The Sword, Shield, and Achilles' Heel: Characterizing the Linguistic Inductive Bias of Large Language Models for Spatial Reasoning in Navigation Planning
Pith reviewed 2026-06-28 22:21 UTC · model grok-4.3
The pith
LLMs in navigation planning treat topological cues as a robust backbone, linguistic formats as a mixed blessing, and incorrect semantic cues as a systematic failure point.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
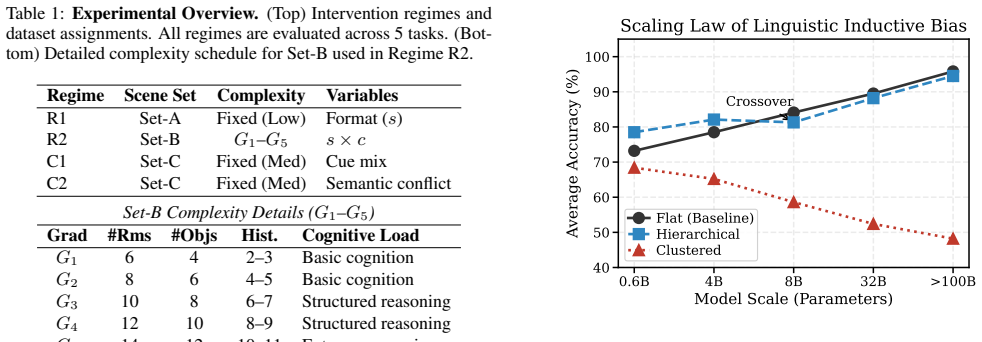
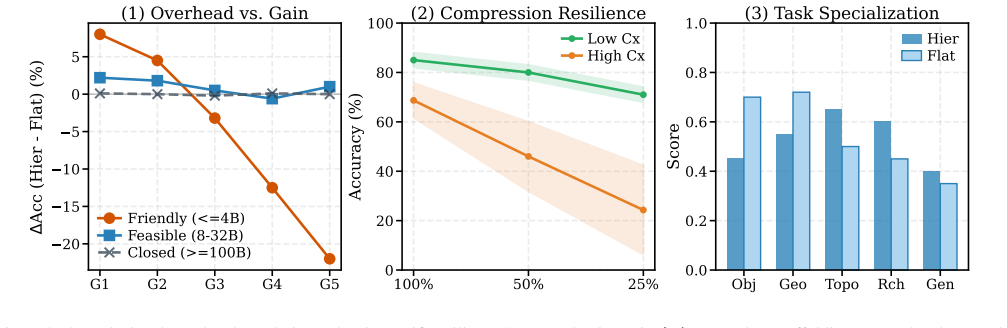
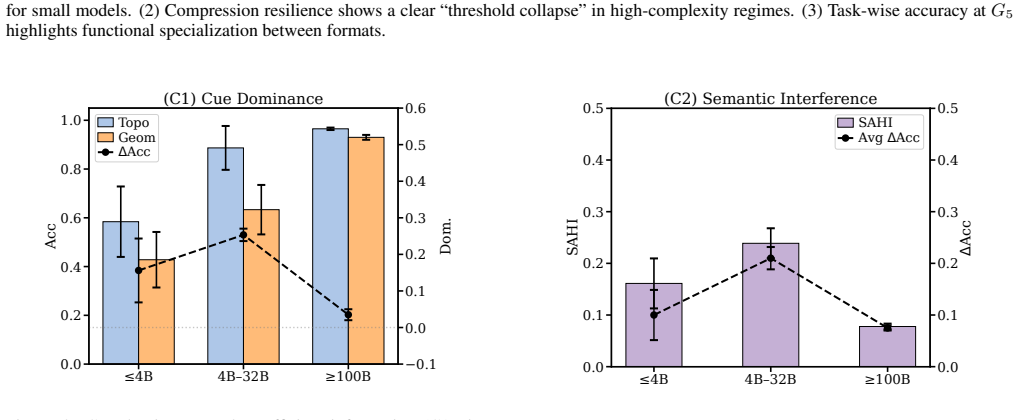
Through controlled interventions on both representation format and contextual content, the work establishes that topological information functions as the sturdy backbone of successful planning, linguistic format acts as a double-edged sword whose value scales with model size and compression, and semantic information operates as a critical vulnerability where incorrect cues cause systematic planning failures.
