When Jokes Cross the Line: Analyzing Regular Humor and Dark Humor in YouTube Shorts
Pith reviewed 2026-07-01 07:35 UTC · model grok-4.3
The pith
Dark humor in YouTube Shorts clusters around critique, coping, awkwardness, and identity rather than forming one uniform category, and draws more mixed or toxic comments than regular humor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
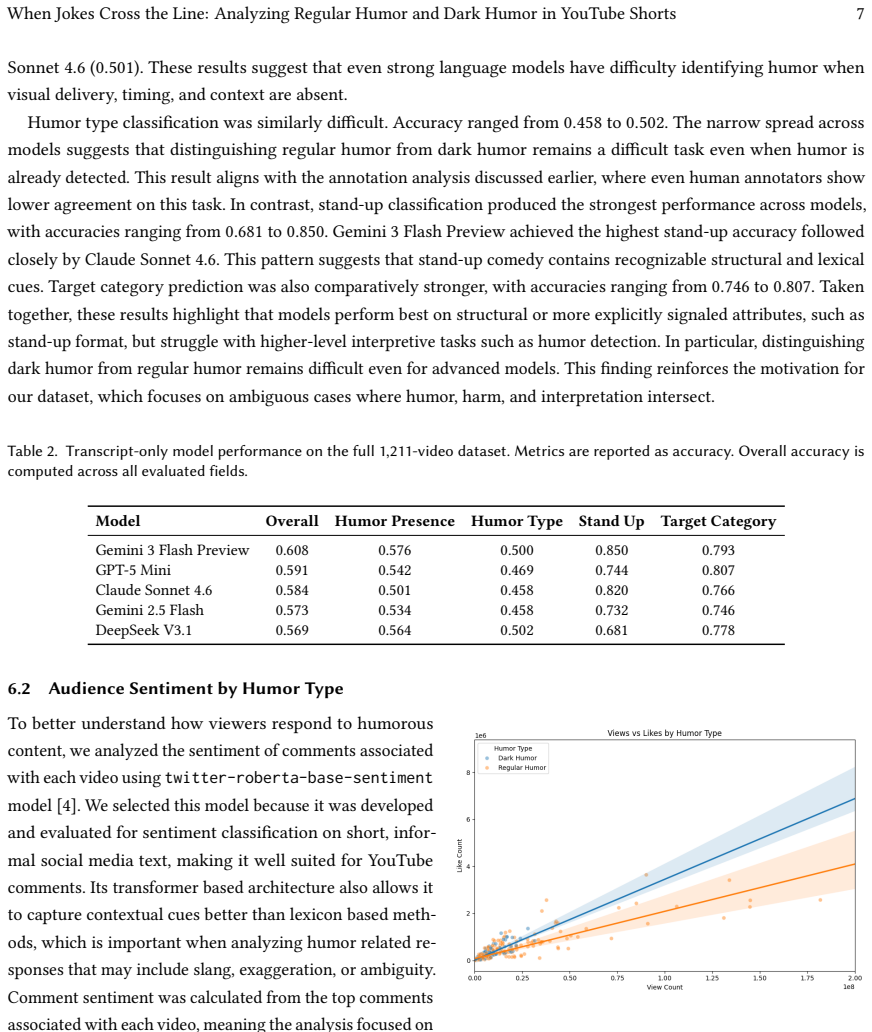
The authors establish through LLooM concept induction on video descriptions that dark humor frequently clusters around themes of critique, coping, awkwardness, and identity expression rather than appearing as a single uniform category. They further show via linked comments that regular humor is associated with more positive sentiment while dark humor receives more mixed, neutral, and sometimes more toxic reactions. Large language models match human annotations better on stand-up comedy than on shorter jokes.
