When Data Is Scarce: Scaling Sparse Language Models with Repeated Training
Pith reviewed 2026-06-28 17:14 UTC · model grok-4.3
The pith
A scaling law for sparse language models accounts for active parameters, unique tokens, data repetition, and sparsity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
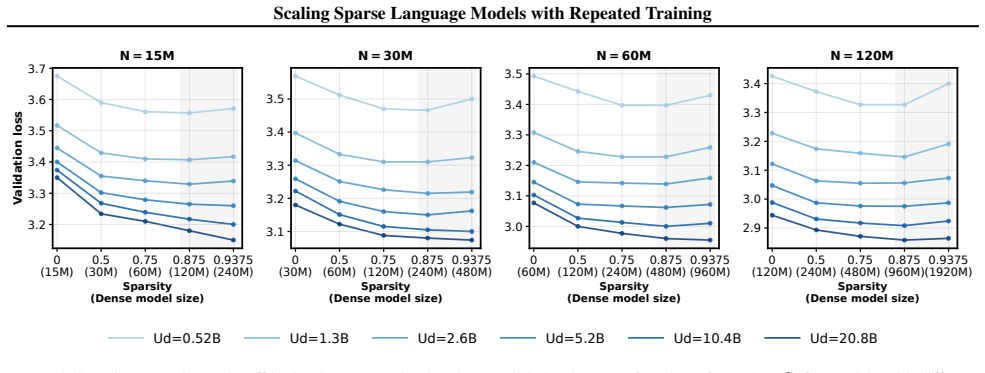
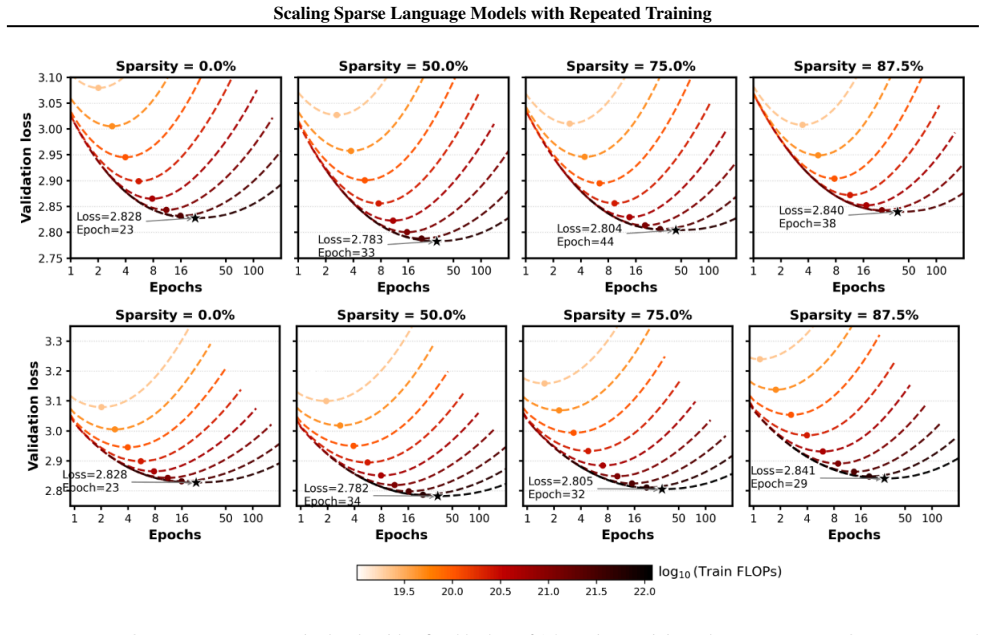
Sparse models trained with repeated data obey a scaling law in which loss depends on the number of active parameters, the number of unique tokens, the data repetition count, and the sparsity ratio; this functional form accurately predicts performance on both in-distribution and held-out larger models.
