Connecting the Dots: Benchmarking Reflective Memory in Long-Horizon Dialogue
Pith reviewed 2026-06-28 17:38 UTC · model grok-4.3
The pith
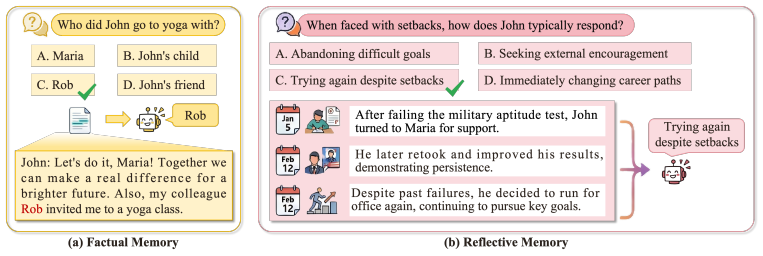
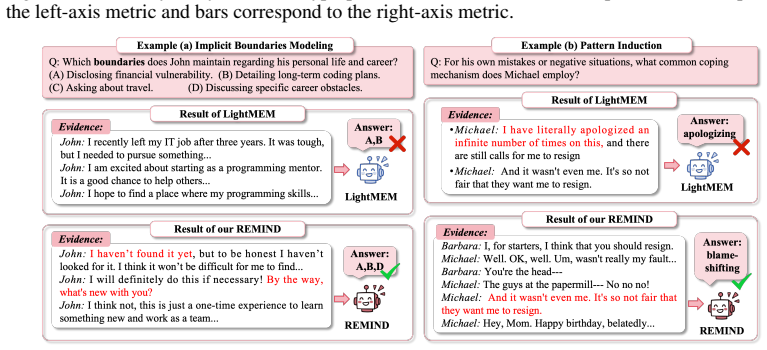
RefMem-Bench tests whether models can synthesize fragmented dialogue cues into high-level interpretations rather than recalling explicit facts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
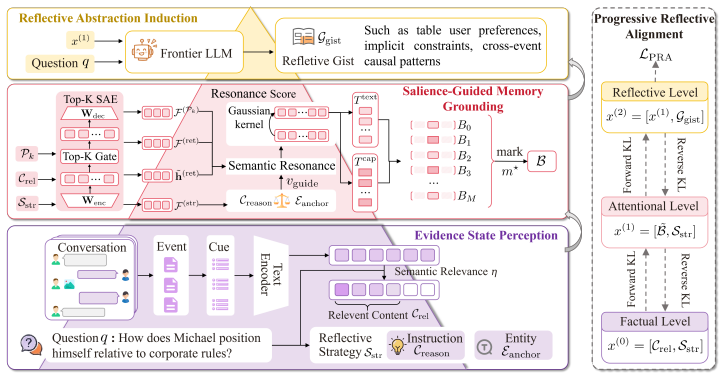
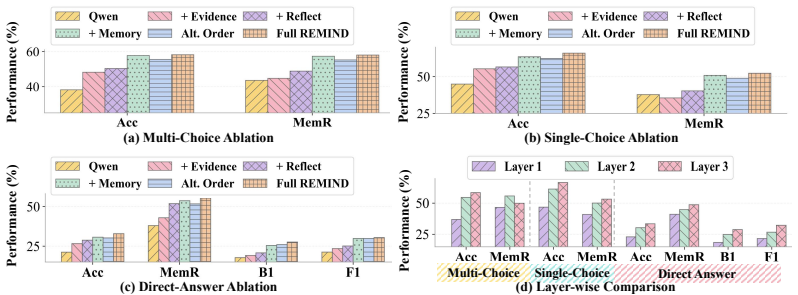
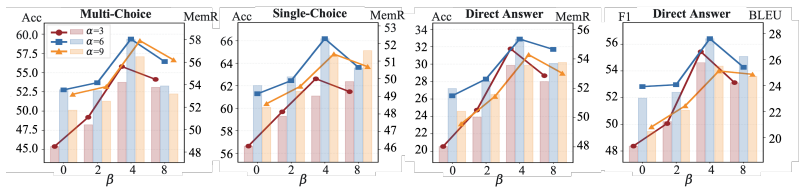
RefMem-Bench demonstrates that current language models struggle to perform reflective memory tasks that require moving beyond explicit recall to infer latent meanings from evidence spread across long interaction histories. The REMIND framework addresses this by implementing a hierarchical process of question-conditioned evidence retrieval, salience-aware grounding, and abstraction-level supervision, using Progressive Reflective Alignment to integrate high-level reflective reasoning into the factual inference pathway, resulting in improved answer accuracy and memory recall.
