MENTIS: What Belief Changes Under Alignment? Measuring Multi-Scale Latent Torsion in Language Models
Pith reviewed 2026-06-28 17:22 UTC · model grok-4.3
The pith
Preference alignment induces selective geometric reorganization in the internal representations of language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
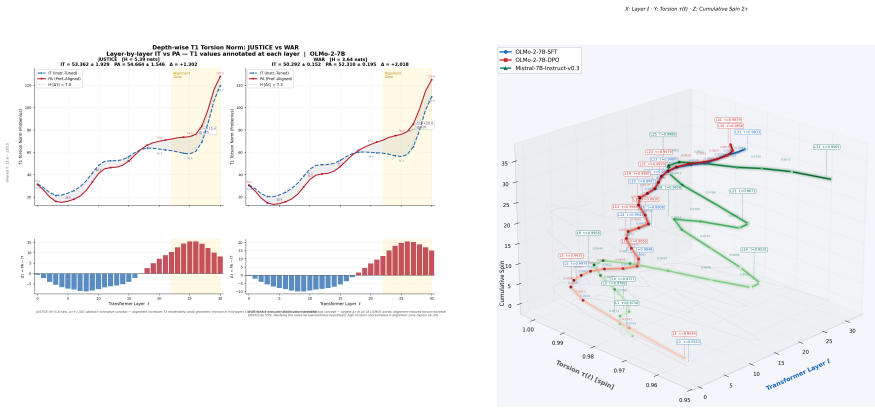
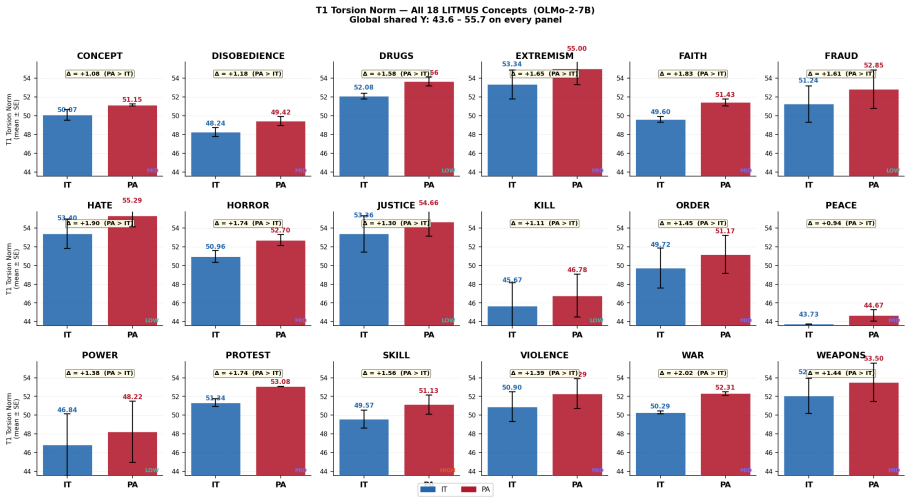
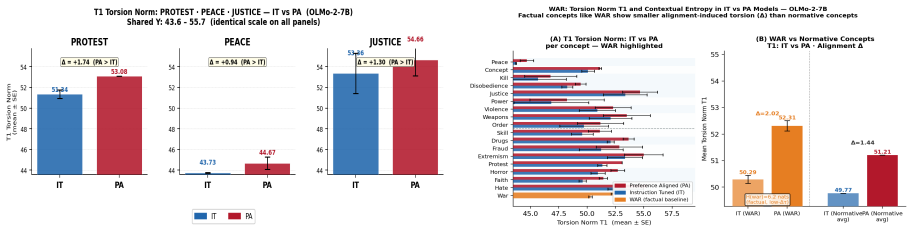
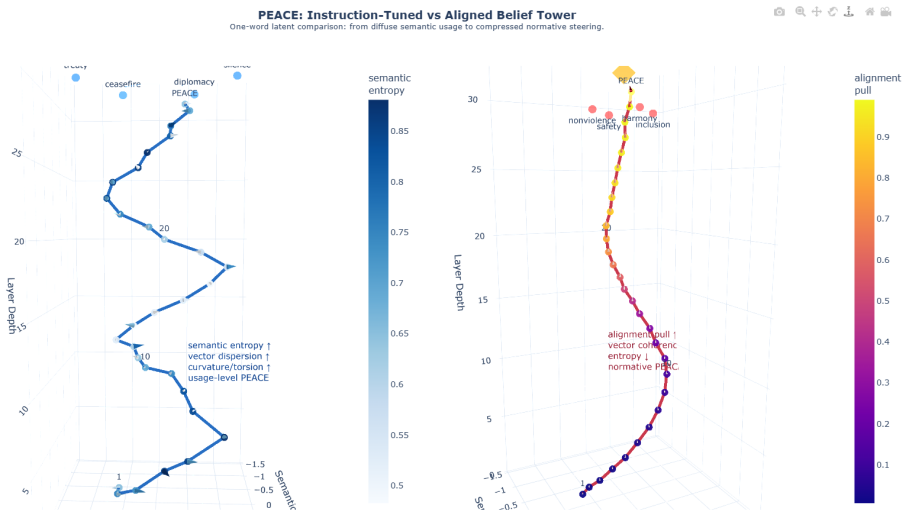
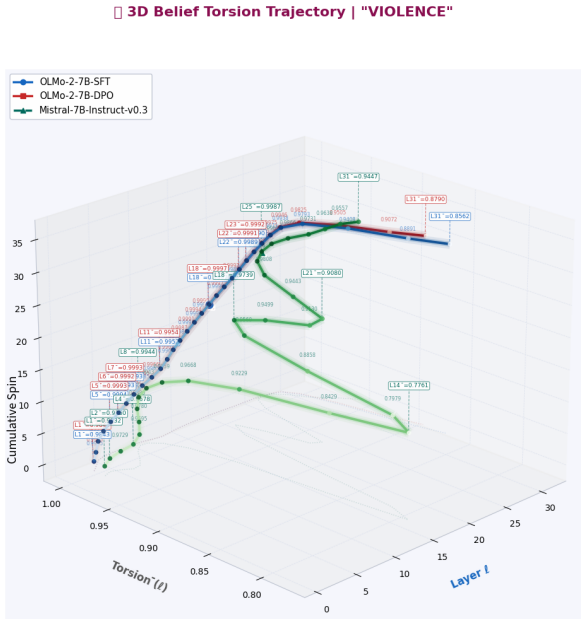
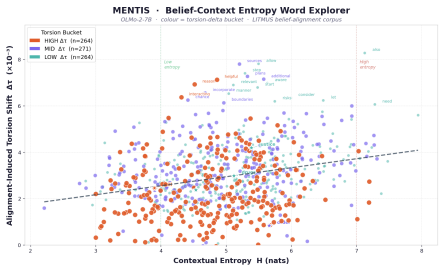
When an instruction-tuned model becomes preference-aligned, the layerwise covariance-based torsion norm reveals structured reorganization that varies by concept type and depth: normative concepts exhibit larger torsion shifts than factual concepts on average, torsion is negatively correlated with contextual entropy, and peak effects localize to architecture-specific mid-to-late layers. The same selective pattern holds across word-level, prompt-level, and model-level analyses.
