Repurposing Adversarial Perturbations for Continual Learning: From Defense to Active Alignment
Pith reviewed 2026-06-28 16:00 UTC · model grok-4.3
The pith
AdvCL repurposes adversarial perturbations into three modules that provide geometric control for continual learning with reduced forgetting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
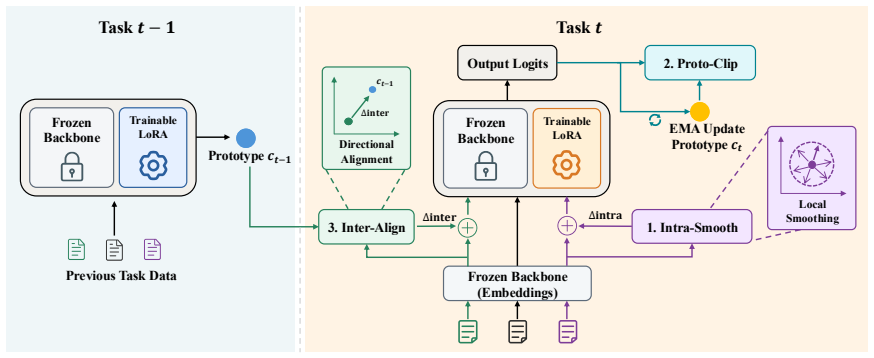
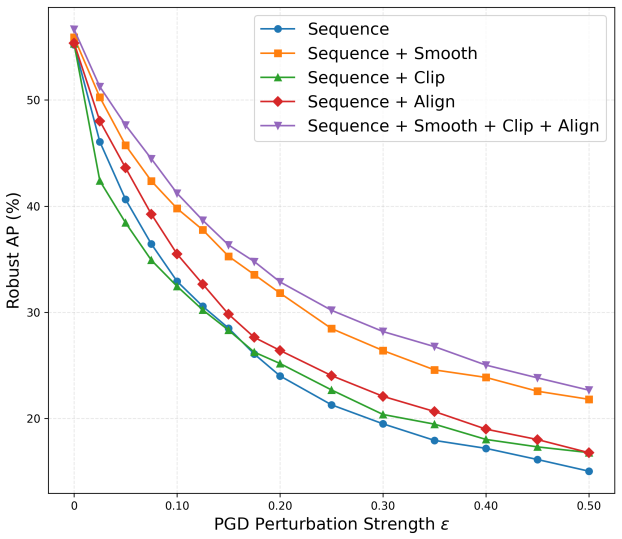
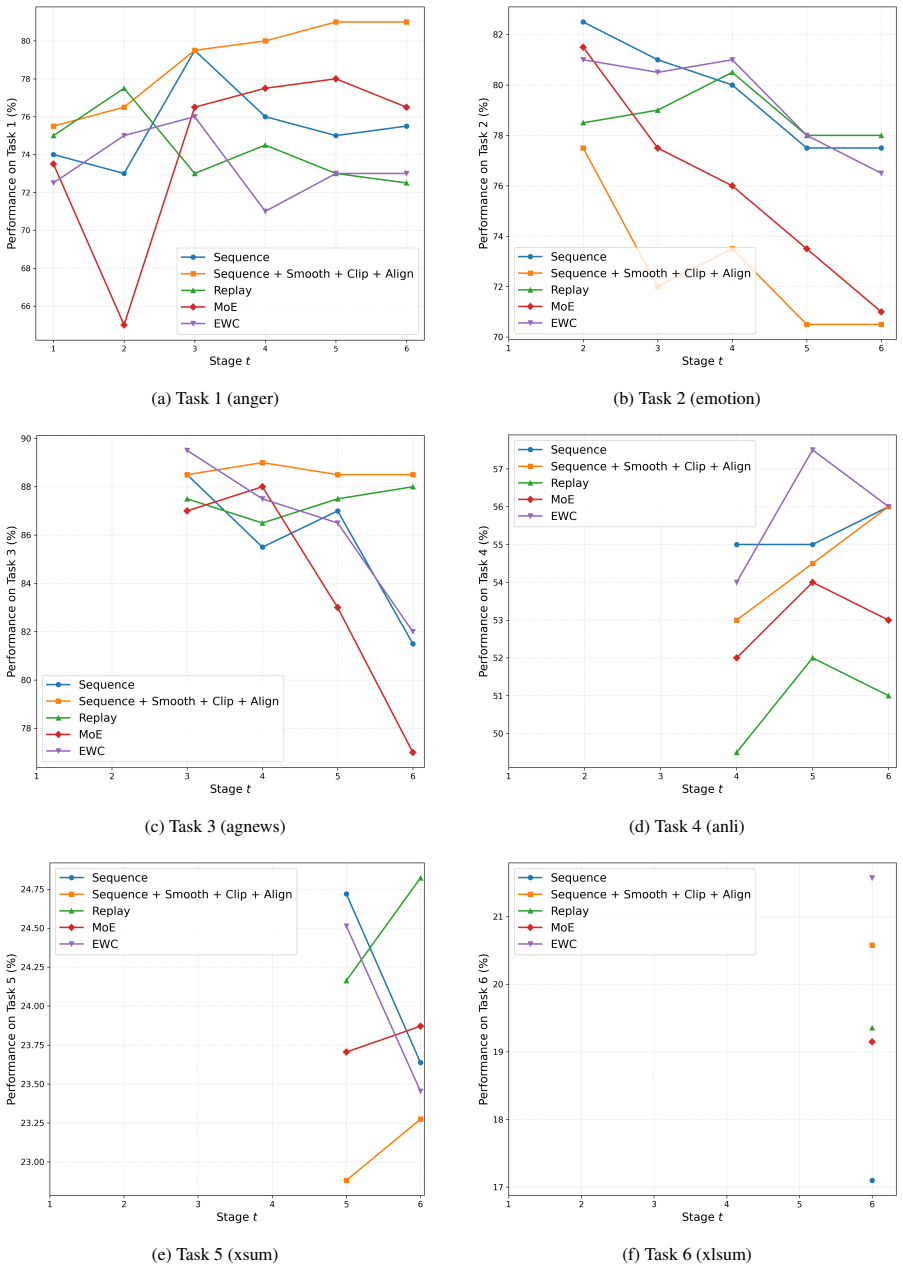
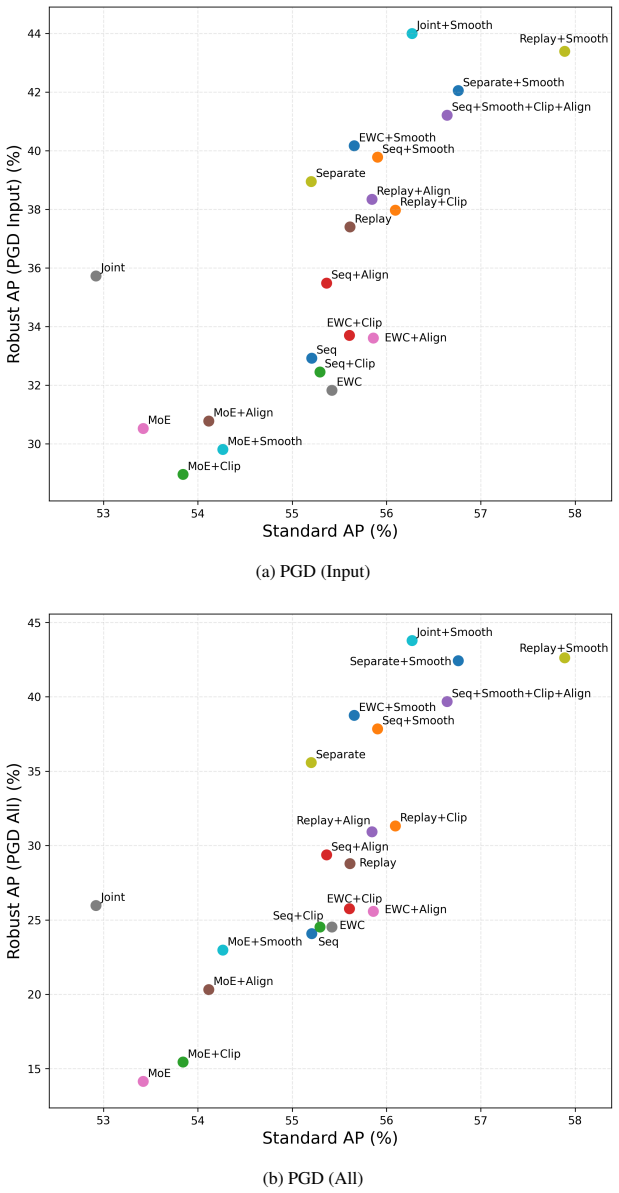
AdvCL repurposes adversarial perturbations as a geometric control signal for stable continual adaptation. It combines three plug-in modules: Intra-Smooth promotes local smoothness via small adversarial perturbations; Proto-Clip uses similarity clipping to prevent excessive alignment to the current task prototype; and Inter-Align applies directional alignment toward the previous task prototype to reduce representational gaps. Experiments show consistent gains in both standard performance and robustness, with lower forgetting and stronger transfer. The modules provide complementary gains when combined and can be integrated individually into replay, regularization, and dynamic architecture para
What carries the argument
The three plug-in modules (Intra-Smooth, Proto-Clip, Inter-Align) that repurpose adversarial perturbations as a geometric control signal.
