From Noise to Control: Parameterized Diffusion Policies
Pith reviewed 2026-06-28 22:04 UTC · model grok-4.3
The pith
Parameterized diffusion policies condition on a learned manifold to steer behaviors precisely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
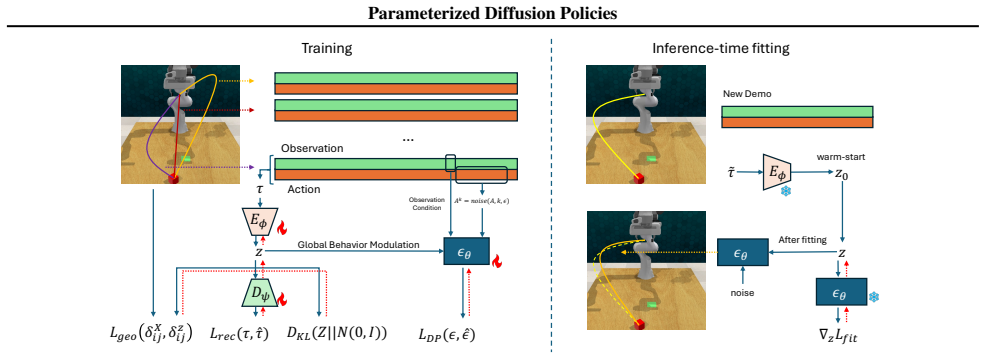
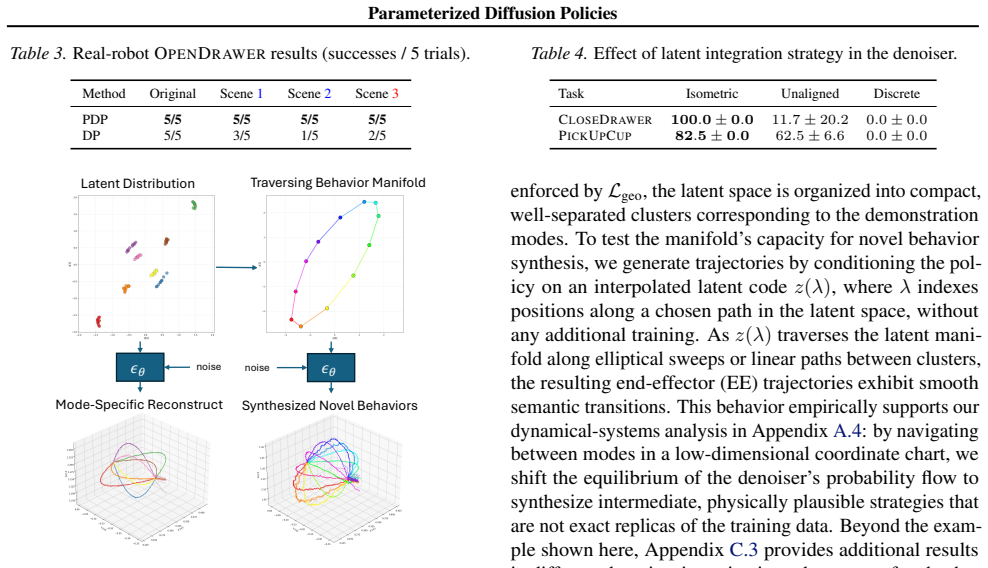
By constructing a manifold in which distances between latent representations reflect the semantic similarity between physical trajectories, diffusion policies can be made conditional on continuous parameters. This transforms the diffusion process from generating stochastic diversity into an optimizable mechanism for steering robot behaviors, enabling smooth interpolation between strategies and adaptation to novel constraints without updating policy weights.
What carries the argument
The learned behavior manifold, where latent distances encode trajectory semantic similarity, used to parameterize the diffusion policy.
Load-bearing premise
That it is possible to learn a low-dimensional manifold in which distances between points accurately reflect the semantic similarity of the corresponding physical trajectories.
What would settle it
Demonstrating that parameter adjustments produce behaviors whose similarities do not align with the manifold distances, or that PDP does not outperform standard diffusion policies in adaptation tasks on the reported benchmarks.