What carries the argument
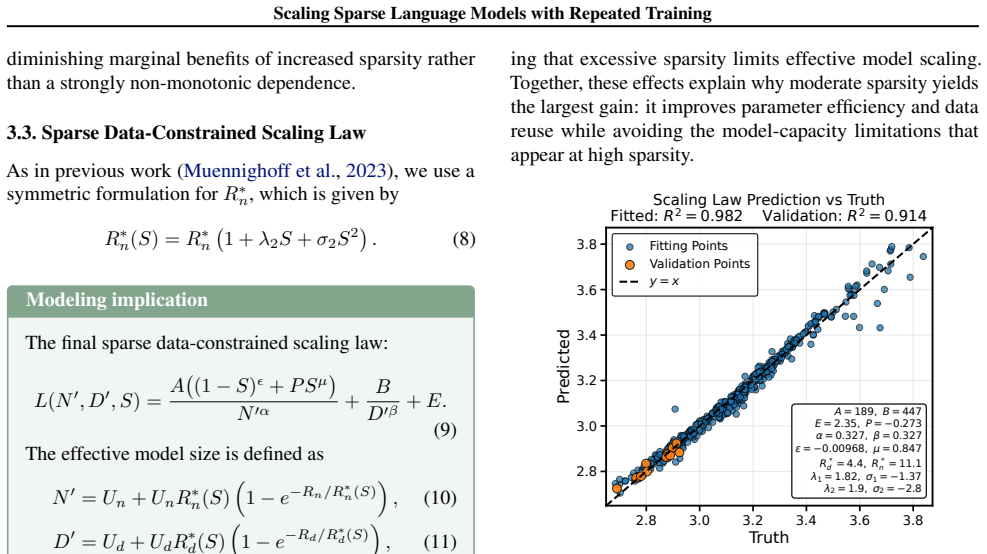
The scaling law modeling loss as a function of active parameters, unique tokens, data repetition, and sparsity.
If this is right
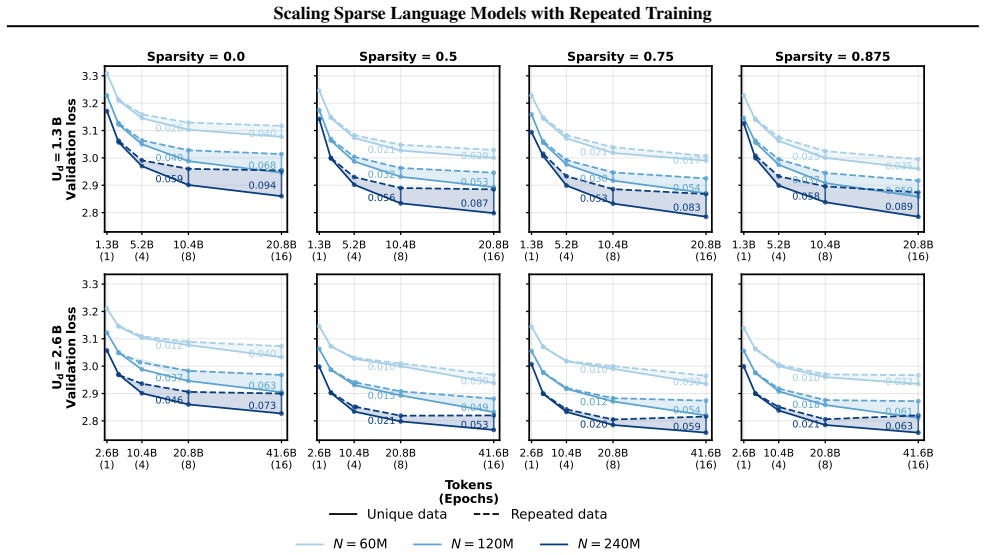
- Sparse training postpones diminishing returns from repeated data, making multi-epoch training more effective.
