Compliance-Scored Best-of-N Guardrail Orchestration for Multimodal Document Generation in Payments Dispute Defense
Pith reviewed 2026-06-28 13:11 UTC · model grok-4.3
The pith
A compliance-scored Best-of-N system selects the highest-scoring output from parallel generations to raise payments dispute win rates by 11 points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
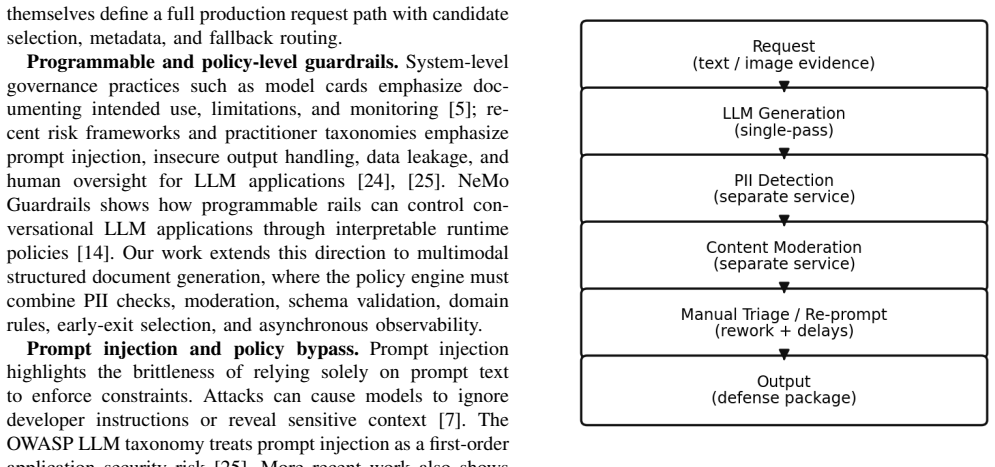
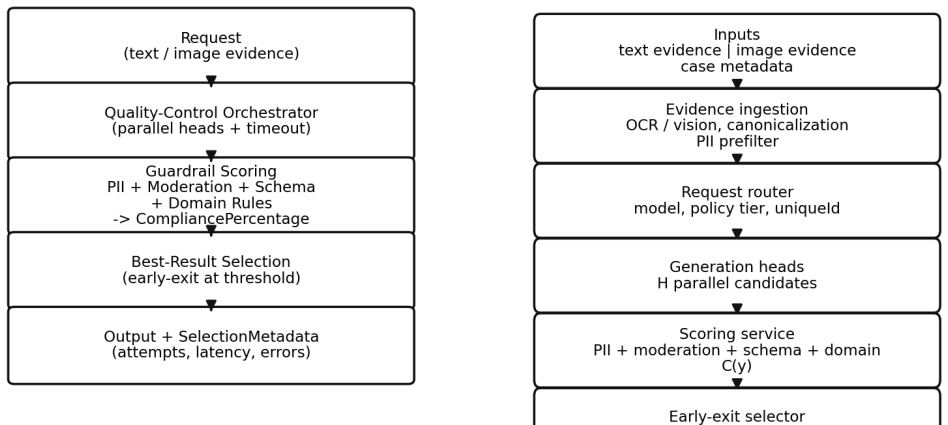
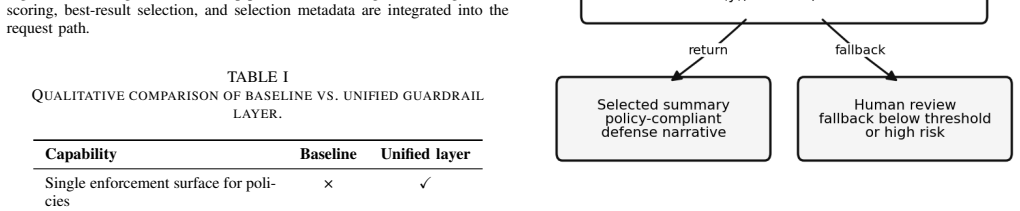
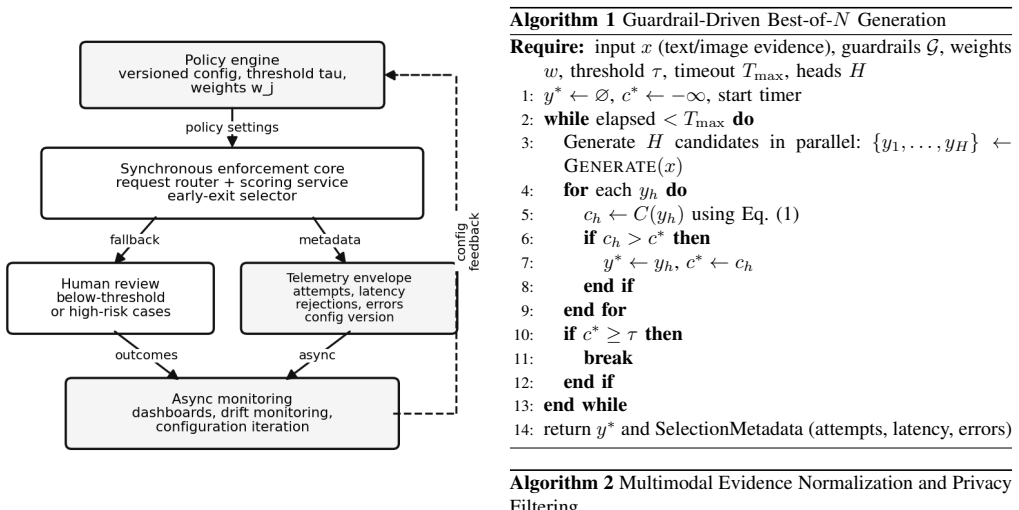
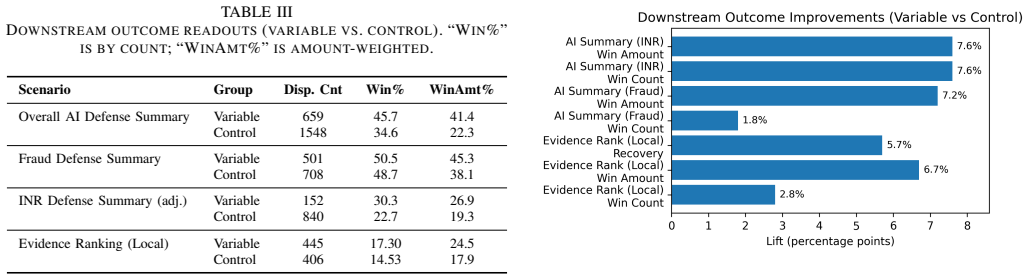
