From Demonstrations to Rewards: Test-Time Prompt Optimization for VLM Reward Models
Pith reviewed 2026-06-30 15:22 UTC · model grok-4.3
The pith
Test-time optimization of VLM language instructions on a few demonstrations produces more accurate reward signals for robotic reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
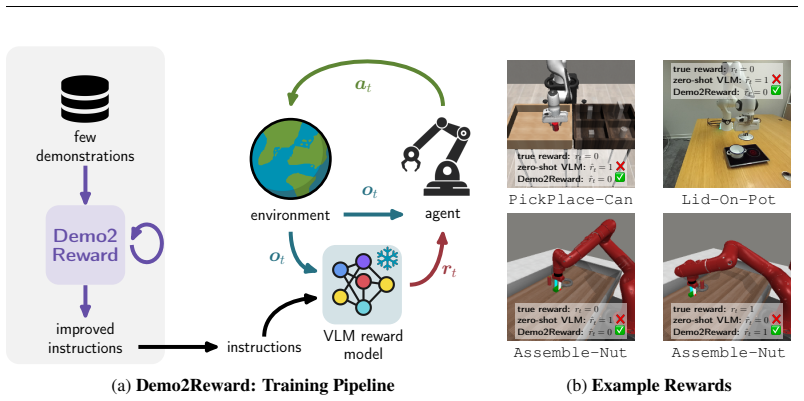
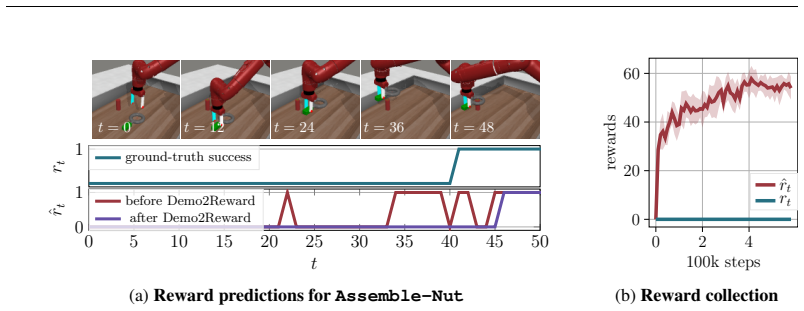
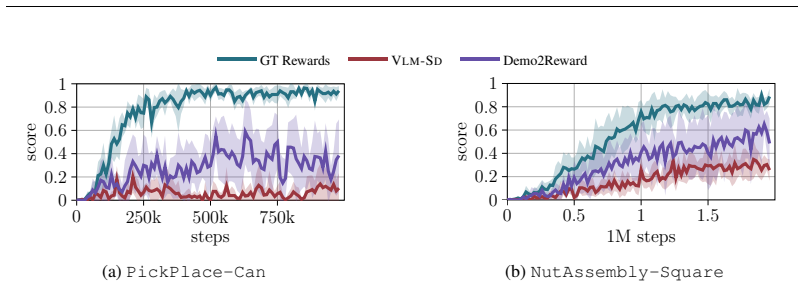
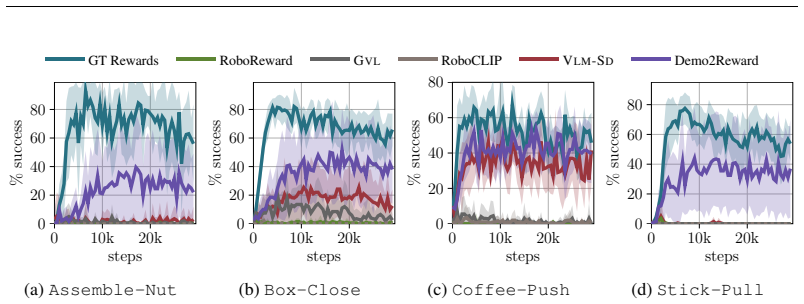
Demo2Reward is a test-time adaptation technique to optimize the language instruction of a reward model based on a few demonstrations (3-10 trajectories) to reduce false positives while preserving true positives. Crucially, this requires no additional model training or computation resources during policy learning. We show that Demo2Reward consistently outperforms existing zero- and few-shot VLM reward models across a range of simulated robotic tasks and policy backbones. Finally, we demonstrate that Demo2Reward effectively transfers to a real-world robotic learning scenario, enabling policy learning without manually engineering a reward function.