What carries the argument
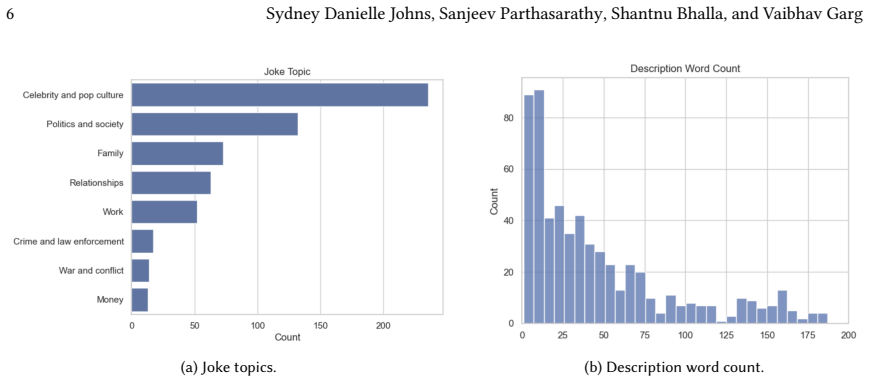
The TwistedHumor dataset of 1,211 hand-annotated YouTube Shorts paired with 33,041 comments, combined with LLooM-based concept induction applied to video descriptions to identify dark humor theme clusters.
If this is right
- Context-aware moderation is needed for short-form video rather than uniform rules based on humor type alone.
- Audience comment patterns differ by humor category, informing platform policies on content that remains allowed but carries mixed effects.
- Large language models require improvement for robust multimodal evaluation of humor and harm in brief video formats.
- The dataset provides a benchmark for testing detection of the gray area between humor and harm.
Where Pith is reading between the lines
- Detection systems may need separate handling for each dark humor cluster rather than treating dark humor as one category.
- The observed comment reaction patterns could be checked on other short-video platforms to test whether they hold beyond YouTube.
- Harm potential may track more closely with specific themes like critique or identity than with the presence of dark elements in general.
Load-bearing premise
The hand annotations classifying the 1,211 videos for humor presence, humor type, harm, topic, rhetorical devices, and stand-up context are accurate, consistent, and free of systematic bias.
What would settle it
Re-annotating the videos or re-running concept induction to show that dark humor themes are uniformly distributed without distinct clusters, or that comment sentiment shows no systematic difference by humor type, would falsify the central claims.
Figures


read the original abstract
Video platforms such as YouTube have reshaped how users engage with entertainment and information, emphasizing brief, highly engaging content such as Shorts. Within this ecosystem, certain content occupies a gray area where it remains allowed but may still have unintended negative effects on some audiences. To study this problem, we introduce TwistedHumor, a dataset of 1,211 YouTube Shorts paired with 33,041 related comments, with hand annotations for humor presence, humor type, harm, topic, rhetorical devices, and stand up context. Beyond dataset creation, we present a multi view analysis of how humor and harm appear in short form social media. Using LLooM based concept induction over video descriptions, we find that dark humor frequently clusters around themes of critique, coping, awkwardness, and identity expression rather than appearing as a single uniform category. We further analyze audience response through linked comments and show that regular humor is associated with more positive sentiment, while dark humor receives more mixed, neutral, and sometimes more toxic reactions. Finally, we evaluate large language models against human annotations and find that they perform better on stand up comedy compared to shorter jokes. Together, these results position TwistedHumor not only as a new benchmark, but as an empirical study of the gray area between humor and harm in short form video, highlighting the need for context aware moderation and more robust multimodal evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the TwistedHumor dataset of 1,211 annotated YouTube Shorts and 33,041 linked comments, with hand labels for humor presence, type (regular vs. dark), harm, topic, rhetorical devices, and stand-up context. It applies LLooM concept induction to video descriptions to identify thematic clusters in dark humor (critique, coping, awkwardness, identity expression) and performs sentiment/toxicity analysis on comments, finding regular humor linked to more positive responses while dark humor shows mixed/neutral/toxic patterns. It also benchmarks LLMs against the human annotations, with better performance on stand-up comedy than short jokes.
