The Image Reconstruction Game: Drawing Common Ground Through Iterative Multimodal Dialogue
Pith reviewed 2026-06-28 15:40 UTC · model grok-4.3
The pith
The describer model is the dominant factor in reconstruction quality in the Image Reconstruction Game, while the generator determines whether iterative refinement helps or hurts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
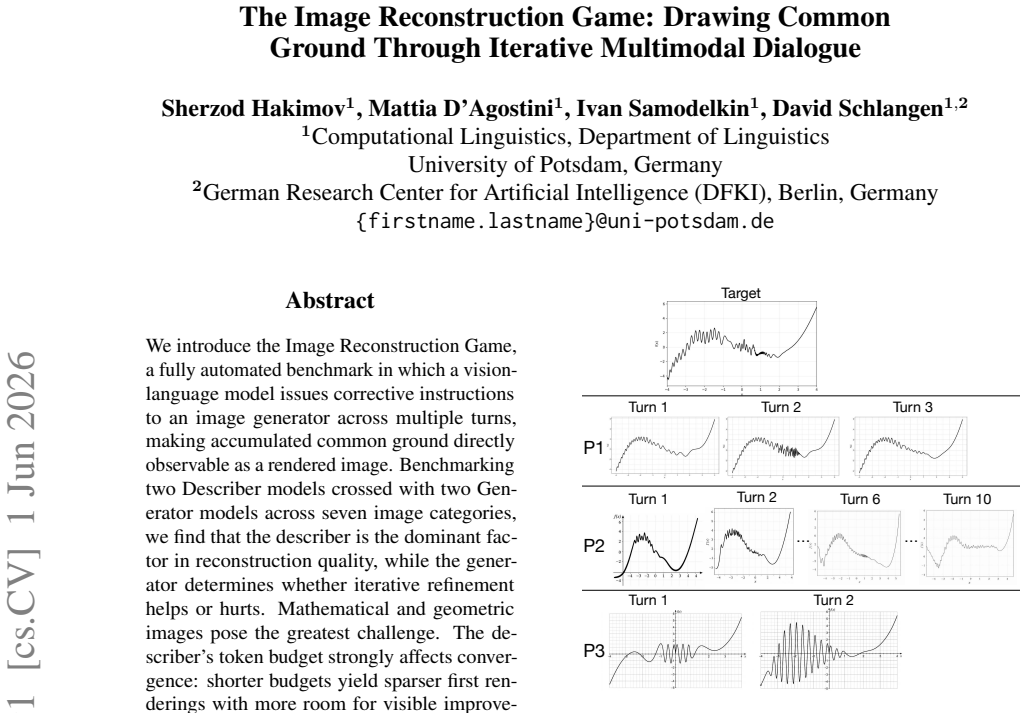