What carries the argument
Demo2Reward, the test-time procedure that refines the language instruction supplied to the VLM reward model by using a small set of demonstration trajectories.
If this is right
- Policies learned with Demo2Reward rewards reach higher task success rates than those using standard zero-shot or few-shot VLM rewards across simulated robotic environments.
- The same optimized rewards support successful policy learning on a physical robot without any manually specified reward function.
- The method applies to multiple policy architectures without requiring changes to the underlying reinforcement learning algorithm.
- No additional model training or extra computation occurs during the policy optimization phase itself.
Where Pith is reading between the lines
- The same demonstration-driven prompt refinement could be applied to other VLM-driven systems that produce sequential decisions, such as visual navigation or manipulation planners.
- If the optimization step proves cheap enough, it could be repeated periodically as new trajectories are collected during training.
- The approach raises the possibility that small demonstration sets can serve as a lightweight regularizer for any VLM used in decision-making loops.
Load-bearing premise
That refining the language instruction on three to ten demonstration trajectories will reduce false positives on new states and actions without the refined instruction becoming overly specific to the demonstrations themselves.
What would settle it
If policies trained with the optimized rewards achieve no higher success rates than policies trained with the original unoptimized VLM prompts on the same tasks and backbones, or if false-positive rates remain unchanged on held-out trajectories after optimization.
Figures


read the original abstract
Reinforcement learning relies on accurate reward functions, which are often hand-crafted or even unavailable in real-world applications, such as robotics. Recent work has explored the zero-shot reasoning capabilities of pre-trained Vision-Language Models (VLMs) as reward models. However, without careful prompt engineering, these approaches tend to produce suboptimal rewards, where false positive predictions can severely degrade downstream policy learning. In robotics, limited datasets comprising expert demonstrations are often collected to bootstrap policy learning. This scenario provides an opportunity to optimize a reward model prior policy training. We propose Demo2Reward a test-time adaptation technique to optimize the language instruction of a reward model based on a few demonstrations (3-10 trajectories) to reduce false positives while preserving true positives. Crucially, this requires no additional model training or computation resources during policy learning. We show that Demo2Reward consistently outperforms existing zero- and few-shot VLM reward models across a range of simulated robotic tasks and policy backbones. Finally, we demonstrate that Demo2Reward effectively transfers to a real-world robotic learning scenario, enabling policy learning without manually engineering a reward function.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Demo2Reward, a test-time adaptation method that optimizes the language instruction prompt of a pre-trained VLM reward model using 3-10 expert demonstration trajectories. The goal is to reduce false-positive rewards while preserving true positives for downstream robotic RL, without any additional model training. The manuscript claims consistent outperformance versus existing zero-shot and few-shot VLM reward baselines across simulated robotic tasks and multiple policy backbones, plus successful transfer to a real-world robotic scenario that enables policy learning without hand-engineered rewards.
Significance. If the empirical claims hold with adequate controls, the work would be significant for robotic RL: it offers a practical, training-free way to adapt powerful VLMs into reward models using the small demonstration sets already collected for policy bootstrapping. This could lower the barrier to deploying VLM-based rewards in domains where manual reward design is difficult. The absence of extra compute during policy learning is a clear practical advantage.
