Generalistic or Specific Embeddings, Which is Better? An Empirical Study on Search for Clinical Coding in Non-English Languages
Pith reviewed 2026-06-29 07:24 UTC · model grok-4.3
The pith
A bi-encoder fine-tuned on synthetic clinical data matches BioBERT-ST on retrieval for ICD codes across five languages without English biomedical pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
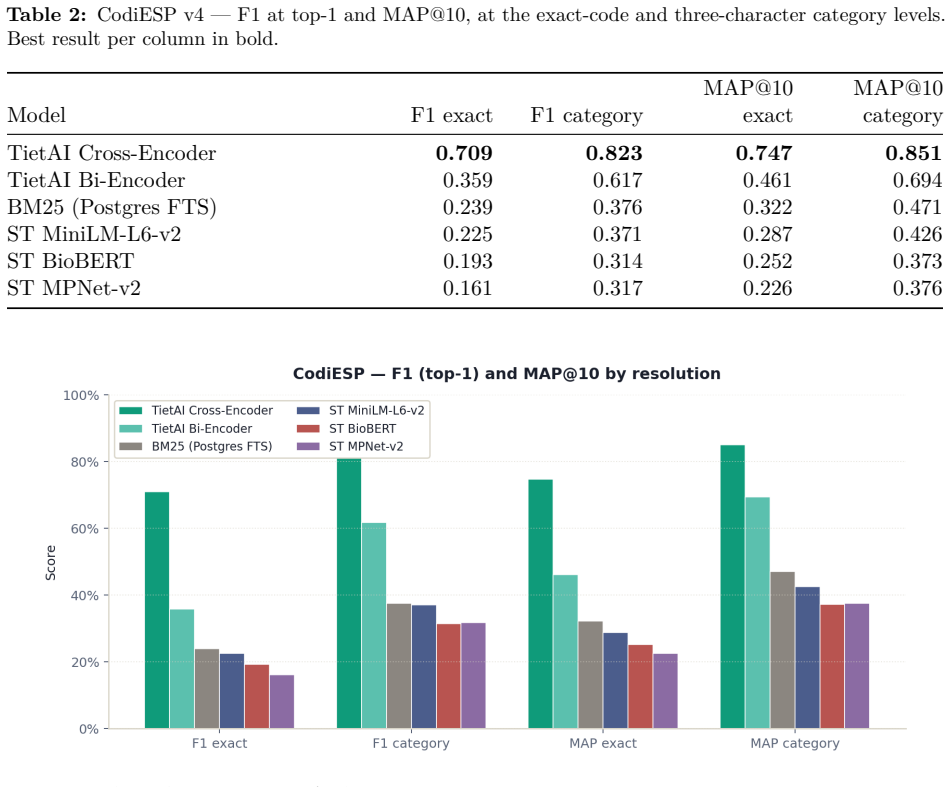
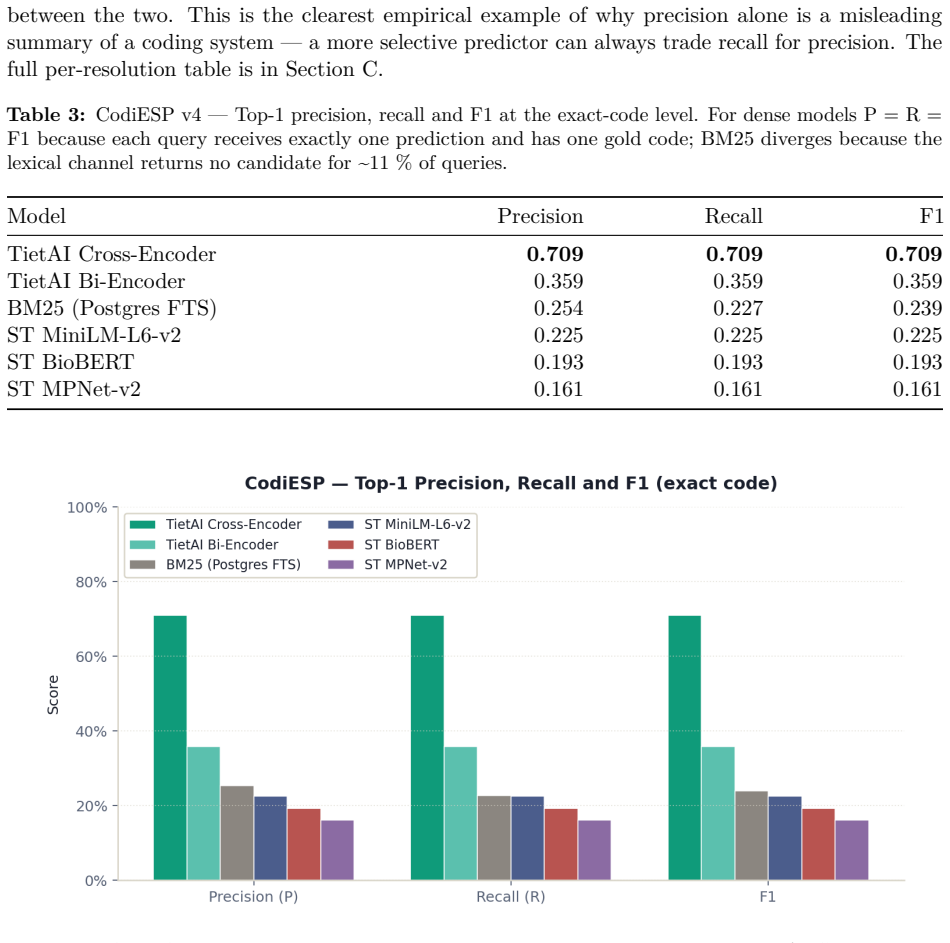
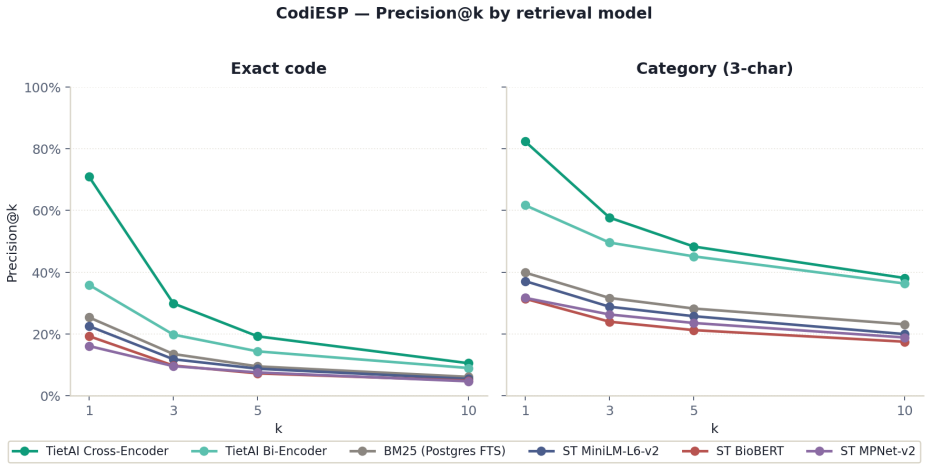
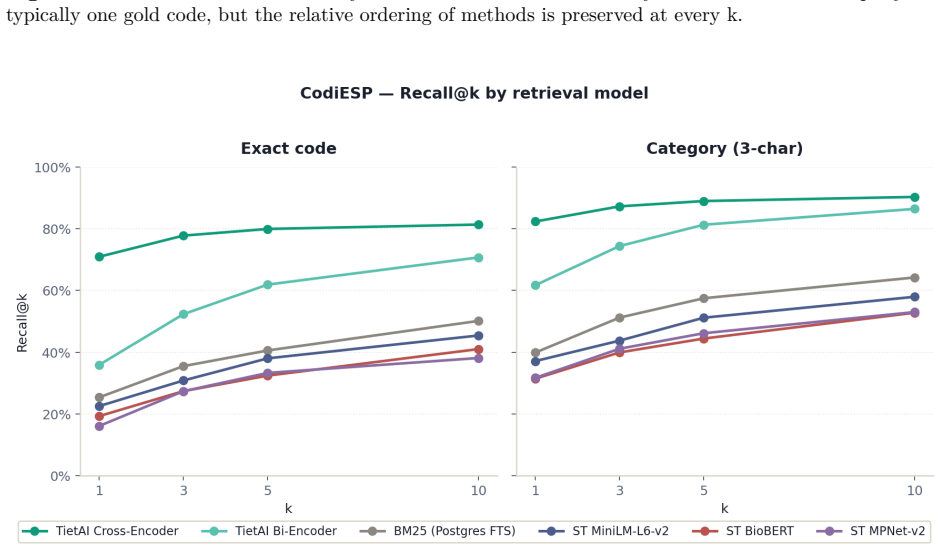
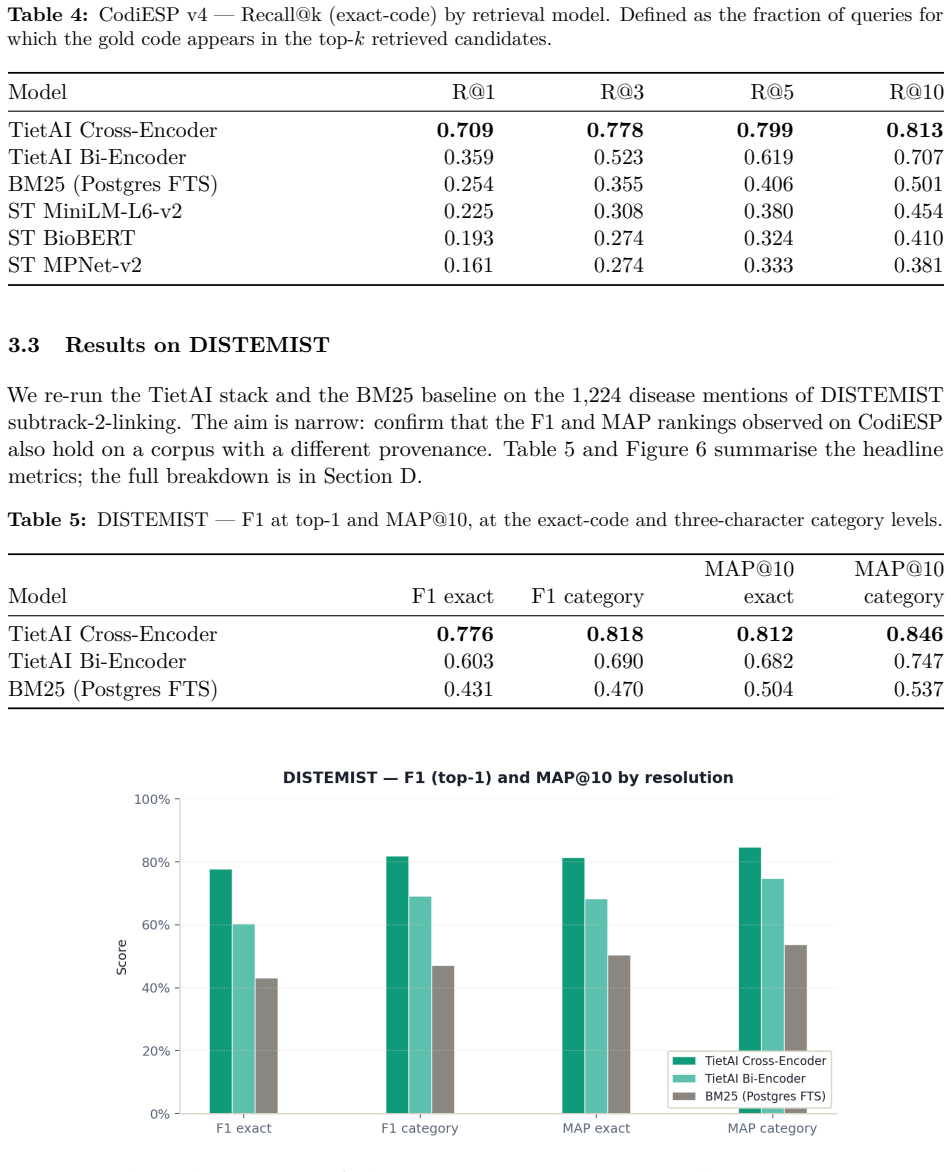
Fine-tuning the Spanish biomedical encoder on approximately 19,500 Gemini-generated synthetic pairs for six languages produces a bi-encoder that attains MRR 0.876 (versus BioBERT-ST 0.866), R@3 