REPOT: Recoverable Program-of-Thought via Checkpoint Repair
Pith reviewed 2026-06-29 06:20 UTC · model grok-4.3
The pith
RePoT recovers from invalid Program-of-Thought plans by replaying to the first error and resuming from the verified prefix with one extra call.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
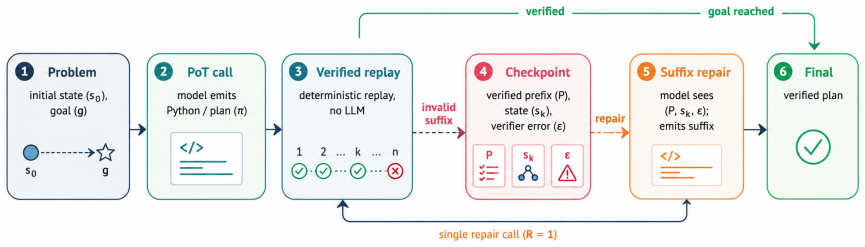
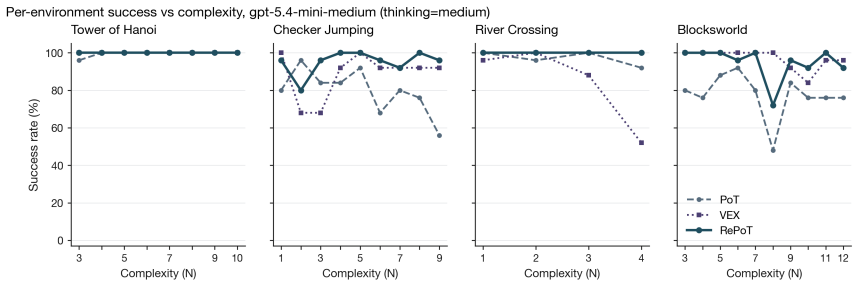
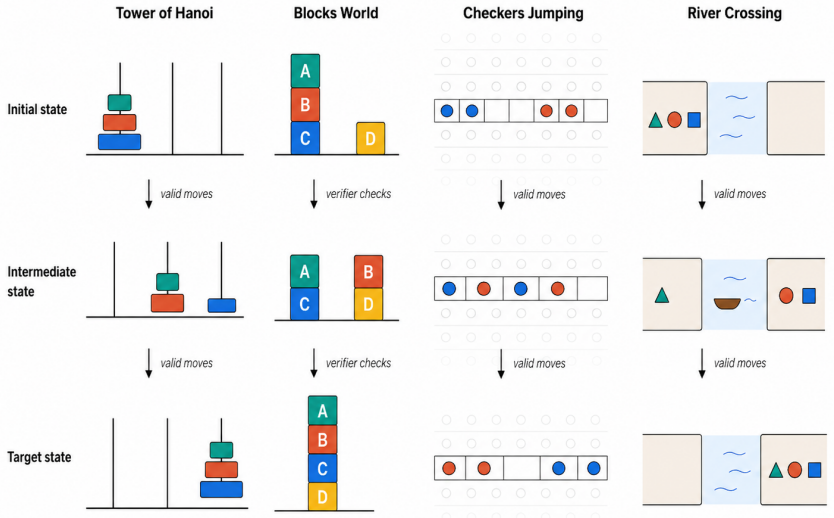
RePoT uses deterministic verified replay of the generated plan to locate its first invalid transition, then performs one LLM call that resumes from the verified prefix to produce a corrected suffix.
