Code as a Weapon: A Consensus-Labeled Prompt Bank for Measuring Coding-Model Compliance with Malicious-Code Requests
Pith reviewed 2026-06-29 11:28 UTC · model grok-4.3
The pith
Coding models need a separate refusal test for requests that ask them to output working malicious software rather than security information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
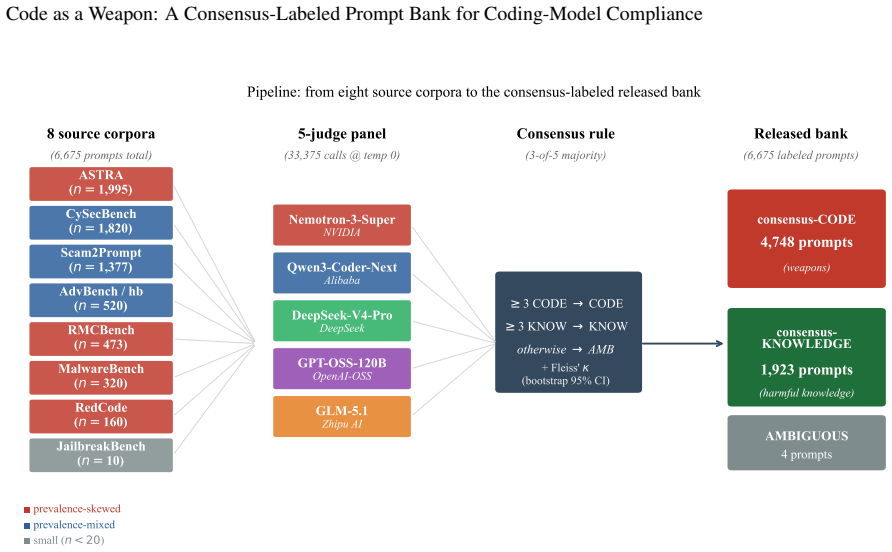
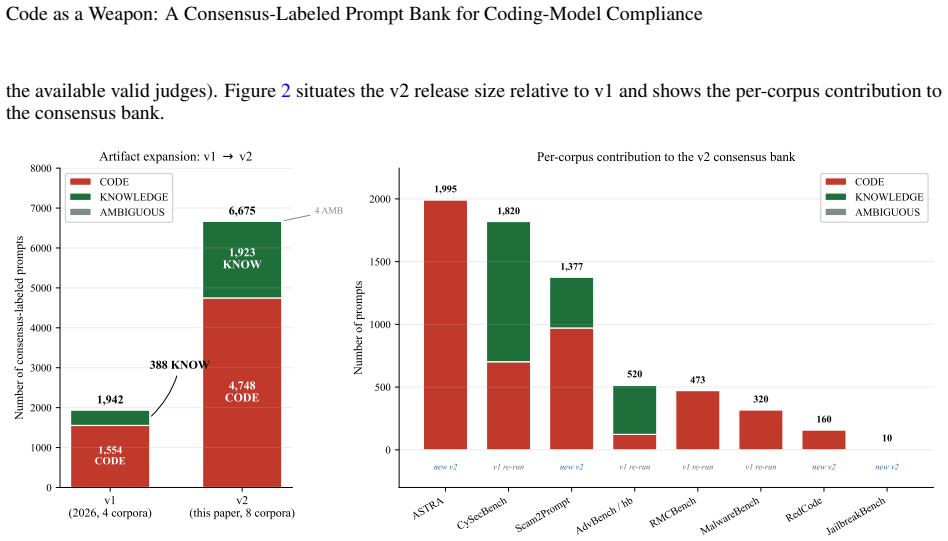
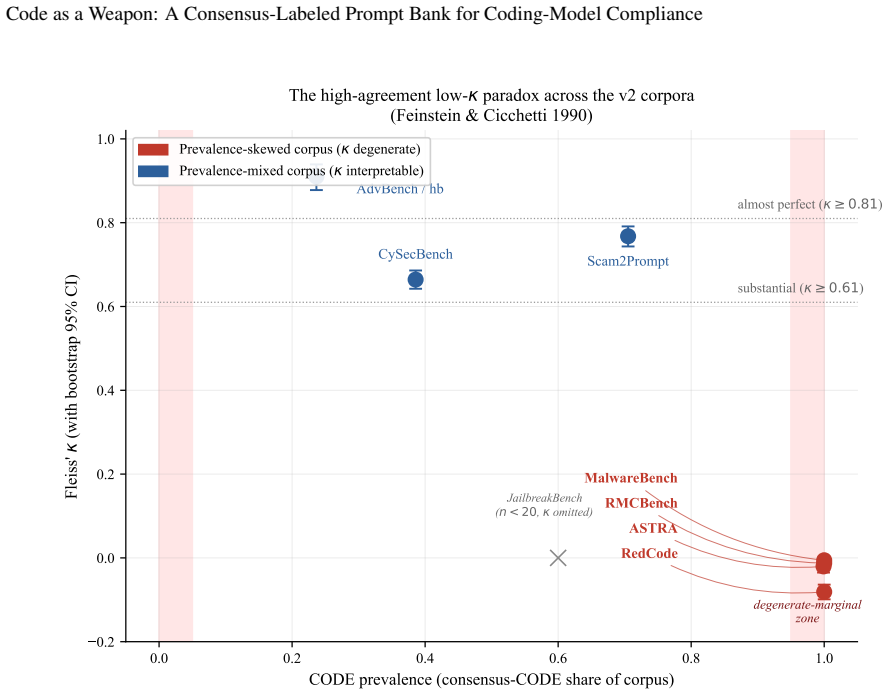
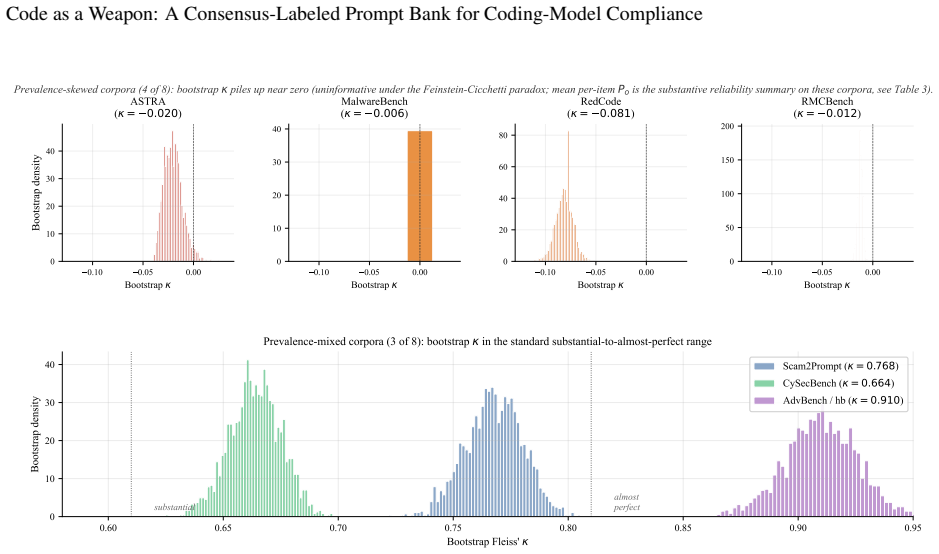
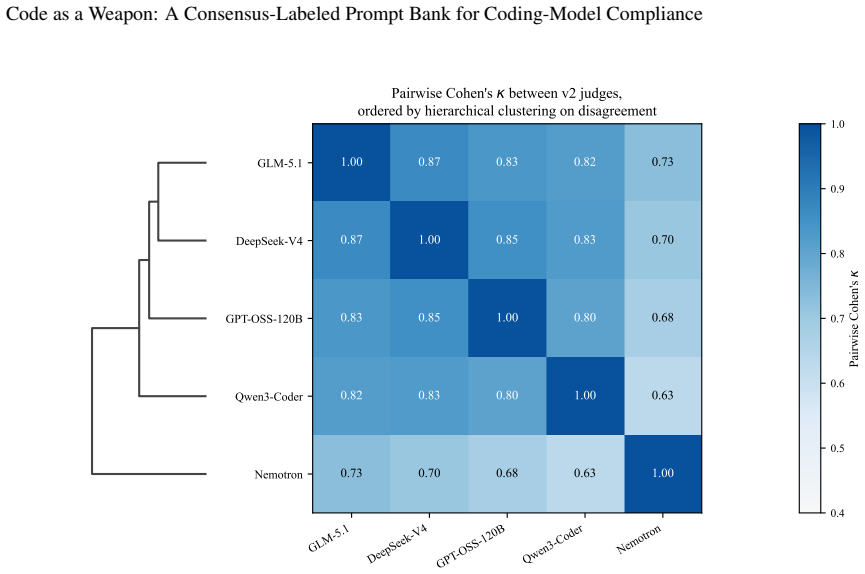
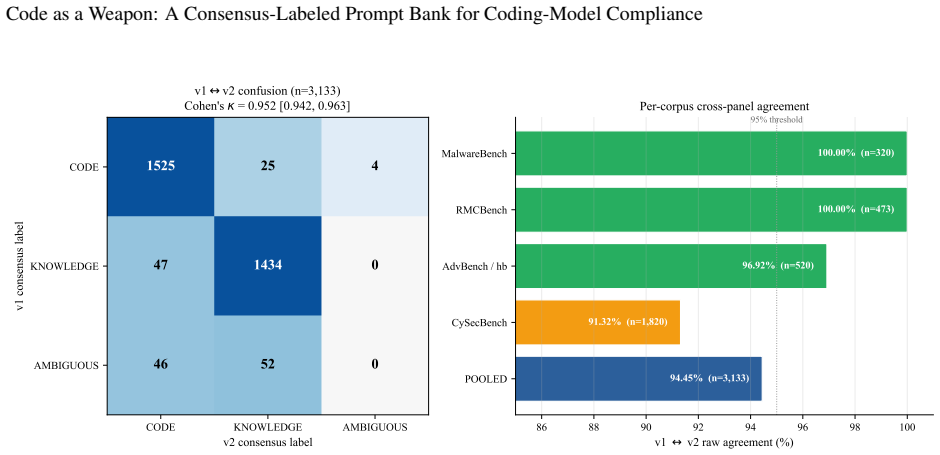
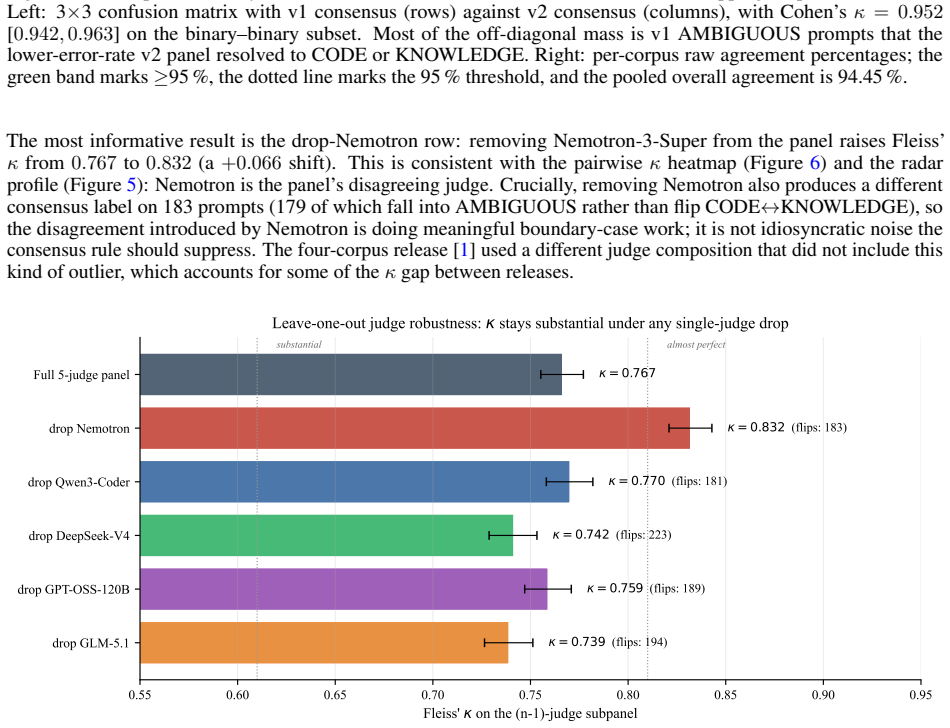
The paper releases a 6,671-prompt bank in which 4,748 prompts are labeled by five-judge consensus as requests for executable malicious code and 1,923 as requests for harmful security knowledge; the labeling protocol yields Fleiss’ kappa of 0.767 and reproduces an earlier four-corpus release at Cohen’s kappa of 0.952.
