Latent Reward Steering: An Adaptive Inference-Time Framework that Implicitly Promotes Cognitive Behaviors in Reasoning LLMs
Pith reviewed 2026-06-28 18:47 UTC · model grok-4.3
The pith
A reward model trained only on final answer correctness can steer SAE latent states during inference to improve LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
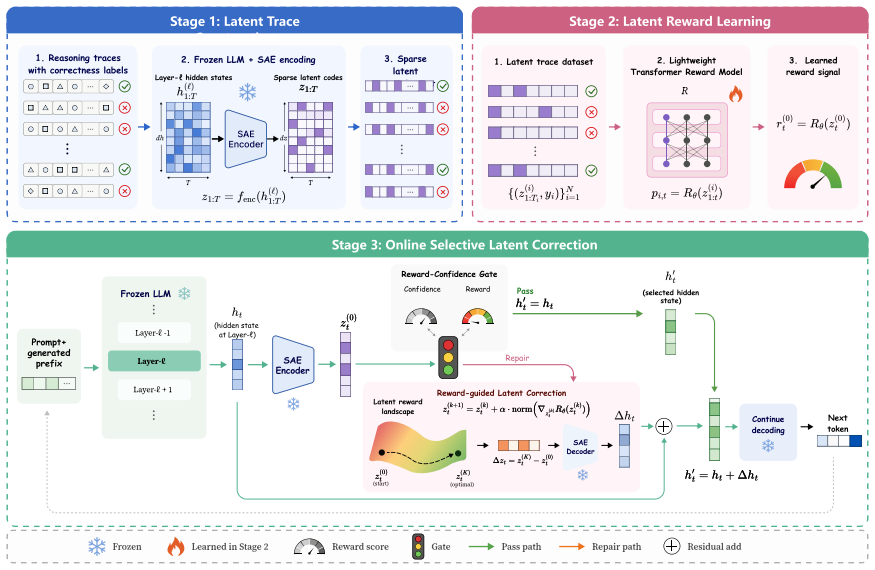
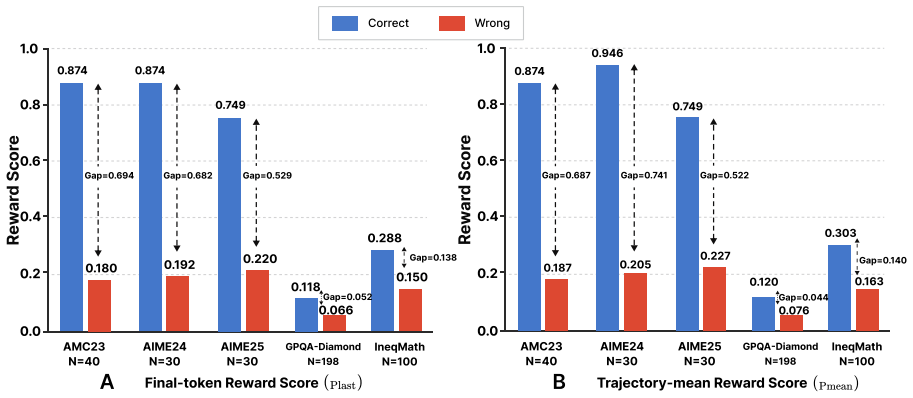
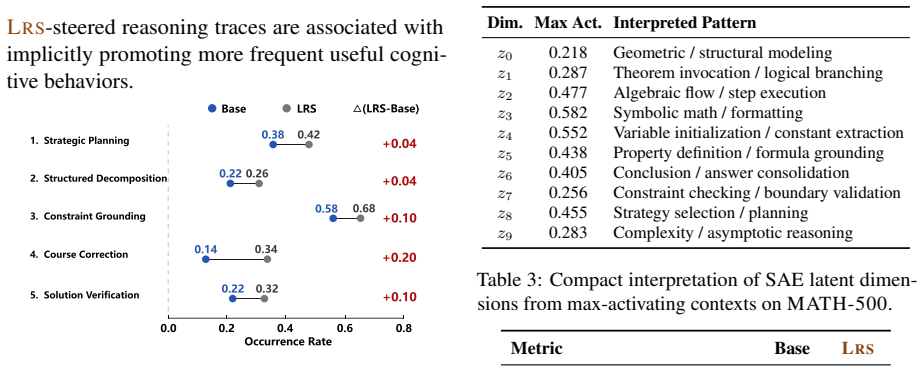
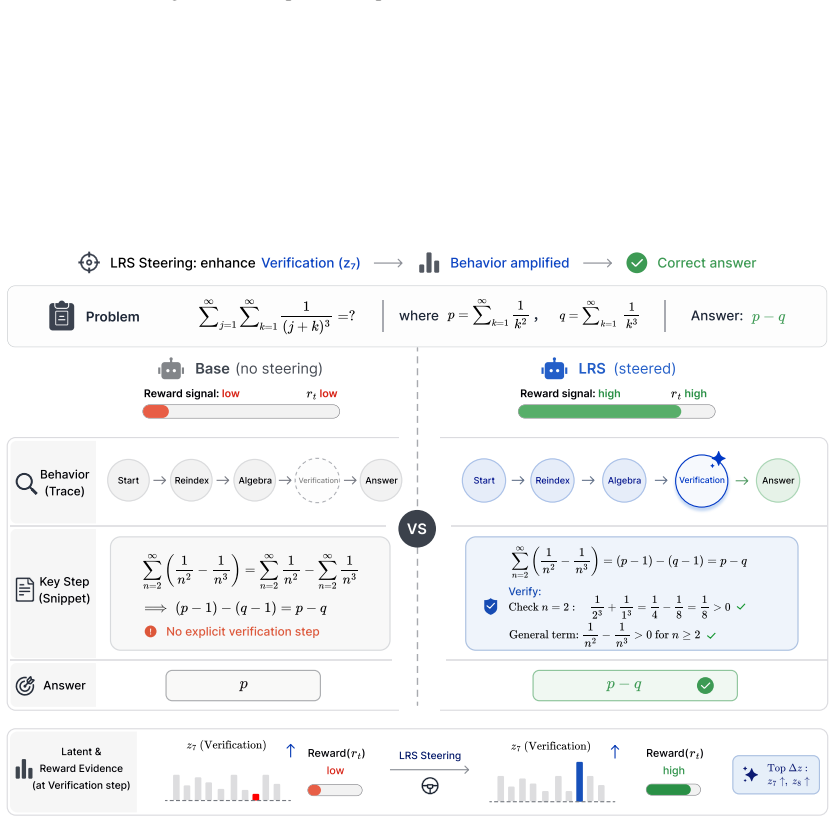
Latent Reward Steering trains a latent reward model on reasoning traces using only final-answer correctness labels. During generation it computes gradients from this model to supply correction directions for fragile SAE latent states and applies the corrections only when both reward and confidence gates indicate intervention is needed. This process yields higher benchmark scores than baselines on several reasoning LLMs and post-hoc inspection shows the adjustments tend to restore cognitive behaviors that resolve the original errors.
What carries the argument
The latent reward model trained on final-answer correctness that supplies gradients for correcting intermediate SAE latent states, gated by reward and confidence thresholds.
If this is right
- Performance rises consistently across multiple reasoning LLM backbones and standard benchmarks.
- The corrections promote cognitive behaviors that repair the specific reasoning errors present in the unsteered run.
- Intervention occurs only on states the reward signal and confidence threshold jointly flag as fragile.
- Steering directions emerge from data rather than from any pre-chosen list of behaviors.
Where Pith is reading between the lines
- The same gradient-steering idea could be tested on other internal representations besides sparse autoencoders.
- If the reward model generalizes across domains, explicit behavior supervision might become less necessary for alignment.
- Extending the approach to tasks where final-answer labels are noisier would test how far the core assumption holds.
Load-bearing premise
Signals derived from whether the final answer is correct can reliably indicate the quality of intermediate latent states inside the model.