What carries the argument
REMIND (REflective Memory INDuction), a hierarchical framework that treats reflective memory as progressive meaning construction through question-conditioned evidence retrieval, salience-aware grounding, abstraction-level supervision, and Progressive Reflective Alignment.
If this is right
- Current models face substantial challenges on reflective memory tasks.
- REMIND improves both answer accuracy and memory recall.
- Progressive evidence perception, grounding, and abstraction are effective for building reflective capabilities.
- The benchmark requires models to infer latent meanings rather than surface-level retrieval.
Where Pith is reading between the lines
- This could lead to dialogue systems that maintain better coherence over extended conversations.
- Similar progressive frameworks might help in other areas requiring abstraction from long sequences, such as document understanding.
- The benchmark construction method could be adapted to create tests for reflective capabilities in other modalities.
Load-bearing premise
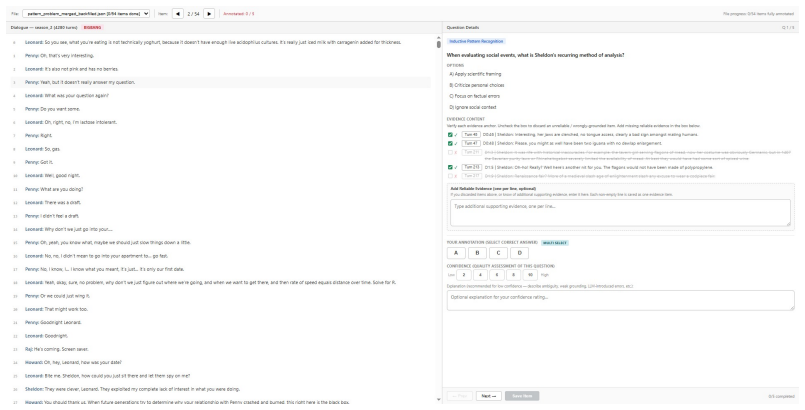
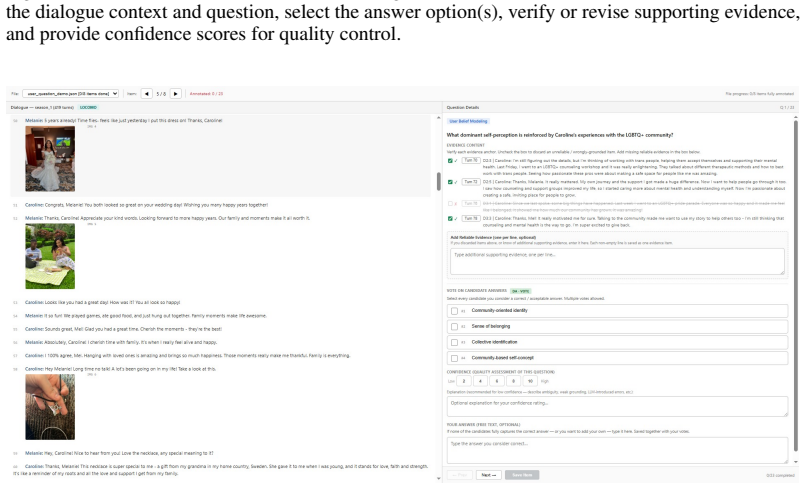
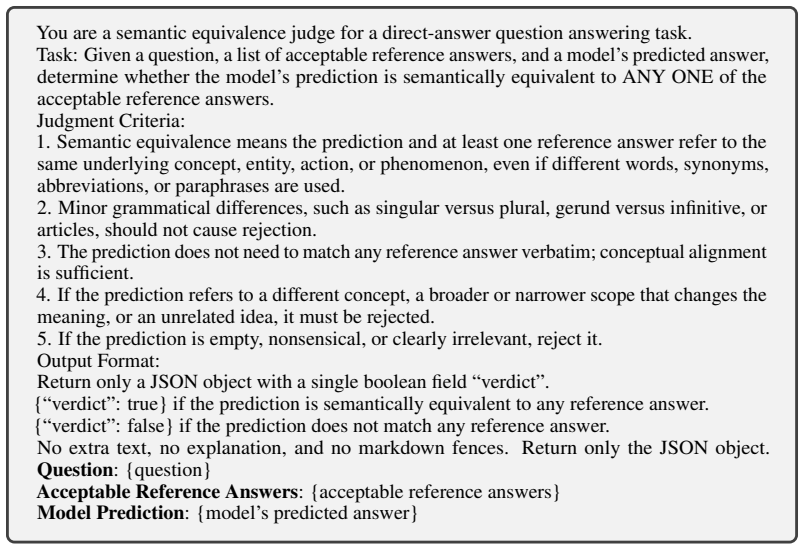
The eight reflective-memory dimensions and three task formats in RefMem-Bench accurately capture the intended latent meanings rather than surface patterns that models could exploit without genuine synthesis.
What would settle it
If a model achieves high accuracy on RefMem-Bench by relying only on surface patterns in the provided histories without demonstrating abstraction or grounding, this would indicate the benchmark does not measure true reflective memory.
Figures



read the original abstract
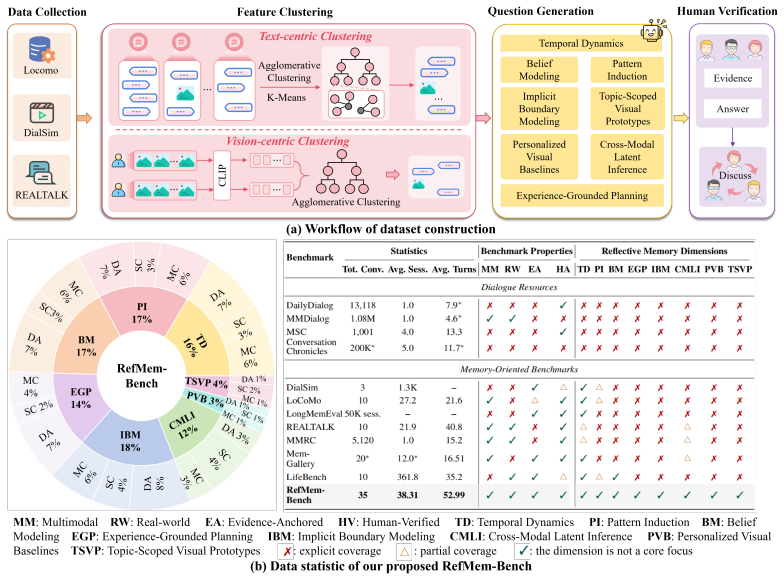
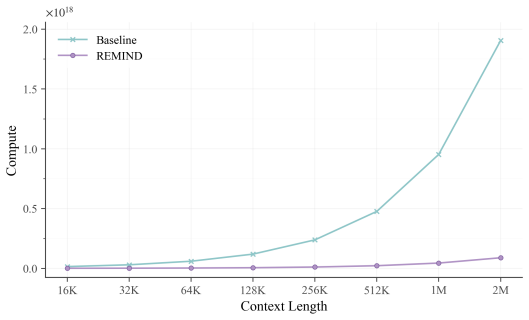
Despite substantial progress in long-context modeling, existing benchmarks remain confined to factual memory for explicit recall, failing to measure the reflective memory required to synthesize fragmented, multimodal cues into high-level interpretations. To address this gap, we introduce RefMem-Bench, a benchmark for reflective memory in long-horizon