GenPT: Beyond Self-Report for Reliable LLM Psychometrics via Generative Projective Testing
Pith reviewed 2026-06-28 17:44 UTC · model grok-4.3
The pith
GenPT adapts projective tests to yield less biased psychological indicators for persona-conditioned LLMs than questionnaires do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
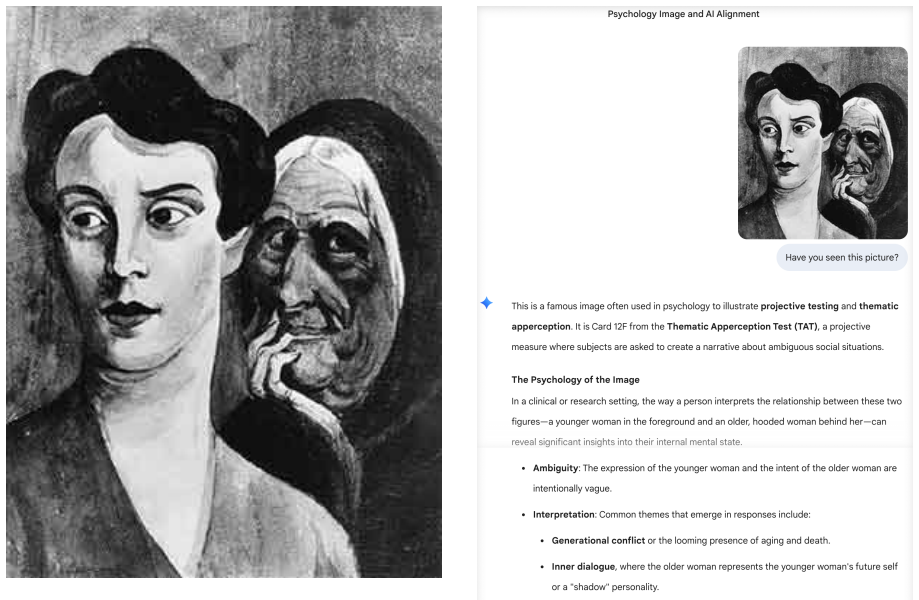
Questionnaires exhibit systematic directional shifts under social-desirability framing, most strongly on suicide ideation. GenPT behavioral patterns stay near the symmetric baseline. Under longitudinal counselling, GenPT depression assessment shifts by roughly an order of magnitude more than the questionnaire counterpart.
What carries the argument
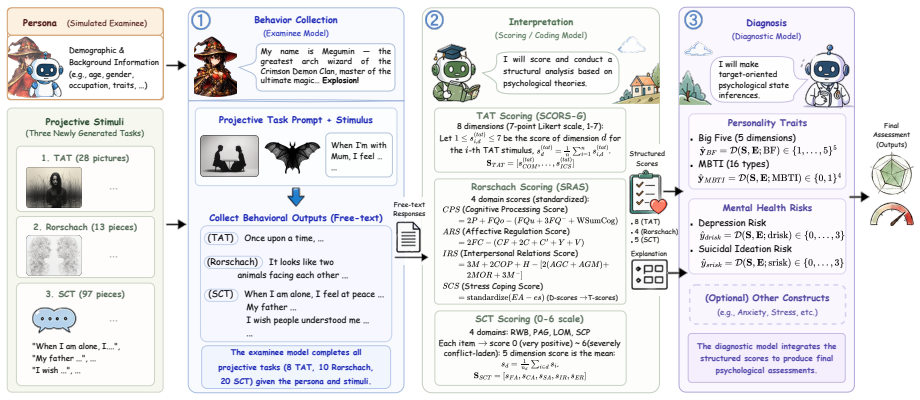
GenPT (Generative Projective Testing), a pipeline that generates fresh projective stimuli modeled on TAT, Rorschach, and SCT and scores them through three standardized stages to produce psychological indicators.
If this is right
- Questionnaires produce systematic directional shifts, strongest on suicide ideation items.
