COLLEAGUE.SKILL: Automated AI Skill Generation via Expert Knowledge Distillation
Pith reviewed 2026-06-28 22:27 UTC · model grok-4.3
The pith
COLLEAGUE.SKILL automates conversion of expert traces into versioned AI skill packages with capability and behavior tracks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
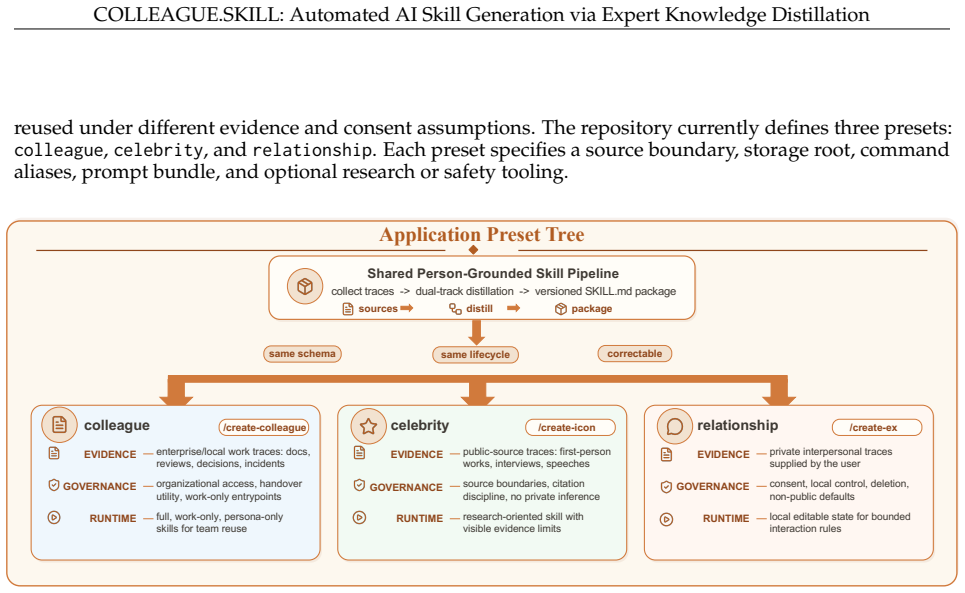
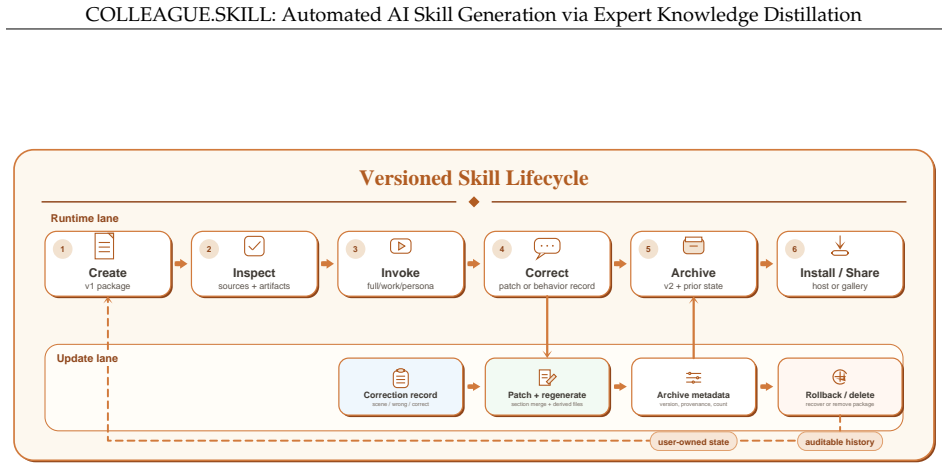
Given materials from a target person or role, COLLEAGUE.SKILL produces a versioned skill package with two coordinated tracks: a capability track for practices, mental models, and decision heuristics, and a bounded behavior track for communication style, interaction rules, and correction history. The package can be inspected, invoked, updated through natural-language feedback, rolled back, installed across agent hosts, and optionally prepared for controlled distribution.
What carries the argument
The versioned skill package with its capability track and bounded behavior track, produced by the trace-to-skill distillation workflow.