Figures



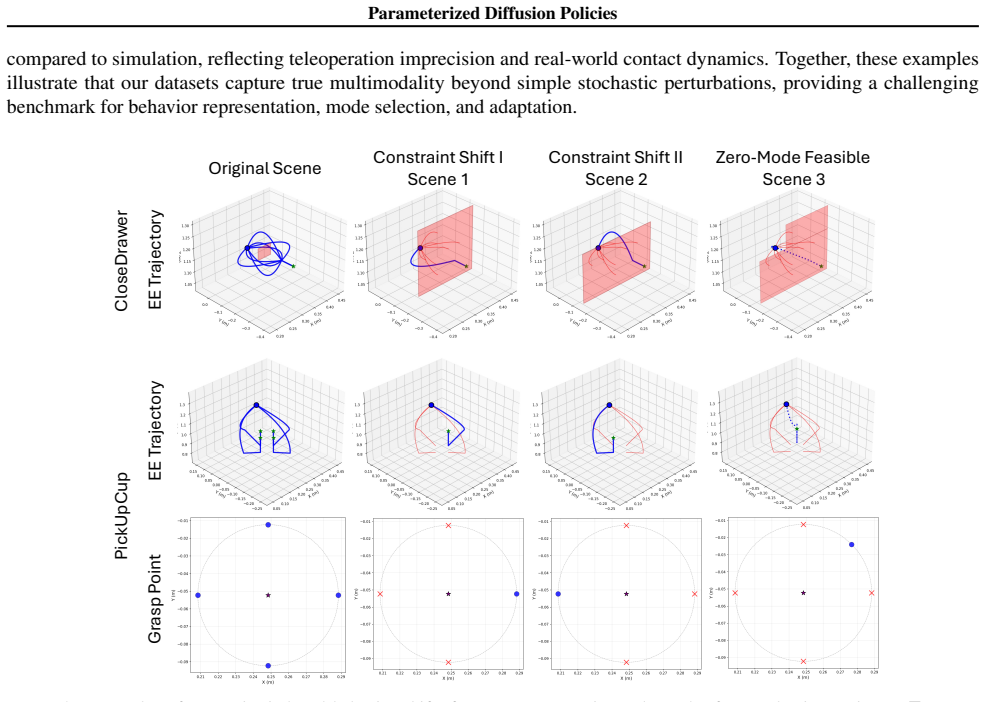

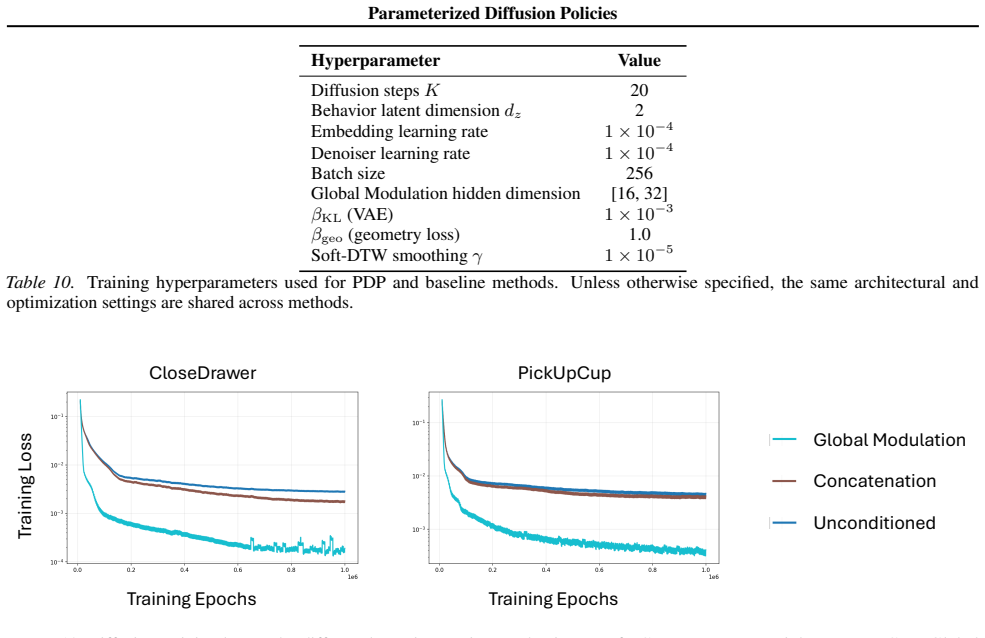
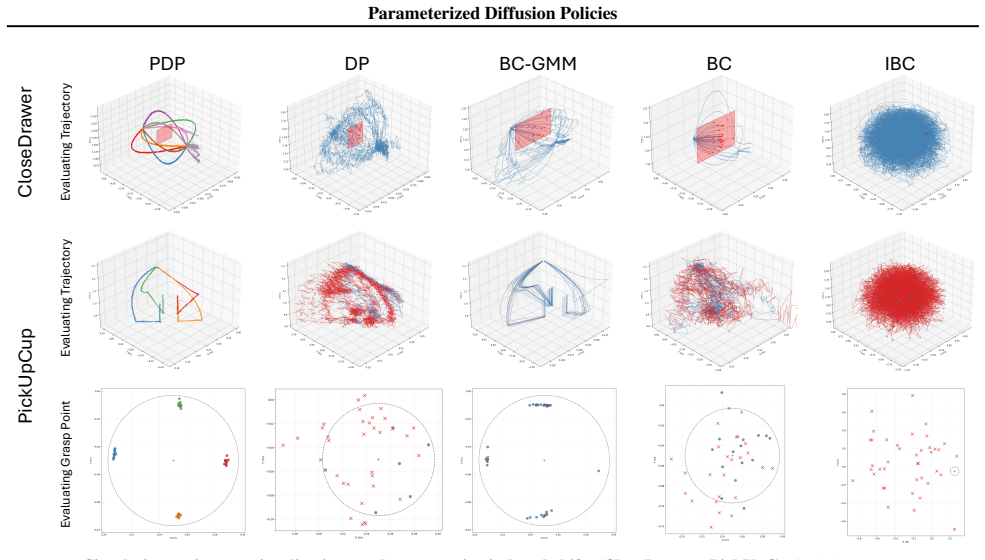
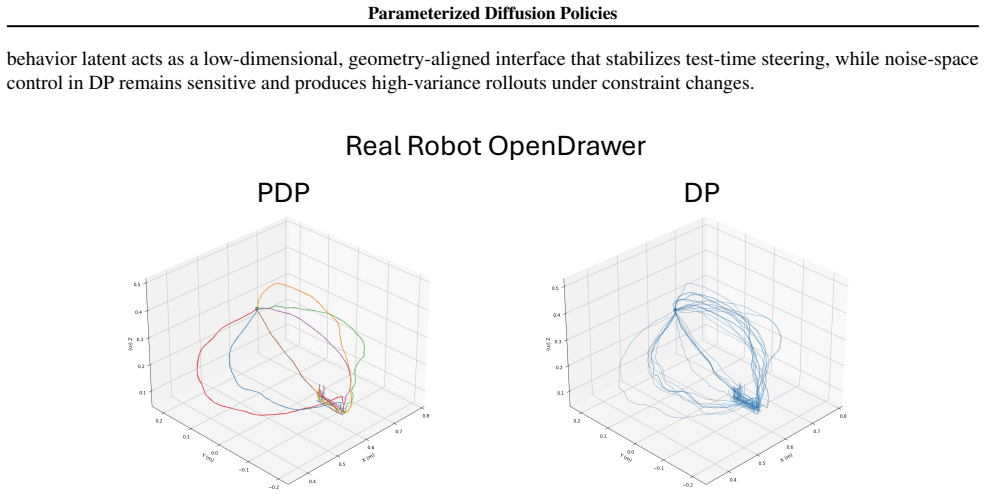
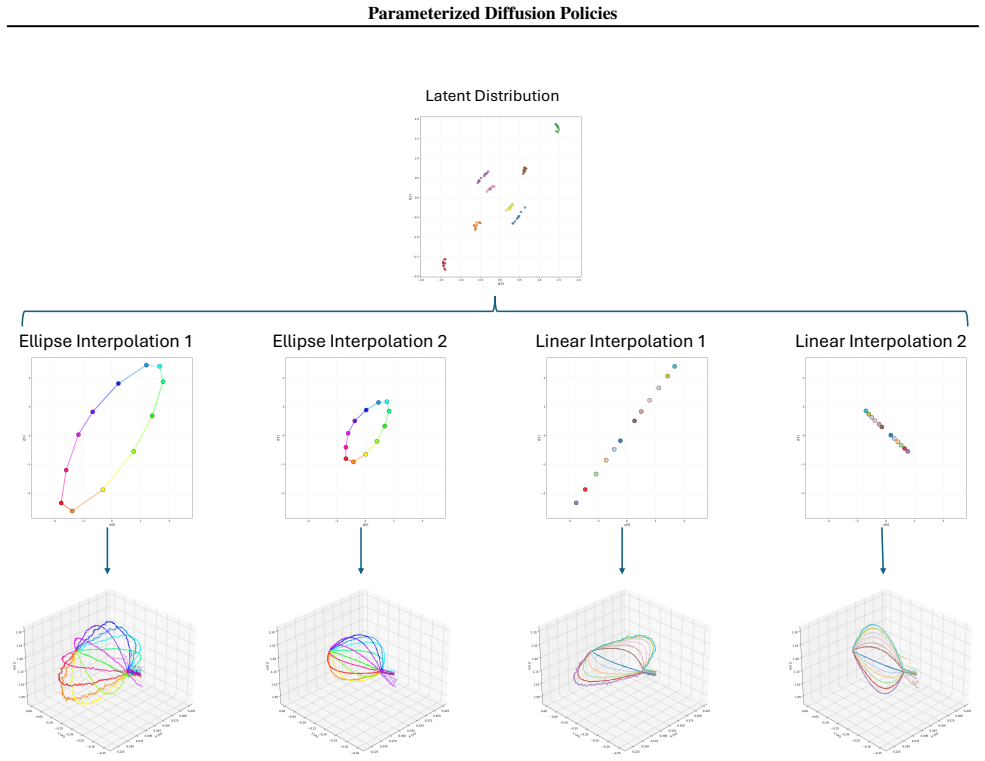
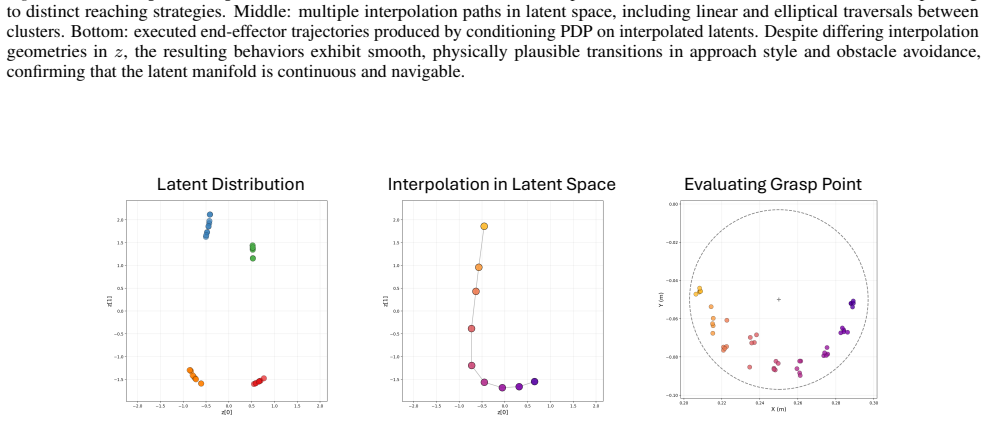
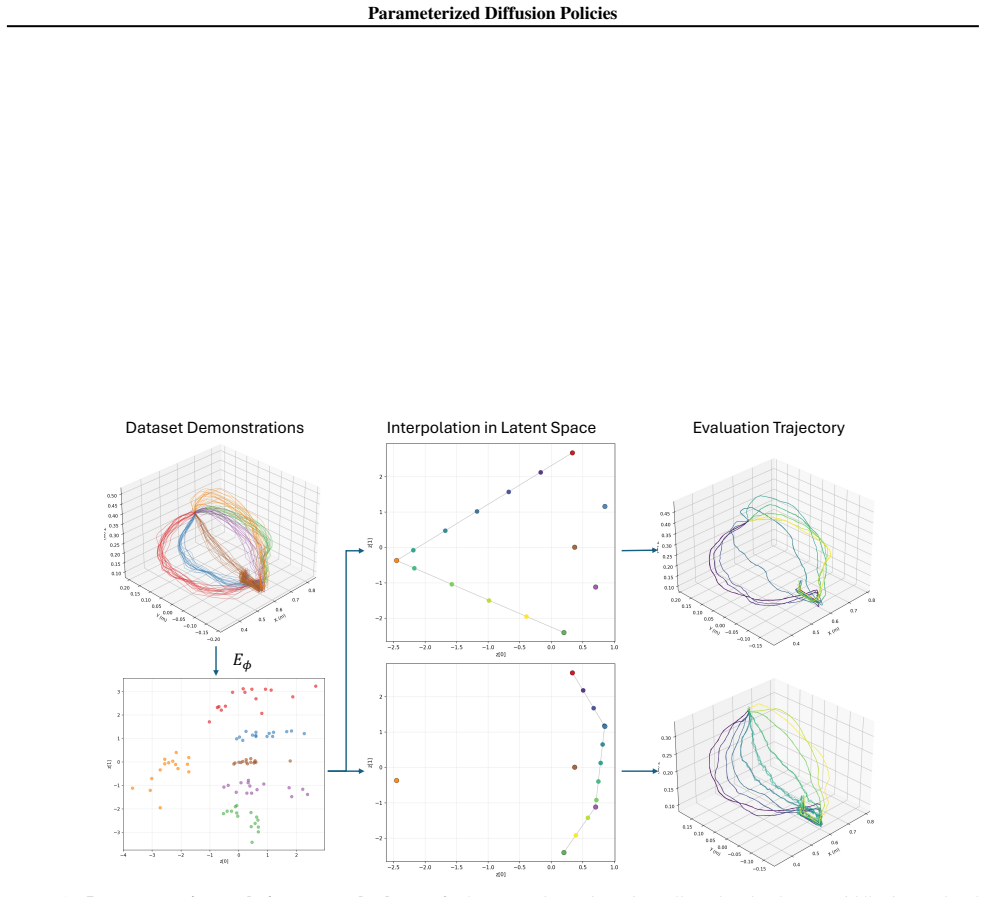
read the original abstract
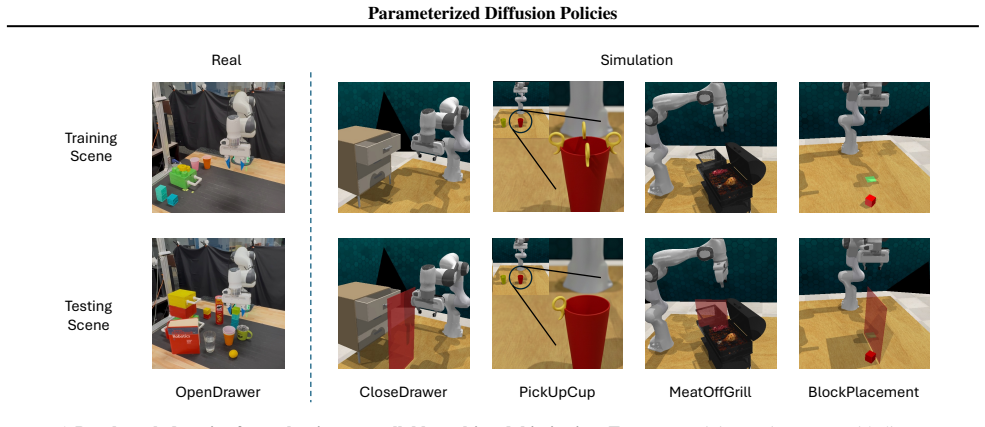
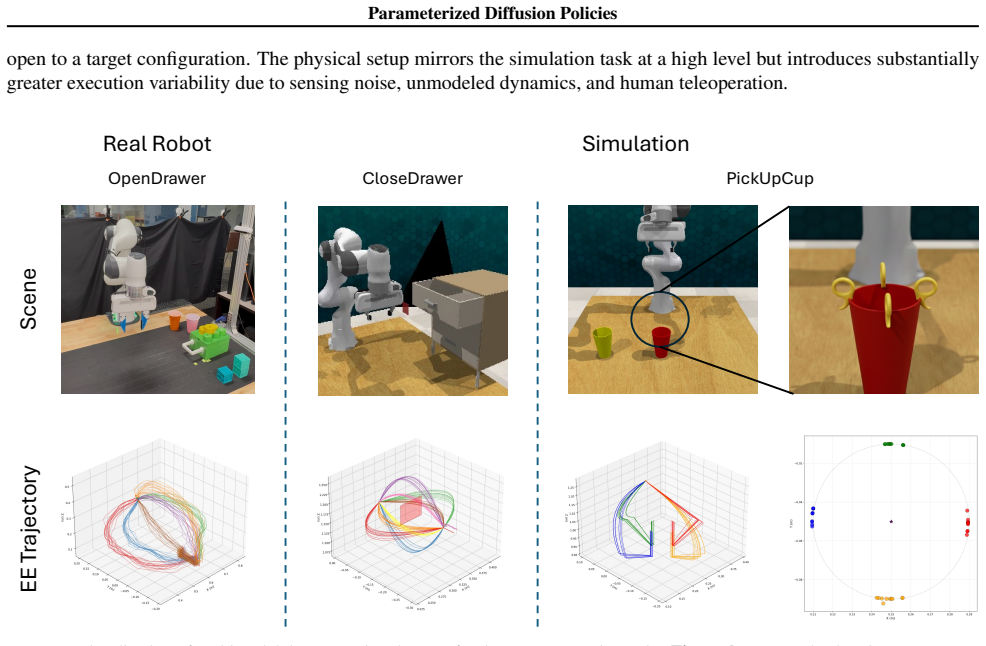
We propose Parameterized Diffusion Policy (PDP), a framework for learning diffusion policies conditioned on low-dimensional, continuous parameters embedded in a learned behavior manifold. By constructing this manifold so that distances between latent representations reflect the semantic similarity between physical trajectories, we transform diffusion from a mechanism for stochastic diversity into a precise and optimizable tool for behavior steering. Our approach enables smooth interpolation between known strategies and efficient adaptation to novel constraints without updating policy weights. We demonstrate that PDP significantly improves adaptation performance on complex multimodal benchmarks in both simulated and real-robot experiments compared to standard diffusion policies, particularly in scenarios requiring the synthesis of novel behaviors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Parameterized Diffusion Policy (PDP), a framework for learning diffusion policies conditioned on low-dimensional continuous parameters embedded in a learned behavior manifold. By constructing the manifold so that distances between latent representations reflect semantic similarity between physical trajectories, the approach aims to transform diffusion into a tool for precise behavior steering. This enables smooth interpolation between known strategies and efficient adaptation to novel constraints without updating policy weights. The authors claim that PDP significantly improves adaptation performance on complex multimodal benchmarks in both simulated and real-robot experiments compared to standard diffusion policies, particularly for synthesizing novel behaviors.
