Embodied3DBench: Benchmarking Low-Level Embodied Spatial Intelligence of Vision Language Models
Pith reviewed 2026-06-29 13:07 UTC · model grok-4.3
The pith
Current vision language models handle object-to-object spatial relations but fail at interaction tasks like affordance and grasp prediction in 3D scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
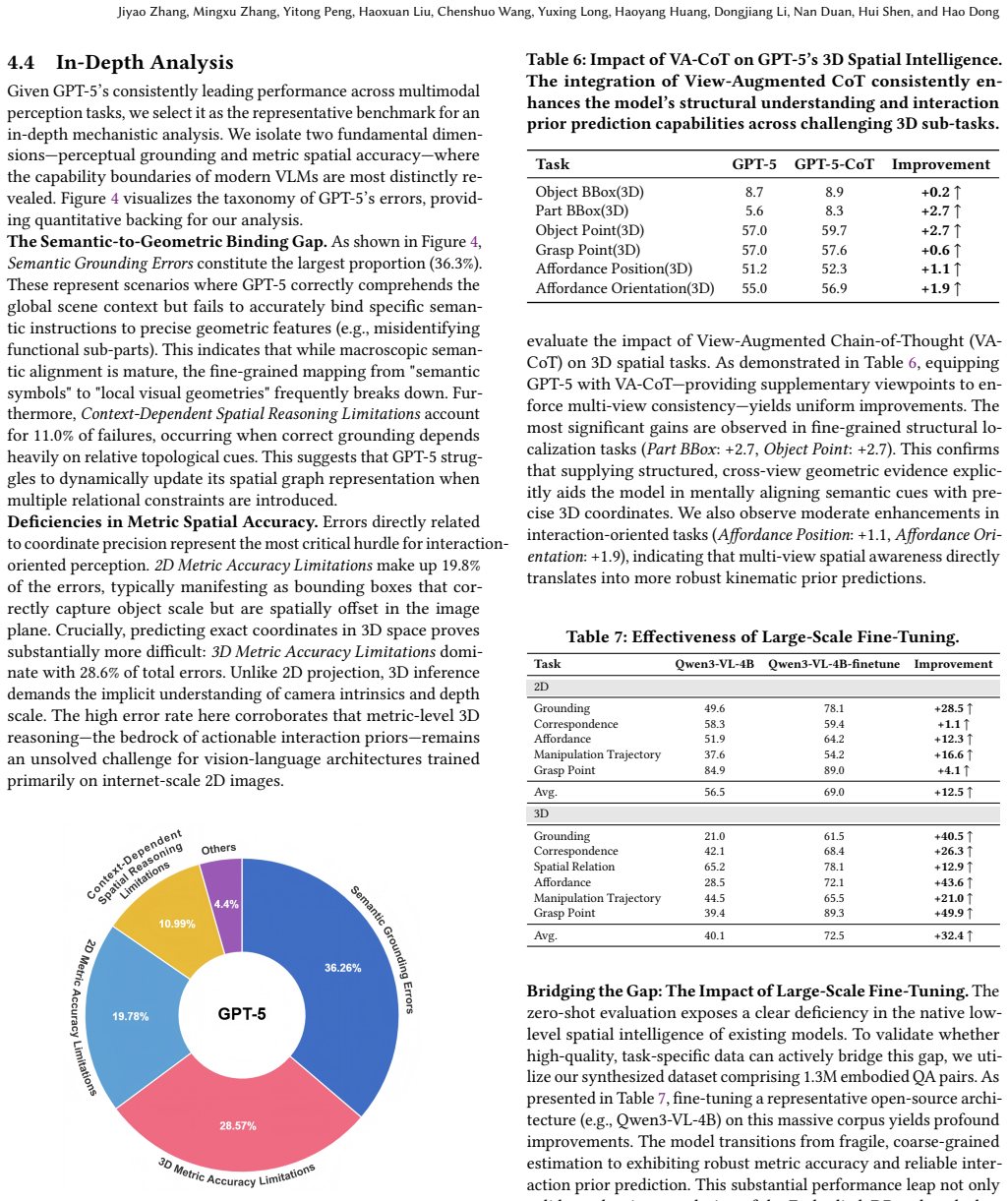
Embodied3DBench evaluates 13 state-of-the-art vision language models on 21k question-answer pairs across six task categories. Models perform relatively well on grounding, spatial relation prediction, and multi-view correspondence, yet remain fragile on affordance prediction, grasp point prediction, and trajectory prediction. The authors conclude that current models lack robust 3D-aware interaction priors. Fine-tuning on an additional 1.3 million synthetic pairs produces measurable gains on the interaction tasks, demonstrating that the identified gap is addressable with scale-appropriate data.
