ElasticMem: Latent Memory as a Learnable Resource for LLM Agents
Pith reviewed 2026-06-28 23:04 UTC · model grok-4.3
The pith
Treating latent memory as a learnable elastic resource lets LLM agents adaptively retrieve and budget memory items to improve task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
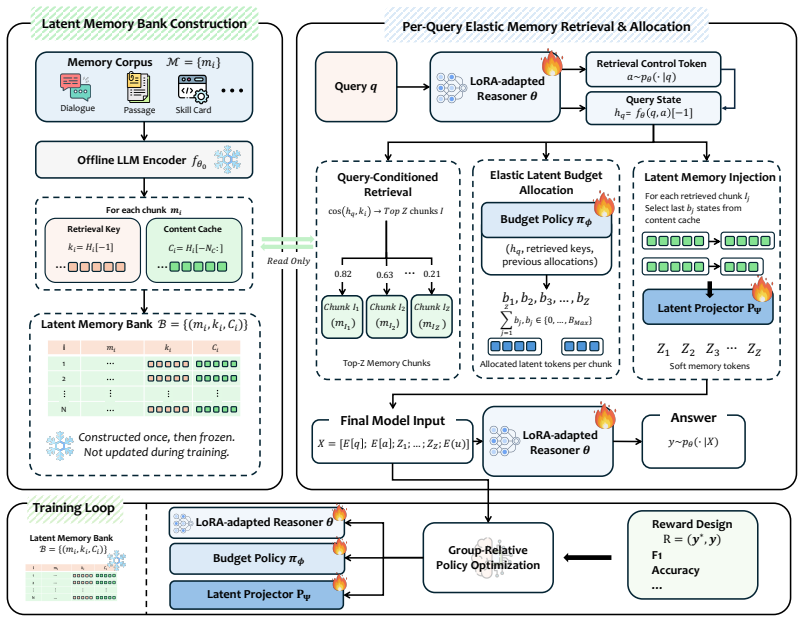
ElasticMem builds an offline latent memory bank with retrieval keys and content caches, retrieves memories adaptively from the reasoner's hidden state, assigns each retrieved memory a variable latent budget through a learned policy, and injects selected latent states as soft memory tokens for generation. The full memory-use process is optimized with downstream task rewards through group-relative policy optimization. Across Qwen2.5-3B-Instruct and Qwen2.5-7B-Instruct backbones, this produces weighted average QA accuracy gains of 26.2% and 24.6% and ALFWorld success rate gains of 66.3% and 27.2% over the strongest baselines while recording the lowest ALFWorld token cost.
What carries the argument
The learned policy for adaptive retrieval from hidden states combined with variable latent budget allocation, optimized via group-relative policy optimization on task rewards.
If this is right
- Adaptive retrieval from hidden states prioritizes useful evidence and transferable plans beyond rigid cosine similarity.
- Variable latent budget allocation reduces token overhead while raising success rates on memory-intensive QA and control tasks.
- The same elastic mechanism produces gains on both 3B and 7B backbones, indicating the policy is not tied to a single model scale.
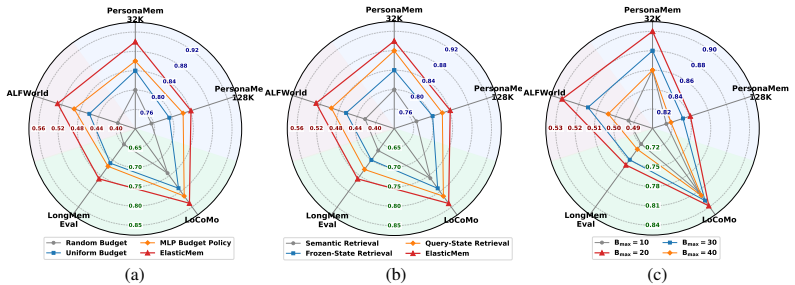
- Ablations confirm that both the adaptive retrieval component and the elastic budget component contribute to the observed performance lift.