0.650 (versus 0.626) and R@5 0.804 (versus 0.790). The added cross-encoder reranker raises aggregate R@5 to 0.822 and improves four of the five non-English languages, with Portuguese reaching 0.829 versus BioBERT-ST's 0.714.
What carries the argument
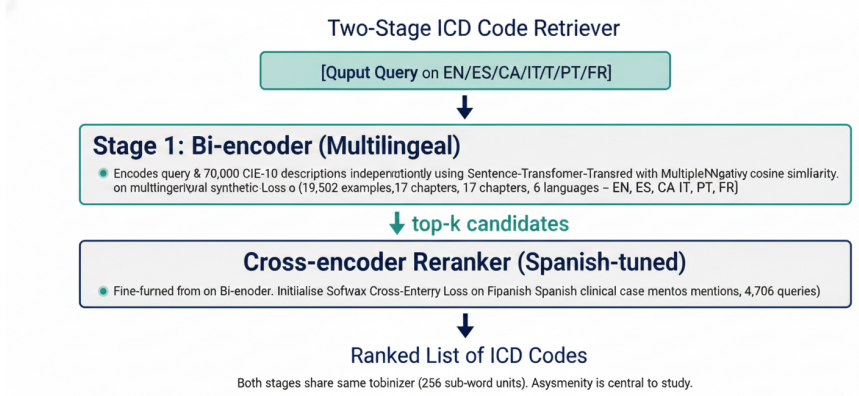
Two-stage retriever of bi-encoder followed by cross-encoder reranker, fine-tuned on LLM-generated synthetic clinical query-code pairs.
If this is right
- The bi-encoder alone matches or exceeds the English baseline on aggregate metrics without English pretraining.
- The cross-encoder reranker produces additional gains that concentrate in Catalan, Portuguese, Spanish and French.
- An open recipe exists for constructing domain-specific medical retrievers from generated data alone.
- The learning gain from the synthetic pairs lifts MRR from 0.755 to 0.876.
Where Pith is reading between the lines
- The same synthetic-data pipeline could be tested on other medical terminologies such as SNOMED CT.
- Mixing a small amount of real English data during fine-tuning might eliminate the minor English regression.
- Deployment in hospitals would still require separate validation on authentic query logs.
Load-bearing premise
The synthetic queries and code descriptions produced by the large language model match the distribution and linguistic features of real clinical text in each target language.
What would settle it
Evaluating the fine-tuned retriever on a collection of genuine hospital queries in Spanish or Portuguese and finding that R@5 falls below BioBERT-ST's level.
