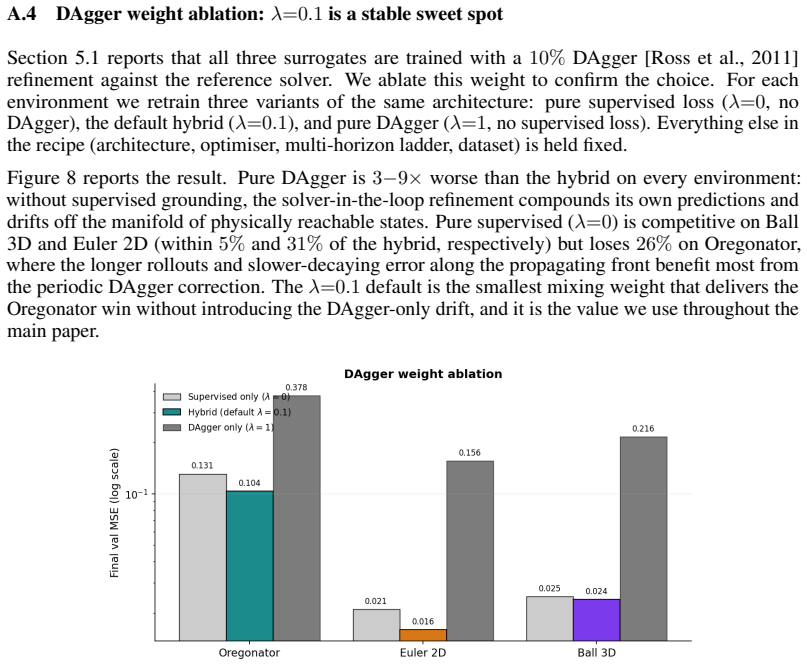
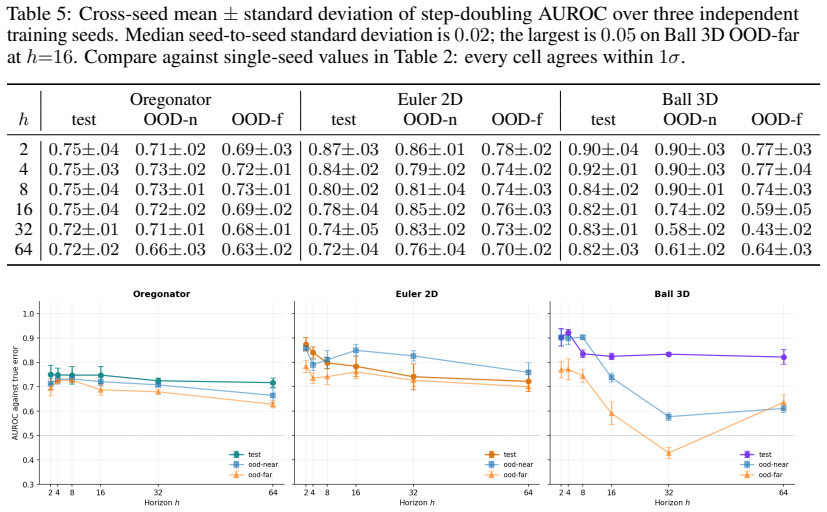
Hybrid Neural World Models
Pith reviewed 2026-06-29 13:57 UTC · model grok-4.3
The pith
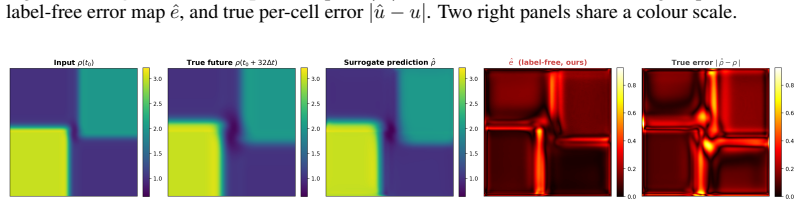
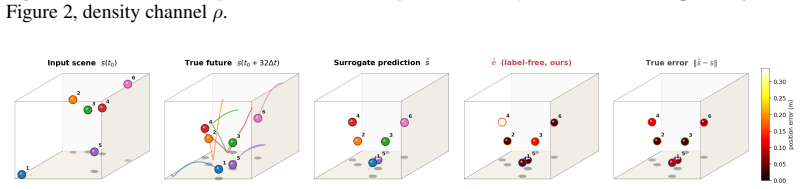
A neural surrogate encodes discontinuity locations implicitly in its per-trajectory error map recovered from forward passes alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
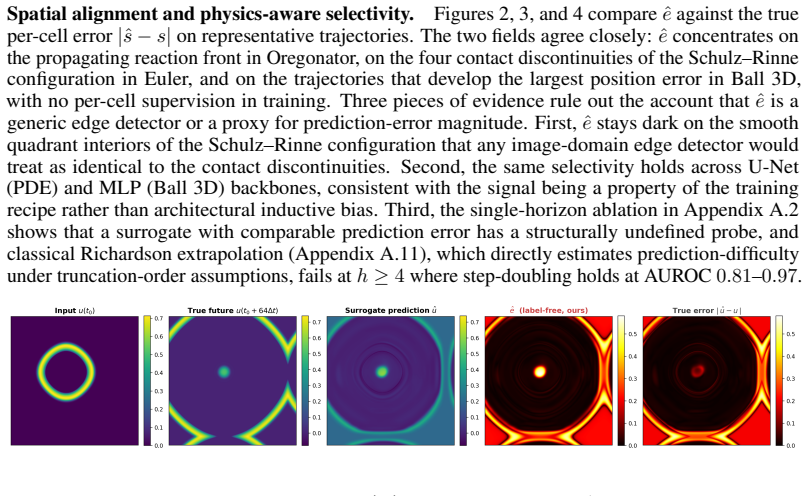
