Towards Consistent Video Geometry Estimation
Pith reviewed 2026-06-29 08:00 UTC · model grok-4.3
The pith
ViGeo recovers dense and temporally consistent video geometry with one plain transformer that adapts attention patterns at test time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
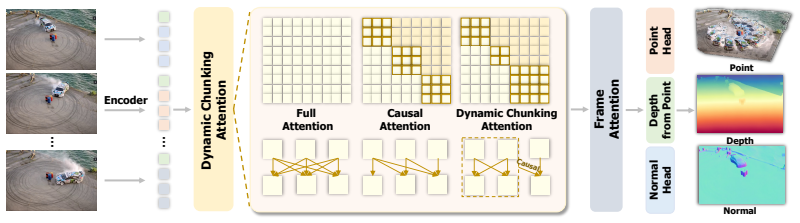
ViGeo is a feed-forward foundation model for recovering spatially dense and temporally consistent geometry from video sequences. Built upon a plain transformer architecture without task-specific architectural modifications, ViGeo supports streaming, full-sequence, and long-video inference within a unified model. The key design is dynamic chunking attention, which exposes the model to both bidirectional and causal temporal contexts during training and allows it to adapt its attention pattern at test time without retraining. To improve supervision quality, the authors introduce a completion-based data refinement framework that trains a video depth completion teacher conditioning on sparse and
What carries the argument
Dynamic chunking attention, which exposes the model to both bidirectional and causal temporal contexts during training and allows adaptation of the attention pattern at test time without retraining.
If this is right
- The same trained model can switch between online streaming depth estimation and offline bidirectional processing without retraining.
- Surface normal and point map predictions are generated alongside depth within one forward pass.
- Long-video sequences maintain geometric consistency using the adapted attention pattern.
- Training targets refined by the teacher model improve supervision quality over raw annotations.
- State-of-the-art results are obtained using only public datasets across the listed tasks.
Where Pith is reading between the lines
- The unified attention mechanism could reduce the engineering overhead of maintaining separate models for different video lengths in production systems.
- Consistent normal and point map outputs may directly feed into downstream tasks such as video-based 3D reconstruction or SLAM without additional alignment steps.
- The refinement approach might generalize to other sparse supervision settings in video, such as optical flow or instance segmentation.
- If the dynamic chunking pattern proves stable, similar attention designs could appear in other sequence models that must support both causal and non-causal inference.
Load-bearing premise
The completion-based data refinement framework produces dense, temporally coherent, and geometrically reliable training targets from sparse and noisy annotations.
What would settle it
If a model trained directly on the original sparse noisy annotations matches or exceeds ViGeo's temporal consistency scores on long-video benchmarks, the contribution of the refinement framework would be falsified.
Figures








read the original abstract
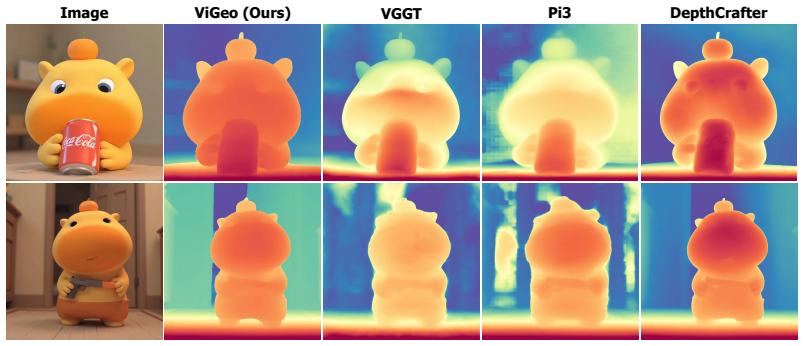
This work presents ViGeo, a feed-forward foundation model for recovering spatially dense and temporally consistent geometry from video sequences. Built upon a plain transformer architecture without task-specific architectural modifications, ViGeo supports streaming, full-sequence, and long-video inference within a unified model. The key design is dynamic chunking attention, which exposes the model to both bidirectional and causal temporal contexts during training and allows it to adapt its attention pattern at test time without retraining. To improve supervision quality, we further introduce a completion-based data refinement framework. This framework trains a video depth completion teacher that conditions on sparse and noisy annotations and exploits video/multi-view context to produce dense, temporally coherent, and geometrically reliable training targets. Beyond depth and point maps, ViGeo also predicts surface normals within the same framework. Trained solely on public datasets, ViGeo achieves state-of-the-art performance across online, offline, and long-video depth estimation, surface normal estimation, and