Mask the Target: A Plug-and-Play Regularizer Against LoRA Forgetting
Pith reviewed 2026-06-29 07:34 UTC · model grok-4.3
The pith
Removing the ground-truth token before KL regularization lets LoRA adapt new tasks while better preserving base model preferences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By excluding the ground-truth token from both distributions, renormalizing the rest, and restricting KL regularization to the non-target vocabulary, the method maintains the base model's relative preferences among alternative tokens and thereby reduces forgetting during LoRA adaptation on distributions that differ substantially from the original training data.
What carries the argument
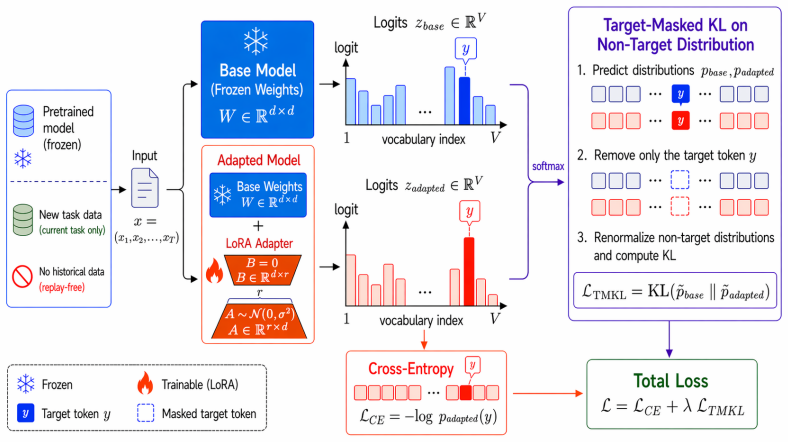
Target-masked KL regularizer: drops the ground-truth token from base and adapted softmax outputs, renormalizes the remaining probabilities, and applies KL only over those non-target entries.
If this is right
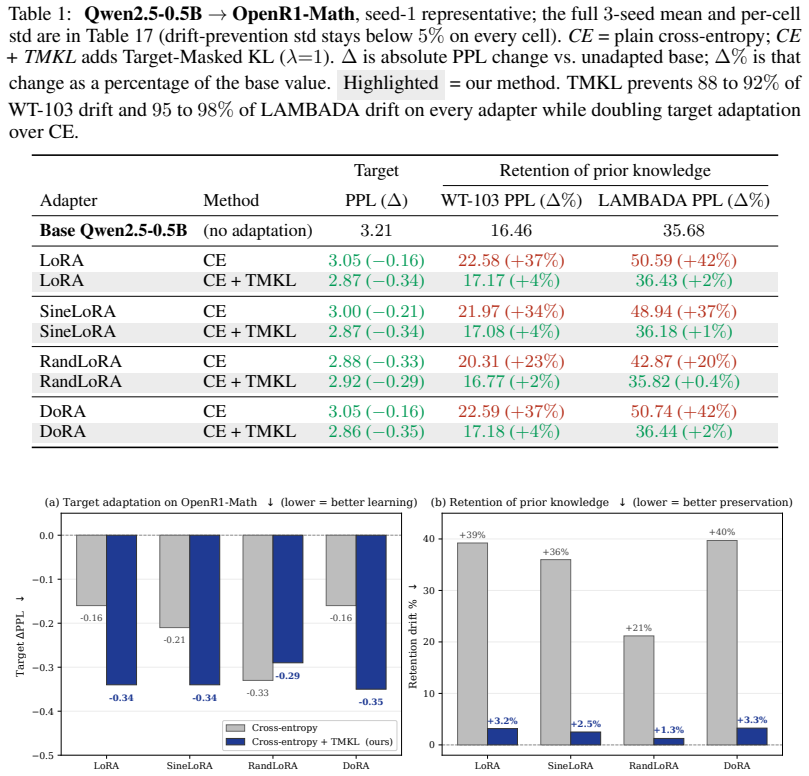
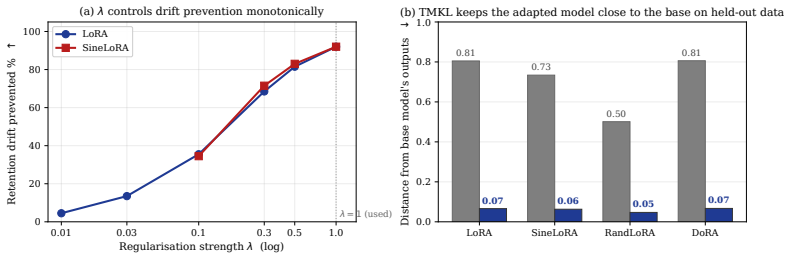
- The regularizer improves the new-learning versus forgetting frontier across tested LoRA variants and model backbones when adaptation distributions differ substantially from pretraining.
