Pre-Registering the Detectable Effect: A Paired-MDE Budget for 4-bit Quantization Benchmarks, with a Pilot Audit
Pith reviewed 2026-06-29 22:39 UTC · model grok-4.3
The pith
A paired MDE bound shows most NF4-FP16 deltas on n=100 splits fall below the minimum detectable effect at a 10 percent disagreement rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
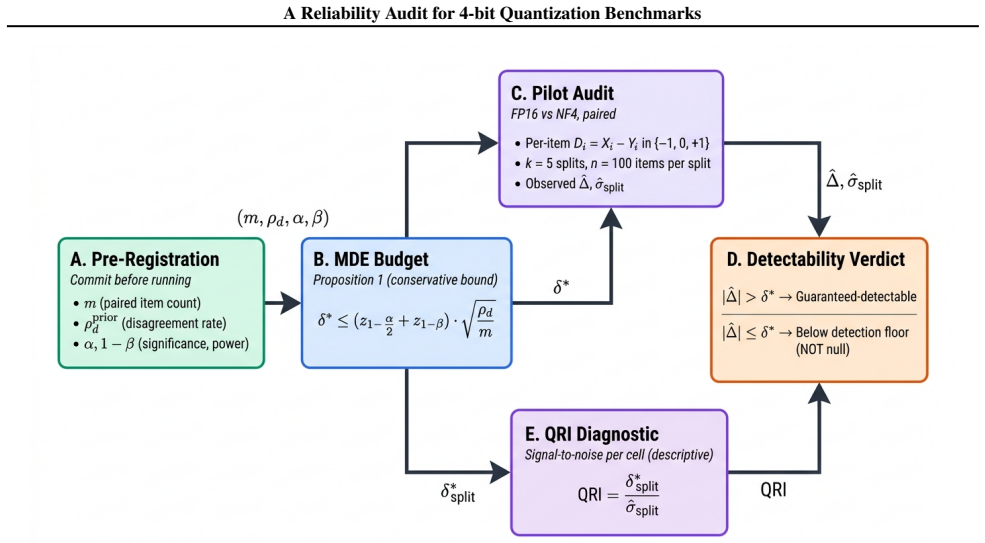
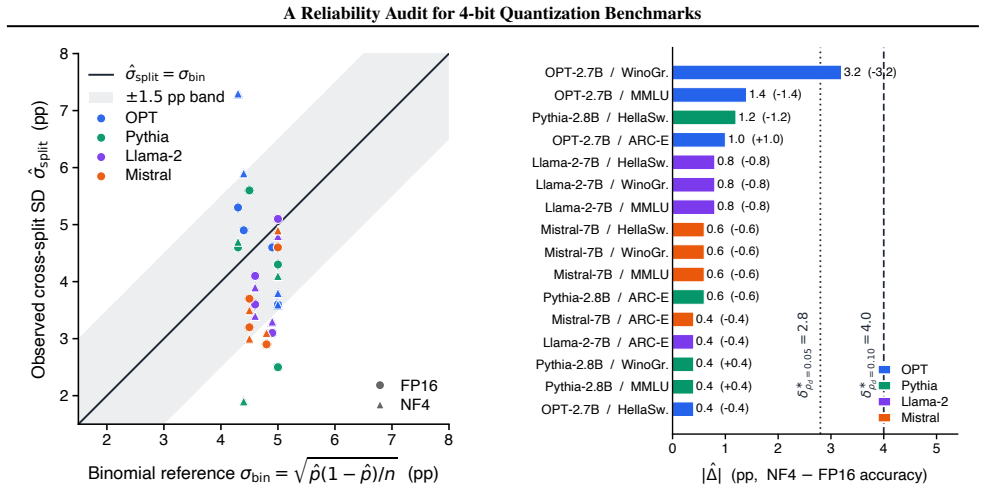
Adapting Miettinen's 1968 paired-binary sample-size formula yields the conservative MDE bound δ* ≤ (z_{1-α/2} + z_{1-β}) √(ρ_d / m) in the paired count m and disagreement rate ρ_d. Assuming ρ_d = 0.10, the pilot audit finds all NF4-FP16 deltas below this bound and most cross-split SDs within ±1.5 pp of √p(1-p)/n, so much reported variance on n=100 subsamples is binomial sampling noise. Prompt-template ranges on MMLU meet or exceed the largest observed quantization delta of 3.2 pp, and the borderline OPT-WinoGrande cell illustrates the explicit planning trade-off at different ρ_d values.