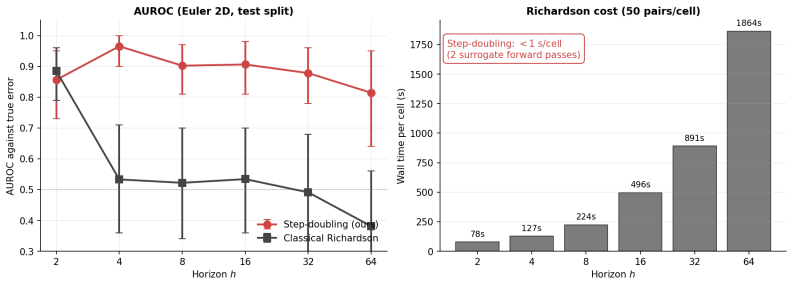
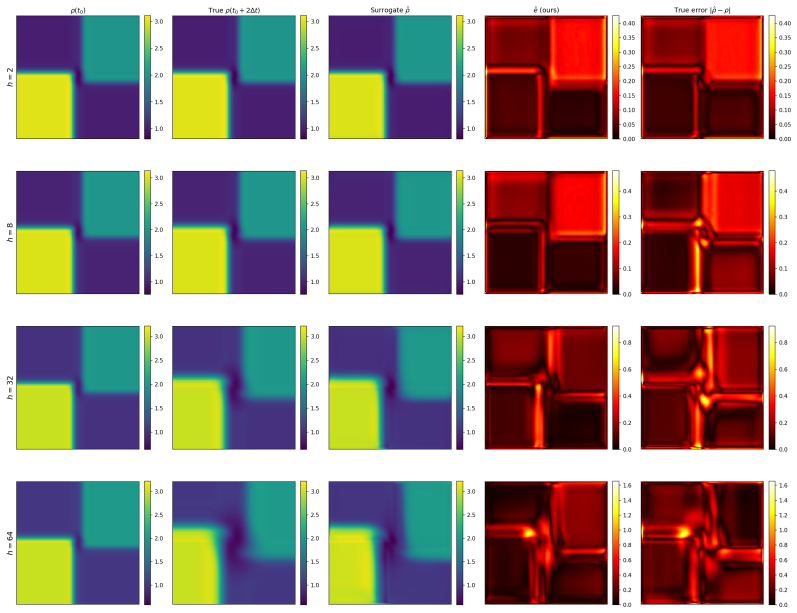
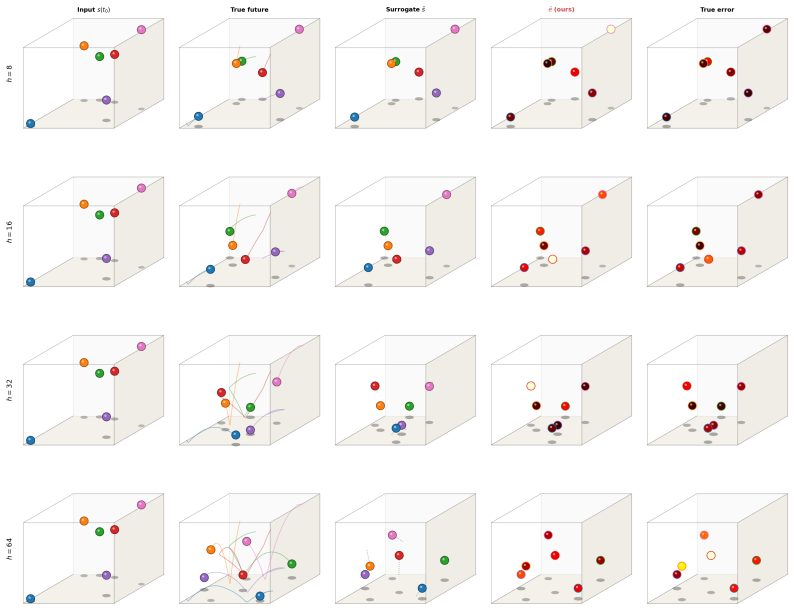
Although no part of the training data, loss function, or architecture supervises discontinuity location, the trained surrogate encodes it implicitly, recoverable from its forward passes alone as a per-trajectory error map that concentrates on shocks, fronts, and contacts, and stays small elsewhere. The map is competitive with or better than standard label-free