What would settle it
Apply the method to a benchmark where the reward model has been shown to misjudge intermediate steps and measure whether accuracy still rises or falls compared with the unsteered baseline.
Figures













read the original abstract
Strong reasoning depends not only on model knowledge but also on how effectively cognitive behaviors are deployed during generation. Existing methods often rely on explicit behavior-level control, making them insufficiently adaptive when failures and required corrections vary across reasoning states, tasks, and models. To this end, we propose Latent Reward Steering (LRS), an adaptive inference-time framework that promotes cognitive behaviors by optimizing the sparse-autoencoder (SAE) latent states that implicitly carry them. Rather than relying on predefined cognitive behaviors or steering directions derived from them, LRS trains a latent reward model on reasoning traces by final answer correctness to estimate the quality of intermediate latent states. During inference, reward gradients provide state-specific correction directions for fragile latent states, while a reward and confidence gate restricts intervention to states the reward signal flags as fragile. Experiments on multiple reasoning LLM backbones and benchmarks show that \ours consistently improves performance over various baselines, and post-hoc analyses further indicate that \ours implicitly promotes good cognitive behaviors that fix the original reasoning errors. Code is available at: https://github.com/jiakanglee/Latent-Reward-Steering.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Latent Reward Steering (LRS), an adaptive inference-time framework for reasoning LLMs. It trains a reward model on complete reasoning traces labeled solely by final-answer correctness to score intermediate SAE latent states. During inference, gradients from this model steer fragile latent states, with reward and confidence gates limiting interventions. Experiments across multiple backbones and benchmarks reportedly show performance gains over baselines, with post-hoc analyses suggesting implicit promotion of beneficial cognitive behaviors that correct original errors. The code is made available.
