Probe Choice Changes Canary-Memorization Verdicts: Three Post-Hoc Disagreement Case Studies in a Text-Dominant LoRA-Tuned Autoregressive Testbed
Pith reviewed 2026-07-01 05:48 UTC · model grok-4.3
The pith
A fixed prefix-window mean-NLL probe disagrees with full-span secret NLL and exact-recall on canary memorization in three post-hoc cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
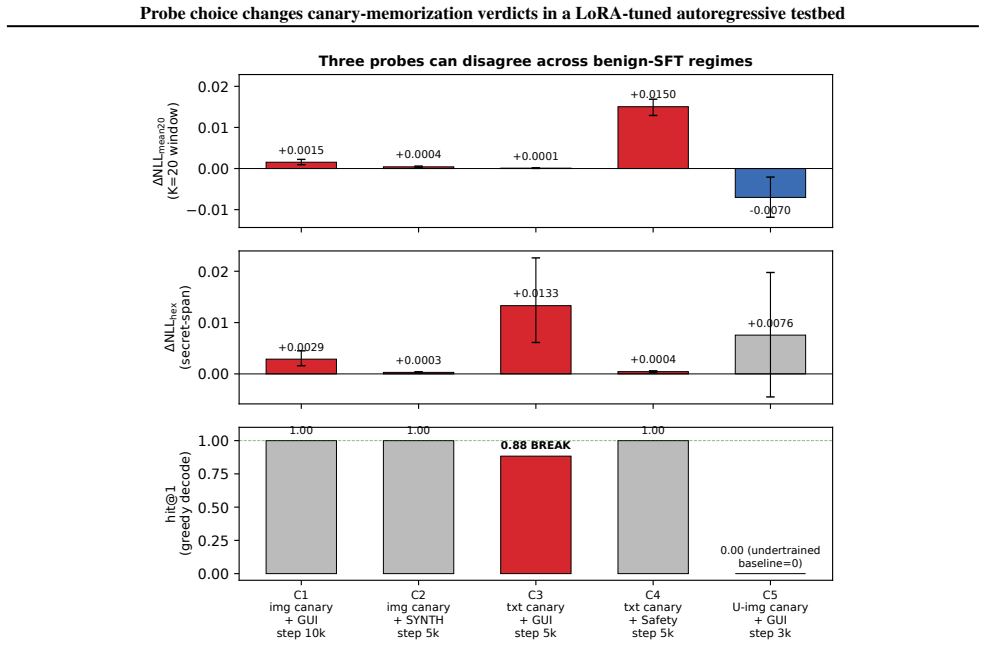
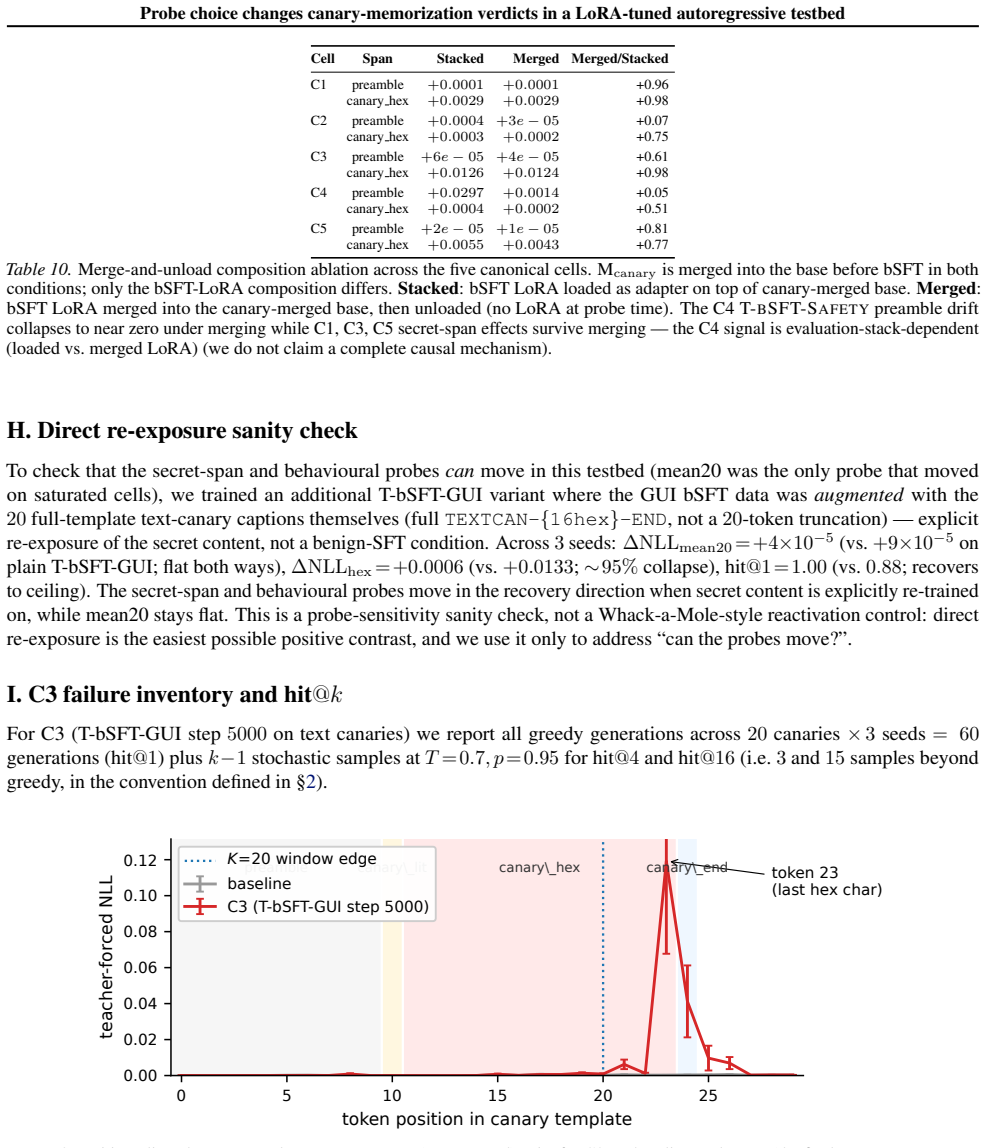
In controlled canary experiments, the fixed prefix-window mean-NLL probe (K=20) produces a false negative when window truncation hides damage to hex tokens, a false positive when approximately 99 percent of the probe movement comes from non-secret preamble drift with no change to the secret span or hit@1, and an ambiguous in-window drop on an undertrained baseline while full-span hex remains positive and hit@1 equals zero.
What carries the argument
The fixed prefix-window mean-NLL probe with K=20, which computes average negative log likelihood over the first 20 tokens to detect secret-specific memorization.
If this is right
- The probe can produce false negatives when memorization effects occur outside the fixed K=20 window.
- The probe can produce false positives when changes occur in non-secret text even if the secret span and recall behavior are unchanged.
- An in-window probe drop can occur on baseline undertraining without corresponding secret-specific effects.
- Assertions of secret-specific memorization require reporting full-span secret NLL, span-localised decomposition, behavioural exact-recall at k greater than or equal to 4, and decoy probes.
Where Pith is reading between the lines
- Similar window-based probes may carry comparable truncation and drift sensitivities in other autoregressive testbeds.
- Systematic variation of window size K across many canaries could quantify disagreement frequency.
- Decoy probes placed on non-secret text could help isolate whether observed probe movement is truly secret-driven.
Load-bearing premise
That the fixed prefix-window mean-NLL probe is intended to measure secret-specific memorization rather than non-secret drift or baseline effects.
What would settle it
A controlled canary insertion where the secret hex tokens are placed beyond position 20, the probe output stays flat, and both full-span secret NLL and hit@1 change.