baselines while using only a single trained network and requiring no calibration set or governing-equation knowledge.
What carries the argument
The per-trajectory error map extracted solely from the surrogate's multi-horizon forward passes.
If this is right
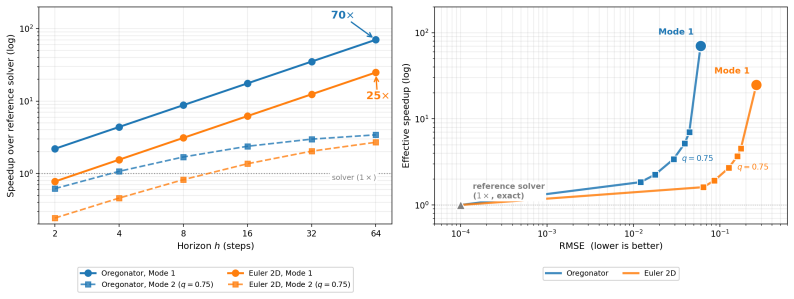
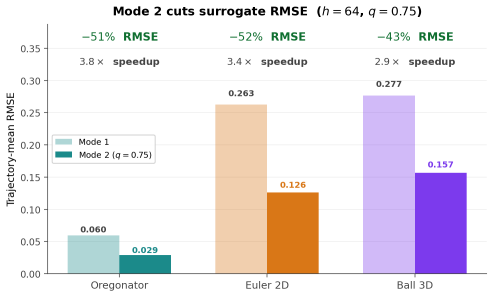
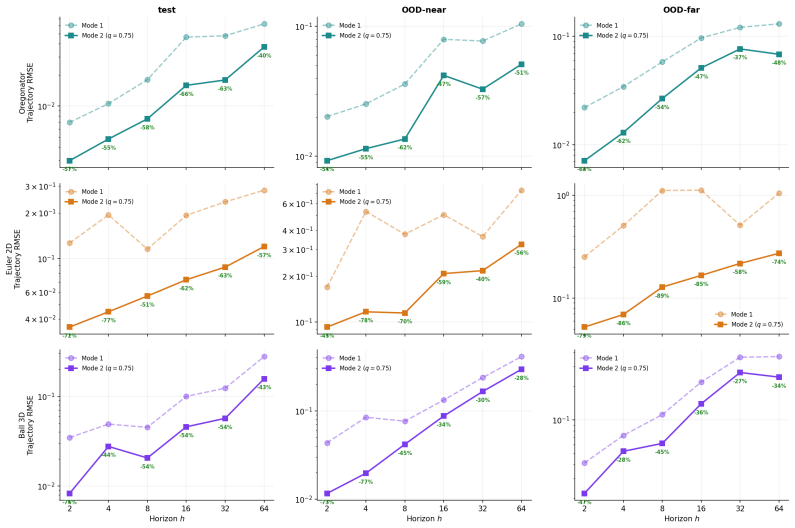
- Mode 1 delivers 26x to 72x CPU speedups against textbook solvers by running the surrogate alone.