Where Pith is reading between the lines
- If the policy truly generalizes, agents could maintain coherent state over interaction lengths that exceed current context windows without proportional cost increases.
- The same reward-driven elasticity could be applied to other internal resources such as KV-cache eviction or attention span.
- Success on ALFWorld suggests the approach may transfer to other embodied or multi-step planning domains that require reuse of past plans.
Load-bearing premise
Optimizing memory retrieval and budget allocation with downstream task rewards produces a policy that generalizes across tasks rather than fitting only the training distribution.
What would settle it
Training the policy on MemorySuite tasks and then testing it on a new memory-intensive task outside that suite, such as a different long-horizon embodied environment, and observing no accuracy or success improvement would falsify the claim of a generalizable elastic memory policy.
Figures
read the original abstract
Long-term memory is essential for LLM agents to reason coherently across extended interactions, personalize responses, and reuse past experience. However, existing memory-augmented methods typically treat memory as a fixed resource: text-space approaches concatenate retrieved memories into the context window, causing substantial token overhead and sensitivity to noisy evidence, while latent-space approaches reduce textual cost but still rely on rigid retrieval or fixed-capacity memory interfaces. This creates a mismatch between query-dependent memory utility and fixed memory allocation. We propose ElasticMem, a memory-augmented LLM framework that learns to use memory as an elastic latent resource. ElasticMem builds an offline latent memory bank with retrieval keys and content caches, retrieves memories adaptively from the reasoner's hidden state, assigns each retrieved memory a variable latent budget through a learned policy, and injects selected latent states as soft memory tokens for generation. The full memory-use process is optimized with downstream task rewards through group-relative policy optimization. We evaluate ElasticMem on MemorySuite, covering memory-intensive QA and embodied agent control. Across Qwen2.5-3B-Instruct and Qwen2.5-7B-Instruct backbones, ElasticMem improves weighted average QA accuracy by 26.2% and 24.6%, and improves ALFWorld success rate by 66.3% and 27.2%, respectively, over the strongest baselines, while achieving the lowest ALFWorld token cost. Ablations and qualitative analyses further show that adaptive retrieval and elastic budget allocation help ElasticMem prioritize useful evidence and transferable plans beyond rigid cosine similarity. Our code for ElasticMem will be released at https://github.com/ulab-uiuc/ElasticMem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ElasticMem, a framework for LLM agents that builds an offline latent memory bank, performs adaptive retrieval from the reasoner's hidden states, assigns variable latent budgets to retrieved memories via a learned policy, and injects them as soft memory tokens. The entire memory-use process is optimized end-to-end with group-relative policy optimization (GRPO) on downstream task rewards. On MemorySuite QA and ALFWorld, it reports large gains (26.2%/24.6% weighted QA accuracy and 66.3%/27.2% success rate for 3B/7B Qwen2.5 backbones) over strongest baselines while using the lowest token cost; ablations suggest benefits from adaptive retrieval and elastic allocation.
Significance. If the results and generalizability claims hold, ElasticMem would advance memory-augmented agents by demonstrating that memory allocation and retrieval can be learned as an elastic, reward-optimized resource rather than fixed or rigid. The planned code release supports reproducibility. The work addresses a clear mismatch between query-dependent memory utility and fixed allocation in prior text- and latent-space methods.
major comments (3)
- [Experiments] Experiments section: the reported gains (e.g., 26.2% QA accuracy, 66.3% ALFWorld success) are presented without details on baseline implementations, number of random seeds, variance, statistical tests, or train/test splits, so the data support for the central performance claims cannot be assessed.
- [Evaluation] Evaluation / §4: no cross-task transfer, held-out task, or out-of-distribution experiments are described to test whether the GRPO-optimized memory budget allocation policy learns transferable utility signals rather than task-specific retrieval patterns on MemorySuite/ALFWorld; this directly bears on the claim that memory becomes a generalizable 'learnable resource'.