What carries the argument
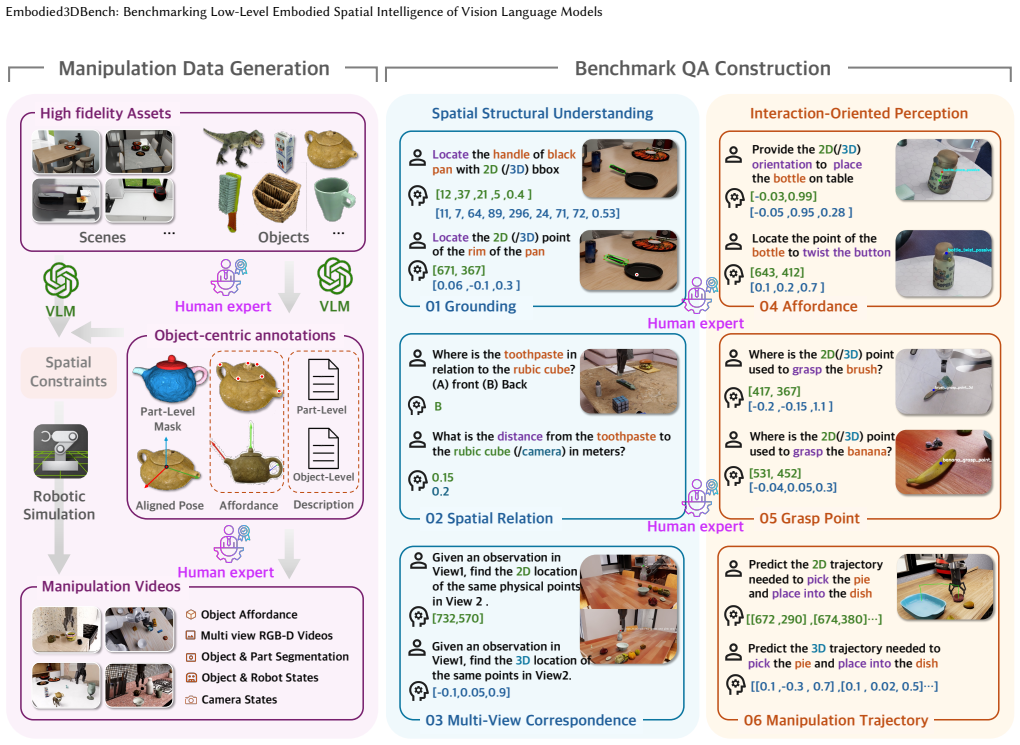
Embodied3DBench, a robot-centric evaluation suite whose six task categories are grouped into Spatial Structural Understanding and Interaction-Oriented Perception.
If this is right
- Models require explicit training signals for interaction priors rather than relying on high-level spatial reasoning alone.
- The benchmark supplies a standardized test that can track progress toward interaction-aware multimodal systems.
- Synthetic data at the reported scale can measurably lift performance on affordance, grasp, and trajectory prediction.
- Future model development should prioritize 3D interaction capabilities alongside existing strengths in object relations.
- The two-group task structure provides a diagnostic that separates structural from functional spatial understanding.
Where Pith is reading between the lines
- Real-world robot deployments may require additional adaptation layers beyond the reported fine-tuning to transfer gains from simulation to physical interaction.
- The benchmark could be extended to measure how well interaction priors generalize across different robot morphologies or sensor suites.
- If the identified gap persists across newer model families, architectural changes that embed explicit 3D geometry may prove necessary rather than data scaling alone.
Load-bearing premise
The 21k evaluation pairs and 1.3M training pairs were generated in a way that faithfully measures genuine low-level embodied spatial intelligence rather than artifacts of the synthesis process.
What would settle it
A controlled experiment in which models fine-tuned on the synthetic data are tested on matched real-robot interaction tasks and show no improvement over baselines would falsify the claim that the data solution closes the capability gap.
