MoEIoU: Rethinking Bounding-Box Regression as a Mixture of Experts
Pith reviewed 2026-06-28 18:49 UTC · model grok-4.3
The pith
MoEIoU models bounding-box errors as experts and aggregates them with log-sum-exp plus curriculum weighting to improve regression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
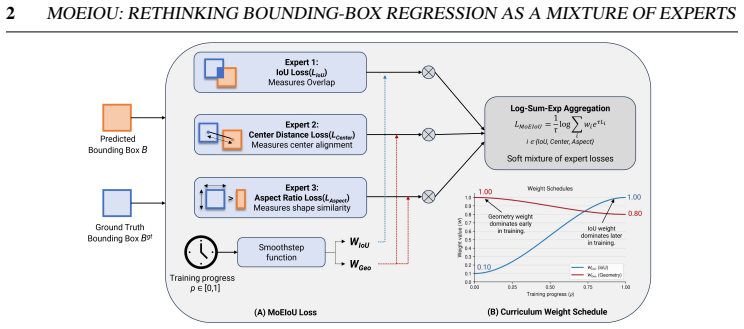
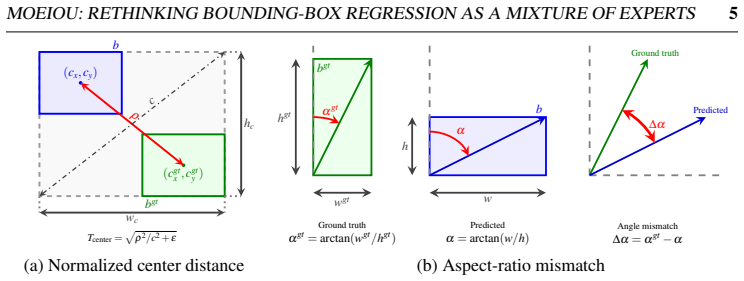
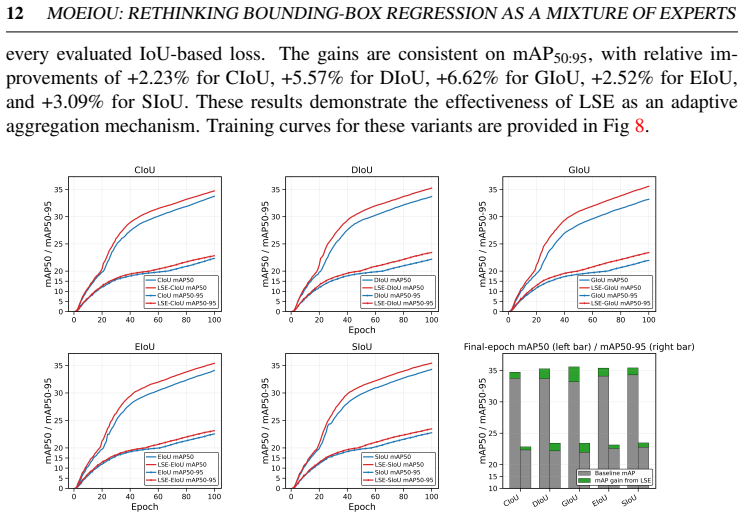
MoEIoU is a mixture-of-experts regression loss that jointly models overlap, center alignment, and aspect-ratio mismatch. It aggregates the three terms with a log-sum-exp function that emphasizes the dominant localization error at each step while keeping contributions from the others smooth. A curriculum-based weighting schedule prioritizes box position and shape in early training and overlap in later stages. Large-scale experiments on multiple YOLO architectures and the listed datasets show consistent gains over both classic and recent state-of-the-art IoU losses in convergence speed and localization accuracy. The same adaptive aggregation can be applied to existing IoU-based losses to yield
What carries the argument
MoEIoU loss, which aggregates overlap, center-distance, and aspect-ratio terms via log-sum-exp and applies curriculum weighting.
If this is right
- Object detectors converge faster when trained with the adaptive loss.
