On the Limits of LLM Adaptability: Impact of Model-Internalized Priors on Annotation Task Performance
Pith reviewed 2026-06-28 19:16 UTC · model grok-4.3
The pith
LLMs follow misaligned task definitions with unchanged confidence and resist prompt correction for most zero-shot errors, with performance tied to definition-specific familiarity rather than memorization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
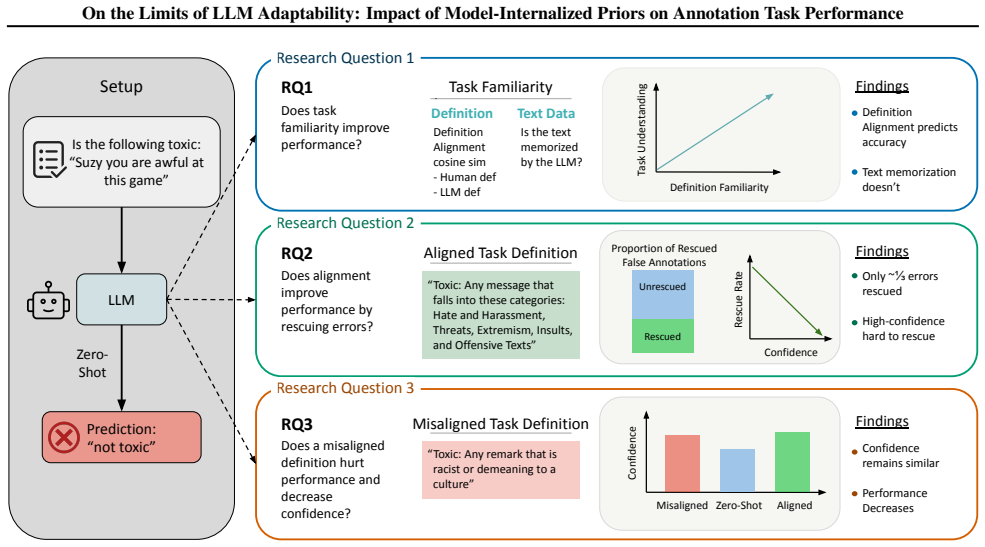
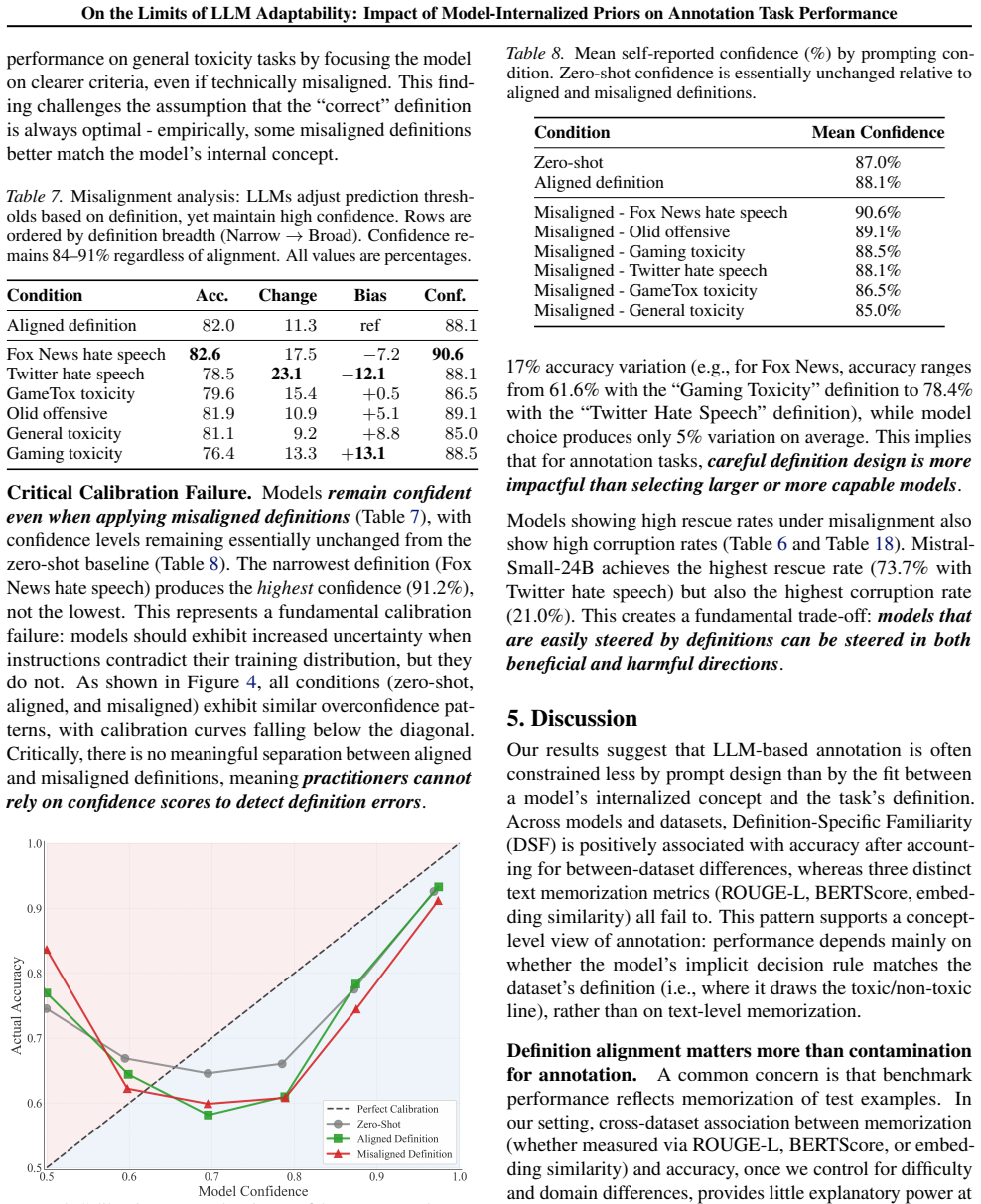
We find that nearly two-thirds of zero-shot errors are resistant to correction, with an overall rescue rate of only 34.8%. High-confidence errors prove especially resistant. When given misaligned definitions, LLMs follow them while maintaining confidence levels unchanged from the aligned condition. After controlling for dataset-level confounds, Definition-Specific Familiarity shows a positive association with model performance (partial r = +0.41), while three distinct memorization metrics all fail to show a positive association.
What carries the argument
Definition-Specific Familiarity (DSF), which measures alignment between a model's internal concept and the supplied task definition.
If this is right
- Additional prompting corrects only about one-third of zero-shot annotation errors overall.
- High-confidence errors remain especially resistant to rescue by prompt changes.
- Models apply misaligned task definitions at the same confidence level as aligned ones.
- Performance differences track definition alignment more than text-level memorization.
Where Pith is reading between the lines
- Task-specific model selection could improve if DSF can be estimated quickly without running full datasets.
- Annotation pipelines may need pre-screening steps that check concept alignment instead of depending on prompt iteration.
- The same resistance pattern could limit reliability in LLM-as-a-judge setups outside toxicity detection.
- Pretraining data choices that shape clear internal concepts may matter more for downstream annotation than volume of text alone.
Load-bearing premise
That Definition-Specific Familiarity validly measures alignment between a model's internal concept and the task definition, and that partial correlation after dataset controls isolates this effect without residual confounds.
What would settle it
A new set of annotation tasks where the partial correlation of DSF with performance falls to zero or below after the same dataset-level controls, or where one memorization metric shows a clear positive link.
