ESPO: Early-Stopping Proximal Policy Optimization
Pith reviewed 2026-06-29 09:06 UTC · model grok-4.3
The pith
ESPO early-stops failed reasoning trajectories in PPO by monitoring surrogate regret from logits, yielding higher accuracy on math benchmarks with over 20 percent fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
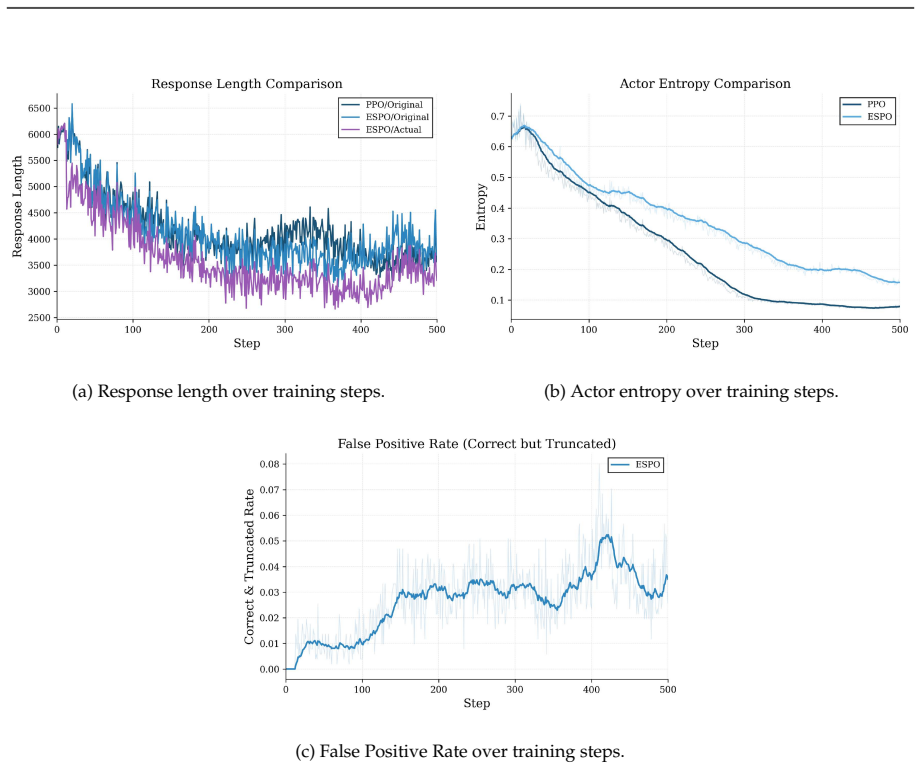
ESPO detects trajectory failure on-the-fly and terminates rollouts early. At each generation step, it computes a surrogate regret using only the logits already computed during sampling, and terminates when the smoothed cumulative regret significantly exceeds its estimated values. Truncated trajectories are treated as absorbing failure states with a terminal reward, concentrating negative temporal-difference errors near the detected failure step without any additional reward model or human annotation.
What carries the argument
The on-the-fly surrogate regret detector that uses already-computed logits to decide when to terminate a rollout early.
Load-bearing premise
The surrogate regret computed from already-generated logits reliably detects true trajectory failure without prematurely terminating paths that would have recovered or missing failures that only appear later.
What would settle it
Running the identical training setup with DeepSeek-R1-Distill-Qwen-7B on AIME 2024, AMC 2023, and MATH-500 and measuring whether ESPO still produces higher accuracy scores and more than 20 percent token savings than standard PPO.