- [Method] Method section, policy description: the free parameters of the memory budget allocation policy are optimized on downstream rewards, but no analysis shows that the resulting policy reduces to quantities independent of the specific training environments, leaving open the possibility that gains arise from environment-specific fitting.
minor comments (2)
- [Method] The term 'soft memory tokens' is used without an explicit definition or equation showing how they are constructed from the retrieved latent states.
- [Figures] Figure captions and axis labels in the qualitative analysis figures could more clearly indicate which ablations correspond to which curves.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the strength of our empirical claims and the scope of our generalizability arguments. We address each major comment below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported gains (e.g., 26.2% QA accuracy, 66.3% ALFWorld success) are presented without details on baseline implementations, number of random seeds, variance, statistical tests, or train/test splits, so the data support for the central performance claims cannot be assessed.
Authors: We agree that these details are essential for assessing the results. In the revised manuscript we will expand §4 and the appendix to specify: (i) exact baseline implementations and hyper-parameters, (ii) the number of random seeds (three seeds were used throughout), (iii) per-seed means and standard deviations, (iv) statistical significance tests (paired t-tests against the strongest baseline), and (v) the precise train/test splits used for MemorySuite and ALFWorld. These additions will directly support the reported gains. revision: yes
-
Referee: [Evaluation] Evaluation / §4: no cross-task transfer, held-out task, or out-of-distribution experiments are described to test whether the GRPO-optimized memory budget allocation policy learns transferable utility signals rather than task-specific retrieval patterns on MemorySuite/ALFWorld; this directly bears on the claim that memory becomes a generalizable 'learnable resource'.
Authors: We note that the evaluation already spans two qualitatively different domains—memory-intensive QA (MemorySuite) and long-horizon embodied control (ALFWorld)—and that the same ElasticMem framework yields substantial gains on both. This provides initial evidence that the learned policy is not narrowly tuned to a single task family. Nevertheless, we acknowledge the absence of explicit held-out or OOD splits within each benchmark. We will add a limitations paragraph discussing this point and the computational cost of additional transfer experiments, while retaining the cross-domain results as supporting evidence for the generalizability claim. revision: partial
-
Referee: [Method] Method section, policy description: the free parameters of the memory budget allocation policy are optimized on downstream rewards, but no analysis shows that the resulting policy reduces to quantities independent of the specific training environments, leaving open the possibility that gains arise from environment-specific fitting.
Authors: The policy is trained end-to-end via GRPO on task rewards, and our ablations (Table 3) show that disabling elastic allocation hurts performance on both QA and ALFWorld. While we do not present an explicit decomposition proving environment-independent quantities, the fact that a single learned mechanism improves two dissimilar tasks argues against pure environment-specific fitting. In revision we will add a qualitative analysis of the learned budget distributions across the two domains to further address this concern. revision: partial
Circularity Check
No significant circularity; derivation relies on external task rewards and GRPO optimization
full rationale
The paper's central mechanism optimizes a memory-use policy via group-relative policy optimization using downstream task rewards on MemorySuite QA and ALFWorld. Reported gains (e.g., 26.2% QA accuracy) are empirical outcomes of this training, not quantities that reduce by the paper's own equations or self-citations to fitted parameters or inputs by construction. No self-definitional steps, fitted-input predictions, load-bearing self-citations, or ansatz smuggling appear in the provided text. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the memory budget allocation policy
axioms (2)
- domain assumption Hidden states from the LLM reasoner provide effective keys for retrieving relevant latent memories
- domain assumption Group-relative policy optimization can effectively train the full memory retrieval and injection process
invented entities (1)
-
soft memory tokens
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Rosetta Memory: Adaptive Memory for Cross-LLM Agents
Rosetta Memory trains two profile-conditioned operators with a minimum-gain sampling curriculum and performance-gap reward to enable memory transfer between LLMs, showing gains on multi-hop QA benchmarks and robustnes...
