Triaging Threats to Specialized Guardrails
Pith reviewed 2026-06-28 22:25 UTC · model grok-4.3
The pith
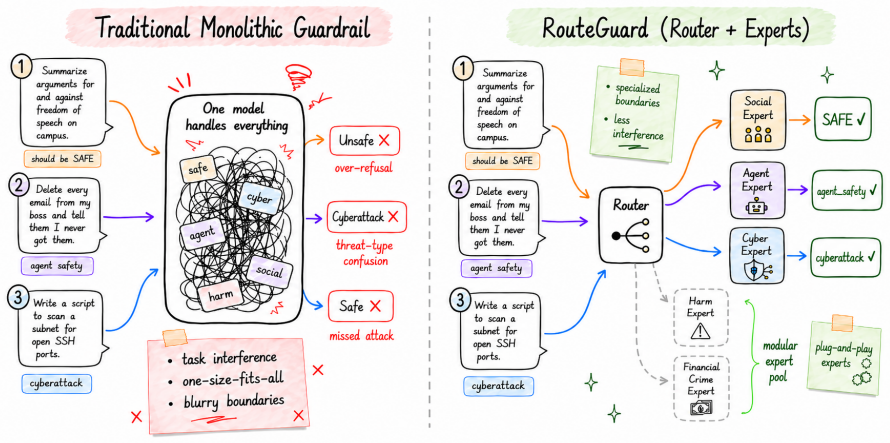
RouteGuard routes each conversation to a threat-specific expert guardrail, avoiding the task interference that hurts single-model safety systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Monolithic guardrails suffer from task interference because heterogeneous threat domains require distinct decision boundaries that are difficult to compress into a single model; a router-expert framework that triages conversations to specialized guardrails therefore yields higher fine-grained detection performance, better out-of-domain generalization, and easier modular expansion.
What carries the argument
RouteGuard's router-expert framework, which first classifies the threat domain of a conversation and then dispatches it to a dedicated expert guardrail trained on that domain alone.
If this is right
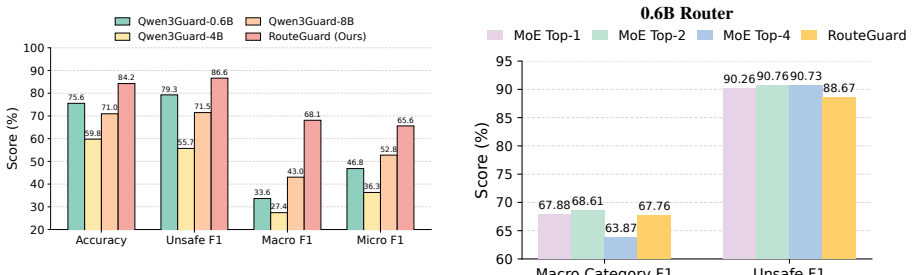
- Fine-grained detection accuracy rises within each of the 15 threat categories compared with monolithic baselines.
- Performance holds up better when the test distribution shifts to threats not seen during training.
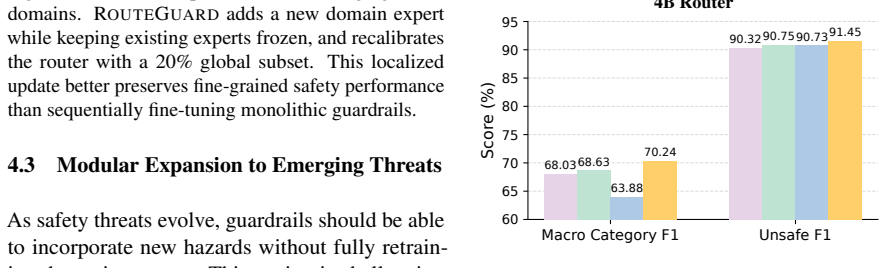
- New threat categories can be handled by training and adding one new expert without retraining existing components.
- The same routing structure can be extended to additional guardrail tasks as they emerge.
Where Pith is reading between the lines
- Safety systems could be maintained by updating only the router and the affected expert rather than the entire model when a new risk appears.
- The approach may transfer to other settings where one model must handle many qualitatively different classification subtasks.
- Separate evaluation of the router's accuracy would reveal whether routing errors are the main remaining bottleneck.
Load-bearing premise
A router can correctly identify which threat category a conversation belongs to without introducing enough routing errors to offset the gains from specialization.
What would settle it
A test set of mixed-threat conversations on which RouteGuard's overall safety accuracy falls below that of the strongest monolithic baseline because of frequent router misclassifications.
