TARIC: Memory-Augmented Traversability-Aware Outdoor VLN under Interrupted Semantic Cues
Pith reviewed 2026-06-28 22:07 UTC · model grok-4.3
The pith
A 3D cue memory grounded in real-time traversability keeps outdoor robot guidance stable through long gaps in semantic cues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
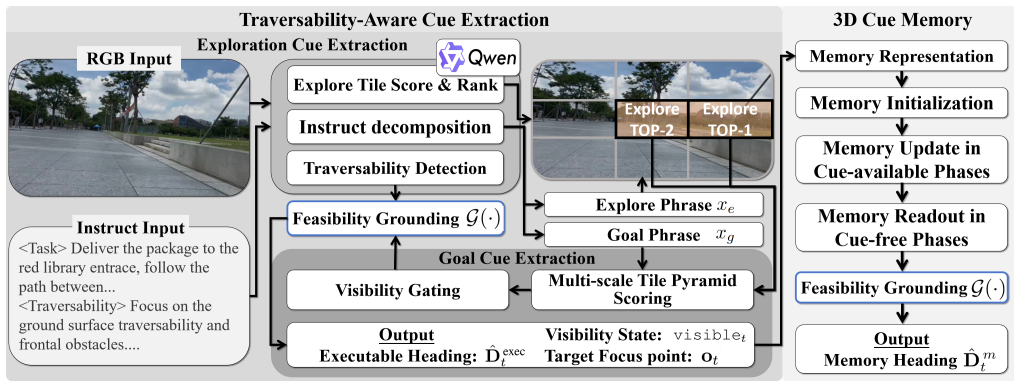
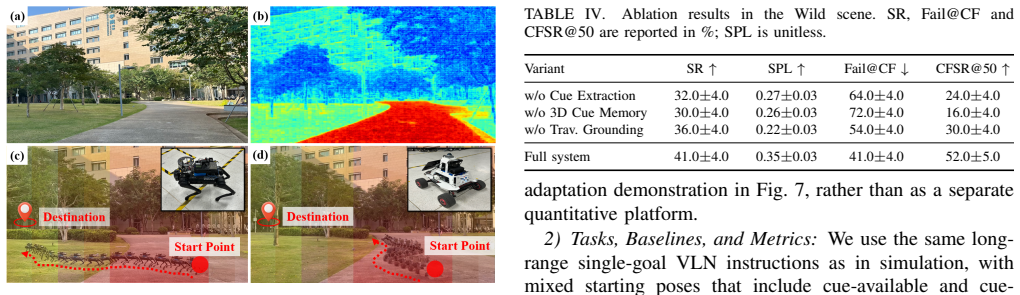
The paper claims that lifting intermittent 2D semantic evidence into a world-aligned 3D cue memory with an uncertainty-aware readout mechanism, while grounding semantic bearings into executable headings via a real-time near-field traversability profile, produces continuously reachable and stable goal-directed guidance even when semantic cues are absent for extended periods. This approach is shown to raise simulation success rates by more than 10 percentage points over the strongest baseline and to reach 40 percent real-world success on long outdoor routes where the baseline reaches only 17.5 percent.
What carries the argument
World-aligned 3D cue memory with uncertainty-aware readout, grounded by real-time near-field traversability profile
If this is right
- Simulation success rate improves by over 10 percentage points compared with the strongest baseline.
- Real-world success rate reaches 40 percent on 600-1000 m routes versus 17.5 percent for the strongest baseline.
- Robustness increases substantially during prolonged cue-free intervals on both quadrupedal and wheeled platforms.