Significance. If the annotations prove reliable, the work supplies a new multimodal benchmark for short-form humor analysis and supplies concrete empirical distinctions between regular and dark humor in themes and audience reactions. The LLooM-based theme induction and linked-comment sentiment analysis are strengths that could support context-aware moderation research.
major comments (1)
- [Dataset section] Dataset section (hand-annotation protocol): No inter-annotator agreement figures, annotation guidelines, or bias-audit results are supplied for the labels on humor type, harm, topic, rhetorical devices, or stand-up context. Because the regular/dark partition directly drives the LLooM clustering and the comment-sentiment/toxicity comparisons, the absence of these validation metrics renders the central claims dependent on unverified labels.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and recommendation for major revision. We address the single major comment below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: [Dataset section] Dataset section (hand-annotation protocol): No inter-annotator agreement figures, annotation guidelines, or bias-audit results are supplied for the labels on humor type, harm, topic, rhetorical devices, or stand-up context. Because the regular/dark partition directly drives the LLooM clustering and the comment-sentiment/toxicity comparisons, the absence of these validation metrics renders the central claims dependent on unverified labels.
Authors: We agree that the manuscript as submitted does not report inter-annotator agreement, the full annotation guidelines, or bias-audit results. This omission weakens the presentation of the dataset. In the revised version we will add a new subsection to the Dataset section that (1) reproduces the complete annotation guidelines provided to annotators for all label categories (humor presence, regular vs. dark type, harm, topic, rhetorical devices, and stand-up context), (2) reports inter-annotator agreement statistics (e.g., Fleiss’ kappa and raw agreement percentages) computed across the multiple annotators who labeled the 1,211 videos, and (3) summarizes any bias-audit procedures or discussions of potential annotator biases. These additions will directly support the reliability of the regular/dark partition used in the LLooM clustering and comment analyses. revision: yes
Circularity Check
No circularity: empirical analysis on newly collected data
full rationale
The paper introduces the TwistedHumor dataset of 1,211 videos with hand annotations for humor type and other attributes, then applies LLooM concept induction to video descriptions and sentiment analysis to linked comments. No equations, fitted parameters, or model predictions are described that could reduce to the inputs by construction. Central claims about theme clusters and audience reactions are derived directly from the new annotations and external tools rather than self-citations or prior fitted quantities. The derivation chain is self-contained as standard empirical work on fresh data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hand annotations for humor presence, type, harm, topic, rhetorical devices, and stand-up context are accurate and consistent
Reference graph
Works this paper leans on
-
[1]
Naima Samreen Ali, Sarvech Qadir, Ashwaq Alsoubai, Munmun De Choudhury, Afsaneh Razi, and Pamela J. Wisniewski. 2024. "I’m gonna KMS": From Imminent Risk to Youth Joking about Suicide and Self-Harm via Social Media. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24)(Honolulu, HI, USA). Association for Computing Machin...
-
[2]
I’m going to hell for laughing at this
Kimberley R. Allison, Kay Bussey, and Naomi Sweller. 2019. “I’m going to hell for laughing at this”: Norms, Humour, and the Neutralisation of Aggression in Online Communities.Proceedings of the ACM on Human-Computer Interaction (PACM-HCI)3, CSCW, Article 152 (2019), 25 pages. doi:10.1145/3359254
-
[3]
Khalid Alnajjar, Mika Hämäläinen, Jörg Tiedemann, Jorma Laaksonen, and Mikko Kurimo. 2022. When to Laugh and How Hard? A Multimodal Approach to Detecting Humor and its Intensity. arXiv:2211.01889 [cs.CL] doi:10.48550/arXiv.2211.01889
-
[4]
Francesco Barbieri, Jose Camacho-Collados, Luis Espinosa-Anke, and Leonardo Neves. 2020. TweetEval: Unified Benchmark and Comparative Evaluation for Tweet Classification. InFindings of the Association for Computational Linguistics: EMNLP 2020. Association for Computational Linguistics, Stroudsburg, PA, USA, 1644–1650
2020
-
[5]
Santiago Castro, Devamanyu Hazarika, Verónica Pérez-Rosas, Roger Zimmermann, Rada Mihalcea, and Soujanya Poria. 2019. Towards Multimodal Sarcasm Detection (An _Obviously_ Perfect Paper). doi:10.48550/arXiv.1906.01815 arXiv:1906.01815 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1906.01815 2019
-
[6]
Liuliu Chen, Jo Robinson, and Mike Conway. 2025. What Do You Meme? – Identifying Characteristics and User Perceptions of Suicide Memes in Social Media. InProceedings of the International AAAI Conference on Web and Social Media (ICWSM), Vol. 19. AAAI Press, 385–402. doi:10.1609/ icwsm.v19i1.35822
2025
-
[7]
Sonnenblick, Magdalayna Curry, Laura D’Adamo, Lindsay Young, Stuart Murray, and Kristina Lerman
Minh Duc Chu, Kshitij Pawar, Zihao He, Roxanna Sharifi, Ross M. Sonnenblick, Magdalayna Curry, Laura D’Adamo, Lindsay Young, Stuart Murray, and Kristina Lerman. 2026. BigTokDetect: A Clinically-Informed Vision–Language Modeling Framework for Detecting Pro-Bigorexia Videos on TikTok. InProceedings of the 19th Conference of the European Chapter of the Assoc...