Figures

read the original abstract
Large Language Models (LLMs) are increasingly used for zero-shot annotation and LLM-as-a-judge tasks, yet their reliability hinges on how model-internalized priors interact with user-provided instructions. We investigate three dimensions of this interaction: (1) how an LLM's familiarity with data and task definitions affects performance, (2) the extent to which additional information in prompts can correct zero-shot errors ("decision stickiness"), and (3) model susceptibility to misaligned task definitions. Through experiments on toxicity detection across diverse datasets (spanning social media, gaming, news, and forums) using both dense and mixture-of-experts models, we find that nearly two-thirds of zero-shot errors are resistant to correction, with an overall rescue rate (fraction of initial errors corrected by prompting) of only 34.8%. High-confidence errors prove especially resistant to correction. When given misaligned definitions, LLMs follow them while maintaining confidence levels unchanged from the aligned condition. Crucially, we introduce Definition-Specific Familiarity (DSF), which measures alignment between a model's internal concept and the task definition. After controlling for dataset-level confounds, DSF shows a positive association with model performance (partial r = +0.41), while three distinct memorization metrics (ROUGE-L, BERTScore, and embedding cosine similarity) all fail to show a positive association. These findings show the limitations of prompt-based correction in annotation tasks, highlighting the importance of definition alignment over text-level memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines interactions between LLM-internalized priors and user-provided task definitions in zero-shot annotation, focusing on toxicity detection across multiple datasets and model types. It reports that ~65% of zero-shot errors resist correction by additional prompting (overall rescue rate 34.8%), that high-confidence errors are especially sticky, that models follow misaligned definitions while preserving confidence levels, and that a newly introduced metric Definition-Specific Familiarity (DSF) exhibits a positive partial correlation (r = +0.41) with performance after dataset-level controls—unlike three memorization metrics (ROUGE-L, BERTScore, embedding cosine similarity).
Significance. If the DSF association and rescue-rate findings hold after full methodological disclosure, the work would usefully document prompt-correction limits and the relative importance of definition alignment versus surface memorization for annotation reliability, providing a concrete empirical basis for prioritizing definition-model fit in LLM-as-a-judge pipelines.
major comments (3)
- [Abstract / Methods] Abstract and Methods: the partial-correlation claim (r = +0.41) between DSF and performance is load-bearing for the central argument that definition alignment matters more than memorization, yet the abstract supplies neither the operational definition of DSF nor the exact list of dataset-level control variables; without these, it is impossible to verify that the reported association isolates internalized-concept alignment rather than residual confounds or construction artifacts.
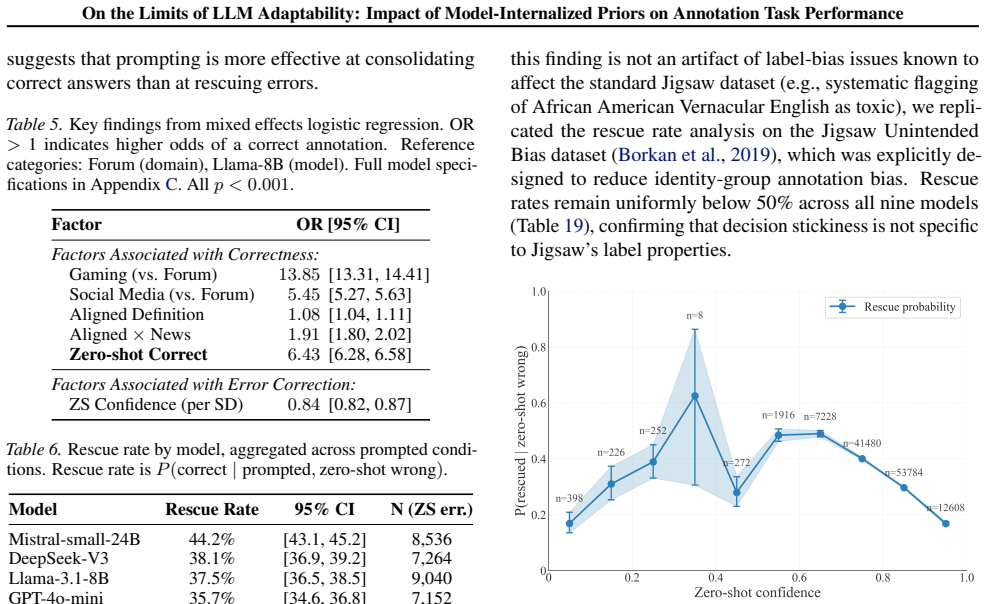
- [Results] Results on decision stickiness: the 34.8% rescue rate and the claim that high-confidence errors are especially resistant are presented without error bars, exact prompt templates, or statistical controls for dataset difficulty; these omissions make it difficult to assess whether the two-thirds resistance figure generalizes or is driven by particular dataset properties.