- No replay data, model architecture changes, or inference-time cost is required because the regularizer operates only at the loss level.
- The same plug-in can be added to any existing LoRA training pipeline without redesigning adapters.
- Forgetting reduction holds in replay-free settings where original training or alignment data cannot be accessed.
Where Pith is reading between the lines
- The result implies that direct opposition on the target token itself is a primary source of forgetting in standard output-space regularization.
- The masking step could be tested on full fine-tuning or other parameter-efficient methods to check whether the same output-space intervention generalizes.
- Combining the regularizer with limited replay when some original data is available might produce additive gains, though the paper does not examine this case.
- The approach suggests that lightweight output interventions can be a practical lever for controlling knowledge retention during LLM updates.
Load-bearing premise
Removing the ground-truth token and renormalizing leaves the base model's relative preferences among the remaining tokens unchanged and does not oppose the adaptation signal from cross-entropy loss.
What would settle it
On a benchmark with highly divergent adaptation data, compare base-model retention metrics (for example, performance on held-out original tasks) between standard LoRA and the regularized version; if the regularized version shows no improvement or worse retention, the claim is falsified.
Figures
read the original abstract
Low-Rank Adaptation (LoRA) has become one of the most widely used fine-tuning mechanisms for adapting large language models to new domains, tasks, and users. Yet adaptation performance alone can obscure an important failure mode: LoRA updates may improve performance on the target distribution while degrading prior capabilities learned during pretraining and alignment. We show that this forgetting becomes especially severe when the adaptation distribution differs substantially from the models original training or alignment distributions. The challenge is amplified in practical settings, where the original training and alignment data are typically unavailable. Motivated by this constraint, we study how LoRA based adaptation balances new learning against forgetting in a replay-free setting, and introduce a simple output space regularizer that can be added directly to existing training pipelines. Our method removes the ground-truth token from both the base and adapted model distributions, renormalizes the remaining probabilities, and applies KL regularization only over the non-target vocabulary. This preserves the base models relative preferences among alternative tokens without directly opposing the cross-entropy signal required for adaptation. As the regularizer acts only at the loss level, it requires no replay data, architectural changes, adapter redesign, or inference-time overhead, and can be applied directly to existing LoRA variants. Across all LoRA variants tested and across various backbones, our method improves the frontier between new learning and forgetting when the adaptation distribution differs substantially from the base models original training or alignment distributions, suggesting a broadly applicable route toward more reliable LLM updating.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a plug-and-play output-space regularizer for LoRA fine-tuning of LLMs. The method masks the ground-truth target token from the base and adapted next-token distributions, renormalizes the remaining probabilities, and applies KL divergence only over the non-target vocabulary. This is claimed to mitigate catastrophic forgetting of pretraining and alignment capabilities in a replay-free setting, improving the learning-forgetting frontier when adaptation data differs substantially from the original distributions. The regularizer requires no architectural changes, replay data, or inference overhead and is asserted to act without directly opposing the cross-entropy adaptation signal.
