SSR: Scaling Surefooted and Symmetric Humanoid Traversal to the Open World
Pith reviewed 2026-06-28 22:34 UTC · model grok-4.3
The pith
SSR enables humanoid robots to traverse open-world terrains safely by learning imagined future footholds and symmetric coordination from vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
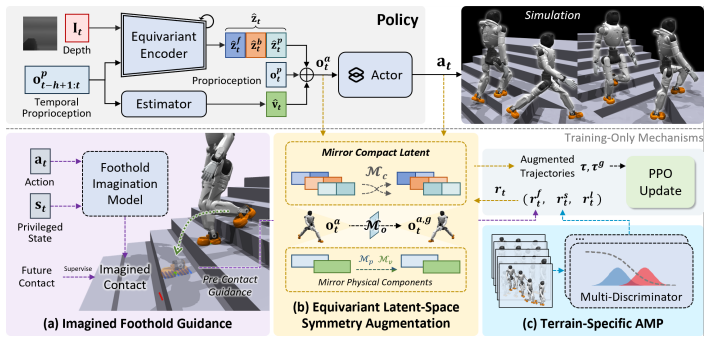
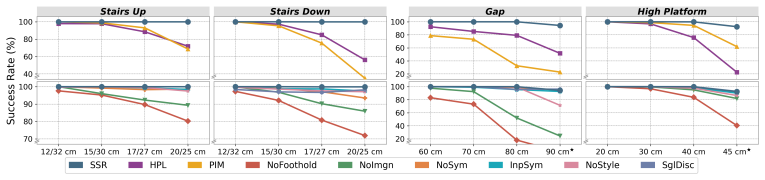
SSR jointly learns imagined foothold guidance to model and evaluate forthcoming swing-foot contacts, equivariant latent-space symmetry augmentation to induce bilateral coordination under visual input, and terrain-specific multi-discriminator motion priors; together these produce safe, stable, high-quality locomotion on heterogeneous real-world terrains including varied stairs and extreme obstacles while supporting reliable long-horizon outdoor traversal.
What carries the argument
Imagined foothold guidance, which models forthcoming swing-foot contacts and scores their support to steer pre-touchdown motion toward stable regions.
If this is right
- Pre-touchdown guidance reduces the frequency of edge slips on irregular surfaces.
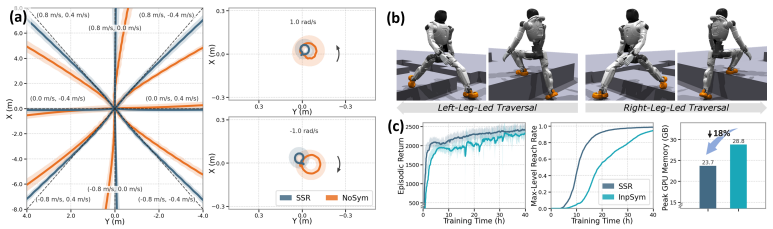
- Symmetry augmentation produces coordinated left-right behaviors from high-dimensional visual observations.
- Terrain-specific priors maintain human-like motion patterns across different scene types.
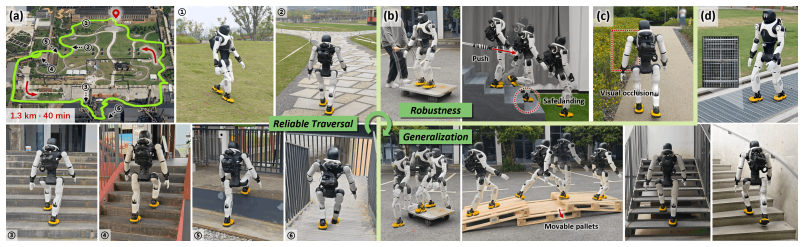
- The combined system supports continuous traversal over long distances without manual resets.
Where Pith is reading between the lines
- Similar guidance mechanisms could be adapted for tasks that combine locomotion with object interaction.
- The symmetry approach may lower sample complexity when training on other bilateral robot platforms.