If this is right
- Each module can be added individually to replay-based, regularization-based, or dynamic architecture continual learning methods.
- Combining the modules yields complementary gains in performance, robustness, forgetting reduction, and transfer.
- The approach supplies a geometric control mechanism that works across diverse continual learning paradigms.
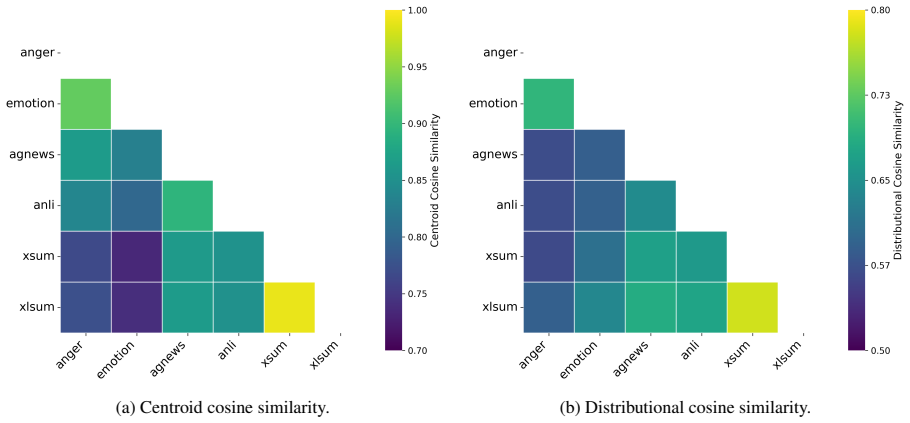
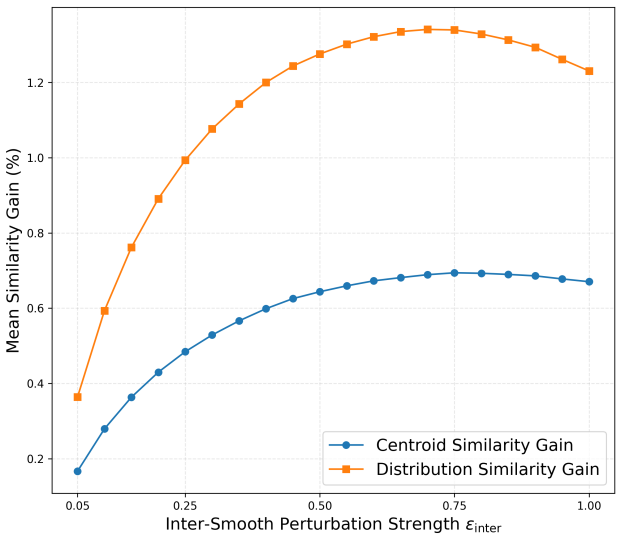
- Quantified sensitivity of Intra-Smooth to perturbation settings and effects of Inter-Align on task similarity provide analysis tools for geometric distance.