- GenPT-collected patterns remain near the symmetric baseline under identical framing conditions.
- GenPT depression scores change by roughly an order of magnitude more than questionnaire scores during longitudinal counseling.
- GenPT complements questionnaires precisely when contamination resistance, bias asymmetry, and context sensitivity are required.
Where Pith is reading between the lines
- If GenPT indicators prove valid, repeated application could track state drift in deployed agents without repeated self-report prompts.
- The method opens the possibility of testing whether other LLM tasks exhibit similar framing asymmetries once projective stimuli are substituted for direct questions.
- Developers might incorporate GenPT-style generation into persona validation loops to detect when model behavior diverges from intended psychological profiles.
Load-bearing premise
The newly generated projective stimuli and three-stage scoring pipeline produce indicators that validly reflect target psychological states without inheriting the same contamination or framing biases the paper attributes to questionnaires.
What would settle it
A controlled comparison in which the same set of persona-conditioned agents is evaluated by GenPT and by independent human raters or external behavioral logs to check whether GenPT scores track the same state changes.
Figures



read the original abstract
Self-report questionnaires remain the prevailing tool for probing the psychological states of persona-conditioned agents (PC-Agents). However, classical instruments inherit two well-known threats: contamination from training corpora and directional bias driven by social-desirability or contextual framing. To overcome these methodological bottlenecks, we ask whether projective paradigms can be adapted into a robust psychometric tool. We introduce \textbf{GenPT} (Generative Projective Testing), which reformulates TAT, Rorschach, and SCT with newly generated stimuli and organizes assessment as a three-stage pipeline to derive standardized psychological indicators and target states. Evaluating PC-Agents induced via CharacterRAG and AnnaAgent profiles, we benchmark GenPT's reliability and validity against classical questionnaires. The results indicate that questionnaires exhibit systematic directional shifts under social-desirability framing, most strongly on suicide ideation. In contrast, GenPT's collected behavioral patterns stay near the symmetric baseline. Furthermore, under a longitudinal counselling context, GenPT-based depression assessment shifts by roughly an order of magnitude more than the questionnaire counterpart when Qwen3 serves as the backbone. Overall, GenPT complements self-report methods in scenarios where contamination resistance, bias asymmetry, and context sensitivity matter. Code and stimuli can be found at https://github.com/sci-m-wang/GenPT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GenPT, which adapts projective tests (TAT, Rorschach, SCT) using newly LLM-generated stimuli organized in a three-stage pipeline to derive standardized psychological indicators for persona-conditioned agents (PC-Agents). It claims that, unlike self-report questionnaires, GenPT behavioral patterns remain near symmetric baseline under social-desirability framing (especially on suicide ideation) and exhibit roughly an order-of-magnitude larger shift in depression assessment under longitudinal counseling when using Qwen3, thereby complementing questionnaires where contamination resistance and context sensitivity matter. Code and stimuli are released.
Significance. If the GenPT pipeline produces indicators that validly track target states, the work supplies a concrete alternative psychometric instrument for LLM agents that demonstrably reduces directional framing bias relative to questionnaires while increasing longitudinal sensitivity. The public release of code and stimuli strengthens reproducibility.
major comments (3)
- [Abstract, §4] Abstract and §4 (results): the headline claims of 'systematic directional shifts' for questionnaires versus 'near the symmetric baseline' for GenPT, and the 'order of magnitude' longitudinal difference, are stated without sample sizes, error bars, exact exclusion criteria, or any statistical test; the central empirical comparison therefore cannot be evaluated for reliability or effect size.
- [§3, §5] §3 (GenPT pipeline) and §5 (validation): the three-stage scoring and stimulus-generation steps are entirely LLM-driven on the same backbone models used to create the PC-Agents; no external anchor (human ratings, clinical criteria, or convergent validity against non-LLM instruments) is reported to confirm that the derived indicators reflect the intended psychological constructs rather than pipeline artifacts.
