If LLMs Have Human-Like Attributes, Then So Does Age of Empires II
Pith reviewed 2026-06-28 22:27 UTC · model grok-4.3
The pith
Anthropomorphic attributes like morality or language understanding ascribed to LLMs can also be ascribed to a neural network trained on Age of Empires II, making them non-unique to language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The purported anthropomorphic attributes of LLMs are empirically non-unique: although some properties such as responses to prompts could remain invariant, others such as the interpretation of their perceived behaviour might change with the substrate. Any entity in a sufficiently-powerful substrate, such as a neural network trained on Age of Empires II or even non-computational systems like LEGO, could present such attributes. Hence any empirically-grounded discussion requires explicit measurement criteria; otherwise the interpretation is left to the representation. Assuming the attributes exist or not in a system independent of the substrate leads to circular or uninformative conclusions reg
What carries the argument
A simple neural network trained on Age of Empires II gameplay data, used to show that the same anthropomorphic attributes can be attributed to non-LLM systems depending on substrate and interpretation.
If this is right
- Responses to prompts may stay the same across substrates, but the interpretation of perceived behavior changes.
- Empirically grounded claims about these attributes require explicit measurement criteria rather than open interpretation.
- Assuming the attributes exist or do not exist in a generalized, substrate-independent manner yields circular or uninformative conclusions.
- Adopting a null assumption of non-uniqueness provides a workable starting point for setting up experiments on the topic.
Where Pith is reading between the lines
- The same non-uniqueness argument could be tested by training networks on other complete game environments to see whether attribute ascription shifts.
- Discussions of AI consciousness or agency would need to specify measurement criteria before substrate comparisons become meaningful.
- The Turing-completeness result for Age of Empires II supplies a concrete example that any sufficiently expressive system can serve as the substrate for such tests.
Load-bearing premise
A neural network trained on Age of Empires II will exhibit the same anthropomorphic attributes as LLMs when its outputs are interpreted in the same way.
What would settle it
A demonstration that the trained Age of Empires II neural network produces no outputs or behaviors that can be interpreted as possessing morality, understanding, or other listed anthropomorphic attributes under the same criteria applied to LLMs.
Figures

read the original abstract
Much research has been carried out on large language models (LLMs) and LLM-powered agentic workflows. However, many works within the field state emergence of, ascribe to, or assume, generalised anthropomorphic attributes to them (e.g., morality or understanding of natural language). Our goal is not to argue in favour or against the existence of these attributes, but to point out that these conclusions could be incorrect. For this we build and train a simple neural network on the videogame Age of Empires II, and note that any entity in a sufficiently-powerful substrate, such as LEGO or the Greater Boston Area, could also present such attributes. Hence, the purported anthropomorphic attributes of LLMs are empirically non-unique: although some properties (e.g., responses to prompts) could remain invariant, others, such as the interpretation of their perceived behaviour, might change with the substrate. Thus, any empirically-grounded discussion on these attributes requires explicit measurement criteria; otherwise the interpretation is left to the representation. We then show that assuming that these attributes exist or not in a system, independent of the substrate and in a generalised way, leads to either circular or uninformative conclusions. This is regardless of the experimenter's viewpoint on the subject, or whether the outcome shows existence or non-existence. Finally we propose a 'null' assumption, where one assumes LLM non-uniqueness instead of assuming anthropomorphic attributes to set up an experiment, along with examples of it. We also discuss potential objections to our work, briefly survey the field, and prove that Age of Empires II is functionally- and Turing-complete.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that anthropomorphic attributes (e.g., morality, natural language understanding) ascribed to LLMs are empirically non-unique because a simple neural network trained on Age of Empires II could exhibit them; the game is shown to be functionally and Turing-complete, and any sufficiently powerful substrate could present such attributes. It argues that assuming existence or non-existence of these attributes leads to circular or uninformative conclusions independent of viewpoint, proposes a 'null' assumption of non-uniqueness for experiments, calls for explicit measurement criteria, surveys the field, and discusses objections.