Load-bearing premise
Heterogeneous traces contain sufficient actionable knowledge that can be automatically extracted into inspectable, correctable skill packages without significant loss or distortion of the original expertise.
What would settle it
Deploy the generated skill packages in agents and check whether their decisions on new scenarios drawn from the same domain match the original expert's choices, or whether natural-language corrections fail to produce accurate updates to the package.
Figures

read the original abstract
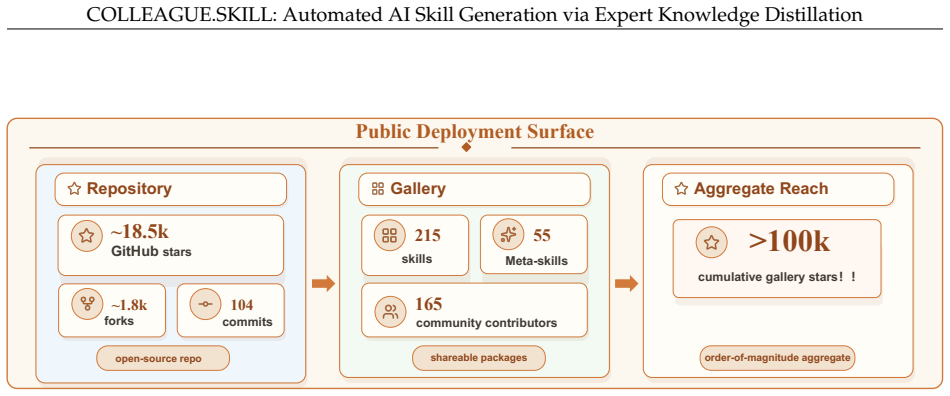
LLM agents are increasingly expected not only to complete isolated tasks, but also to carry bounded representations of human expertise, judgment, and interaction style. Building such person-grounded agents remains difficult because actionable knowledge associated with a person or role is usually embedded in heterogeneous traces rather than written as clean instructions. Existing memory and persona systems capture fragments of this evidence, while skill frameworks provide portable packaging formats; however, there is no end-to-end workflow for distilling these traces into inspectable, correctable, and agent-usable skills. We present an automated trace-to-skill distillation system for generating person-grounded AI skills via expert knowledge distillation. Given materials from a target person or role, COLLEAGUE.SKILL produces a versioned skill package with two coordinated tracks: a capability track for practices, mental models, and decision heuristics, and a bounded behavior track for communication style, interaction rules, and correction history. The package can be inspected, invoked, updated through natural-language feedback, rolled back, installed across agent hosts, and optionally prepared for controlled distribution. We describe the artifact contract, generation workflow, correction lifecycle, deployment surface, and domain presets implemented in the open-source system. At the time of writing, the public repository has approximately 18.5k GitHub stars; the gallery lists 215 skills from 165 contributors and more than 100k cumulative stars across listed skill cards. The system illustrates how person-grounded skills can be represented as portable, correctable packages rather than opaque prompts or hidden memories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents COLLEAGUE.SKILL, an automated trace-to-skill distillation system that converts heterogeneous materials from a target person or role into versioned skill packages. Each package contains two coordinated tracks—a capability track capturing practices, mental models, and decision heuristics, and a bounded behavior track capturing communication style, interaction rules, and correction history. The paper describes the artifact contract, generation workflow, correction lifecycle, deployment surface, and domain presets, and reports community metrics for the open-source implementation (18.5k GitHub stars, 215 skills from 165 contributors).
Significance. If the distillation process reliably extracts actionable expertise into inspectable and correctable packages without material distortion, the work could offer a structured alternative to opaque prompts or fragmented memory systems for building person-grounded LLM agents. The emphasis on versioning, natural-language correction, and cross-host portability addresses practical deployment needs, and the reported adoption metrics suggest the framework has already seen community uptake.
major comments (2)
- [Abstract] Abstract: the central claim that the system produces 'inspectable, correctable, and agent-usable skills' that faithfully capture person-grounded expertise rests entirely on description of the workflow and artifact contract; no empirical validation (expert fidelity ratings, downstream agent performance comparisons, ablation on trace heterogeneity, or error analysis) is reported anywhere in the manuscript.