Significance. If the experimental claims are substantiated with proper controls and the manifold construction is shown to be non-circular, the work could meaningfully advance controllable diffusion policies in robotics by addressing adaptation without retraining. The core idea of embedding parameters in a semantically meaningful manifold has potential to improve generalization in multimodal settings.
major comments (2)
- [Abstract] Abstract: the claim of 'significant improvements' on multimodal benchmarks in simulation and real-robot experiments is unsupported because the text provides no details on baselines, metrics, statistical tests, data handling, or experimental protocol.
- [Abstract] Abstract: the central claim that the manifold enables 'smooth interpolation' and 'efficient adaptation' without weight updates cannot be evaluated, as the manuscript supplies no equations, algorithm, training procedure, or manifold construction details.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. The abstract is a concise summary, while the full manuscript provides the requested technical and experimental details in dedicated sections. We address each comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'significant improvements' on multimodal benchmarks in simulation and real-robot experiments is unsupported because the text provides no details on baselines, metrics, statistical tests, data handling, or experimental protocol.
Authors: The abstract summarizes key findings at a high level, as is standard. The full manuscript details the experimental protocol in Section 4, including baselines (standard diffusion policies and variants), metrics (success rate and adaptation efficiency), statistical tests (means and standard deviations over multiple random seeds), data handling procedures, and both simulated and real-robot setups. These substantiate the adaptation performance claims. revision: no
-
Referee: [Abstract] Abstract: the central claim that the manifold enables 'smooth interpolation' and 'efficient adaptation' without weight updates cannot be evaluated, as the manuscript supplies no equations, algorithm, training procedure, or manifold construction details.
Authors: Section 3 of the manuscript provides the complete technical description: equations for the behavior manifold embedding (ensuring distances reflect semantic trajectory similarity), the conditioning mechanism in the diffusion policy, the manifold construction procedure, the training objective, and Algorithm 1 for the overall method. These directly enable and support the claims of smooth interpolation and adaptation without policy weight updates. revision: no
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract and description introduce PDP via a learned behavior manifold whose distances are constructed to reflect semantic similarity between trajectories, enabling interpolation and adaptation without weight updates. No equations, self-citations, fitted parameters, or uniqueness theorems are supplied that would reduce any claimed prediction or result to an input quantity by construction. The manifold construction is presented as the novel mechanism rather than a renaming or redefinition of prior fitted values, and the central claims remain independent of any internal tautology. The paper is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- dimension of behavior manifold
invented entities (1)
-
behavior manifold
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training diffusion models with reinforcement learning
Black, K., Janner, M., Du, Y., Kostrikov, I., and Levine, S. Training diffusion models with reinforcement learning. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024
2024
-
[2]
On learning, representing, and generalizing a task in a humanoid robot
Calinon, S., Guenter, F., and Billard, A. On learning, representing, and generalizing a task in a humanoid robot. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 2007
2007
-
[3]
Playfusion: Skill acquisition via diffusion from language-annotated play
Chen, L., Bahl, S., and Pathak, D. Playfusion: Skill acquisition via diffusion from language-annotated play. In Proceedings of the Conference on Robot Learning (CoRL), 2023
2023
-
[4]
Diffusion policy: Visuomotor policy learning via action diffusion
Chi, C., Feng, S., Du, Y., Xu, Z., Cousineau, E., Burchfiel, B., and Song, S. Diffusion policy: Visuomotor policy learning via action diffusion. In Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[5]
C., Konidaris, G., and Barto, A
da Silva, B. C., Konidaris, G., and Barto, A. Learning parameterized skills. arXiv preprint arXiv:1206.6398, 2012
Pith/arXiv arXiv 2012
-
[6]
Accelerating robotic reinforcement learning via parameterized action primitives
Dalal, M., Pathak, D., and Salakhutdinov, R. Accelerating robotic reinforcement learning via parameterized action primitives. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[7]
and Nichol, A
Dhariwal, P. and Nichol, A. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[8]
Diffusion-based reinforcement learning via q-weighted variational policy optimization