Figures



read the original abstract
Are current Vision Language Models (VLMs) ready to comprehend and reason about complex embodied interactions in 3D environments? We introduce Embodied3DBench, a robot-centric benchmark targeting low-level spatial intelligence in embodied 3D environments. To systematically evaluate these foundational perceptual capabilities, the benchmark includes 6 task categories divided into two core groups: Spatial Structural Understanding (Grounding, Spatial Relation Prediction, and Multi-view Correspondence) and Interaction-Oriented Perception (Affordance Prediction, Grasp Point Prediction, and Trajectory Prediction). The benchmark spans 12 subcategories and contains over 21k high-quality question-answer pairs. We evaluate 13 state-of-the-art models, and the results show that while current models exhibit relatively strong high-level spatial reasoning, such as understanding object-to-object positional relations, they remain fragile in interaction-oriented perception, highlighting a significant lack of robust 3D-aware interaction priors. To actively bridge this capability gap revealed by our benchmark, we further synthesize a large-scale training dataset comprising 1.3M QA pairs. Notably, fine-tuning on this dataset yields significant improvements in low-level spatial intelligence. Ultimately, Embodied3DBench fills a critical gap by providing both a systematic evaluation framework and a scalable data solution, setting a clear target for the development of interaction-aware multimodal systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Embodied3DBench, a robot-centric benchmark for low-level embodied spatial intelligence in VLMs. It defines 6 task categories split into Spatial Structural Understanding (Grounding, Spatial Relation Prediction, Multi-view Correspondence) and Interaction-Oriented Perception (Affordance Prediction, Grasp Point Prediction, Trajectory Prediction), spanning 12 subcategories and 21k QA pairs. Evaluation of 13 SOTA VLMs shows relatively strong performance on high-level object-to-object spatial reasoning but fragility on interaction tasks, interpreted as evidence of missing 3D-aware interaction priors. The authors additionally synthesize 1.3M QA pairs for fine-tuning and report significant improvements after training on this data.
Significance. If the benchmark tasks validly isolate the claimed capabilities without synthesis artifacts, the work would usefully identify a concrete limitation in current VLMs for embodied settings and supply both an evaluation suite and scalable training data. The scale (21k test pairs, 1.3M training pairs) and the structural-vs-interaction framing are concrete contributions that could guide future model development.
major comments (2)
- [Abstract and §3 (Benchmark Construction)] The central claim that models exhibit 'fragility in interaction-oriented perception' (Abstract) rests on performance gaps in Affordance Prediction, Grasp Point Prediction, and Trajectory Prediction. The manuscript provides no description of how ground-truth labels for these tasks are derived from simulator state or 3D meshes, nor whether those labels are recoverable from the multi-view images supplied to the VLMs. If the labels require privileged information unavailable in the visual input, the observed gap may reflect task construction rather than model priors.
- [Abstract and §4 (Experiments)] No information is given on QA-pair validation, inter-annotator agreement, or statistical significance of the reported model differences (Abstract). Without these, the headline distinction between 'strong high-level spatial reasoning' and 'fragile interaction-oriented perception' cannot be verified as a reliable finding rather than an artifact of the synthesis pipeline.
minor comments (2)
- [§3] Clarify the exact number of scenes, views per scene, and image resolution used for each task category to allow reproducibility.
- [§5] The 1.3M training pairs are described only at high level; a breakdown by task category and any filtering steps would strengthen the data contribution.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback. We address each major comment below and will revise the manuscript to incorporate the requested clarifications on label derivation and validation procedures.
read point-by-point responses
-
Referee: [Abstract and §3 (Benchmark Construction)] The central claim that models exhibit 'fragility in interaction-oriented perception' (Abstract) rests on performance gaps in Affordance Prediction, Grasp Point Prediction, and Trajectory Prediction. The manuscript provides no description of how ground-truth labels for these tasks are derived from simulator state or 3D meshes, nor whether those labels are recoverable from the multi-view images supplied to the VLMs. If the labels require privileged information unavailable in the visual input, the observed gap may reflect task construction rather than model priors.
Authors: We agree that explicit details on label generation are necessary to rule out synthesis artifacts. The ground-truth labels for the interaction tasks are produced from the simulator's internal state (3D mesh vertices, object affordance metadata, and physics engine outputs) but are deliberately restricted to quantities that can be recovered from the provided multi-view RGB images alone; for example, grasp points are defined on visible surface patches and trajectories follow observable object motion in the rendered views. To address the concern, we will add a new subsection in §3 that describes the label extraction pipeline with pseudocode and provides side-by-side examples showing that each label is visually inferable from the image set supplied to the VLMs. This addition will strengthen the claim that the observed performance gap reflects model limitations rather than task construction. revision: yes
-
Referee: [Abstract and §4 (Experiments)] No information is given on QA-pair validation, inter-annotator agreement, or statistical significance of the reported model differences (Abstract). Without these, the headline distinction between 'strong high-level spatial reasoning' and 'fragile interaction-oriented perception' cannot be verified as a reliable finding rather than an artifact of the synthesis pipeline.