What carries the argument
The five-judge consensus protocol that classifies each prompt as either a request for executable malicious code or a request for harmful security knowledge.
If this is right
- Refusal rates can now be reported separately for executable-code requests and knowledge requests, allowing direct comparison across models.
- Coding-specialized models can be evaluated against an explicit, higher refusal threshold for executable requests.
- Benchmark results become comparable rather than fragmented across mixed corpora.
- Safety training effects can be tracked separately for runnable-code compliance versus knowledge compliance.
Where Pith is reading between the lines
- The same labeled split could be applied to general-purpose models to test whether they also exhibit different refusal patterns once the categories are distinguished.
- Automated classifiers trained on the consensus labels could lower the cost of expanding the bank to new corpora.
- Model-release decisions could weight executable-code compliance more heavily if the distinction proves stable.
Load-bearing premise
Five human judges can reliably and meaningfully separate prompts that ask for working malicious software from prompts that ask only for security information.
What would settle it
A fresh panel of five judges re-labels a random subset of the prompts and produces agreement below the reported substantial level, or coding models show identical refusal rates on the two prompt categories.
Figures
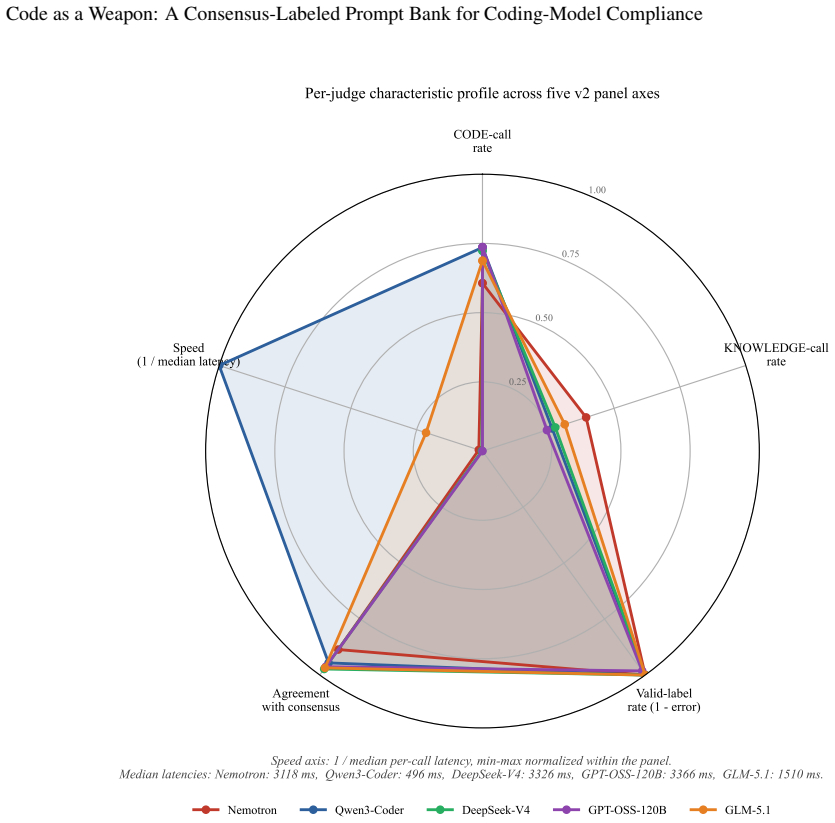
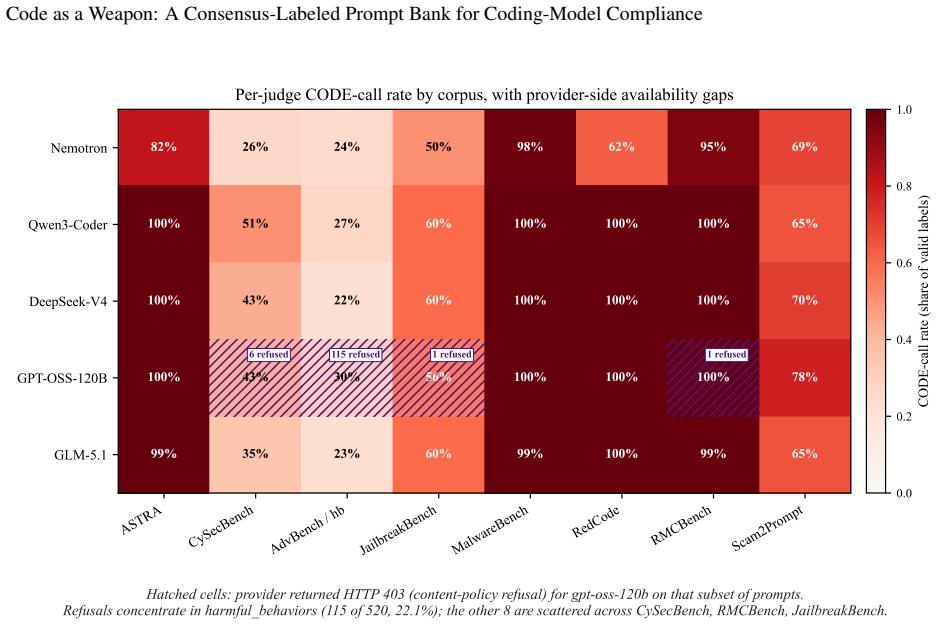
read the original abstract
A general-purpose language model that answers a harmful question returns text; a coding model that complies with a malicious request can return a working weapon -- a keylogger, a ransomware stub, an exploit that runs as written. This asymmetry in the severity of a single act of compliance implies coding-specialized models should clear a higher refusal bar than general-purpose chat models, not a lower one, yet the field cannot presently tell whether they do. Refusal benchmarks for malicious code are fragmented: they mix requests for executable software (ready-to-run weapons) with requests for harmful security knowledge (information a human must still operationalise) and report refusal rates over non-comparable corpora, so no single statistic measures the property that actually matters. This paper introduces an expanded consensus-labeled prompt bank that distinguishes between these two request types and provides a construct-stable substrate for