- Long-horizon reliability suggests the method could support deployment in unstructured human environments without frequent retraining.
Load-bearing premise
The learned foothold predictions, symmetry augmentation, and motion priors trained in simulation will transfer to produce reliable foot placement on unseen real terrains.
What would settle it
Repeated edge slips or falls when the robot encounters a previously unseen terrain type such as loose gravel slopes during extended outdoor runs.
Figures







read the original abstract
Extending humanoid traversal to the open world is key to practical deployment in human environments, but remains challenging. The robot must use vision to ensure safe and reliable foot placement on heterogeneous terrain under highly dynamic motion, while producing coordinated, natural whole-body behaviors. We propose SSR, an efficient end-to-end framework for egocentric vision-based humanoid traversal that jointly learns these capabilities. SSR introduces imagined foothold guidance, which learns to model forthcoming swing-foot contacts and evaluates their support to guide pre-touchdown swings toward stable regions, reducing edge slips. It further employs equivariant latent-space symmetry augmentation to efficiently induce bilateral coordination under high-dimensional visual observations, and uses terrain-specific multi-discriminator motion priors to encourage human-like behavior across scenes. Extensive experiments show that SSR achieves safe, stable, and high-quality locomotion on diverse real-world terrains, including stairs with varied structures and extreme challenges such as wide gaps and high platforms, while enabling reliable long-horizon traversal in open outdoor environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SSR, an end-to-end egocentric vision-based framework for humanoid traversal in open-world settings. It introduces three components: imagined foothold guidance that models forthcoming swing-foot contacts and evaluates their support to guide stable placements; equivariant latent-space symmetry augmentation to induce bilateral coordination from high-dimensional visual inputs; and terrain-specific multi-discriminator motion priors to encourage human-like whole-body behaviors across scenes. The central claim, supported by reported extensive real-world experiments, is that SSR achieves safe, stable, high-quality locomotion on diverse terrains including varied stairs, wide gaps, high platforms, and enables reliable long-horizon traversal in open outdoor environments.
Significance. If the generalization claims hold with rigorous evidence, the work would be significant for practical humanoid deployment, as it targets the core difficulties of vision-guided foot placement under dynamic motion and coordinated behavior on heterogeneous terrain. The symmetry augmentation and multi-discriminator priors represent potentially efficient inductive biases for scaling learning, and the focus on real-world long-horizon tasks addresses a key gap in the field.
major comments (1)
- [Abstract] Abstract: The load-bearing claim that the three learned components (imagined foothold guidance, equivariant symmetry augmentation, terrain-specific motion priors) produce reliable behavior on 'heterogeneous unseen real-world terrains' and 'extreme challenges' is not supported by any quantification of distribution shift, OOD metrics, or bounds on how the test conditions (varied stair structures, gap widths, platform heights, outdoor heterogeneity) relate to the training support. Without such analysis, the reported success does not distinguish robust generalization from in-distribution performance.
Simulated Author's Rebuttal
We thank the referee for highlighting the need to better substantiate generalization claims. We address the concern directly below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that the three learned components (imagined foothold guidance, equivariant symmetry augmentation, terrain-specific motion priors) produce reliable behavior on 'heterogeneous unseen real-world terrains' and 'extreme challenges' is not supported by any quantification of distribution shift, OOD metrics, or bounds on how the test conditions (varied stair structures, gap widths, platform heights, outdoor heterogeneity) relate to the training support. Without such analysis, the reported success does not distinguish robust generalization from in-distribution performance.