-
[8]
Jacob Cohen. 1960. A Coefficient of Agreement for Nominal Scales.Educational and Psychological Measurement20, 1 (1960), 37–46
1960
-
[9]
Mithun Das, Rohit Raj, Punyajoy Saha, Binny Mathew, Manish Gupta, and Animesh Mukherjee. 2023. HateMM: A Multi-Modal Dataset for Hate Video Classification. doi:10.48550/arXiv.2305.03915 arXiv:2305.03915 [cs]
-
[10]
Dorottya Demszky, Dana Movshovitz-Attias, Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. 2020. GoEmotions: A Dataset of Fine-Grained Emotions. doi:10.48550/arXiv.2005.00547 arXiv:2005.00547 [cs]
-
[11]
Laura Hanu and Unitary team. 2020. Detoxify. GitHub. https://github.com/unitaryai/detoxify
2020
-
[12]
Jochen Hartmann. 2022. emotion-english-distilroberta-base. Hugging Face. https://huggingface.co/j-hartmann/emotion-english-distilroberta-base
2022
-
[13]
Md Kamrul Hasan, Wasifur Rahman, Amir Zadeh, Jianyuan Zhong, Md Iftekhar Tanveer, Louis-Philippe Morency, Mohammed, and Hoque. 2019. UR-FUNNY: A Multimodal Language Dataset for Understanding Humor. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Process...
-
[14]
Shagun Jhaver, Alice Qian Zhang, Quan Ze Chen, Nikhila Natarajan, Ruotong Wang, and Amy X. Zhang. 2023. Personalizing Content Moderation on Social Media: User Perspectives on Moderation Choices, Interface Design, and Labor.Proceedings of the ACM on Human-Computer Interaction (PACM-HCI)7, CSCW2, Article 289 (2023). doi:10.1145/3610080
-
[15]
Sai Kartheek Reddy Kasu, Mohammad Zia Ur Rehman, Shahid Shafi Dar, Rishi Bharat Junghare, Dhanvin Sanjay Namboodiri, and Nagendra Kumar
-
[16]
D-HUMOR: Dark Humor Understanding via Multimodal Open-ended Reasoning – A Benchmark Dataset and Method. doi:10.48550/arXiv. 2509.06771 arXiv:2509.06771 [cs]
work page internal anchor Pith review doi:10.48550/arxiv
-
[17]
Dayoon Ko, Sangho Lee, and Gunhee Kim. 2024. Can Language Models Laugh at YouTube Short-form Videos? doi:10.48550/arXiv.2310.14159 arXiv:2310.14159 [cs]
-
[18]
Klaus Krippendorff. 1970. Estimating the Reliability, Systematic Error and Random Error of Interval Data.Educational and Psychological Measurement 30, 1 (1970), 61–70
1970
-
[19]
Naveen Kumar. 2025. Latest YouTube Shorts Statistics 2026 (Users & Demographics). https://www.demandsage.com/youtube-shorts-statistics/
2025
-
[20]
Michelle S. Lam, Janice Teoh, James A. Landay, Jeffrey Heer, and Michael S. Bernstein. 2024. Concept Induction: Analyzing Unstructured Text with High-Level Concepts Using LLooM. InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24). ACM, New York, NY, USA, 1–28. doi:10.1145/3613904.3642830
-
[21]
Chen Ling, Jeremy Blackburn, Emiliano De Cristofaro, and Gianluca Stringhini. 2022. Slapping Cats, Bopping Heads, and Oreo Shakes: Understanding Indicators of Virality in TikTok Short Videos. InProceedings of the 14th ACM Web Science Conference (WebSci ’22). Association for Computing Machinery (ACM), 164–173. doi:10.1145/3501247.3531551
- [22]
-
[23]
Binny Mathew, Punyajoy Saha, Seid Muhie Yimam, Chris Biemann, Pawan Goyal, and Animesh Mukherjee. 2022. HateXplain: A Benchmark Dataset for Explainable Hate Speech Detection. doi:10.48550/arXiv.2012.10289 arXiv:2012.10289 [cs]
-
[24]
Ashlee Milton, Leah Ajmani, Michael Ann DeVito, and Stevie Chancellor. 2023. “I See Me Here”: Mental Health Content, Community, and Algorithmic Curation on TikTok. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Manuscript submitted to ACM When Jokes Cross the Line: Analyzing Regular Humo...