video point map estimation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ViGeo, a feed-forward foundation model based on a plain transformer for recovering spatially dense and temporally consistent geometry (depth, surface normals, point maps) from video. It introduces dynamic chunking attention to enable streaming, full-sequence, and long-video inference within one model. A completion-based data refinement framework trains a video depth completion teacher on sparse/noisy annotations to generate dense, temporally coherent training targets. Trained only on public datasets, ViGeo claims state-of-the-art results on online/offline/long-video depth estimation, surface normal estimation, and video point map estimation.
Significance. If substantiated, the work would advance video geometry estimation by offering a unified, architecture-agnostic foundation model with flexible inference modes. The dynamic chunking attention and public-data training are positive elements that could support broader adoption if the performance claims are rigorously validated.
major comments (1)
- [Data refinement framework] Data refinement framework (abstract and methods section): The SOTA claims depend on the teacher producing 'geometrically reliable' dense targets. No quantitative validation against independent dense ground truth is described, nor are details given on the teacher's loss beyond sparse-point conditioning or explicit multi-view consistency terms. This is load-bearing because unverified target quality could mean reported metric gains reflect annotation propagation rather than model capability.
minor comments (1)
- [Abstract] The abstract states the model 'exploits video/multi-view context' in the teacher but provides no implementation specifics or ablation on this component.
Simulated Author's Rebuttal
We thank the referee for the thoughtful feedback on our data refinement framework. We address the concern point-by-point below and will incorporate additional details and validation in the revised manuscript to strengthen the presentation of the teacher model's target quality.
read point-by-point responses
-
Referee: [Data refinement framework] Data refinement framework (abstract and methods section): The SOTA claims depend on the teacher producing 'geometrically reliable' dense targets. No quantitative validation against independent dense ground truth is described, nor are details given on the teacher's loss beyond sparse-point conditioning or explicit multi-view consistency terms. This is load-bearing because unverified target quality could mean reported metric gains reflect annotation propagation rather than model capability.
Authors: We agree that the current manuscript provides insufficient quantitative validation of the teacher's dense outputs against independent dense ground truth and limited specifics on the full loss formulation. While the framework description emphasizes conditioning on sparse/noisy annotations and exploitation of video/multi-view context to generate coherent targets, we acknowledge this leaves open the possibility that gains partly reflect propagation of existing annotations. In the revision we will expand the methods section with: (1) the complete teacher loss, explicitly including any multi-view consistency or geometric regularization terms beyond sparse-point conditioning; (2) quantitative evaluation of teacher outputs on any available dense ground-truth subsets (e.g., selected sequences from datasets that provide both sparse and dense annotations); and (3) an ablation isolating the effect of the refined targets versus raw sparse supervision. These additions will allow readers to better assess whether the reported improvements stem from model capability or target quality. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The provided abstract and description introduce ViGeo and a completion-based data refinement framework that generates training targets from public datasets' sparse annotations. Performance claims are evaluated on standard external metrics for depth, normals, and point maps across online/offline/long-video settings. No equations, self-citations, or derivations are shown that reduce any prediction or result to its own inputs by construction. The framework is presented as a training aid rather than a self-referential definition of success, and no uniqueness theorems or ansatzes are invoked via self-citation. The derivation chain is self-contained against public data and independent benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