- [Experiments] Misaligned-definition experiment: the finding that models follow misaligned definitions with unchanged confidence requires explicit reporting of how alignment/misalignment was operationalized and how confidence was measured across conditions; absent these details the result cannot be evaluated for robustness against prompt phrasing artifacts.
minor comments (2)
- [Abstract] The abstract states 'three distinct memorization metrics' but does not list the precise implementations or preprocessing steps used for ROUGE-L, BERTScore, and embedding cosine; adding these would aid reproducibility.
- [Data] Dataset descriptions mention 'social media, gaming, news, and forums' but provide no table of sizes, label distributions, or inter-annotator agreement; a supplementary table would strengthen the claim that dataset-level confounds were adequately controlled.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and recommendations for improving the clarity and reproducibility of our work. We address each major comment below and will make the suggested revisions to enhance methodological transparency.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the partial-correlation claim (r = +0.41) between DSF and performance is load-bearing for the central argument that definition alignment matters more than memorization, yet the abstract supplies neither the operational definition of DSF nor the exact list of dataset-level control variables; without these, it is impossible to verify that the reported association isolates internalized-concept alignment rather than residual confounds or construction artifacts.
Authors: We agree that the abstract and Methods section should provide the operational definition of DSF and the specific dataset-level controls used in the partial correlation analysis. In the revised manuscript, we will explicitly define DSF and list the control variables to allow verification that the association reflects internalized-concept alignment. revision: yes
-
Referee: [Results] Results on decision stickiness: the 34.8% rescue rate and the claim that high-confidence errors are especially resistant are presented without error bars, exact prompt templates, or statistical controls for dataset difficulty; these omissions make it difficult to assess whether the two-thirds resistance figure generalizes or is driven by particular dataset properties.
Authors: We will include error bars on all reported rescue rates, provide the exact prompt templates used in an appendix, and add statistical controls for dataset difficulty in the revised Results section. revision: yes
-
Referee: [Experiments] Misaligned-definition experiment: the finding that models follow misaligned definitions with unchanged confidence requires explicit reporting of how alignment/misalignment was operationalized and how confidence was measured across conditions; absent these details the result cannot be evaluated for robustness against prompt phrasing artifacts.
Authors: We will expand the description of the misaligned-definition experiment to detail the operationalization of alignment and misalignment (including example definitions) and specify the method for measuring and comparing confidence levels across conditions. revision: yes
Circularity Check
No circularity: empirical associations with newly introduced metric
full rationale
The paper is an empirical study reporting experimental results on zero-shot annotation performance, decision stickiness (rescue rate 34.8%), and a new metric DSF. It states a partial correlation (partial r = +0.41) after dataset-level controls and contrasts it with null results for three memorization metrics. No equations, derivations, or self-citations are present that reduce the reported statistics or the DSF-performance link to quantities defined by the paper's own fitted parameters or inputs. The central claims rest on experimental measurements and controls rather than any self-definitional, fitted-input, or self-citation chain. This is self-contained empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Partial correlation after removing dataset-level confounds isolates the effect of definition alignment from other dataset properties.