What carries the argument
The conservative minimum detectable effect bound δ* ≤ (z_{1-α/2} + z_{1-β}) √(ρ_d / m) adapted from the paired-binary sample-size calculation, which sets a pre-experiment threshold in the disagreement rate ρ_d and paired item count m.
If this is right
- Benchmark designers obtain an explicit one-line budget they can pre-register before any quantization run.
- On n=100 subsamples, most variance labeled as benchmark unreliability is binomial sampling noise.
- Prompt-template ranges on MMLU can equal or exceed the largest quantization delta, so the template must be fixed first.
- The single 3.2 pp borderline cell is below the MDE at ρ_d=0.10 but above it at ρ_d=0.05, exposing the planning trade-off.
Where Pith is reading between the lines
- The same paired MDE construction could be applied to other compression techniques such as pruning or low-rank adaptation to standardize reliability checks.
- Future audits that first measure ρ_d directly would replace the planning value with an empirical one and tighten the bound.
- Generalizing the paired design to simultaneous comparisons among several quantization formats would require extending the MDE formula to multiple disagreement rates.
Load-bearing premise
The actual FP16-NF4 disagreement rate equals the unmeasured planning value of 0.10 used to compute the MDE bound.
What would settle it
Measuring the true disagreement rate ρ_d on a large held-out set and finding it differs substantially from 0.10, or observing deltas that repeatedly exceed the computed MDE once the measured ρ_d is inserted into the bound.
Figures
read the original abstract
This is a planning-method note with an unpaired pilot audit. We adapt the classical paired-binary sample-size calculation (Miettinen, 1968) to quantization benchmarks, giving a conservative minimum detectable effect (MDE) bound $\delta^{*} \le (z_{1-\alpha/2}+z_{1-\beta})\sqrt{\rho_d/m}$ in the paired item count $m$ and the FP16-NF4 disagreement rate $\rho_d$. The bound turns "how reliable is my quantization claim?" into a one-line budget a benchmark designer can commit to before running. We illustrate the bound on four models and four benchmarks ($k=5$ splits of $n=100$), and add a parallel MMLU prompt-template study to put the bound's quantization-noise scale alongside the prompt-noise scale. Assuming $\rho_d=0.10$ (an unmeasured planning value), all observed NF4-FP16 deltas fall below the implied MDE, and most cross-split SDs lie within $\pm 1.5$ pp of the binomial reference $\sqrt{p(1-p)/n}$, so much of the variance reported as "benchmark unreliability" on $n=100$ subsamples is binomial sampling noise. The single borderline cell (OPT-WinoGrande, $|\Delta|=3.2$ pp) is below the implied MDE at $\rho_d=0.10$ but above it at $\rho_d=0.05$, illustrating the planning trade-off the bound makes explicit. On MMLU, prompt-template ranges of 2-10 pp meet or exceed the largest observed quantization delta (3.2 pp), so a quantization audit that does not first fix the prompt template absorbs template variance into its noise floor. We complement the bound with a five-line pre-registration template.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a planning-method note that adapts the paired-binary sample-size formula from Miettinen (1968) to quantization benchmarks. It supplies the conservative MDE bound δ* ≤ (z_{1-α/2} + z_{1-β}) √(ρ_d / m) in the paired item count m and the FP16-NF4 disagreement rate ρ_d, treats ρ_d as an explicit unmeasured planning parameter, and illustrates the bound with a pilot audit on four models and four benchmarks (k=5 splits of n=100). Under the assumption ρ_d=0.10 the observed NF4-FP16 deltas lie below the implied MDE, cross-split SDs are close to the binomial reference √p(1-p)/n, and MMLU prompt-template ranges meet or exceed the largest observed quantization delta; a five-line pre-registration template is also supplied.
