ELAN4D: Embodiment-Centric 4D Supervision for Vision-Language-Action Models via Plug-and-Play Adaptation
Pith reviewed 2026-06-29 06:55 UTC · model grok-4.3
The pith
Embodiment-centric 4D supervision from robot keypoint tracks improves VLA policy performance under out-of-distribution shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
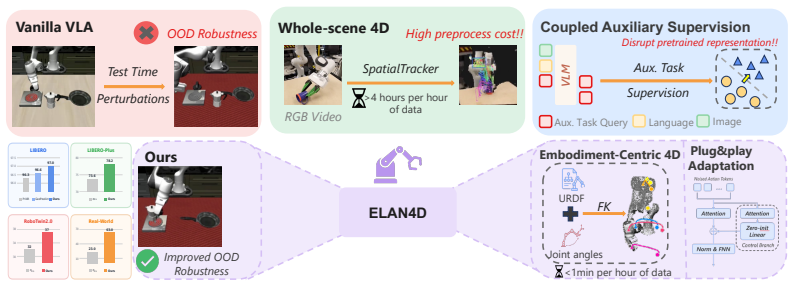
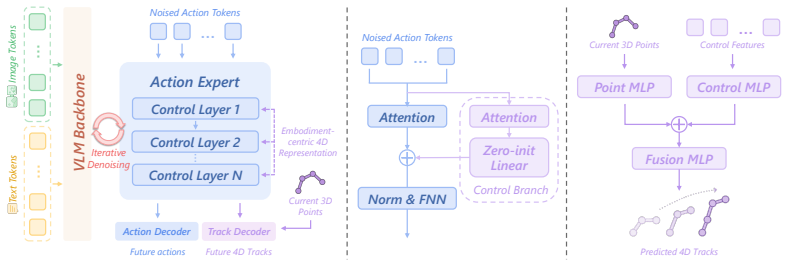
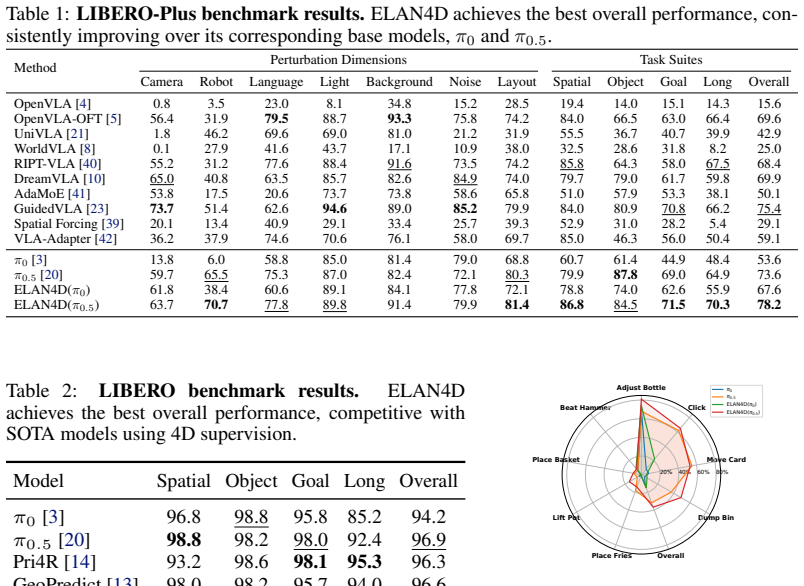
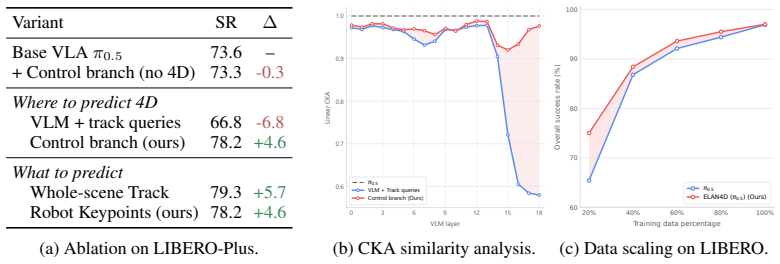
ELAN4D supplies embodiment-centric 4D supervision by deriving 3D displacement tracks of robot keypoints and the end-effector solely from forward kinematics on proprioceptive states, then injecting this signal through a lightweight plug-and-play track decoder that is discarded at inference; the resulting policies achieve the highest overall success rates and the largest improvements under camera, background, and layout perturbations on LIBERO, LIBERO-Plus, RoboTwin2.0, and real-robot tasks.