What carries the argument
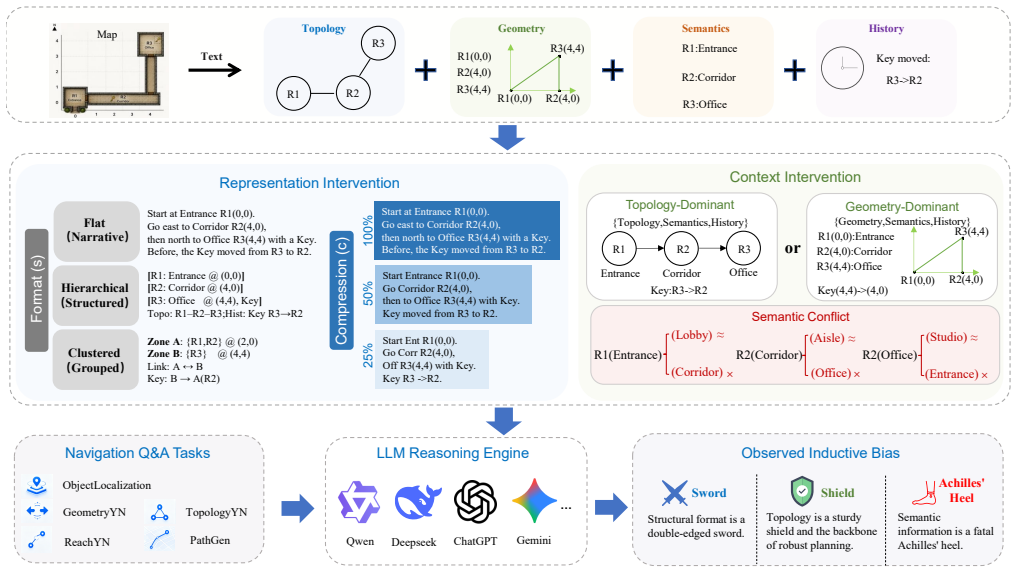
The dual-interventional framework, which applies representation intervention to alter linguistic format and compression while using context intervention plus feature combination and conflict probing to isolate cue preferences.
If this is right
- Navigation inputs should prioritize preservation of topological integrity over other features.
- The degree of linguistic compression must be matched to the capacity of the specific model in use.
- Semantic labels require verification because errors propagate directly into planning failures.
- No single fixed text representation works equally well across model scales and task types.
Where Pith is reading between the lines
- Systems could gain robustness by generating multiple linguistic versions of the same topology and letting the model vote or select.
- The observed semantic fragility may extend to other domains where LLMs receive descriptive labels rather than raw relations.
- Testing the same interventions on embodied robot platforms would reveal whether the biases persist outside pure text settings.
Load-bearing premise
The dual-interventional framework isolates linguistic inductive bias without introducing confounds from task selection or model-specific behaviors.
What would settle it
An experiment in which incorrect semantic labels are supplied alongside intact topological relations and performance does not drop relative to correct-semantics controls.
Figures
read the original abstract
Large Language Model (LLM)-based navigation systems commonly construct explicit spatial representations (e.g., topological graphs, semantic raster maps) and translate them into textual descriptions as LLMs' inputs. However, the linguistic structures of such text-based spatial representations and the choices of contextual features (e.g., topology, geometry) they contain are often treated as neutral engineering decisions rather than key factors that shape LLMs' behavior. To fill the gap, we propose a dual-interventional framework that disentangles linguistic structures from different contextual cues to evaluate the linguistic inductive bias of LLMs for navigation planning. In the framework, representation intervention varies the linguistic format and the degree of linguistic compression, clarifying when linguistic representations support or inhibit navigation planning. Context intervention, combined with contextual feature combination and conflict probing, explicitly clarifies the preferences and weaknesses of LLMs when processing different contextual cues. Experiments across diverse spatial reasoning tasks and multiple model scales reveal a consistent pattern: topological information is a sturdy shield and the backbone of robust planning; linguistic format is a double-edged sword whose effect depends on model size, task demands, and the compression level; and semantic information is a fatal Achilles' heel -- incorrect semantic cues can systematically derail the planning process. Overall, our study shows that effective text-based spatial representations in LLM-based navigation should preserve topological integrity, calibrate representational compression to model capacity, and ensure semantic correctness, rather than simply adopting a single representation. Our code is publicly available at https://github.com/jonesdong150/LLM-Navigation-Inductive-Bias.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a dual-interventional framework to isolate linguistic inductive bias in LLMs for spatial navigation planning tasks. Representation interventions vary linguistic format and compression level, while context interventions combine features and probe conflicts. Experiments across tasks and model scales are reported to show consistent patterns: topology acts as a robust backbone, linguistic format effects are double-edged and context-dependent, and incorrect semantic cues systematically impair planning. The work concludes with design recommendations for text-based spatial representations and releases code.