Significance. If the empirical claims hold after verification, the approach supplies a lightweight, broadly applicable loss-level addition to existing LoRA pipelines that addresses a common practical failure mode in LLM adaptation without replay or redesign. The simplicity and compatibility with multiple LoRA variants and backbones would make it a useful contribution to reliable model updating.
major comments (2)
- [Abstract] Abstract (method description): The claim that the regularizer 'preserves the base model’s relative preferences among alternative tokens without directly opposing the cross-entropy signal required for adaptation' lacks supporting analysis. Defining q_b(v) = p_b(v)/(1-p_b(t)) and q_a(v) = p_a(v)/(1-p_a(t)) for v ≠ t makes the KL(q_b || q_a) term an explicit function of p_a(t); its gradient with respect to the target logit is therefore nonzero in general and can couple to the CE loss. No derivative expansion or ablation isolating this effect is referenced.
- [Abstract] Abstract (empirical claim): The statement that the method 'improves the frontier between new learning and forgetting' across 'all LoRA variants tested and across various backbones' is presented without reference to statistical significance, number of random seeds, hyperparameter controls, or ablation isolating the regularizer from other training choices. These details are load-bearing for the central empirical claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify areas where additional rigor can strengthen the presentation of both the method and the empirical results. We address each major comment below and will incorporate the requested clarifications and analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (method description): The claim that the regularizer 'preserves the base model’s relative preferences among alternative tokens without directly opposing the cross-entropy signal required for adaptation' lacks supporting analysis. Defining q_b(v) = p_b(v)/(1-p_b(t)) and q_a(v) = p_a(v)/(1-p_a(t)) for v ≠ t makes the KL(q_b || q_a) term an explicit function of p_a(t); its gradient with respect to the target logit is therefore nonzero in general and can couple to the CE loss. No derivative expansion or ablation isolating this effect is referenced.
Authors: We acknowledge the referee's observation that the normalization factor introduces a dependence on p_a(t), so the gradient of the KL term w.r.t. the target logit is nonzero. The original phrasing intended to convey that the regularizer operates on the conditional distribution over non-target tokens and therefore does not directly penalize increases in the target probability (the primary adaptation signal remains the CE loss). Nevertheless, we agree that a precise characterization of the coupling is needed. In the revision we will add (i) an explicit derivative expansion of the regularizer gradient w.r.t. the target logit and (ii) an ablation that isolates the contribution of this term from the CE signal. revision: yes
-
Referee: [Abstract] Abstract (empirical claim): The statement that the method 'improves the frontier between new learning and forgetting' across 'all LoRA variants tested and across various backbones' is presented without reference to statistical significance, number of random seeds, hyperparameter controls, or ablation isolating the regularizer from other training choices. These details are load-bearing for the central empirical claim.
