ContinuousBench: Can Differentially Private Synthetic Text Improve Capabilities?
Pith reviewed 2026-06-28 15:35 UTC · model grok-4.3
The pith
Differentially private synthetic text fails to transfer new capabilities from private corpora even at ε=100, while non-private synthesis succeeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
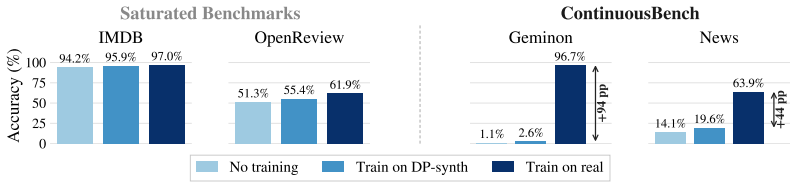
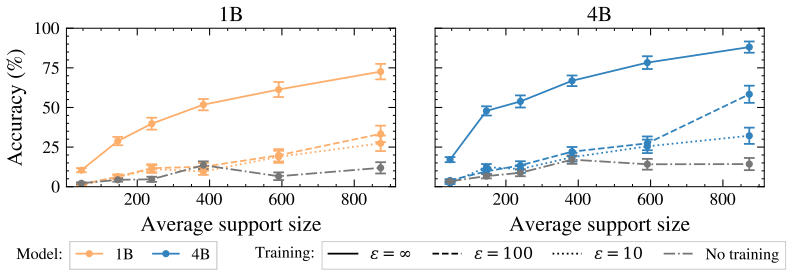
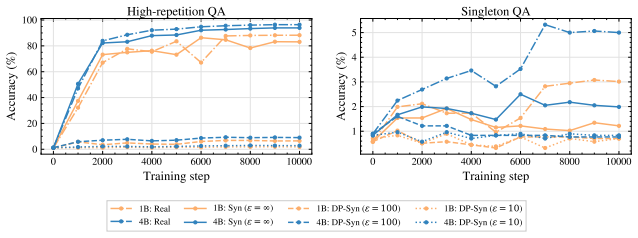
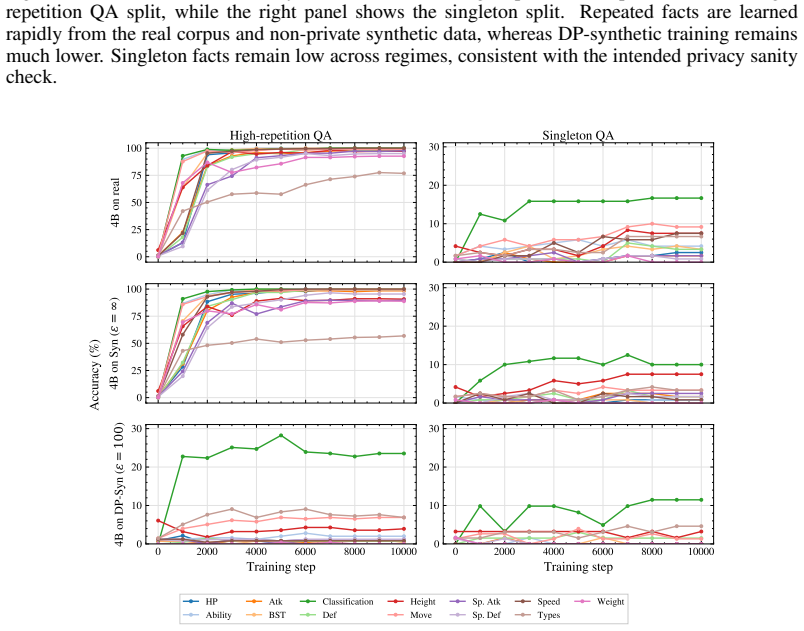
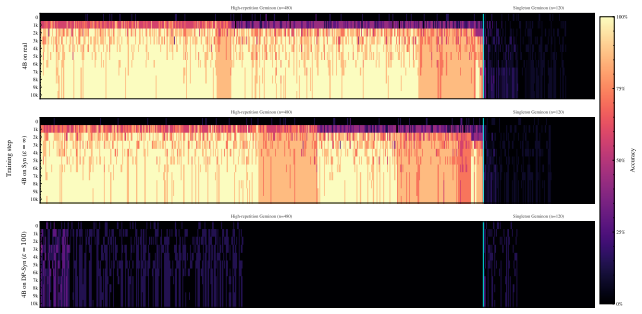
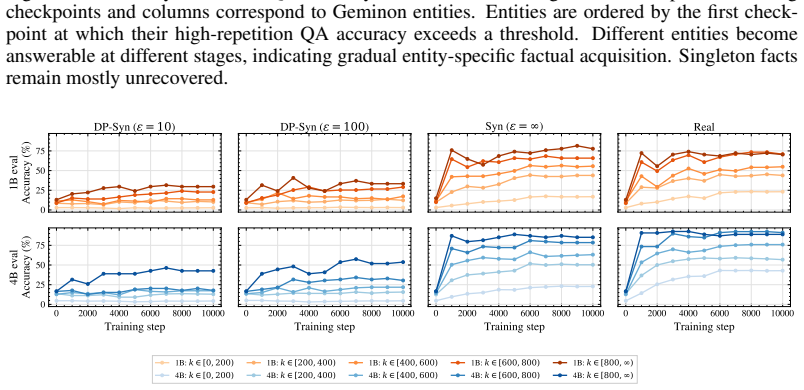
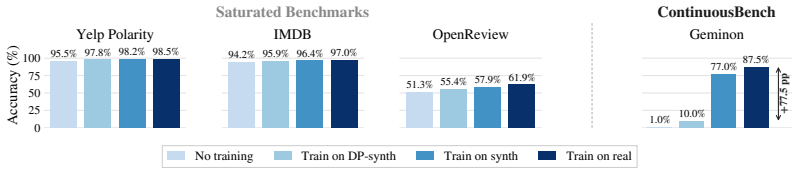
On ContinuousBench, non-private synthesis transfers substantial knowledge from the original corpus, while state-of-the-art DP synthesis methods generally fail to do so, even at ε=100.
What carries the argument
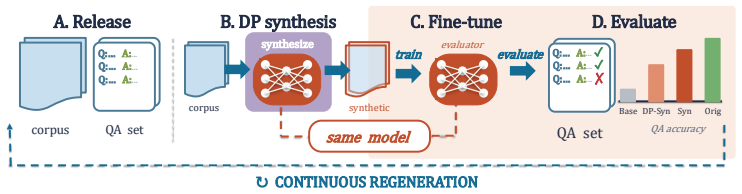
ContinuousBench, a continuously regenerated benchmark that pairs never-before-seen corpora with derived QA sets constructed to be unsolvable without the corpus and learnable under DP noise.
If this is right
- DP synthetic data cannot currently substitute for original corpus access when the goal is to acquire new, corpus-specific capabilities.
- Improvements to DP text synthesis are needed before it can reliably transmit learnable signals from sensitive data.
- Standard benchmarks may overestimate the utility of DP synthesis because they do not isolate corpus-dependent knowledge.
Where Pith is reading between the lines
- The finding implies that for applications requiring novel knowledge extraction, privacy-preserving synthesis may still necessitate additional non-private data sources.
- Extending the benchmark to other data types such as code or structured records could reveal whether the failure is specific to text.
- If future DP methods close the gap, ContinuousBench would provide a standardized way to quantify progress on capability transfer.
Load-bearing premise
The QA sets are constructed to be unsolvable without the corpus and the tested knowledge is supported by hundreds of independent records allowing learnability under DP noise.
What would settle it
A DP synthesis method producing data that lets models score substantially above the no-corpus baseline on the QA sets would show the method succeeds where current ones fail.
