Honeyval: A Comprehensive Evaluation Framework for LLM-powered HTTP Honeypots
Pith reviewed 2026-06-29 06:59 UTC · model grok-4.3
The pith
LLM-powered HTTP honeypots produce longer attacker sessions, lower detection rates, and cost advantages over rule-based baselines when tested against AI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Honeyval grounds honeypot evaluations in 16 backend applications, deploys AI hacking agents as attackers, monitors both sides with two control tasks, and measures success against clear exploit goals; under this protocol, LLM-powered honeypots produce substantially longer interactions with the attacker than rule-based baselines, are detected far less frequently even by frontier models, and preserve an average running-cost advantage against agentic attackers.
What carries the argument
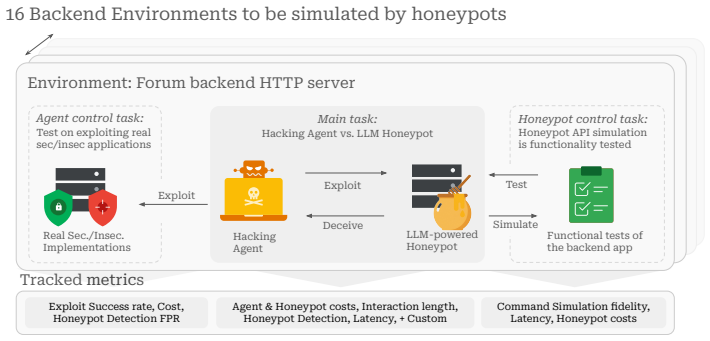
Honeyval evaluation protocol that pairs LLM honeypots with AI hacking agents pursuing verifiable exploit goals on 16 backend applications while running control tasks to track capability.
If this is right
- LLM honeypots can be tuned via configuration changes that trade longer sessions for higher detection risk.
- The cost advantage allows wider deployment of high-interaction honeypots without increasing average running expense against automated attackers.
- Control tasks provide a reproducible way to verify that honeypot customizations preserve both deception and operational stability.
- The framework supports direct comparison of new cost-efficient LLMs as they become available for honeypot backbones.
Where Pith is reading between the lines
- If AI agents prove too predictable, real attackers might shorten sessions or increase detection, narrowing the reported advantage.
- The framework could be extended to measure how well LLM honeypots handle mixed human-plus-automated attack campaigns.
- Developers might combine LLM and rule-based components in the same honeypot to balance the observed trade-offs.
- Similar agent-driven testing could be applied to non-HTTP honeypots once equivalent backend applications and exploit goals are defined.
Load-bearing premise
AI hacking agents serve as realistic proxies for practical real-world attacks and the defined exploit goals accurately measure honeypot performance across configurations.
What would settle it
Direct comparison of session lengths and detection rates when the same LLM honeypots face real human attackers or non-AI exploit tools instead of the AI agents used in the Honeyval tests.
Figures
read the original abstract
Honeypots are decoy systems mimicking real system components designed to defend against cyber attacks. Recently, LLMs increasingly serve as simulation backbones for honeypots. They enable defenders to construct high-interaction honeypots with low system security risks. However, LLM-powered honeypot development lacks a unified evaluation framework. Most evaluations consist of measuring response similarity on fixed commands, manual testing, or real-world deployment. These methods are often not scalable for development, reproducible across evaluations, representative of practical attacks, or adaptable to various attacker and honeypot configurations. In this work, we bridge this gap and propose Honeyval, a comprehensive evaluation framework for LLM-powered HTTP honeypots. We address the limitations of prior evaluations by grounding the honeypots in 16 backend applications, using AI hacking agents as attackers, employing two control tasks to monitor agent and honeypot capabilities across customizations, and defining clear and verifiable exploit goals for the attacker. Using Honeyval, we conduct an extensive evaluation of recent cost-efficient LLMs as HTTP honeypots. Our experiments highlight the promise of LLM-powered honeypots; they lead to substantially longer interactions with the attacker than rule-based baseline honeypots and are far less frequently detected even by frontier models, all while, on average, preserving a running cost advantage against agentic attackers. Further, we experiment with different counter-offensive honeypots configurations, and observe unique trade-offs, such as longer interactions at the cost of increased detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Honeyval, a framework for evaluating LLM-powered HTTP honeypots. It grounds evaluations in 16 backend applications, employs AI hacking agents as attackers, uses two control tasks to monitor capabilities, and defines verifiable exploit goals. Experiments with cost-efficient LLMs as honeypots claim substantially longer attacker interactions than rule-based baselines, lower detection rates even by frontier models, and average running cost advantages, with additional tests on counter-offensive configurations showing trade-offs such as longer interactions at the expense of higher detection.
