Deep Research as Rubric for Reinforcement Learning
Pith reviewed 2026-06-28 17:14 UTC · model grok-4.3
The pith
Reframing rubric construction as an evidence-driven research process via iterative multi-turn agentic search yields scalable fine-grained reward signals for open-ended tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
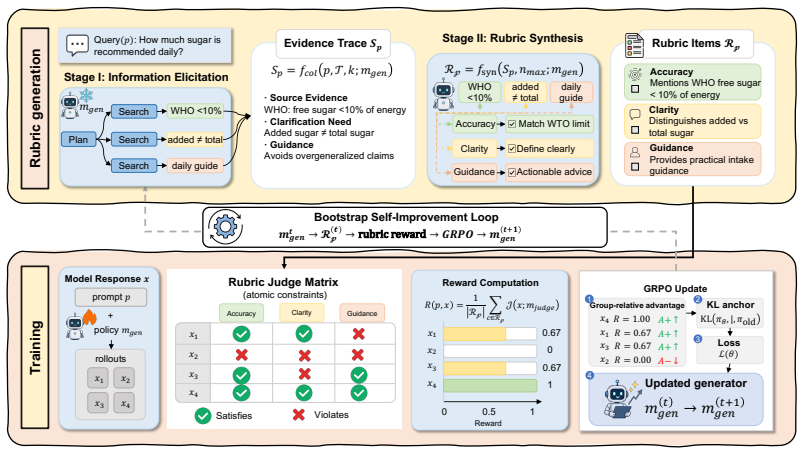
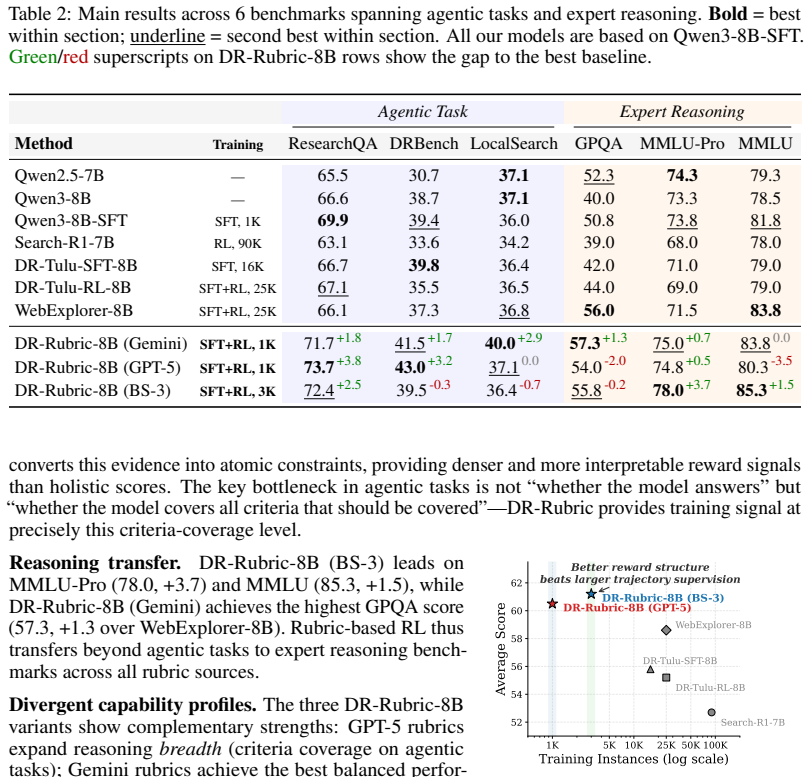
DR-rubric is a two-stage framework in which Stage I elicits domain facts, structural constraints, and failure modes through iterative multi-turn agentic search, and Stage II distills this evidence into atomic, independently verifiable constraints. These constraints serve as reward signals for GRPO-based policy optimization. Because the model under training can serve as its own rubric generator, the method supports bootstrap rubric generation without frontier-model assistance. On six benchmarks spanning agentic research and expert reasoning, the approach achieves strong competitive performance with only 1K-3K training instances; GPT-5-generated rubrics benefit breadth coverage on agentic task
What carries the argument
The DR-rubric two-stage framework, where Stage I performs iterative multi-turn agentic search to synthesize evidence and Stage II distills it into atomic verifiable constraints used as reward signals.