Figures
read the original abstract
Sentence-embedding models for semantic search are overwhelmingly developed and evaluated on English corpora. When applied to clinical retrieval in other languages -- particularly retrieval of ICD-10-CM / CIE-10 codes -- recall degrades in ways often masked by aggregate benchmarks. We study whether large generative language models can serve as data factories to close this gap. We build a two-stage retriever (bi-encoder followed by cross-encoder reranker), fine-tuned from a Spanish biomedical encoder (PlanTL-GOB-ES/bsc-bio-ehr-es) on Gemini-generated synthetic data covering English, Spanish, Catalan, Italian, Portuguese and French, and evaluate against BioBERT-ST and the un-tuned Spanish encoder. The bi-encoder alone matches BioBERT-ST on MRR (0.876 vs. 0.866) and overtakes it on R@3 (0.650 vs. 0.626) and R@5 (0.804 vs. 0.790) without English biomedical pretraining. Adding a cross-encoder reranker lifts aggregate R@5 to 0.822 and dominates on four of five languages (+0.017 Spanish, +0.033 Catalan, +0.018 French, +0.037 Portuguese) at the cost of a small English regression. The trade-off is clinically acceptable: Portuguese reaches R@5 = 0.829 vs. BioBERT-ST's 0.714. Contributions: an open recipe for building domain-specific medical retrievers from LLM-generated data; quantification of the learning gain (MRR 0.755 to 0.876, +15.9% with ~19,500 synthetic pairs); and a characterisation of where gains concentrate by language and rank.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that fine-tuning a Spanish biomedical bi-encoder (PlanTL-GOB-ES/bsc-bio-ehr-es) and a subsequent cross-encoder reranker on ~19,500 Gemini-generated synthetic (query, ICD-10 code) pairs across six languages produces retrieval performance that matches or exceeds BioBERT-ST on MRR (0.876 vs. 0.866), R@3, and R@5 without English biomedical pretraining; the reranker further improves aggregate R@5 to 0.822 and yields gains on four of five non-English languages.
Significance. If the synthetic data distribution matches real clinical queries, the work supplies a practical, open recipe for domain-specific multilingual clinical retrievers and quantifies a substantial learning gain (+15.9% MRR) from modest synthetic data volume, with language-specific trade-offs that are clinically relevant for Portuguese.
major comments (3)
- [Evaluation] Evaluation section: all reported metrics (including the headline bi-encoder MRR 0.876 / R@5 0.804 and reranker R@5 0.822) are computed exclusively on held-out Gemini-generated pairs; no side-by-side results on authentic clinical queries, discharge summaries, or real coding records from the five target languages are presented. This directly affects the central claim of applicability to non-English clinical coding.
- [Data generation] Data generation and validation subsection: the manuscript provides no quantitative comparison (e.g., n-gram overlap, abbreviation frequency, or stylistic metrics) between the Gemini synthetic queries and any sample of real clinical phrasing in Spanish, Catalan, etc., leaving the weakest assumption untested.
- [Results] Results tables: no statistical significance tests (paired t-test, bootstrap CI, or McNemar) are reported for the observed differences versus BioBERT-ST, so it is unclear whether the +0.010 MRR or +0.032 R@5 aggregate lifts are reliable.
minor comments (2)
- [Abstract] The abstract states the bi-encoder 'matches BioBERT-ST on MRR' yet reports 0.876 vs. 0.866; clarify whether this difference is considered within noise or statistically meaningful.
- [Experimental setup] Clarify the exact train / validation / test split ratios and whether any language-specific hyper-parameter tuning was performed.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and indicate the revisions planned.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: all reported metrics (including the headline bi-encoder MRR 0.876 / R@5 0.804 and reranker R@5 0.822) are computed exclusively on held-out Gemini-generated pairs; no side-by-side results on authentic clinical queries, discharge summaries, or real coding records from the five target languages are presented. This directly affects the central claim of applicability to non-English clinical coding.
Authors: We agree that the evaluation is performed solely on held-out synthetic pairs and that this constrains direct claims of applicability to real clinical coding workflows. Large-scale, publicly available labeled query sets for ICD-10 retrieval in Catalan, Portuguese and the other target languages do not exist, which is why the study used synthetic data. In revision we will add an explicit Limitations section that states this constraint, qualifies the applicability claims, and identifies collection of real clinical queries as necessary future work. revision: yes
-
Referee: [Data generation] Data generation and validation subsection: the manuscript provides no quantitative comparison (e.g., n-gram overlap, abbreviation frequency, or stylistic metrics) between the Gemini synthetic queries and any sample of real clinical phrasing in Spanish, Catalan, etc., leaving the weakest assumption untested.
Authors: The observation is correct; no quantitative distributional comparison between the synthetic queries and real clinical text was included. We lacked access to representative real-world query samples across all six languages. We will add this gap to the Limitations section and frame it as an open validation task for subsequent studies. revision: yes
-
Referee: [Results] Results tables: no statistical significance tests (paired t-test, bootstrap CI, or McNemar) are reported for the observed differences versus BioBERT-ST, so it is unclear whether the +0.010 MRR or +0.032 R@5 aggregate lifts are reliable.
Authors: We accept that the absence of significance testing leaves the magnitude of the reported gains open to question. Because the per-query scores are available, we will compute bootstrap confidence intervals on the key metrics and differences and report them in the revised tables. revision: yes
- Side-by-side evaluation on authentic clinical queries or discharge summaries from the five non-English languages, because no such labeled datasets were available to the authors.