Figures



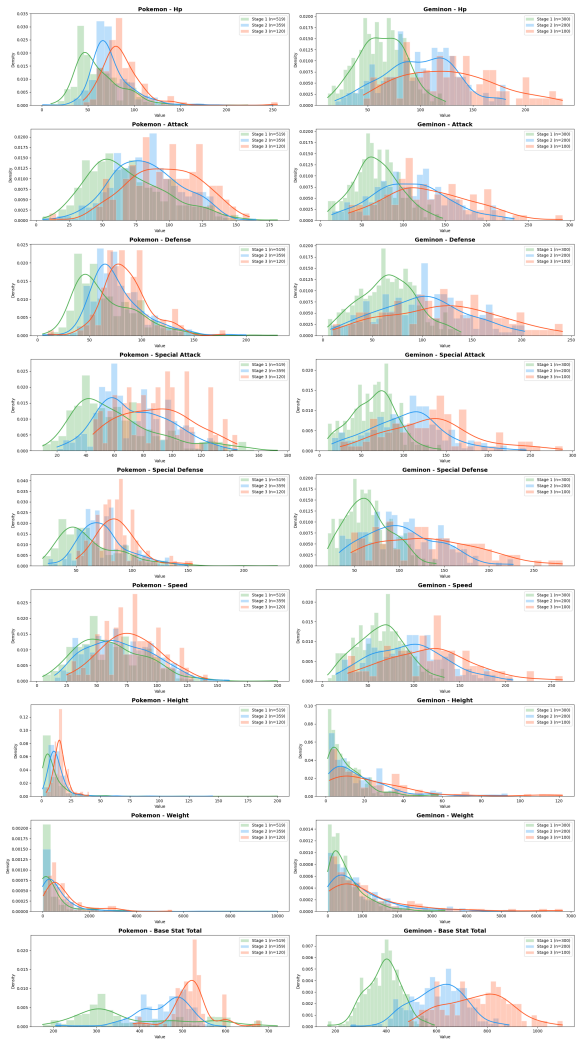


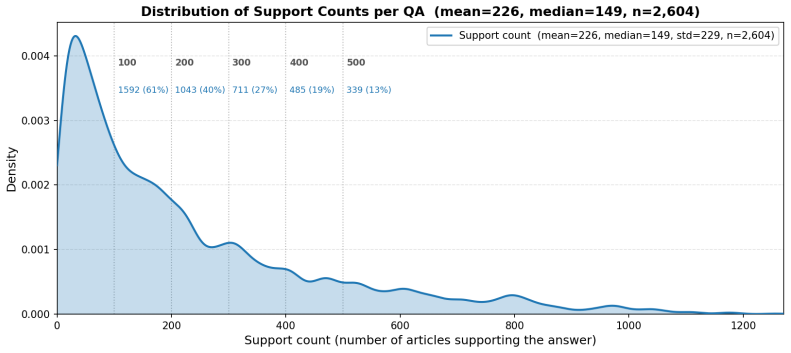
read the original abstract
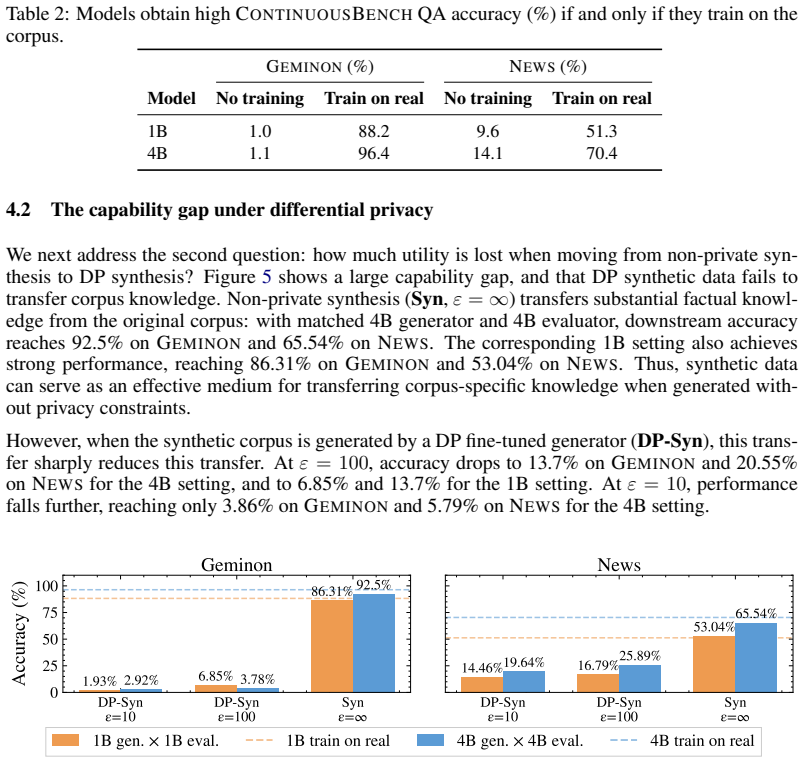
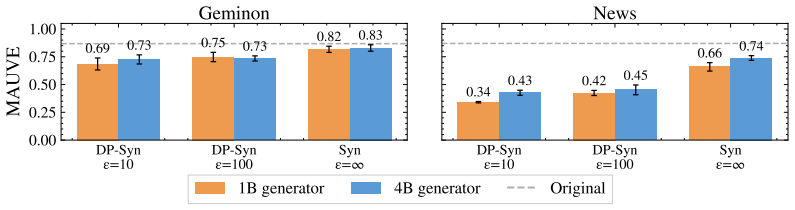
Differentially private (DP) text synthesis promises to unlock sensitive corpora for model training, but it remains unclear whether DP synthetic data transmits genuinely new knowledge and capabilities present only in those corpora. This is because existing evaluations rely on tasks that are nearly solvable without training, so strong benchmark performance does not establish that DP synthesis can substitute original data access. Thus, we introduce ContinuousBench, a continuously and automatically-regenerated benchmark that measures capability gain from DP synthetic text. Each quarter, a new release pairs a never-before-seen training corpus with a derived QA set, constructed to be: (1) unsolvable sans-corpus; and (2) learnable under DP, as the tested knowledge is supported by hundreds of independent records. Researchers produce DP synthetic data from the training corpus