Authors: We agree that the central empirical claim requires stronger statistical grounding. In the revised manuscript we will report results aggregated over multiple random seeds, include statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values), document the hyperparameter search protocol and controls, and add an ablation that isolates the regularizer from other training decisions such as learning-rate schedules and LoRA rank choices. revision: yes
Circularity Check
No circularity: regularizer defined independently; empirical claims not reduced to inputs by construction
full rationale
The paper defines its output-space regularizer explicitly by masking the ground-truth token, renormalizing the remaining distribution, and applying KL divergence only on non-target tokens. This construction is stated as an independent addition to the cross-entropy loss and does not reference or depend on the downstream evaluation metrics for new learning or forgetting. No derivation chain equates a claimed result to a fitted parameter or self-citation; the improvement is presented as an empirical observation across LoRA variants rather than a mathematical identity. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the text. The central premise therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors
Imtiaz Ahmed, Sadman Islam, Partha Protim Datta, Imran Kabir, Md Naseef Ur Rahman Chowdhury, and Ahshanul Haque. Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors. 2025
2025
-
[2]
Zhang, Hemanth Saratchandran, Anton van den Hengel, and Ehsan Abbasnejad
Paul Albert, Frederic Z. Zhang, Hemanth Saratchandran, Anton van den Hengel, and Ehsan Abbasnejad. Towards Higher Effective Rank in Parameter-efficient Fine-tuning using Khatri–Rao Product, August 2025. URLhttp://arxiv.org/abs/2508.00230. arXiv:2508.00230 [cs]
-
[3]
Zhang, Hemanth Saratchandran, Cristian Rodriguez-Opazo, Anton van den Hengel, and Ehsan Abbasnejad
Paul Albert, Frederic Z. Zhang, Hemanth Saratchandran, Cristian Rodriguez-Opazo, Anton van den Hengel, and Ehsan Abbasnejad. RandLoRA: Full-rank parameter-efficient fine-tuning of large models, March 2025. URLhttp://arxiv.org/abs/2502.00987. arXiv:2502.00987 [cs]
-
[4]
PLD: A Choice-Theoretic List-Wise Knowledge Distillation,
Ejafa Bassam, Dawei Zhu, and Kaigui Bian. PLD: A Choice-Theoretic List-Wise Knowledge Distillation,
-
[5]
PLD: A Choice-Theoretic List-Wise Knowledge Distillation
URLhttps://arxiv.org/abs/2506.12542. Version Number: 3
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Elad Ben-Zaken, Shauli Ravfogel, and Yoav Goldberg. BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models, September 2022. URL http://arxiv.org/abs/2106. 10199. arXiv:2106.10199 [cs]
-
[7]
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, Cody Blakeney, and John P. Cunningham. LoRA Learns Less and Forgets Less, September 2024. URL http://arxiv.org/abs/ 2405.09673. arXiv:2405.09673 [cs] version: 2
-
[8]
Dark Experience for General Continual Learning: a Strong, Simple Baseline, October 2020
Pietro Buzzega, Matteo Boschini, Angelo Porrello, Davide Abati, and Simone Calderara. Dark Experience for General Continual Learning: a Strong, Simple Baseline, October 2020. URL http://arxiv.org/ abs/2004.07211. arXiv:2004.07211 [stat]
-
[9]
Efficient Lifelong Learning with A-GEM
Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient Lifelong Learning with A-GEM, January 2019. URL http://arxiv.org/abs/1812.00420. arXiv:1812.00420 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[10]
ccdv/pubmed: Pubmed abstracts and articles
Cohan, Arman and Dernoncourt, Franck and Kim, Doo Soon and Bui, Trung and Kim, Seokhwan and Chang, Walter and Goharian, Nazli. ccdv/pubmed: Pubmed abstracts and articles. https: //huggingface.co/datasets/ccdv/pubmed-summarization, 2018. HuggingFace mirror of the PubMed long-document summarisation corpus used here as a biomedical adaptation target
2018
-
[11]
John Wiley & Sons, 1999
Thomas M Cover.Elements of information theory. John Wiley & Sons, 1999
1999
-
[12]
Mistral-splade: Llms for better learned sparse retrieval.arXiv preprint arXiv:2408.11119, 2024
Meet Doshi, Vishwajeet Kumar, Rudra Murthy, Jaydeep Sen, et al. Mistral-splade: Llms for better learned sparse retrieval.arXiv preprint arXiv:2408.11119, 2024
-
[13]
Arthur Douillard, Alexandre Rame, Guillaume Couairon, and Matthieu Cord. DyTox: Transformers for Continual Learning with DYnamic TOken eXpansion. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9275–9285, New Orleans, LA, USA, June 2022. IEEE. ISBN 978-1-6654-6946-3. doi: 10.1109/CVPR52688.2022.00907. URL https://ieeexp...