Significance. Should the core mechanism prove reliable, LRS could advance inference-time control of reasoning processes by implicitly targeting cognitive behaviors through latent space interventions without requiring explicit behavior definitions. This is potentially significant for improving LLM reasoning adaptively. The provision of code is a positive for enabling verification and extension.
major comments (2)
- Abstract: the claim that LRS 'consistently improves performance over various baselines' and that post-hoc analyses show promotion of good behaviors is load-bearing for the central empirical claim, yet no quantitative details (effect sizes, baseline values, statistical tests, or controls) are provided to support it.
- Method (latent reward model and steering): the reward model is fitted only to final-answer correctness labels and then used to score and supply gradients for intermediate SAE latent states; this assumption that the sparse end-of-sequence signal generalizes to partial trajectories without introducing new errors is not directly validated or ablated, undermining the claim that steering fixes original reasoning errors.
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which help clarify the presentation of our empirical claims and the validation of our core methodological assumptions. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: Abstract: the claim that LRS 'consistently improves performance over various baselines' and that post-hoc analyses show promotion of good behaviors is load-bearing for the central empirical claim, yet no quantitative details (effect sizes, baseline values, statistical tests, or controls) are provided to support it.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the performance claims. While the full manuscript contains tables reporting accuracy improvements, baseline comparisons, and statistical details across backbones and benchmarks, the abstract itself does not summarize these numbers. We will revise the abstract to include key effect sizes, representative baseline values, and mention of controls. revision: yes
-
Referee: Method (latent reward model and steering): the reward model is fitted only to final-answer correctness labels and then used to score and supply gradients for intermediate SAE latent states; this assumption that the sparse end-of-sequence signal generalizes to partial trajectories without introducing new errors is not directly validated or ablated, undermining the claim that steering fixes original reasoning errors.
Authors: This is a fair point on the need for explicit validation of the generalization assumption. Our post-hoc analyses show that interventions correlate with error correction and improved cognitive behaviors, but we did not include a dedicated ablation isolating the effect of applying the end-of-sequence-trained reward model to intermediate states. We will add such an ablation study (e.g., comparing steering with vs. without intermediate-state scoring and measuring introduced errors) to the revised manuscript. revision: yes
Circularity Check
No significant circularity; training and inference steps remain distinct
full rationale
The paper trains a latent reward model on complete reasoning traces labeled solely by final-answer correctness, then applies its gradients at inference time to steer SAE latent states. This separation between supervised training on end-of-sequence labels and inference-time correction does not reduce any claimed result to its own inputs by construction. No equations or self-citations are shown that make a prediction equivalent to a fitted parameter, nor is any uniqueness theorem or ansatz smuggled in. Post-hoc analyses are presented as downstream evidence rather than definitional. The method therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Latent reward model weights
- Intervention threshold and gate parameters
axioms (1)
- domain assumption SAE latent states implicitly encode cognitive behaviors relevant to reasoning quality
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Advances in Neural Information Processing Systems , year =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[9]
arXiv preprint arXiv:2601.20833 , year =
Base Models Know How to Reason, Thinking Models Learn When , author =. arXiv preprint arXiv:2601.20833 , year =
-
[10]
Conference on Language Modeling (COLM) , year =
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs , author =. Conference on Language Modeling (COLM) , year =
-
[11]
Conference on Language Modeling (COLM) , year =
SEAL: Steerable Reasoning Calibration of Large Language Models for Free , author =. Conference on Language Modeling (COLM) , year =
-
[12]
ICLR 2025 Workshop on Reasoning and Planning for LLMs , year =
Understanding Reasoning in Thinking Language Models via Steering Vectors , author =. ICLR 2025 Workshop on Reasoning and Planning for LLMs , year =
2025
-
[13]
arXiv preprint arXiv:2601.09269 , year =
RISER: Orchestrating Latent Reasoning Skills for Adaptive Activation Steering , author =. arXiv preprint arXiv:2601.09269 , year =
-
[14]
arXiv preprint arXiv:2501.????? , year =
MetaScale: Test-Time Scaling with Evolving Meta-Thoughts , author =. arXiv preprint arXiv:2501.????? , year =