The framework runs configurable parallel generation heads, scores candidates against weighted guardrails including PII detection, content moderation, schema constraints, and domain rules, and returns the best-scoring output with selection metadata. For payments dispute defense summaries, aggregate operational scenario readouts show +11.0 percentage points win rate improvement with 95 percent confidence interval [6.6, 15.5] and p < 0.001.
What carries the argument
The compliance-scored Best-of-N guardrail orchestration layer that weights multiple guardrails to select the best output from parallel generations.
If this is right
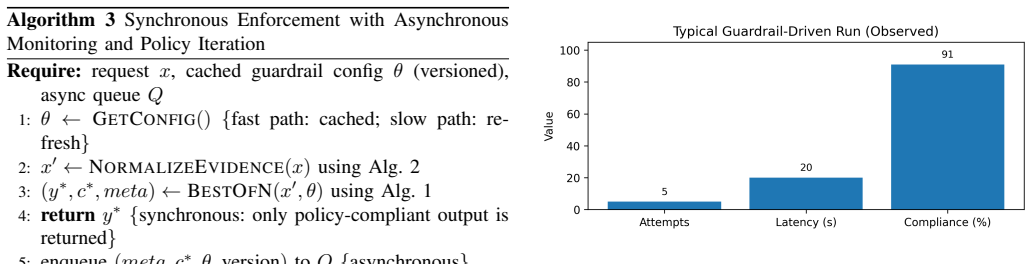
- Document generation achieves 91 percent compliance with five attempts completed inside 20 seconds.