Ding, S., Hu, K., Zhang, Z., Ren, K., Zhang, W., Yu, J., Wang, J., and Shi, Y. Diffusion-based reinforcement learning via q-weighted variational policy optimization. Advances in Neural Information Processing Systems, 37: 0 53945--53968, 2024
2024
-
[9]
Ding, S., Hu, K., Zhong, S., Luo, H., Zhang, W., Wang, J., Wang, J., and Shi, Y. Genpo: Generative diffusion models meet on-policy reinforcement learning. CoRR, abs/2505.18763, 2025. doi:10.48550/ARXIV.2505.18763
-
[10]
and Mordatch, I
Du, Y. and Mordatch, I. Implicit generation and modeling with energy based models. In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[11]
B., Dieleman, S., Fergus, R., Sohl-Dickstein, J., Doucet, A., and Grathwohl, W
Du, Y., Durkan, C., Strudel, R., Tenenbaum, J. B., Dieleman, S., Fergus, R., Sohl-Dickstein, J., Doucet, A., and Grathwohl, W. Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc. In International Conference on Machine Learning (ICML), 2023 a
2023
-
[12]
Learning universal policies via text-guided video generation
Du, Y., Yang, S., Dai, B., Dai, H., Nachum, O., Tenenbaum, J., Schuurmans, D., and Abbeel, P. Learning universal policies via text-guided video generation. Advances in neural information processing systems, 36: 0 9156--9172, 2023 b
2023
-
[13]
A., Wahid, A., Downs, L., Adrianos, A., Hsu, C.-Y., and Chi, C
Florence, P., Lynch, C., Zeng, A., Ramirez, O. A., Wahid, A., Downs, L., Adrianos, A., Hsu, C.-Y., and Chi, C. Implicit behavioral cloning. In Conference on Robot Learning (CoRL), 2022
2022
-
[14]
Meta learning shared hierarchies
Frans, K., Ho, J., Chen, X., Abbeel, P., and Schulman, J. Meta learning shared hierarchies. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings . OpenReview.net, 2018
2018
-
[15]
Meta-learning parameterized skills
Fu, H., Yu, S., Tiwari, S., Littman, M., and Konidaris, G. Meta-learning parameterized skills. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , volume 202 of Proceedings of Machine Learning Research, pp.\ 10461--1048...
2023
-
[16]
Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning
Gupta, A., Kumar, V., Lynch, C., Levine, S., and Hausman, K. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. In Conference on Robot Learning (CoRL), 2019
2019
-
[17]
Learning parameterized skills from demonstrations
Gupta, V., Fu, H., Luo, C., Jiang, Y., and Konidaris, G. Learning parameterized skills from demonstrations. In Advances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[18]
Isometric representation learning for disentangled latent space of diffusion models
Hahm, J., Lee, J., Kim, S., and Lee, J. Isometric representation learning for disentangled latent space of diffusion models. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024
2024
-
[19]
Hausknecht, M. J. and Stone, P. Deep reinforcement learning in parameterized action space. In Bengio, Y. and LeCun, Y. (eds.), 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings , 2016
2016
-
[20]
Denoising diffusion probabilistic models
Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[21]
doi: 10.1109/ICRA55743.2025.11128816
H eg, S. H., Du, Y., and Egeland, O. Fast policy synthesis with variable noise diffusion models. In IEEE International Conference on Robotics and Automation, ICRA 2025, Atlanta, GA, USA, May 19-23, 2025 , pp.\ 4821--4828. IEEE , 2025. doi:10.1109/ICRA55743.2025.11127858
-
[22]
Multimodal deep generative models for trajectory prediction: A conditional variational autoencoder approach
Ivanovic, B., Leung, K., Schmerling, E., and Pavone, M. Multimodal deep generative models for trajectory prediction: A conditional variational autoencoder approach. IEEE Robotics and Automation Letters, 6 0 (2): 0 295--302, 2020
2020
-
[23]
Jackson, M. T., Matthews, M. T., Lu, C., Ellis, B., Whiteson, S., and Foerster, J. Policy-guided diffusion. arXiv preprint arXiv:2404.06356, 2024
arXiv 2024
-
[24]
B., and Levine, S
Janner, M., Du, Y., Tenenbaum, J. B., and Levine, S. Planning with diffusion for flexible behavior synthesis. In International Conference on Machine Learning (ICML), 2022
2022
-
[25]
Towards diverse behaviors: A benchmark for imitation learning with human demonstrations
Jia, X., Blessing, D., Jiang, X., Reuss, M., Donat, A., Lioutikov, R., and Neumann, G. Towards diverse behaviors: A benchmark for imitation learning with human demonstrations. In International Conference on Learning Representations (ICLR), 2024
2024
-
[26]
Efficient diffusion policies for offline reinforcement learning
Kang, B., Ma, X., Du, C., Pang, T., and Yan, S. Efficient diffusion policies for offline reinforcement learning. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, Dece...
2023
-
[27]
Elucidating the design space of diffusion-based generative models
Karras, T., Aittala, M., Aila, T., and Laine, S. Elucidating the design space of diffusion-based generative models. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, Nov...
2022
-
[28]
Konidaris, G. D. and Barto, A. G. Skill discovery in continuous reinforcement learning domains using skill chaining. In Bengio, Y., Schuurmans, D., Lafferty, J. D., Williams, C. K. I., and Culotta, A. (eds.), Advances in Neural Information Processing Systems 22: 23rd Annual Conference on Neural Information Processing Systems 2009. Proceedings of a meeting...