Authors: We acknowledge that the current manuscript lacks these details. Although the QA pairs are generated via deterministic rule-based templates from simulator state, we conducted a post-generation manual review on a stratified sample of 500 pairs (two authors independently verified correctness) and will report the agreement rate in the revision. We will also add statistical significance testing (paired Wilcoxon signed-rank tests with Bonferroni correction) comparing aggregate performance on the Spatial Structural Understanding versus Interaction-Oriented Perception groups, reporting p-values in §4 and the abstract. These changes will be included in the revised manuscript. revision: yes
Circularity Check
No circularity: benchmark and evaluations are externally constructed.
full rationale
The paper presents Embodied3DBench as an independent evaluation instrument consisting of 6 task categories and 21k QA pairs, with empirical results from testing 13 VLMs. No equations, fitted parameters, or derivations are described that reduce the performance claims to the benchmark construction itself. The 1.3M synthetic training pairs are introduced separately to address observed gaps rather than as a self-referential loop. The central claim of differential performance between structural and interaction tasks rests on direct model evaluations, not on any self-definition, fitted-input prediction, or load-bearing self-citation chain. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 6 task categories and generated QA pairs accurately measure low-level embodied spatial intelligence without introducing synthesis artifacts.
Reference graph
Works this paper leans on
-
[1]
https://openai.com
OpenAI. https://openai.com. Accessed: 2025-11-12. 7
2025
-
[2]
Kestrel: 3d multimodal llm for part-aware grounded description, 2025
Mahmoud Ahmed, Junjie Fei, Jian Ding, Eslam Mohamed Bakr, and Mohamed Elhoseiny. Kestrel: 3d multimodal llm for part-aware grounded description, 2025. 2
2025
-
[3]
Spatialbot: Precise spatial understanding with vision lan- guage models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision lan- guage models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498, 2025. 2
2025
-
[4]
Physx-3d: Physical-grounded 3d asset generation, 2025
Ziang Cao, Zhaoxi Chen, Liang Pan, and Ziwei Liu. Physx-3d: Physical-grounded 3d asset generation, 2025. 2
2025
-
[5]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465, 2024. 2, 3
2024
-
[6]
Clustering of trajectories based on hausdorff distance
Jinyang Chen, Rangding Wang, Liangxu Liu, and Jiatao Song. Clustering of trajectories based on hausdorff distance. In2011 international conference on electronics, communications and control (icecc), pages 1940–1944. IEEE, 2011. 6
1940
-
[7]
Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation, 2025
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, Weiliang Deng, Yubin Guo, Tian Nian, Xuanbing Xie, Qiangyu Chen, Kailun Su, Tianling Xu, Guodong Liu, Mengkang Hu, Huan ang Gao, Kaixuan Wang, Zhixuan Liang, Yusen Qin, Xiaokang Yang, Ping Luo, and Yao Mu. Robotwin 2.0: A scalable d...
2025
-
[8]
Clutterdexgrasp: A sim-to-real system for general dexterous grasping in cluttered scenes
Zeyuan Chen, Qiyang Yan, Yuanpei Chen, Tianhao Wu, Jiyao Zhang, Zihan Ding, Jinzhou Li, Yaodong Yang, and Hao Dong. Clutterdexgrasp: A sim-to-real system for general dexterous grasping in cluttered scenes. InConference on Robot Learning, pages 885–905. PMLR, 2025. 2
2025
-
[9]
Spatialrgpt: Grounded spatial reasoning in vision- language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision- language models. InAdvances in Neural Information Processing Systems, pages 135062–135093. Curran Associates, Inc., 2024. 3
2024
-
[10]
Singh, Siddharth Srivastava, Krishna Murthy Jataval- labhula, and K
Tushar Choudhary, Vikrant Dewangan, Shivam Chandhok, Shubham Priyadar- shan, Anushka Jain, Arun K. Singh, Siddharth Srivastava, Krishna Murthy Jataval- labhula, and K. Madhava Krishna. Talk2bev: Language-enhanced bird’s-eye view maps for autonomous driving. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 16345–16352, 2024. 2
2024
-
[11]
Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities, 2025
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, and Noveen Sachdeva et al. Gemini 2.5: Pushing the frontier with advanced reason- ing, multimodality, long context, and next generation agentic capabilities, 2025. 3
2025
-
[12]
Domain randomization-enhanced depth simulation and restoration for perceiving and grasping specular and transparent objects
Qiyu Dai, Jiyao Zhang, Qiwei Li, Tianhao Wu, Hao Dong, Ziyuan Liu, Ping Tan, and He Wang. Domain randomization-enhanced depth simulation and restoration for perceiving and grasping specular and transparent objects. In European Conference on Computer Vision, pages 374–391. Springer, 2022. 2
2022
-
[13]
EmbSpatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. EmbSpatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 346–355, Bangkok, Thailand, 2024. Association for Computationa...