and run our standardized training and evaluation harness on their synthetic data to measure gains. We instantiate two tracks: Geminon, a procedurally-generated dataset about fictional creatures; and News, a stream of newly crawled public news articles. Although standard benchmarks are nearly saturated, on ContinuousBench we find that non-private synthesis transfers substantial knowledge from the original corpus, while state-of-the-art DP synthesis methods generally fail to do so, even at $\varepsilon=100$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
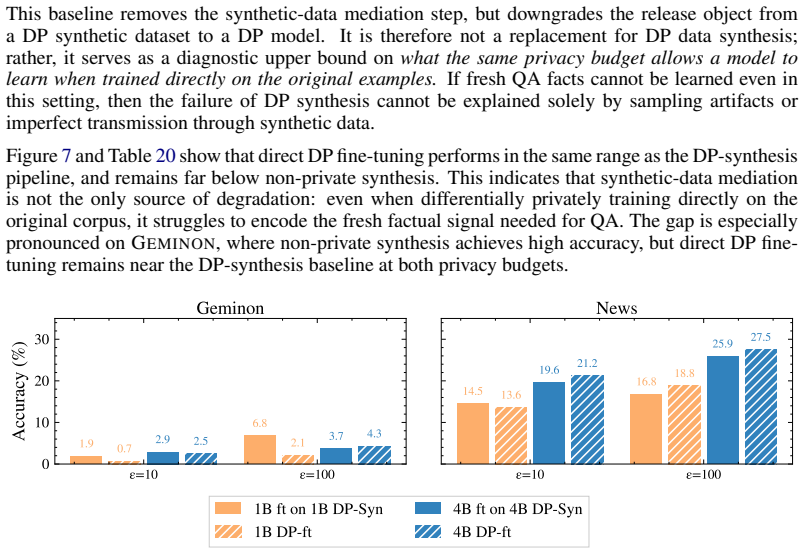
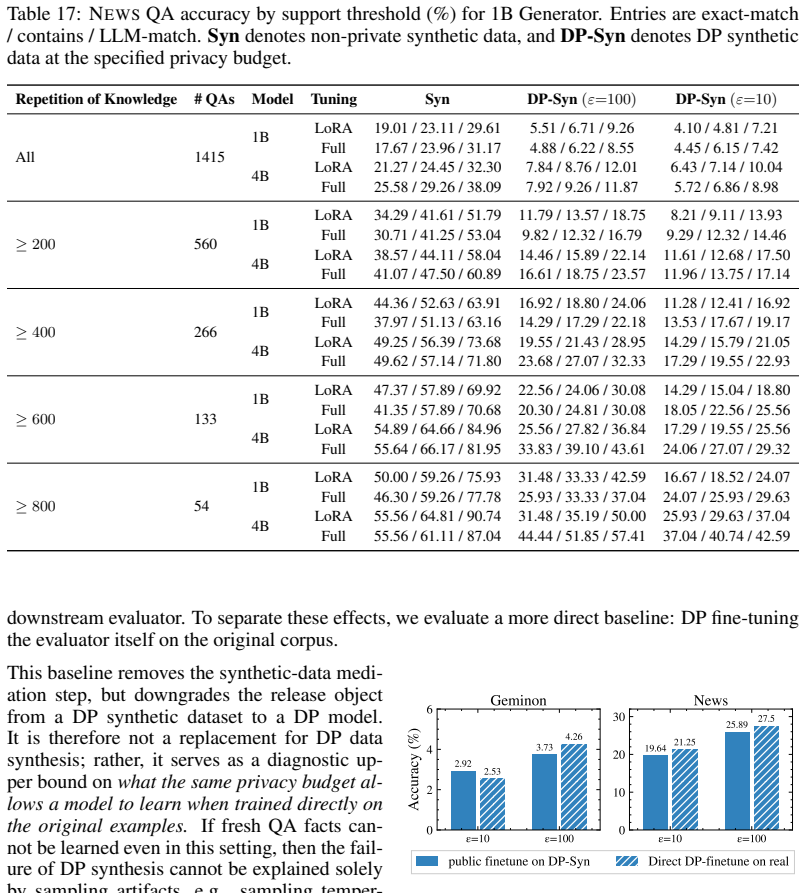
Summary. The paper introduces ContinuousBench, a benchmark that pairs never-before-seen training corpora (Geminon procedural creatures and News articles) with derived QA sets constructed to be unsolvable without the corpus and learnable under DP. Experiments show non-private synthesis transfers substantial knowledge while state-of-the-art DP synthesis methods fail to do so even at ε=100, using a standardized training/evaluation harness.