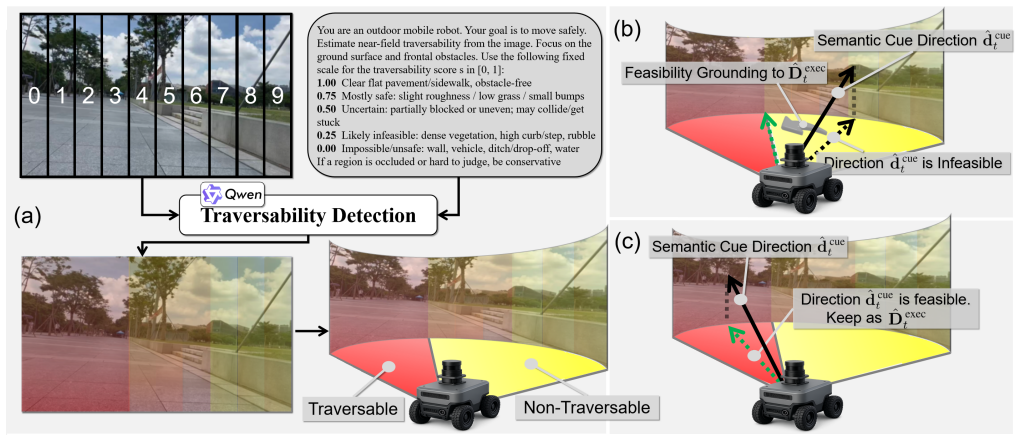
- Guidance remains executable because traversability constraints are incorporated at the moment bearings are turned into headings rather than applied only as reject filters.
Where Pith is reading between the lines
- Treating traversability as a stability condition rather than a local safety layer may extend naturally to other long-range navigation settings where memory must survive terrain constraints.
- The uncertainty-aware readout from 3D memory could be tested with additional intermittent data sources such as sparse GPS or visual odometry to see whether the same structure preserves guidance.
- The separation of cue extraction from traversability grounding suggests that similar memory modules could be swapped into existing VLN pipelines without retraining the entire perception stack.
Load-bearing premise
A real-time near-field traversability profile can be reliably obtained and used to ground semantic bearings into executable headings without introducing new errors during detours.
What would settle it
Measurements showing that success rates fail to exceed baselines by 10 points or that guidance becomes unstable specifically when the robot must take traversability-driven detours away from remembered cue directions would falsify the central claim.
Figures




read the original abstract
Outdoor vision-language navigation (VLN) in long-range, open-world environments is frequently disrupted by semantic-cue interruptions, where informative goal cues become sparse, occluded, or leave the field of view. Once such cues disappear, agents enter a cue-free phase and often degrade into backtracking, oscillatory headings, or aimless exploration. While memory-based methods attempt to bridge these gaps, they often fail under traversability-driven detours: the remembered cue direction may be infeasible, forcing detours that prolong cue-free phases and gradually render robot-centric cues stale and implicit histories blurred. This makes traversability a stability condition for maintaining goal-directed guidance, rather than merely a local safety concern. We propose a unified outdoor VLN framework that survives semantic-cue interruptions by maintaining traversability-consistent executable guidance throughout prolonged cue-free phases. Specifically, our method extracts semantic bearings from visibility-gated goal or exploration cues and grounds them into executable headings using a real-time near-field traversability profile, providing goal-consistent feasible guidance beyond reject-only safety filtering. To prevent guidance degradation during detours, we lift intermittent 2D evidence into a world-aligned 3D cue memory with an uncertainty-aware readout mechanism, ensuring guidance remains continuously reachable and stable as the robot moves. We evaluate the framework on quadrupedal and wheeled platforms over 600--1000 m routes. Our method improves simulation success rate by over 10 percentage points over the strongest baseline and achieves a real-world success rate of 40%, compared to 17.5% for the strongest baseline, with substantially higher robustness during prolonged cue-free intervals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents TARIC, a unified outdoor VLN framework for handling semantic-cue interruptions in long-range navigation. It extracts semantic bearings from visibility-gated cues and grounds them into executable headings via a real-time near-field traversability profile, while lifting 2D evidence into a world-aligned 3D cue memory with uncertainty-aware readout to maintain stable, reachable guidance during detours. Evaluations on quadrupedal and wheeled platforms over 600-1000 m routes report >10 pp gains in simulation success rate over the strongest baseline and a real-world success rate of 40% (vs. 17.5% baseline), with improved robustness in prolonged cue-free intervals.