En- hanced depth navigation through augmented reality depth mapping in patients with low vision
Anastasios Nikolas Angelopoulos, Hossein Ameri, Debbie Mitra, and Mark Humayun. En- hanced depth navigation through augmented reality depth mapping in patients with low vision. Scientific reports, 9(1):11230, 2019
2019
-
[2]
Estimating and exploiting the aleatoric uncertainty in surface normal estimation
Gwangbin Bae, Ignas Budvytis, and Roberto Cipolla. Estimating and exploiting the aleatoric uncertainty in surface normal estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13137–13146, 2021
2021
-
[3]
Rethinking inductive biases for surface normal estima- tion
Gwangbin Bae and Andrew J Davison. Rethinking inductive biases for surface normal estima- tion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9535–9545, 2024
2024
-
[4]
ARKitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile RGB-d data
Gilad Baruch, Zhuoyuan Chen, Afshin Dehghan, Tal Dimry, Yuri Feigin, Peter Fu, Thomas Gebauer, Brandon Joffe, Daniel Kurz, Arik Schwartz, and Elad Shulman. ARKitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile RGB-d data. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021
2021
-
[5]
Adabins: Depth estimation using adaptive bins
Shariq Farooq Bhat, Ibraheem Alhashim, and Peter Wonka. Adabins: Depth estimation using adaptive bins. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4009–4018, 2021
2021
-
[6]
Normalcrafter: Learning temporally consistent normals from video diffusion priors
Yanrui Bin, Wenbo Hu, Haoyuan Wang, Xinya Chen, and Bing Wang. Normalcrafter: Learning temporally consistent normals from video diffusion priors. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8330–8339, 2025
2025
-
[7]
Midas v3.1 – a model zoo for robust monocular relative depth estimation
Reiner Birkl, Diana Wofk, and Matthias Müller. Midas v3. 1–a model zoo for robust monocular relative depth estimation.arXiv preprint arXiv:2307.14460, 2023
-
[8]
Black, Priyanka Patel, Joachim Tesch, and Jinlong Yang
Michael J. Black, Priyanka Patel, Joachim Tesch, and Jinlong Yang. BEDLAM: A synthetic dataset of bodies exhibiting detailed lifelike animated motion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8726–8737, 2023
2023
-
[9]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Do- minik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Transformerfusion: Monocular rgb scene reconstruction using transformers.Advances in Neural Information Processing Systems, 34:1403–1414, 2021
Aljaz Bozic, Pablo Palafox, Justus Thies, Angela Dai, and Matthias Nießner. Transformerfusion: Monocular rgb scene reconstruction using transformers.Advances in Neural Information Processing Systems, 34:1403–1414, 2021
2021
-
[11]
Pix2video: Video editing using image diffusion
Duygu Ceylan, Chun-Hao P Huang, and Niloy J Mitra. Pix2video: Video editing using image diffusion. InProceedings of the IEEE/CVF international conference on computer vision, pages 23206–23217, 2023
2023
-
[12]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22831–22840, 2025
2025
-
[13]
Flashdepth: Real-time streaming video depth estimation at 2k resolution
Gene Chou, Wenqi Xian, Guandao Yang, Mohamed Abdelfattah, Bharath Hariharan, Noah Snavely, Ning Yu, and Paul Debevec. Flashdepth: Real-time streaming video depth estimation at 2k resolution. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9638–9648, 2025
2025
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[15]
Depth map prediction from a single image using a multi-scale deep network.Advances in Neural Information Processing Systems, 27, 2014