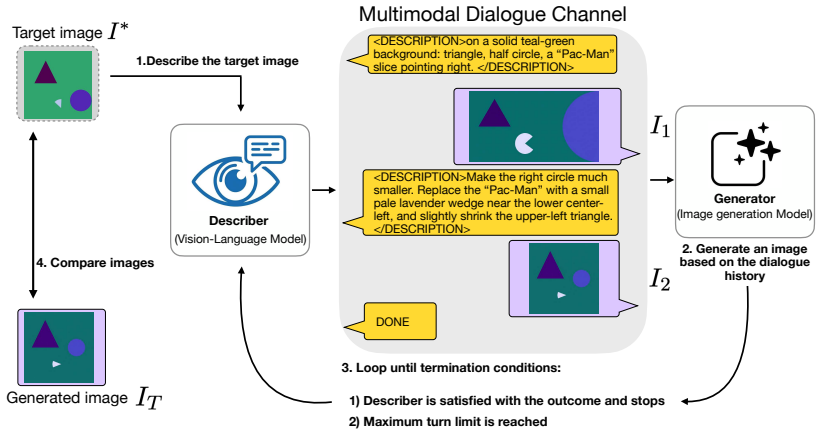
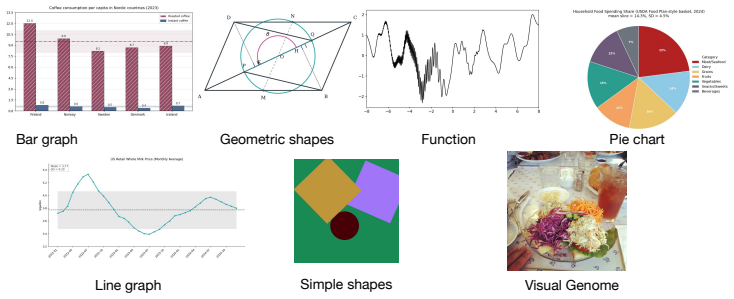
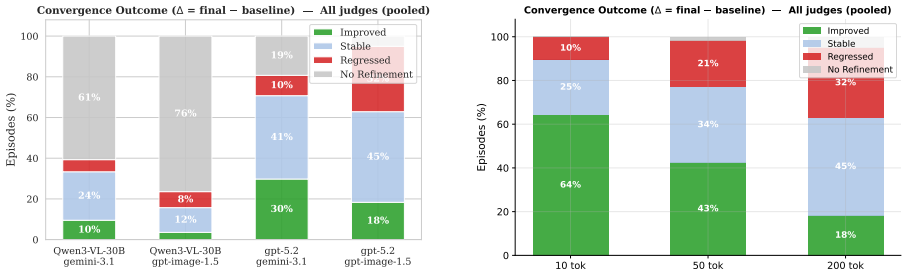
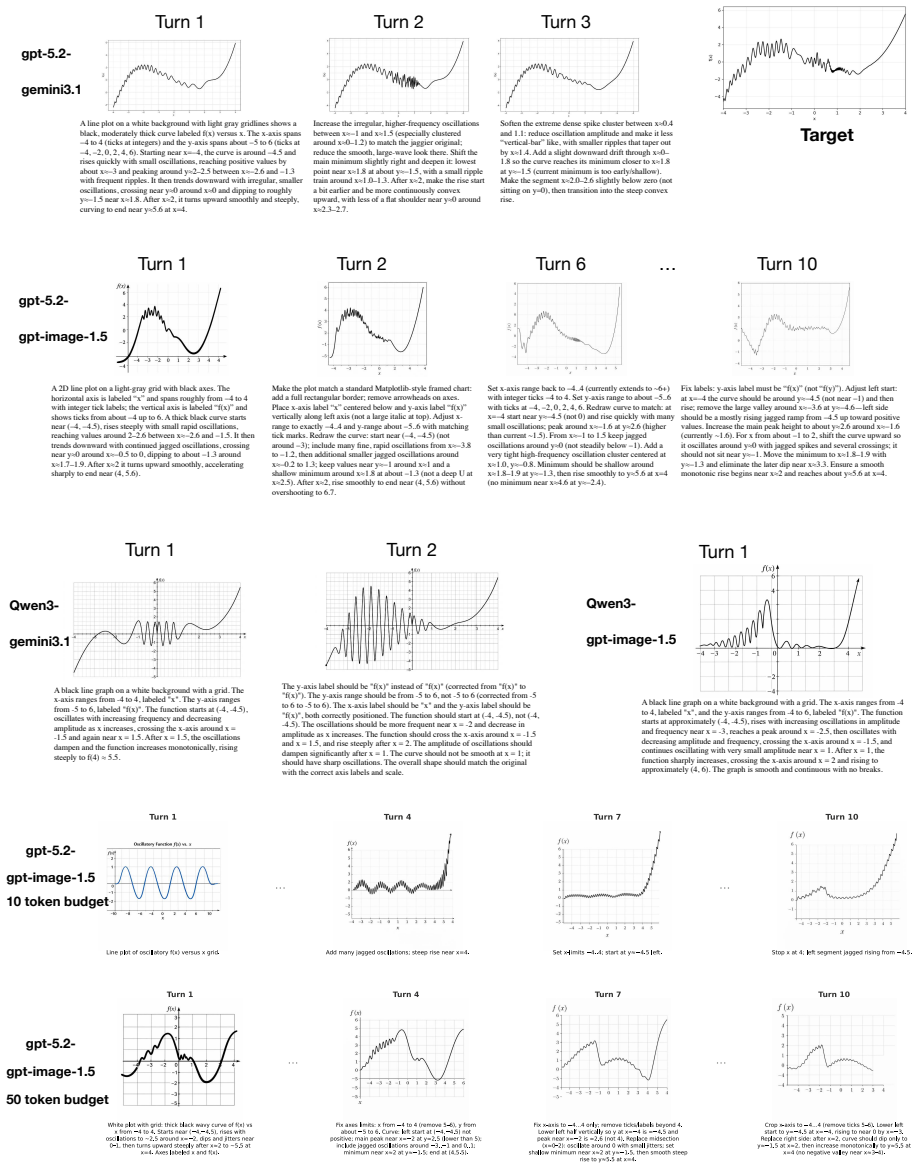
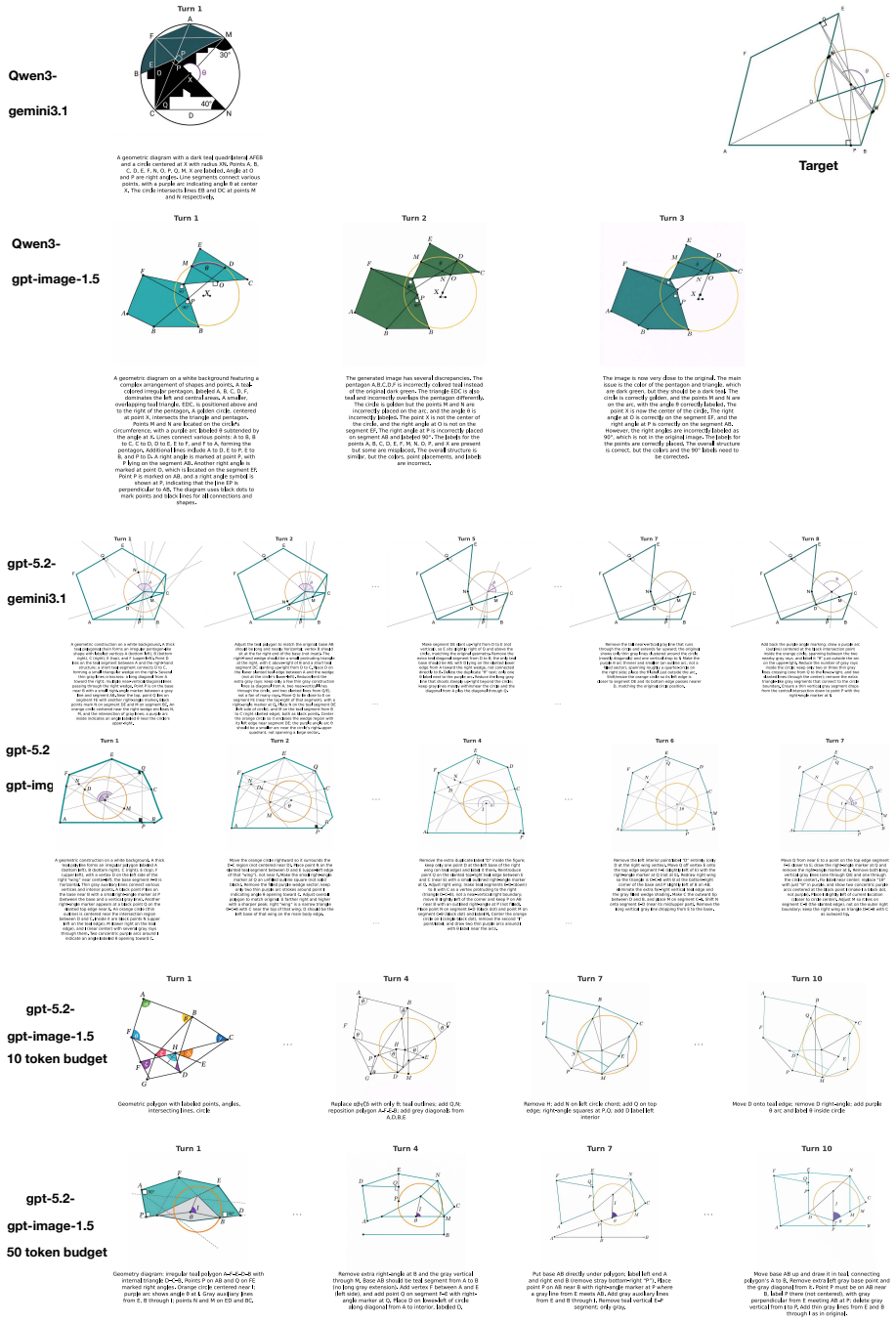
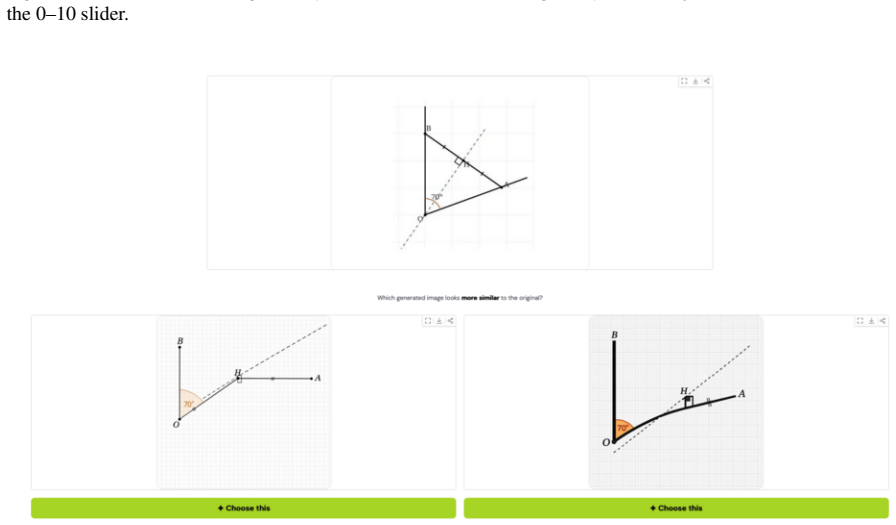
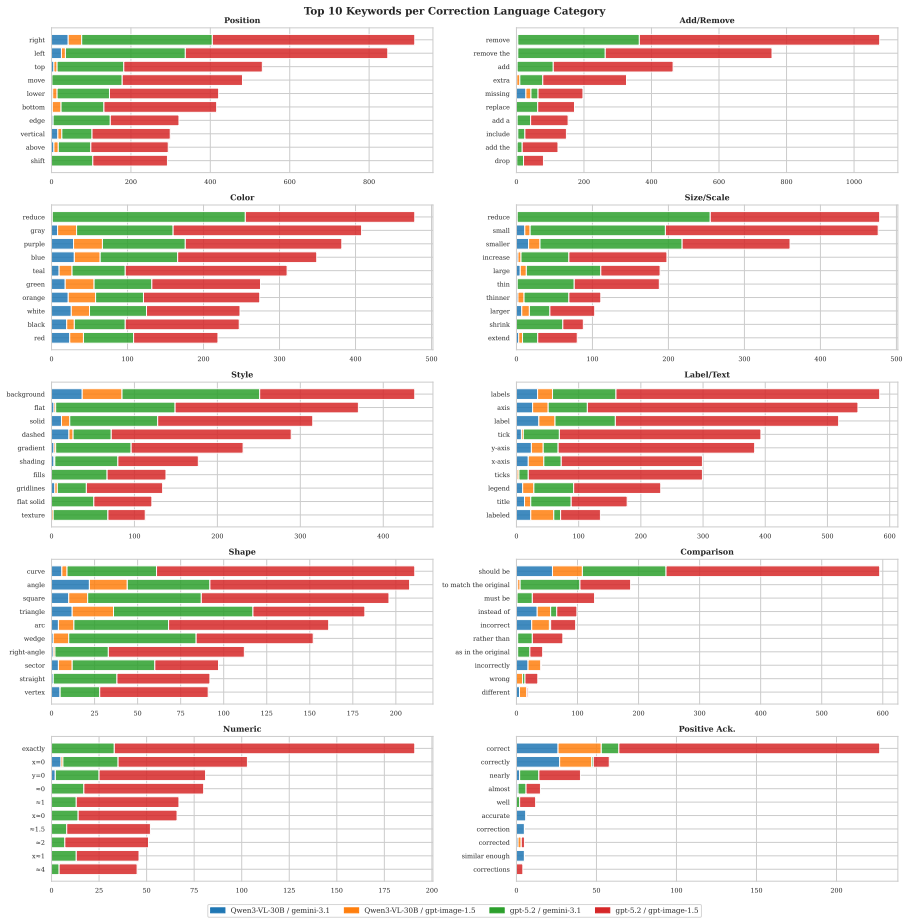
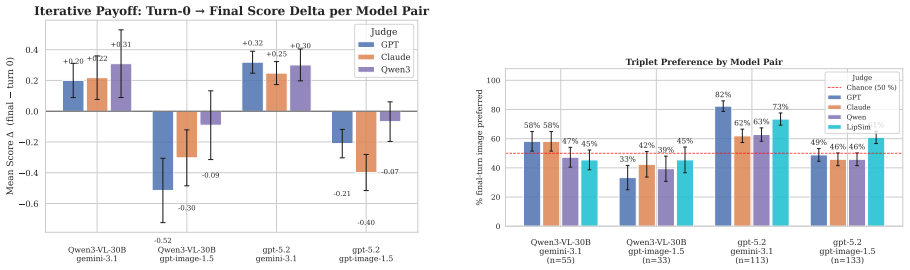
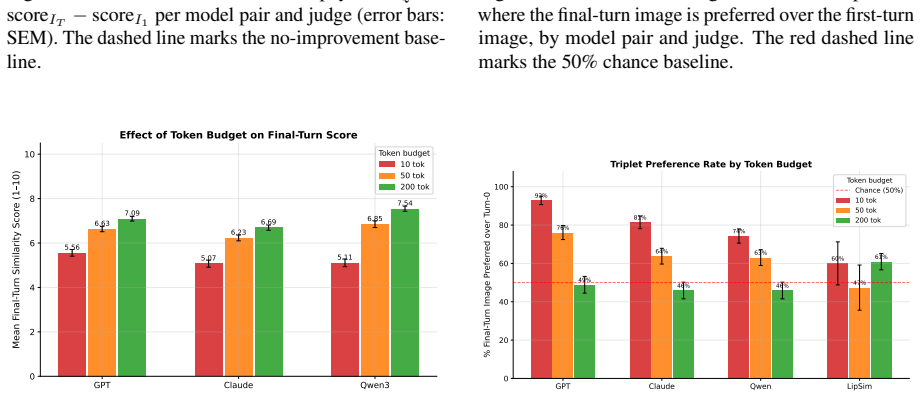
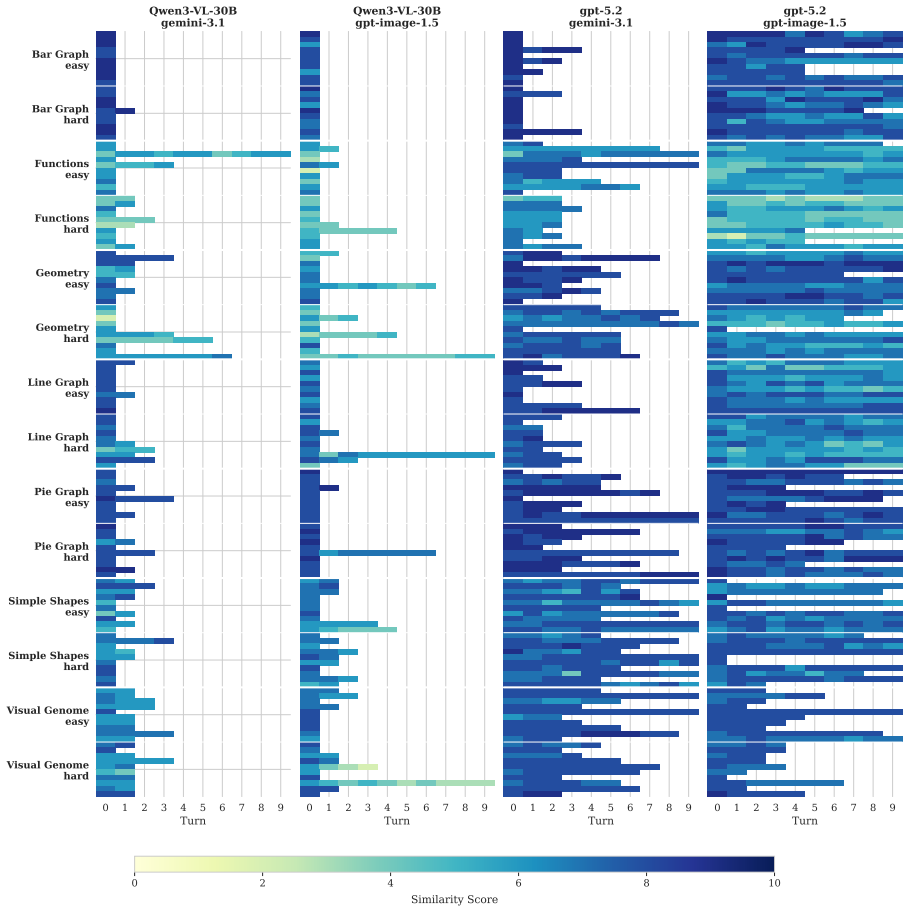
The Image Reconstruction Game reveals that the describer's abilities are the main driver of how accurately a target image can be reconstructed through dialogue, with the generator's role being to enable or limit the value of iterative corrections. Mathematical and geometric images present the largest obstacles. Token budget constraints on the describer shape the process by determining how much the initial rendering leaves room for refinement.
