MPMWorlds: Material-Point-Method Simulations for Inferring and Extrapolating Physical Dynamics
Pith reviewed 2026-06-28 12:17 UTC · model grok-4.3
The pith
Code generation models synthesize stable MPM simulations and extrapolate physical dynamics forward in time more reliably than video diffusion models, which better recover geometry but produce implausible physics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
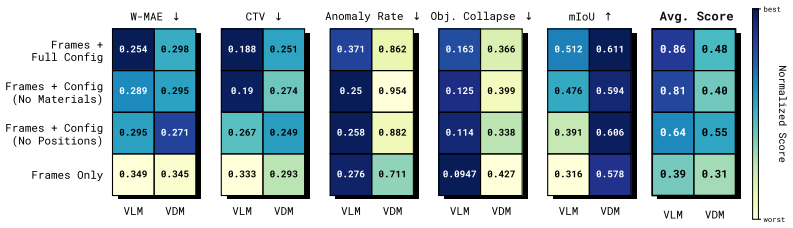
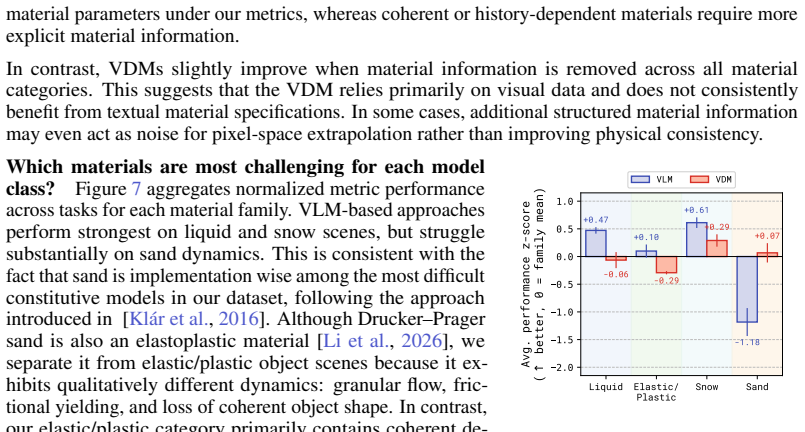
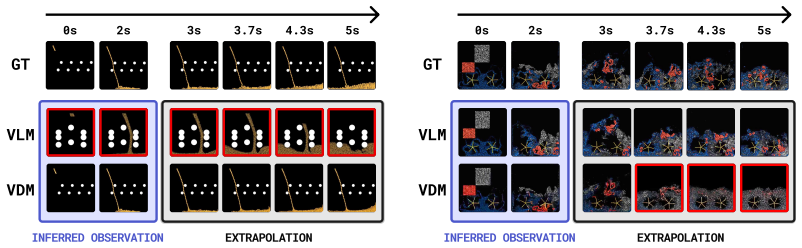
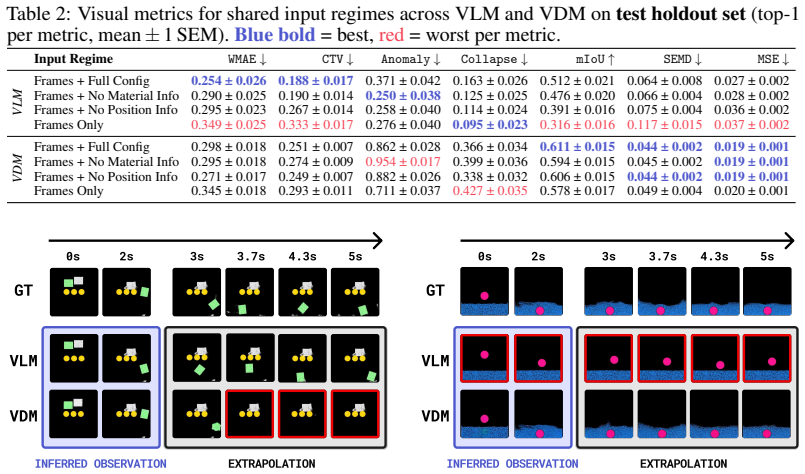
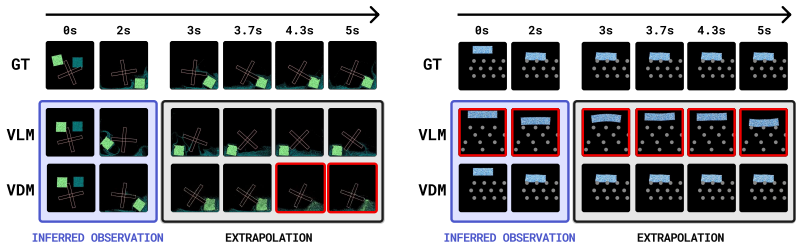
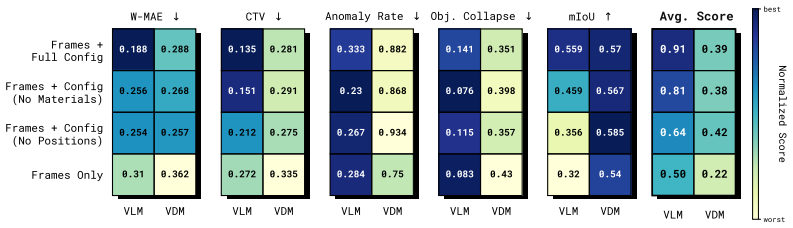
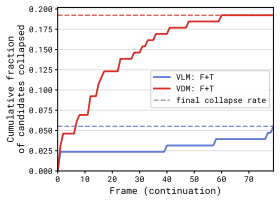
By constructing a dataset of 2D MPM physical simulations and evaluating code generation versus video diffusion models with varying amounts of side information, the work demonstrates that code generation can automatically synthesize MPM simulations and achieves more physically and temporally stable extrapolations, despite difficulties in inferring physical parameters from visuals, while video diffusion identifies geometric properties more effectively but generates physically implausible results.
What carries the argument
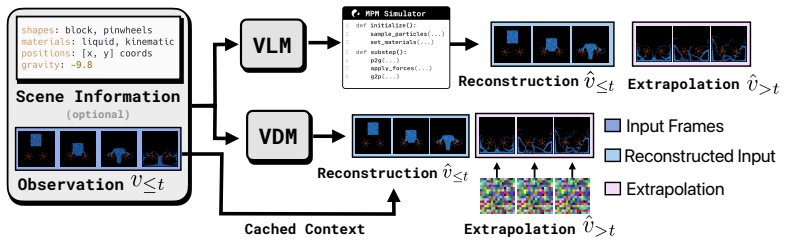
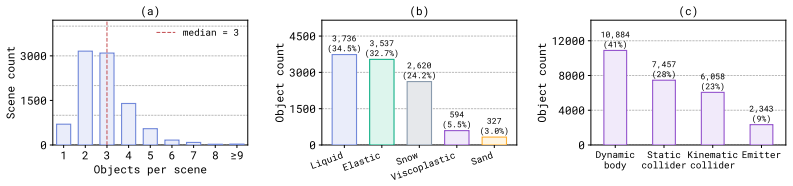
The assembled 2D Material Point Method dataset of simulations covering deformable objects, fluids, kinetic objects, and emitters, used as a controlled testbed to contrast code generation and video diffusion by controlling the quantity of physical side information.
If this is right
- Code generation can serve as a route to automatic creation of executable physical simulators from visual data.
- Video diffusion models remain limited for tasks that require long-horizon physical consistency.
- Strengths of the two approaches are complementary, suggesting possible hybrid pipelines for inference and prediction.
- The dataset provides a benchmark for measuring how side information affects physical parameter recovery versus geometric recovery.
Where Pith is reading between the lines
- Extending the same comparison to three-dimensional MPM simulations could test whether the observed trade-off between stability and geometric fidelity persists in higher dimensions.
- Applying the models to real-world video footage instead of synthetic MPM renders might expose additional failure modes not captured by the current dataset.
- The stability advantage of code generation could make it preferable for control or planning applications that require reliable forward simulation over many steps.
Load-bearing premise
Varying the amount of physically relevant side information on the assembled 2D MPM dataset is sufficient to identify and contrast the strengths and weaknesses of code generation and video diffusion approaches.