-
[25]
Angela Molem, Stephann Makri, and Dana McKay. 2024. Keepin’ it Reel: Investigating how Short Videos on TikTok and Instagram Reels Influence View Change. InProceedings of the 2024 ACM SIGIR Conference on Human Information Interaction and Retrieval (CHIIR ’24)(Sheffield, United Kingdom). Association for Computing Machinery (ACM), New York, NY, USA, 317–327....
-
[26]
Emanuele Moscato, Tiancheng Hu, Matthias Orlikowski, Paul Röttger, and Debora Nozza. 2025. Personalization up to a Point: Why Personalized Content Moderation Needs Boundaries, and How We Can Enforce Them. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Suzhou, Chi...
-
[27]
Viet Cuong Nguyen, Mini Jain, Abhijat Chauhan, Heather Jaime Soled, Santiago Alvarez Lesmes, Zihang Li, Michael L. Birnbaum, Sunny X. Tang, Srijan Kumar, and Munmun De Choudhury. 2025. Supporters and Skeptics: LLM-Based Analysis of Engagement with Mental Health (Mis)Information Content on Video-Sharing Platforms. InProceedings of the International AAAI Co...
-
[28]
Yuqi Niu, Dilara Keküllüoğlu, Weidong Qiu, and Nadin Kokciyan. 2026. Behind the Meme: Understanding User Experiences with Memes on Social Media. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems (CHI ’26). Association for Computing Machinery (ACM), New York, NY, USA, 1–29. doi:10.1145/3772318.3791588
-
[29]
Jeffrey Gottfried and Eugenie Park. 2025. Americans’ Social Media Use 2025. https://www.pewresearch.org/internet/2025/11/20/americans-social- media-use-2025/
2025
-
[30]
Shraman Pramanick, Dimitar Dimitrov, Rituparna Mukherjee, Shivam Sharma, Md Shad Akhtar, Preslav Nakov, and Tanmoy Chakraborty. 2021. Detecting Harmful Memes and Their Targets. doi:10.48550/arXiv.2110.00413 arXiv:2110.00413 [cs]
-
[31]
Yang Qian, Yinan Sun, Ali Kargarandehkordi, Parnian Azizian, Onur Cezmi Mutlu, Saimourya Surabhi, Pingyi Chen, Zain Jabbar, Dennis Paul Wall, and Peter Washington. 2024. Advancing Human Action Recognition with Foundation Models trained on Unlabeled Public Videos. doi:10.48550/ arXiv.2402.08875 arXiv:2402.08875 [cs]
-
[32]
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. 2022. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv:2212.04356 [eess.AS] https://arxiv.org/abs/2212.04356
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Anupama Ray, Shubham Mishra, Apoorva Nunna, and Pushpak Bhattacharyya. 2022. A Multimodal Corpus for Emotion Recognition in Sarcasm. doi:10.48550/arXiv.2206.02119 arXiv:2206.02119 [cs]
-
[34]
Fang, J., Jiang, H., Wang, K., Ma, Y ., Shi, J., Wang, X., He, X., and Chua, T
Mohammad Zia Ur Rehman, Anukriti Bhatnagar, Omkar Kabde, Shubhi Bansal, and Dr. Nagendra Kumar. 2025. ImpliHateVid: A Benchmark Dataset and Two-stage Contrastive Learning Framework for Implicit Hate Speech Detection in Videos. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for...