- Payments dispute defense summaries show an 11.0 percentage point win rate lift in aggregate operational data.
- Fraud and local evidence-ranking outcomes trend positive though not statistically significant in the reported counts.
- Reviewer-calibrated Responsible-AI evidence-quality signals are available from 770 generated-evidence reviews.
- The request interface, scoring logic, and pseudocode define a reproducible boundary for the approach.
Where Pith is reading between the lines
- The same orchestration pattern could be applied to other regulated document tasks such as audit summaries or compliance notices.
- A controlled experiment would be needed to separate the effect of the scoring layer from cohort differences.
- The 20-second latency bound with multiple candidates suggests the approach can scale to production request volumes.
- Extending the weighted guardrails to additional domain rules would be a direct next step within the same framework.
Load-bearing premise
The observed win rate differences can be attributed to the guardrail orchestration system rather than unmeasured differences between the variable and control cohorts.
What would settle it
A randomized A/B test that assigns cases to the orchestration system versus standard generation and finds no statistically significant win rate difference would falsify the central claim.
Figures

read the original abstract
High-stakes enterprise document generation, including financial dispute narratives, compliance notices, and audit summaries, demands schema correctness, policy compliance, and low-latency operation at scale. Prior to a unified guardrail layer, production systems often stitched together separate PII redaction, content moderation, and format validation steps, leading to fragmented logic, slower request paths, and higher operational cost. We present a guardrail orchestration layer for text and image inputs that couples multi-candidate generation with an explicit compliance score used for early exit. The framework runs configurable parallel generation heads, scores candidates against weighted guardrails including PII detection, content moderation, schema constraints, and domain rules, and returns the best-scoring output with selection metadata. The available operational readout reports 5 attempts within 20 seconds and 91 percent compliance. For payments dispute defense summaries, we analyze aggregate operational scenario readouts rather than a randomized A/B test. Variable cohorts show higher count win rates than controls overall, 301/659 versus 536/1548, corresponding to +11.0 percentage points with 95 percent confidence interval [6.6, 15.5] and p < 0.001, and for adjusted item-not-received cases, +7.5 percentage points with 95 percent confidence interval [0.2, 15.7] and p = 0.045. Fraud and local evidence-ranking deltas are directionally positive but not statistically significant from the aggregate count data. We also report reviewer-calibrated Responsible-AI evidence-quality signals from 770 generated-evidence reviews and a 70-case OCR slice, and document the reproducibility boundary through the request interface, scoring logic, pseudocode, and operational evidence boundary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a guardrail orchestration layer for multimodal document generation that runs configurable parallel generation heads, scores candidates against weighted guardrails (PII detection, content moderation, schema constraints, domain rules), and selects the best-scoring output. It reports operational metrics of 5 attempts within 20 seconds at 91% compliance. For payments dispute defense summaries, aggregate operational scenario readouts from variable cohorts show a +11.0 pp win-rate improvement (301/659 vs. 536/1548, 95% CI [6.6, 15.5], p < 0.001) and a smaller effect in adjusted item-not-received cases (+7.5 pp, p = 0.045), along with reviewer-calibrated evidence-quality signals and reproducibility documentation via pseudocode and request interface.
Significance. If the win-rate differences can be causally attributed to the orchestration system, the work would offer a practical contribution to reliable, low-latency document generation in regulated financial domains by unifying previously fragmented guardrails. The explicit provision of scoring logic, pseudocode, and operational evidence boundary supports reproducibility and is a strength. The observational design, however, substantially weakens the ability to claim system-driven improvement.
major comments (2)
- [payments dispute defense summaries analysis (abstract and results)] The payments dispute defense summaries analysis reports a statistically significant +11.0 pp win-rate lift from aggregate operational scenario readouts on variable cohorts (301/659 vs 536/1548) but explicitly notes the absence of a randomized A/B test and provides no description of cohort assignment, covariate balance, or controls for temporal drift, case-mix shift, or reviewer behavior. This design leaves the central attribution of the difference to the compliance-scored best-of-N mechanism unsupported.