2024
-
[14]
Gemini robotics: Bringing ai into the physical world,
Gemini Robotics Team et al. Gemini robotics: Bringing ai into the physical world,
-
[15]
Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction, 2025
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, Hongyu Xu, Justin Theiss, Tianlong Chen, Jiachen Li, Zhengzhong Tu, Zhangyang Wang, and Rakesh Ranjan. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction, 2025. 2
2025
-
[16]
Smith, Wei-Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive, 2024. 2, 3
2024
-
[17]
Yuzheng Gao, Yuxing Long, Lei Kang, Yuchong Guo, Ziyan Yu, Shangqing Mao, Jiyao Zhang, Ruihai Wu, Dongjiang Li, Hui Shen, et al. Realappliance: Let high- fidelity appliance assets controllable and workable as aligned real manuals.arXiv preprint arXiv:2512.00287, 2025. 2
-
[18]
Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts
Haoran Geng, Helin Xu, Chengyang Zhao, Chao Xu, Li Yi, Siyuan Huang, and He Wang. Gapartnet: Cross-category domain-generalizable object perception and manipulation via generalizable and actionable parts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7081–7091, 2023. 4
2023
-
[19]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report. arXiv preprint arXiv:2505.07062, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Surds: Benchmarking spatial understanding and reasoning in driving scenarios with vision language models, 2025
Xianda Guo, Ruijun Zhang, Yiqun Duan, Yuhang He, Dujun Nie, Wenke Huang, Chenming Zhang, Shuai Liu, Hao Zhao, and Long Chen. Surds: Benchmarking spatial understanding and reasoning in driving scenarios with vision language models, 2025. 2
2025
-
[21]
Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation, 2025
Songhao Han, Boxiang Qiu, Yue Liao, Siyuan Huang, Chen Gao, Shuicheng Yan, and Si Liu. Robocerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation, 2025. 4
2025
-
[22]
Omnivla: An omni-modal vision-language-action model for robot navigation, 2025
Noriaki Hirose, Catherine Glossop, Dhruv Shah, and Sergey Levine. Omnivla: An omni-modal vision-language-action model for robot navigation, 2025. 2
2025
-
[23]
Gensim2: Scaling robot data generation with multi-modal and reasoning llms, 2024
Pu Hua, Minghuan Liu, Annabella Macaluso, Yunfeng Lin, Weinan Zhang, Huazhe Xu, and Lirui Wang. Gensim2: Scaling robot data generation with multi-modal and reasoning llms, 2024. 5
2024
-
[24]
A3vlm: Actionable articulation-aware vision language model, 2024
Siyuan Huang, Haonan Chang, Yuhan Liu, Yimeng Zhu, Hao Dong, Peng Gao, Abdeslam Boularias, and Hongsheng Li. A3vlm: Actionable articulation-aware vision language model, 2024. 4
2024
-
[25]
Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipu- lation, 2024
Wenlong Huang, Chen Wang, Yunzhu Li, Ruohan Zhang, and Li Fei-Fei. Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipu- lation, 2024. 2
2024
-
[26]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 7 Jiyao Zhang, Mingxu Zhang, Yitong Peng, Haoxuan Liu, Chenshuo Wang, Yuxing Long, Haoyang Huang, Dongjiang Li, Nan Duan, Hui Shen, and Hao Dong
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Mechanistic interpretability for steering vision-language-action models, 2025
Bear Häon, Kaylene Stocking, Ian Chuang, and Claire Tomlin. Mechanistic interpretability for steering vision-language-action models, 2025. 2
2025
-
[28]
Robobrain: A unified brain model for robotic manipulation from abstract to concrete
Yuheng Ji, Huajie Tan, Jiayu Shi, Xiaoshuai Hao, Yuan Zhang, Hengyuan Zhang, Pengwei Wang, Mengdi Zhao, Yao Mu, Pengju An, Xinda Xue, Qinghang Su, Huaihai Lyu, Xiaolong Zheng, Jiaming Liu, Zhongyuan Wang, and Shanghang Zhang. Robobrain: A unified brain model for robotic manipulation from abstract to concrete. InProceedings of the IEEE/CVF Conference on Co...