invented entities (1)
-
Definition-Specific Familiarity (DSF)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
o ttger, P., Urman, A., Wendsj \
Baumann, J., R \"o ttger, P., Urman, A., Wendsj \"o , A., Plaza-del Arco, F. M., Gruber, J. B., and Hovy, D. Large language model hacking: Quantifying the hidden risks of using LLMs for text annotation. arXiv preprint arXiv:2509.08825, 2025. doi:10.48550/arXiv.2509.08825. URL https://arxiv.org/abs/2509.08825
-
[2]
Nuanced metrics for measuring unintended bias with real data for text classification
Borkan, D., Dixon, L., Sorensen, J., Thain, N., and Vasserman, L. Nuanced metrics for measuring unintended bias with real data for text classification. In Companion Proceedings of The 2019 World Wide Web Conference, WWW '19, pp.\ 491--500, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450366755. doi:10.1145/3308560.3317593. URL ht...
-
[3]
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A.,...
1901
-
[4]
Extracting training data from large language models
Carlini, N., Tram \`e r, F., Wallace, E., Jagielski, M., Herbert-Voss, A., Lee, K., Roberts, A., Brown, T., Song, D., Erlingsson, \'U ., Oprea, A., and Raffel, C. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21), pp.\ 2633--2650. USENIX Association, August 2021. ISBN 978-1-939133-24-3. URL https:/...
2021
-
[5]
A course correction in steerability evaluation: Revealing miscalibration and side effects in LLM s
Chang, T., Schnabel, T., Swaminathan, A., and Wiens, J. A course correction in steerability evaluation: Revealing miscalibration and side effects in LLM s. In Proceedings of the AAAI Conference on Artificial Intelligence, 2026. URL https://arxiv.org/abs/2505.23816
-
[6]
Toxic comment classification challenge
cjadams, Sorensen, J., Elliott, J., Dixon, L., McDonald, M., nithum, and Cukierski, W. Toxic comment classification challenge. Kaggle Competition, 2018. URL https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
2018
-
[7]
Automated hate speech detection and the problem of offensive language
Davidson, T., Warmsley, D., Macy, M., and Weber, I. Automated hate speech detection and the problem of offensive language. Proceedings of the International AAAI Conference on Web and Social Media, 11 0 (1): 0 512--515, 2017. doi:10.1609/icwsm.v11i1.14955
-
[8]
DeepSeek-AI. Deepseek-v3 technical report, 2024. URL https://arxiv.org/abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
ElSherief, M., Kulkarni, V., Nguyen, D., Wang, W. Y., and Belding, E. Hate lingo: A target-based linguistic analysis of hate speech in social media. Proceedings of the International AAAI Conference on Web and Social Media, 12 0 (1), June 2018. doi:10.1609/icwsm.v12i1.15041. URL https://ojs.aaai.org/index.php/ICWSM/article/view/15041
-
[10]
Gao, L. and Huang, R. Detecting online hate speech using context aware models. In Mitkov, R. and Angelova, G. (eds.), Proceedings of the International Conference Recent Advances in Natural Language Processing, RANLP 2017 , pp.\ 260--266, Varna, Bulgaria, September 2017. INCOMA Ltd. doi:10.26615/978-954-452-049-6_036. URL https://aclanthology.org/R17-1036/
-
[11]
A survey of confidence estimation and calibration in large language models
Geng, J., Cai, F., Wang, Y., Koeppl, H., Nakov, P., and Gurevych, I. A survey of confidence estimation and calibration in large language models. In Duh, K., Gomez, H., and Bethard, S. (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers...