Significance. If the adaptation is sound, the note supplies a practical, one-line budgeting device that benchmark designers can commit to before running experiments, together with an explicit sensitivity check on the planning parameter. The pilot observations are consistent with the binomial-noise interpretation, and the side-by-side comparison of quantization deltas with prompt-template variance is a useful contextual contribution. These elements could reduce over-interpretation of small reported differences on n=100 subsamples.
major comments (1)
- [Abstract] Abstract (paragraph beginning 'We adapt the classical...'): the MDE bound is stated directly without showing the steps that convert Miettinen's paired-binary sample-size expression into the displayed form δ* ≤ (z_{1-α/2}+z_{1-β})√(ρ_d/m); because this bound is the central planning device of the note, an explicit one-paragraph derivation or reference to the exact adaptation would be required to confirm that the conservative property carries over to the quantization-delta setting.
minor comments (3)
- [Pilot audit] Pilot-audit paragraph: the description 'k=5 splits of n=100' does not specify whether the splits are drawn independently per model/benchmark or share a common seed, nor whether they are random or stratified; this detail affects how the reported cross-split SDs should be interpreted relative to the binomial reference.
- [MMLU comparison] MMLU prompt-template study: the reported ranges of 2-10 pp are given without stating the number of templates, the exact template variations, or the evaluation protocol, making the scale comparison with the 3.2 pp quantization delta difficult to assess.
- [Throughout] Notation: 'pp' is used for percentage points without an initial definition; while contextually clear, an explicit gloss on first use would aid readers outside statistics.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comment on the abstract. The suggestion to make the central bound's derivation explicit is well taken, and we will incorporate it in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph beginning 'We adapt the classical...'): the MDE bound is stated directly without showing the steps that convert Miettinen's paired-binary sample-size expression into the displayed form δ* ≤ (z_{1-α/2}+z_{1-β})√(ρ_d/m); because this bound is the central planning device of the note, an explicit one-paragraph derivation or reference to the exact adaptation would be required to confirm that the conservative property carries over to the quantization-delta setting.
Authors: We agree that the abstract states the bound without the intermediate steps. In the revised version we will insert a concise one-paragraph derivation (or a pointer to it) immediately after the bound statement. The derivation will start from Miettinen's paired-binary sample-size formula n = (z_{1-α/2} + z_{1-β})^2 * (p_d(1-p_d)) / δ^2, rearrange to solve for the minimum detectable δ under the conservative substitution p_d(1-p_d) ≤ ρ_d/4 (with ρ_d the observed disagreement rate), and note that the resulting δ* ≤ (z_{1-α/2}+z_{1-β})√(ρ_d/m) remains an upper bound on the detectable effect for the paired quantization setting. This addition will be placed either in the abstract or as a short new paragraph in Section 2, preserving the abstract's brevity while satisfying the request for explicit justification. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper adapts the external Miettinen (1968) paired-binary MDE formula and applies it with an explicitly labeled unmeasured planning value ρ_d=0.10 rather than fitting or deriving it from the pilot data. The bound is used to contextualize observed deltas (all below MDE at the planning value) and cross-split SDs (matching binomial reference), with explicit sensitivity check at ρ_d=0.05. No derivation step reduces a claimed prediction to its own inputs by construction, no self-citation is load-bearing, and the central claim remains conditional on the external planning assumption. This is a standard honest non-finding for a methodological planning note.
Axiom & Free-Parameter Ledger
free parameters (1)
- ρ_d =
0.10
axioms (1)
- domain assumption Miettinen's 1968 paired-binary sample-size calculation applies without modification to quantization benchmark deltas.
Forward citations
Cited by 3 Pith papers
-
When AUC 0.998 Is Not Enough: A Candidate Evaluation Protocol for Hidden-State Probes of Indirect Prompt Injection in Multimodal Computer-Use Agents
High AUC from linear probes on model activations for indirect prompt injection does not license an unqualified claim of malicious-content detection, per a Qwen2.5-VL-7B case study with text and visual controls.
-
Chains That See, Answers That Don't: A Multi-Aspect Evaluation Recipe for Forced Chain-of-Thought on Video-MME
Forced CoT produces video-dependent reasoning chains but does not improve MCQ accuracy on Qwen2.5-VL with Video-MME and causes a small drop on the 7B variant.