What carries the argument
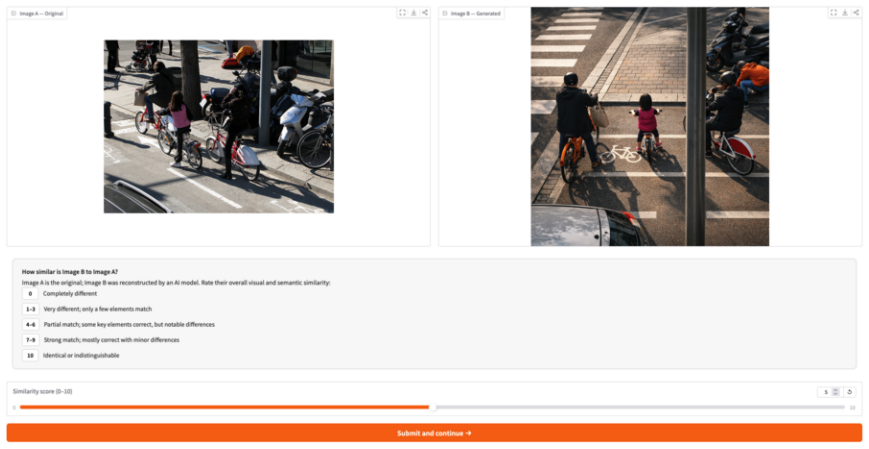
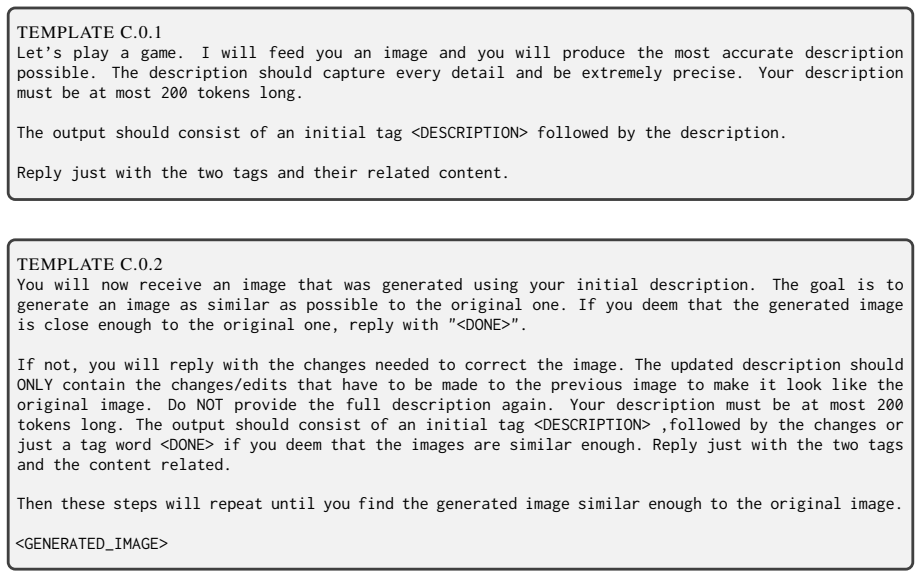
The Image Reconstruction Game benchmark, which makes accumulated common ground observable as the final rendered image after iterative multimodal corrections from describer to generator.
Load-bearing premise
The chosen image categories, model pairs, and automated similarity metrics validly measure accumulated common ground and generalize beyond the tested setups.
What would settle it
A replication using different image categories or metrics that reverses the finding of describer dominance over generator would falsify the central claim.
Figures



read the original abstract
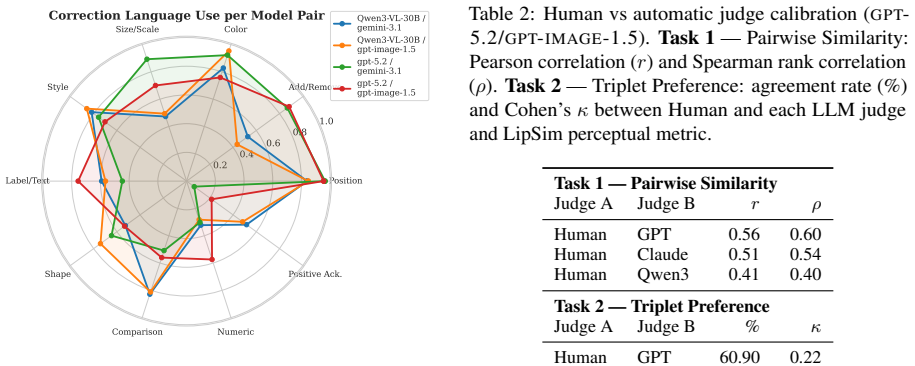
We introduce the Image Reconstruction Game, a fully automated benchmark in which a vision-language model issues corrective instructions to an image generator across multiple turns, making accumulated common ground directly observable as a rendered image. Benchmarking two Describer models crossed with two Generator models across seven image categories, we find that the describer is the dominant factor in reconstruction quality, while the generator determines whether iterative refinement helps or hurts. Mathematical and geometric images pose the greatest challenge. The describer's token budget strongly affects convergence: shorter budgets yield sparser first renderings with more room for visible improvement, while longer budgets raise absolute quality but leave less to fix. Stronger describers use a richer correction vocabulary spanning spatial, numeric, and structural categories, while weaker describers concentrate on surface properties and tend to stop after a few turns. Human validation shows that the best automated judge reaches only slight-to-fair agreement with human preferences, and automated scores require human recalibration to be used reliably.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Image Reconstruction Game, a benchmark in which a vision-language describer model issues iterative corrective instructions to an image generator model, with accumulated common ground measured directly via the rendered output image. Benchmarking two describers crossed with two generators across seven image categories, the central claims are that the describer is the dominant factor in final reconstruction quality, the generator determines whether iteration improves or harms results, mathematical and geometric images are hardest, describer token budget strongly modulates convergence and initial sparsity, and stronger describers employ richer correction vocabularies. The manuscript reports that the best automated similarity metric achieves only slight-to-fair agreement with human preferences and requires recalibration.