Where Pith is reading between the lines
- The geometric alignment technique might extend to non-adversarial perturbations for similar control in sequential learning.
- The modules could be tested for interactions with other forms of representation regularization beyond the three described.
- Measuring changes in geometric distance between prototypes could become a diagnostic for when to apply alignment in new task sequences.
Load-bearing premise
That repurposing adversarial perturbations via the three modules will reliably act as a stable geometric control signal that improves continual learning outcomes across paradigms without introducing new instabilities or negative interactions.
What would settle it
An experiment on a standard continual learning benchmark where adding one or more of the modules increases forgetting rates or lowers accuracy relative to the unmodified baseline.
Figures

read the original abstract
In dynamic environments, large language models need to keep adapting to new tasks, but continual learning often suffers from forgetting, limited transfer, and vulnerability to adversarial perturbations. To address this, we present AdvCL, which repurposes adversarial perturbations as a geometric control signal for stable continual adaptation. AdvCL combines three plug-in modules: Intra-Smooth promotes local smoothness via small adversarial perturbations; Proto-Clip uses similarity clipping to prevent excessive alignment to current task prototype; and Inter-Align applies directional alignment toward previous task prototype to reduce representational gaps. Experiments show consistent gains in both standard performance and robustness, with lower forgetting and stronger transfer. We further analyze key mechanisms by quantifying the sensitivity of Intra-Smooth to perturbation settings and the effect of Inter-Align on task similarity and geometric distance. In summary, the modules provide complementary gains when combined, and each can also be integrated individually into diverse CL paradigms, including replay, regularization, and dynamic architectures, thereby offering a geometric control mechanism for continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AdvCL for continual learning in large language models, repurposing adversarial perturbations as a geometric control signal. It introduces three plug-in modules—Intra-Smooth (local smoothness via small perturbations), Proto-Clip (similarity clipping to avoid excessive current-task alignment), and Inter-Align (directional alignment to prior-task prototypes to reduce gaps)—that can be combined or used individually within replay, regularization, or dynamic-architecture CL methods. The central claim is that the approach yields consistent gains in standard performance and robustness, reduced forgetting, and improved transfer, supported by analyses of perturbation sensitivity and geometric effects.
Significance. If the empirical results are reproducible and the modules prove stable across paradigms, the work supplies a practical geometric mechanism that converts an existing defense technique into an active alignment tool. This could be broadly useful for adapting LLMs without catastrophic forgetting while preserving robustness, and the plug-in design lowers the barrier to adoption in existing CL frameworks.
major comments (2)
- [Abstract] Abstract: the claim of 'consistent gains in both standard performance and robustness, with lower forgetting and stronger transfer' is presented without any mention of datasets, baselines, number of runs, or statistical tests, making it impossible to assess whether the data actually support the stated improvements.
- [Abstract] The weakest assumption—that the three modules act as a stable geometric control signal without introducing instabilities or negative interactions when combined—is load-bearing for the 'complementary gains' and 'plug-in' claims; the manuscript must supply ablation results quantifying interactions and failure modes under varied task similarities.
minor comments (1)
- [Abstract] Abstract: terms such as 'task prototype' and 'representational gaps' are used without brief definitions, which would aid readability for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, agreeing that targeted revisions will strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'consistent gains in both standard performance and robustness, with lower forgetting and stronger transfer' is presented without any mention of datasets, baselines, number of runs, or statistical tests, making it impossible to assess whether the data actually support the stated improvements.
Authors: We agree that the abstract would benefit from additional context to support its claims. In the revised manuscript we will update the abstract to briefly reference the primary continual learning benchmarks, note that results are reported as averages over multiple independent runs, and indicate that statistical significance was evaluated in the experiments. The full details on datasets, baselines, run counts, and tests remain in Sections 4 and 5. revision: yes
-
Referee: [Abstract] The weakest assumption—that the three modules act as a stable geometric control signal without introducing instabilities or negative interactions when combined—is load-bearing for the 'complementary gains' and 'plug-in' claims; the manuscript must supply ablation results quantifying interactions and failure modes under varied task similarities.