Significance. If the central argument holds, the work would push the field toward substrate-independent measurement criteria when discussing LLM attributes, reducing reliance on interpretive assumptions. The Turing-completeness proof for AoE II and the concrete proposal of a null assumption are constructive elements that could support improved experimental designs.
major comments (2)
- [Abstract and neural network training section] Abstract and the section describing the neural network training: the claim that the AoE II neural network 'could also present such attributes' is load-bearing for the empirical non-uniqueness conclusion, yet the manuscript supplies only training details and the Turing-completeness result with no evaluation, metrics, behavioral examples, or comparison showing that the trained network exhibits morality, natural language understanding, or the other listed attributes.
- [Section on the 'null' assumption] Section proposing the 'null' assumption: the argument that assuming non-uniqueness avoids the circularity identified in other assumptions is not accompanied by a concrete demonstration or worked example showing how the null setup produces non-circular, informative conclusions where the alternatives do not.
minor comments (1)
- Notation for 'anthropomorphic attributes' is used without an explicit enumerated list or table early in the manuscript, making it harder to track which properties are claimed to be non-unique.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract and neural network training section] Abstract and the section describing the neural network training: the claim that the AoE II neural network 'could also present such attributes' is load-bearing for the empirical non-uniqueness conclusion, yet the manuscript supplies only training details and the Turing-completeness result with no evaluation, metrics, behavioral examples, or comparison showing that the trained network exhibits morality, natural language understanding, or the other listed attributes.
Authors: The argument for empirical non-uniqueness relies on the Turing-completeness of Age of Empires II, which establishes that the substrate supports arbitrary computation and thus could in principle exhibit any behavior interpretable as an anthropomorphic attribute. The neural network training illustrates applicability of standard ML methods to this substrate but does not claim or demonstrate that this specific network exhibits morality, NLU, or similar attributes. The 'could' phrasing in the abstract reflects substrate capacity rather than observed behavior in the trained model. We will revise the abstract and training section to make this distinction explicit and to foreground the completeness proof as the grounding for the potential. revision: partial
-
Referee: [Section on the 'null' assumption] Section proposing the 'null' assumption: the argument that assuming non-uniqueness avoids the circularity identified in other assumptions is not accompanied by a concrete demonstration or worked example showing how the null setup produces non-circular, informative conclusions where the alternatives do not.
Authors: The manuscript presents the null assumption with conceptual examples illustrating how it structures experiments to test uniqueness rather than presuppose it. We acknowledge that an expanded, fully worked empirical-style example would improve clarity. We will add such an example in the revised manuscript, contrasting experimental designs under the null assumption versus existence or non-existence assumptions. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's argument is conceptual rather than a formal derivation: it constructs and trains a neural network on Age of Empires II, proves the game is functionally and Turing complete, and concludes that anthropomorphic attributes are empirically non-unique because any sufficiently powerful substrate could present them. The proposal of a 'null' assumption of non-uniqueness is offered as a methodological alternative to assumptions of existence or non-existence. No load-bearing step reduces by construction to its inputs; there are no equations, fitted parameters renamed as predictions, self-citations, or self-definitional loops. The central claim rests on logical possibility of substrate dependence and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Anthropomorphic attributes can be identified in behavioral outputs without substrate-specific measurement criteria
Forward citations
Cited by 1 Pith paper
-
Age of LLM: A Strategic 1v1 Benchmark for Reasoning, Diplomacy and Reliability of Large Language Models under Fog of War
Introduces Age of LLM benchmark pitting LLMs in a 13x7 grid game with fog of war, diplomacy, and JSON reliability constraints, reporting nuclear rush dominance in 54 matches and a weak reliability-win link.