What carries the argument
Plug-and-play auxiliary branch containing a lightweight track decoder that receives 3D keypoint displacement tracks as predictive spatio-temporal supervision while isolating gradients from the pretrained vision-language backbone.
If this is right
- VLA policies reach higher success rates on both standard and perturbed manipulation benchmarks.
- The supervision requires no external trackers, cameras, or 3D reconstruction and adds negligible preprocessing cost.
- The deployed policy interface and inference speed remain identical to the original VLA model.
- Gains concentrate under camera, background, and layout distribution shifts.
Where Pith is reading between the lines
- The same proprioceptive tracks could be reused as self-supervision for other robot learning objectives that currently rely on visual reconstruction.
- Extending the track decoder to predict multi-step keypoint sequences might further strengthen long-horizon planning inside VLA models.
- Because the method isolates gradients, it offers a template for adding other embodiment signals without retraining large vision-language backbones.
- If keypoint tracks prove sufficient, similar 4D signals could be derived for non-manipulation embodiments such as mobile bases or humanoids.
Load-bearing premise
That 3D displacement tracks of robot keypoints derived from proprioceptive states via forward kinematics alone supply effective, metric, and generalizable predictive supervision that transfers to improved policy robustness.
What would settle it
A side-by-side training run on LIBERO-Plus in which models that receive the 4D keypoint tracks show no measurable difference in success rate from baseline models when tested under camera and layout shifts.
Figures
read the original abstract
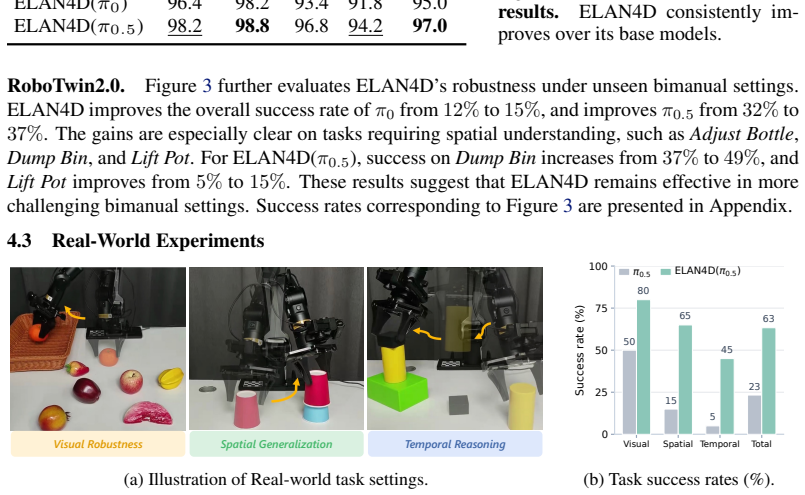
Vision-Language-Action (VLA) models have shown promise for robotic manipulation, yet most existing policies operate reactively by directly regressing actions from current observations, without explicitly modeling future dynamics. This limits their ability to generalize under out-of-distribution perturbations. To address this issue, we propose ELAN4D, an embodiment-centric, 4D-aware training framework that enhances VLA policies with future robot keypoint tracks as predictive spatio-temporal supervision. Using only forward kinematics from proprioceptive states, we derive 3D displacement tracks of robot keypoints, such as joints and the end-effector, with negligible preprocess cost. These tracks provide metric and compact supervision without requiring external trackers or reconstruction. A plug-and-play auxiliary branch with a lightweight track decoder injects this 4D signal into the action expert while preserving the pretrained vision-language backbone through gradient isolation. The track decoder is discarded during inference, leaving the base policy interface unchanged. Extensive experiments on LIBERO, LIBERO-Plus, RoboTwin2.0 and real-world manipulation tasks demonstrate that ELAN4D consistently improves over strong VLA baselines, achieving the best overall performance and substantial gains under out-of-distribution perturbations, including camera, background, and layout shifts. These results highlight the effectiveness of embodiment-centric 4D supervision for building more robust and generalizable manipulation policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ELAN4D, a plug-and-play training framework for Vision-Language-Action (VLA) models that injects embodiment-centric 4D supervision in the form of future 3D displacement tracks of robot keypoints (joints, end-effector) derived solely via forward kinematics from proprioceptive states. A lightweight auxiliary track decoder is attached only to the action expert; gradients are isolated from the pretrained vision-language backbone, and the decoder is discarded at inference. Experiments on LIBERO, LIBERO-Plus, RoboTwin2.0 and real-world tasks are claimed to show consistent gains over strong VLA baselines together with improved robustness under camera, background and layout shifts.