Significance. If the QA construction reliably ensures unsolvability without the corpus and sufficient redundancy for DP learnability, the benchmark would fill a key gap in DP evaluation by moving beyond saturated tasks; the headline empirical contrast between non-private and DP synthesis would then carry substantial weight for privacy-preserving training.
major comments (2)
- [Abstract] Abstract (and benchmark construction section): the central claim that 'DP synthesis methods generally fail to do so' rests on QA items being unsolvable sans the specific corpus. The manuscript asserts this 'by construction' for both tracks but provides no concrete mechanism (base-model zero-shot filtering protocol, human validation procedure, or redundancy count) to establish the property; without such evidence the measured non-private gains could reflect general pretraining rather than corpus transfer, undermining the DP-failure conclusion.
- [Methods] Methods (QA derivation and statistical tests): the claim that 'the tested knowledge is supported by hundreds of independent records' (allowing learnability under DP noise) is load-bearing for interpreting DP failure at ε=100 as a genuine limitation rather than an artifact of insufficient signal. No explicit counting procedure, exclusion rules, or power analysis is referenced to support this redundancy threshold.
minor comments (2)
- [Abstract] Clarify the exact base models and prompting used for any pre-filtering of QA items to make the 'unsolvable sans-corpus' claim reproducible.
- Figure or table reporting per-track base-model accuracy on the QA sets (with and without corpus) would strengthen the construction claim.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on ContinuousBench. We address the major concerns regarding the benchmark construction below and will revise the manuscript accordingly to provide the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract (and benchmark construction section): the central claim that 'DP synthesis methods generally fail to do so' rests on QA items being unsolvable sans the specific corpus. The manuscript asserts this 'by construction' for both tracks but provides no concrete mechanism (base-model zero-shot filtering protocol, human validation procedure, or redundancy count) to establish the property; without such evidence the measured non-private gains could reflect general pretraining rather than corpus transfer, undermining the DP-failure conclusion.
Authors: We agree that the current manuscript does not provide sufficient detail on the mechanisms used to ensure unsolvability by construction. In the revised version, we will expand the benchmark construction section to explicitly describe the base-model zero-shot filtering protocol, the human validation procedure employed, and the redundancy counting approach. This will substantiate that the QA items test corpus-specific knowledge rather than general pretraining capabilities. revision: yes
-
Referee: [Methods] Methods (QA derivation and statistical tests): the claim that 'the tested knowledge is supported by hundreds of independent records' (allowing learnability under DP noise) is load-bearing for interpreting DP failure at ε=100 as a genuine limitation rather than an artifact of insufficient signal. No explicit counting procedure, exclusion rules, or power analysis is referenced to support this redundancy threshold.
Authors: We acknowledge the need for explicit documentation of the redundancy verification. The revision will include a detailed description of the counting procedure for independent records, the exclusion rules applied to avoid overcounting, and a power analysis confirming that the signal is sufficient for learnability under the DP noise levels tested. This will support the interpretation of the DP synthesis results. revision: yes
Circularity Check
No significant circularity; results are empirical evaluations on new benchmark data.