Reference graph
Works this paper leans on
-
[1]
How Value Induction Reshapes LLM Behaviour
URLhttps://arxiv.org/abs/2605.07925. Z. Ben-Zion, K. Witte, A. K. Jagadish, O. Duek, I. Harpaz-Rotem, M.-C. Khorsandian, A. Burrer, E. Seifritz, P. Homan, E. Schulz, and T. R. Spiller. Assessing and alleviating state anxiety in large language models.npj Digital Medicine, 8, 2025. J. Betley, X. Bao, M. Soto, A. Sztyber-Betley, J. Chua, and O. Evans. Tell m...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/bf00413692 2025
-
[2]
doi: 10.1007/s11023-018-9474-5. C. Duffy. Parents of 16-year-old sue OpenAI, claiming ChatGPT advised on his suicide,
-
[3]
URL https://www.cnn.com/2025/08/26/tech/openai-chatgpt-teen- suicide-lawsuit. P. Duhem.The Aim and Structure of Physical Theory. Princeton University Press, 1982. ISBN 9780691079059. URLhttp://www.jstor.org/stable/j.ctv1nj34vm. B. V . Eckhardt. Connectionism and the propositional attitudes. In D. M. Johnson and C. E. Erneling, editors,The Mind As a Scient...
-
[4]
doi: 10.1080/106351599260247. W. S. McCulloch and W. Pitts. A logical calculus of the ideas immanent in nervous activity.The Bulletin of Mathematical Biophysics, 5:115–133, 1943. doi: 10.1007/BF02478259. D. McDermott. Artificial intelligence meets natural stupidity.SIGART Bull., (57):4–9, Apr. 1976. ISSN 0163-5719. doi: 10 .1145/1045339.1045340. URL https...
-
[5]
URL https://proceedings.neurips.cc/paper_files/paper/2024/ file/ca9567d8ef6b2ea2da0d7eed57b933ee-Paper-Conference.pdf. G. Piccinini.Physical Computation: A Mechanistic Account. Oxford University Press UK, Oxford, GB, 2015. A. Placani. Anthropomorphism in AI: hype and fallacy.AI and Ethics, 4, 2024. Politifact. The 50 largest cities in the United States, 2...
-
[6]
doi: https://doi .org/10.1016/S0304-3975(96)00077-1
ISSN 0304-3975. doi: https://doi .org/10.1016/S0304-3975(96)00077-1. URL https: //www.sciencedirect.com/science/article/pii/S0304397596000771. F. Rosenblatt. The perceptron: A perceiving and recognizing automaton. Technical Report 85-460-1, Cornell Aeronautical Laboratory, 1957. F. Rosenblatt. The perceptron: A probabilistic model for information storage ...
-
[7]
URLhttps://openreview.net/forum?id=aY9TAAQuFD. S. Shen, F. Jiang, P. Wang, Y . Feng, Y . Jiang, and C. Liu. Do LLMs know and understand domain conceptual knowledge? In C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 5967–5976, Suzhou, China, Nov. 2025. Asso...
-
[8]
URL https://www.brusselstimes.com/430098/belgian-man-commits- suicide-following-exchanges-with-chatgpt. N. Weinberger and C. Allen. Static-dynamic hybridity in dynamical models of cognition.Philosophy of Science, 89(2):283–301, 2022. doi: 10.1017/psa.2021.27. J. Weizenbaum.Computer Power and Human Reason: From Judgment to Calculation. W H Freeman & Co, 19...
-
[9]
doi: https://doi .org/10.1016/j.chbah.2024.100072
ISSN 2949-8821. doi: https://doi .org/10.1016/j.chbah.2024.100072. URL https: //www.sciencedirect.com/science/article/pii/S294988212400032X. J. Woodward and L. Ross. 20th Century Theories of Scientific Explanation. In E. N. Zalta and U. Nodelman, editors,The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Winter 2025 ed...