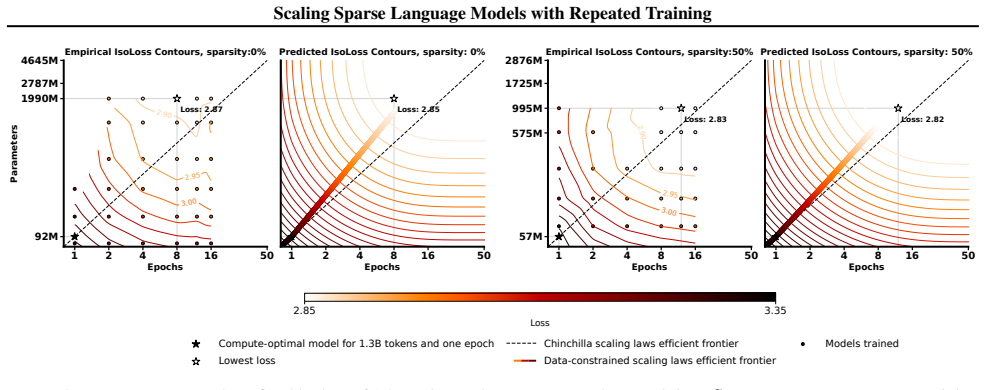
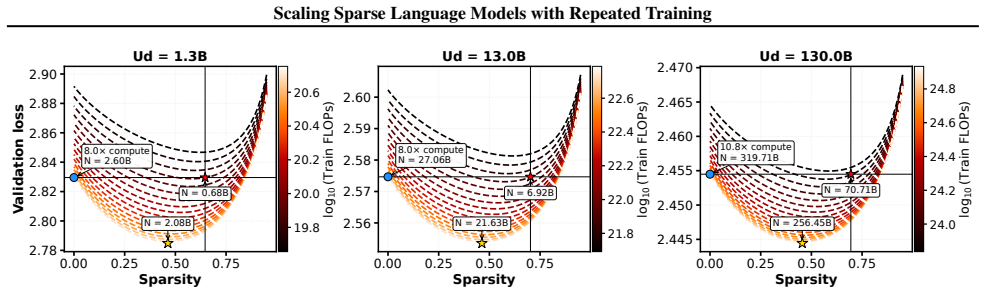
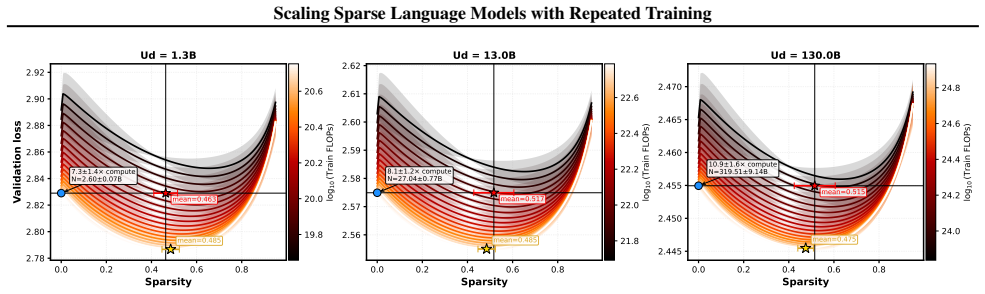
- With fixed unique data, loss is minimized at moderate sparsity levels around 50 percent.
- Compute-optimal sparsity is higher than loss-optimal and increases as the data budget grows.
- The scaling law enables accurate prediction of performance across different compute and data budgets.
Where Pith is reading between the lines
- If the law generalizes, it could be used to optimize sparsity levels before running expensive training jobs with limited data.
- The delayed saturation effect suggests sparsity could interact productively with techniques that increase effective data diversity.
Load-bearing premise
The specific functional form selected for the scaling law captures the primary interactions among sparsity, repetition, and loss without requiring additional terms or being tied to particular model families.
What would settle it
Measuring loss on a model with 10 billion parameters or a sparsity level of 80 percent under a repetition schedule outside the fitted range and finding large deviations from the law's prediction.
Figures
read the original abstract
Scaling laws for dense LLMs under infinite data are well explored, but how sparsity interacts with limited data is not. In this work, we study sparse training in data-constrained regimes where limited unique tokens require multi-epoch training. Our experiments span models up to 1.92B parameters in the fitting set, sparsity up to 93.75%, unique data budgets up to 2.6B tokens, and total training tokens up to 41.6B over 16 epochs; we further validate extrapolation on held-out dense-equivalent models up to 7.68B parameters. We find that: 1. Sparse scaling in data-limited settings: We introduce a scaling law that models loss as a function of active parameters, unique tokens, data repetition, and sparsity, accurately predicting performance across compute and data budgets. 2. Delayed data saturation: sparse training postpones diminishing returns from repeated data, making multi-epoch training more effective. 3. Resource trade-offs: With fixed data, loss-optimal sparsity is moderate ~ 50%, while compute-optimal sparsity is higher and grows with data scale. Overall, sparsity is not just a tool for efficiency, but a mechanism for improving scaling trade-offs under data scarcity. Our code is available at: https://github.com/boqian333/sparse-dc-scaling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper studies sparse language model training in data-constrained regimes requiring data repetition. It introduces a scaling law expressing loss as a function of active parameters, unique tokens, repetition, and sparsity; reports that sparsity delays saturation from repeated data; and analyzes loss-optimal (~50%) versus compute-optimal (higher, scale-dependent) sparsity levels. Experiments fit on models ≤1.92B parameters and sparsity ≤93.75% with validation on held-out dense models up to 7.68B; code is released.
