Label-Free Reinforcement Learning via Cross-Model Entropy
Pith reviewed 2026-06-29 14:15 UTC · model grok-4.3
The pith
A separate verifier model's average log-likelihood supplies a continuous label-free reward that improves open-ended instruction following when plugged into GRPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
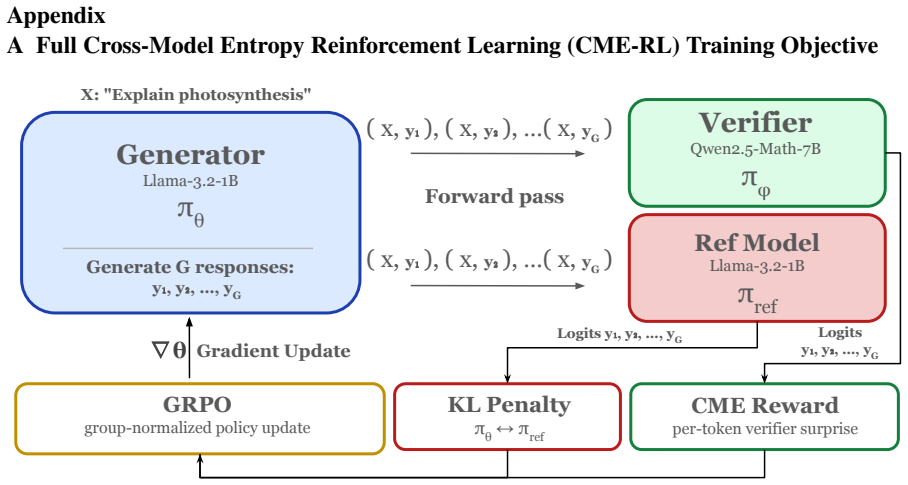
Cross-Model Entropy (CME) is the mean log-likelihood of a generator response under a separate verifier model; because the verifier is independent, responses it finds unsurprising serve as a reliable label-free reward for GRPO, extending effective reinforcement learning to open-ended instruction following where self-referential signals are inapplicable.
What carries the argument
Cross-Model Entropy (CME): the mean log-likelihood of a generator's response under an independent verifier model, used directly as the reward signal.
If this is right
- CME integrates into GRPO with no other changes to the training loop.
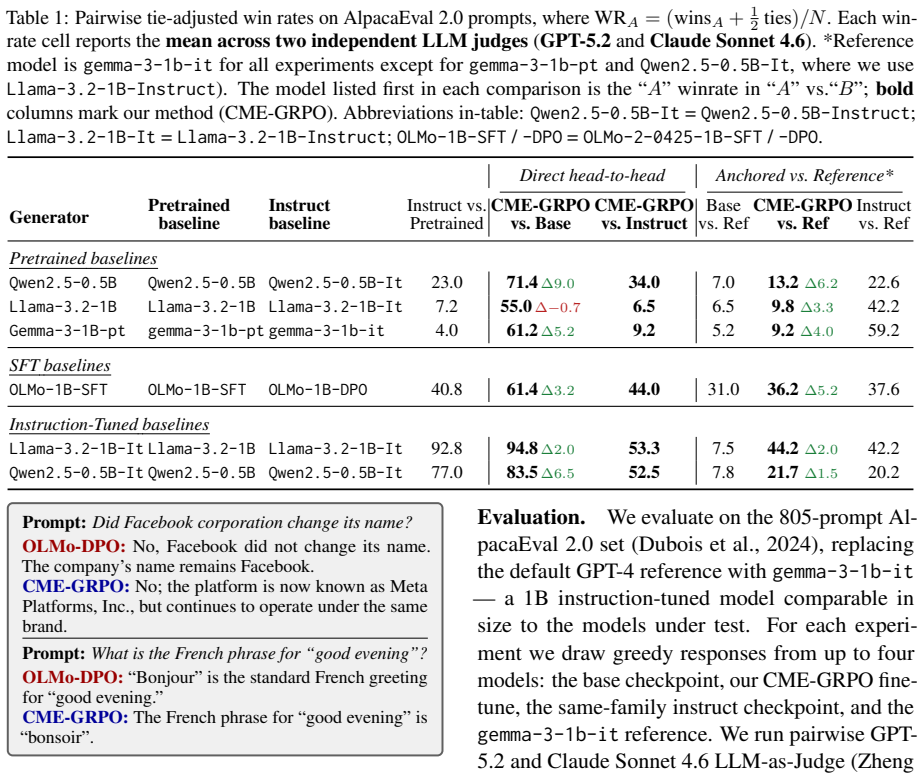
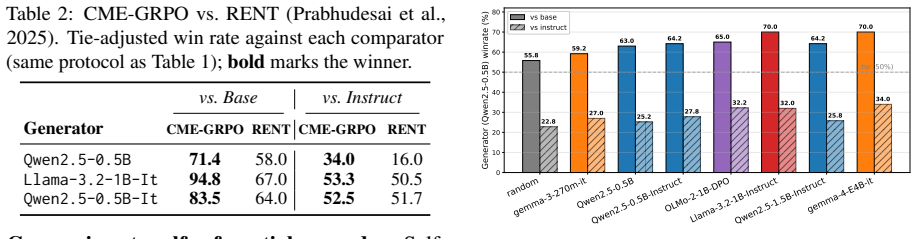
- CME-trained models achieve tie-adjusted win rates of 52.5% to 71.4% against untrained bases on UltraFeedback prompts evaluated by LLM-as-Judge.