-
[10]
doi: 10 .18653/v1/2023.findings-acl.551
Association for Computational Linguistics. doi: 10 .18653/v1/2023.findings-acl.551. URL https://aclanthology.org/2023.findings-acl.551/. T. Yu, S. Pan, C. Fan, S. Luo, Y . Jin, and B. Zhao. Can large language models exhibit cognitive and affective empathy as humans?Computers in Human Behavior: Artificial Humans, 6:100233,
2023
-
[11]
doi: https://doi .org/10.1016/j.chbah.2025.100233
ISSN 2949-8821. doi: https://doi .org/10.1016/j.chbah.2025.100233. URL https:// www.sciencedirect.com/science/article/pii/S2949882125001173. Y . Yuan, M. Su, and X. Li. What makes people say thanks to AI. In H. Degen and S. Ntoa, editors, Artificial Intelligence in HCI, pages 131–149, Cham, 2024. Springer Nature Switzerland. ISBN 978-3-031-60606-9. J. Zho...
-
[12]
Here we also count technical reports and benchmarks as long as they explicitly evaluate agentic workflows/LLMs
article: a scientific article, but not a book chapter, survey, or opinion piece (e.g., these with ‘Opinion’ in the title). Here we also count technical reports and benchmarks as long as they explicitly evaluate agentic workflows/LLMs
-
[13]
survey: a review of the field
-
[14]
Broadly, any text without a clear contribution and/or scientific rigour
book: a textbook, book chapter, how-to guide, or opinion piece. Broadly, any text without a clear contribution and/or scientific rigour
-
[15]
This could be, for example, a text describing a codebase supporting workflows
platform: a scientific article where an agentic workflow or LLM is NOT being evaluated. This could be, for example, a text describing a codebase supporting workflows. Additionally, I’d like you to tell me if an LLM/agentic workflow is the centre of study: - ‘llm_is_central’: whether an LLM or LLM-powered agentic workflow is the central object of study: 1 ...
-
[16]
0 if it didn’t, 1 if it did
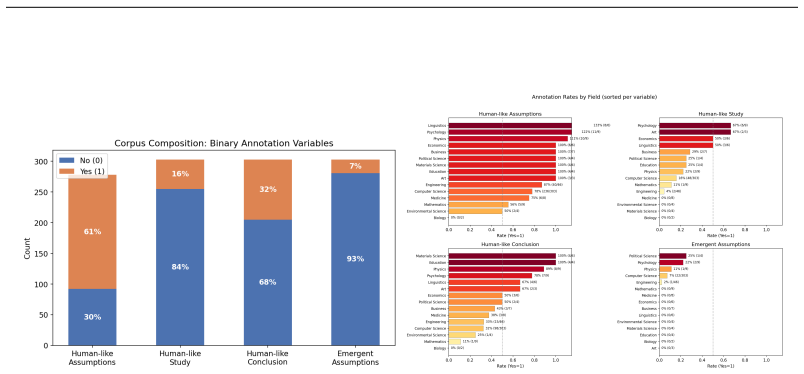
human_like_assumptions: whether the paper assumed or attributed human-like attributes to the LLM or LLM-powered agentic workflow _except_ in the conclusion. 0 if it didn’t, 1 if it did
-
[17]
0 if it doesn’t, 1 if it did
human_like_study: whether the paper central study is human-like attributes in LLMs or LLM- powered agentic workflow. 0 if it doesn’t, 1 if it did
-
[18]
This must be 1 if there is _at least_ some part of the conclusion indicating this, and only 0 if they don’t present them at all
human_like_conclusion: whether the paper concludes that the LLM or LLM-powered agentic workflows have human-like attributes. This must be 1 if there is _at least_ some part of the conclusion indicating this, and only 0 if they don’t present them at all. 0 if it didn’t, 1 if it did
-
[19]
0 if it doesn’t, 1 if it does
emergent_assumptions: whether the paper assumes that these human-like attributes (in either the assumptions or the conclusion) are emergent, and not product of (say) training or memorisation. 0 if it doesn’t, 1 if it does
-
[20]
A few notes: - By ‘human-like attributes’ we mean various aspect of human cognition and behaviour, as well as those of general intelligence
which_ones: a list of which emergent properties are being assumed in the work. A few notes: - By ‘human-like attributes’ we mean various aspect of human cognition and behaviour, as well as those of general intelligence. Here are some examples (but not the only ones!): - Cooperation - Empathy - Emotions (anxiety, happiness, anger, etc.) - Deceit - Values, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.