What would settle it
An experiment in which video diffusion models produce extrapolations with equal or greater physical and temporal stability than code generation models when both receive identical side information.
Figures



read the original abstract
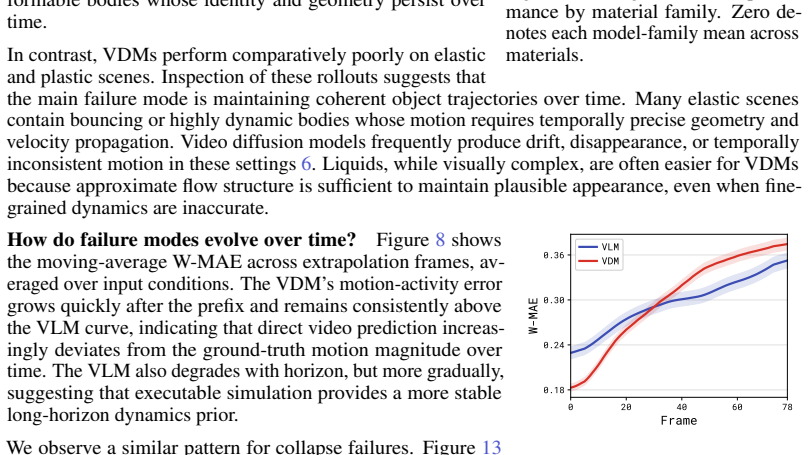
To study the ability to infer physical dynamics from videos and extrapolate them forward in time, we assemble a dataset of 2D Material Point Method (MPM) physical simulations covering rich physical phenomena such as deformable objects, fluids, kinetic objects, and emitters. We study code generation and video diffusion approaches on this dataset, identifying their strengths and weaknesses by varying the amount of physically relevant side information. The code generation model, beyond giving a working demonstration of automatic synthesis of MPM simulations, reveals that such an approach struggles with inferring physical parameters from visual input, but relative to video diffusion, produces physically and temporally stable extrapolations forward in time, while the video diffusion model more strongly identifies geometric properties from visual input but produces physically implausible extrapolations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper assembles a dataset of 2D Material Point Method (MPM) simulations covering deformable objects, fluids, kinetic objects, and emitters. It compares code generation and video diffusion models for inferring physical dynamics from videos and extrapolating forward in time, by varying the amount of physically relevant side information. The central claim is that code generation struggles to infer physical parameters from visual input but produces physically and temporally stable extrapolations relative to video diffusion, while video diffusion better identifies geometric properties but yields physically implausible extrapolations.
Significance. If the qualitative contrasts can be substantiated with quantitative metrics and controlled ablations, the assembled MPM dataset and the demonstration of automatic MPM code synthesis would be useful contributions for benchmarking physical inference methods. The work highlights potential complementary strengths between code-based and video-based generative approaches for simulation tasks.
major comments (2)
- [Abstract] Abstract: the central claims rest on qualitative observations of model behaviors without any reported quantitative metrics (e.g., parameter recovery error, temporal stability scores against held-out MPM ground truth, or geometric fidelity measures), dataset scale, or evaluation protocols, which are load-bearing for assessing the claimed differences in inference and extrapolation performance.
- [Evaluation] Evaluation section (implied by the side-information variation protocol): no ablation tables or explicit definitions of the side-information schedule are provided to demonstrate that the observed model contrasts are attributable to the information variation rather than training regime, prompting, or unstated criteria, undermining isolation of the claimed strengths and weaknesses.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that quantitative metrics and explicit ablations are needed to substantiate the claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims rest on qualitative observations of model behaviors without any reported quantitative metrics (e.g., parameter recovery error, temporal stability scores against held-out MPM ground truth, or geometric fidelity measures), dataset scale, or evaluation protocols, which are load-bearing for assessing the claimed differences in inference and extrapolation performance.