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.Advances in Neural Information Processing Systems, 27, 2014
2014
-
[16]
Dens3r: A foundation model for 3d geometry prediction.arXiv preprint arXiv:2507.16290,
Xianze Fang, Jingnan Gao, Zhe Wang, Zhuo Chen, Xingyu Ren, Jiangjing Lyu, Qiaomu Ren, Zhonglei Yang, Xiaokang Yang, Yichao Yan, and Chengfei Lyu. Dens3r: A foundation model for 3d geometry prediction.arXiv preprint arXiv:2507.16290, 2025
-
[17]
Yi Feng, Zizhan Guo, Yu Ma, Hanli Wang, Rui Fan, et al. An instance-centric panoptic occupancy prediction benchmark for autonomous driving.arXiv preprint arXiv:2603.27238, 2026
-
[18]
Deep ordinal regression network for monocular depth estimation
Huan Fu, Mingming Gong, Chaohui Wang, Kayhan Batmanghelich, and Dacheng Tao. Deep ordinal regression network for monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2002–2011, 2018
2002
-
[19]
Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a 20 single image
Xiao Fu, Wei Yin, Mu Hu, Kaixuan Wang, Yuexin Ma, Ping Tan, Shaojie Shen, Dahua Lin, and Xiaoxiao Long. Geowizard: Unleashing the diffusion priors for 3d geometry estimation from a 20 single image. InEuropean Conference on Computer Vision, pages 241–258. Springer, 2024
2024
-
[20]
More: 3d visual geometry reconstruction meets mixture-of-experts.arXiv preprint arXiv:2510.27234,
Jingnan Gao, Zhe Wang, Xianze Fang, Xingyu Ren, Zhuo Chen, Shengqi Liu, Yuhao Cheng, Jiangjing Lyu, Xiaokang Yang, and Yichao Yan. More: 3d visual geometry reconstruction meets mixture-of-experts.arXiv preprint arXiv:2510.27234, 2025
-
[21]
Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
2013
-
[22]
Towards zero- shot scale-aware monocular depth estimation
Vitor Guizilini, Igor Vasiljevic, Dian Chen, Rares, Ambrus, , and Adrien Gaidon. Towards zero- shot scale-aware monocular depth estimation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9233–9243, 2023
2023
-
[23]
Jing He, Haodong Li, Wei Yin, Yixun Liang, Leheng Li, Kaiqiang Zhou, Hongbo Zhang, Bingbing Liu, and Ying-Cong Chen. Lotus: Diffusion-based visual foundation model for high-quality dense prediction.arXiv preprint arXiv:2409.18124, 2024
-
[24]
Mu Hu, Wei Yin, Chi Zhang, Zhipeng Cai, Xiaoxiao Long, Hao Chen, Kaixuan Wang, Gang Yu, Chunhua Shen, and Shaojie Shen. Metric3d v2: A versatile monocular geomet- ric foundation model for zero-shot metric depth and surface normal estimation.arXiv preprint arXiv:2404.15506, 2024
-
[25]
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos. arXiv preprint arXiv:2409.02095, 2024
-
[26]
Deepmvs: Learning multi-view stereopsis
Po-Han Huang, Kevin Matzen, Johannes Kopf, Narendra Ahuja, and Jia-Bin Huang. Deepmvs: Learning multi-view stereopsis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2821–2830, 2018
2018
-
[27]
On the importance of accurate geometry data for dense 3d vision tasks
HyunJun Jung, Patrick Ruhkamp, Guangyao Zhai, Nikolas Brasch, Yitong Li, Yannick Verdie, Jifei Song, Yiren Zhou, Anil Armagan, Slobodan Ilic, et al. On the importance of accurate geometry data for dense 3d vision tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 780–791, 2023
2023
-
[28]
Dynamicstereo: Consistent dynamic depth from stereo videos
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Dynamicstereo: Consistent dynamic depth from stereo videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[29]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Kon- rad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9492–9502, 2024
2024
-
[30]
B Ke, K Qu, T Wang, N Metzger, S Huang, B Li, A Obukhov, and K Schindler. Marigold: Affordable adaptation of diffusion-based image generators for image analysis.arXiv preprint arXiv:2505.09358, 2025
-
[31]
Mapanything: Universal feed-forward metric 3d reconstruction
Nikhil Varma Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, Jonathon Luiten, Manuel Lopez-Antequera, Samuel Rota Bulò, Christian Richardt, Deva Ramanan, Sebastian Scherer, and Peter Kontschieder. Mapanything: Universal feed-forward metric 3d reconstructio...