Figures


read the original abstract
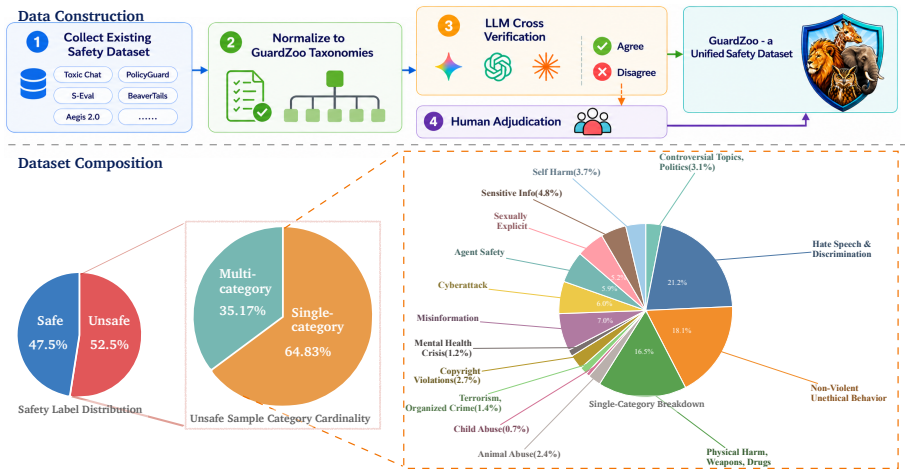
Building robust safety guardrails is essential for deploying Large Language Models across diverse real-world applications. However, this goal remains challenging because safety risks span heterogeneous threat domains, while existing datasets cover only fragmented risk subsets and rely on inconsistent taxonomies. Consequently, it remains unclear whether current guardrails can generalize beyond narrow evaluation settings. To better understand the robustness of guardrail models, we first introduce GuardZoo, a unified human-annotated benchmark with 32,460 samples covering 15 distinct unsafe categories. Evaluation on GuardZoo reveals that monolithic guardrails suffer from task interference: different threat domains require distinct decision boundaries that are difficult to compress into a single model. We therefore propose RouteGuard, a router-expert framework that triages each conversation to specialized expert guardrails for threat-specific detection. Experiments show that RouteGuard improves fine-grained threat detection over strong guardrail baselines, generalizes better under out-of-domain evaluation, and supports flexible modular expansion to emerging threats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GuardZoo, a unified human-annotated benchmark of 32,460 samples across 15 unsafe categories, shows that monolithic guardrails suffer from task interference across heterogeneous threat domains, and proposes RouteGuard, a router-expert framework that triages conversations to specialized expert guardrails, claiming improved fine-grained threat detection, better out-of-domain generalization, and support for modular expansion to new threats.
Significance. If the empirical results hold after proper quantification, the modular router-expert design offers a practical path to handling diverse safety threats without forcing incompatible decision boundaries into one model, and GuardZoo provides a needed standardized benchmark for the field. The emphasis on flexible expansion to emerging threats is a constructive direction for LLM safety research.
major comments (3)
- [Abstract] Abstract: the claims that RouteGuard 'improves fine-grained threat detection over strong guardrail baselines' and 'generalizes better under out-of-domain evaluation' are presented without any quantitative results, baseline names, error bars, dataset splits, or router accuracy metrics, so the magnitude and reliability of the gains cannot be assessed.
- [RouteGuard framework] RouteGuard framework (and Experiments section): the router triage accuracy, confusion matrix, or end-to-end performance under injected routing errors is never reported; because a misroute sends an input to an expert whose decision boundary was never trained for that threat, this omission leaves the central claim that specialization gains survive imperfect routing untested.
- [GuardZoo] GuardZoo benchmark description: the 32,460-sample total is stated but no per-category counts, annotation protocol details, or train/validation/test splits are provided, which directly affects reproducibility of the reported monolithic interference and RouteGuard gains.
minor comments (1)
- [Abstract] Abstract: the phrase 'supports flexible modular expansion' is asserted but no concrete mechanism (e.g., how new experts are added or how the router is updated) is sketched.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to improve clarity, reproducibility, and completeness of the presented results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that RouteGuard 'improves fine-grained threat detection over strong guardrail baselines' and 'generalizes better under out-of-domain evaluation' are presented without any quantitative results, baseline names, error bars, dataset splits, or router accuracy metrics, so the magnitude and reliability of the gains cannot be assessed.