- Localization accuracy rises on PASCAL VOC, HRIPCB, and MS COCO.
- Multiple YOLO architectures obtain measurable gains from the method.
- The adaptive aggregation produces consistent improvements when added to other existing IoU-based losses.
Where Pith is reading between the lines
- Similar dynamic weighting may improve multi-term losses in other vision tasks such as keypoint detection.
- The mixture structure could be tested on three-dimensional bounding-box regression without architectural changes.
- It suggests that stage-aware error emphasis may be more important than the precise functional form of any single penalty term.
Load-bearing premise
The log-sum-exp aggregation combined with the curriculum schedule supplies genuinely superior optimization dynamics rather than simply reweighting the same three terms in a way that happens to fit the chosen schedules and datasets.
What would settle it
Train identical YOLO models on the same MS COCO splits with MoEIoU versus standard GIoU or DIoU and observe no difference in final mAP or number of epochs to reach a given mAP threshold.
Figures


read the original abstract
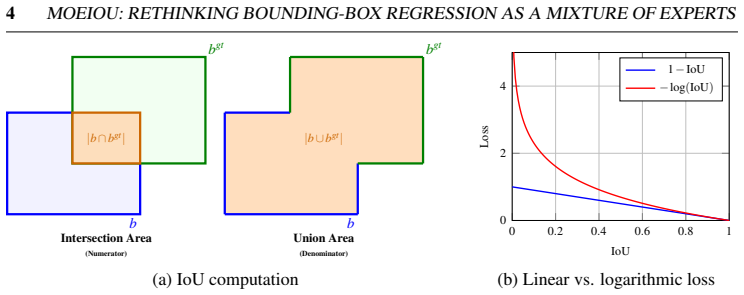
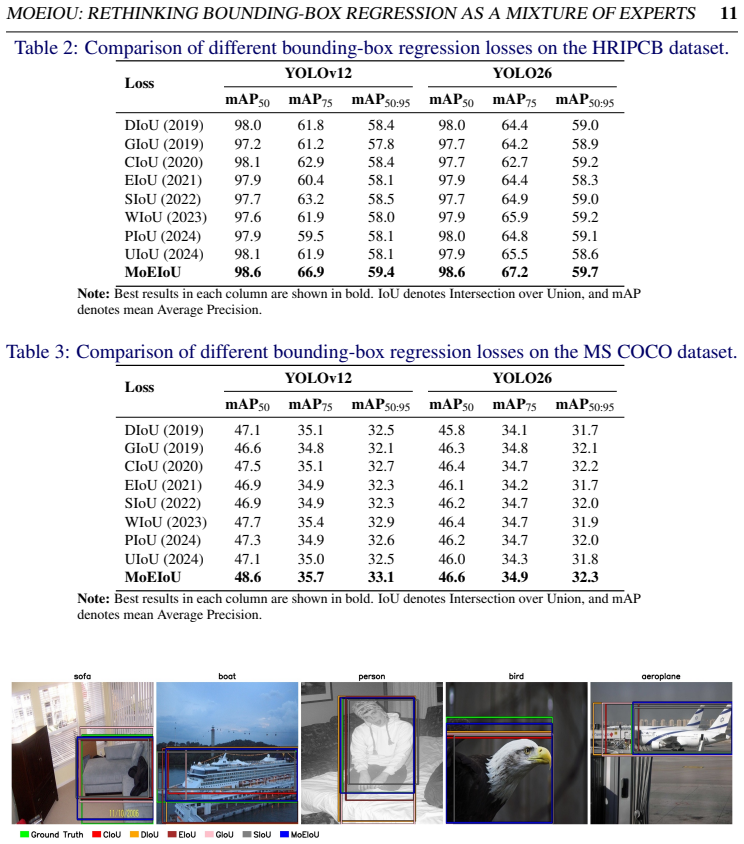
Bounding-box regression is a fundamental component of object detection, playing a critical role in precise object localization. Existing Intersection-over-Union (IoU)-based loss functions extend the IoU objective by incorporating geometric penalties, such as center-distance and aspect-ratio mismatch, to improve bounding-box regression. However, these penalties typically remain fixed throughout training and do not account for the optimization dynamics in which predicted boxes initially exhibit large center-distance and shape errors, with later stages focusing on improving overlap with the ground truth. To address this limitation, we introduce MoEIoU, a mixture-of-experts based regression loss that jointly models overlap, center alignment, and aspect-ratio mismatch. MoEIoU aggregates these components using a log-sum-exp function, which emphasizes the dominant localization error while maintaining smooth contributions from other terms. Additionally, a curriculum-based weighting schedule is employed to prioritize correcting box position and shape in early training stages and improving overlap in later stages. We evaluated proposed MoEIoU on PASCAL VOC, HRIPCB, and MS COCO using multiple YOLO architectures, along with large-scale simulation experiments. It consistently outperforms standard and recent state-of-the-art losses, demonstrating faster convergence and improved localization accuracy. We further show that this adaptive aggregation improves existing IoU-based losses, yielding consistent gains and providing more effective optimization guidance for bounding-box regression in object detection frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MoEIoU, a mixture-of-experts loss for bounding-box regression in object detection. It models overlap, center-distance, and aspect-ratio mismatch as components aggregated via log-sum-exp to emphasize the dominant error, combined with a curriculum schedule that prioritizes position and shape early and overlap later. Evaluations on PASCAL VOC, HRIPCB, and MS COCO with multiple YOLO architectures, plus large-scale simulations, show consistent outperformance over standard and recent IoU losses with faster convergence and better localization.