2026
-
[32]
STream3r: Scalable sequential 3d re- construction with causal transformer
Yushi LAN, Yihang Luo, Fangzhou Hong, Shangchen Zhou, Honghua Chen, Zhaoyang Lyu, Bo Dai, Shuai Yang, Chen Change Loy, and Xingang Pan. STream3r: Scalable sequential 3d re- construction with causal transformer. InInternational Conference on Learning Representations, 2026
2026
-
[33]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean Conference on Computer Vision, pages 71–91, 2024
2024
-
[34]
Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond
Yixuan Li, Lihan Jiang, Linning Xu, Yuanbo Xiangli, Zhenzhi Wang, Dahua Lin, and Bo Dai. Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3205–3215, 2023
2023
-
[35]
Lightwheelocc: A 3d occupancy synthetic dataset in autonomous driving
LightwheelAI and LightwheelOcc contributors. Lightwheelocc: A 3d occupancy synthetic dataset in autonomous driving. https://github.com/OpenDriveLab/LightwheelOcc, 2024
2024
-
[36]
Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. InInternational Conference on Learning Representations, 2026
2026
-
[37]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22160–22169, 2024. 21
2024
-
[38]
Geometry-aware 4D Video Generation for Robot Manipulation
Zeyi Liu, Shuang Li, Eric Cousineau, Siyuan Feng, Benjamin Burchfiel, and Shuran Song. Geometry-aware 4d video generation for robot manipulation.arXiv preprint arXiv:2507.01099, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Align3r: Aligned monocular depth estimation for dynamic videos
Jiahao Lu, Tianyu Huang, Peng Li, Zhiyang Dou, Cheng Lin, Zhiming Cui, Zhen Dong, Sai-Kit Yeung, Wenping Wang, and Yuan Liu. Align3r: Aligned monocular depth estimation for dynamic videos. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22820–22830, 2025
2025
-
[40]
Consistent video depth estimation.ACM Transactions on Graphics, 39(4):71–1, 2020
Xuan Luo, Jia-Bin Huang, Richard Szeliski, Kevin Matzen, and Johannes Kopf. Consistent video depth estimation.ACM Transactions on Graphics, 39(4):71–1, 2020
2020
-
[41]
Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo
Lukas Mehl, Jenny Schmalfuss, Azin Jahedi, Yaroslava Nalivayko, and Andrés Bruhn. Spring: A high-resolution high-detail dataset and benchmark for scene flow, optical flow and stereo. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023
2023
-
[42]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals
Emanuele Palazzolo, Jens Behley, Philipp Lottes, Philippe Giguere, and Cyrill Stachniss. Refusion: 3d reconstruction in dynamic environments for rgb-d cameras exploiting residuals. In IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 7855–7862, 2019
2019
-
[44]
Aria digital twin: A new benchmark dataset for egocentric 3d machine perception
Xiaqing Pan, Nicholas Charron, Yongqian Yang, Scott Peters, Thomas Whelan, Chen Kong, Omkar Parkhi, Richard Newcombe, and Yuheng (Carl) Ren. Aria digital twin: A new benchmark dataset for egocentric 3d machine perception. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20133–20143, 2023
2023
-
[45]
Tartanground: A large-scale dataset for ground robot perception and navigation
Manthan Patel, Fan Yang, Yuheng Qiu, Cesar Cadena, Sebastian Scherer, Marco Hutter, and Wenshan Wang. Tartanground: A large-scale dataset for ground robot perception and navigation. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 20524–20531. IEEE, 2025
2025
-
[46]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Luigi Piccinelli, Christos Sakaridis, Yung-Hsu Yang, Mattia Segu, Siyuan Li, Wim Abbeloos, and Luc Van Gool. Unidepthv2: Universal monocular metric depth estimation made simpler. arXiv preprint arXiv:2502.20110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10106–10116, 2024
