Pairwise Reference Alignment as a Model-Level Ordinal Observable
Pith reviewed 2026-06-28 22:44 UTC · model grok-4.3
The pith
Pairwise reference alignment is the probability that a model scores preferred responses above rejected ones according to a fixed reference distribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
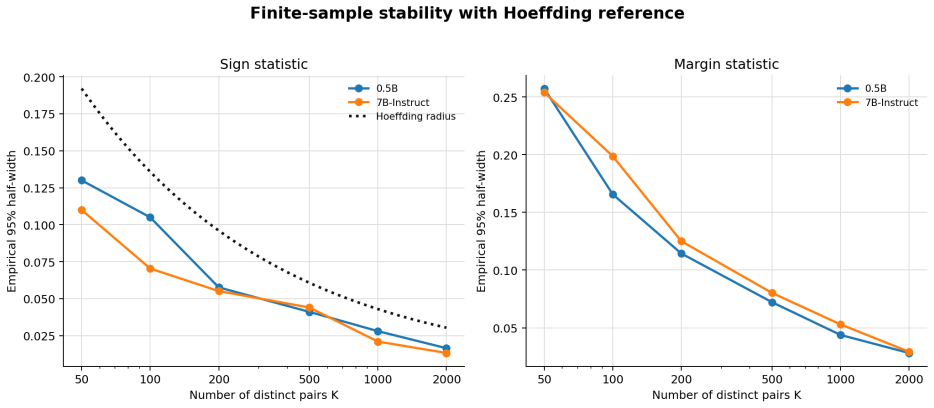
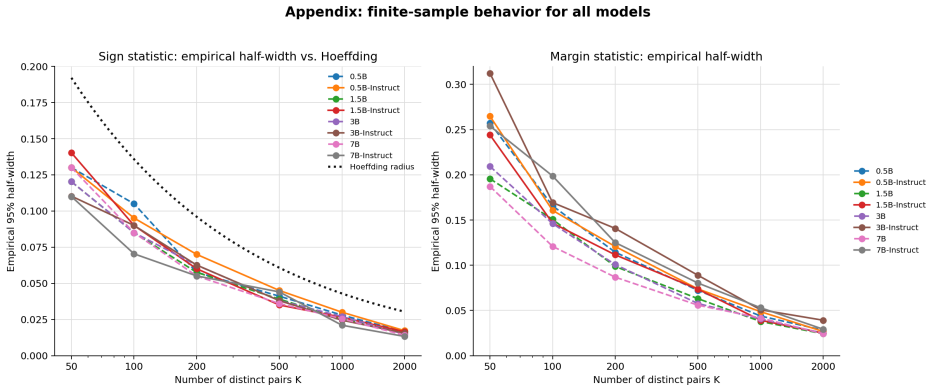
Pairwise reference alignment is defined as the probability that a model-induced ordering agrees with the reference preference ordering. Given a reference pair distribution P_pair over triples (x, y+, y-) and a scalar model score S_M(x, y), the alignment observable equals the probability that S_M(x, y+) exceeds S_M(x, y-). A centered order-parameter-like statistic and a margin-based extension are introduced; both admit simple finite-sample estimators and concentration bounds under independent sampling from P_pair.
What carries the argument
Pairwise reference alignment, the probability that the model scoring function orders y+ above y- on samples from the reference pair distribution P_pair.
If this is right
- The alignment statistic can be estimated directly from any set of reference pairs without requiring a new benchmark.
- Different scoring functions applied to the same model can be compared through their induced alignment values.
- The observable varies systematically across different subsets of the reference distribution.
- Finite-sample concentration bounds follow directly from the independent sampling assumption.
Where Pith is reading between the lines
- The same observable could be applied to compare scoring functions across models of different architectures.
- If the reference distribution is itself estimated from data, the alignment value would become a random variable whose variance could be studied.
- The formulation separates the measurement question from the choice of optimization objective used in preference tuning.
Load-bearing premise
The reference pair distribution is treated as fixed with samples drawn independently.
What would settle it
Drawing many independent triples from the reference distribution and finding that the empirical frequency of correct ordering fails to concentrate around the defined alignment probability.