Significance. If the framework successfully disentangles the claimed factors without confounds, the results would offer actionable guidance for engineering LLM navigation systems, emphasizing preservation of topological structure, calibration of compression to model scale, and avoidance of misleading semantics. Public code availability supports reproducibility and is a clear strength.
major comments (2)
- [Framework description] Framework description (abstract and §3): the orthogonality between representation and context interventions is asserted but not validated via explicit interaction-effect tests or ablation of combined interventions; without this, attribution of observed patterns specifically to linguistic inductive bias remains vulnerable to task- or model-specific confounds.
- [Abstract] Abstract, final experimental paragraph: the claim of a 'consistent pattern' across tasks and scales is presented without reference to statistical methods, sample sizes, error bars, exclusion criteria, or correction for multiple comparisons, rendering the reliability of the central claims (topology as shield, semantics as Achilles' heel) impossible to assess from the provided information.
minor comments (1)
- Notation for intervention conditions and feature combinations could be clarified with a summary table to aid reader tracking across experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the manuscript. We respond to each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: Framework description (abstract and §3): the orthogonality between representation and context interventions is asserted but not validated via explicit interaction-effect tests or ablation of combined interventions; without this, attribution of observed patterns specifically to linguistic inductive bias remains vulnerable to task- or model-specific confounds.
Authors: We acknowledge that the current manuscript asserts the intended orthogonality of the dual-interventional framework without providing explicit statistical validation through interaction-effect tests or ablations of combined interventions. While the design separates representation interventions (linguistic format and compression) from context interventions (feature combination and conflict probing), the absence of these tests leaves the attribution open to potential confounds. In the revised manuscript, we will add a dedicated analysis subsection with interaction-effect tests (e.g., two-way ANOVA) and ablation studies on combined interventions to empirically validate the framework's disentanglement and support the attribution to linguistic inductive bias. revision: yes
-
Referee: Abstract, final experimental paragraph: the claim of a 'consistent pattern' across tasks and scales is presented without reference to statistical methods, sample sizes, error bars, exclusion criteria, or correction for multiple comparisons, rendering the reliability of the central claims (topology as shield, semantics as Achilles' heel) impossible to assess from the provided information.
Authors: We agree that the abstract's claim of a 'consistent pattern' would benefit from explicit references to the supporting statistical details. The main text (Sections 4 and 5) already reports results with statistical methods including ANOVA, sample sizes per condition, error bars, exclusion criteria based on response validity, and Bonferroni correction for multiple comparisons. In the revision, we will update the abstract's final experimental paragraph to concisely reference these elements (e.g., 'across 12 tasks and 5 model scales with N=500 trials per condition, ANOVA with Bonferroni correction') so that the reliability of the topology-as-shield and semantics-as-Achilles'-heel claims can be assessed directly from the abstract. revision: yes
Circularity Check
No circularity: empirical intervention study with independent experimental outcomes
full rationale
The paper describes an empirical dual-interventional framework evaluated through experiments on spatial reasoning tasks across model scales. No equations, fitted parameters, or derivations are present that reduce by construction to self-defined inputs. Central claims about topological information as backbone and semantic cues as Achilles' heel rest on observed experimental patterns rather than self-citation chains, ansatzes, or renamings. The framework is presented as a methodological disentanglement tool without load-bearing self-referential reductions, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs exhibit measurable and consistent linguistic inductive biases for spatial reasoning that interventions can isolate
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
[Ahnet al., 2022 ] Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, et al. Do as i can, not as i say: Grounding language in robotic affordances.arXiv preprint arXiv:2204.01691,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
[Baiet al., 2023 ] Jinze Bai, Shuai Bai, Yunfei Chu, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
[Bubecket al., 2023 ] S´ebastien Bubeck, Varun Chan- drasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang. Sparks of artificial general intel- ligence: Early experiments with GPT-4.arXiv preprint arXiv:2303.12712,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
[Cadenaet al., 2016 ] Cesar Cadena, Luca Carlone, Henry Carrillo, Yasir Latif, Davide Scaramuzza, Jos ´e Neira, Ian Reid, and John J. Leonard. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age.IEEE Transactions on Robotics, 32(6):1309–1332,
2016
- [5]
-
[6]
Robothor: An open simulation-to-real em- bodied AI platform
[Deitkeet al., 2020 ] Matt Deitke, Winson Han, ´Alvaro Her- rasti, Aniruddha Kembhavi, Eric Kolve, Roozbeh Mot- taghi, Jordi Salvador, Dustin Schwenk, Eli VanderBilt, Matthew Wallingford, Luca Weihs, Mark Yatskar, and Ali Farhadi. Robothor: An open simulation-to-real em- bodied AI platform. InProceedings of the IEEE/CVF Conference on Computer Vision and P...