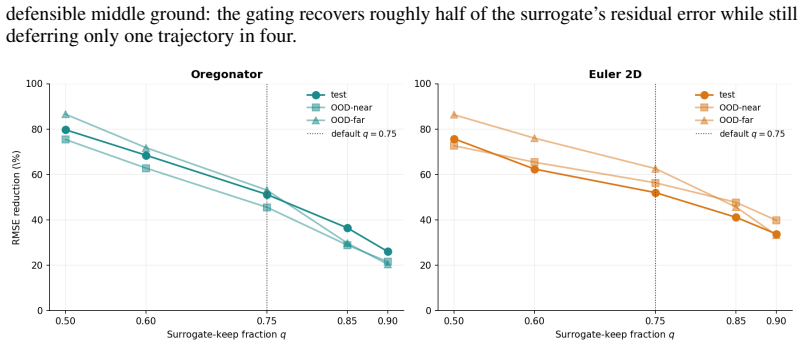
- Mode 2 uses the error map to gate fallbacks and roughly halves residual error.
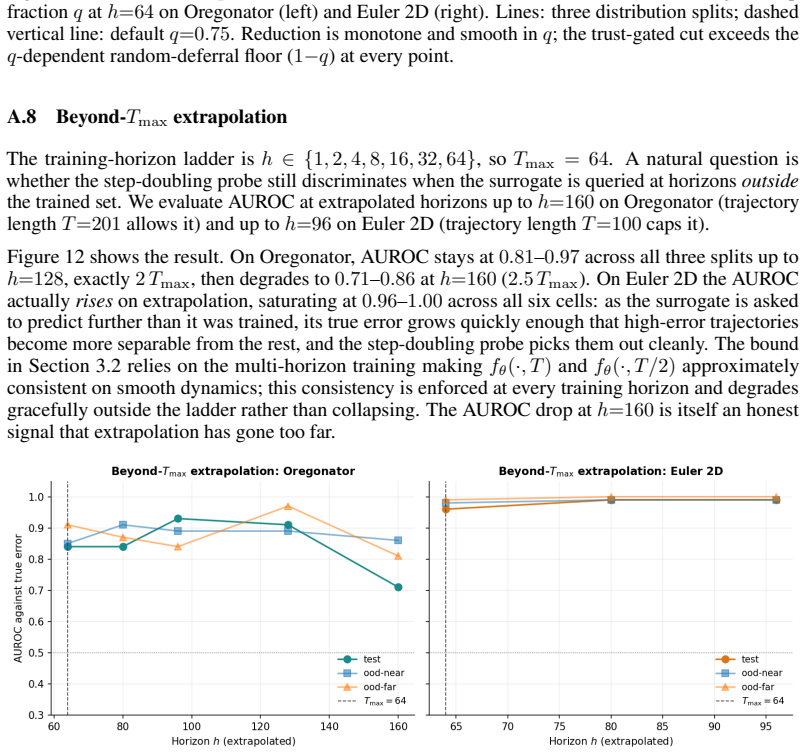
- The same recipe works without modification on reaction-diffusion, compressible Euler, and rigid-body collision problems.
- No calibration set or knowledge of the governing equations is required at deployment.
Where Pith is reading between the lines
- The implicit error map might be reused to focus additional training on high-error trajectories.
- The approach could extend to sequence models outside physics that encounter abrupt transitions.
- Direct supervision against accurate solvers may embed structural information beyond what the loss explicitly requires.