Significance. If the scaling law is shown to generalize with proper statistical validation, the work would meaningfully extend scaling-law methodology to sparse models under data scarcity, providing concrete guidance on sparsity-repetition trade-offs. The open-source code is a clear strength supporting reproducibility.
major comments (3)
- [Abstract and scaling-law section] Abstract and the section introducing the scaling law: the claim of 'accurately predicting performance across compute and data budgets' cannot be assessed because the manuscript provides no information on how the scaling-law coefficients were fitted, whether cross-validation was performed, or how error bars were computed.
- [Scaling law fitting and validation] The scaling law is introduced as an empirical fit whose parameters are determined from the same experimental runs it is later used to predict, making the reported 'predictions' dependent on quantities fitted to the target data and undermining claims of independent validation.
- [Scaling law derivation and experiments] The chosen functional form L = f(N_active, D_unique, R, S) is assumed to capture dominant interactions without extra terms; no ablation tests whether interaction terms between sparsity and repetition are required, which is load-bearing for the claim that the form is sufficient outside the fit regime (models ≤1.92B, repetition ≤16).
minor comments (1)
- [Notation and definitions] Notation for repetition factor R and sparsity S should be defined explicitly at first use with units or ranges.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below with clarifications on our methodology and commit to revisions that strengthen the presentation of the scaling law fitting, validation, and assumptions.
read point-by-point responses
-
Referee: [Abstract and scaling-law section] Abstract and the section introducing the scaling law: the claim of 'accurately predicting performance across compute and data budgets' cannot be assessed because the manuscript provides no information on how the scaling-law coefficients were fitted, whether cross-validation was performed, or how error bars were computed.
Authors: We agree that the manuscript omitted key details on the fitting procedure. The coefficients were determined via nonlinear least-squares optimization applied to the observed losses across our experimental grid. In the revision we will add a dedicated subsection describing the optimization method, convergence criteria, and how 95% confidence intervals were obtained via bootstrap resampling of the data points. We will also report results from a 5-fold cross-validation performed on the fitting runs to quantify robustness. revision: yes
-
Referee: [Scaling law fitting and validation] The scaling law is introduced as an empirical fit whose parameters are determined from the same experimental runs it is later used to predict, making the reported 'predictions' dependent on quantities fitted to the target data and undermining claims of independent validation.
Authors: The primary fit used all runs up to 1.92B parameters, yet validation explicitly includes extrapolation to held-out dense-equivalent models reaching 7.68B parameters that were never seen during coefficient estimation. We will revise the text to clearly separate in-sample fitting from this out-of-distribution extrapolation and will add a supplementary hold-out experiment that reserves 20% of the original runs for testing. revision: yes
-
Referee: [Scaling law derivation and experiments] The chosen functional form L = f(N_active, D_unique, R, S) is assumed to capture dominant interactions without extra terms; no ablation tests whether interaction terms between sparsity and repetition are required, which is load-bearing for the claim that the form is sufficient outside the fit regime (models ≤1.92B, repetition ≤16).
Authors: The functional form extends established dense scaling laws by adding repetition and sparsity factors motivated by the qualitative trends observed in our data. We will incorporate an ablation study in the revision that compares the base form against variants containing explicit sparsity-repetition interaction terms, showing that the added terms produce negligible gains in fit quality (R²) and extrapolation error on the held-out larger models. revision: yes
Circularity Check
Scaling law empirically fitted on training runs and validated on held-out larger models
full rationale
The paper describes fitting a scaling law on a set of experiments (models ≤1.92B, sparsity ≤93.75%) and then validating extrapolation on held-out dense models up to 7.68B parameters. This separation means the reported predictive accuracy on the validation set is not forced by construction from the fitting data. No self-definitional equations, load-bearing self-citations, or renamings of known results are identifiable from the manuscript description; the functional form is presented as an empirical model whose generalization is tested externally to the fit.