major comments (2)
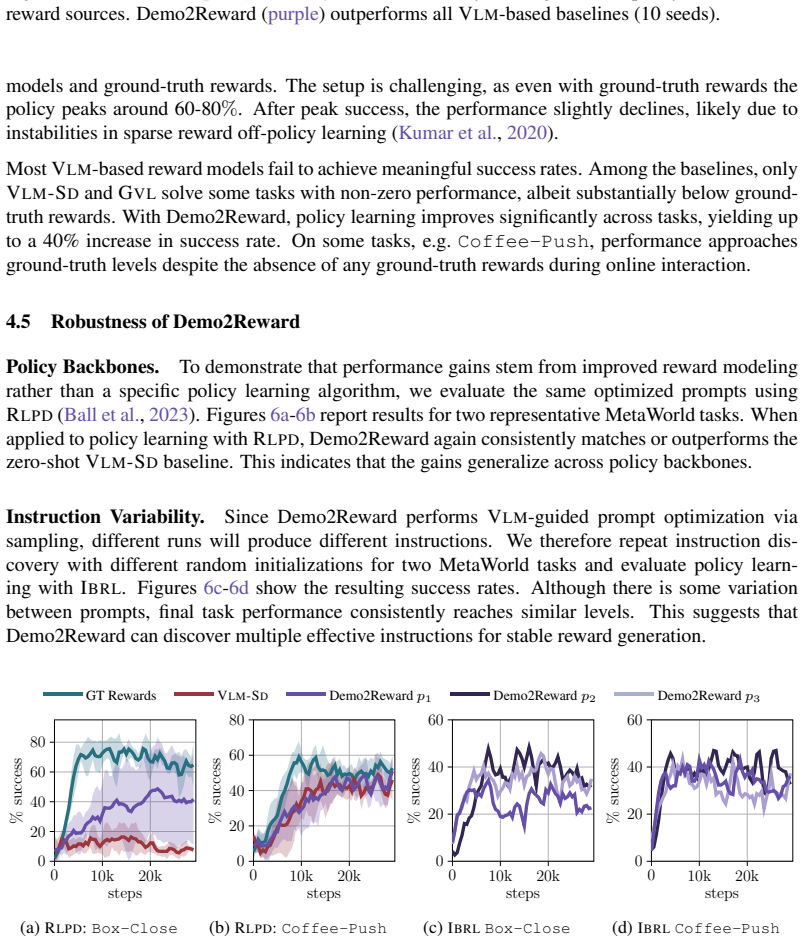
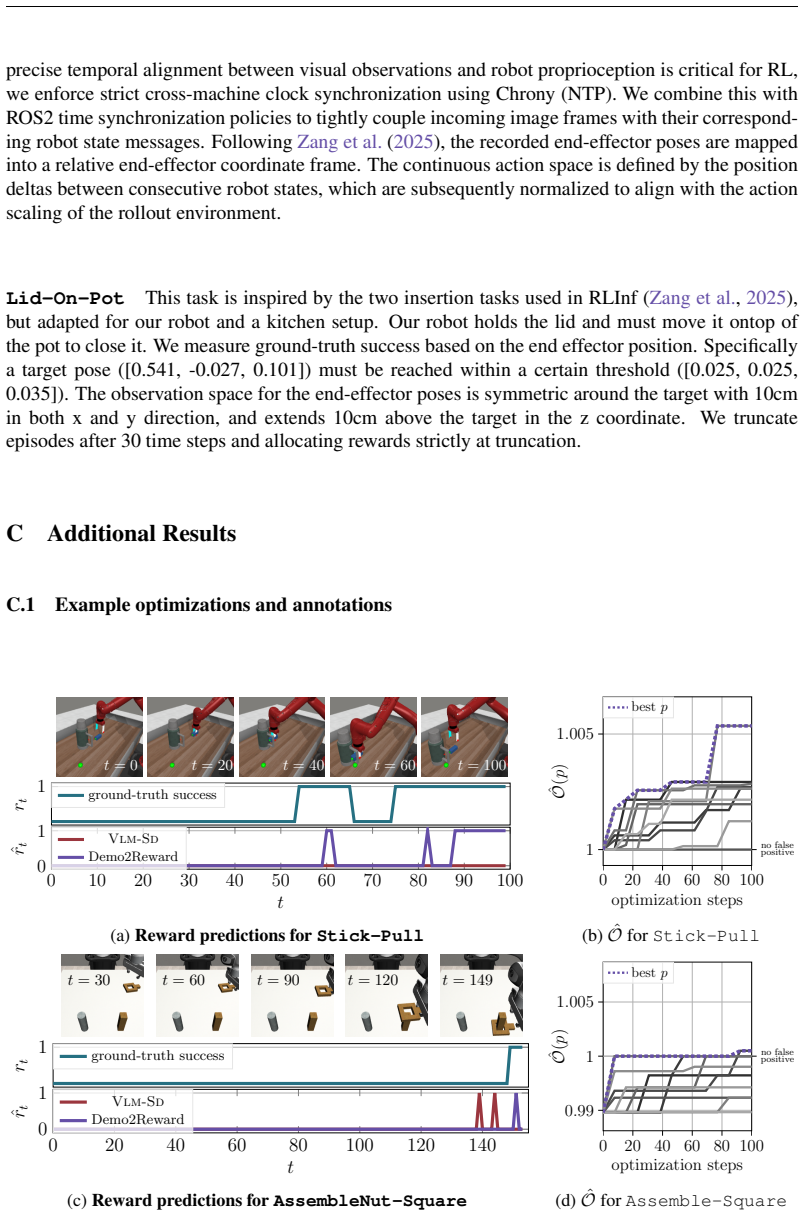
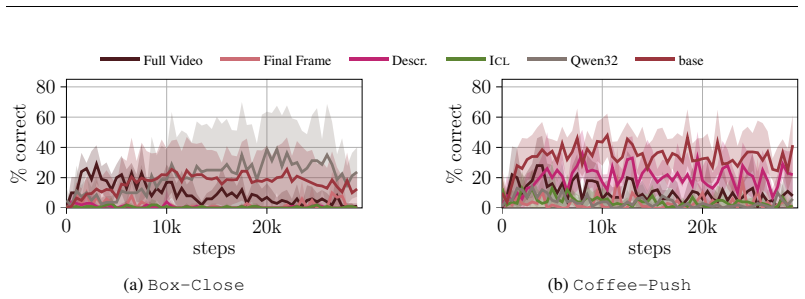
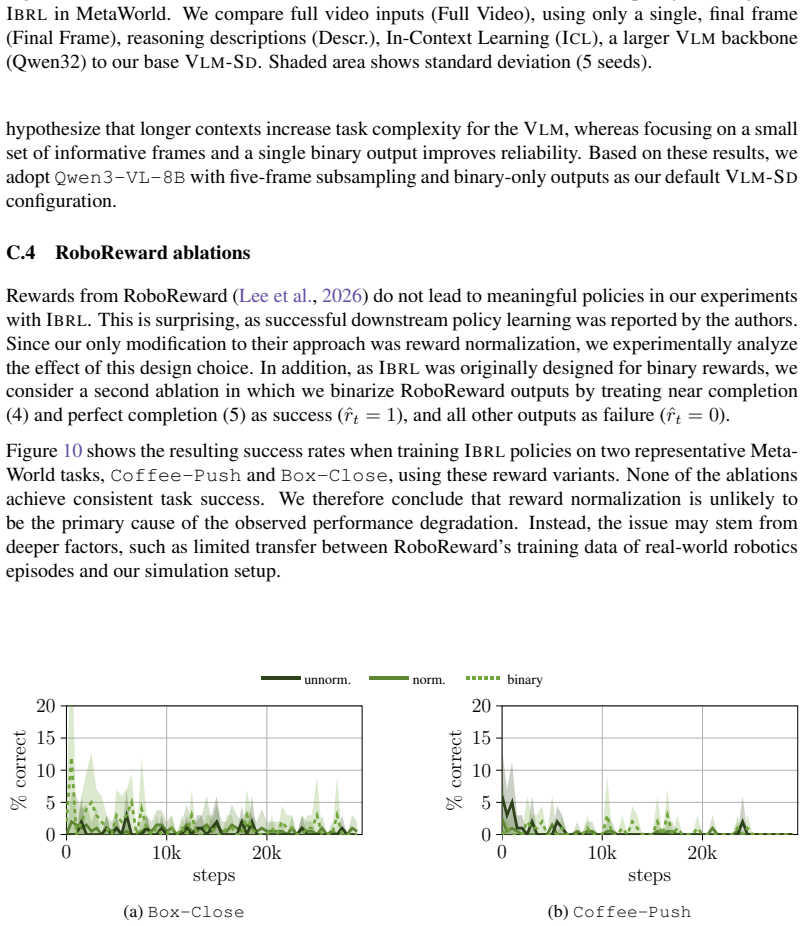
- [Abstract, §4] Abstract and §4 (Experiments): the central claim of 'consistent outperformance' and 'effective transfer' to real-world robotics is stated without any quantitative metrics, tables, error bars, or baseline implementation details visible in the abstract; the load-bearing empirical result therefore cannot be assessed for magnitude or statistical reliability from the provided summary.
- [§3, §4.2] §3 (Method) and §4.2 (Generalization analysis): the core assumption that prompt optimization on 3-10 trajectories will reliably lower false-positive rate on unseen states/actions without overfitting to demo-specific visual or kinematic regularities is load-bearing for all downstream claims, yet the manuscript provides no explicit test (e.g., false-positive rates on held-out negative samples drawn from a broader state distribution or ablation on prompt-search procedure) that would falsify this risk.
minor comments (2)
- [§3] Notation for the optimized prompt and the exact objective used during test-time search should be formalized with an equation or pseudocode for reproducibility.