Authors: We agree that the central claims would be strengthened by quantitative support. In the revised manuscript we will add quantitative metrics (parameter recovery error, temporal stability scores, and geometric fidelity measures computed on held-out MPM ground truth), report the full dataset scale, and describe the evaluation protocols in detail. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by the side-information variation protocol): no ablation tables or explicit definitions of the side-information schedule are provided to demonstrate that the observed model contrasts are attributable to the information variation rather than training regime, prompting, or unstated criteria, undermining isolation of the claimed strengths and weaknesses.
Authors: We will add explicit definitions of each side-information schedule (including the exact prompts and inputs used at each level) together with ablation tables that vary only the amount of side information while holding training regime and prompting fixed. These additions will isolate the contribution of the information schedule to the observed differences. revision: yes
Circularity Check
No circularity: empirical comparison on newly assembled dataset
full rationale
The paper assembles a new 2D MPM simulation dataset and reports an empirical comparison of code-generation versus video-diffusion models under varying side information. No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the provided text. The central claims rest on observed model behaviors against held-out simulations rather than any reduction of outputs to inputs by construction. This is a standard empirical study whose results are independent of the input descriptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phyre: A new benchmark for physical reasoning.arXiv:1908.05656,
Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Girshick. Phyre: A new benchmark for physical reasoning.arXiv:1908.05656,
-
[2]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. Videophy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Videophy-2: A challenging action-centric physical commonsense evaluation in video generation
Hritik Bansal, Clark Peng, Yonatan Bitton, Roman Goldenberg, Aditya Grover, and Kai-Wei Chang. Videophy-2: A challenging action-centric physical commonsense evaluation in video generation. arXiv preprint arXiv:2503.06800,
-
[4]
Daniel M Bear, Elias Wang, Damian Mrowca, Felix J Binder, Hsiao-Yu Fish Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, et al. Physion: Evaluating physical prediction from vision in humans and machines.arXiv preprint arXiv:2106.08261,
-
[5]
"PhyWorldBench": A Comprehensive Evaluation of Physical Realism in Text-to-Video Models
Jing Gu, Xian Liu, Yu Zeng, Ashwin Nagarajan, Fangrui Zhu, Daniel Hong, Yue Fan, Qianqi Yan, Kaiwen Zhou, Ming-Yu Liu, et al. " phyworldbench": A comprehensive evaluation of physical realism in text-to-video models.arXiv preprint arXiv:2507.13428,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
How Far is Video Generation from World Model: A Physical Law Perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
ISSN 0730-0301. doi: 10.1145/2897824.2925906. URL https://doi.org/10.1145/ 2897824.2925906. Minchen Li, Chenfanfu Jiang, Zhaofeng Luo, Wenxin Du, Chang Yu, Žiga Kova ˇciˇc, and Tianyi Xie.Physics-Based Simulation. March
-
[9]
URL https: //doi.org/10.5281/zenodo.20597655
doi: 10.5281/zenodo.20597655. URL https: //doi.org/10.5281/zenodo.20597655. Open-source online book. Live version available at https://phys-sim-book.github.io/. Shiqian Li, Kewen Wu, Chi Zhang, and Yixin Zhu. I-PHYRE: Interactive physical reasoning. InThe Twelfth International Conference on Learning Representations,
-
[10]
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Shi Qiu, Shaoyang Guo, Zhuo-Yang Song, Yunbo Sun, Zeyu Cai, Jiashen Wei, Tianyu Luo, Yixuan Yin, Haoxu Zhang, Yi Hu, et al. Phybench: Holistic evaluation of physical perception and reasoning in large language models.arXiv preprint arXiv:2504.16074,
-
[12]
Tianyidan Xie, Peiyu Wang, Yuyi Qian, Yuxuan Wang, Rui Ma, Ying Tai, Song Wu, Qian Wang, Lanjun Wang, and Zili Yi. Physcodebench: Benchmarking physics-aware symbolic simulation of 3d scenes via self-corrective multi-agent refinement.arXiv preprint arXiv:2604.23580,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Jianhao Yuan, Fabio Pizzati, Francesco Pinto, Lars Kunze, Ivan Laptev, Paul Newman, Philip Torr, and Daniele De Martini. Likephys: Evaluating intuitive physics understanding in video diffusion models via likelihood preference.arXiv preprint arXiv:2510.11512,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.