Significance. If the AI-agent proxy assumption holds, the framework provides a scalable, reproducible evaluation method that improves on prior ad-hoc testing by incorporating control tasks and explicit goals; this could enable systematic comparison of honeypot configurations. The explicit use of defined exploit goals and control tasks is a strength for reproducibility and falsifiability within the agent-based setting.
major comments (3)
- [Abstract and §4 (Experiments)] Abstract and evaluation methodology section: the central claim that LLM-powered honeypots show 'promise' for practical use (longer interactions, lower detection, cost advantage) rests entirely on measurements against AI hacking agents; no external validation against human red-team logs, public exploit datasets, or non-LLM tools is described, which directly affects whether the reported advantages generalize beyond the proxy.
- [§3 (Framework)] Framework description (likely §3): the two control tasks and defined exploit goals are presented as accurately measuring honeypot performance, yet the manuscript provides no evidence that these tasks reproduce attacker behavior patterns observed outside the evaluation (e.g., differences in exploration or response to LLM-generated vs. rule-based replies), making the proxy assumption load-bearing for all quantitative results.
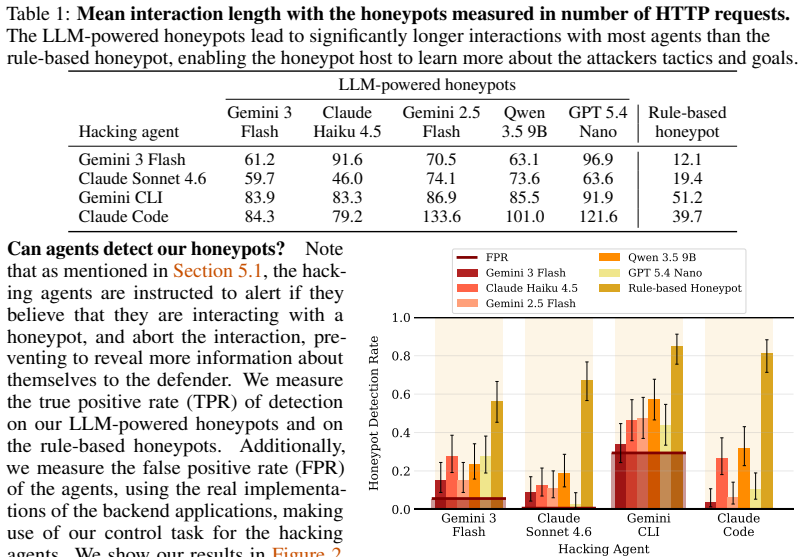
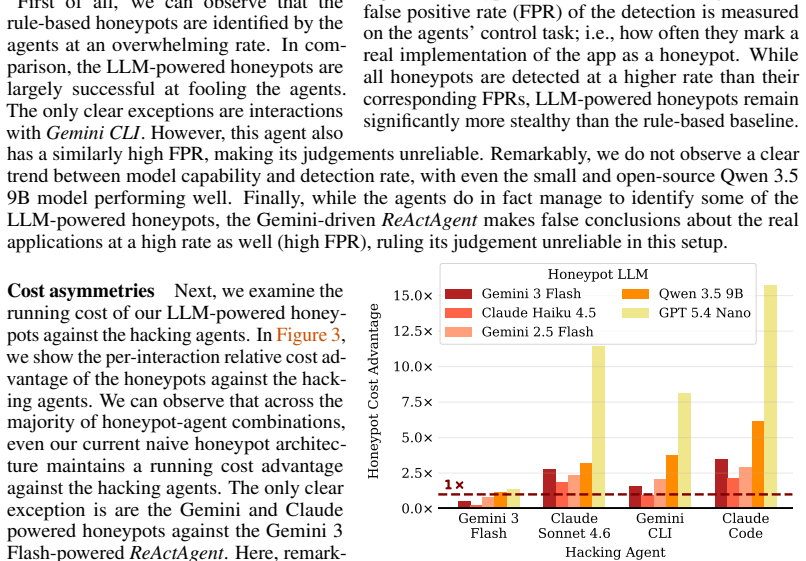
- [§4 (Results)] Results on detection and interaction length: claims of 'far less frequently detected even by frontier models' are measured only within the agent-attacker loop; without a comparison baseline using non-agent attackers or real-world traces, it is unclear whether lower detection reflects honeypot quality or limitations in how the agents model detection.
minor comments (2)
- [Abstract] The abstract states results without referencing specific tables or figures for the quantitative claims (e.g., interaction lengths or detection rates); adding these cross-references would improve clarity.