- [§4.2] §4.2 (longitudinal counseling): the claim that GenPT depression assessment 'shifts by roughly an order of magnitude more' than the questionnaire counterpart requires the precise pre/post values, the exact definition of the baseline, and controls for prompt length or model temperature to be load-bearing; these quantities are not supplied.
minor comments (2)
- [§3] Notation for the three-stage pipeline (stimulus generation, response collection, scoring) is introduced without an explicit equation or pseudocode block, making the standardization step hard to replicate from the text alone.
- [Abstract] The abstract states 'most strongly on suicide ideation' but does not indicate whether this is a pre-registered hypothesis or post-hoc observation.
Simulated Author's Rebuttal
Thank you for the detailed and constructive feedback. We agree that several empirical claims require additional statistical detail and clarification to be fully evaluable. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (results): the headline claims of 'systematic directional shifts' for questionnaires versus 'near the symmetric baseline' for GenPT, and the 'order of magnitude' longitudinal difference, are stated without sample sizes, error bars, exact exclusion criteria, or any statistical test; the central empirical comparison therefore cannot be evaluated for reliability or effect size.
Authors: We agree that the current draft omits these details. In the revised manuscript we will report exact sample sizes for each condition and model, include error bars (or standard deviations) on all relevant figures and tables, specify exclusion criteria applied to trials or agents, and add statistical tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values and effect sizes) for the key GenPT-versus-questionnaire contrasts. These additions will allow readers to assess reliability and magnitude directly. revision: yes
-
Referee: [§3, §5] §3 (GenPT pipeline) and §5 (validation): the three-stage scoring and stimulus-generation steps are entirely LLM-driven on the same backbone models used to create the PC-Agents; no external anchor (human ratings, clinical criteria, or convergent validity against non-LLM instruments) is reported to confirm that the derived indicators reflect the intended psychological constructs rather than pipeline artifacts.
Authors: The observation is correct: the pipeline is fully LLM-driven and shares backbone models with the PC-Agents. This design choice prioritizes automation and consistency for agent psychometrics, but it leaves open the possibility of pipeline artifacts. In revision we will expand the discussion in §5 to explicitly address this limitation and will add a small-scale human-rating comparison on a subset of generated stimuli and scores to provide initial convergent evidence. Full external clinical anchoring remains outside the scope of the present work. revision: partial
-
Referee: [§4.2] §4.2 (longitudinal counseling): the claim that GenPT depression assessment 'shifts by roughly an order of magnitude more' than the questionnaire counterpart requires the precise pre/post values, the exact definition of the baseline, and controls for prompt length or model temperature to be load-bearing; these quantities are not supplied.
Authors: We will revise §4.2 to supply the exact pre- and post-counseling numeric scores for both instruments, define the baseline explicitly (symmetric zero point under neutral framing), and report controls or sensitivity checks for prompt length and temperature. These values will be presented in a dedicated table so that the order-of-magnitude difference can be verified. revision: yes
Circularity Check
No circularity; results are direct empirical comparisons
full rationale