Authors: The referee correctly highlights the importance of verifying stability. While the manuscript already reports complementary gains from module combinations across replay, regularization, and dynamic-architecture paradigms together with geometric analyses, it does not contain a dedicated ablation on negative interactions or instabilities across task-similarity regimes. We will add such experiments in the revision, systematically varying task similarity and reporting any observed instabilities or failure modes to directly support the stability claim. revision: yes
Circularity Check
No significant circularity; empirical method with no derivation chain
full rationale
The paper presents AdvCL as an empirical method consisting of three plug-in modules (Intra-Smooth, Proto-Clip, Inter-Align) whose value is demonstrated through experiments on performance, robustness, forgetting, and transfer. No equations, derivations, or first-principles claims appear in the abstract or referenced text. Claims rest on experimental outcomes rather than any mathematical reduction that could be circular. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, Brian and Al-Rfou, Rami and Constant, Noah. The Power of Scale for Parameter-Efficient Prompt Tuning. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021. doi:10.18653/v1/2021.emnlp-main.243
-
[2]
Language Models Resist Alignment: Evidence From Data Compression
Ji, Jiaming and Wang, Kaile and Qiu, Tianyi Alex and Chen, Boyuan and Zhou, Jiayi and Li, Changye and Lou, Hantao and Dai, Josef and Liu, Yunhuai and Yang, Yaodong. Language Models Resist Alignment: Evidence From Data Compression. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10....
-
[3]
International Conference on Learning Representations , year=
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima , author=. International Conference on Learning Representations , year=
-
[4]
Proceedings of the 36th International Conference on Machine Learning , pages =
Theoretically Principled Trade-off between Robustness and Accuracy , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[5]
2024 , eprint=
Maintaining Adversarial Robustness in Continuous Learning , author=. 2024 , eprint=
2024
-
[6]
Disentangling and mitigating the impact of task similarity for continual learning , volume =
Hiratani, Naoki , booktitle =. Disentangling and mitigating the impact of task similarity for continual learning , volume =. doi:10.52202/079017-0107 , editor =
-
[7]
and Soatto, Stefano and Perona, Pietro , title =
Achille, Alessandro and Lam, Michael and Tewari, Rahul and Ravichandran, Avinash and Maji, Subhransu and Fowlkes, Charless C. and Soatto, Stefano and Perona, Pietro , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
-
[8]
, title =
Rebuffi, Sylvestre-Alvise and Kolesnikov, Alexander and Sperl, Georg and Lampert, Christoph H. , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Cha, Hyuntak and Lee, Jaeho and Shin, Jinwoo , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
2021
-
[10]
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning , year=
Miyato, Takeru and Maeda, Shin-Ichi and Koyama, Masanori and Ishii, Shin , journal=. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning , year=
-
[11]
International Conference on Learning Representations , year=
Sharpness-aware Minimization for Efficiently Improving Generalization , author=. International Conference on Learning Representations , year=
-
[12]
Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal
Huang, Jianheng and Cui, Leyang and Wang, Ante and Yang, Chengyi and Liao, Xinting and Song, Linfeng and Yao, Junfeng and Su, Jinsong. Mitigating Catastrophic Forgetting in Large Language Models with Self-Synthesized Rehearsal. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.186...
-
[13]
2016 , eprint=
Progressive Neural Networks , author=. 2016 , eprint=
2016
-
[14]
Rehearsal-Free Modular and Compositional Continual Learning for Language Models
Wang, Mingyang and Adel, Heike and Lange, Lukas and Str. Rehearsal-Free Modular and Compositional Continual Learning for Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers). 2024. doi:10.18653/v1/2024.naacl-short.39
-
[15]
Revisiting Catastrophic Forgetting in Large Language Model Tuning
Li, Hongyu and Ding, Liang and Fang, Meng and Tao, Dacheng. Revisiting Catastrophic Forgetting in Large Language Model Tuning. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.249
-
[16]
James Kirkpatrick and Razvan Pascanu and Neil Rabinowitz and Joel Veness and Guillaume Desjardins and Andrei A. Rusu and Kieran Milan and John Quan and Tiago Ramalho and Agnieszka Grabska-Barwinska and Demis Hassabis and Claudia Clopath and Dharshan Kumaran and Raia Hadsell , title =. Proceedings of the National Academy of Sciences , volume =. 2017 , doi ...