-
[15]
arXiv preprint arXiv:2501.04682 , year =
Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought , author =. arXiv preprint arXiv:2501.04682 , year =
-
[16]
Steering Language Models With Activation Engineering
Steering Language Models with Activation Engineering , author =. arXiv preprint arXiv:2308.10248 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation Engineering: A Top-Down Approach to AI Transparency , author =. arXiv preprint arXiv:2310.01405 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Base Models Know How to Reason, Thinking Models Learn When , author =
-
[19]
Large Language Models are Zero-Shot Reasoners
Large Language Models are Zero-Shot Reasoners , author =. arXiv preprint arXiv:2205.11916 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
The Eleventh International Conference on Learning Representations , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. The Eleventh International Conference on Learning Representations , year =
-
[21]
Let's Verify Step by Step , author =. arXiv preprint arXiv:2305.20050 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
STaR: Bootstrapping Reasoning With Reasoning
STaR: Bootstrapping Reasoning With Reasoning , author =. arXiv preprint arXiv:2203.14465 , year =
-
[23]
Steering Llama 2 via Contrastive Activation Addition
Steering Llama 2 via Contrastive Activation Addition , author =. arXiv preprint arXiv:2312.06681 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Workshop on Reasoning and Planning for Large Language Models , year =
Understanding Reasoning in Thinking Language Models via Steering Vectors , author =. Workshop on Reasoning and Planning for Large Language Models , year =
-
[26]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author =. arXiv preprint arXiv:2309.08600 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
2024 , note =
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author =. 2024 , note =
2024
-
[28]
arXiv preprint arXiv:2601.03595 , year =
Controllable LLM Reasoning via Sparse Autoencoder-Based Steering , author =. arXiv preprint arXiv:2601.03595 , year =
-
[29]
arXiv preprint arXiv:2504.18587 , year =
Training Large Language Models to Reason via EM Policy Gradient , author =. arXiv preprint arXiv:2504.18587 , year =
-
[30]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. arXiv preprint arXiv:2501.12948 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Scaling LLM Test-Time Compute Optimally Can Be More Effective Than Scaling Model Parameters , author =. arXiv preprint arXiv:2408.03314 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2512.24574 , year=
Understanding and Steering the Cognitive Behaviors of Reasoning Models at Test-Time , author=. arXiv preprint arXiv:2512.24574 , year=
-
[33]
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin
Reasoning-finetuning repurposes latent representations in base models , author=. arXiv preprint arXiv:2507.12638 , year=
-
[34]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
The lessons of developing process reward models in mathematical reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[35]
Large Language Models Cannot Self-Correct Reasoning Yet
Large language models cannot self-correct reasoning yet , author=. arXiv preprint arXiv:2310.01798 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Dissecting Failure Dynamics in Large Language Model Reasoning
Dissecting Failure Dynamics in Large Language Model Reasoning , author=. arXiv preprint arXiv:2604.14528 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
arXiv preprint arXiv:2604.01639 , year=
Fragile Reasoning: A Mechanistic Analysis of LLM Sensitivity to Meaning-Preserving Perturbations , author=. arXiv preprint arXiv:2604.01639 , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
Chain-of-thought reasoning without prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[40]
arXiv preprint arXiv:2501.02497 , year=
A survey of test-time compute: From intuitive inference to deliberate reasoning , author=. arXiv preprint arXiv:2501.02497 , year=
-
[41]
arXiv preprint arXiv:2503.00177 , year=
Steering large language model activations in sparse spaces , author=. arXiv preprint arXiv:2503.00177 , year=
-
[42]
arXiv preprint arXiv:2501.09929 , year=
Interpretable steering of large language models with feature guided activation additions , author=. arXiv preprint arXiv:2501.09929 , year=
-
[43]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Sae-ssv: Supervised steering in sparse representation spaces for reliable control of language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[44]
Steering knowledge selection behaviours in LLMs via sae-based representation engineering , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[45]
arXiv preprint arXiv:2602.10063 , year=
Chain of Mindset: Reasoning with Adaptive Cognitive Modes , author=. arXiv preprint arXiv:2602.10063 , year=
-
[46]
arXiv preprint arXiv:2601.14290 , year=
Project Aletheia: Verifier-Guided Distillation of Backtracking for Small Language Models , author=. arXiv preprint arXiv:2601.14290 , year=
-
[47]
arXiv preprint arXiv:2507.03704 , year=
