognitive Sciences, 8(3):108–114
2004
- [33]
-
[34]
Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. 2021. Show your work: Scratchpads for in- termediate computation with language models.arXiv preprint arXiv:2112.00114
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[35]
OpenAI. 2024. GPT-4o. https://openai. com/index/hello-gpt-4o/
2024
- [36]
-
[37]
Eric Pederson, Eve Danziger, David Wilkins, Stephen Levinson, Sotaro Kita, and Gunter Senft
-
[38]
Semantic typology and spatial conceptualiza- tion.Language, 74(3):557–589
- [39]
-
[40]
Qwen Team. 2024. Qwen2.5: A party of foundation models
2024
-
[41]
Qwen Team. 2025. Qwen2.5-vl: Vision-language models. arXiv:2502.13923
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Qwen Team. 2025. Qwen3.5-flash. API release
2025
-
[43]
Md Imbesat Rizvi, Xiaodan Zhu, and Iryna Gurevych. 2024. SpaRC and SpaRP: Spatial rea- soning characterization and path generation for un- derstanding spatial reasoning capability of large lan- guage models. InProceedings of the 62nd Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 4750–4767. Association for...
2024
-
[44]
Fedor Rodionov, Abdelrahman Eldesokey, Michael Birsak, John Femiani, Bernard Ghanem, and Peter Wonka. 2026. FloorplanQA: A benchmark for spatial reasoning in LLMs using structured representations. arXiv preprint arXiv:2507.07644. KAUST; v3 last revised 30 Jan 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Shepard and Jacqueline Metzler
Roger N. Shepard and Jacqueline Metzler. 1971. Mental rotation of three-dimensional objects.Sci- ence, 171(3972):701–703
1971
-
[46]
Zhengxiang Shi, Qiang Zhang, and Aldo Lipani
-
[47]
InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 36, pages 11321–11329
StepGame: A new benchmark for robust multi- hop spatial reasoning in texts. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 36, pages 11321–11329
-
[48]
2000.Toward a Cognitive Seman- tics, Volume I: Concept Structuring Systems
Leonard Talmy. 2000.Toward a Cognitive Seman- tics, Volume I: Concept Structuring Systems. MIT Press
2000
-
[49]
Manveer Singh Tamber, Forrest Sheng Bao, Chenyu Xu, Ge Luo, Suleman Kazi, Minseok Bae, Miaoran Li, Ofer Mendelevitch, Renyi Qu, and Jimmy Lin
-
[50]
InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing: Industry Track, pages 799–811
Benchmarking LLM faithfulness in RAG with evolving leaderboards. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing: Industry Track, pages 799–811. Association for Computational Linguistics
2025
-
[51]
Thora Tenbrink. 2011. Reference frames of space and time in language.Journal of Pragmatics, 43(3):704–722
2011
-
[52]
TII Falcon Team. 2025. Falcon 3: Frontier open- weight language models from tii. Technology Inno- vation Institute Technical Report
2025
-
[53]
Chen, Ashesh Rambachan, Jon Kleinberg, and Sendhil Mullainathan
Keyon Vafa, Justin Y . Chen, Ashesh Rambachan, Jon Kleinberg, and Sendhil Mullainathan. 2024. Evaluating the world model implicit in a generative model.Advances in Neural Information Processing Systems
2024
-
[54]
Jean-Baptiste Van der Henst and Walter Schaeken
-
[55]
PMCID: PMC8165199
The influence of language on spatial reasoning: Reading habits modulate the formulation of conclu- sions and the integration of premises.Frontiers in Psychology. PMCID: PMC8165199
-
[56]
Vectara. 2025. Hughes hallucination evaluation model (HHEM) leaderboard. https://github.com/vectara/ hallucination-leaderboard
2025
-
[57]
Ruoyao Wang, Graham Todd, Ziang Xiao, Xingdi Yuan, Marc-Alexandre Côté, Peter Clark, and Peter Jansen. 2024. Can language models serve as text- based world simulators? InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
2024
-
[58]
Yue Wang, Qiuzhi Liu, Jiahao Xu, Tian Liang, Xingyu Chen, Zhiwei He, Linfeng Song, Dian Yu, Juntao Li, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. 2025. Thoughts are all over the place: On the underthinking of o1-like LLMs.arXiv preprint arXiv:2501.18585. Tencent AI Lab; NeurIPS 2025
-
[59]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, 11 Quoc V . Le, and Denny Zhou. 2022. Chain-of- thought prompting elicits reasoning in large language models. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), volume 35, pages 24824– 24837
2022
-
[60]
Dongil Yang, Minjin Kim, Sunghwan Kim, Beong- woo Kwak, Minjun Park, Jinseok Hong, Woontack Woo, and Jinyoung Yeo. 2025. LLM meets scene graph: Can large language models understand and generate scene graphs? a benchmark and empirical study. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Vol- ume 1: Long Papers),...
2025
-
[61]
Zheyuan Zhang, Fengyuan Hu, Jayjun Lee, Freda Shi, Parisa Kordjamshidi, Joyce Chai, and Ziqiao Ma
-
[62]
InThe Thirteenth International Con- ference on Learning Representations (ICLR)
Do vision-language models represent space and how? evaluating spatial frame of reference under ambiguities. InThe Thirteenth International Con- ference on Learning Representations (ICLR). Oral Presentation
-
[63]
answer the question
Ahmet Üstün, Viraat Aryabumi, Zheng-Xin Yong, Wei-Yin Ko, Daniel D’souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Kayid, Freddie Vargus, Phil Blunsom, Shayne Long- pre, Niklas Muennighoff, Marzieh Fadaee, Julia Kreutzer, and Sara Hooker. 2024. Aya model: An instruction finetuned open-access multilingual lan- guage model. InProc...
2024
-
[64]
The cup is tomy lefton the kitchen counter
and the operationalization of Premsri and Ko- rdjamshidi [35]. Table 8 gives an English example for each frame; the same scene is rendered in the eight evaluation languages. A.7 Hallucination Evaluator Details The L5 hallucination evaluator computes four de- composed sub-metrics: (i)node F1—token-level F1 over the set of objects in the generated graph 13 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.