Significance. If the improvements are due to the adaptive aggregation rather than the curriculum alone, this could provide a useful framework for designing regression losses that account for training dynamics. The inclusion of large-scale simulation experiments is a strength for validating the approach beyond specific datasets. However, the significance is tempered by the need to confirm the source of the gains.
major comments (3)
- [Experimental evaluation] The manuscript does not include an ablation study that compares MoEIoU to a version using a simple convex combination or time-varying weights of the same three geometric terms while retaining the curriculum schedule. This is necessary to rule out that the reported gains stem from the curriculum reweighting rather than the log-sum-exp MoE aggregation, as the latter is a smooth approximation to max that may not introduce fundamentally new dynamics.
- [Loss formulation] The paper claims the log-sum-exp emphasizes the dominant localization error, but without a derivation or analysis showing how this differs from standard weighted sums in terms of gradient flow or convergence properties, the advantage over existing penalties remains unclear.
- [Results tables] The reported performance improvements lack accompanying standard deviations, number of runs, or statistical tests, making it difficult to assess the robustness of the outperformance claims across the YOLO architectures and datasets.
minor comments (2)
- [Abstract] The abstract mentions 'large-scale simulation experiments' but does not specify what these simulations entail or their purpose in the main text.
- Ensure that the curriculum transition schedule parameters are clearly documented to allow reproduction.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experimental evaluation] The manuscript does not include an ablation study that compares MoEIoU to a version using a simple convex combination or time-varying weights of the same three geometric terms while retaining the curriculum schedule. This is necessary to rule out that the reported gains stem from the curriculum reweighting rather than the log-sum-exp MoE aggregation, as the latter is a smooth approximation to max that may not introduce fundamentally new dynamics.
Authors: We agree that an ablation isolating the log-sum-exp aggregation from the curriculum is needed to substantiate the contribution of the MoE component. In the revised manuscript we will add this ablation, comparing MoEIoU against a convex-combination baseline that retains the identical curriculum schedule on the same three geometric terms. revision: yes
-
Referee: [Loss formulation] The paper claims the log-sum-exp emphasizes the dominant localization error, but without a derivation or analysis showing how this differs from standard weighted sums in terms of gradient flow or convergence properties, the advantage over existing penalties remains unclear.