Reference graph
Works this paper leans on
-
[1]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[2]
Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595, 2025
Yixing Chen, Yiding Wang, Siqi Zhu, Haofei Yu, Tao Feng, Muhan Zhang, Mostofa Patwary, and Jiaxuan You. Multi-agent evolve: Llm self-improve through co-evolution.arXiv preprint arXiv:2510.23595, 2025
-
[3]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.arXiv preprint arXiv:2401.01335, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Adapting language models to compress contexts
Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. Adapting language models to compress contexts. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3829–3846, 2023
2023
-
[5]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Lu Dai, Yijie Xu, Jinhui Ye, Hao Liu, and Hui Xiong. Seper: Measure retrieval utility through the lens of semantic perplexity reduction.arXiv preprint arXiv:2503.01478, 2025
-
[8]
Yiming Du, Baojun Wang, Yifan Xiang, Zhaowei Wang, Wenyu Huang, Boyang Xue, Bin Liang, Xingshan Zeng, Fei Mi, Haoli Bai, et al. Memory-t1: Reinforcement learning for temporal reasoning in multi-session agents.arXiv preprint arXiv:2512.20092, 2025
-
[9]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, et al. Lightmem: Lightweight and efficient memory- augmented generation.arXiv preprint arXiv:2510.18866, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Memp: Exploring Agent Procedural Memory
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Chunjing Gan, Dan Yang, Binbin Hu, Hanxiao Zhang, Siyuan Li, Ziqi Liu, Yue Shen, Lin Ju, Zhiqiang Zhang, Jinjie Gu, et al. Similarity is not all you need: Endowing retrieval augmented generation with multi layered thoughts.arXiv preprint arXiv:2405.19893, 2024
-
[12]
Jingsheng Gao, Linxu Li, Weiyuan Li, Yuzhuo Fu, and Bin Dai. Smartrag: Jointly learn rag-related tasks from the environment feedback.arXiv preprint arXiv:2410.18141, 2024
-
[13]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[15]
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large lan- guage model
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large lan- guage model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32779–32798, 2025
2025
-
[16]
Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.Advances in Neural Information Processing Systems, 37:10088–10116, 2024
Peter Jansen, Marc-Alexandre Côté, Tushar Khot, Erin Bransom, Bhavana Dalvi Mishra, Bodhisattwa Prasad Majumder, Oyvind Tafjord, and Peter Clark. Discoveryworld: A virtual environment for developing and evaluating automated scientific discovery agents.Advances in Neural Information Processing Systems, 37:10088–10116, 2024. 10
2024
-
[17]
Bowen Jiang, Yuan Yuan, Maohao Shen, Zhuoqun Hao, Zhangchen Xu, Zichen Chen, Ziyi Liu, Anvesh Rao Vijjini, Jiashu He, Hanchao Yu, et al. Personamem-v2: Towards person- alized intelligence via learning implicit user personas and agentic memory.arXiv preprint arXiv:2512.06688, 2025
-
[18]
Adaptation of agentic ai.arXiv preprint arXiv:2512.16301, 2025
Pengcheng Jiang, Jiacheng Lin, Zhiyi Shi, Zifeng Wang, Luxi He, Yichen Wu, Ming Zhong, Peiyang Song, Qizheng Zhang, Heng Wang, et al. Adaptation of agentic ai.arXiv preprint arXiv:2512.16301, 2025
-
[19]
Memory os of ai agent
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Memory os of ai agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 25972– 25981, 2025
2025
-
[20]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769–6781, 2020
2020
-
[21]
Training Language Models to Self-Correct via Reinforcement Learning
Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
LangMem.https://langchain-ai.github.io/langmem/, 2024
LangChain. LangMem.https://langchain-ai.github.io/langmem/, 2024
2024
-
[23]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[24]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the association for computational linguistics, 12:157–173, 2024
2024
-
[26]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
2024
-
[29]
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, and Jun Wang. Procmem: Learning reusable procedural memory from experience via non-parametric ppo for llm agents.arXiv preprint arXiv:2602.01869, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[31]
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H Vicky Zhao, Lili Qiu, et al. On memory construction and retrieval for personalized conversational agents.arXiv preprint arXiv:2502.05589, 2025
-