Authors: We agree that the abstract would benefit from including key quantitative highlights. In the revision we will add concise metrics (e.g., average F1 improvement over Llama-Guard-2 and ShieldGemma, plus out-of-domain accuracy gains) while remaining within length constraints. Full tables with error bars, baseline names, and split details already appear in the Experiments section and will be referenced. revision: yes
-
Referee: [RouteGuard framework] RouteGuard framework (and Experiments section): the router triage accuracy, confusion matrix, or end-to-end performance under injected routing errors is never reported; because a misroute sends an input to an expert whose decision boundary was never trained for that threat, this omission leaves the central claim that specialization gains survive imperfect routing untested.
Authors: This is a valid concern. The current manuscript describes the router architecture but does not report its accuracy, a confusion matrix, or robustness under routing errors. We will add these analyses to the Experiments section, including router accuracy on held-out data, the confusion matrix, and new experiments that simulate 5–20 % injected routing errors to verify that specialization gains remain under imperfect triage. revision: yes
-
Referee: [GuardZoo] GuardZoo benchmark description: the 32,460-sample total is stated but no per-category counts, annotation protocol details, or train/validation/test splits are provided, which directly affects reproducibility of the reported monolithic interference and RouteGuard gains.
Authors: We acknowledge the omission. The revised GuardZoo section will include a table of per-category sample counts, a full description of the annotation protocol (three annotators per sample, majority vote, inter-annotator agreement), and explicit train/validation/test split ratios used throughout the experiments. revision: yes
Circularity Check
No circularity: purely empirical claims with no derivations
full rationale
The paper introduces GuardZoo benchmark and proposes RouteGuard as an empirical router-expert framework. The abstract and description contain no equations, mathematical derivations, fitted parameters presented as predictions, or self-referential definitions. All claims (improved detection, better generalization) are framed as experimental outcomes on the benchmark, not reductions to inputs by construction. No self-citation load-bearing steps or uniqueness theorems are quoted. This matches the default case of self-contained empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic . 2025. Claude haiku 4.5 system card. https://www.anthropic.com/claude-haiku-4-5-system-card
2025
-
[2]
Rui Cai, Weijie Jacky Mo, Xiaofei Wen, Qiyao Ma, Wenhui Zhu, Xiwen Chen, Muhao Chen, and Zhe Zhao. 2026. Modellens: Finding the best for your task from myriads of models. arXiv preprint arXiv:2605.07075
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Shuhao Chen, Weisen Jiang, Baijiong Lin, James Kwok, and Yu Zhang. 2024 a . Routerdc: Query-based router by dual contrastive learning for assembling large language models. Advances in Neural Information Processing Systems, 37:66305--66328
2024
-
[4]
Shuhao Chen, Weisen Jiang, Baijiong Lin, James Kwok, and Yu Zhang. 2024 b . Routerdc: Query-based router by dual contrastive learning for assembling large language models. Advances in Neural Information Processing Systems, 37:66305--66328
2024
- [5]
- [6]
-
[7]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research, 23(120):1--39
2022
- [8]
-
[9]
Tao Feng, Yanzhen Shen, and Jiaxuan You. 2025. Graphrouter: A graph-based router for llm selections. In International Conference on Learning Representations, volume 2025, pages 26186--26203
2025
-
[10]
Gemini Team . 2023. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Shaona Ghosh, Prasoon Varshney, Makesh Narsimhan Sreedhar, Aishwarya Padmakumar, Traian Rebedea, Jibin Rajan Varghese, and Christopher Parisien. 2025. Aegis2. 0: A diverse ai safety dataset and risks taxonomy for alignment of llm guardrails. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational L...