Figures
read the original abstract
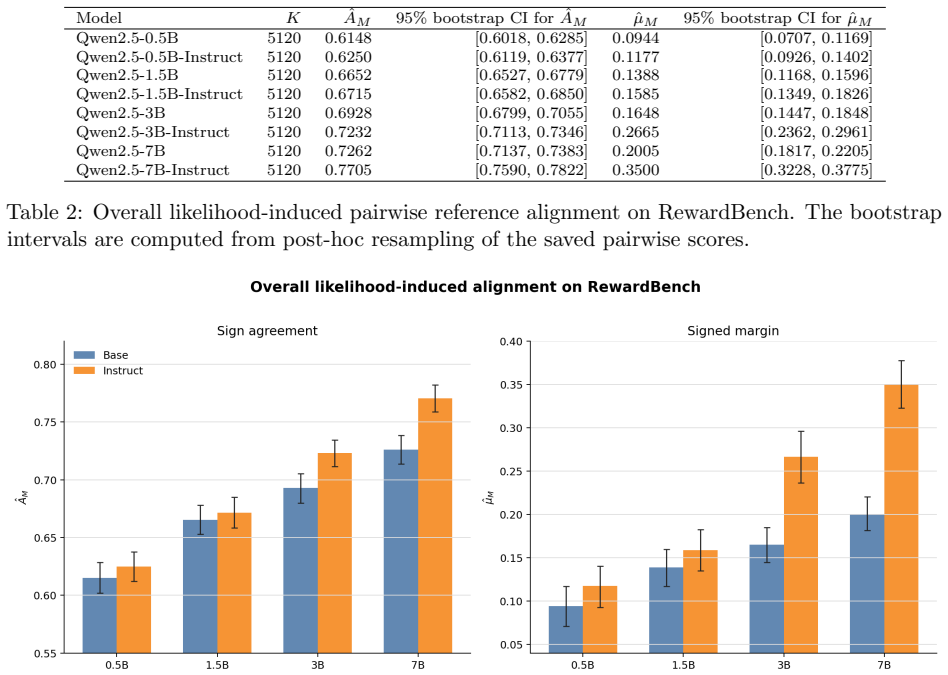
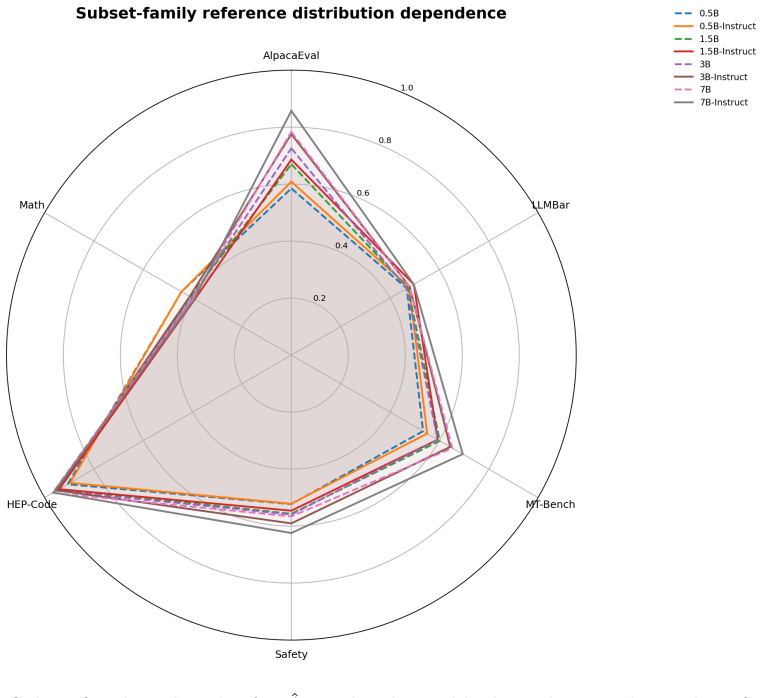
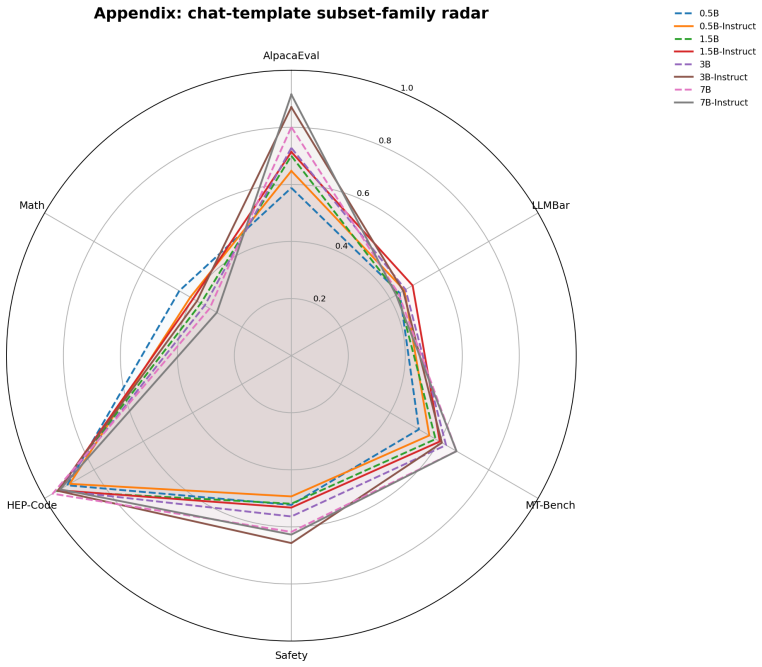
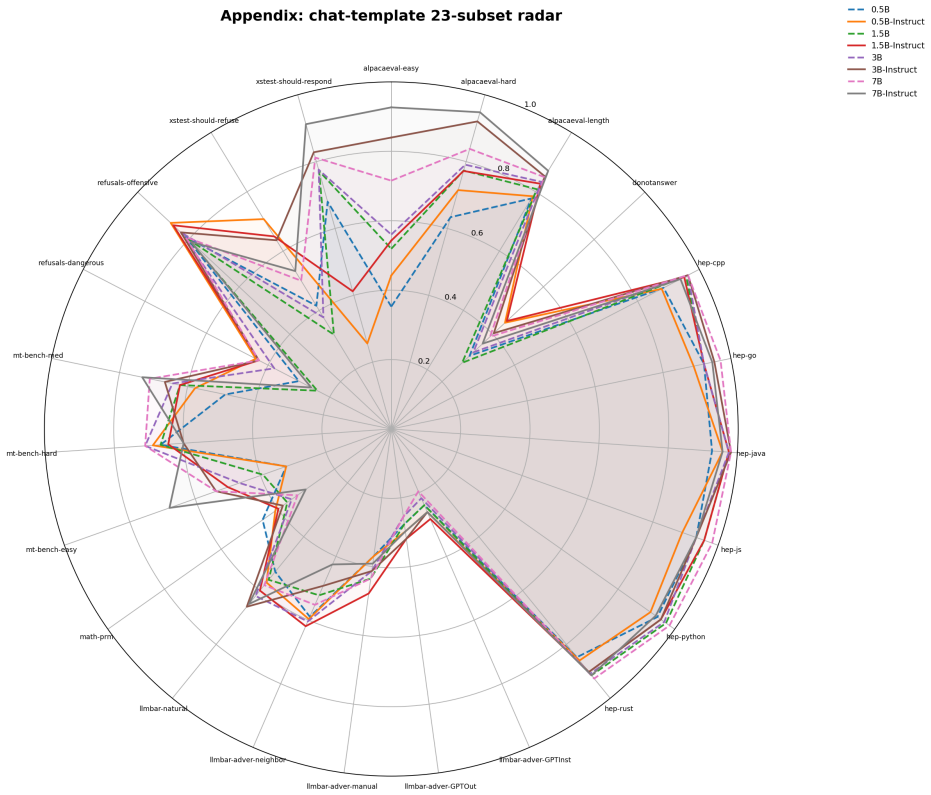
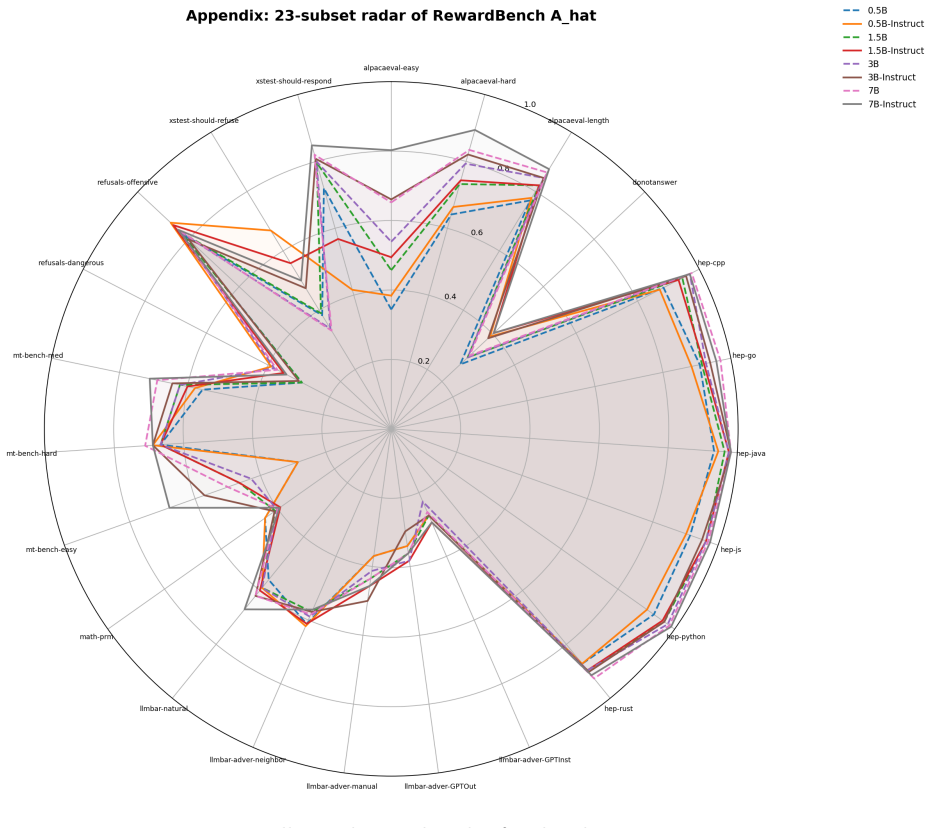
Pairwise preference data is widely used in language-model evaluation and alignment, often for model ranking, reward modeling, or preference optimization. This note formulates a more basic measurement question: given a reference distribution of pairwise preferences, what model-level quantity is estimated when we test whether a model ranks preferred responses above rejected responses? We define pairwise reference alignment as an ordinal observable induced by a model scoring function. Given a reference pair distribution $P_{\mathrm{pair}}$ over triples $(x,y^+,y^-)$, and a scalar model score $S_M(x,y)$, we define the alignment observable as the probability that the model-induced ordering agrees with the reference preference ordering. We further define a centered order-parameter-like statistic and discuss a margin-based extension. The resulting quantities admit simple finite-sample estimators and concentration bounds under independent sampling assumptions. This note does not introduce a new benchmark. It provides a conceptual and statistical formulation for pairwise reference alignment, clarifies the role of the reference pair distribution, and distinguishes the general ordinal observable from scoring choices such as normalized log-probability or energy-based scores. We also provide an initial empirical study on Qwen2.5 models and RewardBench, where the proposed statistics increase with model size and instruction tuning and vary across reference-pair subsets as predicted by the formulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines pairwise reference alignment as the probability that a model scoring function S_M(x,y) orders y+ above y- for triples drawn from a reference pair distribution P_pair. It introduces centered and margin-based variants of this ordinal observable, states that they admit simple finite-sample estimators and concentration bounds under i.i.d. sampling from fixed P_pair, and reports an initial empirical study on Qwen2.5 models using RewardBench in which the statistics increase with model size and instruction tuning and vary across reference-pair subsets.