- [results and operational readout sections] No explicit baseline comparison is presented against the prior fragmented approach (separate PII redaction, moderation, and validation steps) using the same generation heads or any randomized control arm, so the incremental benefit of the unified weighted scoring and early-exit logic cannot be isolated from the reported 91% compliance and win-rate figures.
minor comments (2)
- [abstract] The phrasing 'higher count win rates than controls overall' is imprecise; clarify whether this refers to raw counts, proportions, or a specific metric definition.
- [results] The 70-case OCR slice and 770 generated-evidence reviews are mentioned without details on sampling method or inter-rater reliability; add a brief methods note for these signals.
Simulated Author's Rebuttal
We thank the referee for identifying the core limitations of the observational design. We agree that the reported win-rate differences cannot support causal attribution to the orchestration mechanism without randomization or matched controls. We will revise the manuscript to strengthen the discussion of these boundaries while preserving the transparency already present in the text. Point-by-point responses follow.
read point-by-point responses
-
Referee: The payments dispute defense summaries analysis reports a statistically significant +11.0 pp win-rate lift from aggregate operational scenario readouts on variable cohorts (301/659 vs 536/1548) but explicitly notes the absence of a randomized A/B test and provides no description of cohort assignment, covariate balance, or controls for temporal drift, case-mix shift, or reviewer behavior. This design leaves the central attribution of the difference to the compliance-scored best-of-N mechanism unsupported.
Authors: We agree that the observational nature of the aggregate operational data precludes causal claims. The manuscript already states the absence of a randomized A/B test. In revision we will expand the results and limitations sections to include all available operational cohort descriptors (e.g., case volume trends and reviewer pool stability where logged), restate that the +11.0 pp difference is an observed association in variable cohorts, and add explicit language that temporal drift, case-mix, and reviewer behavior remain unmeasured confounders. revision: partial
-
Referee: No explicit baseline comparison is presented against the prior fragmented approach (separate PII redaction, moderation, and validation steps) using the same generation heads or any randomized control arm, so the incremental benefit of the unified weighted scoring and early-exit logic cannot be isolated from the reported 91% compliance and win-rate figures.
Authors: The introduction describes the prior fragmented production pattern but contains no head-to-head empirical comparison against that pattern using identical generation heads. Because the data derive from a live operational deployment, a randomized or matched baseline arm was not available. We will add a dedicated paragraph in the results section clarifying that the 91% compliance and win-rate figures reflect the orchestrated system only, and we will list the absence of an isolated incremental-benefit measurement as an explicit limitation. revision: partial
- Provision of randomized A/B test data or a matched baseline comparison against the prior fragmented guardrail approach, as these require experimental deployments outside the scope of the existing operational dataset.
Circularity Check
No circularity; paper contains no derivation chain, equations, or fitted predictions
full rationale
The manuscript describes a guardrail orchestration framework and reports empirical operational metrics (e.g., 91% compliance, +11.0 pp win-rate from aggregate counts 301/659 vs 536/1548) without any mathematical derivations, parameter fitting, self-citations used as uniqueness theorems, or ansatzes. The text explicitly flags the comparison as observational rather than randomized A/B, but this is a limitation on causal inference, not a reduction of any claimed result to its own inputs by construction. No load-bearing steps exist that match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The composite compliance score accurately reflects policy adherence and output quality across PII, moderation, schema, and domain rules
Reference graph
Works this paper leans on
-
[1]
The tail at scale,
J. Dean and L. A. Barroso, “The tail at scale,”Communications of the ACM, vol. 56, no. 2, pp. 74–80, 2013
2013
-
[2]
Hidden technical debt in machine learning systems,
D. Sculley et al., “Hidden technical debt in machine learning systems,” inProc. NeurIPS (Workshop), 2015
2015
-
[3]
Training language models to follow instructions with human feedback,
L. Ouyang et al., “Training language models to follow instructions with human feedback,” inProc. NeurIPS, 2022
2022
-
[4]
Constitutional AI: Harmlessness from AI Feedback
Y . Bai et al., “Constitutional AI: Harmlessness from AI feedback,” arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Model cards for model reporting,
M. Mitchell et al., “Model cards for model reporting,” inProc. FAT*, 2019
2019
-
[6]
On the dangers of stochastic parrots: Can language models be too big?