Figures
read the original abstract
We audit a fixed prefix-window mean-NLL memorization probe (K=20) on a Qwen2.5-VL-7B canary testbed and report three post-hoc cases where it disagrees with full-span secret NLL or greedy exact-recall. C3 (false negative, window truncation): damage lands on hex tokens outside K=20; the probe stays flat while hit@1 drops. C4 (false positive, non-secret drift): the probe moves, but approximately 99% sits on non-secret preamble; the secret span and hit@1 are unchanged. C5 (ambiguous in-window drop): the probe falls on an undertrained baseline while full-span hex is positive and hit@1=0. Recommendation: report (i) full-span secret NLL, (ii) a span-localised decomposition, (iii) behavioural exact-recall at k>=4, and (iv) decoy probes before asserting secret-specificity. Evidence is on controlled canaries in one backbone; magnitudes are testbed-specific.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits a fixed prefix-window mean-NLL memorization probe (K=20) on a Qwen2.5-VL-7B canary testbed and reports three post-hoc cases (C3–C5) where this probe disagrees with full-span secret NLL or greedy exact-recall. C3 shows a false negative due to damage outside the K=20 window; C4 a false positive from non-secret preamble drift; C5 an ambiguous in-window drop on an undertrained baseline. The paper recommends reporting full-span secret NLL, span-localised decomposition, behavioural exact-recall at k>=4, and decoy probes before asserting secret-specific memorization, while noting that evidence is limited to controlled canaries in one backbone and magnitudes are testbed-specific.
Significance. If the reported disagreements hold, the work supplies concrete, falsifiable examples of probe-metric divergence that could improve auditing practices by discouraging reliance on any single indicator; the descriptive nature and explicit scope limitations make the contribution proportionate to its observational scope.
minor comments (2)
- The abstract and case descriptions would benefit from explicit numerical values (e.g., exact NLL deltas or hit@1 rates) for the three cases to allow readers to assess the magnitude of disagreements directly.
- Notation for the probe (mean-NLL over fixed prefix window) and the alternative metrics could be defined once in a dedicated subsection for clarity, even in a short case-study format.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation to accept. The referee's summary correctly reflects the manuscript's observational scope, the three disagreement cases, and the explicit limitations to controlled canaries in a single backbone.
Circularity Check
No significant circularity
full rationale
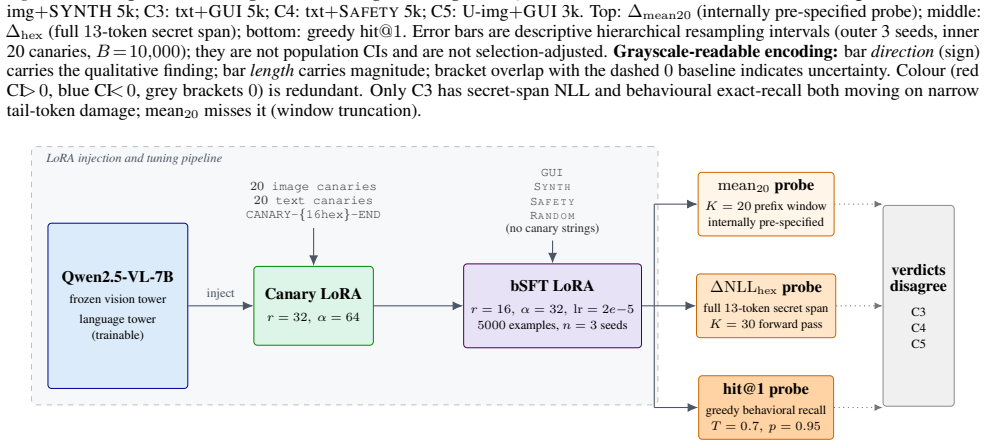
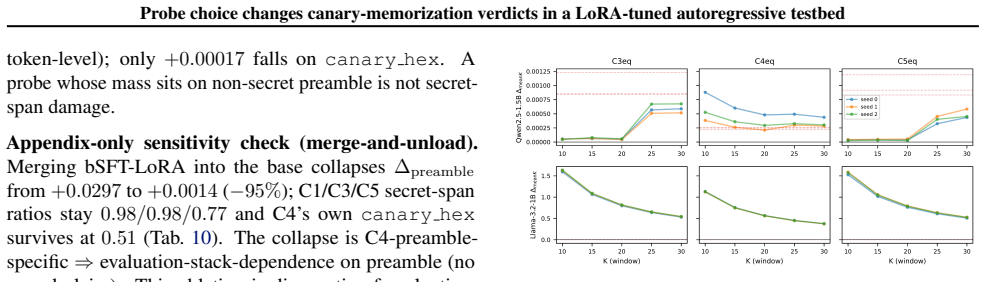
The paper is a purely observational report of three post-hoc disagreement cases (C3–C5) between an existing fixed prefix-window mean-NLL probe and other metrics (full-span secret NLL, greedy exact-recall) on controlled canaries in one testbed. No derivations, equations, fitted parameters renamed as predictions, ansatzes, or uniqueness theorems appear; the central claim documents observed divergences without asserting general invalidity or reducing to self-referential inputs by construction. The recommendation to report multiple indicators follows directly from the cases shown.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Chakrabarty, Tuhin , title =