Significance. If the statistical claims hold under the stated assumptions, the formulation supplies a clean, model-level ordinal observable for reference alignment that is distinct from particular scoring choices such as normalized log-probability. It clarifies the role of the reference distribution P_pair without introducing new benchmarks or free parameters. The empirical observation that the statistic tracks scale and tuning provides initial support, though the dependence structure of the benchmark limits direct applicability of the concentration results.
major comments (1)
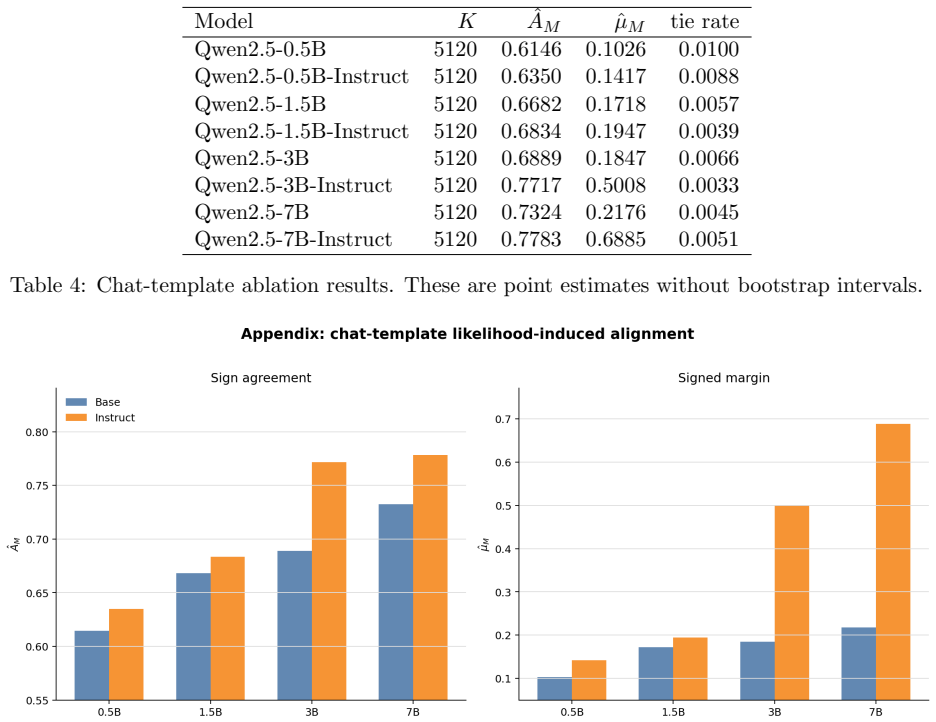
- [Abstract; empirical study on Qwen2.5 and RewardBench] Abstract and empirical study: the finite-sample estimators and concentration bounds are asserted to hold under independent sampling from a fixed P_pair. RewardBench, however, contains dependent pairs arising from shared prompts, multiple pairs per x, and curation. No correction, robustness argument, or explicit qualification is supplied, so the reported numerical values on RewardBench cannot be guaranteed to obey the claimed concentration rates. This directly affects the evidential weight of the empirical section for the statistical claims.
minor comments (1)
- [Abstract] Notation for the reference distribution is introduced as P_pair in the abstract and P_{\mathrm{pair}} in the displayed equation; consistent typesetting would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the mismatch between the i.i.d. assumptions underlying the concentration results and the structure of RewardBench. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract; empirical study on Qwen2.5 and RewardBench] Abstract and empirical study: the finite-sample estimators and concentration bounds are asserted to hold under independent sampling from a fixed P_pair. RewardBench, however, contains dependent pairs arising from shared prompts, multiple pairs per x, and curation. No correction, robustness argument, or explicit qualification is supplied, so the reported numerical values on RewardBench cannot be guaranteed to obey the claimed concentration rates. This directly affects the evidential weight of the empirical section for the statistical claims.