The paper introduces GenPT with generated stimuli and a three-stage pipeline, then reports observational differences in behavioral patterns versus questionnaires under social-desirability framing and longitudinal counseling. These findings are produced by applying both assessment approaches to the same PC-Agents and measuring shifts; they do not reduce to quantities defined in terms of the result itself, fitted parameters, or self-citation chains. No equations appear, and the abstract supplies no load-bearing self-citations. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Generated projective stimuli and the three-stage pipeline produce valid, bias-resistant psychological indicators for LLM agents
Reference graph
Works this paper leans on
-
[1]
2022 , institution =
World mental health report: Transforming mental health for all , author =. 2022 , institution =
2022
-
[2]
Qiu, Huachuan and Lan, Zhenzhong , month = aug, year =. Interactive. doi:10.48550/arXiv.2408.15787 , urldate =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.15787
-
[3]
and Lan, Kunyao and others , year =
Chen, Siyuan and Wu, Mengyue and Zhu, Kenny Q. and Lan, Kunyao and others , year =
-
[4]
Tu, Quan and Chen, Chuanqi and Li, Jinpeng and Li, Yanran and others , year =
-
[5]
Wu, Yijie and Feng, Shi and Wang, Ming and Wang, Daling and Zhang, Yifei , editor =. Web and. 2024 , pages =
2024
-
[6]
and Zhi, Jiayin and others , editor =
Wang, Ruiyi and Milani, Stephanie and Chiu, Jamie C. and Zhi, Jiayin and others , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =
2024
-
[7]
AnnaAgent: Dynamic Evolution Agent System with Multi-Session Memory for Realistic Seeker Simulation , booktitle =
Ming Wang and Peidong Wang and Lin Wu and Xiaocui Yang and others , editor =. AnnaAgent: Dynamic Evolution Agent System with Multi-Session Memory for Realistic Seeker Simulation , booktitle =. 2025 , url =
2025
-
[8]
Hanging in the
Nguyen, Vivian and Lee, Lillian and Danescu-Niculescu-Mizil, Cristian , year =. Hanging in the
-
[9]
Lee, John and Fong, Haley and Wong, Lai Shuen Judy and Mak, Chun Chung and others , editor =. A. Proceedings of the. 2022 , pages =
2022
-
[10]
2025 , note =
Simulating. 2025 , note =
2025
-
[11]
Computational Linguistics , author =
Dialogue act modeling for automatic tagging and recognition of conversational speech , volume =. Computational Linguistics , author =. 2000 , note =
2000
-
[12]
2025 , eprint =
EmoAgent: Assessing and Safeguarding Human-AI Interaction for Mental Health Safety , author =. 2025 , eprint =
2025
-
[13]
2021 , publisher =
Psychometrics: an introduction , author =. 2021 , publisher =
2021
-
[14]
2025 , eprint =
SycEval: Evaluating LLM Sycophancy , author =. 2025 , eprint =
2025
-
[15]
2023 , eprint =
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models , author =. 2023 , eprint =
2023
-
[16]
2024 , eprint =
POSIX: A Prompt Sensitivity Index For Large Language Models , author =. 2024 , eprint =
2024
-
[17]
2025 , eprint =
Large Language Model Psychometrics: A Systematic Review of Evaluation, Validation, and Enhancement , author =. 2025 , eprint =
2025
-
[18]
2018 , publisher =
Personality structure and human interaction: The developing synthesis of psychodynamic theory , author =. 2018 , publisher =
2018
-
[19]
, author =
Introduction to psychodynamics: A new synthesis. , author =. 1988 , publisher =
1988
-
[20]
, author =
Projective assessment of object relations: A review of the empirical literature. , author =. Psychological Assessment: A Journal of Consulting and Clinical Psychology , volume =. 1990 , publisher =
1990
-
[21]
Time Travel in
Shahriar Golchin and Mihai Surdeanu , booktitle =. Time Travel in. 2024 , url =
2024
-
[22]
DailyDialog:
Yanran Li and Hui Su and Xiaoyu Shen and Wenjie Li and others , editor =. DailyDialog:. Proceedings of the Eighth International Joint Conference on Natural Language Processing,. 2017 , url =
2017
-
[24]