E. M. Bender et al., “On the dangers of stochastic parrots: Can language models be too big?” inProc. FAccT, 2021
2021
-
[7]
Ignore Previous Prompt: Attack Techniques For Language Models
E. Perez and M. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” arXiv:2211.09527, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Lexically constrained decoding for sequence generation using grid beam search,
C. Hokamp and Q. Liu, “Lexically constrained decoding for sequence generation using grid beam search,” inProc. ACL, 2017
2017
-
[9]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
X. Wang et al., “Self-consistency improves chain of thought reasoning in language models,” arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
J. Wei et al., “Chain-of-thought prompting elicits reasoning in large language models,” arXiv:2201.11903, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Retrieval-augmented generation for knowledge-intensive NLP tasks,
P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive NLP tasks,” inProc. NeurIPS, 2020
2020
-
[12]
A contextual-bandit approach to personalized news article recommendation,
L. Li et al., “A contextual-bandit approach to personalized news article recommendation,” inProc. WWW, 2010
2010
-
[13]
WILDS: A benchmark of in-the-wild distribution shifts,
P. W. Koh et al., “WILDS: A benchmark of in-the-wild distribution shifts,” inProc. ICML, 2021
2021
-
[14]
T. Rebedea, R. Dinu, M. Sreedhar, C. Parisien, and J. Cohen, “NeMo Guardrails: A toolkit for controllable and safe LLM applications with programmable rails,” arXiv:2310.10501, 2023
-
[15]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan et al., “Llama Guard: LLM-based input-output safeguard for human-AI conversations,” arXiv:2312.06674, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Llama Guard 3-1B-INT4: Compact and efficient safeguard for human-AI conversations,
I. Fedorov et al., “Llama Guard 3-1B-INT4: Compact and efficient safeguard for human-AI conversations,” arXiv:2411.17713, 2024
-
[17]
RigorLLM: Resilient guardrails for large language models against undesired content,
Z. Yuan, Z. Xiong, Y . Zeng, N. Yu, R. Jia, D. Song, and B. Li, “RigorLLM: Resilient guardrails for large language models against undesired content,” arXiv:2403.13031, 2024
-
[18]
R 2-Guard: Robust reasoning enabled LLM guardrail via knowledge-enhanced logical reasoning,
M. Kang and B. Li, “R 2-Guard: Robust reasoning enabled LLM guardrail via knowledge-enhanced logical reasoning,” arXiv:2407.05557, 2024
-
[19]
Efficient Guided Generation for Large Language Models
B. T. Willard and R. Louf, “Efficient guided generation for large language models,” arXiv:2307.09702, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Holistic Evaluation of Language Models
P. Liang et al., “Holistic evaluation of language models,” arXiv:2211.09110, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
VHELM: A holistic evaluation of vision language models,
T. Lee et al., “VHELM: A holistic evaluation of vision language models,” arXiv:2410.07112, 2024
-
[22]
R. Vir, S. Shankar, H. Chase, W. Fu-Hinthorn, and A. Parameswaran, “PROMPTEV ALS: A dataset of assertions and guardrails for custom production large language model pipelines,” arXiv:2504.14738, 2025
-
[23]
RAG makes guardrails unsafe? Investigating robustness of guardrails under RAG-style contexts,
Y . She, D. W. Peterson, M. M. Liu, V . Upadhyay, M. H. Chaghazardi, E. Kang, and D. Roth, “RAG makes guardrails unsafe? Investigating robustness of guardrails under RAG-style contexts,” arXiv:2510.05310, 2025
-
[24]
Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Pro- file,
National Institute of Standards and Technology, “Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Pro- file,” NIST AI 600-1, 2024
2024
-
[25]
OW ASP Top 10 for Large Language Model Applications 2025,
OW ASP Foundation, “OW ASP Top 10 for Large Language Model Applications 2025,” 2025. [Online]. Available: https://owasp.org/ www-project-top-10-for-large-language-model-applications/
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.