Authors: We agree that the finite-sample estimators and concentration bounds are derived under i.i.d. sampling from a fixed P_pair and that RewardBench exhibits dependence (shared prompts, multiple pairs per x, curation). The empirical study is presented as an initial illustration of how the observable varies with model scale, instruction tuning, and reference-pair subsets, not as a direct empirical check of the concentration rates. We will revise the manuscript to add explicit qualifications: (i) in the abstract, (ii) in the empirical section, and (iii) in a new limitations paragraph stating that the reported numerical values on RewardBench cannot be guaranteed to obey the claimed i.i.d. concentration rates. This change clarifies the evidential role of the experiments while leaving the theoretical formulation unchanged. revision: yes
Circularity Check
No circularity: definition is direct probability over given inputs
full rationale
The paper defines the alignment observable explicitly as P(S_M orders y+ > y- | P_pair), then states that this quantity admits standard finite-sample estimators and concentration bounds under an explicit i.i.d. sampling assumption from fixed P_pair. No equation reduces the defined quantity to a fitted parameter, no self-citation chain is invoked for the central claim, and the derivation does not rename or smuggle in prior results by the same authors. The i.i.d. assumption is stated as a prerequisite rather than derived from the observable itself. This is a self-contained definitional formulation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Samples are drawn independently from the reference pair distribution P_pair
invented entities (1)
-
Pairwise reference alignment observable
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A statistical approach to model evaluations
Anthropic. A statistical approach to model evaluations. Anthropic Research, November 2024. Published November 19, 2024
2024
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios N. Angelopoulos, Tianle Li, Dacheng Li, Banghua Zhu, Hao Zhang, Michael I. Jordan, Joseph E. Gonzalez, and Ion Stoica. Chat- bot arena: An open platform for evaluating llms by human preference.arXiv preprint arXiv:2403.04132, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Implicit generation and modeling with energy-based models
Yilun Du and Igor Mordatch. Implicit generation and modeling with energy-based models. In Advances in Neural Information Processing Systems, 2019
2019
-
[5]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal´ azs Galambosi, Percy Liang, and Tatsunori B. Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Johnson, Pablo Samuel Castro, Hugo Larochelle, and Yann Dauphin
Vincent Dumoulin, Daniel D. Johnson, Pablo Samuel Castro, Hugo Larochelle, and Yann Dauphin. A density estimation perspective on learning from pairwise human preferences.arXiv preprint arXiv:2311.14115, 2024
-
[7]
Julien Fageot, Sadegh Farhadkhani, Lˆ e-Nguyˆ en Hoang, and Oscar Villemaud. General- ized bradley-terry models for score estimation from paired comparisons.arXiv preprint arXiv:2308.08644, 2024
-
[8]
Pairwise preference learning and ranking
Johannes F¨ urnkranz and Eyke H¨ ullermeier. Pairwise preference learning and ranking. In Machine Learning: ECML 2003, pages 145–156, 2003
2003
-
[9]
Tanya Ignatenko, Kirill Kondrashov, Marco Cox, and Bert de Vries. On preference learning based on sequential bayesian optimization with pairwise comparison.arXiv preprint arXiv:2103.13192, 2023
-
[10]
Smith, and Hannaneh Hajishirzi
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, Lester James V. Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, Noah A. Smith, and Hannaneh Hajishirzi. Rewardbench: Evaluating reward models for language modeling.arXiv preprint arXiv:2403.13787, 2024. 27
-
[11]
Loss functions for discriminative training of energy-based models
Yann LeCun and Fu Jie Huang. Loss functions for discriminative training of energy-based models. InProceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, pages 206–213, 2005
2005
-
[12]
Adding error bars to evals: A statistical approach to language model evaluations
Evan Miller. Adding error bars to evals: A statistical approach to language model evaluations. arXiv preprint arXiv:2411.00640, 2024
- [13]
-
[14]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. InAdvances in Neural Information Processing Systems, 2023
2023
-
[16]
A survey of preference-based reinforcement learning methods.Journal of Machine Learning Research, 18(136):1–46, 2017
Christian Wirth, Riad Akrour, Gerhard Neumann, and Johannes F¨ urnkranz. A survey of preference-based reinforcement learning methods.Journal of Machine Learning Research, 18(136):1–46, 2017
2017
-
[17]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems, 2023. 28
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.