dialogue. RefMem-Bench contains 26K annotated QA instances with eight reflective-memory dimensions and three task formats, requiring models to move beyond surface-level retrieval and infer latent meanings from evidence distributed across interaction histories. To enhance reflective memory capability, we propose REflective Memory INDuction (REMIND), a hierarchical framework that treats reflective memory as progressive meaning construction. REMIND couples question-conditioned evidence retrieval, salience-aware grounding, and abstraction-level supervision, and uses Progressive Reflective Alignment to distill high-level reflective reasoning into the factual inference pathway. Experiments show RefMem-Bench poses a substantial challenge to current models, while REMIND consistently improves both answer accuracy and memory recall through progressive evidence perception, grounding, and abstraction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces RefMem-Bench, a benchmark of 26K annotated QA instances spanning eight reflective-memory dimensions and three task formats, to evaluate models' synthesis of fragmented multimodal cues into latent high-level interpretations in long-horizon dialogue (beyond explicit factual recall). It proposes the REMIND hierarchical framework (question-conditioned evidence retrieval, salience-aware grounding, abstraction-level supervision, and Progressive Reflective Alignment) and reports that the benchmark challenges current models while REMIND yields consistent gains in answer accuracy and memory recall.
Significance. If the benchmark construction is validated to require genuine reflective synthesis and the reported gains are shown to be robust, this could address a meaningful gap in long-context evaluation by shifting focus from surface retrieval to progressive meaning construction.
major comments (2)
- [Abstract] Abstract (paragraph describing benchmark construction): no annotation protocol, inter-annotator agreement statistics, or human validation is reported to confirm that the eight dimensions and three task formats require inference of latent meanings from distributed cues rather than surface-level retrieval or pattern matching; this assumption is load-bearing for the central claim that RefMem-Bench measures reflective memory.