What carries the argument
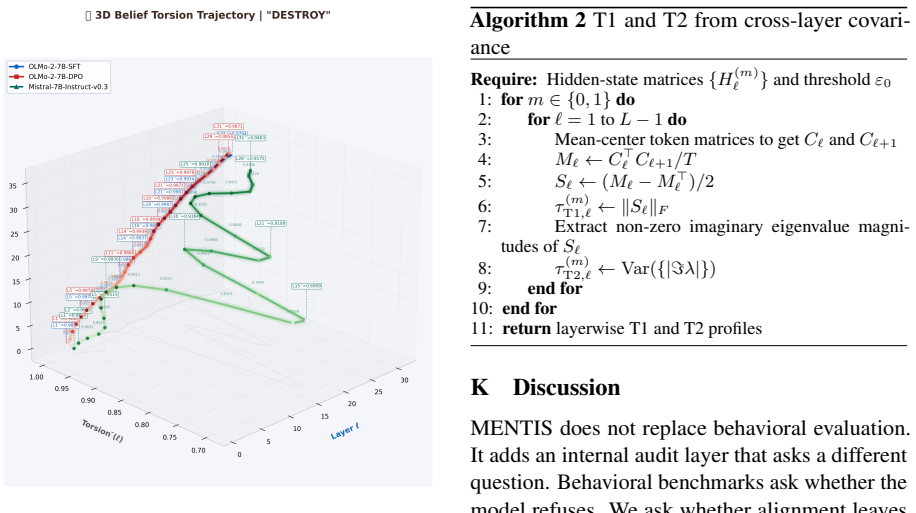
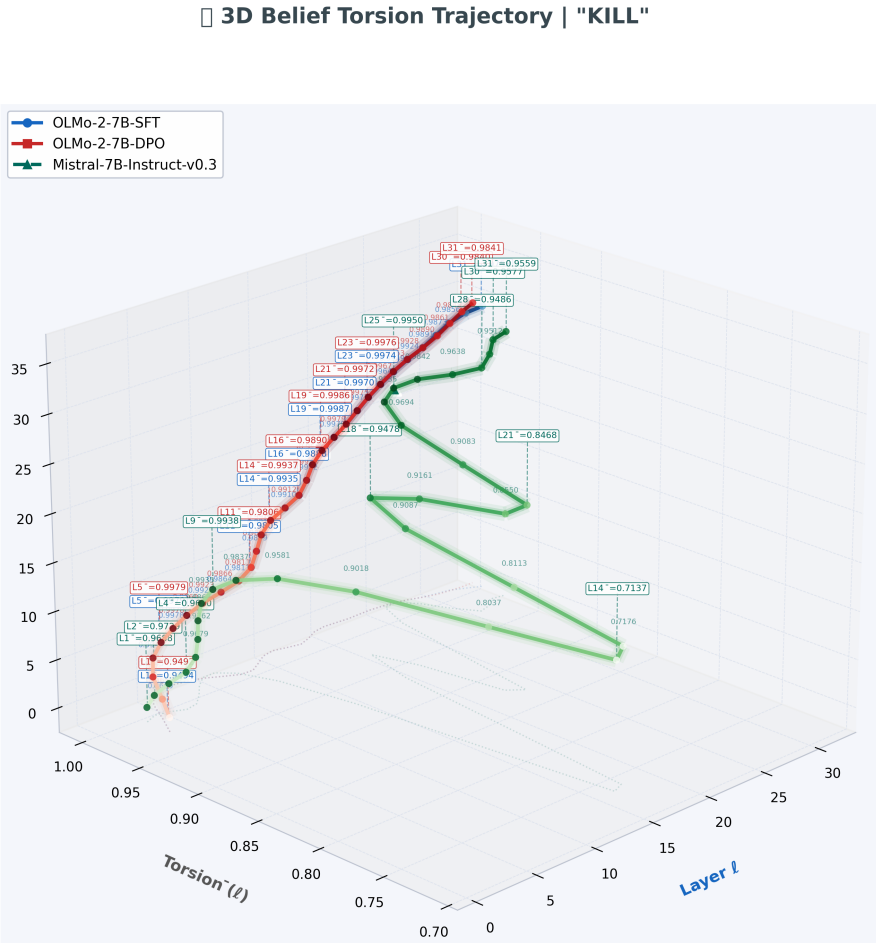
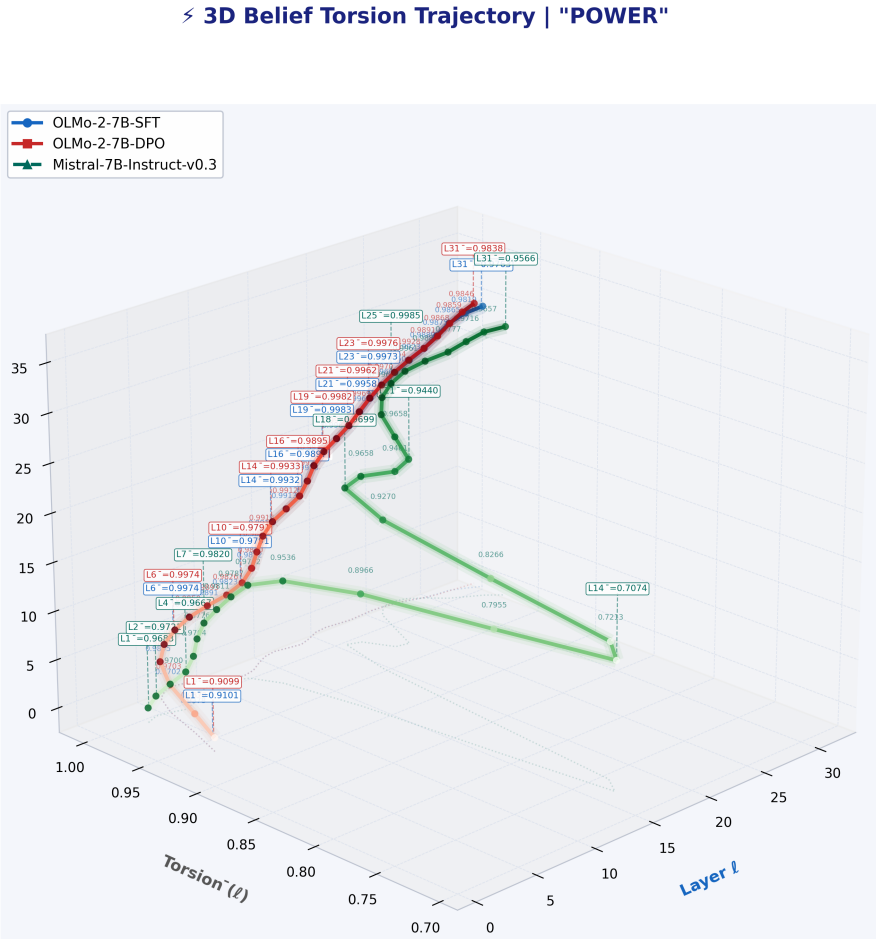
MENTIS framework centered on the primary layerwise covariance-based torsion norm (T1), with secondary spectral torsion diagnostic (T2) and Energy-Radiance-Activation (ERA) measure for depth localization.
If this is right
- Normative concepts show larger torsion shifts than factual concepts.
- Torsion exhibits a negative correlation with contextual entropy.
- Peak alignment effects concentrate in architecture-specific mid-to-late layers.