- [§3] Notation for the 16 backend applications and the two control tasks could be more explicitly defined early in the framework section to aid readers.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. The feedback correctly identifies that our evaluation framework relies on an AI-agent proxy for attackers, which is a core design decision for scalability and reproducibility. We address each major comment below and will incorporate clarifications and an expanded limitations discussion in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §4 (Experiments)] Abstract and evaluation methodology section: the central claim that LLM-powered honeypots show 'promise' for practical use (longer interactions, lower detection, cost advantage) rests entirely on measurements against AI hacking agents; no external validation against human red-team logs, public exploit datasets, or non-LLM tools is described, which directly affects whether the reported advantages generalize beyond the proxy.
Authors: We agree that all quantitative results are obtained using AI hacking agents as attackers. This choice enables controlled, reproducible experiments across many configurations, as motivated in the introduction and framework sections. The manuscript frames Honeyval as an agent-based evaluation framework rather than a direct simulator of all attacker types. In revision we will update the abstract and §4 to state explicitly that advantages are measured against AI agents and add a limitations subsection discussing the proxy assumption along with suggestions for future validation using human red-team data or public exploit traces. revision: partial
-
Referee: [§3 (Framework)] Framework description (likely §3): the two control tasks and defined exploit goals are presented as accurately measuring honeypot performance, yet the manuscript provides no evidence that these tasks reproduce attacker behavior patterns observed outside the evaluation (e.g., differences in exploration or response to LLM-generated vs. rule-based replies), making the proxy assumption load-bearing for all quantitative results.
Authors: The control tasks and exploit goals function as internal consistency checks to confirm that observed differences arise from honeypot customizations rather than agent or LLM capability collapse. We acknowledge that the manuscript supplies no external empirical comparison showing these tasks replicate real-world attacker patterns. We will revise §3 to clarify their role as capability monitors within the agent setting and to note the absence of external behavioral validation as a limitation. revision: partial
-
Referee: [§4 (Results)] Results on detection and interaction length: claims of 'far less frequently detected even by frontier models' are measured only within the agent-attacker loop; without a comparison baseline using non-agent attackers or real-world traces, it is unclear whether lower detection reflects honeypot quality or limitations in how the agents model detection.
Authors: Detection and interaction metrics are computed inside the closed agent-attacker loop, which isolates the influence of honeypot responses on agent continuation and success. We will revise §4 to emphasize that these outcomes are specific to the agent attacker model and to discuss how the agents' internal detection heuristics may affect the measured rates, while preserving the comparative results against the rule-based baseline within the same evaluation setting. revision: partial
Circularity Check
No circularity in empirical evaluation framework
full rationale
The paper introduces Honeyval as an empirical evaluation framework for LLM-powered HTTP honeypots, comparing them against baselines using AI hacking agents, control tasks, and defined exploit goals. No derivation chain, equations, or first-principles predictions are claimed; results are reported from direct experiments on interaction length, detection rates, and costs. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. The central claims rest on observable experimental outcomes rather than any construction that reduces to its own inputs by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An evening with berferd in which a cracker is lured, endured, and studied
