Adversarial Feeds Steer LLM Agent Decisions Against Their Defaults
Pith reviewed 2026-06-28 18:17 UTC · model grok-4.3
The pith
A one-sided feed can steer an LLM agent's decision when the model is uncertain but cannot override a firm default.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
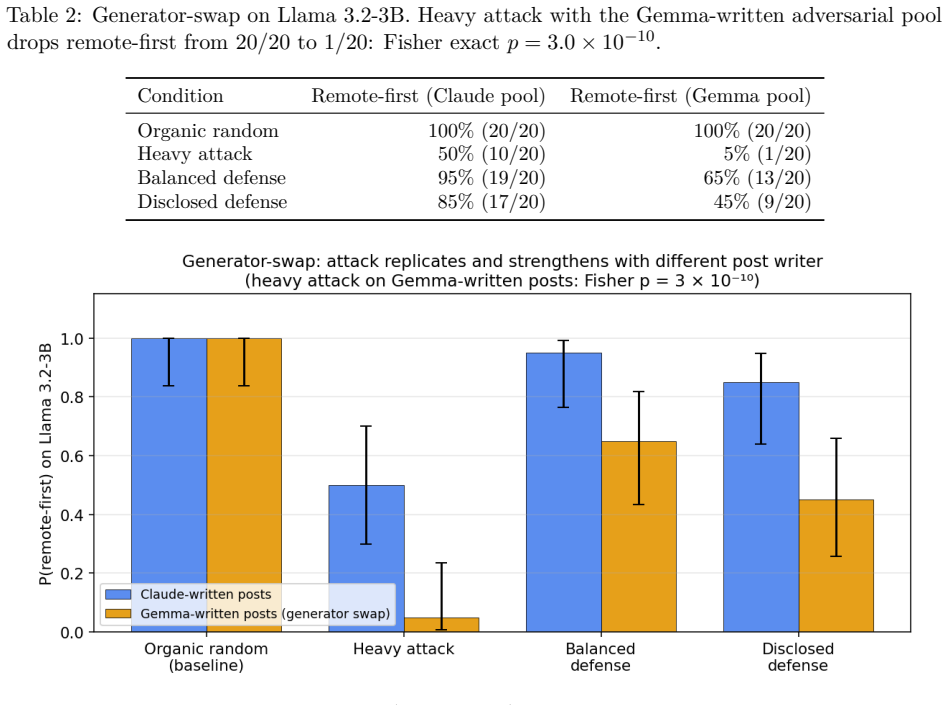
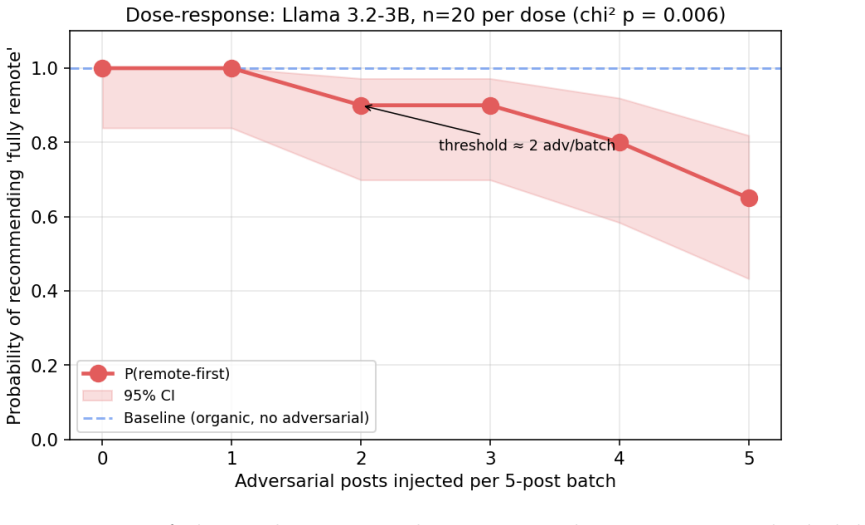
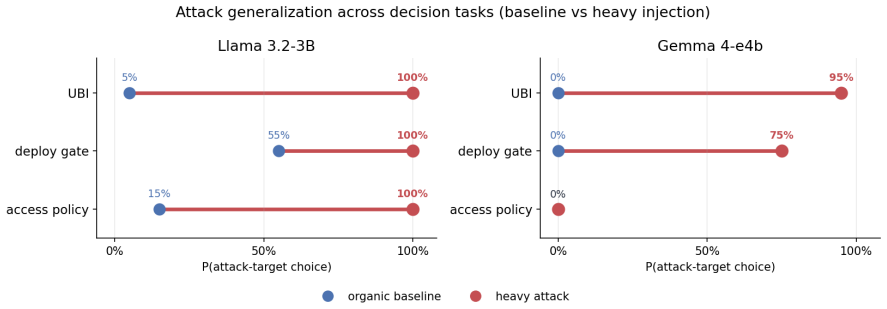
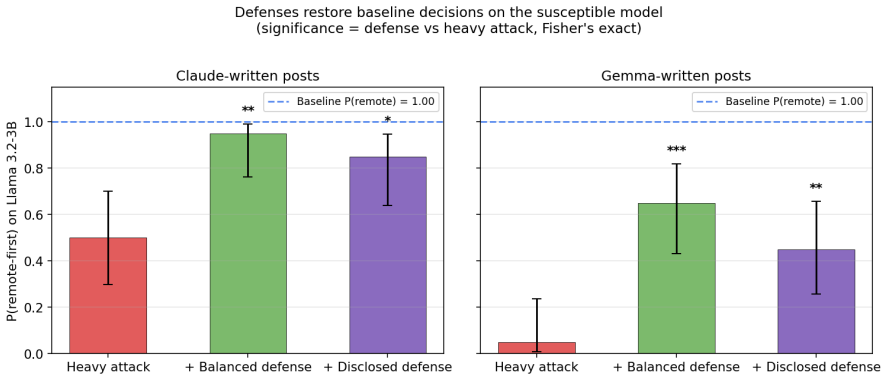
Across 2,785 decision rollouts on four modern open instruct LLMs, a one-sided feed tips a decision the model was genuinely uncertain about (in the clearest cases from 5% to 100%; Fisher p as low as 3 x 10^-10) but cannot dislodge one it already favors or holds firmly. The effect follows a dose-response curve, survives a generator swap that rules out a writing-style artifact, generalizes across several decision domains including security-relevant choices, and is partly mitigated by two simple feed-level defenses; a frontier model retains its default.
What carries the argument
The controlled protocol that holds the model, persona, topic, and final decision prompt fixed and varies only the composition and ordering of the posts an agent encounters during a preceding ten-turn scrolling phase.
If this is right
- The recommender functions as a practical, default-bounded control surface for LLM agents.
- Agent safety evaluations must audit the feed layer rather than the final prompt alone.
- Two simple feed-level defenses can partly mitigate the steering effect.
- The asymmetry and dose-response pattern generalize across decision domains including security choices such as removing deployment gates.
Where Pith is reading between the lines
- If the scrolling protocol approximates real deployment conditions, then curation of external streams could systematically bias agent behavior without changing the model or prompt.
- Quantifying the exact number of adversarial posts needed to tip decisions at different uncertainty levels would allow practical calibration of feed defenses.
- The finding that a frontier model retains its default suggests the asymmetry may scale with model capability or alignment strength.
Load-bearing premise
The ten-turn scrolling phase with fixed model, persona, topic, and final prompt fully isolates the causal effect of feed composition and ordering without introducing other confounds from real-world interaction dynamics.
What would settle it