What carries the argument
Deterministic verified replay that extracts a verified prefix for checkpoint repair
If this is right
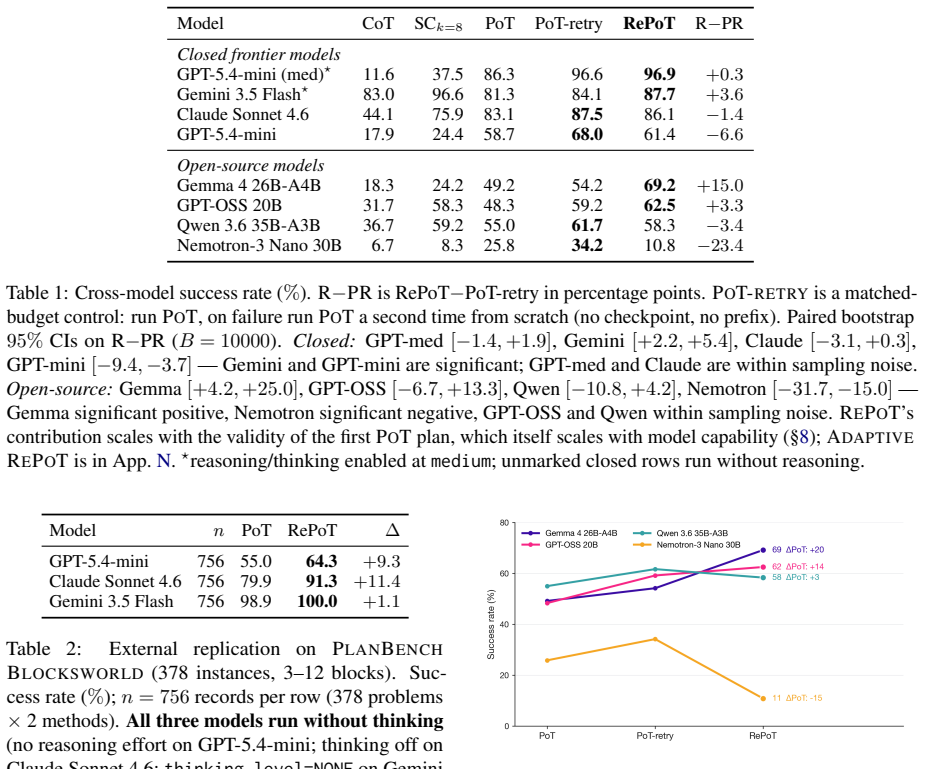
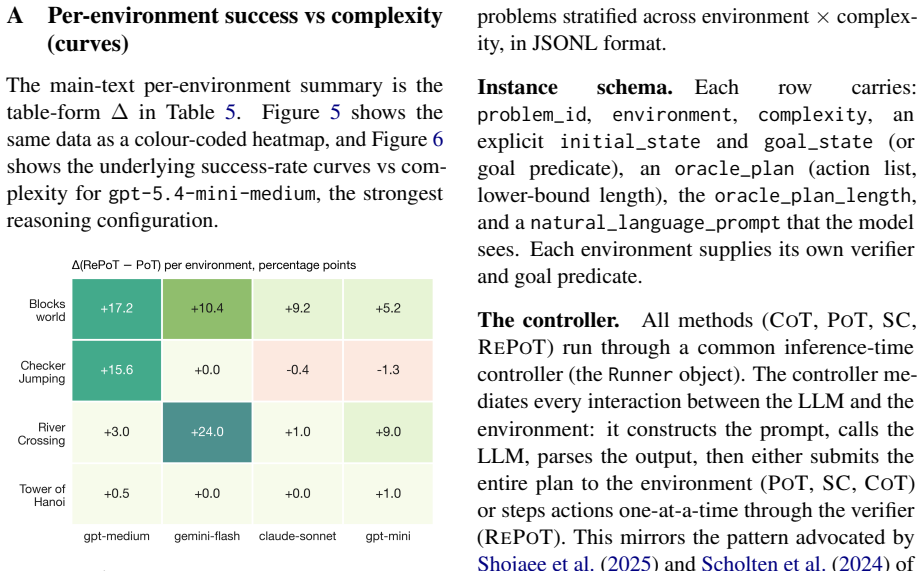
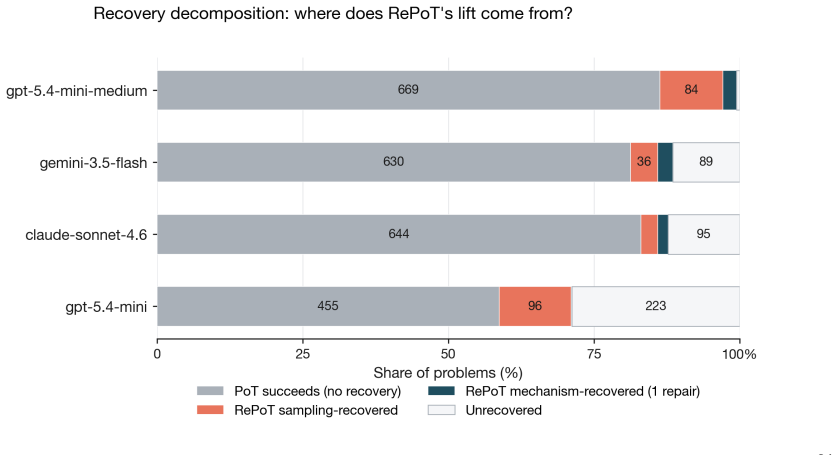
- RePoT improves success by 3 to 11 percentage points over standard PoT on PuzzleZoo-775 across four closed-model configurations.