Significance. If the empirical patterns hold under validated metrics, the work supplies a novel, fully automated protocol for making multimodal common ground observable as image evolution rather than text alone. The direct comparison of model pairs and the token-budget and vocabulary findings could usefully inform the design of collaborative vision-language systems. The absence of free parameters or circular derivations is a strength of the empirical design.
major comments (2)
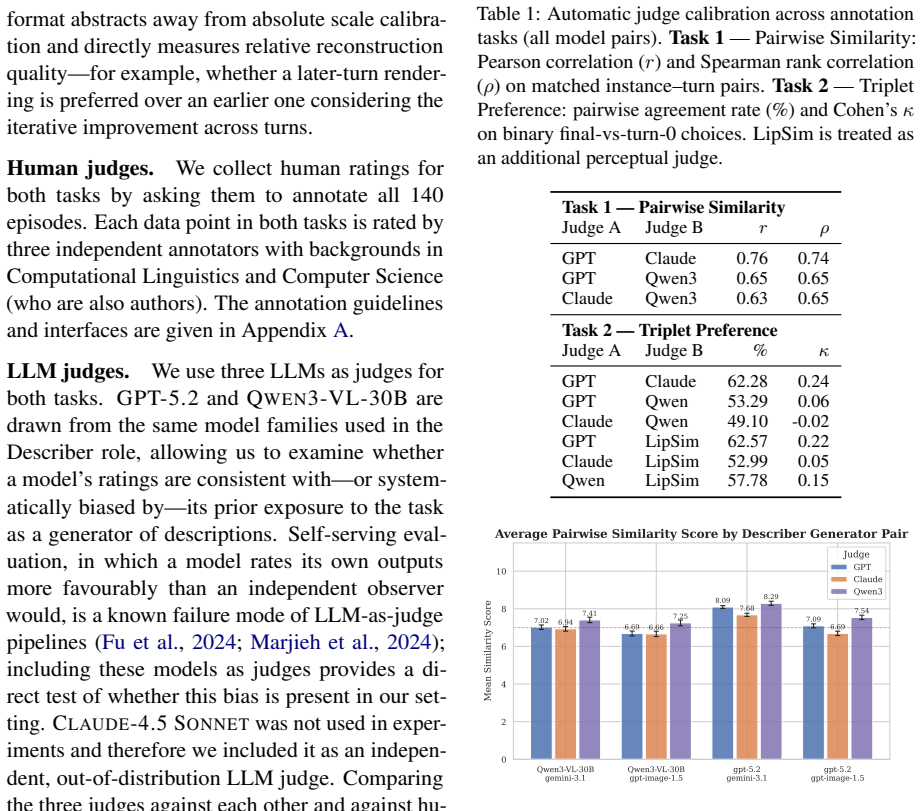
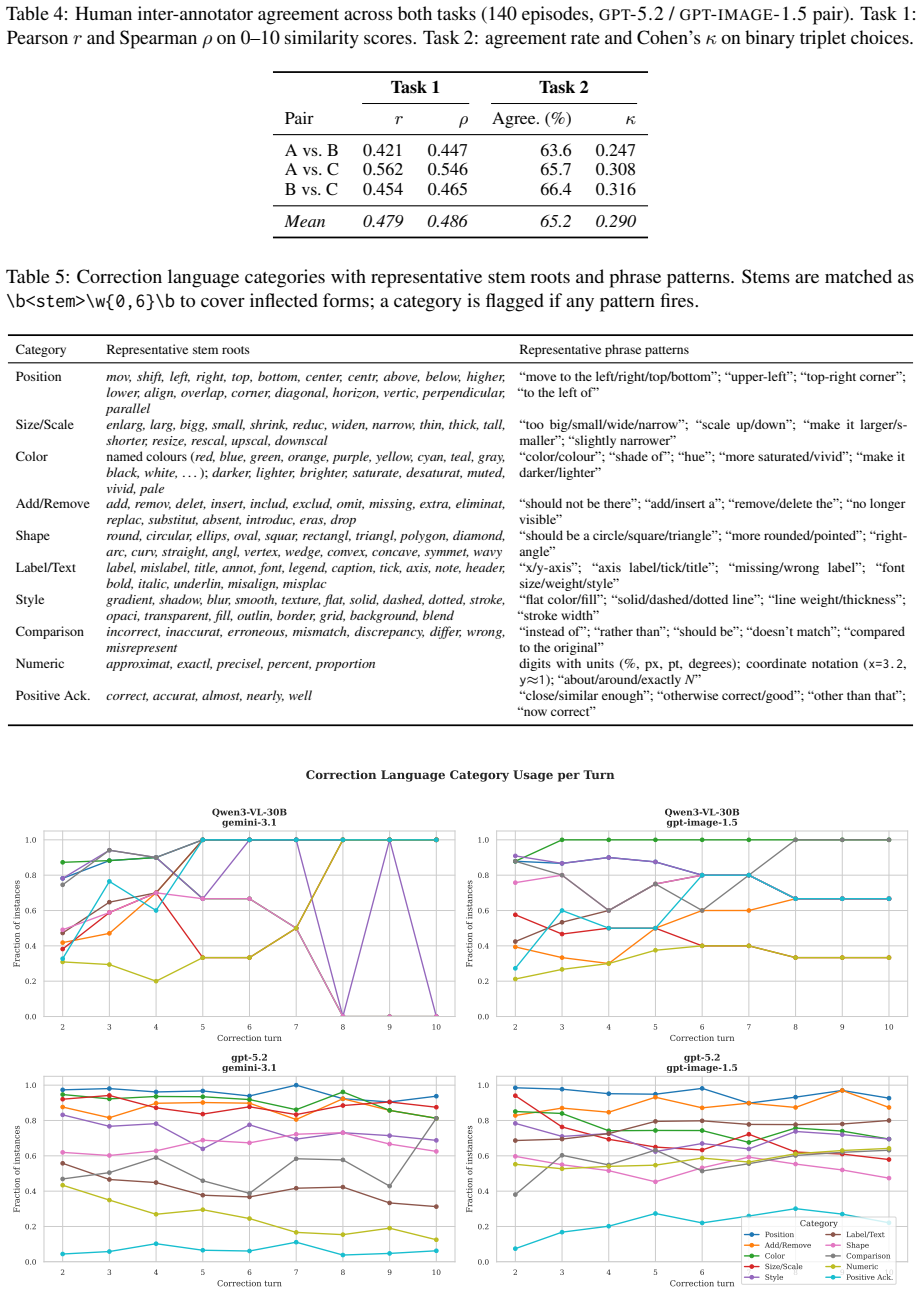
- [Abstract / Results] Abstract and Results: The claims that the describer is the dominant factor, that the generator modulates whether refinement helps, and that token budget affects convergence are all derived from automated image similarity scores. Yet the manuscript states that even the best automated judge reaches only slight-to-fair agreement with human preferences. This correlation level is load-bearing for the central claims; without additional evidence that the chosen metrics track human judgments of corrective dialogue quality on the specific image categories used, the reported dominance patterns risk reflecting metric artifacts rather than accumulated common ground.
