Light Interaction: Training-Free Inference Acceleration for Interactive Video World Models
Pith reviewed 2026-06-28 22:41 UTC · model grok-4.3
The pith
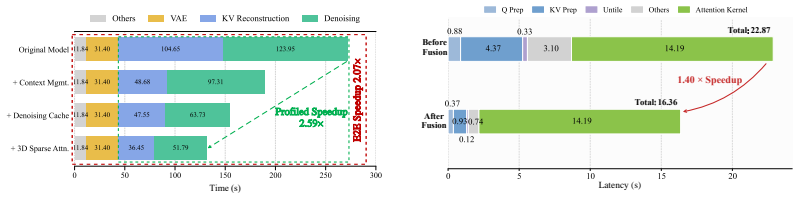
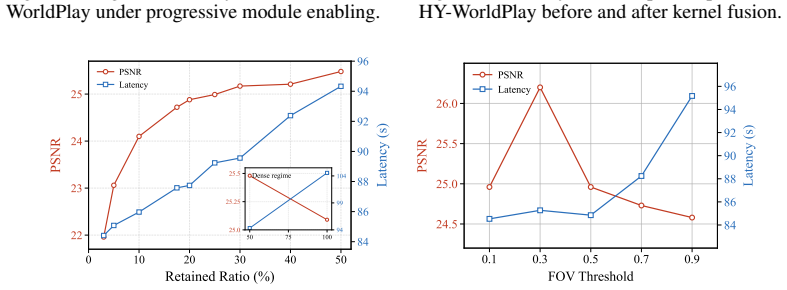
Interactive video world models run up to 2.59 times faster by adapting computation to camera trajectories without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
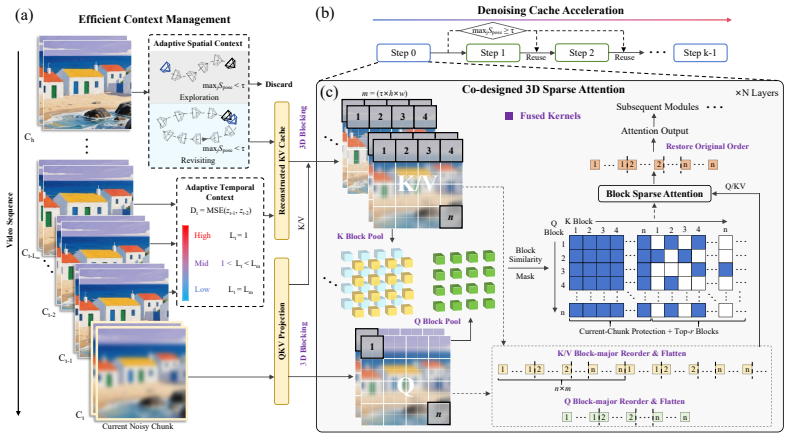
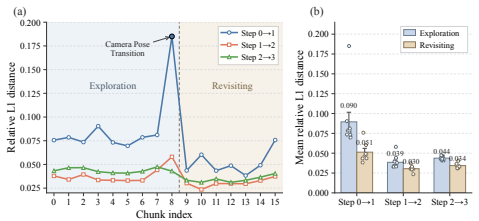
Light Interaction is a training-free inference acceleration framework whose central mechanism is trajectory-dependent adaptive computation: retrieved spatial memory is discarded during novel exploration, temporal context is adjusted according to local latent dynamics, and early-step model outputs are reused when the camera revisits familiar regions, realized via adaptive context management, denoising cache acceleration, and hardware-software co-designed 3D block sparse attention.
What carries the argument
Trajectory-dependent adaptive computation, which discards spatial memory during novel exploration, adjusts temporal context by local latent dynamics, and reuses early outputs on revisits.
If this is right
- Long interactive trajectories become feasible because context memory and attention costs no longer grow unchecked.
- Existing pretrained video world models can be deployed interactively without any retraining step.