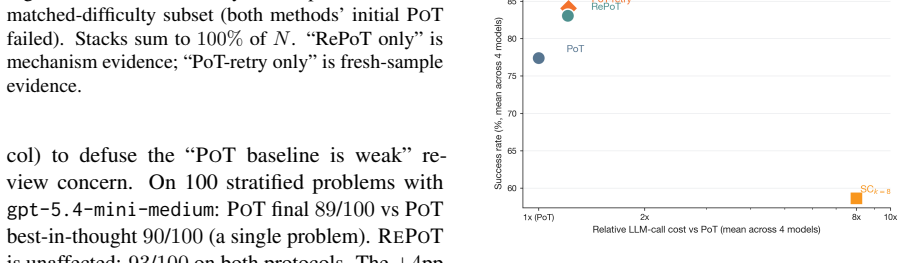
- It outperforms a matched-budget PoT-retry baseline on Gemini and remains within noise on several other models.
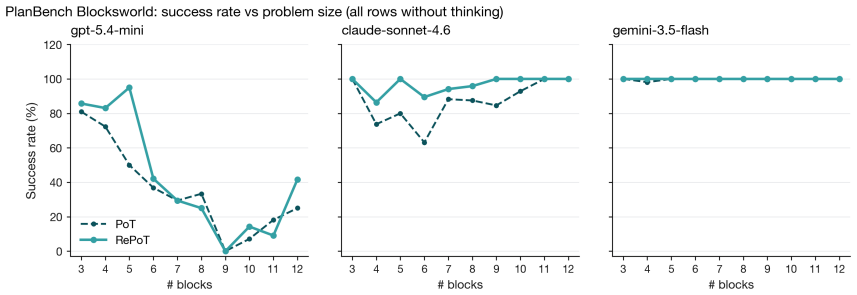
- The same pattern of gains appears on PlanBench Blocksworld and on three of four open-weights models.