- [Evaluation] Evaluation section: No independent verification is described that the automated metrics were calibrated or validated against human judgments specifically for the seven image categories and the iterative correction setting. The manuscript notes that scores 'require human recalibration to be used reliably,' but does not report the recalibration procedure or its effect on the reported model rankings and category difficulty orderings.
minor comments (2)
- [Methods] The manuscript should explicitly list the seven image categories, the exact model pairs, and the precise automated similarity metrics (including any preprocessing) so that the generalizability concern can be assessed by readers.
- [Figures / Tables] Figure captions and table legends would benefit from stating the number of trials per condition and whether error bars represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for stronger grounding of automated metrics. We address the two major comments point-by-point below and will revise the manuscript to qualify claims and clarify evaluation limitations.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results: The claims that the describer is the dominant factor, that the generator modulates whether refinement helps, and that token budget affects convergence are all derived from automated image similarity scores. Yet the manuscript states that even the best automated judge reaches only slight-to-fair agreement with human preferences. This correlation level is load-bearing for the central claims; without additional evidence that the chosen metrics track human judgments of corrective dialogue quality on the specific image categories used, the reported dominance patterns risk reflecting metric artifacts rather than accumulated common ground.
Authors: We agree that the slight-to-fair human agreement constitutes a material limitation for the central claims, which rely on the automated scores. The manuscript already flags this issue in the abstract, but does not sufficiently qualify the reported dominance patterns. In revision we will (1) add explicit caveats to the abstract and results stating that all dominance, convergence, and category-difficulty findings are conditioned on the chosen automated metrics and (2) insert a dedicated limitations paragraph discussing the risk of metric artifacts. No new human validation data for the seven categories exists in the current study. revision: yes
-
Referee: [Evaluation] Evaluation section: No independent verification is described that the automated metrics were calibrated or validated against human judgments specifically for the seven image categories and the iterative correction setting. The manuscript notes that scores 'require human recalibration to be used reliably,' but does not report the recalibration procedure or its effect on the reported model rankings and category difficulty orderings.
Authors: The manuscript does not contain a recalibration procedure or its results because none was performed; the phrase about requiring recalibration is an acknowledgment of an unaddressed gap rather than a claim that such work was done. We will revise the Evaluation section to state explicitly that all reported scores are raw automated metrics without human recalibration, and we will add text clarifying that no category-specific or setting-specific validation was conducted. This change will also be reflected in the limitations discussion. revision: yes
Circularity Check
Empirical benchmark with no self-referential derivations or fitted predictions
full rationale
The paper introduces an experimental benchmark and reports results from running existing vision-language and image-generation models across image categories, measuring reconstruction quality via automated similarity metrics and noting human agreement levels. No equations, parameter fittings, uniqueness theorems, or self-citations are invoked as load-bearing steps in any derivation chain. All central claims (describer dominance, generator effects on refinement, token-budget impacts, category difficulty) rest on direct experimental outputs rather than reducing to inputs by construction. This is the normal case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lawrence Zitnick, Devi Parikh, and Dhruv Batra
Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Devi Parikh, and Dhruv Batra. 2017. https://doi.org/10.1007/S11263-016-0966-6 VQA: visual question answering - www.visualqa.org . Int. J. Comput. Vis., 123(1):4--31
-
[2]
Malihe Alikhani and Matthew Stone. 2020. https://doi.org/10.18653/V1/2020.ACL-TUTORIALS.3 Achieving common ground in multi-modal dialogue . In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: Tutorial Abstracts, ACL 2020, Online, July 5, 2020 , pages 10--15. Association for Computational Linguistics
-
[3]
Kranti Chalamalasetti, Jana G \" o tze, Sherzod Hakimov, Brielen Madureira, Philipp Sadler, and David Schlangen. 2023. https://doi.org/10.18653/V1/2023.EMNLP-MAIN.689 clembench: Using game play to evaluate chat-optimized language models as conversational agents . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EM...
-
[4]
Christopher Clark, Jordi Salvador, Dustin Schwenk, Derrick Bonafilia, Mark Yatskar, Eric Kolve, Alvaro Herrasti, Jonghyun Choi, Sachin Mehta, Sam Skjonsberg, Carissa Schoenick, Aaron Sarnat, Hannaneh Hajishirzi, Aniruddha Kembhavi, Oren Etzioni, and Ali Farhadi. 2021. https://doi.org/10.18653/V1/2021.EMNLP-MAIN.141 Iconary: A pictionary-based game for tes...
-
[5]
Herbert H. Clark. 1996. Using Language. Cambridge University Press, Cambridge
1996
-
[6]
Nicholas Davis, Chih-Pin Hsiao, Kunwar Yashraj Singh, Boyang Lin, and Brian Magerko. 2017. https://doi.org/10.1145/3009981 Quantifying collaboration with a co-creative drawing agent . ACM Transactions on Interactive Intelligent Systems, 7(4)
-
[7]
Nicholas Davis, Chih-Pin Hsiao, Kunwar Yashraj Singh, and Brian Magerko. 2016. https://ojs.aaai.org/index.php/AIIDE/article/view/12863 Co-creative drawing agent with object recognition . In Proceedings of the Twelfth AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, AIIDE'16, pages 9--15. AAAI Press
2016
-
[8]
Nicholas Davis and Janet Rafner. 2025. https://doi.org/10.48550/ARXIV.2501.06607 AI drawing partner: Co-creative drawing agent and research platform to model co-creation . CoRR, abs/2501.06607
-
[9]
Devon Hjelm, Layla El Asri, Samira Ebrahimi Kahou, Yoshua Bengio, and Graham W
Alaaeldin El - Nouby, Shikhar Sharma, Hannes Schulz, R. Devon Hjelm, Layla El Asri, Samira Ebrahimi Kahou, Yoshua Bengio, and Graham W. Taylor. 2019. https://doi.org/10.1109/ICCV.2019.01040 Tell, draw, and repeat: Generating and modifying images based on continual linguistic instruction . In 2019 IEEE/CVF International Conference on Computer Vision, ICCV ...