-
[12]
ChatGPT outperforms crowd workers for text-annotation tasks , volume=
Gilardi, F., Alizadeh, M., and Kubli, M. Chatgpt outperforms crowd workers for text-annotation tasks. Proceedings of the National Academy of Sciences, 120 0 (30): 0 e2305016120, 2023. doi:10.1073/pnas.2305016120. URL https://www.pnas.org/doi/abs/10.1073/pnas.2305016120
-
[13]
and Surdeanu, M
Golchin, S. and Surdeanu, M. Time travel in LLM s: Tracing data contamination in large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=2Rwq6c3tvr
2024
-
[14]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [15]
-
[16]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Jiang, A. Q., Sablayrolles, A., Roux, A., Mensch, A., Savary, B., Bamford, C., Chaplot, D. S., de las Casas, D., Bou Hanna, E., Bressand, F., Lengyel, G., Bour, G., Lample, G., Lavaud, L. R., Saulnier, L., Lachaux, M.-A., Stock, P., Subramanian, S., Yang, S., Antoniak, S., Le Scao, T., Gervet, T., Lavril, T., Wang, T., Lacroix, T., and El Sayed, W. Mixtra...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Khattab, O., Singhvi, A., Maheshwari, P., Zhang, Z., Santhanam, K., Vardhamanan, S., Haq, S., Sharma, A., Joshi, T. T., Moazam, H., Miller, H., Zaharia, M., and Potts, C. Dspy: Compiling declarative language model calls into self-improving pipelines. ArXiv, abs/2310.03714, 2023. URL https://api.semanticscholar.org/CorpusID:263671701
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Prometheus: Inducing fine-grained evaluation capability in language models
Kim, S., Shin, J., Cho, Y., Jang, J., Longpre, S., Lee, H., Yun, S., Shin, S., Kim, S., Thorne, J., and Seo, M. Prometheus: Inducing fine-grained evaluation capability in language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=8euJaTveKw
2024
-
[20]
Kocielnik, R., Li, Z., Kann, C., Sambrano, D., Morrier, J., Linegar, M., Taylor, C., Kim, M., Naqvie, N., Soltani, F., Dehpanah, A., Cahill, G., Anandkumar, A., and Alvarez, R. M. Challenges in moderating disruptive player behavior in online competitive action games. Frontiers in Computer Science, 6: 0 1283735, 2024. doi:10.3389/fcomp.2024.1283735. URL ht...
-
[21]
A., Soltani, F., Sambrano, D., Anandkumar, A., and Alvarez, R
Kocielnik, R., Kim, M., Boonyarungsrit, P. A., Soltani, F., Sambrano, D., Anandkumar, A., and Alvarez, R. M. Prosocial behavior detection in player game chat: From aligning human- AI definitions to efficient annotation at scale. arXiv preprint arXiv:2508.05938, 2025 a . URL https://arxiv.org/abs/2508.05938
-
[22]
Kocielnik, R., Li, Z., Linegar, M., Sambrano, D., Soltani, F., Kim, M., Naqvie, N., Cahill, G., Anandkumar, A., and Alvarez, R. M. Online moderation in competitive action games: How intervention affects player behaviors. Proc. ACM Hum.-Comput. Interact., 9 0 (6), October 2025 b . doi:10.1145/3748599. URL https://doi.org/10.1145/3748599
-
[23]
ROUGE : A package for automatic evaluation of summaries
Lin, C.-Y. ROUGE : A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp.\ 74--81, Barcelona, Spain, July 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013/
2004
-
[24]
G -eval: NLG evaluation using gpt-4 with better human alignment
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., and Zhu, C. G -eval: NLG evaluation using gpt-4 with better human alignment. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 2511--2522, Singapore, December 2023. Association for Computational Linguistics. doi:10.18653/v...
-
[25]
Llama 3.3 model card
Meta AI . Llama 3.3 model card. https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct, December 2024
2024
-
[26]
Miehling, E., Desmond, M., Natesan Ramamurthy, K., Daly, E. M., Varshney, K. R., Farchi, E., Dognin, P., Rios, J., Bouneffouf, D., Liu, M., and Sattigeri, P. Evaluating the prompt steerability of large language models. In Chiruzzo, L., Ritter, A., and Wang, L. (eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associa...