2009
-
[29]
J., Shafiullah, N
Lee, S., Wang, Y., Etukuru, H., Kim, H. J., Shafiullah, N. M. M., and Pinto, L. Behavior generation with latent actions. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024
2024
-
[30]
Editor: Effective and interpretable prompt inversion for text-to-image diffusion models
Li, M., Xia, K., Zhang, G., Wang, Z., Tao, G., Pan, S., Zhai, J., and Ma, S. Editor: Effective and interpretable prompt inversion for text-to-image diffusion models. arXiv preprint arXiv:2506.03067, 2025 a
arXiv 2025
-
[31]
Li, M., Zhang, R., Wen, Z., Pan, S., da Silva, B. C., Zhai, J., and Ma, S. Promptminer: Black-box prompt stealing against text-to-image generative models via reinforcement learning and fuzz optimization. arXiv preprint arXiv:2511.22119, 2025 b
arXiv 2025
-
[32]
Learning multimodal behaviors from scratch with diffusion policy gradient
Li, S., Krohn, R., Chen, T., Ajay, A., Agrawal, P., and Chalvatzaki, G. Learning multimodal behaviors from scratch with diffusion policy gradient. In Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J. M., and Zhang, C. (eds.), Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing S...
2024
-
[33]
Learning multimodal behaviors from scratch with diffusion policy gradient
Li, S., Krohn, R., Chen, T., Ajay, A., Agrawal, P., and Chalvatzaki, G. Learning multimodal behaviors from scratch with diffusion policy gradient. Advances in Neural Information Processing Systems, 37: 0 38456--38479, 2024 b
2024
-
[34]
Li, Z., Yang, R., Chen, R., Luo, Z., and Chen, L. Adpro: a test-time adaptive diffusion policy via manifold-constrained denoising and task-aware initialization for robotic manipulation. arXiv preprint arXiv:2508.06266, 2025 c
arXiv 2025
-
[35]
Learning latent plans from play
Lynch, C., Florence, P., and et al. Learning latent plans from play. In Conference on Robot Learning, 2020
2020
-
[36]
Reinforcement learning with discrete diffusion policies for combinatorial action spaces
Ma, H., Nabati, O., Rosenberg, A., Dai, B., Lang, O., Szpektor, I., Boutilier, C., Li, N., Mannor, S., Shani, L., et al. Reinforcement learning with discrete diffusion policies for combinatorial action spaces. arXiv preprint arXiv:2509.22963, 2025
Pith/arXiv arXiv 2025
-
[37]
Makarova, M., Liu, Q., and Tsetserukou, D. Diffusionrl: Efficient training of diffusion policies for robotic grasping using rl-adapted large-scale datasets. arXiv preprint arXiv:2505.18876, 2025
arXiv 2025
-
[38]
What matters in learning from offline demonstrations for robot manipulation
Mandlekar, A., Xu, D., Wong, J., Nasiriany, S., Wang, C., Kulkarni, R., Fei-Fei, L., Savarese, S., Zhu, Y., and Fan, L. What matters in learning from offline demonstrations for robot manipulation. In Conference on Robot Learning (CoRL), 2021
2021
-
[39]
Masson, W., Ranchod, P., and Konidaris, G. D. Reinforcement learning with parameterized actions. In Schuurmans, D. and Wellman, M. P. (eds.), Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, February 12-17, 2016, Phoenix, Arizona, USA , pp.\ 1934--1940. AAAI Press, 2016. doi:10.1609/AAAI.V30I1.10226
-
[40]
Miao, Z., Wang, J., Wang, Z., Yang, Z., Wang, L., Qiu, Q., and Liu, Z. Training diffusion models towards diverse image generation with reinforcement learning. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024 , pp.\ 10844--10853. IEEE , 2024. doi:10.1109/CVPR52733.2024.01031
-
[41]
Moser, B. B., Shanbhag, A. S., Raue, F., Frolov, S., Palacio, S., and Dengel, A. Diffusion models, image super-resolution, and everything: A survey. IEEE Trans. Neural Networks Learn. Syst. , 36 0 (7): 0 11793--11813, 2025. doi:10.1109/TNNLS.2024.3476671
-
[42]
and Dhariwal, P
Nichol, A. and Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the 38th International Conference on Machine Learning (ICML), 2021
2021
-
[43]
Much ado about noising: Dispelling the myths of generative robotic control
Pan, C., Anantharaman, G., Huang, N.-C., Jin, C., Pfrommer, D., Yuan, C., Permenter, F., Qu, G., Boffi, N., Shi, G., et al. Much ado about noising: Dispelling the myths of generative robotic control. arXiv preprint arXiv:2512.01809, 2025 a
arXiv 2025
-
[44]
Semantics lead the way: Harmonizing semantic and texture modeling with asynchronous latent diffusion
Pan, Y., Feng, R., Dai, Q., Wang, Y., Lin, W., Guo, M., Luo, C., and Zheng, N. Semantics lead the way: Harmonizing semantic and texture modeling with asynchronous latent diffusion. arXiv preprint arXiv:2512.04926, 2025 b
arXiv 2025
-
[45]
Unsupervised discovery of semantic latent directions in diffusion models
Park, Y.-H., Kwon, M., Jo, J., and Uh, Y. Unsupervised discovery of semantic latent directions in diffusion models. arXiv preprint arXiv:2302.01245, 2023
arXiv 2023
-
[46]
Film: Visual reasoning with a general conditioning layer
Perez, E., Strub, F., De Vries, H., Dumoulin, V., and Courville, A. Film: Visual reasoning with a general conditioning layer. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[47]
Offline reinforcement learning with discrete diffusion skills
Qiao, R., Cheng, J., Dai, X., Tian, Y., and Lv, Y. Offline reinforcement learning with discrete diffusion skills. arXiv preprint arXiv:2503.20176, 2025
arXiv 2025
-
[48]