If this is right
- The training model can generate its own rubrics, enabling bootstrap refinement without external frontier models.
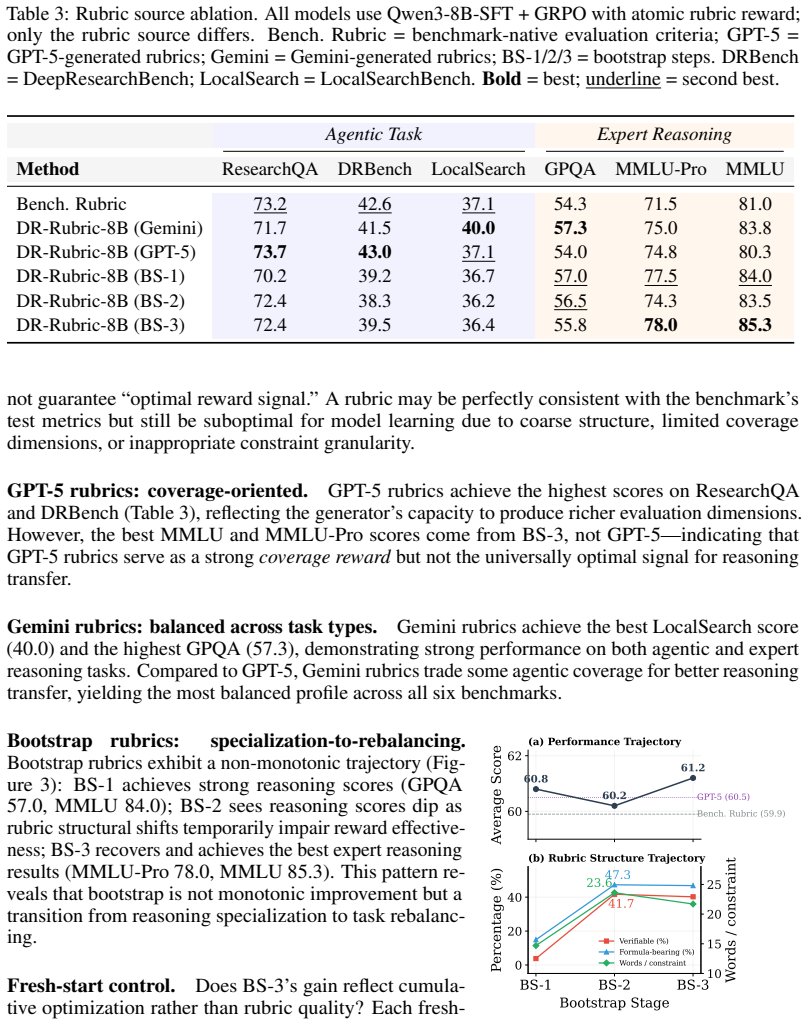
- GPT-5-generated rubrics improve breadth coverage specifically on agentic tasks.
- Gemini-generated rubrics deliver the most balanced results across both agentic and expert-reasoning benchmarks.