- The improvement holds for pretrained, SFT, and instruction-tuned checkpoints in Qwen, Llama, Gemma, and OLMo families.
- CME supplies a usable reward where ground-truth verifiers and human labels are unavailable and where self-referential signals cannot be applied.
Where Pith is reading between the lines
- Pairing the verifier with a model from a different family than the generator could increase signal independence.
- The same likelihood signal might serve as a lightweight quality filter during inference without any RL training.
- CME could be tested on other open-ended generative tasks such as summarization or dialogue where automatic correctness checks do not exist.
Load-bearing premise
Responses that a separate verifier model finds unsurprising are likely correct or high quality.
What would settle it
Head-to-head LLM-as-judge comparisons on AlpacaEval 2.0 in which CME-trained models lose to or tie the untrained base across the four tested families and three regimes would falsify the central effectiveness claim.
Figures

read the original abstract
Post-training large language models with reinforcement learning is bottlenecked by the reward signal. Existing approaches require either ground-truth verifiable rewards, restricting training to domains with automatic correctness checks (e.g., mathematics, code execution), or human preference labels, which are expensive to collect and prone to reward hacking. Recent label-free methods replace ground-truth verifiers with self-referential signals like majority voting or token entropy over a model's own outputs, but risk reinforcing a model's own errors. In this work we propose Cross-Model Entropy (CME), the mean log-likelihood of a generator's response under a separate verifier model, as a label-free reward signal for RL post-training. CME is continuous, training-free, and grounded in the principle that responses a verifier finds unsurprising are likely correct or high quality. Because the verifier is independent of the generator, the signal cannot be gamed through self-consistency. We integrate CME into GRPO with no other changes to the training loop, extending label-free RL to open-ended instruction following -- a regime where self-referential signals are inapplicable or poorly suited. On open-ended instruction following (UltraFeedback prompts, evaluated on AlpacaEval 2.0), CME rewards beat the untrained base in head-to-head LLM-as-Judge comparisons across four model families (Qwen, Llama, Gemma, OLMo) and three training regimes (pretrained, SFT, and instruction-tuned), with tie-adjusted win rates ranging from 52.5% to 71.4%. Code will be released upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Cross-Model Entropy (CME) as a label-free reward for RL post-training of LLMs: the mean log-likelihood of a generator response under an independent verifier model. It integrates CME into GRPO without other changes and reports that this yields higher tie-adjusted win rates (52.5%-71.4%) than the untrained base model on UltraFeedback prompts evaluated via LLM-as-Judge on AlpacaEval 2.0, across four model families and three regimes (pretrained, SFT, instruction-tuned). The approach is motivated as extending label-free RL to open-ended instruction following while avoiding self-referential gaming.
Significance. If the central result holds under rigorous evaluation, the work would supply a continuous, training-free reward signal that operates without ground-truth verifiers or human preferences, addressing a key bottleneck for open-ended tasks. The explicit independence of the verifier and the no-change integration into GRPO are concrete strengths. The stated intent to release code upon publication further supports reproducibility.
major comments (2)
- [Abstract] Abstract: the reported tie-adjusted win rates (52.5% to 71.4%) are presented without error bars, confidence intervals, statistical significance tests, or details on verifier model choice, prompt formatting, or the exact LLM-as-Judge protocol. This absence makes it impossible to determine whether the observed improvements exceed evaluation variance.
- [Abstract] Abstract: the grounding claim that 'responses a verifier finds unsurprising are likely correct or high quality' is asserted without any referenced derivation, correlation study with human preferences, or analysis of potential misalignment (e.g., stylistic or safety biases) for open-ended tasks; this premise is load-bearing for the claim that CME constitutes a reliable reward.
minor comments (1)
- [Abstract] The abstract states results across four model families and three regimes but does not indicate where the per-family or per-regime breakdowns appear in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported tie-adjusted win rates (52.5% to 71.4%) are presented without error bars, confidence intervals, statistical significance tests, or details on verifier model choice, prompt formatting, or the exact LLM-as-Judge protocol. This absence makes it impossible to determine whether the observed improvements exceed evaluation variance.