Authors: We will add a dedicated analysis section deriving the gradient-flow behavior of the log-sum-exp aggregator relative to fixed weighted sums, showing how the soft-max-like emphasis on the dominant term alters the optimization trajectory and convergence properties. revision: yes
-
Referee: [Results tables] The reported performance improvements lack accompanying standard deviations, number of runs, or statistical tests, making it difficult to assess the robustness of the outperformance claims across the YOLO architectures and datasets.
Authors: We will rerun the key experiments with multiple random seeds, report standard deviations in all tables, and include paired statistical significance tests to quantify the robustness of the observed gains. revision: yes
Circularity Check
No circularity; loss is explicitly constructed from standard terms and gains are empirical
full rationale
The paper defines MoEIoU directly as log-sum-exp aggregation of the three conventional geometric penalties (IoU overlap, center distance, aspect ratio) plus an explicit curriculum schedule on their weights. The claimed superiority is presented solely as an empirical outcome measured on held-out datasets (PASCAL VOC, HRIPCB, MS COCO) and YOLO backbones; no equation or theorem inside the paper equates the reported performance numbers to any quantity that was fitted or assumed inside the same derivation. No self-citations are invoked to justify uniqueness or to close the argument. The construction is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- curriculum transition schedule
axioms (1)
- standard math log-sum-exp provides a smooth, differentiable approximation to the maximum of several terms
Reference graph
Works this paper leans on
-
[1]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learning, ICML ’09, page 41–48, New York, NY , USA, 2009. Association for Com- puting Machinery. ISBN 9781605585161. doi: 10.1145/1553374.1553380
-
[2]
Weixun Chen, Xuneng Ke, and Siming Meng. Small defect detection in printed circuit boards based on the multiscale edge strengthening and an improved yolov10.Scientific Reports, 15, 10 2025. doi: 10.1038/s41598-025-20387-x
-
[3]
Mark Everingham, Luc Van Gool, Christopher Williams, John Winn, and Andrew Zis- serman. The pascal visual object classes (voc) challenge.International Journal of Computer Vision, 88:303–338, 06 2010. doi: 10.1007/s11263-009-0275-4
-
[4]
Siou loss: More powerful learning for bounding box regression, 2022
Zhora Gevorgyan. Siou loss: More powerful learning for bounding box regression, 2022
2022
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Ross Girshick. Fast r-cnn. In2015 IEEE International Conference on Computer Vision (ICCV), pages 1440–1448, 2015. doi: 10.1109/ICCV .2015.169
-
[6]
Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour
Priya Goyal, Piotr Dollar, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Weibo Huang, Peng Wei, Manhua Zhang, and Hong Liu. Hripcb: a challenging dataset for pcb defects detection and classification.The Journal of Engineering, 2020(13): 303–309, 2020. doi: https://doi.org/10.1049/joe.2019.1183
-
[8]
Peter J. Huber. Robust Estimation of a Location Parameter.The Annals of Math- ematical Statistics, 35(1):73 – 101, 1964. doi: 10.1214/aoms/1177703732. URL https://doi.org/10.1214/aoms/1177703732
-
[9]
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts.Neural Computation, 3:79–87, 1991. doi: https://doi.org/10.1162/neco.1991.3.1.79
-
[10]
Ultralytics yolo26, 2026
Glenn Jocher and Jing Qiu. Ultralytics yolo26, 2026. URLhttps://github. com/ultralytics/ultralytics
2026
-
[11]
Ultralytics YOLO, January 2023
Glenn Jocher, Jing Qiu, and Ayush Chaurasia. Ultralytics YOLO, January 2023. URL https://github.com/ultralytics/ultralytics
2023
-
[12]
Lawrence Zitnick
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft coco: Common ob- jects in context. In David Fleet, Tomas Pajdla, Bernt Schiele, and Tinne Tuyte- laars, editors,Computer Vision – ECCV 2014, pages 740–755, Cham, 2014. Springer International Publishing. ISBN 978-3-319-1060...