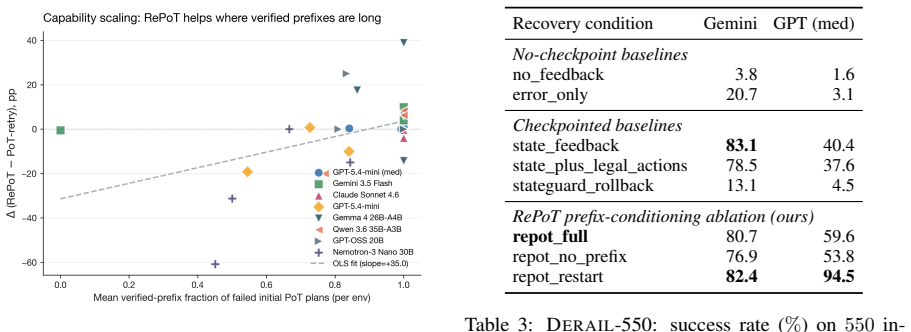
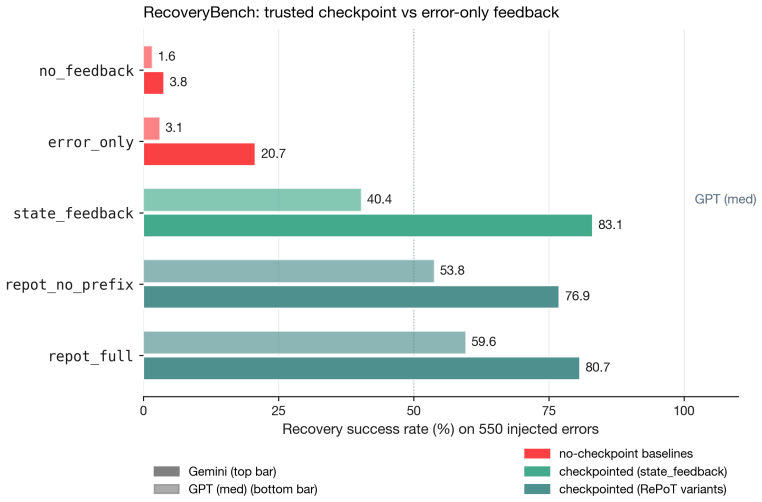
- Every condition supplying checkpoint information reaches at least 30 percent recovery on GPT-medium and 70 percent on Gemini on the Derail-550 benchmark.
Where Pith is reading between the lines
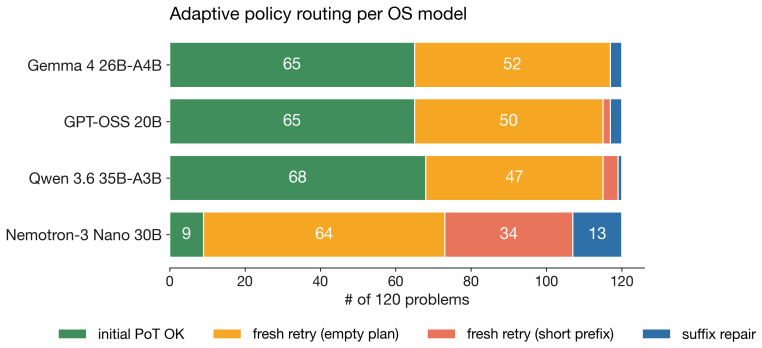
- A rule-based dispatcher that chooses between repair and full retry based on verified-prefix length may further improve results on smaller models.
- The same replay-and-repair pattern could apply to other partially verifiable LLM outputs such as code or mathematical derivations.
- Recovery margins are expected to widen with model capability because stronger models can better exploit the supplied prefix.
Load-bearing premise
The environment must support deterministic, side-effect-free replay of the generated plan up to the first invalid transition so a verified prefix can be extracted.
What would settle it
An experiment on Derail-550 in which recovery success rates with the verified prefix equal those obtained from error-only feedback would falsify the claim that checkpoint information is the load-bearing recovery signal.
Figures


read the original abstract
One-shot Program-of-Thought (PoT) emits a Python program that prints a primitive-action plan; a single invalid action silently invalidates the trajectory. We introduce RePoT (Recoverable PoT): a deterministic verified replay that walks the plan through the environment to its first invalid transition, then one LLM call that resumes from the verified prefix. RePoT costs at most one extra LLM call on the ~14% of problems where PoT fails. RePoT beats PoT by +3 to +11pp across four closed-model configurations on PuzzleZoo-775 and peaks at 96.9% vs 86.3% on gpt-5.4-mini-medium; against the matched-budget PoT-retry baseline, RePoT wins decisively on Gemini (+3.8pp, 95% CI [+2.2,+5.4]), is within sampling noise on GPT-medium and Claude, and loses on GPT-mini -- a capability-scaling pattern we begin to address with Adaptive RePoT, a rule-based dispatcher that routes between suffix repair and a fresh PoT retry based on verified-prefix length (preliminary). We replicate on PlanBench Blocksworld (+1.1 to +11.4pp) and on four open-weights models (+3.3 to +20.0pp on three of four). On Derail-550, our controlled recovery benchmark, every condition with access to checkpoint information clears >=30% on GPT-medium and >=70% on Gemini, vs <=3.1% for error-only feedback -- showing that checkpoint information, not the specific verified-prefix tail, is the load-bearing recovery signal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RePoT, an extension of one-shot Program-of-Thought (PoT) that performs deterministic verified replay of the emitted Python plan to locate the first invalid transition, then issues one additional LLM call to resume from the verified prefix. It reports accuracy gains of +3 to +11pp versus PoT on PuzzleZoo-775 across four closed models (peaking at 96.9% vs 86.3%), decisive wins versus matched-budget PoT-retry on some models, replication on PlanBench (+1.1 to +11.4pp) and open-weight models, and strong results on the new Derail-550 recovery benchmark showing the value of checkpoint information over error-only feedback.