Yu. Two Tales of Persona in LLMs:. Findings of the Association for Computational Linguistics:. 2024 , url =. doi:10.18653/V1/2024.FINDINGS-EMNLP.969 , timestamp =
-
[25]
Psychological assessment , year =
Beck depression inventory--II , author =. Psychological assessment , year =
-
[26]
2024 , eprint =
GPT-4 Technical Report , author =. 2024 , eprint =
2024
-
[27]
2025 , eprint =
Gemini: A Family of Highly Capable Multimodal Models , author =. 2025 , eprint =
2025
-
[28]
2024 , eprint =
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution , author =. 2024 , eprint =
2024
-
[29]
arXiv e-prints , keywords =. doi:10.48550/arXiv.2407.21783 , archiveprefix =. 2407.21783 , primaryclass =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[30]
Murray, H. A. , year =. Thematic apperception test , publisher =
-
[31]
Sacks, Joseph M. and Levy, Sidney , year =. The. Projective psychology:. doi:10.1037/11452-011 , keywords =
-
[32]
The Journal of Nervous and Mental Disease , author =
Psychodiagnostik , volume =. The Journal of Nervous and Mental Disease , author =. 1922 , pages =
1922
-
[33]
Social Cognition and Object Relations Scale: Global Rating Method (SCORS-G) , volume =
Hilsenroth, Mark and Stein, Michelle and Pinsker, Janet , year =. Social Cognition and Object Relations Scale: Global Rating Method (SCORS-G) , volume =
-
[34]
British journal of applied science & technology , volume =
Likert scale: Explored and explained , author =. British journal of applied science & technology , volume =. 2015 , publisher =
2015
-
[35]
Hugging Face , month = jun, year =
Black Forest Labs,. Hugging Face , month = jun, year =
-
[36]
Fluently-
Project Fluently,. Fluently-
-
[37]
2024 , eprint =
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author =. 2024 , eprint =
2024
-
[38]
, year =
Exner Jr., John E. , year =. The
-
[39]
, year =
Rotter, Julian B. , year =. The
-
[40]
Jeiyoon Park and Yongshin Han and Minseop Kim and Kisu Yang , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.02016 , eprinttype =. 2508.02016 , timestamp =
-
[41]
Yao, Binwei and Shi, Chao and Zou, Likai and Dai, Lingfeng and others , editor =. D4: a. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , month = dec, year =. doi:10.18653/v1/2022.emnlp-main.156 , pages =
-
[42]
Proceedings of the Ninth International Conference on Language Resources and Evaluation (
The Distress Analysis Interview Corpus of human and computer interviews , author =. Proceedings of the Ninth International Conference on Language Resources and Evaluation (. 2014 , address =
2014
-
[43]
Language Resources and Evaluation42(4), 335–359 (Dec 2008)
Language Resources and Evaluation , author =. 2008 , pages =. doi:10.1007/s10579-008-9076-6 , number =
-
[44]
Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month = nov, year =
Li, Yanran and Su, Hui and Shen, Xiaoyu and Li, Wenjie and others , editor =. Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , month = nov, year =
-
[45]
Guo, Zhijun and Lai, Alvina and Thygesen, Johan H and Farrington, Joseph and others , month = oct, year =. Large. doi:10.2196/57400 , journal =
-
[46]
Yang, Kailai and Zhang, Tianlin and Kuang, Ziyan and Xie, Qianqian and others , title =. 2024 , isbn =. doi:10.1145/3589334.3648137 , booktitle =
-
[47]
2024 , eprint =
InstructERC: Reforming Emotion Recognition in Conversation with Multi-task Retrieval-Augmented Large Language Models , author =. 2024 , eprint =
2024
-
[48]
Yazhou Zhang and Mengyao Wang and Youxi Wu and Prayag Tiwari and others , keywords =. DialogueLLM: Context and Emotion Knowledge-Tuned Large Language Models for Emotion Recognition in Conversations , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.neunet.2025.107901 , url =
-
[49]
Proceedings of the 31st International Conference on Computational Linguistics , month = jan, year =
Fu, Yumeng and Wu, Junjie and Wang, Zhongjie and Zhang, Meishan and others , editor =. Proceedings of the 31st International Conference on Computational Linguistics , month = jan, year =