-
[27]
Min, S., Lyu, X., Holtzman, A., Artetxe, M., Lewis, M., Hajishirzi, H., and Zettlemoyer, L. Rethinking the role of demonstrations: What makes in-context learning work? In Goldberg, Y., Kozareva, Z., and Zhang, Y. (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 11048--11064, Abu Dhabi, United Arab Emirat...
-
[28]
Mistral-small-24b-instruct-2501
Mistral AI . Mistral-small-24b-instruct-2501. https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501, 2025
2025
-
[29]
S em E val-2016 task 6: Detecting stance in tweets
Mohammad, S., Kiritchenko, S., Sobhani, P., Zhu, X., and Cherry, C. S em E val-2016 task 6: Detecting stance in tweets. In Bethard, S., Carpuat, M., Cer, D., Jurgens, D., Nakov, P., and Zesch, T. (eds.), Proceedings of the 10th International Workshop on Semantic Evaluation ( S em E val-2016) , pp.\ 31--41, San Diego, California, June 2016. Association for...
-
[30]
Nallapati, R., Zhou, B., Gulcehre, C., and Xiang, B
Nadeem, M., Bethke, A., and Reddy, S. S tereo S et: Measuring stereotypical bias in pretrained language models. In Zong, C., Xia, F., Li, W., and Navigli, R. (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp....
-
[31]
Nangia, N., Vania, C., Bhalerao, R., and Bowman, S. R. C row S -pairs: A challenge dataset for measuring social biases in masked language models. In Webber, B., Cohn, T., He, Y., and Liu, Y. (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp.\ 1953--1967, Online, November 2020. Association for Comput...
-
[32]
Naseem, U., Shiwakoti, S., Shah, S. B., Thapa, S., and Zhang, Q. G ame T ox: A comprehensive dataset and analysis for enhanced toxicity detection in online gaming communities. In Chiruzzo, L., Ritter, A., and Wang, L. (eds.), Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human L...
-
[33]
GPT-4o mini : Advancing cost-efficient intelligence
OpenAI . GPT-4o mini : Advancing cost-efficient intelligence. OpenAI Blog, 2024. URL https://openai.com/blog/gpt-4o-mini-advancing-cost-efficient-intelligence
2024
-
[34]
Pang, B. and Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics ( ACL -04) , pp.\ 271--278, Barcelona, Spain, July 2004. doi:10.3115/1218955.1218990. URL https://aclanthology.org/P04-1035/
-
[35]
Parrish, A., Chen, A., Nangia, N., Padmakumar, V., Phang, J., Thompson, J., Htut, P. M., and Bowman, S. R. BBQ : A hand-built bias benchmark for question answering. In Muresan, S., Nakov, P., and Villavicencio, A. (eds.), Findings of the Association for Computational Linguistics: ACL 2022, pp.\ 2086--2105, Dublin, Ireland, May 2022. Association for Comput...
-
[36]
and Holmes, C
Pawitan, Y. and Holmes, C. Confidence in the Reasoning of Large Language Models . Harvard Data Science Review, 7 0 (1), January 2025. https://hdsr.mitpress.mit.edu/pub/jaqt0vpb
2025
-
[37]
The ``problem'' of human label variation: On ground truth in data, modeling and evaluation
Plank, B. The ``problem'' of human label variation: On ground truth in data, modeling and evaluation. In Goldberg, Y., Kozareva, Z., and Zhang, Y. (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp.\ 10671--10682, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi:...
-
[38]
Qwen, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y., Su, Y., Zhang, Y., Wan, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Whose opinions do language models reflect? In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J
Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., and Hashimoto, T. Whose opinions do language models reflect? In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pp.\ 29971--30004. ...
2023
-
[40]
Sap, M., Swayamdipta, S., Vianna, L., Zhou, X., Choi, Y., and Smith, N. A. Annotators with attitudes: How annotator beliefs and identities bias toxic language detection. In Carpuat, M., de Marneffe, M.-C., and Meza Ruiz, I. V. (eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human L...