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
-
[16]
CL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning, May 2025
Jiangpeng He, Zhihao Duan, and Fengqing Zhu. CL-LoRA: Continual Low-Rank Adaptation for Rehearsal-Free Class-Incremental Learning, May 2025. URL http://arxiv.org/abs/2505.24816. arXiv:2505.24816 [cs]. 10
-
[17]
Distilling the Knowledge in a Neural Network, March
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the Knowledge in a Neural Network, March
-
[18]
Distilling the Knowledge in a Neural Network
URLhttp://arxiv.org/abs/1503.02531. arXiv:1503.02531 [stat]
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Parameter-Efficient Transfer Learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-Efficient Transfer Learning for NLP, June 2019. URLhttp://arxiv.org/abs/1902.00751. arXiv:1902.00751 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
STABLE: Gated continual learning for large language models.arXiv preprint arXiv:2510.16089, 2025
William Hoy and Nurcin Celik. STABLE: Gated continual learning for large language models.arXiv preprint arXiv:2510.16089, 2025
-
[21]
Safe LoRA: The silver lining of reducing safety risks when finetuning large language models
Chia-Yi Hsu, Yu-Lin Tsai, Chih-Hsun Lin, Pin-Yu Chen, Chia-Mu Yu, and Chun-Ying Huang. Safe LoRA: The silver lining of reducing safety risks when finetuning large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[22]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models, October 2021. URL http://arxiv.org/abs/2106.09685. arXiv:2106.09685 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[23]
Chengsong Huang, Qian Liu, Min Lin, et al. LoraHub: Efficient cross-task generalization via dynamic lora composition.arXiv preprint arXiv:2307.13269, 2023
-
[24]
Knowledge Distillation from A Stronger Teacher, December 2022
Tao Huang, Shan You, Fei Wang, Chen Qian, and Chang Xu. Knowledge Distillation from A Stronger Teacher, December 2022. URLhttp://arxiv.org/abs/2205.10536. arXiv:2205.10536 [cs]
-
[25]
OpenR1-Math-220k: Math reasoning dataset
HuggingFace Open-R1 Team. OpenR1-Math-220k: Math reasoning dataset. https://huggingface. co/datasets/open-r1/OpenR1-Math-220k , 2025. Released January 2025; post-Qwen2.5-cutoff math- reasoning corpus
2025
-
[26]
Efficient learning with sine-activated low-rank matrices, 2025
Yiping Ji, Hemanth Saratchandran, Cameron Gordon, Zeyu Zhang, and Simon Lucey. Efficient learning with sine-activated low-rank matrices, 2025. URLhttps://arxiv.org/abs/2403.19243
-
[27]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Clau- dia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural net- works.Proceedings of the National Academy of Sciences, 114(13):3...
- [28]
-
[29]
Kopiczko, Tijmen Blankevoort, and Yuki M
Dawid J. Kopiczko, Tijmen Blankevoort, and Yuki M. Asano. VeRA: Vector-based Random Matrix Adaptation, January 2024. URLhttp://arxiv.org/abs/2310.11454. arXiv:2310.11454 [cs]
-
[30]
The Power of Scale for Parameter-Efficient Prompt Tuning
Brian Lester, Rami Al-Rfou, and Noah Constant. The Power of Scale for Parameter-Efficient Prompt Tuning, September 2021. URLhttp://arxiv.org/abs/2104.08691. arXiv:2104.08691 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[31]
NTCE-KD: Non-target-class-enhanced knowledge distillation.Sensors, 24(11):3617, 2024
Chuan Li, Xiao Teng, Yan Ding, and Long Lan. NTCE-KD: Non-target-class-enhanced knowledge distillation.Sensors, 24(11):3617, 2024
2024
-
[32]