- [Abstract] Abstract (experiments paragraph): no details are supplied on baselines, statistical significance tests, data splits, or controls for confounds such as compute or context length, so the claim that REMIND improves performance specifically through progressive perception/grounding/abstraction cannot be verified from the provided information.
minor comments (1)
- [Abstract] The abstract refers to 'multimodal cues' while describing a dialogue benchmark; explicit clarification on whether non-text modalities are included would aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the manuscript to strengthen the presentation of the benchmark and experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph describing benchmark construction): no annotation protocol, inter-annotator agreement statistics, or human validation is reported to confirm that the eight dimensions and three task formats require inference of latent meanings from distributed cues rather than surface-level retrieval or pattern matching; this assumption is load-bearing for the central claim that RefMem-Bench measures reflective memory.
Authors: We agree that the abstract does not report the annotation protocol, inter-annotator agreement statistics, or human validation. These elements are necessary to substantiate that the benchmark requires reflective synthesis rather than surface retrieval. In the revised version we will add a concise description of the annotation protocol, IAA results, and human validation to the abstract, and expand the methods section if needed to fully document the process. revision: yes
-
Referee: [Abstract] Abstract (experiments paragraph): no details are supplied on baselines, statistical significance tests, data splits, or controls for confounds such as compute or context length, so the claim that REMIND improves performance specifically through progressive perception/grounding/abstraction cannot be verified from the provided information.