Circularity Check
No significant circularity; empirical comparison on held-out synthetic data against external baselines
full rationale
The paper reports an empirical study that fine-tunes a bi-encoder and cross-encoder on Gemini-generated synthetic (query, code) pairs and measures MRR and recall on held-out synthetic test data, with direct numerical comparisons to BioBERT-ST and the untuned encoder. No derivation chain, equations, or uniqueness claims are present; performance figures are experimental outcomes rather than quantities forced by construction from the training inputs. No self-citations are invoked as load-bearing premises, and no ansatz or renaming patterns appear. The central claims rest on observable metric differences, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Synthetic data from Gemini is of sufficient quality and coverage to train effective retrievers for clinical coding tasks in the studied languages.
Reference graph
Works this paper leans on
-
[1]
Sentence-BERT: Sentence embeddings using siamese BERT-networks
Nils Reimers and Iryna Gurevych. Sentence-BERT: Sentence embeddings using siamese BERT-networks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019. 19
2019
-
[2]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[3]
Passage re-ranking with BERT, 2019
Rodrigo Nogueira and Kyunghyun Cho. Passage re-ranking with BERT, 2019
2019
-
[4]
Improving efficient neural ranking models with cross-architecture knowledge distillation
Sebastian Hofstätter, Sophia Althammer, Mete Schröder, Mete Sertkan, and Allan Hanbury. Improving efficient neural ranking models with cross-architecture knowledge distillation. In arXiv preprint arXiv:2010.02666, 2020
-
[5]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[6]
Benchmarking retrieval-augmented generation for medicine
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang. Benchmarking retrieval-augmented generation for medicine. InFindings of the Association for Computational Linguistics (ACL Findings), 2024
2024
-
[7]
Retrieval-augmented generation (RAG) in healthcare: A comprehensive review.AI (MDPI), 2025
Others. Retrieval-augmented generation (RAG) in healthcare: A comprehensive review.AI (MDPI), 2025
2025
-
[8]
Explainable prediction of medical codes from clinical text.NAACL-HLT, 2018
James Mullenbach, Sarah Wiegreffe, Jon Duke, Jimeng Sun, and Jacob Eisenstein. Explainable prediction of medical codes from clinical text.NAACL-HLT, 2018
2018
-
[9]
Shaoxiong Ji, Sina Pan, Erik Cambria, Pekka Marttinen, and Philip S. Yu. Does the magic of BERT apply to medical code assignment? a quantitative study.Computers in Biology and Medicine, 139:104998, 2021
2021
-
[10]
Code synonyms do matter: Multiple synonyms matching network for automatic ICD coding
Zheng Yuan, Chuanqi Tan, and Songfang Huang. Code synonyms do matter: Multiple synonyms matching network for automatic ICD coding. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022
2022
-
[11]
BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. BioBERT: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
2020
-
[12]
Murphy, Willie Boag, Wei-Hung Weng, Di Jin, Tristan Naumann, and Matthew B
Emily Alsentzer, John R. Murphy, Willie Boag, Wei-Hung Weng, Di Jin, Tristan Naumann, and Matthew B. A. McDermott. Publicly available clinical BERT embeddings.Proceedings of the 2nd Clinical Natural Language Processing Workshop (NAACL), 2019
2019
-
[13]
Pubmedqa: A dataset for biomedical research question answering.EMNLP, 2019
Qiao Jin, Bhuwan Dhingra, William Cohen, and Xinghua Lu. Pubmedqa: A dataset for biomedical research question answering.EMNLP, 2019
2019
-
[14]
The state and fate of linguistic diversity and inclusion in the NLP world.Proceedings of the 58th Annual Meeting of the ACL, 2020
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. The state and fate of linguistic diversity and inclusion in the NLP world.Proceedings of the 58th Annual Meeting of the ACL, 2020
2020
-
[15]
Unsupervised cross-lingual representation learning at scale
Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. Unsupervised cross-lingual representation learning at scale. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020. 20
2020
-
[16]
How multilingual is multilingual BERT? In Proceedings of the 57th Annual Meeting of the ACL, 2019
Telmo Pires, Eva Schlinger, and Dan Garrette. How multilingual is multilingual BERT? In Proceedings of the 57th Annual Meeting of the ACL, 2019
2019
-
[17]
Making monolingual sentence embeddings multilingual using knowledge distillation
Nils Reimers and Iryna Gurevych. Making monolingual sentence embeddings multilingual using knowledge distillation. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[18]
Clinical natural language processing in languages other than English: Opportunities and challenges.Journal of Biomedical Semantics, 9(12), 2018