-
[10]
Fan, Monica Dinculescu, and David Ha
Judith E. Fan, Monica Dinculescu, and David Ha. 2019. https://doi.org/10.1145/3325480.3326578 collabdraw: An environment for collaborative sketching with an artificial agent . In Proceedings of the 2019 Conference on Creativity and Cognition, C&C '19, page 556–561, New York, NY, USA. Association for Computing Machinery
-
[11]
Yuheng Feng, Jianhui Wang, Kun Li, Sida Li, Tianyu Shi, Haoyue Han, Miao Zhang, and Xueqian Wang. 2025. https://doi.org/10.48550/ARXIV.2503.17669 TDRI: two-phase dialogue refinement and co-adaptation for interactive image generation . CoRR, abs/2503.17669
-
[12]
Chrisantha Fernando, Daria Zenkova, Stanislav Nikolov, and Simon Osindero. 2020. https://arxiv.org/abs/2010.02820 From language games to drawing games . CoRR, abs/2010.02820
arXiv 2020
-
[13]
Smith, Wei - Chiu Ma, and Ranjay Krishna
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei - Chiu Ma, and Ranjay Krishna. 2024. https://doi.org/10.1007/978-3-031-73337-6\_9 BLINK: multimodal large language models can see but not perceive . In Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedi...
-
[14]
Sara Ghazanfari, Alexandre Araujo, Prashanth Krishnamurthy, Farshad Khorrami, and Siddharth Garg. 2024. https://openreview.net/forum?id=0w42S2Gp70 Lipsim: A provably robust perceptual similarity metric . In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net
2024
-
[15]
Janosch Haber, Tim Baumg \" a rtner, Ece Takmaz, Lieke Gelderloos, Elia Bruni, and Raquel Fern \' a ndez. 2019. https://doi.org/10.18653/V1/P19-1184 The photobook dataset: Building common ground through visually-grounded dialogue . In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- A...
-
[16]
Sherzod Hakimov, Yerkezhan Abdullayeva, Kushal Koshti, Antonia Schmidt, Yan Weiser, Anne Beyer, and David Schlangen. 2025. https://aclanthology.org/2025.coling-main.381/ Using game play to investigate multimodal and conversational grounding in large multimodal models . In Proceedings of the 31st International Conference on Computational Linguistics, COLIN...
2025
-
[17]
Ting Han and David Schlangen. 2017. https://aclanthology.org/I17-2061 Draw and tell: Multimodal descriptions outperform verbal- or sketch-only descriptions in an image retrieval task . In Proceedings of the 8th International Joint Conference on Natural Language Processing ( IJCNLP 2017), Volume 2: Short Papers , pages 361--365. Asian Federation of Natural...
2017
-
[18]
Yujie Hu, Zecheng Tang, Xu Jiang, Weiqi Li, and Jian Zhang. 2026. https://doi.org/10.48550/ARXIV.2601.01915 Talkphoto: A versatile training-free conversational assistant for intelligent image editing . CoRR, abs/2601.01915
-
[19]
Forrest Huang, Eldon Schoop, David Ha, and John Canny. 2020. https://doi.org/10.1145/3377325.3377485 Scones: Towards conversational authoring of sketches . In Proceedings of the 25th International Conference on Intelligent User Interfaces, pages 313--323. ACM
-
[20]
Minbin Huang, Yanxin Long, Xinchi Deng, Ruihang Chu, Jiangfeng Xiong, Xiaodan Liang, Hong Cheng, Qinglin Lu, and Wei Liu. 2025. https://doi.org/10.18653/V1/2025.FINDINGS-NAACL.25 Dialoggen: Multi-modal interactive dialogue system with multi-turn text-image generation . In Findings of the Association for Computational Linguistics: NAACL 2025, Albuquerque, ...
-
[21]
Francisco Ibarrola, Tomas Lawton, and Kazjon Grace. 2024. https://doi.org/10.1109/TVCG.2023.3293853 A collaborative, interactive and context-aware drawing agent for co-creative design . IEEE Trans. Vis. Comput. Graph. , 30(8):5525--5537
-
[22]
Jin - Hwa Kim, Nikita Kitaev, Xinlei Chen, Marcus Rohrbach, Byoung - Tak Zhang, Yuandong Tian, Dhruv Batra, and Devi Parikh. 2019. https://doi.org/10.18653/V1/P19-1651 Codraw: Collaborative drawing as a testbed for grounded goal-driven communication . In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florenc...
-
[23]
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li - Jia Li, David A. Shamma, Michael S. Bernstein, and Li Fei - Fei. 2017. https://doi.org/10.1007/S11263-016-0981-7 Visual genome: Connecting language and vision using crowdsourced dense image annotations . Int. J. Comput. Vis., 123(1):32--73
-
[24]
Hyunhee Lee, Gyeongmin Kim, Yuna Hur, and Heuiseok Lim. 2021. https://doi.org/10.1109/ACCESS.2021.3074973 Visual thinking of neural networks: Interactive text to image synthesis . IEEE Access , 9:64510--64523
-
[25]
Tao Li, Gang Li, Jingjie Zheng, Purple Wang, and Yang Li. 2024. https://aclanthology.org/2024.findings-eacl.17 MUG: interactive multimodal grounding on user interfaces . In Findings of the Association for Computational Linguistics: EACL 2024, St. Julian's, Malta, March 17-22, 2024 , Findings of ACL , pages 231--251. Association for Computational Linguistics
2024
-
[26]
Xiaoyuan Li, Moxin Li, Wenjie Wang, Rui Men, Yichang Zhang, Fuli Feng, Dayiheng Liu, and Junyang Lin. 2025. https://doi.org/10.48550/ARXIV.2507.18140 Mathopeval: A fine-grained evaluation benchmark for visual operations of mllms in mathematical reasoning . CoRR, abs/2507.18140
-
[27]
Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, and William Yang Wang. 2023. Llmscore: unveiling the power of large language models in text-to-image synthesis evaluation. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA. Curran Associates Inc
2023
-
[28]
Shichao Ma, Yunhe Guo, Jiahao Su, Qihe Huang, Zhengyang Zhou, and Yang Wang. 2026. https://ojs.aaai.org/index.php/AAAI/article/view/40519 Talk2Image : A multi-agent system for multi-turn image generation and editing . In Proceedings of the Fortieth AAAI Conference on Artificial Intelligence. AAAI Press
2026
-
[29]
Shichao Ma, Xinfeng Zhang, Zeng Zhao, Bai Liu, Changjie Fan, and Zhipeng Hu. 2025. https://ojs.aaai.org/index.php/AAAI/article/view/34661 DialogDraw : Image generation and editing system based on multi-turn dialogue . In Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence. AAAI Press
2025
-
[30]
Brielen Madureira and David Schlangen. 2023. https://doi.org/10.18653/V1/2023.EACL-MAIN.169 Instruction clarification requests in multimodal collaborative dialogue games: Tasks, and an analysis of the codraw dataset . In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2023, Dubrovnik, Croat...