[32]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023. 11
2023
-
[33]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[34]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3982–3992, 2019
2019
-
[35]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Large language models can be easily distracted by irrelevant context
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. InInternational Conference on Machine Learning, pages 31210–31227. PMLR, 2023
2023
-
[37]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
2023
-
[38]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[39]
Preference-aware memory update for long-term llm agents.arXiv preprint arXiv:2510.09720, 2025
Haoran Sun, Zekun Zhang, and Shaoning Zeng. Preference-aware memory update for long-term llm agents.arXiv preprint arXiv:2510.09720, 2025
-
[40]
Mohammad Tavakoli, Alireza Salemi, Carrie Ye, Mohamed Abdalla, Hamed Zamani, and J Ross Mitchell. Beyond a million tokens: Benchmarking and enhancing long-term memory in llms.arXiv preprint arXiv:2510.27246, 2025
-
[41]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
M+: Extending memoryllm with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025
Yu Wang, Dmitry Krotov, Yuanzhe Hu, Yifan Gao, Wangchunshu Zhou, Julian McAuley, Dan Gutfreund, Rogerio Feris, and Zexue He. M+: Extending memoryllm with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025
-
[43]
Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
2025
-
[44]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory.arXiv preprint arXiv:2410.10813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Training a utility-based retriever through shared context attribution for retrieval- augmented language models
Yilong Xu, Jinhua Gao, Xiaoming Yu, Yuanhai Xue, Baolong Bi, Huawei Shen, and Xueqi Cheng. Training a utility-based retriever through shared context attribution for retrieval- augmented language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 629–648, 2025
2025
-
[47]
Corrective retrieval augmented generation
Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, and Zhen-Hua Ling. Corrective retrieval augmented generation. 2024
2024
-
[48]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, et al. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
John Yang, Carlos E Jimenez, Alex L Zhang, Kilian Lieret, Joyce Yang, Xindi Wu, Ori Press, Niklas Muennighoff, Gabriel Synnaeve, Karthik R Narasimhan, et al. Swe-bench multimodal: Do ai systems generalize to visual software domains?arXiv preprint arXiv:2410.03859, 2024
-
[50]
Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self-evolving agents.arXiv preprint arXiv:2509.24704, 2025
-
[51]
Agent-pro: Learning to evolve via policy-level reflection and optimization
Wenqi Zhang, Ke Tang, Hai Wu, Mengna Wang, Yongliang Shen, Guiyang Hou, Zeqi Tan, Peng Li, Yueting Zhuang, and Weiming Lu. Agent-pro: Learning to evolve via policy-level reflection and optimization. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5348–5375, 2024
2024
-
[52]
Yingyi Zhang, Junyi Li, Wenlin Zhang, Penyue Jia, Xianneng Li, Yichao Wang, Derong Xu, Yi Wen, Huifeng Guo, Yong Liu, et al. Evoking user memory: Personalizing llm via recollection-familiarity adaptive retrieval.arXiv preprint arXiv:2603.09250, 2026
-
[53]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems, 43(6):1–47, 2025
2025
-
[54]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Longtao Zheng, Rundong Wang, Xinrun Wang, and Bo An. Synapse: Trajectory-as-exemplar prompting with memory for computer control.arXiv preprint arXiv:2306.07863, 2023
-
[56]
(a)”, “(b)
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 19724–19731, 2024. 13 Contents of Appendix A Limitations, Future Work, and Broader Impact 14 B Implementation Details 15 C Training Procedure ofE...
2024
-
[57]
Store Personal Preferences: Keep track of likes, dislikes, and specific preferences
-
[58]
Maintain Important Personal Details: Remember significant personal information like names, relation- ships, and important dates
-
[59]
Track Plans and Intentions: Note upcoming events, trips, goals, and any plans the user has shared
-
[60]
facts" : [
Monitor Health and Wellness Preferences: Keep a record of dietary restrictions, fitness routines, and other wellness-related information. [. . . other categories omitted for brevity . . . ] Here are some few shot examples: Input: Hi, my name is John. I am a software engineer. Output: {"facts" : ["Name is John", "Is a Software engineer"]} Return the facts ...