Figures


read the original abstract
When a large language model under reinforcement learning commits a wrong reasoning step early in a trajectory, standard algorithms force it to keep generating until the maximum horizon, spending compute on tokens that never receive positive reward and polluting advantage estimates with post-failure noise. We propose ESPO (Early-Stopping Proximal Policy Optimization), which detects trajectory failure on-the-fly and terminates rollouts early. At each generation step, ESPO computes a surrogate regret using only the logits already computed during sampling, and terminates when the smoothed cumulative regret significantly exceeds its estimated values. Truncated trajectories are treated as absorbing failure states with a terminal reward, concentrating negative temporal-difference (TD) errors near the detected failure step without any additional reward model or human annotation. On DeepSeek-R1-Distill-Qwen-7B trained for mathematical reasoning, ESPO surpasses PPO on AIME~2024 (46.28% vs. 45.25%), AMC~2023 (85.83% vs. 82.94%), and MATH-500 (87.42% vs. 85.43%), while saving more than 20% rollout tokens cumulatively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ESPO, a modification to Proximal Policy Optimization for LLM reinforcement learning on mathematical reasoning tasks. It computes a surrogate regret from already-generated logits at each step to detect trajectory failures on-the-fly, terminates rollouts early when smoothed cumulative regret exceeds estimated values, and treats truncated trajectories as absorbing failure states with a terminal reward. This is claimed to concentrate negative TD errors near failure steps and avoid polluting advantages with post-failure noise. On DeepSeek-R1-Distill-Qwen-7B, ESPO reports higher accuracies than standard PPO on AIME 2024 (46.28% vs. 45.25%), AMC 2023 (85.83% vs. 82.94%), and MATH-500 (87.42% vs. 85.43%), plus more than 20% cumulative rollout token savings.
Significance. If the surrogate regret detector proves reliable, the method could improve sample efficiency in long-horizon RL for reasoning by reducing wasted computation on irrecoverable paths. The reported gains and token savings would then represent a practical advance, but the current presentation supplies no variance, statistical tests, or validation of the detector, so the result's significance cannot yet be evaluated.
major comments (3)
- [Abstract] Abstract: the numerical claims (AIME +1.03 pp, AMC +2.89 pp, MATH-500 +1.99 pp) are presented without variance estimates, statistical significance tests, or ablation details on the early-stopping component, so the improvements cannot be assessed from the given text.
- [Method] Method (surrogate regret definition): no equation or precise specification is supplied for the surrogate regret, its smoothing, or the threshold relative to estimated values, leaving the central assumption—that partial-logit regret reliably identifies irrecoverable failures—unverifiable and potentially circular with the training dynamics.
- [Experiments] Experiments: no calibration of the regret detector against ground-truth trajectory success/failure, no false-positive/negative rate analysis, and no ablation removing the early-stopping rule are reported; without these, it is impossible to rule out that the observed gains arise from altered trajectory distributions rather than improved optimization.
minor comments (1)
- [Abstract] Abstract: the notation 'AIME~2024' and similar uses a tilde that appears to be a typesetting artifact for spacing and should be replaced with a standard space or en-dash for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our submission. We address each major comment below and will revise the manuscript accordingly to improve clarity, verifiability, and rigor of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the numerical claims (AIME +1.03 pp, AMC +2.89 pp, MATH-500 +1.99 pp) are presented without variance estimates, statistical significance tests, or ablation details on the early-stopping component, so the improvements cannot be assessed from the given text.
Authors: We agree that variance estimates and statistical tests would allow better assessment of the reported gains. In the revised manuscript we will add standard deviations computed across multiple random seeds for all three benchmarks and include a brief statement on statistical significance. We will also reference the early-stopping ablation (to be added in the experiments section) within the abstract where space permits. revision: yes
-
Referee: [Method] Method (surrogate regret definition): no equation or precise specification is supplied for the surrogate regret, its smoothing, or the threshold relative to estimated values, leaving the central assumption—that partial-logit regret reliably identifies irrecoverable failures—unverifiable and potentially circular with the training dynamics.
Authors: The current manuscript provides only a high-level textual description of the surrogate regret computation. We acknowledge that an explicit equation, smoothing formula, and threshold definition are required for verifiability. The revised version will include the precise mathematical formulation of the surrogate regret, the exponential smoothing applied to the cumulative value, and the exact condition used to compare against estimated values. revision: yes
-
Referee: [Experiments] Experiments: no calibration of the regret detector against ground-truth trajectory success/failure, no false-positive/negative rate analysis, and no ablation removing the early-stopping rule are reported; without these, it is impossible to rule out that the observed gains arise from altered trajectory distributions rather than improved optimization.