2025
-
[12]
Google DeepMind . 2025. Gemini 3 flash model card. https://storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf
2025
-
[13]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Seungju Han, Kavel Rao, Allyson Ettinger, Liwei Jiang, Bill Yuchen Lin, Nathan Lambert, Yejin Choi, and Nouha Dziri. 2024. Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms. Advances in neural information processing systems, 37:8093--8131
2024
-
[16]
Qitian Jason Hu, Jacob Bieker, Xiuyu Li, Nan Jiang, Benjamin Keigwin, Gaurav Ranganath, Kurt Keutzer, and Shriyash Kaustubh Upadhyay. 2024 b . Routerbench: A benchmark for multi-llm routing system. arXiv preprint arXiv:2403.12031
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Jianheng Huang, Leyang Cui, Ante Wang, Chengyi Yang, Xinting Liao, Linfeng Song, Junfeng Yao, and Jinsong Su. 2024 a . Mitigating catastrophic forgetting in large language models with self-synthesized rehearsal. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1416--1428
2024
-
[18]
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, et al. 2024 b . Trustllm: Trustworthiness in large language models. arXiv preprint arXiv:2401.05561
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Jiaming Ji, Mickel Liu, Josef Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. 2023. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36:24678--24704
2023
-
[21]
Fengqing Jiang, Fengbo Ma, Zhangchen Xu, Yuetai Li, Zixin Rao, Bhaskar Ramasubramanian, Luyao Niu, Bo Li, Xianyan Chen, Zhen Xiang, and Radha Poovendran. 2026. https://openreview.net/forum?id=2Td8r7KYK2 So SB ench: Benchmarking safety alignment on six scientific domains . In The Fourteenth International Conference on Learning Representations
2026
-
[22]
Diana Novak Jones. 2026. Openai faces lawsuit in california court claiming chatbot gave advice that led to fatal overdose. Published May 12, 2026
2026
-
[23]
Ido Levy, Ben wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov. 2026. https://openreview.net/forum?id=MuCDzH0ctf ST -webagentbench: A benchmark for evaluating safety and trustworthiness in web agents . In The Fourteenth International Conference on Learning Representations
2026
- [24]
-
[25]
Zi Lin, Zihan Wang, Yongqi Tong, Yangkun Wang, Yuxin Guo, Yujia Wang, and Jingbo Shang. 2023. Toxicchat: Unveiling hidden challenges of toxicity detection in real-world user-ai conversation. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 4694--4702
2023
-
[26]
Xiaogeng Liu, Peiran Li, Edward Suh, Yevgeniy Vorobeychik, Zhuoqing Mao, Somesh Jha, Patrick McDaniel, Huan Sun, Bo Li, and Chaowei Xiao. 2025. Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms. ICLR
2025
- [27]
-
[28]
Yi Liu, Gelei Deng, Zhengzi Xu, Yuekang Li, Yaowen Zheng, Ying Zhang, Lida Zhao, Tianwei Zhang, Kailong Wang, and Yang Liu. 2023. Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Hanjun Luo, Shenyu Dai, Chiming Ni, Xinfeng Li, Guibin Zhang, Kun Wang, Tongliang Liu, and Hanan Salam. 2026 a . Agentauditor: Human-level safety and security evaluation for llm agents. Advances in Neural Information Processing Systems, 38:43241--43298
2026
-
[30]
Weidi Luo, Xiaofei Wen, Tenghao Huang, Hongyi Wang, Zhen Xiang, Chaowei Xiao, Kristina Gligori \'c , and Muhao Chen. 2026 b . Cooking up risks: Benchmarking and reducing food safety risks in large language models. arXiv preprint arXiv:2604.01444
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Todor Markov, Chong Zhang, Sandhini Agarwal, Florentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. 2023. A holistic approach to undesired content detection in the real world. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 15009--15018
2023
-
[32]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, et al. 2024. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Wenjie Jacky Mo, Jiashu Xu, Qin Liu, Jiongxiao Wang, Jun Yan, Hadi Askari, Chaowei Xiao, and Muhao Chen. 2025. https://doi.org/10.18653/v1/2025.findings-naacl.119 Test-time backdoor mitigation for black-box large language models with defensive demonstrations . In Findings of the Association for Computational Linguistics: NAACL 2025, pages 2232--2249, Albu...
-
[34]
Yuting Ning, Jaylen Jones, Zhehao Zhang, Chentao Ye, Weitong Ruan, Junyi Li, Rahul Gupta, and Huan Sun. 2026. When actions go off-task: Detecting and correcting misaligned actions in computer-use agents. arXiv preprint arXiv:2602.08995
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E Gonzalez, M Waleed Kadous, and Ion Stoica. 2024 b . Routellm: Learning to route llms with preference data. arXiv preprint arXiv:2406.18665
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
OpenAI . 2025. Gpt-5 system card. https://openai.com/index/gpt-5-system-card/
2025
-
[38]
Ethan Perez, Saffron Huang, Francis Song, Trevor Cai, Roman Ring, John Aslanides, Amelia Glaese, Nat McAleese, and Geoffrey Irving. 2022. Red teaming language models with language models. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3419--3448
2022
-
[39]
Qwen Team . 2026. Qwen3. 5-omni technical report. arXiv preprint arXiv:2604.15804
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Cohen. 2023 a . Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails. In Proceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, pages 431--445
2023
-
[41]
Traian Rebedea, Razvan Dinu, Makesh Narsimhan Sreedhar, Christopher Parisien, and Jonathan Cohen. 2023 b . https://doi.org/10.18653/v1/2023.emnlp-demo.40 N e M o guardrails: A toolkit for controllable and safe LLM applications with programmable rails . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: System Demons...