Authors: We agree that explicit quantification of distribution shift would make the generalization claims more rigorous. In real-world robotics, defining precise support bounds for visual and terrain distributions is inherently difficult, which is why we relied on qualitative diversity in testing (e.g., outdoor heterogeneity and extreme parameters such as wider gaps and higher platforms). However, to address the point, we will revise the abstract to temper the language and add a dedicated paragraph in the experiments section that describes the training data collection protocol versus the specific test terrain parameters (stair variations, gap widths, platform heights) to better illustrate the degree of shift. This will not include formal OOD bounds, as they are not standard or straightforward in this domain, but will provide clearer evidence distinguishing the test conditions. revision: yes
Circularity Check
No circularity: empirical validation of learned components with no self-referential derivation chain.
full rationale
The paper proposes an end-to-end learned framework (imagined foothold guidance, equivariant symmetry augmentation, terrain-specific motion priors) and supports its claims solely via reported real-world experiments on diverse terrains. No equations, uniqueness theorems, or derivation steps are present in the provided text that reduce any output quantity to a fitted input or self-citation by construction. The central claims are empirical performance statements, not algebraic identities or predictions forced by the training procedure itself. This matches the default expectation of a non-circular empirical ML robotics paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
I. Radosavovic, S. Kamat, T. Darrell, and J. Malik. Learning humanoid locomotion over chal- lenging terrain.arXiv preprint arXiv:2410.03654, 2024
-
[2]
Bonnen, J
K. Bonnen, J. S. Matthis, A. Gibaldi, M. S. Banks, D. M. Levi, and M. Hayhoe. Binocular vision and the control of foot placement during walking in natural terrain.Scientific reports, 11(1):20881, 2021
2021
-
[3]
Zhuang, S
Z. Zhuang, S. Yao, and H. Zhao. Humanoid parkour learning. InConference on Robot Learn- ing (CoRL), 2024
2024
- [4]
-
[5]
W. Sun, Y . Su, L. Huang, A. Zhang, D. Wei, M. San, D. Tian, E. Cao, F. Yan, E. Xie, et al. Now you see that: Learning end-to-end humanoid locomotion from raw pixels.arXiv preprint arXiv:2602.06382, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [6]
-
[7]
B. Nie, Y . Zhang, R. Jin, Z. Cao, H. Lin, X. Yang, and Y . Gao. Coordinated humanoid robot locomotion with symmetry equivariant reinforcement learning policy. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 18523–18531, 2026
2026
-
[8]
Mittal, N
M. Mittal, N. Rudin, V . Klemm, A. Allshire, and M. Hutter. Symmetry considerations for learning task symmetric robot policies. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 7433–7439. IEEE, 2024
2024
-
[9]
Z. Su, X. Huang, D. Ordo ˜nez-Apraez, Y . Li, Z. Li, Q. Liao, G. Turrisi, M. Pontil, C. Semini, Y . Wu, et al. Leveraging symmetry in rl-based legged locomotion control. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6899–6906. IEEE, 2024
2024
-
[10]
X. B. Peng, Z. Ma, P. Abbeel, S. Levine, and A. Kanazawa. Amp: Adversarial motion priors for stylized physics-based character control.ACM Transactions on Graphics (ToG), 40(4): 1–20, 2021
2021
-
[11]
A. Tang, T. Hiraoka, N. Hiraoka, F. Shi, K. Kawaharazuka, K. Kojima, K. Okada, and M. Inaba. Humanmimic: Learning natural locomotion and transitions for humanoid robot via wasserstein adversarial imitation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 13107–13114. IEEE, 2024
2024
-
[12]
Zhang, P