Controlling thinking speed in reasoning models , author=. arXiv preprint arXiv:2507.03704 , year=
-
[48]
Process reward models that think.arXiv preprint arXiv:2504.16828,
Process reward models that think , author=. arXiv preprint arXiv:2504.16828 , year=
-
[49]
Autoregressive, Yet Revisable: In Decoding Revision for Secure Code Generation
Autoregressive, Yet Revisable: In Decoding Revision for Secure Code Generation , author=. arXiv preprint arXiv:2602.01187 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
arXiv preprint arXiv:2501.15602 , year=
Rethinking external slow-thinking: From snowball errors to probability of correct reasoning , author=. arXiv preprint arXiv:2501.15602 , year=
-
[51]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
LLMs cannot find reasoning errors, but can correct them given the error location , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[52]
Steered LLM Activations are Non-Surjective
Steered LLM Activations are Non-Surjective , author=. arXiv preprint arXiv:2604.09839 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
International Conference on Machine Learning , pages=
Scaling laws for reward model overoptimization , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[54]
arXiv preprint arXiv:2410.12299 , year=
Semantics-adaptive activation intervention for llms via dynamic steering vectors , author=. arXiv preprint arXiv:2410.12299 , year=
-
[55]
arXiv preprint arXiv:2510.13290 , year=
To steer or not to steer? mechanistic error reduction with abstention for language models , author=. arXiv preprint arXiv:2510.13290 , year=
-
[56]
arXiv preprint arXiv:2602.04428 , year=
Fine-Grained Activation Steering: Steering Less, Achieving More , author=. arXiv preprint arXiv:2602.04428 , year=
-
[57]
International Conference on Learning Representations , volume=
Let's verify step by step , author=. International Conference on Learning Representations , volume=
-
[58]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
arXiv preprint arXiv:2507.12885 , year=
VAR-MATH: Probing True Mathematical Reasoning in LLMS via Symbolic Multi-Instance Benchmarks , author=. arXiv preprint arXiv:2507.12885 , year=
-
[60]
Advances in Neural Information Processing Systems , volume=
Solving inequality proofs with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[61]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Least-to-most prompting enables complex reasoning in large language models , author=. arXiv preprint arXiv:2205.10625 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
International Conference on Learning Representations , volume=
Take a step back: Evoking reasoning via abstraction in large language models , author=. International Conference on Learning Representations , volume=
-
[64]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Large language models are better reasoners with self-verification , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[65]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[66]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[67]
arXiv preprint arXiv:2308.00436 , year=
Selfcheck: Using llms to zero-shot check their own step-by-step reasoning , author=. arXiv preprint arXiv:2308.00436 , year=
-
[68]
Findings of the association for computational linguistics: ACL 2024 , pages=
Chain-of-verification reduces hallucination in large language models , author=. Findings of the association for computational linguistics: ACL 2024 , pages=
2024
-
[69]
arXiv preprint arXiv:2509.26314 , year=
Latent thinking optimization: Your latent reasoning language model secretly encodes reward signals in its latent thoughts , author=. arXiv preprint arXiv:2509.26314 , year=
-
[70]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[71]
arXiv preprint arXiv:2601.17897 , year=
UniCog: Uncovering Cognitive Abilities of LLMs through Latent Mind Space Analysis , author=. arXiv preprint arXiv:2601.17897 , year=
-
[72]
arXiv preprint arXiv:2602.01695 , year=
Beyond Dense States: Elevating Sparse Transcoders to Active Operators for Latent Reasoning , author=. arXiv preprint arXiv:2602.01695 , year=
-
[73]
Ren, Hangliang , booktitle =
-
[74]
Advances in Neural Information Processing Systems , volume=
Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model , author=. Advances in Neural Information Processing Systems , volume=
-
[75]
MAA Invitational Competitions: American Invitational Mathematics Examination , author =. n.d. , howpublished =
-
[76]
2024 , howpublished =
2024 AIME I Problems and Solutions , author =. 2024 , howpublished =
2024
-
[77]
2024 , howpublished =
2024 AIME II Problems and Solutions , author =. 2024 , howpublished =
2024
-
[78]
2025 , howpublished =
2025 AIME I Problems and Solutions , author =. 2025 , howpublished =
2025
-
[79]
2025 , howpublished =
2025 AIME II Problems and Solutions , author =. 2025 , howpublished =
2025
-
[80]
2025 , publisher =
AMC 2023 Dataset , author =. 2025 , publisher =
2023
-
[81]
Companion Proceedings of the ACM on Web Conference 2025 , pages=
Apeer: Automatic prompt engineering enhances large language model reranking , author=. Companion Proceedings of the ACM on Web Conference 2025 , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.