2024
-
[48]
Xiaojuan Qi, Zhengzhe Liu, Renjie Liao, Philip HS Torr, Raquel Urtasun, and Jiaya Jia. Geonet++: Iterative geometric neural network with edge-aware refinement for joint depth and surface normal estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(2):969–984, 2020
2020
-
[49]
Vision transformers for dense prediction
René Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12179– 12188, 2021
2021
-
[50]
René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE transactions on pattern analysis and machine intelligence, 44(3):1623–1637, 2020
2020
-
[51]
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10912–10922, 2021
2021
-
[52]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[53]
The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes
German Ros, Laura Sellart, Joanna Materzynska, David Vazquez, and Antonio M Lopez. The synthia dataset: A large collection of synthetic images for semantic segmentation of urban scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3234–3243, 2016
2016
-
[54]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4104–4113, 2016
2016
-
[55]
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Matteo Poggi, and Yiyi Liao. Learning temporally consistent video depth from video diffusion priors.arXiv preprint arXiv:2406.01493, 2024
-
[56]
Indoor segmentation and support inference from rgbd images
Nathan Silberman, Derek Hoiem, Pushmeet Kohli, and Rob Fergus. Indoor segmentation and support inference from rgbd images. InProceedings of the European Conference on Computer 22 Vision, pages 746–760, 2012
2012
-
[57]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, Vijay Vasudevan, Wei Han, Jiquan Ngiam, Hang Zhao, Aleksei Timofeev, Scott Ettinger, Maxim Krivokon, Amy Gao, Aditya Joshi, Yu Zhang, Jonathon Shlens, Zhifeng Chen, and Dragomir Anguelov. Scalability in perception...
2020
-
[58]
Masked depth modeling for spatial perception.arXiv preprint arXiv:[2601.17895], 2026
Bin Tan, Changjiang Sun, Xiage Qin, Hanat Adai, Zelin Fu, Tianxiang Zhou, Han Zhang, Yinghao Xu, Xing Zhu, Yujun Shen, et al. Masked depth modeling for spatial perception.arXiv preprint arXiv:2601.17895, 2026
-
[59]
Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds
Zhenggang Tang, Yuchen Fan, Dilin Wang, Hongyu Xu, Rakesh Ranjan, Alexander Schwing, and Zhicheng Yan. Mv-dust3r+: Single-stage scene reconstruction from sparse views in 2 seconds. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5283–5293, 2025
2025
-
[60]
Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021
Zachary Teed and Jia Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras.Advances in neural information processing systems, 34:16558–16569, 2021
2021
-
[61]
Depth from motion for smartphone ar.ACM Transactions on Graphics, 37(6):1–19, 2018
Julien Valentin, Adarsh Kowdle, Jonathan T Barron, Neal Wadhwa, Max Dzitsiuk, Michael Schoenberg, Vivek Verma, Ambrus Csaszar, Eric Turner, Ivan Dryanovski, et al. Depth from motion for smartphone ar.ACM Transactions on Graphics, 37(6):1–19, 2018
2018
-
[62]
3D Reconstruction with Spatial Memory
Hengyi Wang and Lourdes Agapito. 3d reconstruction with spatial memory.arXiv preprint arXiv:2408.16061, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5294–5306, 2025
2025
-
[64]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21686–21697, 2024
2024
-
[65]
From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025
JiYuan Wang, Chunyu Lin, Lei Sun, Rongying Liu, Lang Nie, Mingxing Li, Kang Liao, Xiangxiang Chu, and Yao Zhao. From editor to dense geometry estimator.arXiv preprint arXiv:2509.04338, 2025