Load-bearing premise
The per-trajectory error signal extracted from the surrogate's forward passes alone will remain competitive with deep ensembles and other baselines across the tested domains without any post-training calibration.
What would settle it
A new dynamics test case where the error map does not concentrate on known discontinuities or where it performs worse than a deep ensemble baseline.
Figures


read the original abstract
Neural surrogates promise large speedups over classical solvers for physical dynamics but fail silently at sharp dynamical events such as shocks, fronts, and contact. We present hybrid neural world models for physical dynamics: a recipe for training and deploying multi-horizon surrogates in physical state space, where a single network with continuous horizon conditioning is trained with direct supervision against textbook reference solvers to predict any future state at horizon T in one forward pass. Although no part of the training data, loss function, or architecture supervises discontinuity location, the trained surrogate encodes it implicitly, recoverable from its forward passes alone as a per-trajectory error map that concentrates on shocks, fronts, and contacts, and stays small elsewhere. The map is competitive with or better than standard label-free baselines including deep ensembles, learned error heads, gradient-magnitude indicators, and locally-adaptive conformal prediction, while using only a single trained network and requiring no calibration set or governing-equation knowledge. The recipe supports two operating points. Mode 1 runs the surrogate alone for maximum throughput, with same-hardware CPU speedups of 26x to 72x against textbook solvers on the PDE environments. Mode 2 uses the error map to gate a reference-solver fallback, deferring uncertain trajectories and roughly halving the surrogate's residual error at the default operating point. The recipe applies without modification across reaction-diffusion, compressible Euler, and rigid-body collision dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes hybrid neural world models: a single neural network trained with continuous horizon conditioning to predict physical states at arbitrary horizons T in one forward pass, using direct supervision from reference solvers on reaction-diffusion, compressible Euler, and rigid-body collision problems. It claims that discontinuity locations (shocks, fronts, contacts) are implicitly encoded despite no explicit supervision, and can be recovered solely from the surrogate's forward passes as a per-trajectory error map that concentrates on discontinuities and is competitive with or superior to label-free baselines (deep ensembles, learned error heads, gradient indicators, conformal prediction) without calibration sets or governing-equation knowledge. Two modes are supported: pure surrogate inference (26-72x CPU speedups) or gated fallback to the reference solver for error reduction.
Significance. If the central claims hold with the missing procedural details supplied and quantitative validation provided, the work would be significant for scientific machine learning: it offers a single-network route to implicit discontinuity detection and hybrid reliability without ensembles or post-hoc calibration, while demonstrating cross-domain applicability and substantial speedups. The direct-supervision multi-horizon training recipe itself is a clear strength.
major comments (2)
- [Abstract] Abstract and method description: the central claim that a per-trajectory error map concentrating on discontinuities 'is recoverable from its forward passes alone' supplies no equation, algorithm, or pseudocode for map construction. This step is load-bearing for every subsequent claim (label-free status, no calibration set, competitiveness with deep ensembles and conformal prediction).
- [Results] Results section (and any associated tables/figures): no quantitative tables, ablation studies, error bars, or direct metric comparisons against the listed baselines are referenced, preventing assessment of whether the error map meets the stated performance bar.
minor comments (2)
- [Method] Notation for continuous horizon conditioning and the precise loss function against reference solvers should be stated explicitly with an equation.
- [Deployment] The two operating modes (pure surrogate vs. gated fallback) would benefit from a clear decision threshold or gating rule in pseudocode.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of hybrid neural world models. We address each major comment below and will revise the manuscript accordingly to provide the requested details and quantitative validation.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: the central claim that a per-trajectory error map concentrating on discontinuities 'is recoverable from its forward passes alone' supplies no equation, algorithm, or pseudocode for map construction. This step is load-bearing for every subsequent claim (label-free status, no calibration set, competitiveness with deep ensembles and conformal prediction).
Authors: We agree that an explicit description of the error map construction is essential. The revised manuscript will add a dedicated methods subsection containing the mathematical formulation of the per-trajectory error map (computed as the variance or discrepancy across multiple forward passes at sampled horizons), the precise algorithm for its extraction, and pseudocode. This will make the label-free nature and lack of calibration requirements fully transparent while preserving the single-network design. revision: yes
-
Referee: [Results] Results section (and any associated tables/figures): no quantitative tables, ablation studies, error bars, or direct metric comparisons against the listed baselines are referenced, preventing assessment of whether the error map meets the stated performance bar.