full rationale
The paper introduces ContinuousBench with QA sets asserted to be unsolvable without the corpus and learnable under DP by construction, then reports empirical measurements showing non-private synthesis transfers knowledge while DP methods do not. These outcomes are obtained via standardized training/evaluation harness on generated data rather than any derivation that reduces to fitted parameters, self-definitions, or self-citation chains. No equations or claims equate a 'prediction' to its inputs by construction, and the central comparison rests on external experimental outcomes against the benchmark rather than internal redefinitions. The load-bearing properties of the QA sets are presented as design choices whose validity is tested by the reported performance gaps, not presupposed in a way that forces the headline result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 41st International Conference on Machine Learning , pages =
Position: Considerations for Differentially Private Learning with Large-Scale Public Pretraining , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , volume =
2024
-
[2]
2024 , eprint=
Gecko: Versatile Text Embeddings Distilled from Large Language Models , author=. 2024 , eprint=
2024
-
[3]
2021 , eprint=
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers , author=. 2021 , eprint=
2021
-
[4]
NeurIPS 2023 Workshop on Socially Responsible Language Modelling Research (SoLaR) , year=
Training Private and Efficient Language Models with Synthetic Data from LLMs , author=. NeurIPS 2023 Workshop on Socially Responsible Language Modelling Research (SoLaR) , year=
2023
-
[5]
Differentially Private Synthetic Data via Foundation Model
Xie, Chulin and Lin, Zinan and Backurs, Arturs and Gopi, Sivakanth and Yu, Da and Inan, Huseyin A and Nori, Harsha and Jiang, Haotian and Zhang, Huishuai and Lee, Yin Tat and Li, Bo and Yekhanin, Sergey , booktitle =. Differentially Private Synthetic Data via Foundation Model. 2024 , editor =
2024
-
[6]
Reuel, Anka and Hardy, Amelia and Smith, Chandler and Lamparth, Max and Hardy, Malcolm and Kochenderfer, Mykel J , journal=
-
[7]
Lin, Bill Yuchen and Deng, Yuntian and Chandu, Khyathi and Brahman, Faeze and Ravichander, Abhilasha and Pyatkin, Valentina and Dziri, Nouha and Bras, Ronan Le and Choi, Yejin , journal=
-
[8]
Li, Jeffrey and Fang, Alex and Smyrnis, Georgios and Ivgi, Maor and Jordan, Matt and Gadre, Samir and Bansal, Hritik and Guha, Etash and Keh, Sedrick and Arora, Kushal and others , journal=
-
[9]
Private prediction for large-scale synthetic text generation
Amin, Kareem and Bie, Alex and Kong, Weiwei and Kurakin, Alexey and Ponomareva, Natalia and Syed, Umar and Terzis, Andreas and Vassilvitskii, Sergei. Private prediction for large-scale synthetic text generation. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024
2024
-
[10]
Proceedings of the 42nd International Conference on Machine Learning , year =
Synthesizing Privacy-Preserving Text Data via Finetuning without Finetuning Billion-Scale LLMs , author =. Proceedings of the 42nd International Conference on Machine Learning , year =
-
[11]
2025 , url=
Wang, Shuaiqi and Raunak, Vikas and Backurs, Arturs and Reis, Victor and Zhou, Pei and Chen, Sihao and Yang, Longqi and Lin, Zinan and Yekhanin, Sergey and Fanti, Giulia , booktitle=. 2025 , url=
2025
-
[12]
ACTG-ARL: Differentially Private Conditional Text Generation with RL-Boosted Control
Yuzheng Hu and Ryan McKenna and Da Yu and Shanshan Wu and Han Zhao and Zheng Xu and Peter Kairouz , year=. doi:10.48550/arXiv.2510.18232 , url=. 2510.18232 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18232
-
[13]
Natalia Ponomareva and Zheng Xu and H. Brendan McMahan and Peter Kairouz and Lucas Rosenblatt and Vincent Cohen-Addad and Cristóbal Guzmán and Ryan McKenna and Galen Andrew and Alex Bie and Da Yu and Alex Kurakin and Morteza Zadimoghaddam and Sergei Vassilvitskii and Andreas Terzis , year=. doi:10.48550/arXiv.2512.03238 , url=. 2512.03238 , archivePrefix=
-
[14]
Harnessing large-language models to generate private synthetic text , author=. 2023 , eprint=. doi:10.48550/arXiv.2306.01684 , url=
-
[15]
2021 , publisher =
maca11 , title =. 2021 , publisher =
2021
-
[16]
International Studies Association Annual Conference , volume=
GDELT: Global Data on Events, Location, and Tone, 1979-2012 , author=. International Studies Association Annual Conference , volume=. 2013 , address=
1979
-
[17]
2024 , publisher =
Thiago Amancio , title =. 2024 , publisher =
2024
-
[18]
2025 , url=
Wu, Xiaobao and Pan, Liangming and Xie, Yuxi and Zhou, Ruiwen and Zhao, Shuai and Ma, Yubo and Du, Mingzhe and Mao, Rui and Luu, Anh Tuan and Wang, William Yang , booktitle=. 2025 , url=
2025
-
[19]
F resh LLM s: Refreshing Large Language Models with Search Engine Augmentation
Vu, Tu and Iyyer, Mohit and Wang, Xuezhi and Constant, Noah and Wei, Jerry and Wei, Jason and Tar, Chris and Sung, Yun-Hsuan and Zhou, Denny and Le, Quoc and Luong, Thang. F resh LLM s: Refreshing Large Language Models with Search Engine Augmentation. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.813
-
[20]
and Kolter, J
Maini, Pratyush and Feng, Zhili and Schwarzschild, Avi and Lipton, Zachary C. and Kolter, J. Zico , booktitle=. 2024 , url=
2024
-
[21]
2022 , volume =