Significance. If the reported gains are shown to be attributable to the 4D signal rather than incidental factors, the work would offer a low-cost, metric supervision mechanism that leaves the inference interface unchanged and preserves pretrained backbones. The gradient-isolation design is a practical strength for deployment. The significance is tempered by the need to demonstrate that dynamics-centric tracks transfer to visual OOD robustness when visual features remain frozen.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim of 'substantial gains under out-of-distribution perturbations' is load-bearing, yet the abstract (and by extension the reported experiments) provides no baselines, statistical tests, ablation results, or quantitative tables isolating the track-loss contribution from other training factors. Without these, it is impossible to verify whether the OOD improvements arise from the claimed 4D mechanism.
- [Method] Method section (gradient isolation paragraph): the vision-language backbone is frozen while the track decoder predicts future keypoints from current visual observations. It is therefore unclear why a dynamics-centric signal should improve robustness to appearance-based shifts (camera, background, layout). An explicit ablation that removes the track loss while keeping all other factors fixed is required to support the causal claim.
minor comments (2)
- [Method] Notation for the 3D displacement tracks and the track-decoder architecture should be introduced with explicit equations rather than prose descriptions only.
- [Experiments] The manuscript should include a table comparing parameter counts and inference latency with and without the auxiliary branch to quantify the 'plug-and-play' overhead.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our contributions. We respond point-by-point to the major comments below and commit to revisions that strengthen the evidence for the 4D supervision mechanism.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim of 'substantial gains under out-of-distribution perturbations' is load-bearing, yet the abstract (and by extension the reported experiments) provides no baselines, statistical tests, ablation results, or quantitative tables isolating the track-loss contribution from other training factors. Without these, it is impossible to verify whether the OOD improvements arise from the claimed 4D mechanism.
Authors: The experiments section reports consistent improvements of ELAN4D over multiple strong VLA baselines across LIBERO, LIBERO-Plus, RoboTwin2.0, and real-world tasks, with the sole addition being the 4D track supervision under gradient isolation. These baseline comparisons isolate the contribution of the track loss. However, to address the request for explicit isolation, we will add a dedicated ablation table in the revised manuscript that trains an otherwise identical model without the track loss, including quantitative results, standard deviations, and statistical significance tests on the OOD splits. revision: yes
-
Referee: [Method] Method section (gradient isolation paragraph): the vision-language backbone is frozen while the track decoder predicts future keypoints from current visual observations. It is therefore unclear why a dynamics-centric signal should improve robustness to appearance-based shifts (camera, background, layout). An explicit ablation that removes the track loss while keeping all other factors fixed is required to support the causal claim.
Authors: Although the vision-language backbone is frozen, the track loss supervises the action expert (via the auxiliary decoder) to produce actions consistent with predicted future 3D keypoint displacements derived from proprioception. This embodiment-centric signal encourages the action expert to prioritize dynamics-relevant features within the fixed visual representations, yielding policies that generalize better under visual shifts. We agree an explicit ablation is needed and will include it in the revision, comparing performance with and without the track loss on the same OOD perturbations while holding all other factors fixed. revision: yes
Circularity Check
No significant circularity; supervision derived independently via forward kinematics
full rationale
The paper computes 3D displacement tracks of robot keypoints solely from proprioceptive states using forward kinematics, an external, metric computation independent of the VLA model's visual features or predictions. This signal is injected via a plug-and-play auxiliary decoder attached only to the action expert (with gradient isolation on the backbone), but the reported performance gains on LIBERO and OOD tasks are presented as empirical outcomes rather than quantities forced by definition or self-referential fitting. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing premises in the abstract or described mechanism. The derivation chain remains self-contained against external benchmarks like standard FK and does not reduce any central claim to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Forward kinematics from proprioceptive states can derive accurate 3D keypoint displacement tracks with negligible cost
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning (CoRL). PMLR, 2023
2023
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv.2410.2...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. P. Foster, P. R. Sanketi, Q. Vuong, et al. Openvla: An open-source vision-language-action model. InConference on Robot Learning (CoRL). PMLR, 2025
2025
-
[5]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
A Survey on Vision-Language-Action Models: An Action Tokenization Perspective
Y . Zhong, F. Bai, S. Cai, X. Huang, Z. Chen, X. Zhang, Y . Wang, S. Guo, T. Guan, K. N. Lui, et al. A survey on vision-language-action models: An action tokenization perspective.arXiv preprint arXiv:2507.01925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [7]
-
[8]
J. Cen, C. Yu, H. Yuan, Y . Jiang, S. Huang, J. Guo, X. Li, Y . Song, H. Luo, F. Wang, et al. Worldvla: Towards autoregressive action world model.arXiv preprint arXiv:2506.21539, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
H. Wu, Y . Jing, C. Cheang, G. Chen, J. Xu, X. Li, M. Liu, H. Li, and T. Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InICLR, 2024
2024
-
[10]
Zhang, H
W. Zhang, H. Liu, Z. Qi, Y . Wang, X. Yu, J. Zhang, R. Dong, J. He, H. Wang, Z. Zhang, et al. Dreamvla: A vision-language-action model dreamed with comprehensive world knowledge. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025. 9
2025
-
[11]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
J. Qian, B. Han, C. Shi, L. Xiao, L. Yang, S. Shi, and L. Jiang. Geopredict: Leveraging predictive kinematics and 3d gaussian geometry for precise vla manipulation.arXiv preprint arXiv:2512.16811, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
-
[15]
Y . Xiao, J. Wang, N. Xue, N. Karaev, I. Makarov, B. Kang, X. Zhu, H. Bao, Y . Shen, and X. Zhou. Spatialtrackerv2: 3d point tracking made easy. InICCV, 2025
2025
-
[16]
Zhang, X
J. Zhang, X. Chen, Y . Guo, Y . Hu, and J. Chen. VLM4VLA: Revisiting vision-language- models in vision-language-action models. InThe F ourteenth International Conference on Learning Representations (ICLR), 2026
2026
- [17]
-
[18]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision (CVPR), 2023
2023
-
[19]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[20]
Black, N
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. R. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, brian ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. Vuong, H. Wa...