Authors: We agree that the abstract supplies no details on baselines, statistical significance tests, data splits, or controls for confounds. This limits verifiability of the specific contributions of REMIND. We will revise the abstract to include a brief summary of the experimental setup, baselines, and controls, while ensuring the full paper provides complete information on data splits, significance testing, and confound controls. revision: yes
Circularity Check
No circularity; empirical benchmark and method evaluation is self-contained
full rationale
The paper introduces RefMem-Bench (26K QA instances across eight dimensions and three formats) and the REMIND framework, then reports experimental improvements in accuracy and recall. No equations, parameter fits, derivations, or self-citations appear in the abstract or described content that would reduce any claimed result to an input by construction. The central claims are empirical outcomes on a newly constructed test set, which functions as an external benchmark rather than a self-referential loop. This is the standard case of a benchmark paper whose validity can be assessed independently of any derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Evaluating very long-term conversational memory of llm agents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[2]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Longmemeval: Benchmarking chat assistants on long-term interactive memory , author=. arXiv preprint arXiv:2410.10813 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2502.13270 , year=
Realtalk: A 21-day real-world dataset for long-term conversation , author=. arXiv preprint arXiv:2502.13270 , year=
-
[4]
arXiv preprint arXiv:2504.14225 , year=
Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale , author=. arXiv preprint arXiv:2504.14225 , year=
-
[5]
Madial-bench: Towards real-world evaluation of memory-augmented dialogue generation , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[6]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Mmrc: A large-scale benchmark for understanding multimodal large language model in real-world conversation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
Hamann, Jingrui He, and Hanghang Tong
Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents , author=. arXiv preprint arXiv:2601.03515 , year=
-
[8]
Proceedings of the AAAI conference on artificial intelligence , volume=
Memorybank: Enhancing large language models with long-term memory , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[9]
, author=
MemGPT: towards LLMs as operating systems. , author=. 2023 , publisher=
2023
-
[10]
Advances in Neural Information Processing Systems , volume=
Augmenting language models with long-term memory , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2402.04624 , year=
Memoryllm: Towards self-updatable large language models , author=. arXiv preprint arXiv:2402.04624 , year=
-
[12]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Mem0: Building production-ready ai agents with scalable long-term memory , author=. arXiv preprint arXiv:2504.19413 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Memory os of ai agent , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[14]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
A-MEM: Agentic Memory for LLM Agents
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
M+: Extending memoryllm with scalable long-term memory.arXiv preprint arXiv:2502.00592, 2025
M+: Extending MemoryLLM with scalable long-term memory , author=. arXiv preprint arXiv:2502.00592 , year=
-
[17]
Psychometrika , volume=
Hierarchical clustering schemes , author=. Psychometrika , volume=. 1967 , publisher=
1967
-
[18]
Journal of the American Statistical Association , volume =
Hierarchical Grouping to Optimize an Objective Function , author =. Journal of the American Statistical Association , volume =
-
[19]
Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability , volume =
Some Methods for Classification and Analysis of Multivariate Observations , author =. Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability , volume =
-
[20]
, journal =
Lloyd, Stuart P. , journal =. Least Squares Quantization in
-
[21]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =
-
[22]
Psychological Bulletin , volume =
Measuring Nominal Scale Agreement Among Many Raters , author =. Psychological Bulletin , volume =
-
[23]
Biometrics , volume =
The Measurement of Observer Agreement for Categorical Data , author =. Biometrics , volume =
-
[24]
Educational and Psychological Measurement , volume=
A Coefficient of Agreement for Nominal Scales , author=. Educational and Psychological Measurement , volume=
-
[25]
2025 , howpublished =
LangMem. 2025 , howpublished =
2025
-
[26]
LightMem: Lightweight and Efficient Memory-Augmented Generation
LightMem: Lightweight and Efficient Memory-Augmented Generation , author =. arXiv preprint arXiv:2510.18866 , year =. doi:10.48550/arXiv.2510.18866 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18866
-
[27]
arXiv preprint arXiv:2511.18423 , year=