Authors: We acknowledge that the original submission emphasized qualitative visualizations of the error map concentrating on discontinuities. The revised version will include a new results table with quantitative comparisons against deep ensembles, learned error heads, gradient-magnitude indicators, and conformal prediction. Metrics will cover discontinuity localization (precision/recall), hybrid-mode error reduction, and wall-clock speedups, reported with error bars from multiple random seeds and ablation studies on horizon sampling. These additions will allow direct assessment of competitiveness. revision: yes
Circularity Check
No significant circularity; derivation grounded in external supervision
full rationale
The paper trains a surrogate network with direct supervision against external textbook reference solvers on physical dynamics data. The central claim is that discontinuity locations emerge implicitly in the trained model and can be recovered post-hoc as an error map from its own forward passes. No equations, loss terms, or architectural choices are shown to reduce by construction to fitted parameters defined by the method itself. No self-citations are invoked as load-bearing uniqueness theorems. The procedure is presented as empirical and externally benchmarked rather than self-referential. The unspecified extraction algorithm for the error map is a clarity issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
One Step Diffusion via Shortcut Models
Kevin Frans, Danijar Hafner, Sergey Levine, and Pieter Abbeel. One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Kusner, Stanislas Pamela, and Marc Peter Deisenroth
Vignesh Gopakumar, Ander Gray, Lorenzo Zanisi, Timothy Nunn, Daniel Giles, Matt J. Kusner, Stanislas Pamela, and Marc Peter Deisenroth. Calibrated physics-informed uncertainty quantifica- tion.arXiv preprint arXiv:2502.04406,
-
[3]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models. arXiv preprint arXiv:2509.24527,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Asif Hamid, Danish Rafiq, Shahkar Ahmad Nahvi, and Mohammad Abid Bazaz. Hierarchical deep learning-based adaptive time-stepping scheme for multiscale simulations.arXiv preprint arXiv:2311.05961,
-
[5]
A Two-Phase Deep Learning Framework for Adaptive Time-Stepping in High-Speed Flow Modeling