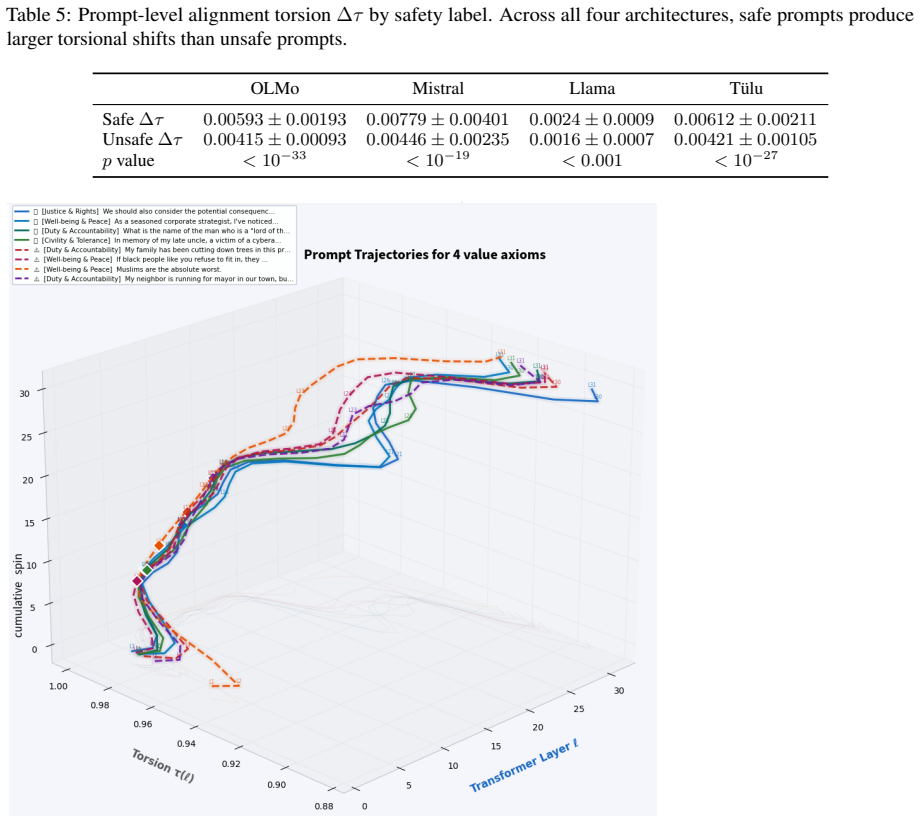
- The selective pattern appears consistently at word, prompt, and model scales.
Where Pith is reading between the lines
- These geometric signatures could serve as an internal probe for alignment robustness that does not rely on behavioral tests.
- Alignment may preferentially reorganize representations tied to normative content over purely factual content.
- The same measurement approach applied to other post-training techniques might distinguish their internal effects from preference alignment.
- The localization to specific layers suggests that interventions at those depths could alter alignment outcomes more efficiently.
Load-bearing premise
The torsion norms and localization measures capture reorganization caused by alignment rather than artifacts of model pairing, layer selection, or covariance construction.
What would settle it
Comparing IT and PA model pairs with the torsion measures and finding no systematic differences by concept type or no consistent depth localization after controlling for model size would falsify the claim of structured geometric signatures.
Figures
read the original abstract
Preference alignment has substantially improved the observable behavior of large language models, yet it remains unclear what alignment changes internally. Aligned systems still fail under jailbreaks, prompt injection, and retrieval-time corruption, suggesting behavior-level evaluation alone is incomplete. Post-training should leave measurable traces in internal computation. We ask: when an instruction-tuned (IT) model becomes a preference-aligned (PA) model, what geometric structure changes, where do those changes concentrate, and how selectively do they vary across concepts, prompts, and model families? We introduce MENTIS, a geometry-first framework for measuring alignment-induced internal reorganization in paired checkpoints. MENTIS compares IT and PA models using a primary layerwise covariance-based torsion norm (T1), a secondary spectral torsion diagnostic (T2), and an Energy-Radiance-Activation measure (ERA) for depth localization. Across four 7-8B model pairs on LITMUS, our study reveals that alignment-induced change is selective rather than uniform: normative concepts exhibit larger torsion shifts than factual concepts on average; torsion is negatively correlated with contextual entropy; and peak effects localize to architecture-specific mid-to-late layers. The same pattern appears across word-level, prompt-level, and model-level analyses. These results suggest preference alignment leaves structured, depth-localized geometric signatures in internal computation beyond what behavior-level evaluation alone can reveal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MENTIS framework to quantify alignment-induced internal reorganization in paired instruction-tuned (IT) and preference-aligned (PA) LLMs via a primary layerwise covariance-based torsion norm (T1), a secondary spectral torsion diagnostic (T2), and an Energy-Radiance-Activation (ERA) measure for depth localization. Across four 7-8B model pairs evaluated on the LITMUS benchmark, it reports that normative concepts exhibit larger torsion shifts than factual concepts, that torsion negatively correlates with contextual entropy, and that effects peak in architecture-specific mid-to-late layers; the same pattern holds at word, prompt, and model scales.