Significance. If the results hold, the work makes a meaningful contribution by treating traversability as a stability condition for memory consistency rather than solely a local safety filter, addressing a practical failure mode in outdoor VLN. The introduction of the world-aligned 3D cue memory with uncertainty-aware readout and the empirical gains on both simulation and real platforms (including 600-1000 m routes) are strengths that could advance memory-augmented navigation if the traversability grounding proves reliable across varied conditions.
major comments (2)
- [Abstract] Abstract: the central robustness claim during prolonged cue-free intervals rests on the traversability profile reliably converting semantic bearings into executable headings without compounding errors on detours, yet no quantitative characterization of profile accuracy, latency, or noise is supplied, nor any ablation isolating its contribution versus the 3D cue memory.
- [Evaluation] Evaluation description: the reported 10 pp simulation gain and 40% real-world success rate lack failure-mode analysis for cases where profile noise produces locally feasible but globally inconsistent headings, or for cue-free intervals longer than those tested; this leaves open whether the gains are general or condition-specific.
minor comments (1)
- [Abstract] The abstract sentence on real-world results could explicitly restate the route lengths (600-1000 m) for immediate context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will incorporate the suggested analyses into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central robustness claim during prolonged cue-free intervals rests on the traversability profile reliably converting semantic bearings into executable headings without compounding errors on detours, yet no quantitative characterization of profile accuracy, latency, or noise is supplied, nor any ablation isolating its contribution versus the 3D cue memory.
Authors: We agree that the abstract and current evaluation lack explicit quantitative metrics on traversability profile accuracy, latency, and noise, as well as an ablation separating its role from the 3D cue memory. In the revision we will add a dedicated subsection in Evaluation reporting these metrics (e.g., heading error distributions, latency histograms, and noise sensitivity curves) from both simulation and real-world logs, together with an ablation that disables the traversability grounding while retaining the 3D memory (and vice versa) to quantify each component's contribution to success rate under extended cue-free intervals. revision: yes
-
Referee: [Evaluation] Evaluation description: the reported 10 pp simulation gain and 40% real-world success rate lack failure-mode analysis for cases where profile noise produces locally feasible but globally inconsistent headings, or for cue-free intervals longer than those tested; this leaves open whether the gains are general or condition-specific.
Authors: We acknowledge the absence of explicit failure-mode analysis for profile-induced global inconsistency and for cue-free intervals exceeding the tested durations. The revision will include a new failure-case study that (i) injects controlled profile noise and measures resulting heading drift and success degradation, and (ii) extends cue-free intervals in simulation up to 300 s while reporting success-rate curves versus interval length. These additions will clarify the conditions under which the reported gains hold. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or self-referential predictions
full rationale
The paper describes a VLN framework and reports empirical success rates from simulation and real-world tests on specific platforms and routes. No equations, derivations, fitted parameters presented as predictions, or uniqueness theorems appear in the provided text. Claims rest on experimental outcomes rather than any chain that reduces by construction to inputs. Self-citations, if present in the full manuscript, are not load-bearing for any mathematical result here. This is the standard case of an applied robotics paper whose central claims are externally falsifiable via replication of the reported trials.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Robots can obtain accurate real-time near-field traversability profiles.
- domain assumption The 3D cue memory can be maintained without significant drift or loss of information during detours.