Liska, Adam and Kocisky, Tomas and Gribovskaya, Elena and Terzi, Tayfun and Sezener, Eren and Agrawal, Devang and De Masson D'Autume, Cyprien and Scholtes, Tim and Zaheer, Manzil and Young, Susannah and Gilsenan-Mcmahon, Ellen and Austin, Sophia and Blunsom, Phil and Lazaridou, Angeliki , booktitle =. 2022 , volume =
2022
-
[22]
Evaluating Differentially Private Generation of Domain-Specific Text , author=. Proceedings of the 34th ACM International Conference on Information and Knowledge Management (CIKM '25) , pages=. 2025 , publisher=. doi:10.1145/3627673.3680074 , url=
-
[23]
Evaluating Differentially Private Synthetic Data Generation in High-Stakes Domains
Ramesh, Krithika and Gandhi, Nupoor and Madaan, Pulkit and Bauer, Lisa and Peris, Charith and Field, Anjalie. Evaluating Differentially Private Synthetic Data Generation in High-Stakes Domains. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.894
-
[24]
Brendan and Vassilvitskii, Sergei and Chien, Steve and Thakurta, Abhradeep , journal=
Ponomareva, Natalia and Hazimeh, Hussein and Kurakin, Alex and Xu, Zheng and Denison, Carson and McMahan, H. Brendan and Vassilvitskii, Sergei and Chien, Steve and Thakurta, Abhradeep , journal=. How to. 2023 , doi=
2023
-
[25]
International Conference on Learning Representations (ICLR) , year=
Differentially Private Fine-tuning of Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[26]
Proceedings of the 42nd International Conference on Machine Learning , pages =
Scaling Laws for Differentially Private Language Models , author =. Proceedings of the 42nd International Conference on Machine Learning , pages =. 2025 , volume =
2025
-
[27]
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers , url =
Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid , booktitle =. MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers , url =
-
[28]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[30]
EmbeddingGemma Team , year=. 2509.20354 , archivePrefix=
-
[31]
Barbaresi, Adrien. Proceedings of the Joint Conference of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations
-
[32]
Ou-Yang, Lucas , journal=
-
[33]
Chen, Kai and Li, Xiaochen and Gong, Chen and Mckenna, Ryan and Wang, Tianhao , title =. Proc. ACM Manag. Data , month = dec, articleno =. 2025 , issue_date =. doi:10.1145/3769764 , abstract =
-
[34]
Chen Gong and Kecen Li and Zinan Lin and Tianhao Wang , year=. 2503.14681 , archivePrefix=
-
[35]
Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7, 2006
Calibrating noise to sensitivity in private data analysis , author=. Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7, 2006. Proceedings 3 , pages=. 2006 , organization=
2006
-
[36]
Advances in Cryptology-EUROCRYPT 2006: 25th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St
Our data, ourselves: Privacy via distributed noise generation , author=. Advances in Cryptology-EUROCRYPT 2006: 25th Annual International Conference on the Theory and Applications of Cryptographic Techniques, St. Petersburg, Russia, May 28-June 1, 2006. Proceedings 25 , pages=. 2006 , organization=
2006
-
[37]
McKenna, Ryan and Andrew, Galen and Balle, Borja and Doroshenko, Vadym and Ganesh, Arun and Kong, Weiwei and Kurakin, Alex and McMahan, Brendan and Pravilov, Mikhail , journal=
-
[38]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Instruction pre-training: Language models are supervised multitask learners , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[39]
arXiv preprint arXiv:2504.05571 , year=
Knowledge-instruct: Effective continual pre-training from limited data using instructions , author=. arXiv preprint arXiv:2504.05571 , year=
-
[40]
and Daly, Raymond E
Maas, Andrew L. and Daly, Raymond E. and Pham, Peter T. and Huang, Dan and Ng, Andrew Y. and Potts, Christopher , title =. Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies , month =. 2011 , address =
2011
-
[41]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[42]
2024 , howpublished =
Yelp Open Dataset , author =. 2024 , howpublished =
2024
-
[43]
2017 , eprint=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. 2017 , eprint=
2017
-
[44]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[45]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[46]
arXiv preprint arXiv:2503.05919 , year=
From style to facts: Mapping the boundaries of knowledge injection with finetuning , author=. arXiv preprint arXiv:2503.05919 , year=
-
[47]
arXiv preprint arXiv:2409.07431 , year=
Synthetic continued pretraining , author=. arXiv preprint arXiv:2409.07431 , year=
-
[48]
arXiv preprint arXiv:2309.14316 , year=
Physics of language models: Part 3.1, knowledge storage and extraction , author=. arXiv preprint arXiv:2309.14316 , year=
-
[49]
arXiv:1509.01626 [cs] , author =
Character-Level. arXiv:1509.01626 [cs] , author =. arXiv , eprinttype =:1509.01626 , primaryClass =
-
[50]
Wu, Yuping and Schlegel, Viktor and Del-Pinto, Warren and Nandakumar, Srinivasan and Zahid, Iqra and Sun, Yidan and Omar, Usama Farghaly and Jasmine, Amirah and Kaliya-Perumal, Arun-Kumar and Tham, Chun Shen and others , journal=
-
[51]
doi: 10.18653/v1/2023.acl-long.74
Yue, Xiang and Inan, Huseyin and Li, Xuechen and Kumar, Girish and McAnallen, Julia and Shajari, Hoda and Sun, Huan and Levitan, David and Sim, Robert. Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. do...