- [The manuscript as a whole] The manuscript as a whole: the assumption that LLM-mediated extraction from heterogeneous traces incurs no significant loss or distortion is load-bearing for the claimed utility, yet remains untested; without such checks the two-track structure and correction lifecycle cannot be shown to improve upon existing memory or persona systems.
minor comments (1)
- [Abstract] Abstract: the GitHub adoption statistics are presented without any accompanying analysis of how contributor volume or star counts correlate with skill correctness or usability.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying the need to clarify the scope and evidential basis of the manuscript. We address each major comment below and commit to revisions that better frame the contribution as a systems description while acknowledging the absence of empirical validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the system produces 'inspectable, correctable, and agent-usable skills' that faithfully capture person-grounded expertise rests entirely on description of the workflow and artifact contract; no empirical validation (expert fidelity ratings, downstream agent performance comparisons, ablation on trace heterogeneity, or error analysis) is reported anywhere in the manuscript.
Authors: We agree that the manuscript provides no empirical validation of skill fidelity, downstream performance, or error characteristics. The paper is a systems description of the artifact contract, workflow, correction lifecycle, and open-source implementation, with community adoption (18.5k GitHub stars, 215 skills) offered as indirect evidence of practical utility rather than controlled evaluation. We will revise the abstract and introduction to explicitly state that the work presents a distillation framework and portable package format, not validated extraction accuracy. A new 'Limitations and Future Work' section will be added to discuss the need for expert fidelity studies, agent performance benchmarks, and ablation experiments on trace heterogeneity. revision: yes
-
Referee: [The manuscript as a whole] The manuscript as a whole: the assumption that LLM-mediated extraction from heterogeneous traces incurs no significant loss or distortion is load-bearing for the claimed utility, yet remains untested; without such checks the two-track structure and correction lifecycle cannot be shown to improve upon existing memory or persona systems.
Authors: The manuscript does not assert that extraction incurs no loss or distortion; the design of the two-track structure and natural-language correction mechanism is intended to surface and mitigate such issues through human inspection and rollback. Nevertheless, we acknowledge that no comparative evaluation against memory or persona systems is provided, so claims of improvement remain untested. In revision we will add an explicit discussion of related memory and persona approaches, state the untested assumptions regarding extraction fidelity, and outline planned empirical comparisons as future work. revision: yes
Circularity Check
No circularity: purely descriptive system design with no derivations or fitted predictions
full rationale
The manuscript presents an engineering artifact (trace-to-skill distillation workflow, two-track package contract, correction lifecycle) without equations, parameter fitting, uniqueness theorems, or any claimed first-principles derivations. No step reduces a result to its own inputs by construction, and no self-citations are invoked as load-bearing mathematical justification. The central claim is an existence and design statement whose validity is independent of the paper's own text; external validation (user studies, fidelity metrics) is simply absent, which is a correctness issue rather than circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Actionable knowledge associated with a person or role is usually embedded in heterogeneous traces rather than written as clean instructions.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2305.16291. Zekun Moore Wang, Zhongyuan Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Stephen W. Huang, Jie Fu, and Junran Peng. Rolellm: Benchmarking, eliciting, and enhancing role-playing abilities of large language mod...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
URLhttps://arxiv.org/abs/2308.08155. 11 COLLEAGUE.SKILL: Automated AI Skill Generation via Expert Knowledge Distillation Yutao Yang, Junsong Li, Qianjun Pan, Bihao Zhan, Yuxuan Cai, Lin Du, Jie Zhou, Kai Chen, Qin Chen, Xin Li, Bo Zhang, and Liang He. Autoskill: Experience-driven lifelong learning via skill self-evolution. arXiv:2603.01145, 2026. URLhttps...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
PersonaAgent: Bridging Memory and Action for Personalized LLM Agents
URLhttps://arxiv.org/abs/2506.06254. Xuhui Zhou, Hao Zhu, Leena Mathur, Ruohong Zhang, Haofei Yu, Zhengyang Qi, Louis-Philippe Morency, Yonatan Bisk, Daniel Fried, Graham Neubig, and Maarten Sap. SOTOPIA: Interactive evaluation for social intelligence in language agents. InInternational Conference on Learning Representations, 2024. URL https://arxiv.org/a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.