2014
-
[13]
Can Liu, Kaige Wang, Qing Li, Fazhan Zhao, Kun Zhao, and Hongtu Ma. Powerful- iou: More straightforward and faster bounding box regression loss with a nonmono- tonic focusing mechanism.Neural Networks, 170:276–284, 2024. ISSN 0893-6080. doi: https://doi.org/10.1016/j.neunet.2023.11.041
-
[14]
Sgdr: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. InInternational Conference on Learning Representations, 2017
2017
-
[15]
Unified-iou: For high-quality object detection, 2024
Xiangjie Luo, Zhihao Cai, Bo Shao, and Yingxun Wang. Unified-iou: For high-quality object detection, 2024
2024
-
[16]
Ken Perlin. Improving noise.ACM Trans. Graph., 21(3):681–682, July 2002. ISSN 0730-0301. doi: 10.1145/566654.566636. URLhttps://doi.org/10.1145/ 566654.566636
-
[17]
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection.2016 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 779–788, 2015. doi: https: //doi.org/10.48550/arXiv.1506.02640. URLhttps://api.semanticscholar. org/CorpusID:206594738
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1506.02640 2016
-
[18]
Generalized Intersection Over Union: A Metric and a Loss for Bound- ing Box Regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Sil- vio Savarese. Generalized Intersection Over Union: A Metric and a Loss for Bound- ing Box Regression . In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 658–666, Los Alamitos, CA, USA, June 2019. IEEE Com- puter Society. doi: 10.1109/CVPR.2019.00075
-
[19]
Houghnet: Integrating near and long-range evidence for bottom-up object detection
Nermin Samet, Samet Hicsonmez, and Emre Akbas. Houghnet: Integrating near and long-range evidence for bottom-up object detection. InComputer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXV, page 406–423, Berlin, Heidelberg, 2020. Springer-Verlag. ISBN 978-3-030-58594-5. doi: 10.1007/978-3-030-58595-2_25
-
[20]
Yolov12: Attention-centric real-time object detectors, 2025
Yunjie Tian, Qixiang Ye, and David Doermann. Yolov12: Attention-centric real-time object detectors, 2025
2025
-
[21]
Wise-iou: Bounding box regres- sion loss with dynamic focusing mechanism, 2023
Zanjia Tong, Yuhang Chen, Zewei Xu, and Rong Yu. Wise-iou: Bounding box regres- sion loss with dynamic focusing mechanism, 2023
2023
-
[22]
Unit- box: An advanced object detection network
Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao, and Thomas Huang. Unit- box: An advanced object detection network. InProceedings of the 24th ACM In- ternational Conference on Multimedia, MM ’16, page 516–520, New York, NY , USA, 2016. Association for Computing Machinery. ISBN 9781450336031. doi: 10.1145/2964284.2967274
-
[23]
Focal and efficient iou loss for accurate bounding box regression.Neurocomputing, 506:146–157, 2022
Yi-Fan Zhang, Weiqiang Ren, Zhang Zhang, Zhen Jia, Liang Wang, and Tieniu Tan. Focal and efficient iou loss for accurate bounding box regression.Neurocomputing, 506:146–157, 2022. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2022.07. 042. MOEIOU: RETHINKING BOUNDING-BOX REGRESSION AS A MIXTURE OF EXPERTS17
-
[24]
Zhong-Qiu Zhao, Peng Zheng, Shou-Tao Xu, and Xindong Wu. Object detection with deep learning: A review.IEEE Transactions on Neural Networks and Learning Sys- tems, 30(11):3212–3232, 2019. doi: 10.1109/TNNLS.2018.2876865
-
[25]
Distance-iou loss: Faster and better learning for bounding box regression
Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, and Dongwei Ren. Distance-iou loss: Faster and better learning for bounding box regression. InPro- ceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 34, pages 12993–13000, 2020. doi: 10.1609/aaai.v34i07.6999
-
[26]
Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, and Wangmeng Zuo. Enhancing geometric factors in model learning and inference for object detection and instance segmentation.IEEE Transactions on Cybernetics, 52: 8574–8586, 2020. doi: 10.48550/arXiv.2005.03572
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.