2020
-
[7]
[Fatemi and others, 2023] Bahare Fatemi et al
IEEE/CVF. [Fatemi and others, 2023] Bahare Fatemi et al. Talk like a graph: Encoding graphs for large language models.arXiv preprint arXiv:2310.04560,
-
[8]
[Grattafiori and others, 2024] Aaron Grattafiori et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Language models represent space and time.arXiv preprint arXiv:2310.02207,
[Gurnee and Tegmark, 2023] Wes Gurnee and Max Tegmark. Language models represent space and time.arXiv preprint arXiv:2310.02207,
-
[10]
Hirtle and John Jonides
[Hirtle and Jonides, 1985] Stephen C. Hirtle and John Jonides. Evidence of hierarchies in cognitive maps. Memory & Cognition, 13(3):208–217,
1985
-
[11]
Visual language maps for robot navigation.arXiv preprint arXiv:2210.05714,
[Huanget al., 2022a ] Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. Visual language maps for robot navigation.arXiv preprint arXiv:2210.05714,
-
[12]
Inner Monologue: Embodied Reasoning through Planning with Language Models
[Huanget al., 2022b ] Wenlong Huang, Pieter Abbeel, Deepak Pathak, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Scaling Laws for Neural Language Models
[Kaplanet al., 2020 ] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Large Language Models are Zero-Shot Reasoners
[Kojimaet al., 2022 ] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.arXiv preprint arXiv:2205.11916,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
The spatial semantic hi- erarchy.Artificial Intelligence, 119(1–2):191–233,
[Kuipers, 2000] Benjamin Kuipers. The spatial semantic hi- erarchy.Artificial Intelligence, 119(1–2):191–233,
2000
-
[16]
Kluwer Academic Publishers, Norwell, MA,
[Latombe, 1991] Jean-Claude Latombe.Robot Motion Plan- ning. Kluwer Academic Publishers, Norwell, MA,
1991
-
[17]
Code as Policies: Language Model Programs for Embodied Control
[Liang and others, 2022] Jacky Liang et al. Code as policies: Language model programs for embodied control.arXiv preprint arXiv:2209.07753,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Lost in the Middle: How Language Models Use Long Contexts
[Liu and others, 2023] Nelson F. Liu et al. Lost in the mid- dle: How language models use long contexts.arXiv preprint arXiv:2307.03172,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Montello and Corina Sas
[Montello and Sas, 2006] Daniel R. Montello and Corina Sas. Human factors of wayfinding in navigation. InInter- national Encyclopedia of Ergonomics and Human Factors, pages 2003–2008. CRC Press/Taylor & Francis,
2006
-
[20]
Montello
[Montello, 1998] Daniel R. Montello. A new framework for understanding the acquisition of spatial knowledge in large-scale environments. In Max J. Egenhofer and Regi- nald G. Golledge, editors,Spatial and Temporal Reason- ing in Geographic Information Systems, pages 143–154. Oxford University Press,
1998
-
[21]
Montello
[Montello, 2001] Daniel R. Montello. Spatial cognition. In Neil J. Smelser and Paul B. Baltes, editors,Interna- tional Encyclopedia of the Social & Behavioral Sciences, pages 14771–14775. Elsevier,
2001
-
[22]
Neural Map: Structured Memory for Deep Reinforcement Learning
DOI:10.1016/B0-08- 043076-7/02492-X. [Parisotto and Salakhutdinov, 2017] Emilio Parisotto and Ruslan Salakhutdinov. Neural map: Structured mem- ory for deep reinforcement learning.arXiv preprint arXiv:1702.08360,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/b0-08- 2017
-
[23]
[Ranaet al., 2023 ] Kanishka Rana, Jack Haviland, et al. Sayplan: Grounding large language models using 3d scene graphs for scalable robot task planning.arXiv preprint arXiv:2307.06135,
-
[24]
Habitat: A platform for embodied AI research