-
[41]
On second thought, let ' s not think step by step! bias and toxicity in zero-shot reasoning
Shaikh, O., Zhang, H., Held, W., Bernstein, M., and Yang, D. On second thought, let ' s not think step by step! bias and toxicity in zero-shot reasoning. In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 4454--4470, Toronto, Canada, ...
-
[42]
Detecting pretraining data from large language models
Shi, W., Ajith, A., Xia, M., Huang, Y., Liu, D., Blevins, T., Chen, D., and Zettlemoyer, L. Detecting pretraining data from large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=zWqr3MQuNs
2024
-
[43]
A., Singhvi, A., Lai, L., Ryan, M
Tan, S., Agrawal, L. A., Singhvi, A., Lai, L., Ryan, M. J., Klein, D., Khattab, O., Sen, K., and Zaharia, M. L ang P ro B e: a language program benchmark. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V. (eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 21489--21509, Suzhou, China, November 2025. Associa...
-
[44]
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., and Manning, C. D. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. pp.\ 5433--5442, December 2023. doi:10.18653/v1/2023.emnlp-main.330. URL https://aclanthology.org/2023.emnlp-main.330/
-
[45]
S em E val-2018 task 3: Irony detection in E nglish tweets
Van Hee, C., Lefever, E., and Hoste, V. S em E val-2018 task 3: Irony detection in E nglish tweets. In Apidianaki, M., Mohammad, S. M., May, J., Shutova, E., Bethard, S., and Carpuat, M. (eds.), Proceedings of the 12th International Workshop on Semantic Evaluation, pp.\ 39--50, New Orleans, Louisiana, June 2018. Association for Computational Linguistics. ...
-
[46]
Weld, H., Huang, G., Lee, J., Zhang, T., Wang, K., Guo, X., Long, S., Poon, J., and Han, C. CONDA : a CON textual dual-annotated dataset for in-game toxicity understanding and detection. In Zong, C., Xia, F., Li, W., and Navigli, R. (eds.), Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pp.\ 2406--2416, Online, August 2021. As...
-
[47]
Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s
Xiong, M., Hu, Z., Lu, X., Li, Y., Fu, J., He, J., and Hooi, B. Can LLM s express their uncertainty? an empirical evaluation of confidence elicitation in LLM s. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=gjeQKFxFpZ
2024
-
[48]
On Verbalized Confidence Scores for LLMs
Yang, D., Tsai, Y.-H. H., and Yamada, M. On verbalized confidence scores for LLMs . arXiv preprint arXiv:2412.14737, 2024. URL https://arxiv.org/abs/2412.14737
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Zampieri, M., Malmasi, S., Nakov, P., Rosenthal, S., Farra, N., and Kumar, R. S em E val-2019 task 6: Identifying and categorizing offensive language in social media ( O ffens E val). In May, J., Shutova, E., Herbelot, A., Zhu, X., Apidianaki, M., and Mohammad, S. M. (eds.), Proceedings of the 13th International Workshop on Semantic Evaluation, pp.\ 75--8...
-
[50]
D., and Shi, W
Zhang, J., Yu, S., Chong, D., Sicilia, A., Tomz, M., Manning, C. D., and Shi, W. Verbalized sampling: How to mitigate mode collapse and unlock LLM diversity. In The Fourteenth International Conference on Learning Representations (ICLR), 2026. URL https://openreview.net/forum?id=9jQkmGunGo
2026
-
[51]
Q., and Artzi, Y
Zhang, T., Kishore, V., Wu, F., Weinberger, K. Q., and Artzi, Y. BERTScore : Evaluating text generation with BERT . In International Conference on Learning Representations (ICLR), 2020. URL https://openreview.net/forum?id=SkeHuCVFDr
2020
-
[52]
E., and Stoica, I
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E., Zhang, H., Gonzalez, J. E., and Stoica, I. Judging LLM -as-a-judge with MT -bench and chatbot arena. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=uccHPGDlao
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.