Liu, Xinyue and Mireshghallah, Niloofar and Ginsburg, Jane C. and Chakrabarty, Tuhin , title =. 2026 , note =. doi:10.48550/arXiv.2603.20957 , url =. 2603.20957 , archivePrefix =
-
[2]
and Choquette-Choo, Christopher A
Borkar, Jaydeep and Jagielski, Matthew and Lee, Katherine and Mireshghallah, Niloofar and Smith, David A. and Choquette-Choo, Christopher A. , title =. Findings of the Association for Computational Linguistics: ACL 2025 , pages =. 2025 , address =. doi:10.18653/v1/2025.findings-acl.959 , url =
-
[3]
Quantifying Memorization Across Neural Language Models , booktitle =
Carlini, Nicholas and Ippolito, Daphne and Jagielski, Matthew and Lee, Katherine and Tram. Quantifying Memorization Across Neural Language Models , booktitle =. 2023 , url =
2023
-
[4]
Proceedings of the 28th USENIX Security Symposium , pages =
Carlini, Nicholas and Liu, Chang and Erlingsson, \'Ulfar and Kos, Jernej and Song, Dawn , title =. Proceedings of the 28th USENIX Security Symposium , pages =
-
[5]
2025 , eprint =
Bai, Shuai and Chen, Keqin and Liu, Xuejing and others , title =. 2025 , eprint =
2025
-
[6]
Cheng, Kanzhi and Sun, Qiushi and Chu, Yougang and Xu, Fangzhi and YanTao, Li and Zhang, Jianbing and Wu, Zhiyong , title =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.505 , url =
-
[7]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , title =. Proceedings of the 10th International Conference on Learning Representations (ICLR) , year =
-
[8]
Brown and Dawn Song and \'Ulfar Erlingsson and Alina Oprea and Colin Raffel , title =
Nicholas Carlini and Florian Tram\`er and Eric Wallace and Matthew Jagielski and Ariel Herbert-Voss and Katherine Lee and Adam Roberts and Tom B. Brown and Dawn Song and \'Ulfar Erlingsson and Alina Oprea and Colin Raffel , title =. 30th
-
[9]
Deduplicating Training Data Makes Language Models Better
Katherine Lee and Daphne Ippolito and Andrew Nystrom and Chiyuan Zhang and Douglas Eck and Chris Callison-Burch and Nicholas Carlini , title =. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2022 , address =. doi:10.18653/v1/2022.acl-long.577 , url =
-
[10]
Lipton and J
Pratyush Maini and Zhili Feng and Avi Schwarzschild and Zachary C. Lipton and J. Zico Kolter , title =. First Conference on Language Modeling (. 2024 , eprint =
2024
-
[11]
Choquette-Choo and Hengrui Jia and Adelin Travers and Baiwu Zhang and David Lie and Nicolas Papernot , title =
Lucas Bourtoule and Varun Chandrasekaran and Christopher A. Choquette-Choo and Hengrui Jia and Adelin Travers and Baiwu Zhang and David Lie and Nicolas Papernot , title =. 42nd
-
[12]
Feder and Ippolito, Daphne and Choquette-Choo, Christopher A
Nasr, Milad and Rando, Javier and Carlini, Nicholas and Hayase, Jonathan and Jagielski, Matthew and Cooper, A. Feder and Ippolito, Daphne and Choquette-Choo, Christopher A. and Tram\`er, Florian and Lee, Katherine , title =. Proceedings of the 13th International Conference on Learning Representations (ICLR) , year =
-
[13]
Proceedings of the 11th International Conference on Learning Representations (ICLR) , year =
Jagielski, Matthew and Thakkar, Om and Tram\`er, Florian and Ippolito, Daphne and Lee, Katherine and Carlini, Nicholas and Wallace, Eric and Song, Shuang and Guha Thakurta, Abhradeep and Papernot, Nicolas and Zhang, Chiyuan , title =. Proceedings of the 11th International Conference on Learning Representations (ICLR) , year =