Aurélie Névéol, Hercules Dalianis, Sumithra Velupillai, Guergana Savova, and Pierre Zweigen- baum. Clinical natural language processing in languages other than English: Opportunities and challenges.Journal of Biomedical Semantics, 9(12), 2018
2018
-
[19]
Pretrained biomedical language models for clinical NLP in Spanish.Proceedings of the 21st Workshop on Biomedical Language Processing, BioNLP at ACL, 2022
Casimiro Pio Carrino, Joan Llop, Marc Pàmies, Asier Gutiérrez-Fandiño, Jordi Armengol- Estapé, Joaquín Silveira-Ocampo, Alfonso Valencia, Aitor Gonzalez-Agirre, and Marta Villegas. Pretrained biomedical language models for clinical NLP in Spanish.Proceedings of the 21st Workshop on Biomedical Language Processing, BioNLP at ACL, 2022
2022
-
[20]
From zero to hero: On the limitations of zero-shot cross-lingual transfer with multilingual transformers
Anne Lauscher, Vinit Ravishankar, Ivan Vulić, and Goran Glavaš. From zero to hero: On the limitations of zero-shot cross-lingual transfer with multilingual transformers. InEMNLP, 2020
2020
-
[21]
Beto, bentz, becas: The surprising cross-lingual effectiveness of BERT
Shijie Wu and Mark Dredze. Beto, bentz, becas: The surprising cross-lingual effectiveness of BERT. InEMNLP-IJCNLP, 2019
2019
-
[22]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-Instruct: Aligning language models with self-generated instruc- tions. InProceedings of the 61st Annual Meeting of the ACL, 2023
2023
-
[23]
InPars: Unsupervised dataset generation for information retrieval
Luiz Bonifacio, Hugo Abonizio, Marzieh Fadaee, and Rodrigo Nogueira. InPars: Unsupervised dataset generation for information retrieval. InSIGIR, 2022
2022
-
[24]
Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith Hall, and Ming-Wei Chang
Zhuyun Dai, Vincent Y. Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith Hall, and Ming-Wei Chang. Promptagator: Few-shot dense retrieval from 8 examples, 2022
2022
-
[25]
Smith, Nima PourNejatian, Anthony B
Cheng Peng, Xi Yang, Aokun Chen, Kaleb E. Smith, Nima PourNejatian, Anthony B. Costa, Cheryl Martin, Mona G. Flores, Ying Zhang, Tanja Magoc, Gloria Lipori, Duane A. Mitchell, Naykky S. Ospina, Mustafa M. Ahmed, William R. Hogan, Elizabeth A. Shenkman, Yi Guo, Jiang Bian, and Yonghui Wu. A study of generative large language model for medical research and ...
2023
-
[26]
Knowledge-infused prompting: Assessing and advancing clinical text data generation with large language models
Ran Xu, Hejie Cui, Yue Yu, Xuan Kan, Wenqi Shi, Yuchen Zhuang, Wei Jin, Joyce Ho, and Carl Yang. Knowledge-infused prompting: Assessing and advancing clinical text data generation with large language models. InFindings of the Association for Computational Linguistics: ACL 2024, 2024
2024
-
[27]
Two directions for clinical data generation with large language models: Data-to-label and label-to-data
Rumeng Li, Xun Wang, and Hong Yu. Two directions for clinical data generation with large language models: Data-to-label and label-to-data. InFindings of the Association for Computational Linguistics: EMNLP 2023, 2023
2023
-
[28]
MedSyn: LLM-based synthetic medical text generation framework
Gleb Kumichev, Pavel Blinov, Yulia Kuzkina, Vasily Goncharov, Galina Zubkova, Nikolai Zenovkin, Aleksei Goncharov, and Andrey Savchenko. MedSyn: LLM-based synthetic medical text generation framework. InMachine Learning and Knowledge Discovery in Databases, 2024. 21
2024
-
[29]
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. On LLMs-driven synthetic data generation, curation, and evaluation: A survey.arXiv preprint arXiv:2406.15126, 2024
-
[30]
The curse of recursion: Training on generated data makes models forget, 2023
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, and Ross Anderson. The curse of recursion: Training on generated data makes models forget, 2023
2023
-
[31]
Efficient natural language response suggestion for Smart Reply, 2017
Matthew Henderson, Rami Al-Rfou, Brian Strope, Yun-Hsuan Sung, László Lukács, Ruiqi Guo, Sanjiv Kumar, Balint Miklos, and Ray Kurzweil. Efficient natural language response suggestion for Smart Reply, 2017
2017
-
[32]
Learning to rank: From pairwise approach to listwise approach
Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. Learning to rank: From pairwise approach to listwise approach. InProceedings of the 24th International Conference on Machine Learning, pages 129–136, 2007
2007
-
[33]
Gemini 2.5 pro, 2025
Google DeepMind. Gemini 2.5 pro, 2025
2025
-
[34]
Overview of automatic clinical coding: Annotations, guidelines, and solutions for non-English clinical cases at CodiEsp track of CLEF eHealth 2020
Antonio Miranda-Escalada, Aitor Gonzalez-Agirre, Jordi Armengol-Estapé, and Martin Krallinger. Overview of automatic clinical coding: Annotations, guidelines, and solutions for non-English clinical cases at CodiEsp track of CLEF eHealth 2020. InWorking Notes of CLEF 2020 – Conference and Labs of the Evaluation Forum, 2020
2020
-
[35]
Unsupervised keyword combination query generation from online health related content for evidence-based fact checking