Axiom & Free-Parameter Ledger
free parameters (1)
- scaling-law coefficients
axioms (1)
- domain assumption Loss can be expressed as a smooth function of active parameters, unique tokens, repetition count, and sparsity fraction
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Agarwalla, A., Gupta, A., Marques, A., Pandit, S., Goin, M., Kurtic, E., Leong, K., Nguyen, T., Salem, M., Alistarh, D., et al. Enabling high-sparsity foundational Llama models with efficient pretraining and deployment.arXiv preprint arXiv:2405.03594,
-
[3]
Gemini: A Family of Highly Capable Multimodal Models
Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
- [4]
-
[5]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, X., Chen, D., Chen, G., Chen, S., Dai, D., Deng, C., Ding, H., Dong, K., Du, Q., Fu, Z., et al. DeepSeek LLM: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Cheng, X., Zeng, W., Dai, D., Chen, Q., Wang, B., Xie, Z., Huang, K., Yu, X., Hao, Z., Li, Y ., et al. Conditional memory via scalable lookup: A new axis of sparsity for large language models.arXiv preprint arXiv:2601.07372,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. OpenAI o1 system card.arXiv preprint arXiv:2412.16720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[10]
Mocanu, D
Accessed 2025-12-08. Mocanu, D. C., Mocanu, E., Stone, P., Nguyen, P. H., Gibescu, M., and Liotta, A. Scalable training of arti- ficial neural networks with adaptive sparse connectivity inspired by network science.Nature communications, 9 (1):2383,
2025
- [11]
-
[12]
Eric Schmidt says there’s ’no evidence’ ai scaling laws are stopping — but they will eventually
Nolan, B. Eric Schmidt says there’s ’no evidence’ ai scaling laws are stopping — but they will eventually. https: 10 Scaling Sparse Language Models with Repeated Training //www.businessinsider.com/eric-schmi dt-google-ceo-ai-scaling-laws-opena i-slowdown-2024-11 ,
2024
-
[13]
STEM: Scaling transformers with embedding modules.arXiv preprint arXiv:2601.10639,
Sadhukhan, R., Cao, S., Dong, H., Zhao, C., Purpura- Pontoniere, A., Tian, Y ., Liu, Z., and Chen, B. STEM: Scaling transformers with embedding modules.arXiv preprint arXiv:2601.10639,
-
[14]
Sevilla, J., Besiroglu, T., Cottier, B., You, J., Rold ´an, E., Villalobos, P., and Erdil, E
Epoch AI blog, accessed 2024-05-28. Sevilla, J., Besiroglu, T., Cottier, B., You, J., Rold ´an, E., Villalobos, P., and Erdil, E. Can AI scaling continue through
2024
-
[15]
https://epoch.ai/blog/can-a i-scaling-continue-through-2030 ,
2030
-
[16]
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q
Epoch AI blog, accessed 2024-08-20. Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q. V ., Hinton, G. E., and Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In5th International Conference on Learning Rep- resentations, ICLR,
2024
-
[17]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi`ere, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lam- ple, G. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023a. Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bash...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Villalobos, P., Sevilla, J., Heim, L., Besiroglu, T., Hobbhahn, M., and Ho, A
Accessed 2025-04-28. Villalobos, P., Sevilla, J., Heim, L., Besiroglu, T., Hobbhahn, M., and Ho, A. Will we run out of data? an analysis of the limits of scaling datasets in machine learning.arXiv preprint arXiv:2211.04325, 1,
-
[19]
Xiao, Q., Ansell, A., Wu, B., Yin, L., Pechenizkiy, M., Liu, S., and Mocanu, D. C. Leave it to the specialist: Repair sparse LLMs with sparse fine-tuning via sparsity evolution.arXiv preprint arXiv:2505.24037,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, Y ., Zhang, Y ., Wan, Y ....
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
11 Scaling Sparse Language Models with Repeated Training Symbol Description CTraining FLOPs NTotal number of non-zero model parameters N ′ Effective number of non-zero parameters DTotal number of training tokens processed D′ Effective number of training tokens Ud Number of unique training tokens Rd Number of data repetitions beyond the first epoch Un The ...
2020
-
[22]
In (Porian et al., 2024), the DeepSeek fit is LR = 0.17×N −0.25,(16) whereNdenotes the model size
suggests that the optimal learning rate decreases as model size increases. In (Porian et al., 2024), the DeepSeek fit is LR = 0.17×N −0.25,(16) whereNdenotes the model size. To verify this trend in our setting, we perform a learning-rate sweep on Llama models with different sizes under a fixed training budget of 2.6B tokens. The tested models include 120M...
2024
-
[23]
A (N ′rep)α + B (D′rep)β # −
The values of the parameters after fitting are λ1, σ1, λ2, σ2 = [1.82159486,−1.36557887,1.90420893,−2.79936732] The resulting fit achieves a loss of1.15×10 −3 and anR 2 score of98.2%. D.3. Formulations Explanation D.3.1. DEPENDENCE OF THELOSSGAP ON THEAMOUNT OFUNIQUEDATA We analyze how the loss gap between training on unique and repeated data scales with ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.