Q. Zhang, P. Cui, D. Yan, J. Sun, Y . Duan, G. Han, W. Zhao, W. Zhang, Y . Guo, A. Zhang, et al. Whole-body humanoid robot locomotion with human reference. In2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 11225–11231. IEEE, 2024. 9
2024
-
[13]
Cheng, K
X. Cheng, K. Shi, A. Agarwal, and D. Pathak. Extreme parkour with legged robots. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 11443–11450. IEEE, 2024
2024
-
[14]
Zhang, W
C. Zhang, W. Xiao, T. He, and G. Shi. Wococo: Learning whole-body humanoid control with sequential contacts. InConference on Robot Learning (CoRL), 2024
2024
-
[15]
V ollenweider, M
E. V ollenweider, M. Bjelonic, V . Klemm, N. Rudin, J. Lee, and M. Hutter. Advanced skills through multiple adversarial motion priors in reinforcement learning. In2023 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 5120–5126. IEEE, 2023
2023
-
[16]
H. Wang, Z. Wang, J. Ren, Q. Ben, T. Huang, W. Zhang, and J. Pang. Beamdojo: Learning agile humanoid locomotion on sparse footholds. InRobotics: Science and Systems (RSS), 2025
2025
-
[17]
Z. Wu, X. Huang, L. Yang, Y . Zhang, K. Sreenath, X. Chen, P. Abbeel, R. Duan, A. Kanazawa, C. Sferrazza, et al. Perceptive humanoid parkour: Chaining dynamic human skills via motion matching.arXiv preprint arXiv:2602.15827, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang. Learning humanoid locomo- tion with perceptive internal model. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9997–10003. IEEE, 2025
2025
- [19]
- [20]
-
[21]
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter. Attention-based map encoding for learning generalized legged locomotion.Science Robotics, 10(105):eadv3604, 2025
2025
- [22]
- [23]
-
[24]
Zhang, G
Q. Zhang, G. Han, J. Sun, W. Zhao, C. Sun, J. Cao, J. Wang, Y . Guo, and R. Xu. Distillation- ppo: A novel two-stage reinforcement learning framework for humanoid robot perceptive lo- comotion. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 2916–2922. IEEE, 2025
2025
- [25]
-
[26]
N. Rudin, J. He, J. Aurand, and M. Hutter. Parkour in the wild: Learning a general and extensible agile locomotion policy using multi-expert distillation and rl fine-tuning.arXiv preprint arXiv:2505.11164, 2025
-
[27]
Mastalli, I
C. Mastalli, I. Havoutis, M. Focchi, D. G. Caldwell, and C. Semini. Motion planning for quadrupedal locomotion: Coupled planning, terrain mapping, and whole-body control.IEEE Transactions on Robotics, 36(6):1635–1648, 2020. 10
2020
-
[28]
Agrawal, S
A. Agrawal, S. Chen, A. Rai, and K. Sreenath. Vision-aided dynamic quadrupedal locomotion on discrete terrain using motion libraries. In2022 International Conference on Robotics and Automation (ICRA), pages 4708–4714. IEEE, 2022
2022
-
[29]
Fahmi, V
S. Fahmi, V . Barasuol, D. Esteban, O. Villarreal, and C. Semini. Vital: Vision-based terrain- aware locomotion for legged robots.IEEE Transactions on Robotics, 39(2):885–904, 2022
2022
-
[30]
Tsounis, M
V . Tsounis, M. Alge, J. Lee, F. Farshidian, and M. Hutter. Deepgait: Planning and control of quadrupedal gaits using deep reinforcement learning.IEEE Robotics and Automation Letters, 5(2):3699–3706, 2020
2020
-
[31]
Jenelten, J
F. Jenelten, J. He, F. Farshidian, and M. Hutter. Dtc: Deep tracking control.Science Robotics, 9(86):eadh5401, 2024
2024
-
[32]
W. Yu, D. Jain, A. Escontrela, A. Iscen, P. Xu, E. Coumans, S. Ha, J. Tan, and T. Zhang. Visual-locomotion: Learning to walk on complex terrains with vision. InConference on Robot Learning (CoRL), 2021
2021
-
[33]
Gangapurwala, M
S. Gangapurwala, M. Geisert, R. Orsolino, M. Fallon, and I. Havoutis. Rloc: Terrain-aware legged locomotion using reinforcement learning and optimal control.IEEE Transactions on Robotics, 38(5):2908–2927, 2022
2022
-
[34]
Zhuang, Z
Z. Zhuang, Z. Fu, J. Wang, C. Atkeson, S. Schwertfeger, C. Finn, and H. Zhao. Robot parkour learning. InConference on Robot Learning (CoRL), 2023
2023
-
[35]