Pritam Deka and Anna Jurek-Loughrey. Unsupervised keyword combination query generation from online health related content for evidence-based fact checking. InThe 23rd International Conference on Information Integration and Web Intelligence, pages 267–277, 2021
2021
-
[36]
MPNet: Masked and permuted pre-training for language understanding
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MPNet: Masked and permuted pre-training for language understanding. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[37]
Overview of DisTEMIST at BioASQ: Automatic detection and normalization of diseases from spanish clinical cases
Antonio Miranda-Escalada, Luis Gascó, Salvador Lima-López, Eulàlia Farré-Maduell, Daniel Estrada, Anastasios Nentidis, Anastasia Krithara, Georgios Katsimpras, Georgios Paliouras, and Martin Krallinger. Overview of DisTEMIST at BioASQ: Automatic detection and normalization of diseases from spanish clinical cases. InWorking Notes of CLEF 2022, 2022
2022
-
[38]
Centers for Medicare & Medicaid Services and National Center for Health Statistics.ICD-10- CM Official Guidelines for Coding and Reporting, FY 2024, 2024
2024
-
[39]
Ministerio de Sanidad, Servicios Sociales e Igualdad, Gobierno de España.Manual de Codificación CIE-10-ES Diagnósticos, 6ªEdición, 2024
2024
-
[40]
How good is your tokenizer? on the monolingual performance of multilingual language models
Phillip Rust, Jonas Pfeiffer, Ivan Vulić, Sebastian Ruder, and Iryna Gurevych. How good is your tokenizer? on the monolingual performance of multilingual language models. In Proceedings of ACL-IJCNLP, 2021
2021
-
[41]
Mortensen, Noah A
Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Jungo Kasai, David R. Mortensen, Noah A. Smith, and Yulia Tsvetkov. Do all languages cost the same? tokenization in the era of commercial language models. InProceedings of EMNLP, 2023
2023
-
[42]
Aleksandar Petrov, Emanuele La Malfa, Philip H. S. Torr, and Adel Bibi. Language model tokenizers introduce unfairness between languages. InAdvances in Neural Information Processing Systems (NeurIPS), 2023. 22
2023
-
[43]
Multilingual clinical NER: Translation or cross-lingual transfer?Proceedings of the LREC BioNLP Workshop, 2019
Felipe Soares, Marta Villegas, Aitor Gonzalez-Agirre, Martin Krallinger, and Jordi Armengol- Estapé. Multilingual clinical NER: Translation or cross-lingual transfer?Proceedings of the LREC BioNLP Workshop, 2019
2019
-
[44]
IAM at CLEF eHealth 2020: Concept annotation in Spanish electronic health records
Aitor Garcia-Pablos, Naiara Perez, and Montse Cuadros. IAM at CLEF eHealth 2020: Concept annotation in Spanish electronic health records. InWorking Notes of CLEF 2020, 2020
2020
-
[45]
Integrating agentic artificial intelligence to automate ICD-10 medical coding.Informatics (MDPI), 2026
Preprints.org Authors. Integrating agentic artificial intelligence to automate ICD-10 medical coding.Informatics (MDPI), 2026
2026
-
[46]
Fernando Gallego, Guillermo López-García, Luis Gascó-Sánchez, Martin Krallinger, and Francisco J. Veredas. ClinLinker: Medical entity linking of clinical concept mentions in Spanish. InInternational Conference on Computational Science (ICCS), 2024
2024
-
[47]
PLM-ICD: Automatic ICD coding withpretrainedlanguagemodels
Chao-Wei Huang, Shang-Chi Tsai, and Yun-Nung Chen. PLM-ICD: Automatic ICD coding withpretrainedlanguagemodels. InProceedings of the 4th Clinical Natural Language Processing Workshop (ACL-ClinicalNLP), 2022
2022
-
[48]
GoM-ICD: Automatic ICD coding with gap schemes and mixture of experts.Big Data Mining and Analytics, 2025
Yuxiang Pan et al. GoM-ICD: Automatic ICD coding with gap schemes and mixture of experts.Big Data Mining and Analytics, 2025
2025
-
[49]
Automatic ICD coding using LLMs: a systematic review.medRxiv preprint, 2025
medRxiv Authors. Automatic ICD coding using LLMs: a systematic review.medRxiv preprint, 2025
2025
-
[50]
HealthBench Professional: Evaluating Large Language Models on Real Clinician Chats
OpenAI. HealthBench Professional: Evaluating large language models on real clinician chats. arXiv preprint arXiv:2604.27470, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Ruchir Arora et al. HealthBench: Evaluating large language models towards improved human health.arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Introducing HealthBench, 2025
OpenAI. Introducing HealthBench, 2025
2025
- [53]
-
[54]
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments.npj Digital Medicine, 2026
Samuel Schmidgall et al. AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments.npj Digital Medicine, 2026
2026
-
[55]
MedAgentBench: A realistic virtual EHR environment to benchmark medical LLM agents.NEJM AI, 2025
Stanford ML Group et al. MedAgentBench: A realistic virtual EHR environment to benchmark medical LLM agents.NEJM AI, 2025
2025
-
[56]
PhysicianBench: Evaluating LLM Agents in Real-World EHR Environments