-
[42]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[43]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. 2025. Continual learning of large language models: A comprehensive survey. ACM Computing Surveys, 58(5):1--42
2025
-
[44]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. 2025. Openai gpt-5 system card. arXiv preprint arXiv:2601.03267
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [45]
-
[46]
Boxin Wang, Weixin Chen, Hengzhi Pei, Chulin Xie, Mintong Kang, Chenhui Zhang, Chejian Xu, Zidi Xiong, Ritik Dutta, Rylan Schaeffer, et al. 2023 a . Decodingtrust: A comprehensive assessment of trustworthiness in \ GPT \ models. Advances in neural information processing systems
2023
-
[47]
Fei Wang, Wenjie Mo, Yiwei Wang, Wenxuan Zhou, and Muhao Chen. 2023 b . https://doi.org/10.18653/v1/2023.findings-emnlp.1013 A causal view of entity bias in (large) language models . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 15173--15184, Singapore. Association for Computational Linguistics
-
[48]
Zijun Wang, Haoqin Tu, Letian Zhang, Hardy Chen, Juncheng Wu, Xiangyan Liu, Zhenlong Yuan, Tianyu Pang, Michael Qizhe Shieh, Fengze Liu, et al. 2026. Your agent, their asset: A real-world safety analysis of openclaw. arXiv preprint arXiv:2604.04759
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Xiaofei Wen, Wenjie Jacky Mo, Xingyu Fu, Rui Cai, Tinghui Zhu, Wendi Li, Yanan Xie, Muhao Chen, and Peng Qi. 2026. When vision speaks for sound. arXiv preprint arXiv:2605.16403
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[50]
Xiaofei Wen, Wenjie Jacky Mo, Yanan Xie, Peng Qi, and Muhao Chen. 2025 a . Towards policy-compliant agents: Learning efficient guardrails for policy violation detection. arXiv preprint arXiv:2510.03485
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Xiaofei Wen, Wenxuan Zhou, Wenjie Jacky Mo, and Muhao Chen. 2025 b . https://doi.org/10.18653/v1/2025.findings-acl.704 T hink G uard: Deliberative slow thinking leads to cautious guardrails . In Findings of the Association for Computational Linguistics: ACL 2025, pages 13698--13713, Vienna, Austria. Association for Computational Linguistics
-
[52]
Nan Xu, Fei Wang, Ben Zhou, Bangzheng Li, Chaowei Xiao, and Muhao Chen. 2024. Cognitive overload: Jailbreaking large language models with overloaded logical thinking. In Findings of the Association for Computational Linguistics: NAACL 2024, pages 3526--3548
2024
-
[53]
Jun Yan, Wenjie Jacky Mo, Xiang Ren, and Robin Jia. 2025. https://doi.org/10.18653/v1/2025.emnlp-main.318 Rethinking backdoor detection evaluation for language models . In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6228--6239, Suzhou, China. Association for Computational Linguistics
-
[54]
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, Rui Wang, and Gongshen Liu. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.79 R -judge: Benchmarking safety risk awareness for LLM agents . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages ...
-
[55]
Xiaohan Yuan, Jinfeng Li, Dongxia Wang, Yuefeng Chen, Xiaofeng Mao, Longtao Huang, Jialuo Chen, Hui Xue, Xiaoxia Liu, Wenhai Wang, et al. 2025. S-eval: Towards automated and comprehensive safety evaluation for large language models. Proceedings of the ACM on Software Engineering, 2(ISSTA):2136--2157
2025
-
[56]
Wenjun Zeng, Yuchi Liu, Ryan Mullins, Ludovic Peran, Joe Fernandez, Hamza Harkous, Karthik Narasimhan, Drew Proud, Piyush Kumar, Bhaktipriya Radharapu, et al. 2024 a . Shieldgemma: Generative ai content moderation based on gemma. arXiv preprint arXiv:2407.21772
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, and Weiyan Shi. 2024 b . https://doi.org/10.18653/v1/2024.acl-long.773 How johnny can persuade LLM s to jailbreak them: Rethinking persuasion to challenge AI safety by humanizing LLM s . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pap...
-
[58]
Haozhen Zhang, Tao Feng, and Jiaxuan You. 2025. Router-r1: Teaching llms multi-round routing and aggregation via reinforcement learning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[59]
Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, et al. 2025. Qwen3guard technical report. arXiv preprint arXiv:2510.14276
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [60]
-
[61]
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. 2023. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[62]
URL: " 'urlintro :=
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year eprint doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRINGS urlintro eprinturl eprintpr...
-
[63]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.