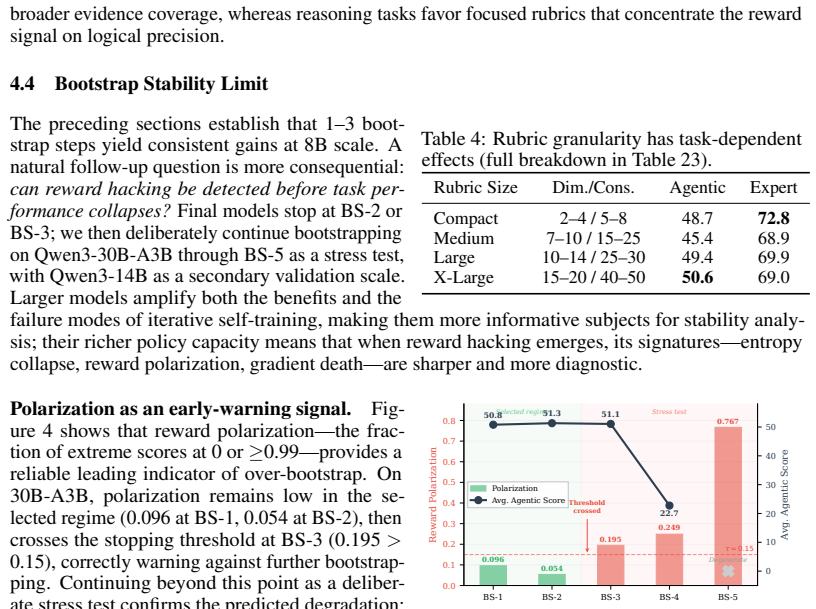
- Bootstrap rubrics evolve through specialization then rebalancing, reaching peak performance at the third iteration.
- Competitive policy optimization is possible on the tested benchmarks with training sets as small as 1K-3K instances.
Where Pith is reading between the lines
- The same evidence-driven rubric process could be applied to create reward signals for other open-ended domains such as creative writing or scientific hypothesis generation.
- Self-generated rubrics open the possibility of closed-loop self-improvement in which each training cycle produces better constraints for the next.
- Mixing rubric sources (for example, agentic-search rubrics for breadth with expert-reasoning rubrics for depth) might produce task-specific hybrids superior to any single source.
- The discovered failure modes could be reused as diagnostic tools to evaluate models even outside the reinforcement-learning setting.
Load-bearing premise
Iterative multi-turn agentic search can reliably discover and synthesize the task-specific, knowledge-intensive dimensions and failure modes that matter most for the target task.
What would settle it
A controlled experiment in which policies trained with DR-rubric constraints show no improvement over policies trained with static hand-crafted or simple prompt-generated rubrics on the same six benchmarks using identical 1K-3K instance counts and GRPO settings.
Figures

read the original abstract
Open-ended reasoning and long-form generation tasks lack reliable automatic verification signals for reward-based policy optimization. Rubrics offer a promising alternative, but existing approaches treat them as given artifacts -- either hand-crafted or prompt-generated -- and often miss the task-specific, knowledge-intensive dimensions that matter most, distorting the reward signal. Our key observation is that rubric construction is itself a research problem: identifying what makes a response correct or insightful requires discovering and synthesizing external knowledge. We propose Deep Research as Rubric (DR-rubric), a two-stage framework for constructing such rubrics. Stage I elicits domain facts, structural constraints, and failure modes through iterative multi-turn agentic search; Stage II distills this evidence into atomic, independently verifiable constraints for GRPO-based policy optimization. Because the model under training can serve as its own rubric generator, DR-rubric-8B supports bootstrap rubric generation without frontier-model assistance. We evaluate on 6 benchmarks spanning agentic research and expert reasoning. Experiments show that DR-Rubric achieves strong competitive performance with only 1K -- 3K training instances, where GPT-5-generated rubrics particularly benefit breadth coverage on agentic tasks, Gemini-generated rubrics yield the most balanced performance across agentic and expert reasoning tasks, and bootstrap rubrics exhibit a specialization-to-rebalancing evolution achieving the best overall performance at the third iteration. Results demonstrate that reframing rubric construction from static evaluation templates into an evidence-driven research process yields more scalable, fine-grained reward signals for open-ended tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Deep Research as Rubric (DR-rubric), a two-stage framework that reframes rubric construction for RL policy optimization as an evidence-driven research process. Stage I performs iterative multi-turn agentic search to discover domain facts, structural constraints, and failure modes; Stage II distills the evidence into atomic, independently verifiable constraints used for GRPO-based optimization. The approach supports bootstrap rubric generation with an 8B model and is evaluated on 6 benchmarks spanning agentic research and expert reasoning, claiming competitive performance with 1K–3K training instances, generator-dependent strengths, and progressive improvement across bootstrap iterations.