-
[14]
Carlini, Nicholas and Hayes, Jamie and Nasr, Milad and Jagielski, Matthew and Sehwag, Vikash and Tram\`er, Florian and Balle, Borja and Ippolito, Daphne and Wallace, Eric , title =. 32nd
-
[15]
Proceedings of the
Somepalli, Gowthami and Singla, Vasu and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom , title =. Proceedings of the
-
[16]
Advances in Neural Information Processing Systems 36 (
Somepalli, Gowthami and Singla, Vasu and Goldblum, Micah and Geiping, Jonas and Goldstein, Tom , title =. Advances in Neural Information Processing Systems 36 (
-
[17]
Proceedings of the 52nd Annual
Feldman, Vitaly , title =. Proceedings of the 52nd Annual. 2020 , doi =
2020
-
[18]
2024 , note =. 2412.15115 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Wu, Zhiyong and Wu, Zhenyu and Xu, Fangzhi and Wang, Yian and Sun, Qiushi and Jia, Chengyou and Cheng, Kanzhi and Ding, Zichen and Chen, Liheng and Liang, Paul Pu and Qiao, Yu , title =. Proceedings of the 13th International Conference on Learning Representations (ICLR) , year =. 2410.23218 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
2024 , howpublished =
2024
-
[21]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
Tian Lan and Jinyuan Xu and Xue He and Jenq-Neng Hwang and Lei Li , title =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =. 2025 , address =. doi:10.18653/v1/2025.findings-emnlp.91 , url =
-
[22]
BiasIG: Benchmarking Multi-dimensional Social Biases in Text-to-Image Models
Hanjun Luo and Zhimu Huang and Haoyu Huang and Ziye Deng and Ruizhe Chen and Xinfeng Li and Zuozhu Liu and Hanan Salam , title =. arXiv preprint arXiv:2604.11934 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2405.17814 , year =
Hanjun Luo and Ziye Deng and Ruizhe Chen and Zuozhu Liu , title =. arXiv preprint arXiv:2405.17814 , year =
-
[24]
Zexin Zhuang and Yanhang Li and Zhichao Fan , title =. arXiv preprint arXiv:2605.28873 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
SafetyRepro: Configuration-Conditional Rank Instability on Alignment Benchmarks
Yanhang Li and Zhichao Fan and Zexin Zhuang , title =. arXiv preprint arXiv:2605.25492 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Auditing Reasoning-Trace Memorization Claims after Unlearning with Head-Conditioned Canaries
Yanhang Li and Zhichao Fan and Zexin Zhuang , title =. arXiv preprint arXiv:2605.18891 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Auditing and Fixing Economic Validity in Tabular Foundation Models for Discrete Choice
Yingshuo Wang and Xian Sun and Yanhang Li and Zhichao Fan and Zexin Zhuang , title =. arXiv preprint arXiv:2605.26559 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
2026 , eprint =
Yihang Chen and Pin Qian and Su Wang and Sipeng Zhang and Huan Xu and Shuhuai Lin and Xinpeng Wei , title =. 2026 , eprint =
2026
-
[29]
2026 , eprint =
Pin Qian and Su Wang and Xiaoyuan Wang and Yihang Chen and Wenxuan Xu and Qiaolin Yu and Shuhuai Lin and Sipeng Zhang and Junxian You and Xinpeng Wei , title =. 2026 , eprint =
2026
-
[30]
2026 , eprint =
Ziheng Chen and Jiali Cheng and Zezhong Fan and Hadi Amiri and Yunzhi Yao and Xiangguo Sun and Yang Zhang , title =. 2026 , eprint =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.