-
[52]
Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , title =
Abadi, Martin and Chu, Andy and Goodfellow, Ian and McMahan, H. Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , title =. Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security , year =. doi:10.1145/2976749.2978318 , pages =
-
[53]
Sun, Yidan and Schlegel, Viktor and Nandakumar, Srinivasan and Zahid, Iqra and Wu, Yuping and Wu, Yulong and Li, Hao and Zhang, Jie and Del-Pinto, Warren and Nenadic, Goran and others , journal=
-
[54]
Contrastive Private Data Synthesis via Weighted Multi-
Tianyuan Zou and Yang Liu and Peng Li and Yufei Xiong and Jianqing Zhang and Jingjing Liu and Xiaozhou Ye and Ye Ouyang and Ya-Qin Zhang , booktitle=. Contrastive Private Data Synthesis via Weighted Multi-. 2025 , url=
2025
-
[55]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Private Evolution Converges , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[56]
2025 , url=
Jianqing Zhang and Yang Liu and JIE FU and Yang Hua and Tianyuan Zou and Jian Cao and Qiang Yang , booktitle=. 2025 , url=
2025
-
[57]
The Fourteenth International Conference on Learning Representations , year=
Secret-Protected Evolution for Differentially Private Synthetic Text Generation , author=. The Fourteenth International Conference on Learning Representations , year=
-
[58]
Banayeeanzade, Amin and Yang, Qingchuan and Fu, Deqing and Hong, Spencer and Babinsky, Erin and Samuel, Alfy and Kumar, Anoop and Jia, Robin and Karimireddy, Sai Praneeth , journal=
-
[59]
2024 , booktitle =
Hou, Charlie and Shrivastava, Akshat and Zhan, Hongyuan and Conway, Rylan and Le, Trang and Sagar, Adithya and Fanti, Giulia and Lazar, Daniel , title =. 2024 , booktitle =
2024
-
[60]
Differentially Private Language Models for Secure Data Sharing
Mattern, Justus and Jin, Zhijing and Weggenmann, Benjamin and Sch. Differentially Private Language Models for Secure Data Sharing. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.323
-
[61]
The Fourth AAAI Workshop on Privacy-Preserving Artificial Intelligence (PPAI) , primaryClass=
Can Foundation Models Help Us Achieve Perfect Secrecy? , author=. The Fourth AAAI Workshop on Privacy-Preserving Artificial Intelligence (PPAI) , primaryClass=. 2022 , url=
2022
-
[62]
Scalable
Lynn Chua and Badih Ghazi and Pritish Kamath and Ravi Kumar and Pasin Manurangsi and Amer Sinha and Chiyuan Zhang , booktitle=. Scalable. 2024 , url=
2024
-
[63]
arXiv preprint arXiv:2508.15089 , year=
Tighter privacy analysis for truncated Poisson sampling , author=. arXiv preprint arXiv:2508.15089 , year=
-
[64]
arXiv preprint arXiv:2204.13650 , year=
Unlocking high-accuracy differentially private image classification through scale , author=. arXiv preprint arXiv:2204.13650 , year=
-
[65]
2022 ,booktitle =
Large-Scale Differentially Private BERT ,author =. 2022 ,booktitle =
2022
-
[66]
International Conference on Learning Representations , year=
Large Language Models Can Be Strong Differentially Private Learners , author=. International Conference on Learning Representations , year=
-
[67]
2023 , volume =
Sander, Tom and Stock, Pierre and Sablayrolles, Alexandre , booktitle =. 2023 , volume =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.