Significance. If the empirical claims hold, the work could advance reward design for open-ended tasks by replacing static or prompt-generated rubrics with synthesized, task-specific constraints derived from external knowledge, offering a scalable alternative that reduces reliance on frontier models while improving fine-grained signal quality.
major comments (2)
- [Abstract] Abstract: the central claim of 'strong competitive performance' on 6 benchmarks with only 1K–3K instances is stated without any metrics, baselines, error bars, ablation results, or experimental protocol, rendering the primary empirical contribution impossible to assess or replicate from the supplied text.
- [Abstract] Abstract (Stage I description): the assumption that iterative multi-turn agentic search 'reliably discovers and synthesizes the task-specific, knowledge-intensive dimensions and failure modes' is presented as an observed outcome without any validation, human evaluation, or failure-case analysis of the search process itself.
minor comments (1)
- [Abstract] The abstract refers to 'GRPO-based policy optimization' and 'bootstrap rubric generation' without defining the acronyms or the precise optimization objective on first use.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address each major comment below, clarifying that the full manuscript supplies the requested experimental details while agreeing to strengthen the abstract and add limitations discussion where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'strong competitive performance' on 6 benchmarks with only 1K–3K instances is stated without any metrics, baselines, error bars, ablation results, or experimental protocol, rendering the primary empirical contribution impossible to assess or replicate from the supplied text.
Authors: The abstract is a concise summary constrained by length limits. The full manuscript provides all requested elements in Section 4 (Tables 1–3 report exact metrics, baselines including standard GRPO and prompt-generated rubrics, and comparisons across the 6 benchmarks) and Section 3 (full experimental protocol with 1K–3K instance counts and training details). Results include means and standard deviations from multiple runs. We will revise the abstract to include one or two representative quantitative results. revision: yes
-
Referee: [Abstract] Abstract (Stage I description): the assumption that iterative multi-turn agentic search 'reliably discovers and synthesizes the task-specific, knowledge-intensive dimensions and failure modes' is presented as an observed outcome without any validation, human evaluation, or failure-case analysis of the search process itself.
Authors: The abstract summarizes the observed outcome. The manuscript provides supporting evidence via progressive performance gains across bootstrap iterations (Section 4.3) and qualitative examples of generated atomic constraints in the appendix, which illustrate coverage of domain facts and failure modes. We agree that explicit human evaluation of the search process itself is absent and will add a limitations paragraph addressing this and potential failure cases. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents DR-rubric as an empirical two-stage engineering framework (agentic search followed by distillation into verifiable constraints) evaluated on benchmarks. No equations, fitted parameters, predictions of derived quantities, or load-bearing self-citations appear in the abstract or described claims. The bootstrap evolution is reported as an observed experimental outcome across iterations rather than a definitional identity or fitted input renamed as prediction. The central claim—that reframing rubric construction as research yields better rewards—rests on external benchmark results and does not reduce to its own inputs by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rubric construction is itself a research problem that benefits from iterative external knowledge synthesis via agentic search.