Bill Cheswick. An evening with berferd in which a cracker is lured, endured, and studied. In Proceedings of the Winter 1992 USENIX Conference, pages 163–173, 1992
1992
-
[2]
A virtual honeypot framework
Niels Provos. A virtual honeypot framework. In13th USENIX Security Symposium (USENIX Security 04), San Diego, CA, August 2004. USENIX As- sociation. URL https://www.usenix.org/conference/13th-usenix-security- symposium/virtual-honeypot-framework
2004
-
[3]
Chatbots in a honeypot world, 2023
Forrest McKee and David Noever. Chatbots in a honeypot world, 2023. URL https://arxiv. org/abs/2301.03771
-
[4]
Strong supermartingales and limits of nonnegative martingales
Muris Sladi ´c, Veronica Valeros, Carlos Catania, and Sebastian Garcia. Llm in the shell: Generative honeypots. In2024 IEEE European Symposium on Security and Privacy Workshops, page 430–435. IEEE, July 2024. doi: 10.1109/eurospw61312.2024.00054. URL http://dx. doi.org/10.1109/EuroSPW61312.2024.00054
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/eurospw61312.2024.00054 2024
-
[5]
Beelzebub: Ai-native security platforms
Beelzebub. Beelzebub: Ai-native security platforms. https://beelzebub.ai/, 2026. Last accessed: 18.04.2026
2026
-
[6]
Bridges, Thomas R
Robert A. Bridges, Thomas R. Mitchell, Mauricio Muñoz, and Ted Henriksson. Sok: Honeypots & llms, more than the sum of their parts?, 2025. URL https://arxiv.org/abs/2510. 25939
2025
-
[7]
Niclas Ilg, Dominik Germek, Paul Duplys, and Michael Menth. Beekeeper: Accelerating honeypot analysis with llm-driven feedback.IEEE Access, 13:168034–168054, 2025. doi: 10.1109/ACCESS.2025.3613118
-
[8]
Gpt-5 at ctfs: Case studies from top-tier cybersecurity events, 2025
Reworr, Artem Petrov, and Dmitrii V olkov. Gpt-5 at ctfs: Case studies from top-tier cybersecurity events, 2025. URLhttps://arxiv.org/abs/2511.04860
-
[9]
Evaluating and mitigating the growing risk of llm-discovered 0-days
Nicholas Carlini, Keane Lucas, Evyatar Ben Asher, Newton Cheng, Hasnain Lakhani, David Forsythe, and Kyla Guru. Evaluating and mitigating the growing risk of llm-discovered 0-days. https://red.anthropic.com/2026/zero-days/, 2026. Last accessed: 17.04.2026
2026
-
[10]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Claude code, 2026
Anthropic. Claude code, 2026. URLhttps://github.com/anthropics/claude-code
2026
-
[12]
Gemini cli, 2026
Google. Gemini cli, 2026. URLhttps://github.com/google-gemini/gemini-cli
2026
-
[13]
Honeypots: concepts, approaches, and challenges
Iyatiti Mokube and Michele Adams. Honeypots: concepts, approaches, and challenges. In Proceedings of the 45th Annual ACM Southeast Conference, ACMSE ’07, page 321–326, New York, NY , USA, 2007. Association for Computing Machinery. ISBN 9781595936295. doi: 10.1145/1233341.1233399. URLhttps://doi.org/10.1145/1233341.1233399
-
[14]
Cowrie: Advanced ssh honeypot for enterprise security, 2026
Cowrie. Cowrie: Advanced ssh honeypot for enterprise security, 2026. URL https://www. cowrie.org/. Last accessed: 17.04.2026
2026
-
[15]
Iotcandyjar: Towards an intelligent-interaction honeypot for iot devices
Tongbo Luo, Zhaoyan Xu, Xing Jin, Yanhui Jia, and Xin Ouyang. Iotcandyjar: Towards an intelligent-interaction honeypot for iot devices. InBlack Hat USA, 2017. URL https://blackhat.com/docs/us-17/thursday/us-17-Luo-Iotcandyjar-Towards- An-Intelligent-Interaction-Honeypot-For-IoT-Devices-wp.pdf
2017
-
[16]
Honeyllm: Enabling shell honeypots with large language models
Chongqi Guan, Guohong Cao, and Sencun Zhu. Honeyllm: Enabling shell honeypots with large language models. In2024 IEEE Conference on Communications and Network Security (CNS),
-
[17]
doi: 10.1109/CNS62487.2024.10735663
-
[18]
Hakan T. Otal and M. Abdullah Canbaz. Llm honeypot: Leveraging large language models as advanced interactive honeypot systems. In2024 IEEE Conference on Communications and Network Security (CNS), page 1–6. IEEE, September 2024. doi: 10.1109/cns62487.2024. 10735607. URLhttp://dx.doi.org/10.1109/CNS62487.2024.10735607
-
[19]
Pranjay Malhotra. Llmhoney: A real-time ssh honeypot with large language model-driven dynamic response generation, 2025. URLhttps://arxiv.org/abs/2509.01463