SaLoRA: Safety-alignment preserved low-rank adaptation
Mingjie Li, Wai Man Si, Michael Backes, Yang Zhang, and Yisen Wang. SaLoRA: Safety-alignment preserved low-rank adaptation. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[33]
Prefix-Tuning: Optimizing Continuous Prompts for Generation, January
Xiang Lisa Li and Percy Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation, January
-
[34]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
URLhttp://arxiv.org/abs/2101.00190. arXiv:2101.00190 [cs]
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Zhizhong Li and Derek Hoiem. Learning without Forgetting, February 2017. URL http://arxiv.org/ abs/1606.09282. arXiv:1606.09282 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
InfLoRA: Interference-free low-rank adaptation for continual learning
Yan-Shuo Liang and Wu-Jun Li. InfLoRA: Interference-free low-rank adaptation for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[37]
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA: Weight-Decomposed Low-Rank Adaptation, July 2024. URL http://arxiv.org/abs/2402.09353. arXiv:2402.09353 [cs]. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Controlled low-rank adaptation with subspace regularization for continued training on large language models
Yuheng Lu, Bingshuo Qian, Caixia Yuan, Huixing Jiang, and Xiaojie Wang. Controlled low-rank adaptation with subspace regularization for continued training on large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 19165– 19181, 2025
2025
-
[39]
PEFT: State-of-the-art parameter-efficient fine-tuning
Sourab Mangrulkar, Sylvain Gugger, Lysandre Debut, Younes Belkada, Sayak Paul, and Benjamin Bossan. PEFT: State-of-the-art parameter-efficient fine-tuning. https://github.com/huggingface/peft, 2022
2022
-
[40]
Michael McCloskey and Neal J. Cohen. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. InPsychology of Learning and Motivation, volume 24, pages 109–165. Elsevier, 1989. ISBN 978-0-12-543324-2. doi: 10.1016/S0079-7421(08)60536-8. URL https:// linkinghub.elsevier.com/retrieve/pii/S0079742108605368
-
[41]
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. PiSSA: Principal Singular Values and Singular Vec- tors Adaptation of Large Language Models, April 2025. URL http://arxiv.org/abs/2404.02948. arXiv:2404.02948 [cs]
-
[42]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In International Conference on Learning Representations (ICLR), 2017
2017
-
[43]
Learning from the undesirable: Robust adaptation of language models without forgetting
Yunhun Nam, Jaehyung Kim, and Jongheon Jeong. Learning from the undesirable: Robust adaptation of language models without forgetting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 32537–32545, 2026
2026
-
[44]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL), 2016
2016
-
[45]
LFPT5: A unified framework for lifelong few-shot language learning based on prompt tuning of t5
Chengwei Qin and Shafiq Joty. LFPT5: A unified framework for lifelong few-shot language learning based on prompt tuning of t5. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[46]
Tahaei, Hyock Ju Kwon, Ali Ghodsi, Boxing Chen, and Mehdi Rezagholizadeh
Hossein Rajabzadeh, Mojtaba Valipour, Tianshu Zhu, Marzieh S. Tahaei, Hyock Ju Kwon, Ali Ghodsi, Boxing Chen, and Mehdi Rezagholizadeh. QDyLoRA: Quantized Dynamic Low-Rank Adaptation for Efficient Large Language Model Tuning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 712–718, Miami, Flo...