2025
-
[29]
Controlvla: Few-shot object-centric adaptation for pre-trained vision-language- action models, 2025
Puhao Li, Yingying Wu, Ziheng Xi, Wanlin Li, Yuzhe Huang, Zhiyuan Zhang, Yinghan Chen, Jianan Wang, Song-Chun Zhu, Tengyu Liu, and Siyuan Huang. Controlvla: Few-shot object-centric adaptation for pre-trained vision-language- action models, 2025. 2
2025
-
[30]
Evo-0: Vision-language-action model with implicit spatial under- standing, 2025
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, Yuxin Du, Jiting Liu, Encheng Gu, and Bo Zhao. Evo-0: Vision-language-action model with implicit spatial under- standing, 2025. 2
2025
-
[31]
Rgbgrasp: Image-based object grasping by capturing multiple views during robot arm movement with neural radiance fields.IEEE Robotics and Automation Letters, 9(6):6012–6019, 2024
Chang Liu, Kejian Shi, Kaichen Zhou, Haoxiao Wang, Jiyao Zhang, and Hao Dong. Rgbgrasp: Image-based object grasping by capturing multiple views during robot arm movement with neural radiance fields.IEEE Robotics and Automation Letters, 9(6):6012–6019, 2024. 2
2024
-
[32]
Checkmanual: A new challenge and benchmark for manual-based appli- ance manipulation
Yuxing Long, Jiyao Zhang, Mingjie Pan, Tianshu Wu, Taewhan Kim, and Hao Dong. Checkmanual: A new challenge and benchmark for manual-based appli- ance manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22595–22604, 2025. 2
2025
-
[33]
Geal: General- izable 3d affordance learning with cross-modal consistency
Dongyue Lu, Lingdong Kong, Tianxin Huang, and Gim Hee Lee. Geal: General- izable 3d affordance learning with cross-modal consistency. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1680–1690, 2025. 2
2025
-
[34]
Spatiallm: Training large language models for structured indoor modeling, 2025
Yongsen Mao, Junhao Zhong, Chuan Fang, Jia Zheng, Rui Tang, Hao Zhu, Ping Tan, and Zihan Zhou. Spatiallm: Training large language models for structured indoor modeling, 2025. 2
2025
-
[35]
Chang, Li Yi, Subarna Tripathi, Leonidas J
Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. Partnet: A large-scale benchmark for fine-grained and hierarchical part-level 3d object understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. 4
2019
-
[36]
Learning object affordances: From sensory–motor coordination to imitation
Luis Montesano, Manuel Lopes, Alexandre Bernardino, and JosÉ Santos-Victor. Learning object affordances: From sensory–motor coordination to imitation. IEEE Transactions on Robotics, 24(1):15–26, 2008. 4
2008
-
[37]
3d bounding box estimation using deep learning and geometry
Arsalan Mousavian, Dragomir Anguelov, John Flynn, and Jana Kosecka. 3d bounding box estimation using deep learning and geometry. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7074–7082,
-
[38]
Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints
Mingjie Pan, Jiyao Zhang, Tianshu Wu, Yinghao Zhao, Wenlong Gao, and Hao Dong. Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17359–17369, 2025. 2
2025
-
[39]
Metaspatial: Reinforcing 3d spatial reasoning in vlms for the metaverse, 2025
Zhenyu Pan and Han Liu. Metaspatial: Reinforcing 3d spatial reasoning in vlms for the metaverse, 2025. 2
2025
-
[40]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. InAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2017. 6
2017
-
[41]
Sofar: Language- grounded orientation bridges spatial reasoning and object manipulation, 2025
Zekun Qi, Wenyao Zhang, Yufei Ding, Runpei Dong, Xinqiang Yu, Jingwen Li, Lingyun Xu, Baoyu Li, Xialin He, Guofan Fan, Jiazhao Zhang, Jiawei He, Jiayuan Gu, Xin Jin, Kaisheng Ma, Zhizheng Zhang, He Wang, and Li Yi. Sofar: Language- grounded orientation bridges spatial reasoning and object manipulation, 2025. 4
2025
-
[42]
Spatialvla: Exploring spatial representations for visual-language-action model, 2025