-
[20]
Ohra: dynamic multi- protocol llm-based cyber deception
Anastasia Safargalieva, Artur Rüffer, and Emmanouil Vasilomanolakis. Ohra: dynamic multi- protocol llm-based cyber deception. InProceedings of the 30th Nordic Conference on Secure IT Systems (Nordsec 2025). Springer, 2025. 10
2025
-
[21]
Guan Yang, Zhengzheng Sun, and Yu Wang. Shellbox: Adversarially enhanced llm-interactive honeypot framework.IEEE Access, 13:143618–143630, 2025. doi: 10.1109/ACCESS.2025. 3598779
-
[22]
Vellmes: A high- interaction ai-based deception framework
Muris Sladi ´c, Veronica Valeros, Carlos Catania, and Sebastian Garcia. Vellmes: A high- interaction ai-based deception framework. In2025 IEEE European Symposium on Security and Privacy Workshops, page 671–679. IEEE, June 2025. doi: 10.1109/eurospw67616.2025.00082. URLhttp://dx.doi.org/10.1109/EuroSPW67616.2025.00082
-
[23]
Honeygpt: Breaking the trilemma in terminal honeypots with large language model, 2025
Ziyang Wang, Jianzhou You, Haining Wang, Tianwei Yuan, Shichao Lv, Yang Wang, and Limin Sun. Honeygpt: Breaking the trilemma in terminal honeypots with large language model, 2025. URLhttps://arxiv.org/abs/2406.01882
-
[24]
Pentestgpt: An llm-empowered automatic penetration testing tool,
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. Pentestgpt: An llm-empowered automatic penetra- tion testing tool.arXiv preprint arXiv:2308.06782, 2023
-
[25]
Pentestagent: Incorporating llm agents to automated penetration testing,
Xiangmin Shen, Lingzhi Wang, Zhenyuan Li, Yan Chen, Wencheng Zhao, Dawei Sun, Jiashui Wang, and Wei Ruan. Pentestagent: Incorporating llm agents to automated penetration testing,
- [26]
-
[27]
Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik Narasimhan, Ramesh Karri, and Ofir Press
Talor Abramovich, Meet Udeshi, Minghao Shao, Kilian Lieret, Haoran Xi, Kimberly Milner, Sofija Jancheska, John Yang, Carlos E. Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik Narasimhan, Ramesh Karri, and Ofir Press. Enigma: Interactive tools substantially assist lm agents in finding security vulnerabilities,
- [28]
-
[29]
Meet Udeshi, Minghao Shao, Haoran Xi, Nanda Rani, Kimberly Milner, Venkata Sai Charan Putrevu, Brendan Dolan-Gavitt, Sandeep Kumar Shukla, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. D-cipher: Dynamic collaborative intelli- gent multi-agent system with planner and heterogeneous executors for offensive security, 2025. UR...
-
[30]
Craken: Cybersecurity llm agent with knowledge-based execution,
Minghao Shao, Haoran Xi, Nanda Rani, Meet Udeshi, Venkata Sai Charan Putrevu, Kimberly Milner, Brendan Dolan-Gavitt, Sandeep Kumar Shukla, Prashanth Krishnamurthy, Farshad Khorrami, Ramesh Karri, and Muhammad Shafique. Craken: Cybersecurity llm agent with knowledge-based execution, 2025. URLhttps://arxiv.org/abs/2505.17107
-
[31]
Xbow: The intelligence of a hacker at the speed of a machine, 2026
XBOW. Xbow: The intelligence of a hacker at the speed of a machine, 2026. URL https: //xbow.com/. Last accessed: 17.04.2026
2026
-
[32]
Firecompass: Automated pen testing & red teaming across web, api, cloud & infra., 2026
FireCompass. Firecompass: Automated pen testing & red teaming across web, api, cloud & infra., 2026. URLhttps://firecompass.com/. Last accessed: 17.04.2026
2026
-
[33]
Hacking ctfs with plain agents,
Rustem Turtayev, Artem Petrov, Dmitrii V olkov, and Denis V olk. Hacking ctfs with plain agents,
- [34]
-
[35]
Cybergym: Evaluating AI agents’ real-world cybersecurity capabilities at scale
Zhun Wang, Tianneng Shi, Jingxuan He, Matthew Cai, Jialin Zhang, and Dawn Song. Cybergym: Evaluating AI agents’ real-world cybersecurity capabilities at scale. InThe F ourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=2YvbLQEdYt
2026
-
[36]
Assessing claude mythos preview’s cyberse- curity capabilities
Nicholas Carlini, Newton Cheng, Keane Lucas, Michael Moore, Milad Nasr, Vinay Prab- hushankar, Winnie Xiao Hakeem Angulu, Evyatar Ben Asher, Jackie Bow, Keir Bradwell, Ben Buchanan, David Forsythe, Daniel Freeman, Alex Gaynor, Xinyang Ge, Logan Graham, Kyla Guru, Hasnain Lakhani, Matt McNiece, Mojtaba Mehrara, Renee Nichol, Adnan Pirzada, Sophia Porter, A...