invented entities (1)
-
World-aligned 3D cue memory with uncertainty-aware readout
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Vision-language navigation: a survey and taxonomy,
W. Wuet al., “Vision-language navigation: a survey and taxonomy,” Neural Computing and Applications, vol. 36, no. 7, pp. 3291–3316, 2024
2024
-
[2]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wanget al., “Qwen2-vl: Enhancing vision-language model’s percep- tion of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
The llama 3 herd of models,
A. Dubeyet al., “The llama 3 herd of models,”arXiv e-prints, pp. arXiv–2407, 2024
2024
-
[4]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
G. Teamet al., “Gemini 1.5: Unlocking multimodal under- standing across millions of tokens of context,”arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Vision-and-language navigation today and tomor- row: A survey in the era of foundation models,
Y . Zhanget al., “Vision-and-language navigation today and tomor- row: A survey in the era of foundation models,”arXiv preprint arXiv:2407.07035, 2024
-
[6]
Streamvln: Streaming vision-and-language navigation via slowfast context modeling
M. Weiet al., “Streamvln: Streaming vision-and-language navigation via slowfast context modeling,”arXiv preprint arXiv:2507.05240, 2025
-
[7]
Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks,
J. Zhanget al., “Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks,”Robot.: Sci. Syst., 2024
2024
-
[8]
Gmm-searcher: efficient object search in large-scale scenes using large language models,
L. Zhenget al., “Gmm-searcher: efficient object search in large-scale scenes using large language models,”Scientific Reports, vol. 15, no. 1, p. 16709, 2025
2025
-
[9]
Genie: A generalizable navigation system for in-the- wild environments,
J. Wanget al., “Genie: A generalizable navigation system for in-the- wild environments,”IEEE Robot. Autom. Lett., 2025
2025
-
[10]
Vlm-gronav: Robot navigation using physically grounded vision-language models in outdoor environments,
M. Elnooret al., “Vlm-gronav: Robot navigation using physically grounded vision-language models in outdoor environments,” inProc. IEEE Int. Conf. Robot. Autom.IEEE, 2025, pp. 2391–2398
2025
-
[11]
Vint: A foundation model for visual navigation,
D. Shahet al., “Vint: A foundation model for visual navigation,” in Proc. IEEE Conf. Rob. Learn
-
[12]
Nomad: Goal masked diffusion policies for naviga- tion and exploration,
A. Sridharet al., “Nomad: Goal masked diffusion policies for naviga- tion and exploration,” inProc. IEEE Int. Conf. Robot. Autom.IEEE, 2024, pp. 63–70
2024
-
[13]
Citywalker: Learning embodied urban navigation from web-scale videos,
X. Liuet al., “Citywalker: Learning embodied urban navigation from web-scale videos,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2025, pp. 6875–6885
2025
-
[14]
Towards learning a generalist model for embodied navigation,
D. Zhenget al., “Towards learning a generalist model for embodied navigation,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2024, pp. 13 624–13 634
2024
-
[15]
Convoi: Context-aware navigation using vision language models in outdoor and indoor environments,
A. J. Sathyamoorthyet al., “Convoi: Context-aware navigation using vision language models in outdoor and indoor environments,” inProc. IEEE/RJS Int. Conf. Intell. Robots Syst.IEEE, 2024, pp. 13 837– 13 844
2024
-
[16]
Opennav: Open-world navigation with multimodal large language models,
M. Yuanet al., “Opennav: Open-world navigation with multimodal large language models,”arXiv preprint arXiv:2507.18033, 2025
-
[17]
Vl-nav: Real-time vision-language navigation with spatial reasoning,
Y . Duet al., “Vl-nav: Real-time vision-language navigation with spatial reasoning,”arXiv preprint arXiv:2502.00931, 2025
-
[18]
T. Zenget al., “Ezreal: Enhancing zero-shot outdoor robot naviga- tion toward distant targets under varying visibility,”arXiv preprint arXiv:2509.13720, 2025
-
[19]
Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,
O. Alamaet al., “Rayfronts: Open-set semantic ray frontiers for online scene understanding and exploration,”Proc. IEEE/RJS Int. Conf. Intell. Robots Syst., 2025
2025
-
[20]
Zest: an llm-based zero-shot traversability navi- gation for unknown environments,
S. Gummadiet al., “Zest: an llm-based zero-shot traversability navi- gation for unknown environments,”arXiv preprint arXiv:2508.19131, 2025
-
[21]
S. Baiet al., “Qwen3-vl technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2511.21631
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Hello gpt-4o,
OpenAI, “Hello gpt-4o,” 2024. [Online]. Available: https://openai. com/index/hello-gpt-4o/
2024
-
[23]
G. Comaniciet al., “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Yoco: You only calibrate once for accurate extrinsic parameter in lidar-camera systems,
T. Zenget al., “Yoco: You only calibrate once for accurate extrinsic parameter in lidar-camera systems,”Measurement Science and Tech- nology, vol. 36, no. 7, p. 075009, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.