Ruoqi Liu, Imran Q. Mohiuddin, Austin J. Schoeffler, et al. PhysicianBench: Evaluating LLM agents in real-world EHR environments.arXiv preprint arXiv:2605.02240, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Lin Yang, Yuancheng Yang, Xu Wang, Changkun Liu, and Haihua Yang. MedMT-Bench: Can LLMs memorize and understand long multi-turn conversations in medical scenarios?arXiv preprint arXiv:2603.23519, 2026
-
[58]
MedAgents: Large language models as collaborators for zero-shot medical reasoning
Xiangru Tang et al. MedAgents: Large language models as collaborators for zero-shot medical reasoning. 2024
2024
-
[59]
Glicksberg, Girish N
Alon Gorenshtein, Mahmud Omar, Benjamin S. Glicksberg, Girish N. Nadkarni, and Eyal Klang. AI agents in clinical medicine: A systematic review.medRxiv preprint, 2025. 23
2025
-
[60]
Medical Reasoning with Large Language Models: A Survey and MR-Bench
Others. Medical reasoning with large language models: A survey and MR-Bench.arXiv preprint arXiv:2604.08559, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
Oliver Normand, Esther Borsi, Mitch Fruin, Lauren E. Walker, et al. A real-world evaluation of LLM medication safety reviews in NHS primary care.arXiv preprint arXiv:2512.21127, 2025
-
[62]
Large language model as clinical decision support system augments medication safety in 16 clinical specialties.npj Digital Medicine, 2025
Others. Large language model as clinical decision support system augments medication safety in 16 clinical specialties.npj Digital Medicine, 2025
2025
-
[63]
Matthew Lewis, Samuel Thio, Amy Roberts, et al. Grounding large language models in clinical evidence: A retrieval-augmented generation system for querying UK NICE clinical guidelines. arXiv preprint arXiv:2510.02967, 2025
-
[64]
Prompt-Level Distillation: A Non-Parametric Alternative to Model Fine-Tuning for Efficient Reasoning
Derek Wong et al. Prompt-level distillation.arXiv preprint arXiv:2602.21103, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[65]
Gemini 3.1 pro, 2026
Google DeepMind. Gemini 3.1 pro, 2026
2026
-
[66]
Gpt-5.4, 2026
OpenAI. Gpt-5.4, 2026. Accessed 2026-03-05
2026
-
[67]
MedGemma: Open medical foundation models, 2025
Google Research. MedGemma: Open medical foundation models, 2025
2025
-
[68]
TietAI Hydra Platform, 2026
Roberto Cruz. TietAI Hydra Platform, 2026
2026
-
[69]
TietAI Evals Public: Empirical analysis results for MDIA on HealthBench Professional, 2026
Cruz, Roberto, Rey-Blanco, David. TietAI Evals Public: Empirical analysis results for MDIA on HealthBench Professional, 2026. Public repository
2026
-
[70]
Chateval: Towards better llm-based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. InInternational Conference on Learning Representations, 2024
2024
-
[71]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena, 2023
2023
-
[72]
Multi-agent debate for llm judges with adaptive stability detection
Tianyu Hu, Zhen Tan, Song Wang, Huaizhi Qu, and Tianlong Chen. Multi-agent debate for llm judges with adaptive stability detection. InAdvances in Neural Information Processing Systems, 2025
2025
-
[73]
Laura Dietz, Oleg Zendel, Peter Bailey, Charles L. A. Clarke, Ellese Cotterill, Jeff Dalton, Faegheh Hasibi, Mark Sanderson, and Nick Craswell. Principles and guidelines for the use of llm judges. InProceedings of the 2025 International ACM SIGIR Conference on Innovative Concepts and Theories in Information Retrieval, ICTIR ’25, pages 1–12. ACM, 2025
2025
-
[74]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large- scale multi-subject multi-choice dataset for medical domain question answering.arXiv preprint arXiv:2203.14371, 2022
-
[75]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021
Di Jin, Eileen Pan, Nahid Oufattole, Wei-Hung Weng, Hui Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams.Applied Sciences, 11(14):6421, 2021. 24
2021
-
[76]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Sivasankar Kannan, Dawn Song, and Jacob Stein- hardt. Measuring massive multitask language understanding.arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[77]
Large language models encode clinical knowledge.Nature, 620:172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, et al. Large language models encode clinical knowledge.Nature, 620:172–180, 2023
2023
-
[78]
Hashimoto
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators, 2024
2024
-
[79]
Yu Ying Chiu, Michael S. Lee, Rachel Calcott, Brandon Handoko, Paul de Font-Reaulx, Paula Rodriguez, Chen Bo Calvin Zhang, Ziwen Han, Udari Madhushani Sehwag, Yash Maurya, Christina Knight, Harry Lloyd, Florence Bacus, Mantas Mazeika, Bing Liu, Yejin Choi, Mitchell Gordon, and Sydney Levine. Morebench: Evaluating procedural and pluralistic moral reasoning...
2025
-
[80]
Explaining length bias in llm-based preference evaluations, 2024
Zhengyu Hu, Linxin Song, Jieyu Zhang, Zheyuan Xiao, Tianfu Wang, Zhenyu Chen, Jianxun Lian, Nicholas Jing Yuan, Kaize Ding, and Hui Xiong. Explaining length bias in llm-based preference evaluations, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.