-
[31]
Sumers, Nori Jacoby, and Thomas L
Raja Marjieh, Ilia Sucholutsky, Theodore R. Sumers, Nori Jacoby, and Thomas L. Griffiths. 2022. https://escholarship.org/uc/item/7mz2c7k4 Predicting human similarity judgments using large language models . In Proceedings of the 44th Annual Meeting of the Cognitive Science Society, CogSci 2022, Toronto, ON, Canada, July 27-30, 2022. cognitivesciencesociety.org
2022
-
[32]
Raja Marjieh, Ilia Sucholutsky, Pol van Rijn, Nori Jacoby, and Thomas L Griffiths. 2024. Large language models predict human sensory judgments across six modalities. Scientific Reports, 14(1):21445
2024
-
[33]
Daniela Mihai and Jonathon S. Hare. 2021. https://proceedings.neurips.cc/paper/2021/hash/39d0a8908fbe6c18039ea8227f827023-Abstract.html Learning to draw: Emergent communication through sketching . In Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, vir...
2021
-
[34]
Biswesh Mohapatra. 2023. https://doi.org/10.1145/3577190.3614226 Conversational grounding in multimodal dialog systems . In Proceedings of the 25th International Conference on Multimodal Interaction, pages 706--710. ACM
-
[35]
Shuwen Qiu, Sirui Xie, Lifeng Fan, Tao Gao, Jungseock Joo, Song - Chun Zhu, and Yixin Zhu. 2022. http://papers.nips.cc/paper\_files/paper/2022/hash/550ff553efc2c58410f277c667d12786-Abstract-Conference.html Emergent graphical conventions in a visual communication game . In Advances in Neural Information Processing Systems 35: Annual Conference on Neural In...
2022
-
[36]
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. 2020. https://arxiv.org/abs/1912.01734 ALFRED: A Benchmark for Interpreting Grounded Instructions for Everyday Tasks . In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
arXiv 2020
-
[37]
Yanpeng Sun, Shan Zhang, Wei Tang, Aotian Chen, Piotr Koniusz, Kai Zou, Yuan Xue, and Anton van den Hengel. 2025. https://arxiv.org/abs/2503.20745 Math blind: Failures in diagram understanding undermine reasoning in mllms . Preprint, arXiv:2503.20745
arXiv 2025
-
[38]
Alberto Testoni and Raquel Fern \' a ndez. 2024. https://aclanthology.org/2024.eacl-long.16 Asking the right question at the right time: Human and model uncertainty guidance to ask clarification questions . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024 - Volume 1: Long Papers, St....
2024
-
[39]
Ubaid Ullah, Jeong-Sik Lee, Chang-Hyeon An, Hyeonjin Lee, Su-Yeong Park, Rock-Hyun Baek, and Hyun-Chul Choi. 2022. https://doi.org/10.3390/s22186816 A review of multi-modal learning from the text-guided visual processing viewpoint . Sensors, 22(18):6816
-
[40]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Yael Vinker, Tamar Rott Shaham, Kristine Zheng, Alex Zhao, Judith E. Fan, and Antonio Torralba. 2025. https://doi.org/10.1109/CVPR52734.2025.02175 Sketchagent: Language-driven sequential sketch generation . In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025 , pages 23355--23368. Computer Visi...
-
[41]
Jianhui Wang, Yangfan He, Yan Zhong, Xinyuan Song, Jiayi Su, Yuheng Feng, Ruoyu Wang, Hongyang He, Wenyu Zhu, Xinhang Yuan, Miao Zhang, Keqin Li, Jiaqi Chen, Tianyu Shi, and Xueqian Wang. 2025. https://doi.org/10.1145/3746027.3755141 Twin co-adaptive dialogue for progressive image generation . In Proceedings of the 33rd ACM International Conference on Mul...
-
[42]
Zhijie Wang, Yuheng Huang, Da Song, Lei Ma, and Tianyi Zhang. 2024. https://doi.org/10.1145/3613904.3642803 PromptCharm : Text-to-image generation through multi-modal prompting and refinement . In Proceedings of the CHI Conference on Human Factors in Computing Systems, pages 1--16. ACM
-
[43]
Jingxuan Wei, Caijun Jia, Xi Bai, Xinglong Xu, Siyuan Li, Linzhuang Sun, Bihui Yu, Conghui He, Lijun Wu, and Cheng Tan. 2026. https://arxiv.org/abs/2511.11134 Ggbench: A geometric generative reasoning benchmark for unified multimodal models . Preprint, arXiv:2511.11134
arXiv 2026
-
[44]
Jingxuan Wei, Shiyu Wu, Xin Jiang, and Yequan Wang. 2023. https://doi.org/10.48550/ARXIV.2303.10073 Dialogpaint: A dialog-based image editing model . CoRR, abs/2303.10073
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[46]
Xiang Yue, Yuansheng Ni, Tianyu Zheng, Kai Zhang, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, Cong Wei, Botao Yu, Ruibin Yuan, Renliang Sun, Ming Yin, Boyuan Zheng, Zhenzhu Yang, Yibo Liu, Wenhao Huang, and 3 others. 2024. https://doi.org/10.1109/CVPR52733.2024.00913 MMMU: A massive multi-discipline multimodal understanding...
-
[47]
Chao Zhang, Cheng Yao, Jianhui Liu, Zili Zhou, Weilin Zhang, Lijuan Liu, Fangtian Ying, Yijun Zhao, and Guanyun Wang. 2021. https://doi.org/10.1145/3411763.3451785 Storydrawer: A co-creative agent supporting children's storytelling through collaborative drawing . In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems, CHI E...
-
[48]
Hanjie, Sida I
Victor Zhong, Austin W. Hanjie, Sida I. Wang, Karthik Narasimhan, and Luke Zettlemoyer. 2021. Silg: the multi-environment symbolic interactive language grounding benchmark. In Proceedings of the 35th International Conference on Neural Information Processing Systems, NIPS '21, Red Hook, NY, USA. Curran Associates Inc
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.