Significance. If the deterministic replay assumption holds, RePoT offers a low-overhead recovery technique that improves PoT success rates with at most one extra LLM call on failing cases. The work supplies confidence intervals, cross-model replications, and a controlled benchmark isolating checkpoint utility; these elements strengthen the empirical case for the approach in environments where side-effect-free replay is feasible.
major comments (2)
- [Method description (and Abstract)] The method presupposes that the target environment supports deterministic, side-effect-free replay of the generated plan up to the first invalid transition so that a verified prefix can be extracted. The paper evaluates exclusively on PuzzleZoo-775 and PlanBench (both constructed to satisfy the assumption) and provides no analysis, bounds, or characterization of the broader class of environments where the assumption holds; this is load-bearing for all reported gains versus PoT and error-only baselines.
- [Experiments (Derail-550 results)] Derail-550 is presented as a controlled recovery benchmark, yet the manuscript supplies no validation metrics, construction details, or exclusion criteria for the 550 instances; without these, it is difficult to assess whether the >=30% / >=70% recovery rates (versus <=3.1% for error-only) generalize beyond the specific test distribution.
minor comments (2)
- [Abstract] The abstract states performance deltas and 95% CIs but does not specify exact baseline implementations, data splits, or statistical testing procedure; adding these details would improve reproducibility.
- [Method] Notation for the verified prefix and recovery call could be formalized with a short pseudocode block or equation to clarify the single extra LLM call cost.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Method description (and Abstract)] The method presupposes that the target environment supports deterministic, side-effect-free replay of the generated plan up to the first invalid transition so that a verified prefix can be extracted. The paper evaluates exclusively on PuzzleZoo-775 and PlanBench (both constructed to satisfy the assumption) and provides no analysis, bounds, or characterization of the broader class of environments where the assumption holds; this is load-bearing for all reported gains versus PoT and error-only baselines.
Authors: We agree the deterministic replay assumption is load-bearing. The evaluated benchmarks are standard planning domains constructed to satisfy it. In revision we will add a subsection characterizing the applicable environment class (deterministic transitions, no irreversible side-effects) and explicitly stating the limitation for stochastic or side-effectful settings. We do not provide formal bounds across all environments, as that would constitute a separate theoretical contribution. revision: partial
-
Referee: [Experiments (Derail-550 results)] Derail-550 is presented as a controlled recovery benchmark, yet the manuscript supplies no validation metrics, construction details, or exclusion criteria for the 550 instances; without these, it is difficult to assess whether the >=30% / >=70% recovery rates (versus <=3.1% for error-only) generalize beyond the specific test distribution.