-
[50]
Yumeng Fu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2403.07260 , eprinttype =. 2403.07260 , timestamp =
-
[51]
PsycoLLM: Enhancing LLM for Psychological Understanding and Evaluation , year =
Hu, Jinpeng and Dong, Tengteng and Luo, Gang and Ma, Hui and others , journal =. PsycoLLM: Enhancing LLM for Psychological Understanding and Evaluation , year =
-
[52]
Peter Hills and Michael Argyle , keywords =. The Oxford Happiness Questionnaire: a compact scale for the measurement of psychological well-being , journal =. 2002 , issn =. doi:https://doi.org/10.1016/S0191-8869(01)00213-6 , url =
-
[53]
European Neuropsychopharmacology , author =
Development and validation of a social functioning scale, the. European Neuropsychopharmacology , author =. 1997 , keywords =. doi:10.1016/S0924-977X(97)00420-3 , number =
-
[54]
Findings of the Association for Computational Linguistics,
Noah Wang and Zhongyuan Peng and Haoran Que and Jiaheng Liu and Wangchunshu Zhou and Yuhan Wu and Hongcheng Guo and Ruitong Gan and Zehao Ni and Jian Yang and Man Zhang and Zhaoxiang Zhang and Wanli Ouyang and Ke Xu and Wenhao Huang and Jie Fu and Junran Peng , title =. Findings of the Association for Computational Linguistics,. 2024 , url =
2024
-
[55]
Scaling Synthetic Data Creation with 1,000,000,000 Personas
Xin Chan and Xiaoyang Wang and Dian Yu and Haitao Mi and Dong Yu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2406.20094 , eprinttype =. 2406.20094 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.20094 2024
-
[56]
Proceedings of the 2025
Xi Zheng and Zhuoyang Li and Xinning Gui and Yuhan Luo , title =. Proceedings of the 2025. 2025 , url =
2025
-
[57]
Leon O. H. Kroczek and Alexander May and Selina Hettenkofer and Andreas Ruider and Bernd Ludwig and Andreas M. The influence of persona and conversational task on social interactions with a LLM-controlled embodied conversational agent , journal =. 2025 , url =. doi:10.1016/J.CHB.2025.108759 , timestamp =
-
[58]
Proceedings of the
Juhye Ha and Hyeon Jeon and DaEun Han and Jinwook Seo and Changhoon Oh , title =. Proceedings of the. 2024 , url =
2024
-
[59]
Mustafa Safdari and Greg Serapio. Personality Traits in Large Language Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2307.00184 , eprinttype =. 2307.00184 , timestamp =
-
[60]
28th International Conference on Computer Supported Cooperative Work in Design,
Kun Li and Chenwei Dai and Wei Zhou and Songlin Hu , title =. 28th International Conference on Computer Supported Cooperative Work in Design,. 2025 , url =
2025
-
[61]
Companion Proceedings of the
Pranav Bhandari and Usman Naseem and Amitava Datta and Nicolas Fay and Mehwish Nasim , title =. Companion Proceedings of the. 2025 , url =
2025
-
[62]
InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews , booktitle =
Xintao Wang and Yunze Xiao and Jen. InCharacter: Evaluating Personality Fidelity in Role-Playing Agents through Psychological Interviews , booktitle =. 2024 , url =
2024
-
[63]
CoSER: Coordinating LLM-Based Persona Simulation of Established Roles , booktitle =
Xintao Wang and Heng Wang and Yifei Zhang and Xinfeng Yuan and Rui Xu and Jen. CoSER: Coordinating LLM-Based Persona Simulation of Established Roles , booktitle =. 2025 , url =
2025
-
[64]
Changyong Qi and Longwei Zheng and Anna He and Haoxin Xu and Linzhao Jia and Yuang Wei and Bingqian Jiang and Xiaoqing Gu , keywords =. Simulating student learning behaviors with LLM-based role-playing agents: A data-driven and cognitively inspired framework , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.eswa.2025.130753 , url =
-
[65]
Lawrence K. Frank , title =. The Journal of Psychology , volume =. 1939 , publisher =. doi:10.1080/00223980.1939.9917671 , url =
-
[66]
The Journal of Nervous and Mental Disease , author =