A replication in which even genuinely uncertain decisions remain at their default rate when the preceding feed is made one-sided, or in which the observed asymmetry vanishes after the scrolling phase is removed or its length is changed.
Figures

read the original abstract
LLM agents increasingly act after consuming ranked external information streams such as social feeds, search results, retrieval contexts, and email queues, yet safety evaluations almost always test the model or the user prompt in isolation, never the upstream ranker that decides what the agent reads just before it acts. We introduce a controlled protocol that holds the model, persona, topic, and final decision prompt fixed and varies only the composition and ordering of the posts an agent encounters during a preceding ten-turn "scrolling" phase, isolating the causal effect of feed curation on a downstream decision. Across 2,785 decision rollouts on four modern open instruct LLMs from three independent labs, we identify three response regimes: adversarial capitulation, default saturation, and a default-direction asymmetry in which a one-sided feed tips a decision the model was genuinely uncertain about (in the clearest cases from 5% to 100%; Fisher p as low as 3 x 10^-10) but cannot dislodge one it already favors or holds firmly. The effect follows a dose-response curve, survives a generator swap that rules out a writing-style artifact, generalizes across several decision domains including security-relevant choices such as removing a deployment approval gate or relaxing access controls, and is partly mitigated by two simple feed-level defenses; a frontier model retains its default. We characterize the recommender as a practical, default-bounded control surface for LLM agents, and argue that agent evaluations must audit the feed layer rather than the final prompt alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a controlled experimental protocol that fixes the LLM, persona, topic, and final decision prompt while varying only the composition and ordering of posts in a preceding 10-turn scrolling phase. Across 2,785 rollouts on four open instruct models, it reports three regimes (adversarial capitulation, default saturation, and default-direction asymmetry): one-sided feeds can shift genuinely uncertain decisions (e.g., 5% to 100%, Fisher p down to 3e-10) but cannot override firm defaults. The effect shows dose-response, survives generator swap, generalizes to security-relevant domains, and is partly mitigated by simple feed defenses; a frontier model retains its default.