- Visual quality remains comparable to full-computation baselines on the evaluated platforms.
- Hardware throughput rises through the use of fused 3D block sparse attention kernels.
Where Pith is reading between the lines
- The same trajectory signals could be applied to other user-driven generative tasks to skip redundant work.
- Energy consumption for real-time embodied simulations would drop in proportion to the reduced denoising and attention operations.
- The approach might combine with distillation or quantization for further gains in resource-constrained settings.
Load-bearing premise
User camera movements in practice create enough opportunities to safely discard memory and reuse outputs without lowering visual quality.
What would settle it
Running the method on a sequence where the camera revisits familiar regions yet produces visibly degraded frames or no speedup would show the adaptive rules do not hold.
Figures
read the original abstract
Interactive video world models generate video chunk by chunk in response to user-controlled camera movements, enabling applications such as real-time game simulation, virtual scene navigation, and embodied AI training. However, scaling to long interactive trajectories is prohibitively expensive due to growing context memory, quadratic attention complexity, and repeated denoising steps. We present Light Interaction, a training-free inference acceleration framework for interactive video world models. Our key insight is that interaction naturally enables trajectory-dependent adaptive computation: retrieved spatial memory can be discarded during novel exploration, temporal context can be adjusted according to local latent dynamics, and early-step model outputs can be reused when the camera revisits familiar regions. Based on this insight, Light Interaction combines adaptive context management, denoising cache acceleration, and hardware-software co-designed 3D block sparse attention with fused Triton kernels. Evaluated on HY-WorldPlay and Matrix-Game-3.0, Light Interaction achieves up to 2.59x speedup without model retraining while maintaining competitive visual quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Light Interaction is a training-free inference acceleration framework for interactive video world models. It exploits interaction-induced trajectory statistics for adaptive computation—discarding spatial memory on novel exploration, dynamically adjusting temporal context, and reusing early denoising outputs on revisits—combined with adaptive context management, denoising cache acceleration, and hardware-software co-designed 3D block sparse attention via fused Triton kernels. On HY-WorldPlay and Matrix-Game-3.0 it reports up to 2.59x speedup without retraining while preserving competitive visual quality.
Significance. If the quality-preservation claim holds under the adaptive mechanisms, the work would offer a practical route to scaling long interactive trajectories in real-time game simulation and embodied AI without model retraining. The training-free design and explicit hardware co-design (Triton kernels) are concrete strengths that could be adopted more broadly.
major comments (2)
- [Evaluation] Evaluation section: the central claim that the three adaptive mechanisms (spatial-memory discard, temporal-context adjustment, early-output reuse) incur no perceptible quality loss is load-bearing yet unsupported by ablations that isolate each mechanism or by quantitative perceptual metrics (FVD, LPIPS) comparing optimized vs. baseline trajectories on held-out data.
- [Abstract and Evaluation] Abstract and Evaluation: no failure-case analysis or quantitative comparison of temporal inconsistencies/artifacts is provided, leaving the assumption that interaction statistics always permit safe pruning untested beyond the two reported datasets.
minor comments (1)
- The abstract would be clearer if it listed the precise visual-quality metrics and the exact speedup measurement protocol (e.g., wall-clock time per chunk, batch size).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will make to strengthen the evaluation.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claim that the three adaptive mechanisms (spatial-memory discard, temporal-context adjustment, early-output reuse) incur no perceptible quality loss is load-bearing yet unsupported by ablations that isolate each mechanism or by quantitative perceptual metrics (FVD, LPIPS) comparing optimized vs. baseline trajectories on held-out data.