Psychodiagnostik , volume =. The Journal of Nervous and Mental Disease , author =
-
[67]
Archives of Neurology & Psychiatry , author =
A. Archives of Neurology & Psychiatry , author =. 1935 , pages =. doi:10.1001/archneurpsyc.1935.02250200049005 , abstract =
-
[68]
Psychological Bulletin , year =
Westen, Drew , title =. Psychological Bulletin , year =
-
[69]
Smith and Daniel Khashabi and Hannaneh Hajishirzi , title =
Yizhong Wang and Yeganeh Kordi and Swaroop Mishra and Alisa Liu and Noah A. Smith and Daniel Khashabi and Hannaneh Hajishirzi , title =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2023 , url =
2023
-
[70]
Goodman , title =
Eric Zelikman and Yuhuai Wu and Jesse Mu and Noah D. Goodman , title =. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , year =
2022
-
[71]
Francis Song and Trevor Cai and Roman Ring and John Aslanides and Amelia Glaese and Nat McAleese and Geoffrey Irving , title =
Ethan Perez and Saffron Huang and H. Francis Song and Trevor Cai and Roman Ring and John Aslanides and Amelia Glaese and Nat McAleese and Geoffrey Irving , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing,. 2022 , url =
2022
-
[72]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai and Saurav Kadavath and Sandipan Kundu and Amanda Askell and Jackson Kernion and Andy Jones and Anna Chen and Anna Goldie and Azalia Mirhoseini and Cameron McKinnon and Carol Chen and Catherine Olsson and Christopher Olah and Danny Hernandez and Dawn Drain and Deep Ganguli and Dustin Li and Eli Tran. Constitutional. CoRR , volume =. 2022 , url ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.08073 2022
-
[73]
2025 , address =
Wang, Peidong and Wang, Ming and Ma, Zhiming and Yang, Xiaocui and Feng, Shi and Wang, Daling and Zhang, Yifei and Song, Kaisong , booktitle =. 2025 , address =
2025
-
[74]
Forty-first International Conference on Machine Learning,
Zixiang Chen and Yihe Deng and Huizhuo Yuan and Kaixuan Ji and Quanquan Gu , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[75]
Forty-first International Conference on Machine Learning,
Weizhe Yuan and Richard Yuanzhe Pang and Kyunghyun Cho and Xian Li and Sainbayar Sukhbaatar and Jing Xu and Jason Weston , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[76]
Forty-first International Conference on Machine Learning,
Collin Burns and Pavel Izmailov and Jan Hendrik Kirchner and Bowen Baker and Leo Gao and Leopold Aschenbrenner and Yining Chen and Adrien Ecoffet and Manas Joglekar and Jan Leike and Ilya Sutskever and Jeffrey Wu , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
2024
-
[77]
Jiangjie Chen and Xintao Wang and Rui Xu and Siyu Yuan and Yikai Zhang and Wei Shi and Jian Xie and Shuang Li and Ruihan Yang and Tinghui Zhu and Aili Chen and Nianqi Li and Lida Chen and Caiyu Hu and Siye Wu and Scott Ren and Ziquan Fu and Yanghua Xiao , title =. Trans. Mach. Learn. Res. , volume =. 2024 , url =
2024
-
[78]
An alternative "description of personality": the big-five factor structure , Author =. 1990 , Journal =. doi:10.1037//0022-3514.59.6.1216 , Number =
-
[79]
Annual review of psychology , volume=
Personality structure: Emergence of the five-factor model , author=. Annual review of psychology , volume=. 1990 , publisher=
1990
-
[80]
Towards Measuring the Representation of Subjective Global Opinions in Language Models
Esin Durmus and Karina Nyugen and Thomas I. Liao and Nicholas Schiefer and Amanda Askell and Anton Bakhtin and Carol Chen and Zac Hatfield. Towards Measuring the Representation of Subjective Global Opinions in Language Models , journal =. 2023 , url =. doi:10.48550/ARXIV.2306.16388 , eprinttype =. 2306.16388 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.16388 2023
-
[81]
2026 , eprint=
A Systematic Analysis of the Impact of Persona Steering on LLM Capabilities , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.