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Exploring spatial representations for visual-language-action model, 2025. 2
2025
-
[43]
Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko
Arijit Ray, Jiafei Duan, Ellis Brown, Reuben Tan, Dina Bashkirova, Rose Hen- drix, Kiana Ehsani, Aniruddha Kemb havi, Bryan A. Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko. Sat: Dynamic spatial aptitude training for multimodal language models, 2025. 3
2025
-
[44]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InComputer Vision – ECCV 2024, pages 256–274, Cham, 2025. Springer Nature Switzerland. 2
2024
-
[45]
Robospatial: Teaching spatial understanding to 2d and 3d vision- language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospatial: Teaching spatial understanding to 2d and 3d vision- language models for robotics. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15768–15780, 2025. 2, 3, 4
2025
-
[46]
JoyAI-Image: Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
Lin Song, Wenbo Li, Guoqing Ma, Wei Tang, Bo Wang, Yuan Zhang, Yijun Yang, Yicheng Xiao, Jianhui Liu, Yanbing Zhang, et al. Awaking spatial intel- ligence in unified multimodal understanding and generation.arXiv preprint arXiv:2605.04128, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
Robobrain 2.0 technical report, 2025
BAAI RoboBrain Team, Mingyu Cao, Huajie Tan, Yuheng Ji, Xiansheng Chen, Minglan Lin, Zhiyu Li, Zhou Cao, Pengwei Wang, Enshen Zhou, Yi Han, Yingbo Tang, Xiangqi Xu, Wei Guo, Yaoxu Lyu, Yijie Xu, Jiayu Shi, Mengfei Du, Cheng Chi, Mengdi Zhao, Xiaoshuai Hao, Junkai Zhao, Xiaojie Zhang, Shanyu Rong, Huaihai Lyu, Zhengliang Cai, Yankai Fu, Ning Chen, Bolun Zh...
2025
-
[48]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Drivevlm: The convergence of autonomous driving and large vision-language models, 2024
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. Drivevlm: The convergence of autonomous driving and large vision-language models, 2024. 2
2024
-
[50]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms, 2024
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai Charitha Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, Ziteng Wang, Rob Fergus, Yann LeCun, and Saining Xie. Cambrian-1: A fully open, vision-centric exploration of multimodal llms, 2024. 2, 3
2024
-
[51]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025. 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Omniear: Bench- marking agent reasoning in embodied tasks, 2025
Zixuan Wang, Dingming Li, Hongxing Li, Shuo Chen, Yuchen Yan, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Omniear: Bench- marking agent reasoning in embodied tasks, 2025. 4
2025
-
[54]
Learn- ing score-based grasping primitive for human-assisting dexterous grasping
Tianhao Wu, Mingdong Wu, Jiyao Zhang, Yunchong Gan, and Hao Dong. Learn- ing score-based grasping primitive for human-assisting dexterous grasping. Advances in Neural Information Processing Systems, 36:22132–22150, 2023. 2
2023
-
[55]
Karlsson, Ziming Wang, Tengtao Song, Qi Zhu, Jun Song, Zhiming Ding, and Bo Zheng
Xinrun Xu, Pi Bu, Ye Wang, Börje F. Karlsson, Ziming Wang, Tengtao Song, Qi Zhu, Jun Song, Zhiming Ding, and Bo Zheng. Deepphy: Benchmarking agentic vlms on physical reasoning, 2025. 2
2025
-
[56]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[57]
Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie
Jihan Yang, Shusheng Yang, Anjali W. Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces, 2025. 3
2025
-
[58]
The dawn of lmms: Preliminary explorations with gpt- 4v(ision), 2023
Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu, and Lijuan Wang. The dawn of lmms: Preliminary explorations with gpt- 4v(ision), 2023. 3
2023
-
[59]
Correctnav: Self-correction flywheel empowers vision- language-action navigation model