Reference graph
Works this paper leans on
-
[1]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.CoRR, abs/2507.17746, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Junkai Zhang, Zihao Wang, Lin Gui, Swarnashree Mysore Sathyendra, Jaehwan Jeong, Victor Veitch, Wei Wang, Yunzhong He, Bing Liu, and Lifeng Jin. Chasing the tail: Effective rubric- based reward modeling for large language model post-training.CoRR, abs/2509.21500, 2025
-
[3]
Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Jiale Zhao, Jingwen Yang, Jianwei Lv, Kongcheng Zhang, Yihe Zhou, Hengtong Lu, Wei Chen, Yan Xie, and Mingli Song. Breaking the exploration bottleneck: Rubric-scaffolded reinforcement learning for general LLM reasoning. CoRR, abs/2508.16949, 2025
-
[4]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health.CoRR, abs/2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and LLM alignment.CoRR, abs/2510.07743, 2025
-
[6]
Lipeng Xie, Sen Huang, Zhuo Zhang, Anni Zou, Yunpeng Zhai, Dingchao Ren, Kezun Zhang, Haoyuan Hu, Boyin Liu, Haoran Chen, Zhaoyang Liu, and Bolin Ding. Auto-rubric: Learning to extract generalizable criteria for reward modeling.CoRR, abs/2510.17314, 2025
-
[7]
Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, Xijun Gu, Peiyi Tu, Jiaxin Liu, Wenyu Chen, Yuzhuo Fu, Zhiting Fan, Yanmei Gu, Yuanyuan Wang, Zhengkai Yang, Jianguo Li, and Junbo Zhao. Reinforcement learning with rubric anchors.CoRR, abs/2508.12790, 2025
-
[8]
Jianghao Chen, Wei Sun, Qixiang Yin, Lingxing Kong, Zhixing Tan, and Jiajun Zhang. ACE-RL: adaptive constraint-enhanced reward for long-form generation reinforcement learning.CoRR, abs/2509.04903, 2025
-
[9]
DR Tulu: Reinforcement Learning with Evolving Rubrics for Deep Research
Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, Varsha Kishore, Jingming Zhuo, Xinran Zhao, Molly Park, Samuel G. Finlayson, David A. Sontag, Tyler Murray, Sewon Min, Pradeep Dasigi, Luca Soldaini, Faeze Brahman, Wen-tau Yih, Tongshuang Wu, Luke Zettlemoyer, Yoon Kim, Hannaneh Hajishirzi, and Pang Wei Koh. DR tulu: Reinforcement learning with...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Online rubrics elicitation from pairwise comparisons.CoRR, abs/2510.07284, 2025
MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek. Online rubrics elicitation from pairwise comparisons.CoRR, abs/2510.07284, 2025
-
[11]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosuite, L...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.CoRR, abs/2401.01335, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.CoRR, abs/2401.10020, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar
Li S. Yifei, Allen Chang, Chaitanya Malaviya, and Mark Yatskar. Researchqa: Evaluating scholarly question answering at scale across 75 fields with survey-mined questions and rubrics. CoRR, abs/2509.00496, 2025
-
[15]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents.CoRR, abs/2506.11763, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
LocalSearchBench: Benchmarking Agentic Search in Real-World Local Life Services
Hang He, Chuhuai Yue, Chengqi Dong, Mingxue Tian, Zhenfeng Liu, Jiajun Chai, Xiaohan Wang, Yufei Zhang, Qun Liao, Guojun Yin, Wei Lin, Chengcheng Wan, Haiying Sun, and Ting Su. Localsearchbench: Benchmarking agentic search in real-world local life services.CoRR, abs/2512.07436, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof q&a benchmark.CoRR, abs/2311.12022, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela ...
2024
-
[19]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[20]
Qwen Team. Qwen3 technical report.CoRR, abs/2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Dong Wang, Heng Ji, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.CoRR, abs/2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning
Qingfei Zhao, Ruobing Wang, Yukun Yan, Ruihua Song, Zhichao Duan, Renjun Hu, Xinyu Cao, Ying Chen, Li Ma, Shu Li, Yong Zhang, Mingde Shao, Zhiyuan Liu, and Maosong Sun. Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning. CoRR, abs/2411.02337, 2024
-
[23]
OpenAI. Openai GPT-5 system card.CoRR, abs/2601.03267, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/, February 2026. Accessed: 2026-05-30
2026
-
[25]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.CoRR, abs/2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Xiaoxi Li, Jiajie Jin, Yujia Zhou, Yuyao Zhang, Peitian Zhang, Yutao Zhu, Zheng Liu, and Zhicheng Dou. Webthinker: Empowering large reasoning models with deep research capability. CoRR, abs/2504.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Tongyi DeepResearch Technical Report
Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, Kuan Li, Liangcai Su, Litu Ou, Liwen Zhang, Pengjun Xie, Rui Ye, Wenbiao Yin, Xinmiao Yu, Xinyu Wang, Xixi Wu, Xuanzhong Chen, Yida Zhao, Zhen Zhang, Zhengwei Tao, Zhongwang Zhang, Zile Qiao, Chenxi Wang, Donglei Yu, Gang Fu, Haiyang Shen, Jiayi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
DeerFlow: Deep exploration and efficient research flow
Daniel Walnut, Henry Li, and ByteDance Inc. DeerFlow: Deep exploration and efficient research flow. https://github.com/bytedance/deer-flow, 2025. Open-source multi- agent framework for deep research automation
2025
-
[29]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
2023
-
[30]
OpenReview.net, 2023
2023
-
[31]
Mistral AI. Ministral 3.CoRR, abs/2601.08584, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
S. Bai, L. Bing, L. Lei, R. Li, X. Li, X. Lin, E. Min, L. Su, B. Wang, L. Wang, L. Wang, S. Wang, X. Wang, Y . Zhang, Z. Zhang, G. Chen, L. Chen, Z. Cheng, Y . Deng, Z. Huang, D. Ng, J. Ni, Q. Ren, X. Tang, B. L. Wang, H. Wang, N. Wang, C. Wei, Q. Wu, J. Xia, Y . Xiao, H. Xu, X. Xu, C. Xue, Z. Yang, Z. Yang, F. Ye, H. Ye, J. Yu, C. Zhang, W. Zhang, H. Zha...