2025
-
[21]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [22]
-
[23]
X. Jia, B. Yang, Z. Ge, X. Nie, Y . Zhou, C. Fan, Y . Li, Y . Chai, C. Jing, Z. Liang, Q. Bu, H. Cao, C. Wu, Q. Li, Z. Yang, C. Zhang, H. Li, Z. Wu, J. Yan, and Y .-G. Jiang. Guided- vla: Specifying task-relevant factors via plug-and-play action attention specialization.arXiv preprint arXiv:2605.12369, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations. In F orty-second International Conference on Machine Learning (ICML), 2024. 10
2024
- [25]
-
[26]
X. Fan, S. Deng, X. Wu, Y . Lu, Z. Li, M. Yan, Y . Zhang, Z. Zhang, H. Wang, and H. Zhao. Any3d-vla: Enhancing vla robustness via diverse point clouds.arXiv preprint arXiv:2602.00807, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
D. Qu, H. Song, Q. Chen, Y . Yao, X. Ye, Y . Ding, Z. Wang, J. Gu, B. Zhao, D. Wang, et al. Spatialvla: Exploring spatial representations for visual-language-action model.arXiv preprint arXiv:2501.15830, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [28]
-
[29]
Hafner, T
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination. InInternational Conference on Learning Representations (ICLR), 2019
2019
- [30]
-
[31]
Rynnvla-001: Using human demonstrations to improve robot manipulation
Y . Jiang, S. Huang, S. Xue, Y . Zhao, J. Cen, S. Leng, K. Li, J. Guo, K. Wang, M. Chen, F. Wang, D. Zhao, and X. Li. Rynnvla-001: Using human demonstrations to improve robot manipulation.arXiv preprint arXiv:2509.15212, 2025
- [32]
-
[33]
Hafner, K.-H
D. Hafner, K.-H. Lee, I. Fischer, and P. Abbeel. Deep hierarchical planning from pixels. Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[34]
J. Qian, Z. He, C. Shi, L. Xiao, and L. Jiang. Escape: Episodic spatial memory and adaptive execution policy for long-horizon mobile manipulation.arXiv preprint arXiv:2604.13633, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems (NeurIPS), 2023
2023
-
[36]
Black, M
K. Black, M. Nakamoto, P. Atreya, H. Walke, C. Finn, A. Kumar, and S. Levine. Zero- shot robotic manipulation with pre-trained image-editing diffusion models. InNeurIPS 2023 Workshop on Goal-Conditioned Reinforcement Learning, 2023
2023
-
[37]
Beyer, A
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Alab- dulmohsin, M. Tschannen, E. Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer. CoRR, 2024
2024
-
[38]
J. J. Craig.Introduction to robotics: mechanics and control, 3/E. Pearson Education India, 2009
2009
-
[39]
F. Li, W. Song, H. Zhao, J. Wang, P. Ding, D. Wang, L. ZENG, and H. Li. Spatial forcing: Implicit spatial representation alignment for vision-language-action model. InThe F ourteenth International Conference on Learning Representations (ICLR), 2026
2026
-
[40]
S. Tan, K. Dou, Y . Zhao, and P. Kr ¨ahenb¨uhl. Interactive post-training for vision-language- action models.arXiv preprint arXiv:2505.17016, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [41]
- [42]
-
[43]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision (CVPR), 2023. 12
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.