-
Probe Choice Changes Canary-Memorization Verdicts: Three Post-Hoc Disagreement Case Studies in a Text-Dominant LoRA-Tuned Autoregressive Testbed
A prefix-window mean-NLL memorization probe disagrees with full-span NLL and exact-recall in three cases on a controlled autoregressive testbed, leading to recommendations for multi-probe reporting.
Reference graph
Works this paper leans on
-
[1]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Anthony, Herbie Bradley, Kyle O'Brien, Eric Hallahan, et al. Pythia: A suite for analyzing large language models across training and scaling. In Proceedings of the 40th International Conference on Machine Learning (ICML), pp.\ 2397--2430, 2023
2023
-
[2]
An empirical investigation of statistical significance in NLP
Taylor Berg-Kirkpatrick, David Burkett, and Dan Klein. An empirical investigation of statistical significance in NLP . In Proceedings of EMNLP-CoNLL, pp.\ 995--1005, 2012
2012
-
[3]
Lessons from the Trenches on Reproducible Evaluation of Language Models
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, et al. Lessons from the trenches on reproducible evaluation of language models. arXiv preprint arXiv:2405.14782, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Why do some inputs break low-bit LLM quantization? In Proceedings of EMNLP, pp.\ 3410--3429, 2025
Ting-Yun Chang, Muru Zhang, Jesse Thomason, and Robin Jia. Why do some inputs break low-bit LLM quantization? In Proceedings of EMNLP, pp.\ 3410--3429, 2025
2025
-
[5]
Robert J. Connor. Sample size for testing differences in proportions for the paired-sample design. Biometrics, 43(1):207--211, 1987
1987
-
[6]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC , the AI2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
GPT3.int8() : 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. GPT3.int8() : 8-bit matrix multiplication for transformers at scale. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[8]
QLoRA : Efficient finetuning of quantized LLM s
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA : Efficient finetuning of quantized LLM s. In Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[9]
SpQR : A sparse-quantized representation for near-lossless LLM weight compression
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh. SpQR : A sparse-quantized representation for near-lossless LLM weight compression. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[10]
The hitchhiker's guide to testing statistical significance in natural language processing
Rotem Dror, Gili Baumer, Segev Shlomov, and Roi Reichart. The hitchhiker's guide to testing statistical significance in natural language processing. In Proceedings of ACL, pp.\ 1383--1392, 2018
2018
-
[11]
Fagerland, Stian Lydersen, and Petter Laake
Morten W. Fagerland, Stian Lydersen, and Petter Laake. The McNemar test for binary matched-pairs data: mid- p and asymptotic are better than exact conditional. BMC Medical Research Methodology, 13(1):91, 2013
2013
-
[12]
OPTQ : Accurate quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. OPTQ : Accurate quantization for generative pre-trained transformers. In Proceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[13]
LLMC : Benchmarking large language model quantization with a versatile compression toolkit
Ruihao Gong, Yang Yong, Shiqiao Gu, Yushi Huang, Chengtao Lv, Yunchen Zhang, Dacheng Tao, and Xianglong Liu. LLMC : Benchmarking large language model quantization with a versatile compression toolkit. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pp.\ 132--152, 2024
2024
-
[14]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[15]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, et al. Mistral 7B. arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
A comprehensive evaluation of quantization strategies for large language models
Renren Jin, Jiangcun Du, Wuwei Huang, Wei Liu, Jian Luan, Bin Wang, and Deyi Xiong. A comprehensive evaluation of quantization strategies for large language models. In Findings of the Association for Computational Linguistics: ACL 2024, 2024
2024
-
[17]
John M. Lachin. Power and sample size evaluation for the McNemar test with application to matched case-control studies. Statistics in Medicine, 11(9):1239--1251, 1992
1992
-
[18]
Holistic evaluation of language models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, et al. Holistic evaluation of language models. Transactions on Machine Learning Research, 2023
2023
-
[19]
Evaluating quantized large language models
Shiyao Li, Xuefei Ning, Luning Wang, Tengxuan Liu, Xiangsheng Shi, Shengen Yan, Guohao Dai, Huazhong Yang, and Yu Wang. Evaluating quantized large language models. In Proceedings of the 41st International Conference on Machine Learning (ICML), volume 235 of PMLR, pp.\ 28480--28524, 2024