Zhuoyuan Yu, Yuxing Long, Zihan Yang, Chengyan Zeng, Hongwei Fan, Jiyao Zhang, and Hao Dong. Correctnav: Self-correction flywheel empowers vision- language-action navigation model. InProceedings of the AAAI Conference on Artificial Intelligence, pages 18737–18745, 2026. 2
2026
-
[60]
Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation, 2025
Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, and Xing Wei. Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation, 2025. 2
2025
-
[61]
Lvdiffusor: Distilling functional rearrangement priors from large models into diffusor.IEEE Robotics and Automation Letters, 9(10):8258–8265, 2024
Yiming Zeng, Mingdong Wu, Long Yang, Jiyao Zhang, Hao Ding, Hui Cheng, and Hao Dong. Lvdiffusor: Distilling functional rearrangement priors from large models into diffusor.IEEE Robotics and Automation Letters, 9(10):8258–8265, 2024. 2
2024
-
[62]
Cadgrasp: Learning contact and collision aware general dexterous grasping in cluttered scenes
Jiyao Zhang, Zhiyuan Ma, Tianhao Wu, Zeyuan Chen, and Hao Dong. Cadgrasp: Learning contact and collision aware general dexterous grasping in cluttered scenes. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 2
-
[63]
Generative category-level object pose estimation via diffusion models.Advances in Neural Information Processing Systems, 36:54627–54644, 2023
Jiyao Zhang, Mingdong Wu, and Hao Dong. Generative category-level object pose estimation via diffusion models.Advances in Neural Information Processing Systems, 36:54627–54644, 2023. 2
2023
-
[64]
Omni6dpose: A benchmark and model for universal 6d object pose estimation and tracking
Jiyao Zhang, Weiyao Huang, Bo Peng, Mingdong Wu, Fei Hu, Zijian Chen, Bo Zhao, and Hao Dong. Omni6dpose: A benchmark and model for universal 6d object pose estimation and tracking. InEuropean Conference on Computer Vision, pages 199–216. Springer, 2024. 2
2024
-
[65]
Up-vla: A unified understanding and prediction model for embodied agent,
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent,
-
[66]
Jiyao Zhang, Weiyao Huang, Bo Peng, Mingdong Wu, Fei Hu, Zijian Chen, Bo Zhao, and Hao Dong. Omni6dpose: A benchmark and model for universal 6d Embodied3DBench: Benchmarking Low-Level Embodied Spatial Intelligence of Vision Language Models object pose estimation and tracking. InComputer Vision – ECCV 2024, pages 199–216, Cham, 2025. Springer Nature Switzerland. 4
2024
-
[67]
Embodied navigation foundation model, 2025
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, Yuxin Fan, Wenjun Li, Zhibo Chen, Fei Gao, Qi Wu, Zhizheng Zhang, and He Wang. Embodied navigation foundation model, 2025. 2
2025
-
[68]
HiPolicy: Hierarchical Multi-Frequency Action Chunking for Policy Learning
Jiyao Zhang, Zimu Han, Junhan Wang, Xionghao Wu, Shihong Lin, Jinzhou Li, Hongwei Fan, Ruihai Wu, Dongjiang Li, and Hao Dong. Hipolicy: Hier- archical multi-frequency action chunking for policy learning.arXiv preprint arXiv:2604.06067, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[69]
𝑛𝑎𝑣𝑎 3: Understanding any instruction, navigating anywhere, finding anything, 2025
Lingfeng Zhang, Xiaoshuai Hao, Yingbo Tang, Haoxiang Fu, Xinyu Zheng, Peng- wei Wang, Zhongyuan Wang, Wenbo Ding, and Shanghang Zhang. 𝑛𝑎𝑣𝑎 3: Understanding any instruction, navigating anywhere, finding anything, 2025. 2
2025
-
[70]
Mem2ego: Empowering vision-language models with global-to- ego memory for long-horizon embodied navigation, 2025
Lingfeng Zhang, Yuecheng Liu, Zhanguang Zhang, Matin Aghaei, Yaochen Hu, Hongjian Gu, Mohammad Ali Alomrani, David Gamaliel Arcos Bravo, Raika Karimi, Atia Hamidizadeh, Haoping Xu, Guowei Huang, Zhanpeng Zhang, Tong- tong Cao, Weichao Qiu, Xingyue Quan, Jianye Hao, Yuzheng Zhuang, and Yingxue Zhang. Mem2ego: Empowering vision-language models with global-t...
2025
-
[71]
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models, 2025
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zh...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.