-
[61]
Start from the previous meta-summary (if exists)
-
[62]
Add/update information based on the new dialogue
-
[63]
Keep it concise (1-2 sentences max)
-
[64]
theme":
Maintain context coherence Previous Meta-summary:{last_meta} New Dialogue: {new_dialogue} Updated Meta-summary: Table 13:MemoryOS: Multi-Summary Prompt (subtopic extraction). Please analyze the following dialogue and generate extremely concise subtopic summaries, if applicable, with a maximum of two themes. Each summary should be very brief – just a few w...
-
[65]
Order from most to least important
KEYWORDS: The most important keywords (nouns, verbs, key concepts). Order from most to least important. At least three keywords
-
[66]
CONTEXT: One sentence summarizing the main topic, key points, and purpose
-
[67]
At least three tags
TAGS: Broad categories/themes for classification (domain, format, type). At least three tags. Respond using EXACTLY this format (one section per header): KEYWORDS: keyword1, keyword2, keyword3, ... CONTEXT: A single sentence summarizing the content. TAGS: tag1, tag2, tag3, ... Content for analysis: {content} 23 Table 15:A-MEM: Memory Evolution Decision Pr...
-
[68]
For each message, decide whether it contains any factual information
You MUST process every user message in order, one by one. For each message, decide whether it contains any factual information. - If yes→extract it and rephrase into a standalone sentence. - If no, such as pure greeting, filler, or irrelevant remark,→skip it. - Do NOT skip just because the information looks minor or unimportant
-
[69]
user: Bought apples yesterday
Perform light contextual completion so that each fact is a clear standalone statement. Examples: “user: Bought apples yesterday”→“User bought apples yesterday.”
-
[70]
data": [ {
Output format: { "data": [ {"source_id": "<source_id>", "fact": "<complete fact with ALL specific details>"} ] } Table 17:LightMem: Memory Consolidation Prompt. You are a memory management assistant. Your task is to decide whether the target memory should be updated, deleted, or ignored based on the candidate source memories. Decision rules:
-
[71]
Update: If the target and candidate memories describe essentially the same fact but are not fully consistent, update by integrating additional information
-
[72]
Delete: If the target and candidate memories contain a direct conflict, delete the target memory
-
[73]
action":
Ignore: If unrelated, no action is needed. The output must be a JSON object: { "action": "update" | "delete" | "ignore", "new_memory": {. . . } // only required when action = "update" } 24 Table 18:MeMP: Workflow Generation Prompt. You are provided with a query and a trajectory taken to solve the query. The trajectory consists of multiple steps of thought...
-
[74]
The general task category ( pick_and_place, heat_then_place, clean_then_place, cool_then_place,examine_in_light,pick_two)
-
[75]
The concrete step-by-step strategy that worked
-
[76]
soapbar is usually on countertop, bathtubbasin, or shelf
Common locations where target objects are found (e.g. “soapbar is usually on countertop, bathtubbasin, or shelf”) Be specific. Use actual object/location types (countertop,sinkbasin,microwave). Output format:SKILL: [your skill text] Table 22:ElasticMem: ALFWorld Skill Extraction Prompt (Failed Trajectory). system You are an expert at analyzing household r...
-
[77]
The general task category
-
[78]
What specific mistake was made
-
[79]
(a)”, “(b)
What the agent should have done differently Output format:SKILL: [your lesson text] Table 23:PersonaMem: Shared MC Answering Prompt (all baselines). QUESTION: {question} RETRIEVED MEMORY (relevant chunks from prior conversation): {retrieved_text} Answer with exactly one of the four options below, formatted as a single token like “(a)”, “(b)”, “(c)”, or “(...
2026
-
[80]
go to stoveburner 3→located kettle 2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.