General Agentic Memory Via Deep Research , author =. arXiv preprint arXiv:2511.18423 , year =. doi:10.48550/arXiv.2511.18423 , url =
-
[28]
MemAgent: Reshaping Long-Context
Yu, Hongli and Chen, Tinghong and Feng, Jiangtao and Chen, Jiangjie and Dai, Weinan and Yu, Qiying and Zhang, Ya-Qin and Ma, Wei-Ying and Liu, Jingjing and Wang, Mingxuan and Zhou, Hao , journal =. MemAgent: Reshaping Long-Context. 2025 , doi =
2025
-
[29]
Qwen3 Technical Report , author =. arXiv preprint arXiv:2505.09388 , year =. doi:10.48550/arXiv.2505.09388 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[30]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in. arXiv preprint arXiv:2501.12948 , year =. doi:10.48550/arXiv.2501.12948 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948
-
[31]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[32]
arXiv preprint arXiv:2601.23014 , year=
Mem-T: Densifying Rewards for Long-Horizon Memory Agents , author=. arXiv preprint arXiv:2601.23014 , year=
-
[33]
Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning , author=. arXiv preprint arXiv:2508.19828 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Craik, Fergus I. M. and Lockhart, Robert S. , title =. Journal of Verbal Learning and Verbal Behavior , year =
-
[35]
Trends in Cognitive Sciences , year =
Badre, David , title =. Trends in Cognitive Sciences , year =
-
[36]
and D'Esposito, Mark , title =
Badre, David and Hoffman, Joshua and Cooney, Jeffrey W. and D'Esposito, Mark , title =. Nature Neuroscience , year =
-
[37]
and Brainerd, Charles J
Reyna, Valerie F. and Brainerd, Charles J. , title =. Learning and Individual Differences , year =
-
[38]
and Reyna, Valerie F
Brainerd, Charles J. and Reyna, Valerie F. , title =. Current Directions in Psychological Science , year =
-
[39]
Scaling and evaluating sparse autoencoders
Scaling and evaluating sparse autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
arXiv preprint arXiv:2406.13144 , year=
DialSim: A Dialogue Simulator for Evaluating Long-Term Multi-Party Dialogue Understanding of Conversational Agents , author=. arXiv preprint arXiv:2406.13144 , year=. doi:10.48550/arXiv.2406.13144 , url=
-
[41]
2023 , howpublished =
Xiaoju Ye , title =. 2023 , howpublished =
2023
-
[42]
MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents
Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents , author=. arXiv preprint arXiv:2506.15841 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[44]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:2304.11062 , year=
Scaling transformer to 1m tokens and beyond with rmt , author=. arXiv preprint arXiv:2304.11062 , year=
-
[46]
Journal of Instrumentation , volume=
Impact of the gas choice and the geometry on the breakdown limits in Micromegas detectors , author=. Journal of Instrumentation , volume=. 2023 , publisher=
2023
-
[47]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[48]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[49]
Psychological Bulletin , volume=
Is memory schematic? , author=. Psychological Bulletin , volume=. 1983 , publisher=
1983
-
[50]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[51]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Gpteval: Nlg evaluation using gpt-4 with better human alignment , author=. arXiv preprint arXiv: 2303.16634 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Ma, Qingsen and Wang, Dianyun and Wang, Yaoye and Ning, Lechen and Zhu, Sujie and Zhang, Xiaohang and Lyu, Jiaming and Ren, Linhao and Xu, Zhenbo and He, Zhaofeng , journal=. S
-
[54]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Dialogcc: An automated pipeline for creating high-quality multi-modal dialogue dataset , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[55]
IEEE Trans
Divergence measures based on the Shannon entropy , author=. IEEE Trans. Inf. Theory , year=
-
[56]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Evaluating memory in llm agents via incremental multi-turn interactions , author=. arXiv preprint arXiv:2507.05257 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
arXiv preprint arXiv:2603.03781 , year=
LifeBench: A Benchmark for Long-Horizon Multi-Source Memory , author=. arXiv preprint arXiv:2603.03781 , year=
-
[58]
KnowMe-Bench: Benchmarking Person Understanding for Lifelong Digital Companions
KnowMe-Bench: Benchmarking Person Understanding for Lifelong Digital Companions , author=. arXiv preprint arXiv:2601.04745 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
arXiv preprint arXiv:2601.16690 , year=
EMemBench: Interactive Benchmarking of Episodic Memory for VLM Agents , author=. arXiv preprint arXiv:2601.16690 , year=
-
[60]
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory
Evo-memory: Benchmarking llm agent test-time learning with self-evolving memory , author=. arXiv preprint arXiv:2511.20857 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems
MemoryBench: A Benchmark for Memory and Continual Learning in LLM Systems , author=. arXiv preprint arXiv:2510.17281 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Membench: Towards more comprehensive evaluation on the memory of llm-based agents , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.