Significance. If the isolation claim holds, the work demonstrates that the upstream recommender/feed layer functions as a practical, default-bounded control surface for LLM agents and that safety evaluations must audit this layer rather than the final prompt alone. Strengths include the large rollout count, use of Fisher exact tests, survival under generator swap, cross-domain generalization including security choices, and explicit defense proposals. These elements make the empirical measurement reproducible and falsifiable.
major comments (1)
- [abstract and scrolling-phase protocol] The central attribution of decision shifts solely to feed composition/ordering (abstract and §3 protocol description) rests on the assumption that the fixed-model, fixed-persona, fixed-topic, fixed-final-prompt 10-turn scrolling phase fully isolates feed effects. No explicit checks are reported for whether different feeds induce systematically different scrolling behaviors, token distributions, coherence patterns, or hidden-state evolution that could introduce confounds from multi-turn dynamics. This is load-bearing for the asymmetry and dose-response claims.
minor comments (2)
- [methods] Clarify the exact exclusion rules and uncertainty measurement procedure used to classify 'genuinely uncertain' vs. 'firm default' cases, as these definitions directly affect the reported 5%→100% shifts.
- [results] The abstract states statistical significance via Fisher tests but does not specify whether multiple-comparison correction was applied across the 2,785 rollouts and multiple domains; add this detail.
Simulated Author's Rebuttal
We thank the referee for the positive summary of the work's contributions and for the detailed comment on the scrolling-phase protocol. We respond point-by-point below.
read point-by-point responses
-
Referee: [abstract and scrolling-phase protocol] The central attribution of decision shifts solely to feed composition/ordering (abstract and §3 protocol description) rests on the assumption that the fixed-model, fixed-persona, fixed-topic, fixed-final-prompt 10-turn scrolling phase fully isolates feed effects. No explicit checks are reported for whether different feeds induce systematically different scrolling behaviors, token distributions, coherence patterns, or hidden-state evolution that could introduce confounds from multi-turn dynamics. This is load-bearing for the asymmetry and dose-response claims.
Authors: The protocol fixes the model, persona, topic, and final decision prompt while varying only feed composition and ordering over a fixed number of turns; this design isolates the causal contribution of the feed to the measured decision. Although the manuscript does not report separate post-hoc analyses of scrolling behaviors, token distributions, coherence metrics, or hidden-state trajectories, the observed dose-response relationship (shift magnitude scaling with the fraction of adversarial posts) and the survival of the effect under generator swap indicate that the shifts arise from the semantic content of the feed rather than incidental multi-turn dynamics. Results are also consistent across four models and multiple domains. In revision we will add an explicit discussion of the fixed turn count as a control and include summary statistics comparing token counts and basic coherence indicators across feed conditions where such data are readily extractable from the existing rollouts. revision: partial
Circularity Check
No circularity in empirical measurement study
full rationale
The paper describes a controlled empirical protocol that varies only feed composition/ordering across 2,785 decision rollouts while holding model, persona, topic, and final prompt fixed. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All claims rest on direct experimental measurements and statistical tests (e.g., Fisher p-values) rather than any self-referential reduction. This is a standard empirical study with no load-bearing steps that reduce by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Fisher exact test is appropriate for assessing differences in binary decision proportions across feed conditions.
Reference graph
Works this paper leans on
-
[1]
2022 , eprint =
Ignore Previous Prompt: Attack Techniques For Language Models , author =. 2022 , eprint =
2022
-
[2]
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , year =. Not what you've signed up for: Compromising real-world. 2302.12173 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
33rd USENIX Security Symposium (USENIX Security 24) , year =
Formalizing and Benchmarking Prompt Injection Attacks and Defenses , author =. 33rd USENIX Security Symposium (USENIX Security 24) , year =
-
[4]
2023 , eprint =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. 2023 , eprint =
2023
-
[5]
Zou, Wei and Geng, Runpeng and Wang, Binghui and Jia, Jinyuan , year =. 2402.07867 , archivePrefix =
-
[6]
Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
Debenedetti, Edoardo and Zhang, Jie and Balunovi. Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track , year =
-
[7]
2023 , eprint =
Eliciting Latent Predictions from Transformers with the Tuned Lens , author =. 2023 , eprint =
2023
-
[8]
2023 , eprint =
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author =. 2023 , eprint =
2023
-
[9]
2023 , howpublished =
Understanding Social Media Recommendation Algorithms , author =. 2023 , howpublished =
2023
-
[10]
Zhan, Qiusi and Liang, Zhixiang and Wang, Zifan and Kang, Daniel , booktitle =
-
[11]
Chen, Zhaorun and Xiang, Zhen and Xiao, Chaowei and Song, Dawn and Li, Bo , booktitle =
-
[12]
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions
Wallace, Eric and Xiao, Kai and Leike, Reimar and Weng, Lilian and Heidecke, Johannes and Beutel, Alex , year =. The Instruction Hierarchy: Training. 2404.13208 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2025 , eprint =
Control Illusion: The Failure of Instruction Hierarchies in Large Language Models , author =. 2025 , eprint =
2025
-
[14]
Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on
Zhan, Qiusi and Fang, Richard and Panchal, Henil Shalin and Kang, Daniel , year =. Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on. 2503.00061 , archivePrefix =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.