Authors: We will add an ablation that disables the early-stopping rule while keeping all other PPO components fixed, allowing direct comparison of performance and token usage. For detector calibration we will report false-positive and false-negative rates obtained via manual inspection of a sampled subset of trajectories; full ground-truth labeling of every partial trajectory is not feasible without additional human annotation, but the added ablation and error-rate analysis will help isolate the contribution of early stopping from distribution shift. revision: partial
Circularity Check
No significant circularity; method is a heuristic detector with empirical validation
full rationale
The abstract and description present ESPO as an algorithmic modification to PPO that introduces an on-the-fly surrogate regret detector for early termination. No equations, fitted parameters, or self-citations are shown that reduce the claimed performance gains (AIME +1.03 pp etc.) or token savings to a tautological redefinition of the inputs. The surrogate regret is described as computed from already-generated logits and compared to estimated values, but without any derivation chain that equates it by construction to the success metric or to a fit on the same trajectories. The reported results are external benchmarks on held-out math problems, making the central claim falsifiable outside any internal loop. This is the normal case of an applied RL heuristic paper whose validity rests on experiment rather than on a closed mathematical reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Constitutional AI: Harmlessness from AI Feedback
URLhttps://arxiv.org/abs/2212.08073. Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, 10 Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. Open problems and fundamental limitations of reinforcement learning from human feedback.arXiv preprint arXiv:2307.15217,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
URL https://arxiv.or g/abs/2110.14168. DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Jingcheng Deng, Zihao Wei, Liang Pang, Junhong Wu, Shicheng Xu, Zenghao Duan, and Huawei Shen. Latent-GRPO: Group relative policy optimization for latent reasoning.arXiv preprint arXiv:2604.27998,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
AIME 2024 dataset.https://huggingface.co/datasets/Maxwell-Jia/AIME_2024,
Maxwell Jia. AIME 2024 dataset.https://huggingface.co/datasets/Maxwell-Jia/AIME_2024,
2024
-
[7]
Li, Y ., Yuan, P., Feng, S., Pan, B., Wang, X., Sun, B., Wang, H., and Li, K
Gang Li, Yan Chen, Ming Lin, and Tianbao Yang. DRPO: Efficient reasoning via decoupled reward policy optimization.arXiv preprint arXiv:2510.04474,
-
[8]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023a. URL https: //arxiv.org/abs/2305.20050. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Co...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Time limits in reinforcement learning
Fabio Pardo, Arash Tavakoli, Vitaly Levdik, and Petar Kormushev. Time limits in reinforcement learning. InProceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, Proceedings of Machine Learning Research, pages 4042–4051. PMLR,
2018
-
[10]
Manning, Stefano Ermon, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems 36: NeurIPS 2023, New Orleans, LA, USA,
2023
-
[11]
Proximal Policy Optimization Algorithms
URL http: //papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstr act-Conference.html. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
HybridFlow: A Flexible and Efficient RLHF Framework
11 Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework.arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
LLaMA: Open and Efficient Foundation Language Models
URLhttps://arxiv.org/abs/2302.13971. Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, et al. Solving math word problems with process- and outcome-based feedback.arXiv preprint arXiv:2211.14275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Solving math word problems with process- and outcome-based feedback
URL https://arxiv.org/abs/2211.14275. Junda Wang, Zhichao Yang, Dongxu Zhang, Sanjit Singh Batra, and Robert E. Tillman. ESTAR: Early- stopping token-aware reasoning for efficient inference.arXiv preprint arXiv:2602.10004,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Group Sequence Policy Optimization
URLhttps://arxiv.org/abs/2507.18071. 12 A Training Details For the ESPO training hyperparameters, the learning rate is set to 1 × 10−6. The maximum rollout length (Tmax) is configured to 8192 tokens, alongside a global batch size of 64 and the number of rollout is
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The initial value of β is set to 7.0
Regarding the algorithmic specifics, the failure reward rfail is set to −1.0, the EMA αema to 0.99, and the normalisation αs to 0.9. The initial value of β is set to 7.0. A β adjustment rate of 0.1 is applied to maintain a target termination rate of 0.25. The baseline methods maintain the same settings, such as the global batch size. Additionally, for DAP...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.