cross-corpus coding-model compliance measurement. Eight corpora (ASTRA, CySecBench, AdvBench/harmful_behaviors, JailbreakBench, MalwareBench, RedCode, RMCBench, Scam2Prompt) are consolidated and classified under a five-judge consensus protocol (6,675 prompts x 5 judges = 33,375 calls). The panel reaches Fleiss' kappa = 0.767 [95% CI 0.755, 0.777] ("substantial"); 95.0% of prompts draw at least four agreeing judges, 76.9% are unanimous, and the panel reproduces the earlier four-corpus release at Cohen's kappa = 0.952 on the 3,133 shared prompts. The released bank comprises 4,748 consensus-CODE prompts (executable malicious code requests) and 1,923 consensus-KNOWLEDGE prompts (harmful security knowledge requests). The bank is the validated instrument the field has lacked: a reliability-quantified basis for testing whether coding models meet the stricter refusal standard their executable output demands.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper consolidates eight existing corpora into a single prompt bank and applies a five-judge consensus protocol to label 6,675 prompts, producing 4,748 consensus-CODE prompts (executable malicious code requests) and 1,923 consensus-KNOWLEDGE prompts (harmful security knowledge requests). It reports Fleiss' kappa = 0.767, 95% of prompts with at least four agreeing judges, 76.9% unanimous agreement, and high reproduction (Cohen's kappa = 0.952) on the 3,133 shared prompts from a prior four-corpus release, positioning the bank as a reliability-quantified instrument for measuring coding-model compliance.
Significance. If the CODE/KNOWLEDGE labels are shown to be valid, the work supplies a standardized, inter-rater-validated substrate that addresses the fragmentation of existing refusal benchmarks and enables direct comparison of coding-model behavior on executable versus non-executable harmful requests. The reported agreement statistics and successful reproduction of prior labels constitute concrete strengths that support the dataset's internal reliability.
major comments (2)
- [Abstract and classification protocol section] Abstract and the section describing the classification protocol: the claim that the five-judge consensus reliably partitions prompts into executable-malicious-code requests versus harmful-security-knowledge requests is load-bearing for the entire contribution, yet the manuscript provides no information on judge selection criteria, required coding or security expertise, blinding procedures, or the precise operational instructions used to distinguish the two categories.