Queisser, J. F. and Steil, J. J. Bootstrapping of parameterized skills through hybrid optimization in task and policy spaces. Frontiers Robotics AI , 5: 0 49, 2018. doi:10.3389/FROBT.2018.00049
-
[49]
Goal-conditioned imitation learning using score-based diffusion policies
Reuss, M., Li, M., Jia, X., and Lioutikov, R. Goal-conditioned imitation learning using score-based diffusion policies. In Proceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[50]
Forward kl regularized preference optimization for aligning diffusion policies
Shan, Z., Fan, C., Qiu, S., Shi, J., and Bai, C. Forward kl regularized preference optimization for aligning diffusion policies. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 14386--14395, 2025
2025
-
[51]
A., Maheswaranathan, N., and Ganguli, S
Sohl-Dickstein, J., Weiss, E. A., Maheswaranathan, N., and Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the 32nd International Conference on Machine Learning (ICML), 2015
2015
-
[52]
and Ermon, S
Song, Y. and Ermon, S. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[53]
P., Kumar, A., Ermon, S., and Poole, B
Song, Y., Sohl - Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. Score-based generative modeling through stochastic differential equations. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021
2021
-
[54]
S., Precup, D., and Singh, S
Sutton, R. S., Precup, D., and Singh, S. Between mdps and semi-mdps: A framework for temporal abstraction in reinforcement learning. Artificial Intelligence, 1999
1999
-
[55]
S., Osindero, S., Schaul, T., Heess, N., Jaderberg, M., Silver, D., and Kavukcuoglu, K
Vezhnevets, A. S., Osindero, S., Schaul, T., Heess, N., Jaderberg, M., Silver, D., and Kavukcuoglu, K. Feudal networks for hierarchical reinforcement learning. In Precup, D. and Teh, Y. W. (eds.), Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017 , volume 70 of Proceedings of Machine ...
2017
-
[56]
Steering your diffusion policy with latent space reinforcement learning
Wagenmaker, A., Nakamoto, M., Zhang, Y., Park, S., Yagoub, W., Nagabandi, A., Gupta, A., and Levine, S. Steering your diffusion policy with latent space reinforcement learning. Conference on Robot Learning (CoRL), 2025
2025
-
[57]
J., and Zhou, M
Wang, Z., Hunt, J. J., and Zhou, M. Diffusion policies as an expressive policy class for offline reinforcement learning. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023
2023
-
[58]
Learning intractable multimodal policies with reparameterization and diversity regularization
Wang, Z., Liu, J., and Pan, L. Learning intractable multimodal policies with reparameterization and diversity regularization. arXiv preprint arXiv:2511.01374, 2025
arXiv 2025
-
[59]
Diffusion models for robotic manipulation: A survey
Wolf, R., Shi, Y., Liu, S., and Rayyes, R. Diffusion models for robotic manipulation: A survey. Frontiers in Robotics and AI, 12: 0 1606247, 2025
2025
-
[60]
doi: 10.1109/ICRA55743.2025.11128816
Wu, K., Zhu, Y., Li, J., Wen, J., Liu, N., Xu, Z., and Tang, J. Discrete policy: Learning disentangled action space for multi-task robotic manipulation. In IEEE International Conference on Robotics and Automation, ICRA 2025, Atlanta, GA, USA, May 19-23, 2025 , pp.\ 8811--8818. IEEE , 2025. doi:10.1109/ICRA55743.2025.11127630
-
[61]
Diffusion models for reinforcement learning: Foundations, taxonomy, and development
Xu, C., Guo, J., Liang, Y., Huang, H., Zou, H., Zheng, X., Yu, S., Chu, X., Cao, J., and Wang, T. Diffusion models for reinforcement learning: Foundations, taxonomy, and development. arXiv preprint arXiv:2510.12253, 2025
arXiv 2025
-
[62]
Diffusion- ES : Gradient-free planning with diffusion for autonomous driving and zero-shot instruction following
Yang, B., Su, H., Gkanatsios, N., Ke, T.-W., Jain, A., Schneider, J., and Fragkiadaki, K. Diffusion- ES : Gradient-free planning with diffusion for autonomous driving and zero-shot instruction following. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[63]
Efficient task-specific conditional diffusion policies: Shortcut model acceleration and so (3) optimization
Yu, H., Jin, Y., He, Y., and Sui, W. Efficient task-specific conditional diffusion policies: Shortcut model acceleration and so (3) optimization. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 4174--4183, 2025
2025
-
[64]
Model-based reinforcement learning for parameterized action spaces
Zhang, R., Fu, H., Miao, Y., and Konidaris, G. Model-based reinforcement learning for parameterized action spaces. In Proceedings of the 41st International Conference on Machine Learning (ICML), 2024
2024
-
[65]
D., Huang, F., and Kolobov, A
Zheng, R., Cheng, C.-A., III, H. D., Huang, F., and Kolobov, A. Prise: Llm-style sequence compression for learning temporal action abstractions in control. In Forty-first International Conference on Machine Learning, 2024
2024
-
[66]
N., and Gao, R
Zhu, Y., Xie, J., Wu, Y. N., and Gao, R. Learning energy-based models by cooperative diffusion recovery likelihood. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024
2024
-
[67]
Diffusion models for reinforcement learning: A survey
Zhu, Z., Zhao, H., He, H., Zhong, Y., Zhang, S., Yu, Y., and Zhang, W. Diffusion models for reinforcement learning: A survey. arXiv preprint arXiv:2311.01223, 2023
arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.