-
[66]
Flow-motion and depth network for monocular stereo and beyond.arXiv preprint arXiv:1909.05452, 2019
Kaixuan Wang and Shaojie Shen. Flow-motion and depth network for monocular stereo and beyond.arXiv preprint arXiv:1909.05452, 2019
-
[67]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10510–10522, 2025
2025
-
[68]
Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision
Ruicheng Wang, Sicheng Xu, Cassie Dai, Jianfeng Xiang, Yu Deng, Xin Tong, and Jiaolong Yang. Moge: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5261–5271, 2025
2025
-
[69]
Moge-2: Accurate monocular geometry with metric scale and sharp details
Ruicheng Wang, Sicheng Xu, Yue Dong, Yu Deng, Jianfeng Xiang, Zelong Lv, Guangzhong Sun, Xin Tong, and Jiaolong Yang. Moge-2: Accurate monocular geometry with metric scale and sharp details. InAdvances in Neural Information Processing Systems, 2025
2025
-
[70]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jérôme Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024
2024
-
[71]
Tartanair: A dataset to push the limits of visual slam
Wenshan Wang, Delong Zhu, Xiangwei Wang, Yaoyu Hu, Yuheng Qiu, Chen Wang, Yafei Hu, Ashish Kapoor, and Sebastian Scherer. Tartanair: A dataset to push the limits of visual slam. In 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 4909–4916, 2020
2020
-
[72]
Neural video depth stabilizer
Yiran Wang, Min Shi, Jiaqi Li, Zihao Huang, Zhiguo Cao, Jianming Zhang, Ke Xian, and Guosheng Lin. Neural video depth stabilizer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9466–9476, 2023
2023
-
[73]
π3: Permutation-equivariant visual geometry learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning. InInternational Conference on Learning Representations, 2026
2026
-
[74]
Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation
Tong Wu, Jiarui Zhang, Xiao Fu, Yuxin Wang, Jiawei Ren, Liang Pan, Wayne Wu, Lei Yang, Jiaqi Wang, Chen Qian, Dahua Lin, and Ziwei Liu. Omniobject3d: Large-vocabulary 3d object dataset for realistic perception, reconstruction and generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023
2023
-
[75]
Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos
Hongchi Xia, Yang Fu, Sifei Liu, and Xiaolong Wang. Rgbd objects in the wild: Scaling real-world 3d object learning from rgb-d videos. InProceedings of the IEEE/CVF conference 23 on computer vision and pattern recognition, pages 22378–22389, 2024
2024
-
[76]
Shaocong Xu, Songlin Wei, Qizhe Wei, Zheng Geng, Hong Li, Licheng Shen, Qianpu Sun, Shu Han, Bin Ma, Bohan Li, Chongjie Ye, Yuhang Zheng, Nan Wang, Saining Zhang, and Hao Zhao. Diffusion knows transparency: Repurposing video diffusion for transparent object depth and normal estimation.arXiv preprint arXiv:2512.23705, 2025
-
[77]
Ge- ometrycrafter: Consistent geometry estimation for open-world videos with diffusion priors
Tian-Xing Xu, Xiangjun Gao, Wenbo Hu, Xiaoyu Li, Song-Hai Zhang, and Ying Shan. Ge- ometrycrafter: Consistent geometry estimation for open-world videos with diffusion priors. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6632–6644, 2025
2025
-
[78]
Depth any video with scalable synthetic data.arXiv preprint arXiv:2410.10815, 2024
Honghui Yang, Di Huang, Wei Yin, Chunhua Shen, Haifeng Liu, Xiaofei He, Binbin Lin, Wanli Ouyang, and Tong He. Depth any video with scalable synthetic data.arXiv preprint arXiv:2410.10815, 2024
-
[79]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21924–21935, 2025
2025
-
[80]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.