[Savvaet al., 2019 ] Manolis Savva, Abhishek Kadian, Olek- sandr Maksymets, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. Habitat: A platform for embodied AI research. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea,
2019
-
[25]
IEEE/CVF. arXiv:1904.01201. [Shahet al., 2023 ] Dhruv Shah, Blazej Osinski, Brian Ichter, and Sergey Levine. Lm-nav: Robotic navigation with large pre-trained models of language, vision, and ac- tion. InProceedings of the Conference on Robot Learn- ing (CoRL), Atlanta, GA,
-
[26]
Also available as arXiv:2207.04429
PMLR. Also available as arXiv:2207.04429. [Thrunet al., 2005 ] Sebastian Thrun, Wolfram Burgard, and Dieter Fox.Probabilistic Robotics. MIT Press, Cam- bridge, Massachusetts,
-
[27]
[Tolman, 1948] Edward C. Tolman. Cognitive maps in rats and men.Psychological Review, 55(4):189–208,
1948
-
[28]
LLaMA: Open and Efficient Foundation Language Models
[Touvronet al., 2023 ] Hugo Touvron, Thibaut Lavril, Gau- tier Izacard, et al. LLaMA: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
On the planning abilities of large language models (a critical investigation)
[Valmeekam and others, 2023] Karthik Valmeekam et al. On the planning abilities of large language models (a critical investigation). InAdvances in Neural Information Pro- cessing Systems (NeurIPS), New Orleans, LA,
2023
-
[30]
Cur- ran Associates. arXiv:2310.12397. [Vaswaniet al., 2017 ] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need.arXiv preprint arXiv:1706.03762,
-
[31]
Voyager: An Open-Ended Embodied Agent with Large Language Models
[Wanget al., 2023a ] Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open- ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Can language models solve graph problems in natural lan- guage?arXiv preprint arXiv:2305.10037,
[Wanget al., 2023b ] Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. Can language models solve graph problems in natural lan- guage?arXiv preprint arXiv:2305.10037,
-
[33]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
[Weiet al., 2022 ] Jason Wei, Xuezhi Wang, Dale Schuur- mans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elic- its reasoning in large language models.arXiv preprint arXiv:2201.11903,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
[Yang and others, 2024] An Yang et al. Qwen2 technical re- port.arXiv preprint arXiv:2407.10671,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
ReAct: Synergizing Reasoning and Acting in Language Models
[Yaoet al., 2022 ] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language mod- els.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
[Zhang and others, 2024] Y . Zhang et al. Can LLM graph reasoning generalize beyond pattern memorization?arXiv preprint arXiv:2406.15992,
-
[37]
Neural SLAM: Learning to explore with external memory.arXiv preprint arXiv:1706.09520,
[Zhanget al., 2017 ] Jingwei Zhang, Lei Tai, Joschka Boedecker, Wolfram Burgard, and Ming Liu. Neural SLAM: Learning to explore with external memory.arXiv preprint arXiv:1706.09520,
-
[38]
MapNav: A Novel Memory Representation via Annotated Semantic Maps for Vision-and-Language Navigation
[Zhanget al., 2025 ] Lingfeng Zhang, Xiaoshuai Hao, Qin- wen Xu, Qiang Zhang, Xinyao Zhang, Pengwei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, and Renjing Xu. Mapnav: A novel memory representation via annotated semantic maps for vlm-based vision-and- language navigation.arXiv preprint arXiv:2502.13451,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
[Zhouet al., 2023 ] Gengze Zhou, Yicong Hong, and Qi Wu. Navgpt: Explicit reasoning in vision-and-language nav- igation with large language models.arXiv preprint arXiv:2305.16986, 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.