-
[33]
15 System Prompt: Stage II (Rubric Synthesis) # Role Definition You are an expert in evaluation framework design for academic research
Key Dimensions of Quality:(What specific attributes—e.g., conciseness, creativity, coding style—matter most forthisspecific query?) 4.Edge Cases & Constraints:(What subtle details must be correct?) Action:Begin your deep research into{{ query }}now. 15 System Prompt: Stage II (Rubric Synthesis) # Role Definition You are an expert in evaluation framework d...
-
[34]
This report contains the necessary factual information (algorithms, parameters, benchmarks, etc.) that a high-quality responseshouldcontain
Analyze the Final Report:Use the provided {{ final_report }} as theground truth. This report contains the necessary factual information (algorithms, parameters, benchmarks, etc.) that a high-quality responseshouldcontain
-
[35]
Prohibited Content:
Design the Framework:Construct evaluation criteria where the specific metrics, names, and thresholds are derived from the facts found in the{{ final_report }}. Prohibited Content:
-
[36]
Direct answers to the query or summaries of the final report
-
[37]
Recommendations, tutorials, or explanatory content
-
[38]
>=[X] specific algorithms included
Generic criteria unrelated to the specific facts in the final report. # Evaluation Framework Design Requirements 1.Content-Centric & Fact-Based Evaluation: • Core Principle:Focus oninformation qualityandfactual completenessbased on the{{ final_report }}. • Calibration:Do not set unrealistic thresholds. Align thresholds with the actual information landscap...
-
[39]
#### Core Dimension:
Framework Generation:Assess response quality based on the facts provided in {{ final_report }}. 2.Dimension Design:3–8 dimensions, Core Dimension first. 3.Core Dimension: • Explicitly labeled (e.g., “#### Core Dimension: . . . ”). 16 • Grounded in Fact:Check for the specific entities (methods, papers, data) present in the{{ final_report }}. 4.Strict Thres...
2057
-
[40]
Stop ifP n >max(0.15,2×P n−1)
Primary criterion:After bootstrap step n, compute polarization Pn (fraction of samples scoring 0 or≥0.99). Stop ifP n >max(0.15,2×P n−1). 2.Model selection:arg min k Pk (lowest polarization)
-
[41]
Auxiliary:If min(entropy)<0.70 within a step, the rubrics are too narrow—consider reducing constraint specificity
-
[42]
Retrospective validation on both scales: this rule correctly selects BS-2 and terminates at BS-3, avoiding BS-4/BS-5 and saving 40–60% of total bootstrap compute
Hard bound:Do not exceed 3 bootstrap iterations without external rubric grounding (e.g., a GPT-5 “reset” step). Retrospective validation on both scales: this rule correctly selects BS-2 and terminates at BS-3, avoiding BS-4/BS-5 and saving 40–60% of total bootstrap compute. J Fresh-Start Bootstrap: Disentangling Rubric Quality from Policy Drift The cumula...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.