Authors: We agree that construction details, exclusion criteria, and validation metrics for Derail-550 are missing. The revised manuscript will include an appendix section supplying these elements, including how instances were generated, filtering rules, and any quality or distribution statistics. revision: yes
Circularity Check
No circularity; purely empirical comparisons to external baselines
full rationale
The paper reports accuracy improvements from RePoT versus PoT, PoT-retry, and error-only feedback on PuzzleZoo-775, PlanBench, and Derail-550. These are direct experimental measurements against independent methods and benchmarks; no equations, fitted parameters, or self-citations are used to derive the claimed gains. The central assumption (deterministic replay) is stated explicitly as an environmental prerequisite rather than derived from the method itself. All numbers are externally falsifiable and not reduced to quantities fitted from the same data.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Edward Y. Chang and Longling Geng. 2025. https://arxiv.org/abs/2503.11951 SagaLLM : Context management, validation, and transaction guarantees for multi-agent llm planning . Preprint, arXiv:2503.11951
-
[4]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. https://arxiv.org/abs/2211.12588 Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks . Transactions on Machine Learning Research (TMLR)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Google DeepMind . 2025. https://ai.google.dev/gemma/docs/core Gemma 4: Open multimodal models . Model card; Apache 2.0 license
2025
- [6]
-
[7]
Peiran Li, Xinkai Zou, Zhuohang Wu, Ruifeng Li, Shuo Xing, Hanwen Zheng, Zhikai Hu, Yuping Wang, Haoxi Li, Qin Yuan, Yingmo Zhang, and Zhengzhong Tu. 2025. https://arxiv.org/abs/2506.07564 SafeFlow : A principled protocol for trustworthy and transactional autonomous agent systems . Preprint, arXiv:2506.07564
- [8]
-
[9]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2024. https://arxiv.org/abs/2305.20050 Let's verify step by step . In International Conference on Learning Representations (ICLR)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. 2023. https://arxiv.org/abs/2303.17651 Self-Refine : Iterative refinement with self-feedback . In Adv...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Bardia Mohammadi, Nearchos Potamitis, Lars Klein, Akhil Arora, and Laurent Bindschaedler. 2026. https://arxiv.org/abs/2602.14849 Atomix: Timely, transactional tool use for reliable agentic workflows . Preprint, arXiv:2602.14849
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [12]
-
[13]
Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar- Lezama
Theo X. Olausson, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao, and Armando Solar-Lezama. 2024. https://arxiv.org/abs/2306.09896 Is self-repair a silver bullet for code generation? In International Conference on Learning Representations (ICLR)
-
[14]
OpenAI . 2025. https://arxiv.org/abs/2508.10925 gpt-oss-120b & gpt-oss-20b model card . Preprint, arXiv:2508.10925
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Qwen Team . 2026. https://qwen.ai/blog?id=qwen3.6-35b-a3b Qwen3.6-35B-A3B : Agentic coding power, now open to all
2026
-
[16]
Florian Scholten, Tobias R. Rebholz, and Mandy H \"u tter. 2024. https://arxiv.org/abs/2408.05568 Metacognitive myopia in large language models . Preprint, arXiv:2408.05568
-
[17]
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. https://arxiv.org/abs/2303.11366 Reflexion : Language agents with verbal reinforcement learning . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. 2025. https://arxiv.org/abs/2506.06941 The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [19]
-
[20]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. 2023 a . https://arxiv.org/abs/2206.10498 PlanBench : An extensible benchmark for evaluating large language models on planning and reasoning about change . In Advances in Neural Information Processing Systems (NeurIPS)
- [21]
-
[22]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://arxiv.org/abs/2203.11171 Self-consistency improves chain of thought reasoning in language models . In International Conference on Learning Representations (ICLR)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. https://arxiv.org/abs/2201.11903 Chain-of-thought prompting elicits reasoning in large language models . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, and Dongkuan Xu. 2023. https://arxiv.org/abs/2305.18323 ReWOO : Decoupling reasoning from observations for efficient augmented language models . Preprint, arXiv:2305.18323
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023 a . https://arxiv.org/abs/2305.10601 Tree of thoughts: Deliberate problem solving with large language models . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023 b . https://arxiv.org/abs/2210.03629 ReAct : Synergizing reasoning and acting in language models . In International Conference on Learning Representations (ICLR)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. 2024. https://arxiv.org/abs/2310.04406 Language agent tree search unifies reasoning, acting, and planning in language models . In International Conference on Machine Learning (ICML)
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.