2024
-
[20]
AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ : Activation-aware weight quantization for on-device LLM compression and acceleration. In Proceedings of Machine Learning and Systems (MLSys), 2024
2024
-
[21]
Mahoney, and Yaoqing Yang
Haiquan Lu, Yefan Zhou, Shiwei Liu, Zhangyang Wang, Michael W. Mahoney, and Yaoqing Yang. AlphaPruning : Using heavy-tailed self regularization theory for improved layer-wise pruning of large language models. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[22]
Miettinen
Olli S. Miettinen. The matched pairs design in the case of all-or-none responses. Biometrics, 24(2):339--352, 1968
1968
-
[23]
State of what art? a call for multi-prompt LLM evaluation
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? a call for multi-prompt LLM evaluation. Transactions of the Association for Computational Linguistics, 12:933--949, 2024
2024
-
[24]
tinyBenchmarks : Evaluating LLM s with fewer examples
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. tinyBenchmarks : Evaluating LLM s with fewer examples. In Proceedings of the 41st International Conference on Machine Learning (ICML), volume 235 of PMLR, pp.\ 34303--34326, 2024
2024
-
[25]
WinoGrande : An adversarial Winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande : An adversarial Winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, 2020
2020
-
[26]
Quantifying language models' sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models' sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting. In Proceedings of the International Conference on Learning Representations (ICLR), 2024
2024
-
[27]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, et al. Llama 2 : Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
SmoothQuant : Accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant : Accurate and efficient post-training quantization for large language models. In Proceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[29]
ZeroQuant : Efficient and affordable post-training quantization for large-scale transformers
Zhewei Yao, Reza Yazdani Aminabadi, Minjia Zhang, Xiaoxia Wu, Conglong Li, and Yuxiong He. ZeroQuant : Efficient and affordable post-training quantization for large-scale transformers. In Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[30]
More accurate tests for the statistical significance of result differences
Alexander Yeh. More accurate tests for the statistical significance of result differences. In Proceedings of the 18th International Conference on Computational Linguistics (COLING), Volume 2, pp.\ 947--953, 2000
2000
-
[31]
HellaSwag : Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pp.\ 4791--4800, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag : Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), pp.\ 4791--4800, 2019
2019
-
[32]
OPT: Open Pre-trained Transformer Language Models
Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, et al. OPT : Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference. Journal of the American Statistical Association, 22(158):209--212, 1927
1927
-
[34]
Jiaqi Zhao, Ming Wang, Miao Zhang, Yuzhang Shang, Xuebo Liu, Yaowei Wang, Min Zhang, and Liqiang Nie. Benchmarking post-training quantization in LLM s: Comprehensive taxonomy, unified evaluation, and comparative analysis. arXiv preprint arXiv:2502.13178, 2025
-
[35]
Yuelyu Ji, Zhuochun Li, Rui Meng, and Daqing He. Retrieval--reasoning processes for multi-hop question answering: A four-axis design framework and empirical trends. arXiv preprint arXiv:2601.00536, 2026
-
[36]
BiasIG : Benchmarking multi-dimensional social biases in text-to-image models
Hanjun Luo et al. BiasIG : Benchmarking multi-dimensional social biases in text-to-image models. In Proceedings of the 2026 International Joint Conference on Neural Networks (IJCNN), 2026
2026
-
[37]
AtelierEval : Agentic evaluation of humans & LLM s as text-to-image prompters
Hanjun Luo et al. AtelierEval : Agentic evaluation of humans & LLM s as text-to-image prompters. In Proceedings of the 43rd International Conference on Machine Learning (ICML), 2026
2026
-
[38]
AgentAuditor : Human-level safety and security evaluation for LLM agents
Hanjun Luo et al. AgentAuditor : Human-level safety and security evaluation for LLM agents. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[39]
Scaling law for time series forecasting
Jingzhe Shi, Qinwei Ma, Huan Ma, and Lei Li. Scaling law for time series forecasting. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[40]
Intrinsic Entropy of Context Length Scaling in LLM s
Jingzhe Shi et al. Intrinsic Entropy of Context Length Scaling in LLM s . In Proceedings of the International Conference on Learning Representations (ICLR), 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.