2026
-
[37]
Baxbench: Can llms generate correct and secure backends?arXiv preprint arXiv:2502.11844, 2025
Mark Vero, Niels Mündler, Victor Chibotaru, Veselin Raychev, Maximilian Baader, Nikola Jovanovi´c, Jingxuan He, and Martin Vechev. Baxbench: Can llms generate correct and secure backends?arXiv preprint arXiv:2502.11844, 2025
-
[38]
The openapi specification
OpenAPI Initiative. The openapi specification. https://github.com/OAI/OpenAPI- Specification, 2026. Last accessed: 16.04.2026
2026
-
[39]
How we hacked mckinsey’s ai platform
CodeWall. How we hacked mckinsey’s ai platform. https://codewall.ai/blog/how-we- hacked-mckinseys-ai-platform, 2026. Last accessed: 16.04.2026. 11
2026
-
[40]
Gemini 3 flash: frontier intelligence built for speed, 2026
Google. Gemini 3 flash: frontier intelligence built for speed, 2026. URL https:// blog.google/products-and-platforms/products/gemini/gemini-3-flash/ . Last accessed: 21.05.2026
2026
-
[41]
Claude sonnet 4.6, 2026
Anthropic. Claude sonnet 4.6, 2026. URL https://www.anthropic.com/news/claude- sonnet-4-6. Last accessed: 15.04.2026
2026
-
[42]
Claude haiku 4.5, 2025
Anthropic. Claude haiku 4.5, 2025. URL https://www.anthropic.com/claude/haiku. Last accessed: 15.04.2026
2025
-
[43]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[45]
Introducing gpt-5.4 mini and nano, 2026
OpenAI. Introducing gpt-5.4 mini and nano, 2026. URL https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/. Last accessed: 15.04.2026
2026
-
[46]
Serverless inference on together ai, 2026
Together AI. Serverless inference on together ai, 2026. URL https://www.together.ai/ serverless-inference. Last accessed: 15.04.2026
2026
-
[47]
The model is the computer
Taalas. The model is the computer. https://taalas.com/, 2026. Last accessed: 06.05.2026
2026
-
[48]
Groq delivers fast, low cost inference that doesn’t flake when things get real
Groq. Groq delivers fast, low cost inference that doesn’t flake when things get real. https://groq.com/, 2026. Last accessed: 06.05.2026
2026
-
[49]
Cloak, honey, trap: Proactive defenses against LLM agents
Daniel Ayzenshteyn, Roy Weiss, and Yisroel Mirsky. Cloak, honey, trap: Proactive defenses against LLM agents. In Lujo Bauer and Giancarlo Pellegrino, editors,34th USENIX Se- curity Symposium, USENIX Security 2025, Seattle, WA, USA, August 13-15, 2025, pages 8095–8114. USENIX Association, 2025. URL https://www.usenix.org/conference/ usenixsecurity25/presen...
2025
-
[50]
AutoBaxBuilder: Bootstrapping Code Security Benchmarking
Tobias von Arx, Niels Mündler, Mark Vero, Maximilian Baader, and Martin Vechev. Auto- baxbuilder: Bootstrapping code security benchmarking, 2025. URL https://arxiv.org/ abs/2512.21132. 12 Appendix A Broader Impact Statement In this paper, we introduced a comprehensive framework for evaluating, testing, and developing LLM- powered HTTP honeypots. As honeyp...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.