Authors: We agree that the abstract lacks sufficient statistical and methodological detail. In the revised manuscript we will expand the abstract to report confidence intervals or standard errors on the win rates, name the specific verifier models employed, describe the LLM-as-Judge prompt template and formatting, and reference the statistical significance tests that appear in the main results tables. revision: yes
-
Referee: [Abstract] Abstract: the grounding claim that 'responses a verifier finds unsurprising are likely correct or high quality' is asserted without any referenced derivation, correlation study with human preferences, or analysis of potential misalignment (e.g., stylistic or safety biases) for open-ended tasks; this premise is load-bearing for the claim that CME constitutes a reliable reward.
Authors: The premise is presented as an intuitive grounding rather than a formally derived result. The current manuscript does not contain a dedicated correlation study or bias analysis. We will revise the abstract wording for precision and add a short discussion subsection that (i) cites prior work on likelihood as a quality proxy, (ii) acknowledges possible stylistic and safety misalignments, and (iii) reports a post-hoc correlation between CME scores and a small human preference subset where available. revision: yes
Circularity Check
No circularity: CME defined independently and evaluated externally
full rationale
The paper defines CME directly as mean log-likelihood of generator outputs under a separate verifier model and inserts it unchanged into GRPO. The grounding principle is asserted as an external premise rather than derived from any equation or self-referential loop. No fitted parameters are relabeled as predictions, no self-citations bear the central claim, and no uniqueness theorems or ansatzes are imported from prior author work. Empirical results on AlpacaEval are presented as external validation, not tautological restatements of the input definition. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Responses a verifier finds unsurprising are likely correct or high quality
Reference graph
Works this paper leans on
-
[1]
Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI feed- back.arXiv preprint arXiv:2212.08073. Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. UltraFeedback: Boosting language mod- els with scaled AI feedback. InProceedings of the 41st International Conference o...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and 1 others. 2024. Im- prove mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592. Mathematical Association of America. 2024...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
The Effects of Reward Misspecification: Mapping and Mitigating Misaligned Models
The effects of reward misspecification: Map- ping and mitigating misaligned models.arXiv preprint arXiv:2201.03544. Mihir Prabhudesai, Lili Chen, Alex Ippoliti, Katerina Fragkiadaki, Hao Liu, and Deepak Pathak. 2025. Maximizing confidence alone improves reasoning. arXiv preprint arXiv:2505.22660. Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Proximal Policy Optimization Algorithms
Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, volume 36. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal pol- icy optimization algorithms. InarXiv preprint arXiv:1707.06347. Rulin Shao, Shuyue Stella Li, Rui Xin, Scott Geng,...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Spurious Rewards: Rethinking Training Signals in RLVR
Spurious rewards: Rethinking training signals in RLVR.arXiv preprint arXiv:2506.10947. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y .K. Li, Y . Wu, and 1 others. 2024. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300. Joar Skalse, N...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations.arXiv preprint arXiv:2312.08935. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171. Lai Wei and 1 others. 2...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
The Lessons of Developing Process Reward Models in Mathematical Reasoning
Judging LLM-as-a-judge with MT-bench and chatbot arena. InAdvances in Neural Information Processing Systems, volume 36. Zhenru Zheng and 1 others. 2025b. The lessons of developing process reward models in mathematical reasoning.arXiv preprint arXiv:2501.07301. Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xian-...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Immunization: Vaccines stimulate the body’s immune system to produce antibodies against specific pathogens
-
[9]
Immune memory: After receiving a vaccine, the immune system produces memory cells that can quickly recognize and respond to future infections
-
[10]
Protection: The vaccinated individual will be protected if they contract the disease after being exposed to it through exposure to the virus or bacteria contained within the vaccine
-
[11]
Community protection: By protecting vulnerable populations such as infants, elderly people, and those with weakened immune systems, vaccination programs help reduce the overall burden of infectious diseases on community health. Herd immunity refers to the phenomenon where a sufficient number of individuals in a population become immune to a particular dis...
1980
-
[12]
Distribute the 5 on the right side of the equation:5(x−2) = 5x−10
-
[13]
Combine like terms on the right side:5x−10 = 5x−10
-
[14]
4.Divide both sides by−10to solve forx:x= 0
Subtract5xfrom both sides to isolate thexterms:0 =−10. 4.Divide both sides by−10to solve forx:x= 0
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.