Authors: We agree that isolating each adaptive mechanism via dedicated ablations and reporting quantitative perceptual metrics such as FVD and LPIPS on held-out trajectories would provide stronger support for the quality-preservation claim. In the revised manuscript we will add these ablations and include FVD and LPIPS comparisons between the accelerated and baseline trajectories on held-out data from both datasets. revision: yes
-
Referee: [Abstract and Evaluation] Abstract and Evaluation: no failure-case analysis or quantitative comparison of temporal inconsistencies/artifacts is provided, leaving the assumption that interaction statistics always permit safe pruning untested beyond the two reported datasets.
Authors: We acknowledge that explicit failure-case analysis and quantitative metrics for temporal inconsistencies would better test the limits of the interaction-statistics assumption. In the revision we will add a section with failure-case discussion and quantitative temporal-artifact comparisons on the existing datasets. revision: yes
Circularity Check
No circularity: empirical acceleration method with no self-referential derivations
full rationale
The paper describes a training-free inference acceleration framework relying on adaptive context management, denoising cache, and sparse attention, motivated by interaction properties in video world models. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims rest on empirical evaluation (speedup on HY-WorldPlay and Matrix-Game-3.0) rather than any derivation that reduces to its own inputs by construction. This is a standard engineering contribution with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing interactive video world models support adaptive context management and caching without retraining.
Reference graph
Works this paper leans on
-
[1]
Diffusion for world modeling: Visual details matter in Atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in Atari. InAdvances in Neural Information Processing Systems (NeurIPS), volume 37, pages 58757–58791, 2024. 9
2024
-
[2]
Diffusion models are real-time game engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. InProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[3]
Navigation world models
Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. Navigation world models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15791–15801, 2025
2025
-
[4]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. WorldPlay: Towards long-term geometric consistency for real-time interactive world modeling.arXiv preprint arXiv:2512.14614, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Yangguang Li et al. Matrix-Game 3.0: Real-time and streaming interactive world model with long-horizon memory.arXiv preprint arXiv:2604.08995, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
H2O: Heavy-hitter oracle for efficient generative inference of large language models
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, pages 34661–34710, 2023
2023
-
[8]
Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, 2024
2024
-
[9]
DeepCache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. DeepCache: Accelerating diffusion models for free. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[10]
Real-time video generation with pyramid attention broadcast.arXiv preprint arXiv:2408.12588, 2024
Xuanlei Zhao, Xiaolong Jin, Kai Wang, and Yang You. Real-time video generation with pyramid attention broadcast.arXiv preprint arXiv:2408.12588, 2024
- [11]
-
[12]
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model.arXiv preprint arXiv:2411.19108, 2024
-
[13]
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen. ∆-DiT: A training-free acceleration method tailored for diffusion transformers.arXiv preprint arXiv:2406.01125, 2024
-
[14]
SpargeAttn: Accurate sparse attention accelerating any model inference
Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. SpargeAttn: Accurate sparse attention accelerating any model inference. InProceedings of the International Conference on Machine Learning (ICML), 2025
2025
-
[15]
Haocheng Xi, Shuo Yang, Yilong Zhao, Chenfeng Xu, Muyang Li, Xiuyu Li, Yujun Lin, Han Cai, Jintao Zhang, Dacheng Li, et al. Sparse VideoGen: Accelerating video diffusion transformers with spatial-temporal sparsity.arXiv preprint arXiv:2502.01776, 2025
-
[16]
Sparse VideoGen2: Accelerate Video Generation with Sparse Attention via Semantic-Aware Permutation
Shuo Yang, Haocheng Xi, Yilong Zhao, Muyang Li, Jintao Zhang, Han Cai, Yujun Lin, Xiuyu Li, Chenfeng Xu, and Kelly Peng. Sparse VideoGen2: Accelerate video generation with sparse attention via semantic-aware profiling.arXiv preprint arXiv:2505.18875, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