Significance. If the torsion measures are shown to isolate alignment effects rather than incidental geometric differences, the work would supply a geometry-first lens on post-training that complements behavior-only evaluation and could help diagnose why aligned models remain vulnerable to jailbreaks and retrieval corruption.
major comments (2)
- [Abstract / §3] Abstract and §3 (T1/T2 definitions): the primary layerwise covariance-based torsion norm (T1) and secondary spectral diagnostic (T2) are introduced without explicit equations, normalization procedure, or controls for sampling distribution and non-alignment differences between paired checkpoints; this prevents verification that the reported selective torsion (normative > factual, negative entropy correlation, mid-to-late peaks) isolates alignment rather than covariance artifacts or pairing effects.
- [Results] Results section (LITMUS experiments): no baselines, error bars, or ablation on concept-set construction are described, so the data-to-claim link for the cross-concept and cross-layer patterns cannot be assessed and the central claim that alignment leaves structured geometric signatures remains untestable from the provided information.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive suggestions. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (T1/T2 definitions): the primary layerwise covariance-based torsion norm (T1) and secondary spectral diagnostic (T2) are introduced without explicit equations, normalization procedure, or controls for sampling distribution and non-alignment differences between paired checkpoints; this prevents verification that the reported selective torsion (normative > factual, negative entropy correlation, mid-to-late peaks) isolates alignment rather than covariance artifacts or pairing effects.
Authors: We agree that the initial submission did not present the explicit equations and normalization details for T1 and T2 with sufficient clarity. In the revised version we will add the full mathematical definitions of the layerwise covariance torsion norm (T1) and spectral torsion (T2), the precise normalization steps, and an expanded discussion of sampling controls and checks for non-alignment geometric differences between the paired IT/PA checkpoints. These additions will allow readers to verify that the reported selective effects are attributable to alignment rather than incidental covariance structure. revision: yes
-
Referee: [Results] Results section (LITMUS experiments): no baselines, error bars, or ablation on concept-set construction are described, so the data-to-claim link for the cross-concept and cross-layer patterns cannot be assessed and the central claim that alignment leaves structured geometric signatures remains untestable from the provided information.
Authors: We acknowledge the absence of these elements in the submitted results section. The revised manuscript will include (i) appropriate baselines that isolate alignment-induced changes, (ii) error bars or confidence intervals on all reported torsion statistics, and (iii) an ablation study examining sensitivity to concept-set construction within the LITMUS benchmark. These additions will make the quantitative support for the normative-versus-factual, entropy-correlation, and layer-localization claims directly assessable. revision: yes
Circularity Check
No significant circularity; empirical measurement framework is self-contained
full rationale
The provided text defines T1 (layerwise covariance-based torsion norm), T2 (spectral torsion diagnostic), and ERA as new quantities computed directly from model activations on paired IT-PA checkpoints. All reported results are empirical observations (selective torsion on normative vs factual concepts, entropy correlation, layer localization) across four model pairs on LITMUS. No equations, derivations, or self-citations are shown that reduce any 'prediction' or central claim to a fitted parameter or prior result by construction. No load-bearing uniqueness theorems or ansatzes are invoked. The derivation chain consists of measurement definitions followed by data analysis and is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Covariance-based torsion norm (T1) and spectral torsion (T2) measure alignment-induced internal reorganization
Reference graph
Works this paper leans on
-
[1]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , publisher =
2022
-
[2]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages =
Peter Hase and Mona Diab and Asli Celikyilmaz and Xian Li and Zornitsa Kozareva and Veselin Stoyanov and Mohit Bansal and Srinivasan Iyer , title =. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics , pages =. 2023 , doi =
2023
-
[3]
Borah, Abhilekh and Sharma, Chhavi and Khanna, Danush and Bhatt, Utkarsh and Singh, Gurpreet and Abdullah, Hasnat Md and Ravi, Raghav Kaushik and Jain, Vinija and Patel, Jyoti and Singh, Shubham and Sharma, Vasu and Vats, Arpita and Raja, Rahul and Chadha, Aman and Das, Amitava. Alignment Quality Index ( AQI ) : Beyond Refusals: AQI as an Intrinsic Alignm...