- [35]
- [36]
-
[37]
Supriyono Supriyono. 2024. Analyzing Audience Sentiments in Digital Comedy: A Study of YouTube Comments Using LSTM Models.Journal of Applied Data Sciences5, 4 (Dec. 2024), 1877–1889. doi:10.47738/jads.v5i4.393
-
[38]
TheFunniestStandUp. 2026. C O M E D Y | The Top 20 most followed stand-up comedians on social media!! 1: Ellen Degeneres (258 million) 2: Kevin Hart (253 million) 3: Joe Rogan... https://www.instagram.com/funnieststandup/p/DK9js_yRjk7/
2026
-
[39]
TheTopTens. 2026. Top 10 Best YouTube Comedians. https://www.thetoptens.com/youtube/best-youtube-comedians/
2026
-
[40]
2020-2025
Maxim Tkachenko, Mikhail Malyuk, Andrey Holmanyuk, and Nikolai Liubimov. 2020-2025. Label Studio: Data labeling software. https://github. com/HumanSignal/label-studio Open source software available from https://github.com/HumanSignal/label-studio
2020
-
[41]
Xiaoyu Tong, Zhi Zhang, Pia Sommerauer, Martha Lewis, and Ekaterina Shutova. 2026. Hummus: A Dataset of Humorous Multimodal Metaphor Use. doi:10.48550/arXiv.2504.02983 arXiv:2504.02983 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.02983 2026
-
[42]
Tubics. 2026. Top 30 Comedy Channels YouTube Channels 2026 | YouTube Statistics | tubics. https://www.tubics.com/rankings/industries/comedy- channels
2026
-
[43]
Caroline Violot, Tuğrulcan Elmas, Igor Bilogrevic, and Mathias Humbert. 2024. Shorts vs. Regular Videos on YouTube: A Comparative Analysis of User Engagement and Content Creation Trends. InACM Web Science Conference. ACM, Stuttgart Germany, 213–223. doi:10.1145/3614419.3644023
-
[44]
Han Wang, Tan Rui Yang, Usman Naseem, and Roy Ka-Wei Lee. 2024. MultiHateClip: A Multilingual Benchmark Dataset for Hateful Video Detection on YouTube and Bilibili. InProceedings of the 32nd ACM International Conference on Multimedia. ACM, New York, NY, USA, 7493–7502. doi:10.1145/3664647.3681521 arXiv:2408.03468 [cs]
-
[45]
Cai Yang, Sepehr Mousavi, Abhisek Dash, Krishna P. Gummadi, and Ingmar Weber. 2025. Studying Behavioral Addiction by Combining Surveys and Digital Traces: A Case Study of TikTok. InProceedings of the International AAAI Conference on Web and Social Media (ICWSM), Vol. 19. AAAI Press, 2106–2123. doi:10.1609/icwsm.v19i1.35922
- [46]
-
[47]
Savvas Zannettou, Olivia Nemes-Nemeth, Oshrat Ayalon, Angelica Goetzen, Krishna P. Gummadi, Elissa M. Redmiles, and Franziska Roesner. 2024. Analyzing User Engagement with TikTok’s Short Format Video Recommendations using Data Donations. InProceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machiner...
-
[48]
Haris Bin Zia, Ignacio Castro, and Gareth Tyson. 2021. Racist or Sexist Meme? Classifying Memes beyond Hateful. InProceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021). Association for Computational Linguistics, Online, 215–219. doi:10.18653/v1/2021.woah-1.23
-
[49]
Malika Ziyada and Pakizar Shamoi. 2024. Video Popularity in Social Media: Impact of Emotions, Raw Features and Viewer Comments. arXiv:2407.16272 [cs.HC] doi:10.48550/arXiv.2407.16272 Manuscript submitted to ACM
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.