- [§4] Figure captions and axis labels in the experimental plots should explicitly state the number of random seeds and whether shaded regions represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of empirical results and generalization analysis.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the central claim of 'consistent outperformance' and 'effective transfer' to real-world robotics is stated without any quantitative metrics, tables, error bars, or baseline implementation details visible in the abstract; the load-bearing empirical result therefore cannot be assessed for magnitude or statistical reliability from the provided summary.
Authors: We agree that the abstract would benefit from including key quantitative results. In the revision we will add specific metrics (e.g., mean success rates with standard deviations across tasks and baselines) and a brief reference to the tables in §4 so that the magnitude and reliability of the claimed improvements can be assessed directly from the abstract. revision: yes
-
Referee: [§3, §4.2] §3 (Method) and §4.2 (Generalization analysis): the core assumption that prompt optimization on 3-10 trajectories will reliably lower false-positive rate on unseen states/actions without overfitting to demo-specific visual or kinematic regularities is load-bearing for all downstream claims, yet the manuscript provides no explicit test (e.g., false-positive rates on held-out negative samples drawn from a broader state distribution or ablation on prompt-search procedure) that would falsify this risk.
Authors: Section 4.2 already evaluates policy learning on states and tasks outside the demonstration distribution and reports improved downstream performance, which provides indirect evidence against overfitting. Nevertheless, we acknowledge that an explicit false-positive-rate evaluation on held-out negatives and an ablation of the prompt-search procedure would make the claim more robust. We will add both analyses in the revised manuscript. revision: yes
Circularity Check
No circularity; empirical test-time adaptation without derivations or self-referential reductions
full rationale
The paper describes an empirical technique (Demo2Reward) for optimizing VLM prompts on 3-10 demonstration trajectories to improve reward signals. No equations, parameter fits, uniqueness theorems, or derivation chains appear in the abstract or method outline. Claims rest on reported outperformance across simulated tasks, policy backbones, and real-robot transfer, which are external benchmarks rather than reductions to the method's own inputs by construction. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Flamingo: a Visual Language Model for Few-Shot Learning
URLhttps://arxiv.org/abs/2204.14198. 10 Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Ta...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
DOI: 10.48550/arXiv.2503.14734. URLhttps://arxiv.org/ abs/2503.14734. Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learning from human preferences.Advances in neural information processing sys- tems, 30,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14734
-
[4]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team and Google. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
DOI: 10.48550/arXiv.2403.05530. URLhttps://arxiv.org/abs/2403.05530. Abhishek Gupta, Corey Lynch, Brandon Kinman, Garrett Peake, Sergey Levine, and Karol Haus- man. Demonstration-bootstrapped autonomous practicing via multi-task reinforcement learn- ing. In2023 IEEE International Conference on Robotics and Automation (ICRA), pp. 5020–
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.05530
-
[6]
DOI: 10.1109/ICRA48891.2023.10161447. URLhttps://doi.org/ 10.1109/ICRA48891.2023.10161447. Yaru Hao, Zewen Chi, Li Dong, and Furu Wei. Optimizing prompts for text-to-image generation. InThirty-seventh Conference on Neural Information Processing Systems,
-
[7]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.π 0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Tony Lee, Andrew Wagenmaker, Karl Pertsch, Percy Liang, Sergey Levine, and Chelsea Finn. Roboreward: General-purpose vision-language reward models for robotics.arXiv preprint arXiv:2601.00675,
-
[9]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A survey of automatic prompt engineering: An optimization perspective
Wenwu Li, Xiangfeng Wang, Wenhao Li, and Bo Jin. A survey of automatic prompt engineering: An optimization perspective.arXiv preprint arXiv:2502.11560,
-
[11]
OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DOI: 10.48550/arXiv. 2303.08774. URLhttps://arxiv.org/abs/2303.08774. Julian Quevedo, Ansh Kumar Sharma, Yixiang Sun, Varad Suryavanshi, Percy Liang, and Sherry Yang. Worldgym: World model as an environment for policy evaluation.arXiv preprint arXiv:2506.00613,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv
-
[13]
DOI: 10.15607/RSS.2018.XIV .049. URLhttps://www. roboticsproceedings.org/rss14/p49.html. Juan Rocamonde, Victoriano Montesinos, Elvis Nava, Ethan Perez, and David Lindner. Vision- language models are zero-shot reward models for reinforcement learning. InThe Twelfth Interna- tional Conference on Learning Representations,
-
[14]
Ansh Kumar Sharma, Yixiang Sun, Ninghao Lu, Yunzhe Zhang, Jiarao Liu, and Sherry Yang. World-gymnast: Training robots with reinforcement learning in a world model.arXiv preprint arXiv:2602.02454,
-
[15]
Huajie Tan, Sixiang Chen, Yijie Xu, Zixiao Wang, Yuheng Ji, Cheng Chi, Yaoxu Lyu, Zhongxia Zhao, Xiansheng Chen, Peterson Co, et al. Robo-dopamine: General process reward modeling for high-precision robotic manipulation.arXiv preprint arXiv:2512.23703,
-
[16]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
Mel Vecerik, Todd Hester, Jonathan Scholz, Fumin Wang, Olivier Pietquin, Bilal Piot, Nico- las Heess, Thomas Rothörl, Thomas Lampe, and Martin Riedmiller. Leveraging demonstra- tions for deep reinforcement learning on robotics problems with sparse rewards.arXiv preprint arXiv:1707.08817,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
URLhttps://arxiv. org/abs/2309.13037. Markus Wulfmeier, Peter Ondruska, and Ingmar Posner. Maximum entropy deep inverse reinforce- ment learning.arXiv preprint arXiv:1507.04888,
-
[19]
Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, and Tao Yu. Text2reward: Reward shaping with language models for reinforcement learning.arXiv preprint arXiv:2309.11489,
-
[20]
Icpl: Few-shot in-context preference learning via llms.arXiv preprint arXiv:2410.17233,
13 Chao Yu, Qixin Tan, Hong Lu, Jiaxuan Gao, Xinting Yang, Yu Wang, Yi Wu, and Eugene Vinitsky. Icpl: Few-shot in-context preference learning via llms.arXiv preprint arXiv:2410.17233,
-
[21]
Rlinf-vla: A unified and effi- cient framework for vla+ rl training,
Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training. arXiv preprint arXiv:2510.06710,
-
[22]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InThe Eleventh Interna- tional Conference on Learning Representations, 2023a. URLhttps://openreview.net/ forum?id=92gvk82DE-. Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, and Bin Liu. Large languag...
-
[23]
the Critic
14 Supplementary Materials The following content was not necessarily subject to peer review. A Implementation Details A.1 Demo2Reward A.1.1 Hyperparameters Hyperparameters are shown per suite, with shared hyperparameters displayed in the center. Name Value MetaWorld RoboMimic Real λ0.01 Optimization stepsI100 mcritic model Qwen3-8B-VL mmeta models Qwen3-8...
2025
-
[24]
on the HowTo100M dataset (Miech et al., 2019). However, in preliminary experiments we observed that the raw dot-product similarity used by RoboCLIP exhibits substantial variation in magnitude across successful demonstrations from the same tasks. The reward values differed by up to three orders of magnitude for different videos of the same MetaWorld task. ...
2019
-
[25]
and use their implemen- tation of IBRLand RLPD. We modify only one aspect: rewards are provided exclusively at the end of each episode, consistent with prior work on VLM-based reward models (Sontakke et al., 2023; Lee et al., 2026). In particular, we disable early episode termination and assign rewards at the end of truncated episodes. Disabling early ter...
2023
-
[26]
Data processingTo seamlessly interface our hardware setup with the RLInf training pipeline, we implemented a custom data-logging module tailored to match their expected data format
for teleoperation, using its native Franka controller and joint state publisher. Data processingTo seamlessly interface our hardware setup with the RLInf training pipeline, we implemented a custom data-logging module tailored to match their expected data format. Since 21 precise temporal alignment between visual observations and robot proprioception is cr...
2025
-
[27]
1" if the mug is visibly under the spout (any portion of the mug overlaps the spout’s projection); output
Ignore robot motion or intermediate positioning -- only evaluate whether the mug is located under the spout’s projection in the final frame. Coffee-Push-3 25 In the final frame, determine if the robot has completed the task by visually confirming that the white mug is positioned within the dispensing area of the red coffee machine -- meaning the mug must ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.