-
[47]
Matthew Riemer, Erik Miehling, Miao Liu, Djallel Bouneffouf, and Murray Campbell. The effectiveness of approximate regularized replay for efficient supervised fine-tuning of large language models.arXiv preprint arXiv:2512.22337, 2025
-
[48]
LoRA vs Full Fine- tuning: An Illusion of Equivalence, October 2025
Reece Shuttleworth, Jacob Andreas, Antonio Torralba, and Pratyusha Sharma. LoRA vs Full Fine- tuning: An Illusion of Equivalence, October 2025. URL http://arxiv.org/abs/2410.21228. arXiv:2410.21228 [cs]
-
[49]
Logit Standardization in Knowledge Distillation, March 2024
Shangquan Sun, Wenqi Ren, Jingzhi Li, Rui Wang, and Xiaochun Cao. Logit Standardization in Knowledge Distillation, March 2024. URLhttp://arxiv.org/abs/2403.01427. arXiv:2403.01427 [cs]
-
[50]
Titsias, Jonathan Schwarz, Alexander G
Michalis K. Titsias, Jonathan Schwarz, Alexander G. de G. Matthews, Razvan Pascanu, and Yee Whye Teh. Functional Regularisation for Continual Learning with Gaussian Processes, February 2020. URL http://arxiv.org/abs/1901.11356. arXiv:1901.11356 [stat]
-
[51]
Mojtaba Valipour, Mehdi Rezagholizadeh, Ivan Kobyzev, and Ali Ghodsi. DyLoRA: Parameter Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation, April 2023. URL http://arxiv.org/abs/2210.07558. arXiv:2210.07558 [cs]
-
[52]
CoT-VLA: Visual chain-of-thought reasoning for vision- language-action models,
Huiyi Wang, Haodong Lu, Lina Yao, and Dong Gong. Self-Expansion of Pre-trained Models with Mixture of Adapters for Continual Learning. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10087–10098, June 2025. doi: 10.1109/CVPR52734.2025.00943. URL https://ieeexplore.ieee.org/document/11093725/. ISSN: 2575-7075
-
[53]
A Comprehensive Survey of Continual Learn- ing: Theory, Method and Application, February 2024
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A Comprehensive Survey of Continual Learn- ing: Theory, Method and Application, February 2024. URL http://arxiv.org/abs/2302.00487. arXiv:2302.00487 [cs]. 12
-
[54]
Orthogonal Subspace Learning for Language Model Continual Learning, October 2023
Xiao Wang, Tianze Chen, Qiming Ge, Han Xia, Rong Bao, Rui Zheng, Qi Zhang, Tao Gui, and Xuanjing Huang. Orthogonal Subspace Learning for Language Model Continual Learning, October 2023. URL http://arxiv.org/abs/2310.14152. arXiv:2310.14152 [cs]
-
[55]
TIES-merging: Resolving interference when merging models
Prateek Yadav, Derek Tam, Leshem Choshen, Colin Raffel, and Mohit Bansal. TIES-merging: Resolving interference when merging models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[56]
Shipeng Yan, Jiangwei Xie, and Xuming He. DER: Dynamically Expandable Representation for Class Incremental Learning. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3013–3022, Nashville, TN, USA, June 2021. IEEE. ISBN 978-1-6654-4509-2. doi: 10.1109/CVPR46437.2021.00303. URLhttps://ieeexplore.ieee.org/document/9578633/
-
[57]
V*: Guided visual search as a core mechanism in multimodal llms
Jiazuo Yu, Yunzhi Zhuge, Lu Zhang, Ping Hu, Dong Wang, Huchuan Lu, and You He. Boosting Continual Learning of Vision-Language Models via Mixture-of-Experts Adapters. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 23219–23230, Seattle, WA, USA, June 2024. IEEE. ISBN 979-8-3503-5300-6. doi: 10.1109/CVPR52733.2024.02191. ...
-
[58]
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch.arXiv preprint arXiv:2311.03099, 2023
-
[59]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning, December 2023. URLhttp://arxiv.org/abs/2303.10512. arXiv:2303.10512 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
C-LoRA: Continual low-rank adaptation for pre-trained models.arXiv preprint arXiv:2502.17920, 2025
Xin Zhang, Liang Bai, Xian Yang, and Jiye Liang. C-LoRA: Continual low-rank adaptation for pre-trained models.arXiv preprint arXiv:2502.17920, 2025
-
[61]
Decoupled Knowledge Distillation, July
Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled Knowledge Distillation, July
-
[62]
URLhttp://arxiv.org/abs/2203.08679. arXiv:2203.08679 [cs]. 13 Supplementary Material A Extended Related Work The main-text related work (§2) condenses the literature into three paragraphs. This appendix expands the discussion for readers who want a more complete picture of the LoRA, replay-free continual learning, and output-space distillation literatures...
-
[63]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.