-
[17]
Orthogonal Subspace Learning for Language Model Continual Learning
Wang, Xiao and Chen, Tianze and Ge, Qiming and Xia, Han and Bao, Rong and Zheng, Rui and Zhang, Qi and Gui, Tao and Huang, Xuanjing. Orthogonal Subspace Learning for Language Model Continual Learning. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.715
-
[18]
Lu, Yuheng and Qian, Bingshuo and Yuan, Caixia and Jiang, Huixing and Wang, Xiaojie. Controlled Low-Rank Adaptation with Subspace Regularization for Continued Training on Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.940
-
[19]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo
-
[20]
Zhao, Weixiang and Wang, Shilong and Hu, Yulin and Zhao, Yanyan and Qin, Bing and Zhang, Xuanyu and Yang, Qing and Xu, Dongliang and Che, Wanxiang. SAPT : A Shared Attention Framework for Parameter-Efficient Continual Learning of Large Language Models. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long ...
-
[21]
SLIM : Let LLM Learn More and Forget Less with Soft L o RA and Identity Mixture
Han, Jiayi and Du, Liang and Du, Hongwei and Zhou, Xiangguo and Wu, Yiwen and Zhang, Yuanfang and Zheng, Weibo and Han, Donghong. SLIM : Let LLM Learn More and Forget Less with Soft L o RA and Identity Mixture. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[22]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and De Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle =. Parameter-Efficient Transfer Learning for. 2019 , editor =
2019
-
[23]
International Conference on Learning Representations , year=
FreeLB: Enhanced Adversarial Training for Natural Language Understanding , author=. International Conference on Learning Representations , year=
-
[24]
Jiang, Haoming and He, Pengcheng and Chen, Weizhu and Liu, Xiaodong and Gao, Jianfeng and Zhao, Tuo. SMART : Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.197
-
[25]
International Conference on Learning Representations , year=
Better Fine-Tuning by Reducing Representational Collapse , author=. International Conference on Learning Representations , year=
-
[26]
The Twelfth International Conference on Learning Representations , year=
Neel Jain and Ping. The Twelfth International Conference on Learning Representations , year=
-
[27]
2022 , eprint=
The Effect of Task Ordering in Continual Learning , author=. 2022 , eprint=
2022
-
[28]
Sentence Embedding Alignment for Lifelong Relation Extraction
Wang, Hong and Xiong, Wenhan and Yu, Mo and Guo, Xiaoxiao and Chang, Shiyu and Wang, William Yang. Sentence Embedding Alignment for Lifelong Relation Extraction. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.186...
-
[29]
Refining Sample Embeddings with Relation Prototypes to Enhance Continual Relation Extraction
Cui, Li and Yang, Deqing and Yu, Jiaxin and Hu, Chengwei and Cheng, Jiayang and Yi, Jingjie and Xiao, Yanghua. Refining Sample Embeddings with Relation Prototypes to Enhance Continual Relation Extraction. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language ...
-
[30]
Consistent Representation Learning for Continual Relation Extraction
Zhao, Kang and Xu, Hua and Yang, Jiangong and Gao, Kai. Consistent Representation Learning for Continual Relation Extraction. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.268
-
[31]
International Conference on Learning Representations , year=
Towards Deep Learning Models Resistant to Adversarial Attacks , author=. International Conference on Learning Representations , year=
-
[32]
International Conference on Learning Representations , year=
Explaining and Harnessing Adversarial Examples , author=. International Conference on Learning Representations , year=
-
[33]
Super- N atural I nstructions: Generalization via Declarative Instructions on 1600+ NLP Tasks
Wang, Yizhong and Mishra, Swaroop and Alipoormolabashi, Pegah and Kordi, Yeganeh and Mirzaei, Amirreza and Naik, Atharva and Ashok, Arjun and Dhanasekaran, Arut Selvan and Arunkumar, Anjana and Stap, David and Pathak, Eshaan and Karamanolakis, Giannis and Lai, Haizhi and Purohit, Ishan and Mondal, Ishani and Anderson, Jacob and Kuznia, Kirby and Doshi, Kr...