VMoBA: Mixture-of-block attention for video diffusion models.arXiv preprint arXiv:2506.23858, 2025
Jianzong Wu, Liang Hou, Haotian Yang, Xin Tao, Ye Tian, Pengfei Wan, Di Zhang, and Yunhai Tong. VMoBA: Mixture-of-block attention for video diffusion models.arXiv preprint arXiv:2506.23858, 2025
-
[18]
Light Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention
Chengtao Lv, Yumeng Shi, Yushi Huang, Ruihao Gong, Shen Ren, and Wenya Wang. Light Forcing: Accelerating autoregressive video diffusion via sparse attention.arXiv preprint arXiv:2602.04789, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. CogVideoX: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators.OpenAI Blog, 1(8):1, 2024
2024
-
[22]
Lvmin Zhang and Maneesh Agrawala. Packing input frame context in next-frame prediction models for video generation.arXiv preprint arXiv:2504.12626, 2025
-
[23]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Long-Context Autoregressive Video Modeling with Next-Frame Prediction
Yuchao Gu, Weijia Mao, and Mike Zheng Shou. Long-context autoregressive video modeling with next-frame prediction.arXiv preprint arXiv:2503.19325, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
StreamingT2V: Consistent, dynamic, and extendable long video generation from text
Roberto Henschel, Levon Khachatryan, Hayk Poghosyan, Daniil Hayrapetyan, Vahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. StreamingT2V: Consistent, dynamic, and extendable long video generation from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2568–2577, 2025
2025
-
[26]
VMem: Consistent interactive video scene generation with surfel-indexed view memory
Runjia Li, Philip Torr, Andrea Vedaldi, and Tomas Jakab. VMem: Consistent interactive video scene generation with surfel-indexed view memory. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025
2025
-
[27]
WonderWorld: Interactive 3D scene generation from a single image
Hong-Xing Yu, Haoyi Duan, Charles Herrmann, William T Freeman, and Jiajun Wu. WonderWorld: Interactive 3D scene generation from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5916–5926, 2025
2025
-
[28]
Gen3C: 3D-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3C: 3D-informed world-consistent video generation with precise camera control. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6121–6132, 2025
2025
-
[29]
arXiv preprint arXiv:2504.12369 (2025)
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. WorldMem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
-
[30]
Jiwen Yu, Jianhong Bai, Yiran Qin, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval.arXiv preprint arXiv:2506.03141, 2025
-
[31]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InProceedings of the International Conference on Learning Representations (ICLR), 2020
2020
-
[32]
DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[33]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6613–6623, 2024
2024
-
[35]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22963–22974, 2025
2025
-
[36]
Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507, 2025
Peiyuan Zhang, Yongqi Chen, Runlong Su, Hangliang Ding, Ion Stoica, Zhenghong Liu, and Hao Zhang. Fast video generation with sliding tile attention.arXiv preprint arXiv:2502.04507, 2025
-
[37]
VSA: Faster video diffusion with trainable sparse attention.arXiv preprint arXiv:2505.13389, 2025
Peiyuan Zhang, Yongqi Chen, Haofeng Huang, Will Lin, Zhengzhong Liu, Ion Stoica, Eric Xing, and Hao Zhang. VSA: Faster video diffusion with trainable sparse attention.arXiv preprint arXiv:2505.13389, 2025
-
[38]
Yushi Huang, Xingtong Ge, Ruihao Gong, Chengtao Lv, and Jun Zhang. LinVideo: A post-training framework towards O(N) attention in efficient video generation.arXiv preprint arXiv:2510.08318, 2025
-
[39]
Improving the training of rectified flows.Advances in neural information processing systems, 37:63082–63109, 2024
Sangyun Lee, Zinan Lin, and Giulia Fanti. Improving the training of rectified flows.Advances in neural information processing systems, 37:63082–63109, 2024. 11
2024
-
[40]
Tencent Hunyuan Foundation Model Team
Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun Liang, Liya Ma, Siyu Ren, Xiaoming Wei, Rixu Xie, et al. Longcat-video technical report.arXiv preprint arXiv:2510.22200, 2025
-
[41]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 12 Table 3: Leave-one-out ablation of ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.