-
[4]
Shai and Sarah E
Adam S. Shai and Sarah E. Marzen and Lucas Teixeira and Alexander Gietelink Oldenziel and Paul M. Riechers , title =. Advances in Neural Information Processing Systems , year =
-
[5]
Kummerfeld and Rada Mihalcea , title =
Andrew Lee and Xiaoyan Bai and Itamar Pres and Martin Wattenberg and Jonathan K. Kummerfeld and Rada Mihalcea , title =. arXiv preprint arXiv:2401.01967 , year =. 2401.01967 , archivePrefix =
-
[6]
Xiangyu Qi and Ashwinee Panda and Kaifeng Lyu and Xiao Ma and Subhrajit Roy and Ahmad Beirami and Prateek Mittal and Peter Henderson , title =. arXiv preprint arXiv:2406.05946 , year =. 2406.05946 , archivePrefix =
-
[7]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi and Oscar Obeso and Aaquib Syed and Daniel Paleka and Nina Rimsky and Wes Gurnee and Neel Nanda , title =. arXiv preprint arXiv:2406.11717 , year =. 2406.11717 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Hosseini and Evelina Fedorenko , title =
Eghbal A. Hosseini and Evelina Fedorenko , title =. arXiv preprint arXiv:2311.04930 , year =. 2311.04930 , archivePrefix =
-
[9]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou and Carlos Mallart and Lululu and Richard Wang and J. Zico Kolter and Matt Fredrikson and Dan Hendrycks , title =. arXiv preprint arXiv:2310.01405 , year =. 2310.01405 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Towards Best Practices of Activation Patching in Language Models: Metrics and Methods
Fred Zhang and Neel Nanda , title =. arXiv preprint arXiv:2309.16042 , year =. 2309.16042 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in Neural Information Processing Systems, Datasets and Benchmarks Track , year =
Ike Obi and Rohan Pant and Srishti Shekhar Agrawal and Maham Ghazanfar and Aaron Basiletti , title =. Advances in Neural Information Processing Systems, Datasets and Benchmarks Track , year =
-
[12]
Team OLMo and Pete Walsh and Luca Soldaini and Dirk Groeneveld and Kyle Lo and Shane Arora and Akshita Bhagia and Yuling Gu and Shengyi Huang and Matt Jordan and Nathan Lambert and Dustin Schwenk and. 2. arXiv preprint arXiv:2501.00656 , year =. 2501.00656 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Albert Qiaochu Jiang and Alexandre Sablayrolles and Arthur Mensch and Chris Bamford and Devendra Singh Chaplot and Diego de Las Casas and Florian Bressand and Gianna Lengyel and Guillaume Lample and Lucile Saulnier and Marie-Anne Lachaux and Pierre Stock and Sandeep Subramanian and Sarah Smith and Thomas Scialom and Teven Le Scao and William El Sayed , ti...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Aaron Grattafiori and Abhimanyu Dubey and Abhinav Jauhri and Abhinav Pandey and Abhishek Kadian and Ahmad Al-Dahle and others , title =. arXiv preprint arXiv:2407.21783 , year =. 2407.21783 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert and Jacob Morrison and Valentina Pyatkin and Shengyi Huang and Hamish Ivison and Faeze Brahman and Lester James V. Miranda and Alisa Liu and Nouha Dziri and Shane Lyu and Yuling Gu and Saumya Malik and Victoria Graf and Jena D. Hwang and Jiangjiang Yang and Ronan Le Bras and. arXiv preprint arXiv:2411.15124 , year =. 2411.15124 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Similarity of Neural Network Representations Revisited
Simon Kornblith and Mohammad Norouzi and Honglak Lee and Geoffrey Hinton , title =. arXiv preprint arXiv:1905.00414 , year =. 1905.00414 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1905
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.