-
[34]
S em E val-2018 Task 1: Affect in Tweets
Mohammad, Saif and Bravo-Marquez, Felipe and Salameh, Mohammad and Kiritchenko, Svetlana. S em E val-2018 Task 1: Affect in Tweets. Proceedings of the 12th International Workshop on Semantic Evaluation. 2018. doi:10.18653/v1/S18-1001
-
[35]
CARER : Contextualized Affect Representations for Emotion Recognition
Saravia, Elvis and Liu, Hsien-Chi Toby and Huang, Yen-Hao and Wu, Junlin and Chen, Yi-Shin. CARER : Contextualized Affect Representations for Emotion Recognition. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1404
-
[36]
Character-level Convolutional Networks for Text Classification , volume =
Zhang, Xiang and Zhao, Junbo and LeCun, Yann , booktitle =. Character-level Convolutional Networks for Text Classification , volume =
-
[37]
Adversarial NLI : A New Benchmark for Natural Language Understanding
Nie, Yixin and Williams, Adina and Dinan, Emily and Bansal, Mohit and Weston, Jason and Kiela, Douwe. Adversarial NLI : A New Benchmark for Natural Language Understanding. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.441
-
[38]
Hardt, M., Recht, B., and Singer, Y
Narayan, Shashi and Cohen, Shay B. and Lapata, Mirella. Don ' t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1206
-
[39]
Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M
Hasan, Tahmid and Bhattacharjee, Abhik and Islam, Md. Saiful and Mubasshir, Kazi and Li, Yuan-Fang and Kang, Yong-Bin and Rahman, M. Sohel and Shahriyar, Rifat. XL -Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.413
-
[40]
International Conference on Learning Representations , year=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. International Conference on Learning Representations , year=
-
[41]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[42]
Morris, John and Lifland, Eli and Yoo, Jin Yong and Grigsby, Jake and Jin, Di and Qi, Yanjun. T ext A ttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020. doi:10.18653/v1/2020.emnlp-demos.16
-
[43]
2025 , eprint=
Parameter-Efficient Continual Fine-Tuning: A Survey , author=. 2025 , eprint=
2025
-
[44]
Learning to Route for Dynamic Adapter Composition in Continual Learning with Language Models
Araujo, Vladimir and Moens, Marie-Francine and Tuytelaars, Tinne. Learning to Route for Dynamic Adapter Composition in Continual Learning with Language Models. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.38
-
[45]
Model Sensitivity Aware Continual Learning , volume =
Wang, Zhenyi and Huang, Heng , booktitle =. Model Sensitivity Aware Continual Learning , volume =. doi:10.52202/079017-4215 , editor =
-
[46]
Datasets: A Community Library for Natural Language Processing
Lhoest, Quentin and Villanova del Moral, Albert and Jernite, Yacine and Thakur, Abhishek and von Platen, Patrick and Patil, Suraj and Chaumond, Julien and Drame, Mariama and Plu, Julien and Tunstall, Lewis and Davison, Joe and S a s ko, Mario and Chhablani, Gunjan and Malik, Bhavitvya and Brandeis, Simon and Le Scao, Teven and Sanh, Victor and Xu, Canwen ...
-
[47]
Sourab Mangrulkar and Sylvain Gugger and Lysandre Debut and Younes Belkada and Sayak Paul and Benjamin Bossan and Marian Tietz , howpublished =
-
[48]
doi: 10.18653/v1/2020.emnlp-demos.6
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[49]
, journal=
Hunter, John D. , journal=. Matplotlib: A 2D Graphics Environment , year=
-
[50]
Charles R. Harris and K. Jarrod Millman and St. Array programming with. 2020 , month = sep, journal =. doi:10.1038/s41586-020-2649-2 , publisher =
-
[51]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , volume =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and Kopf, Andreas and Yang, Edward and DeVito, Zachary and Raison, Martin and Tejani, Alykhan and Chilamkurthy, Sasank and Steiner, Benoit and Fang, Lu an...
-
[52]
Journal of Open Source Software , author =
Waskom, Michael L. , title =. doi:10.21105/joss.03021 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.