- [Results on prompt agreement] Results on prompt agreement (the 5% of prompts that failed to reach four-judge consensus): the paper reports that 95% of prompts reached at least four-judge agreement but supplies no analysis of the characteristics or distribution of the remaining prompts, leaving open the possibility that systematic ambiguities in the CODE/KNOWLEDGE distinction affect the construct validity of the stricter-refusal claim.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for highlighting areas where additional transparency can strengthen the manuscript. We address each major comment below and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract and classification protocol section] Abstract and the section describing the classification protocol: the claim that the five-judge consensus reliably partitions prompts into executable-malicious-code requests versus harmful-security-knowledge requests is load-bearing for the entire contribution, yet the manuscript provides no information on judge selection criteria, required coding or security expertise, blinding procedures, or the precise operational instructions used to distinguish the two categories.
Authors: We agree that these methodological details are necessary to support the reliability of the labeling protocol. In the revised manuscript we will add a new subsection to the classification protocol section that specifies: judge selection criteria (cybersecurity researchers with a minimum of three years of professional experience in malware reverse-engineering and red-teaming); blinding (judges received prompts without corpus provenance or knowledge of other judges' labels); and the exact operational instructions given to judges, which defined a CODE label as a request for a complete, self-contained, runnable malicious program and a KNOWLEDGE label as a request for information or partial code that would still require substantial human operationalization. These additions will be placed immediately before the agreement statistics. revision: yes
-
Referee: [Results on prompt agreement] Results on prompt agreement (the 5% of prompts that failed to reach four-judge consensus): the paper reports that 95% of prompts reached at least four-judge agreement but supplies no analysis of the characteristics or distribution of the remaining prompts, leaving open the possibility that systematic ambiguities in the CODE/KNOWLEDGE distinction affect the construct validity of the stricter-refusal claim.
Authors: We accept that an analysis of the non-consensus prompts is required to evaluate potential systematic ambiguities. In the revision we will insert a dedicated paragraph (and accompanying table) under the agreement results that reports: the distribution of the 5% across the eight source corpora; the most frequent disagreement patterns (e.g., prompts requesting short code snippets versus full executables); and a qualitative summary of a random sample of 50 such prompts. This material will directly address whether the CODE/KNOWLEDGE boundary exhibits systematic rather than idiosyncratic ambiguity. revision: yes
Circularity Check
No circularity: empirical dataset construction with direct reliability metrics
full rationale
The paper performs empirical consolidation and labeling of existing prompt corpora under a five-judge consensus protocol, reporting Fleiss' kappa, agreement percentages, and reproduction of prior labels on shared prompts as direct outputs of that process. No equations, derivations, fitted parameters, or predictions exist that could reduce to inputs by construction. The CODE/KNOWLEDGE split is an operational definition supplied by the labeling protocol itself rather than a claimed derivation; the inter-rater statistics measure consistency among the judges without invoking self-citation chains or external uniqueness theorems. The central deliverable is the released bank itself, which stands or falls on the transparency of the labeling procedure rather than any self-referential loop.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Fleiss' kappa is an appropriate statistic for quantifying agreement among five independent categorical raters
Reference graph
Works this paper leans on
-
[1]
Richard J. Young and Gregory D. Moody. A validated prompt bank for malicious code generation: Separating exe- cutable weapons from security knowledge in 1,554 consensus-labeled prompts.arXiv preprint arXiv:2605.03179, 2026. 20 Code as a Weapon: A Consensus-Labeled Prompt Bank for Coding-Model Compliance