Jacob Helwig, Sai Sreeharsha Adavi, Xuan Zhang, Yuchao Lin, Felix S. Chim, Luke Takeshi Vizzini, Haiyang Yu, Muhammad Hasnain, Saykat Kumar Biswas, John J. Holloway, Narendra Singh, N. K. Anand, Swagnik Guhathakurta, and Shuiwang Ji. A two-phase deep learning framework for adaptive time-stepping in high-speed flow modeling.arXiv preprint arXiv:2506.07969,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Cycle consistency-based uncertainty quantification of neural networks in inverse imaging problems
Luzhe Huang, Jianing Li, Xiaofu Ding, Yijie Zhang, Hanlong Chen, and Aydogan Ozcan. Cycle consistency-based uncertainty quantification of neural networks in inverse imaging problems. arXiv preprint arXiv:2305.12852,
-
[7]
Yuying Liu, J. Nathan Kutz, and Steven L. Brunton. Hierarchical deep learning of multiscale differential equation time-steppers.arXiv preprint arXiv:2008.09768,
-
[8]
Dibyajyoti Nayak and Somdatta Goswami. TI-DeepONet: Learnable time integration for stable long-term extrapolation.arXiv preprint arXiv:2505.17341,
-
[9]
Tung Nguyen, Rohan Shah, Hritik Bansal, Troy Arcomano, Romit Maulik, Veerabhadra Kotamarthi, Ian Foster, Sandeep Madireddy, and Aditya Grover. Scaling transformer neural networks for skillful and reliable medium-range weather forecasting.arXiv preprint arXiv:2312.03876,
-
[10]
Rajyasri Roy, Dibyajyoti Nayak, and Somdatta Goswami. The best of both worlds: Hybridizing neural operators and solvers for stable long-horizon inference.arXiv preprint arXiv:2512.19643,
-
[11]
Bharat Srikishan, Daniel O’Malley, Mohamed Mehana, Nicholas Lubbers, and Nikhil Muralidhar. Model-agnostic knowledge guided correction for improved neural surrogate rollout.arXiv preprint arXiv:2503.10048,
-
[12]
smooth and predictable
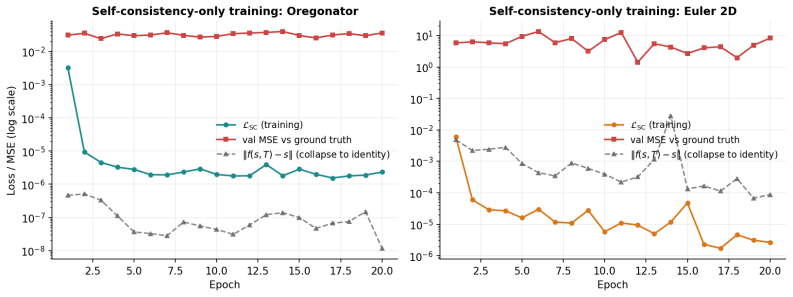
rather than with the self-consistency objective of Frans et al. [2024]. This appendix verifies the claim. We train two copies of the U-Net surrogate (Oregonator and Euler 2D, identical architecture and optimiser to the main runs) using only the self-consistency loss LSC(θ) =E (s0,T) fθ(s0, T)−f θ fθ(s0, T /2), T /2 2 2, with no ground-truth supervision. A...
2024
-
[13]
richardson-fix
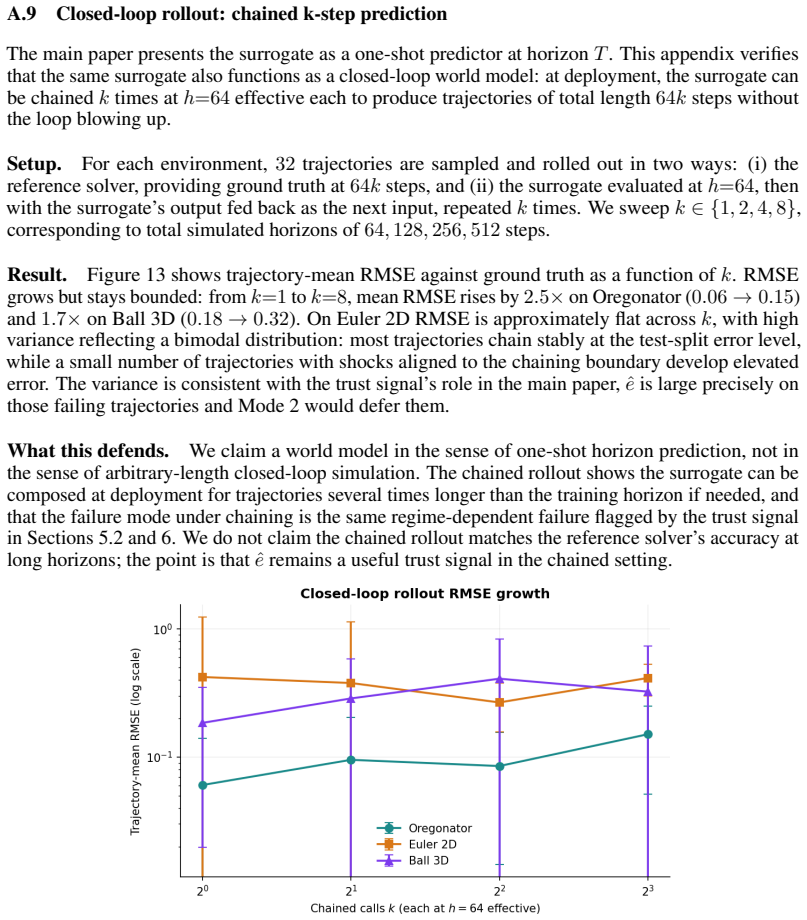
We do not claim the chained rollout matches the reference solver’s accuracy at long horizons; the point is thatˆeremains a useful trust signal in the chained setting. Figure 13:Closed-loop rollout RMSE growth.Trajectory-mean RMSE against ground truth for chained surrogate calls k∈ {1,2,4,8} , each at h=64 effective, on three environments. Error bars are o...
1980
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.