R. S. Sutton.Temporal credit assignment in reinforcement learning. University of Mas- sachusetts Amherst, 1984
1984
-
[36]
D. Zhu, C. Zhu, Z. Zhang, S. Xin, and Y . Liu. Learning safe locomotion for quadrupedal robots by derived-action optimization. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6870–6876. IEEE, 2024
2024
-
[37]
Zhang, N
C. Zhang, N. Rudin, D. Hoeller, and M. Hutter. Learning agile locomotion on risky terrains. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 11864–11871. IEEE, 2024
2024
-
[38]
Abdolhosseini, H
F. Abdolhosseini, H. Y . Ling, Z. Xie, X. B. Peng, and M. Van de Panne. On learning symmetric locomotion. InProceedings of the 12th ACM SIGGRAPH Conference on Motion, Interaction and Games, pages 1–10, 2019
2019
-
[39]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
I. M. A. Nahrendra, B. Yu, and H. Myung. Dreamwaq: Learning robust quadrupedal lo- comotion with implicit terrain imagination via deep reinforcement learning. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 5078–5084. IEEE, 2023
2023
-
[41]
Huang, S
R. Huang, S. Zhu, Y . Du, and H. Zhao. Moe-loco: Mixture of experts for multitask locomotion. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 14218–14225. IEEE, 2025
2025
-
[42]
R. A. Jacobs, M. I. Jordan, S. J. Nowlan, and G. E. Hinton. Adaptive mixtures of local experts. Neural computation, 3(1):79–87, 1991
1991
-
[43]
S. Luo, S. Li, R. Yu, Z. Wang, J. Wu, and Q. Zhu. Pie: Parkour with implicit-explicit learning framework for legged robots.IEEE Robotics and Automation Letters, 9(11):9986–9993, 2024
2024
-
[44]
P. Li, H. Li, Y . Ma, L. Chang, X. Yang, R. Yu, Y . Zhang, Y . Cao, Q. Zhu, and G. Sartoretti. Kivi: Kinesthetic-visuospatial integration for dynamic and safe egocentric legged locomotion. arXiv preprint arXiv:2509.23650, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
R. Yu, Q. Wang, H. Li, Z. Jun, Z. Wang, J. Wu, and Q. Zhu. Start: Traversing sparse footholds with terrain reconstruction.IEEE Robotics and Automation Letters, 11(2):2194–2201, 2025
2025
-
[46]
Zargarbashi, J
F. Zargarbashi, J. Cheng, D. Kang, R. Sumner, and S. Coros. Robotkeyframing: Learning locomotion with high-level objectives via mixture of dense and sparse rewards. InConference on Robot Learning (CoRL), 2024
2024
-
[47]
Huang, J
T. Huang, J. Ren, H. Wang, Z. Wang, Q. Ben, M. Wen, X. Chen, J. Li, and J. Pang. Learn- ing humanoid standing-up control across diverse postures. InRobotics: Science and Systems (RSS), 2025
2025
-
[48]
G. Cesa, L. Lang, and M. Weiler. A program to build e(n)-equivariant steerable cnns. In International Conference on Learning Representations (ICLR), 2022
2022
-
[49]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[50]
M. Macklin. Warp: A high-performance python framework for gpu simulation and graphics. InNVIDIA GPU Technology Conference (GTC), volume 3, 2022
2022
-
[51]
Z. Fu, A. Kumar, J. Malik, and D. Pathak. Minimizing energy consumption leads to the emer- gence of gaits in legged robots. InConference on Robot Learning (CoRL), 2021
2021
-
[52]
B. R. Whittington and D. G. Thelen. A simple mass-spring model with roller feet can induce the ground reactions observed in human walking.Journal of biomechanical engineering, 131 (1):011013, 2009
2009
-
[53]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on Robot Learning (CoRL), 2021
2021
-
[54]
Mahmood, N
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019
2019
-
[55]
W. Xie, J. Han, J. Zheng, H. Li, X. Liu, J. Shi, W. Zhang, C. Bai, and X. Li. Kungfubot: Physics-based humanoid whole-body control for learning highly-dynamic skills. In D. Bel- grave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors,Ad- vances in Neural Information Processing Systems, volume 38, pages 62406–62433. Curran Associ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.