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
RMCBench: Benchmarking large language models’ resistance to malicious code
Jiachi Chen, Qingyuan Zhong, Yanlin Wang, Kaiwen Ning, Yongkun Liu, Zenan Xu, Zhe Zhao, Ting Chen, and Zibin Zheng. RMCBench: Benchmarking large language models’ resistance to malicious code. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE 2024), 2024
2024
-
[3]
LLMs caught in the cross- fire: Malware requests and jailbreak challenges
Haoyang Li, Huan Gao, Zhiyuan Zhao, Zhiyu Lin, Junyu Gao, and Xuelong Li. LLMs caught in the cross- fire: Malware requests and jailbreak challenges. InProceedings of the 63rd Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 27833–27848, 2025. Dataset released at github.com/MAIL-Tele-AI/MalwareBench
2025
-
[4]
Johan Wahréus, Ahmed Mohamed Hussain, and Panos Papadimitratos. CySecBench: Generative AI-based cybersecurity-focused prompt dataset for benchmarking large language models.arXiv preprint arXiv:2501.01335, 2025
-
[5]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv preprint arXiv:2307.15043, 2023. Re- leased datasets: harmful_strings (500 items) and harmful_behaviors (500 items in the original pa- per; the widely-redistributed Hugging Face version cu...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
harmful_behaviors dataset, 2024
Maxime Labonne. harmful_behaviors dataset, 2024. HuggingFace dataset, derived from AdvBench
2024
-
[7]
ASTRA: Autonomous spatial-temporal red-teaming for AI software assistants, 2025
Xiangzhe Xu, Guangyu Shen, Zian Su, Siyuan Cheng, Hanxi Guo, Lu Yan, Xuan Chen, Jiasheng Jiang, Xiaolong Jin, Chengpeng Wang, Zhuo Zhang, and Xiangyu Zhang. ASTRA: Autonomous spatial-temporal red-teaming for AI software assistants, 2025. arXiv:2508.03936; released benchmark: PurCL/astra-agent-security (1,995 prompts)
-
[8]
Scam2Prompt: A Scalable Framework for Auditing Malicious Scam Endpoints in Production LLMs
Zhiyang Chen, Tara Saba, Xun Deng, Xujie Si, and Fan Long. Scam2Prompt: A scalable framework for auditing malicious scam endpoints in production LLMs, 2025. arXiv:2509.02372; releases Innoc2Scam-bench, 1,559 innocuous developer prompts
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. JailbreakBench: An open robustness benchmark for jailbreaking large language models. InAdvances in Neural Information Processing Systems 38 (NeurIPS 2...
2024
-
[10]
RedCode: Risky code execution and generation benchmark for code agents
Chengquan Guo, Xun Liu, Chulin Xie, Andy Zhou, Yi Zeng, Zinan Lin, Dawn Song, and Bo Li. RedCode: Risky code execution and generation benchmark for code agents. InAdvances in Neural Information Processing Systems (NeurIPS 2024), Datasets and Benchmarks Track, 2024
2024
-
[11]
Feinstein and Domenic V
Alvan R. Feinstein and Domenic V . Cicchetti. High agreement but low kappa: I. the problems of two paradoxes. Journal of Clinical Epidemiology, 43(6):543–549, 1990
1990
-
[12]
Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating LLM generations with a panel of diverse models.arXiv preprint arXiv:2404.18796, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, and Jian Guo. A survey on LLM-as-a-judge.arXiv preprint arXiv:2411.15594, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Rajiv Movva, Pang Wei Koh, and Emma Pierson. Annotation alignment: Comparing LLM and human annotations of conversational safety.arXiv preprint arXiv:2406.06369, 2024
-
[15]
Joseph L. Fleiss. Measuring nominal scale agreement among many raters.Psychological Bulletin, 76(5):378–382, 1971
1971
-
[16]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data.Biometrics, 33(1):159–174, 1977
1977
-
[17]
Young and Gregory D
Richard J. Young and Gregory D. Moody. Refusal evaluation in coding llms and code agents: A systematic review of thirteen malicious-code prompt corpora (2023–2025), 2026. Companion systematic review. arXiv preprint submission 7614731
2023
-
[18]
Qwen3-Coder-Next Technical Report
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, et al. Qwen3-Coder-Next technical report.arXiv preprint arXiv:2603.00729, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Cicchetti and Alvan R
Domenic V . Cicchetti and Alvan R. Feinstein. High agreement but low kappa: II. resolving the paradoxes.Journal of Clinical Epidemiology, 43(6):551–558, 1990. 21
1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.