DPA4: Pushing the Accuracy-Cost Frontier of Interatomic Potentials with EMFA SO(2) Convolution
Pith reviewed 2026-06-28 12:02 UTC · model grok-4.3
The pith
DPA4's EMFA SO(2) convolution delivers interatomic potentials that match or exceed larger models at far lower parameter count and training cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
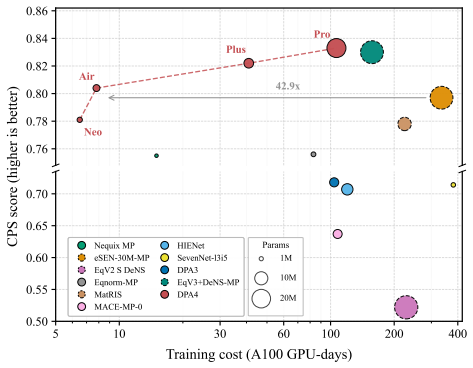
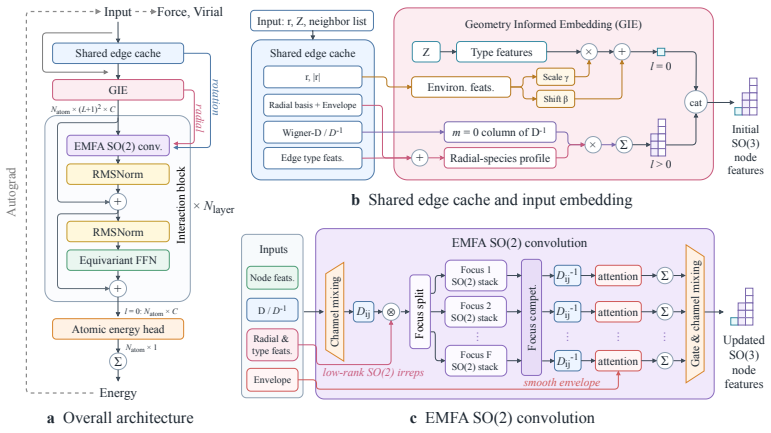
DPA4 introduces an SE(3)-equivariant interatomic-potential model whose central component is the EMFA SO(2)-equivariant convolution; the convolution performs a low-rank edge-node SO(2)-equivariant product, applies multi-focus nonlinearity to messages, aggregates them with envelope-gated attention, and projects the result onto a Lebedev grid to preserve SO(3) equivariance to machine precision. A separate conservative energy-gradient training path yields up to threefold wall-clock speedup under torch compile. These choices produce the reported benchmark outcomes: best Combined Performance Score on Matbench Discovery for DPA4-Pro, superior accuracy for the 2.76 M DPA4-Air versus the 30.1 M eSEN
What carries the argument
EMFA SO(2)-equivariant convolution: a low-rank edge-node product combined with multi-focus message nonlinearity, envelope-gated attention, and Lebedev-grid projection that maintains exact SO(3) equivariance while enabling efficient message passing.
If this is right
- DPA4-Pro records the highest Combined Performance Score on the Matbench Discovery leaderboard.
- DPA4-Air reaches higher accuracy than a 30.1 M-parameter baseline using 2.76 M parameters and 42.9 times less training compute.
- DPA4-Plus reduces aggregate molecular energy and force errors by 29 percent and 30 percent relative to a 6.5 M-parameter baseline on SPICE-MACE-OFF.
- DPA4-Air still surpasses the same baseline with roughly 2.4 times fewer parameters.
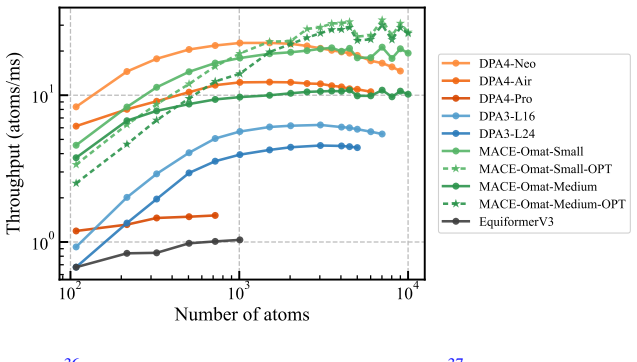
- The conservative energy-gradient path supplies up to threefold wall-clock speedup when compiled.
Where Pith is reading between the lines
- The same convolution pattern could be inserted into other equivariant message-passing networks that currently rely on more expensive tensor-product operations.
- If the reported scaling holds, the architecture may serve as a practical backbone for pre-training large atomistic models on heterogeneous datasets.
- The Lebedev projection step offers a general technique for restoring exact rotational equivariance after any nonlinear operation that breaks it.
- Controlled ablation studies that isolate the low-rank product, the multi-focus design, and the attention gate would clarify which element drives most of the efficiency gain.
Load-bearing premise
The measured benchmark gains arise chiefly from the convolution design and projection step rather than from any unstated differences in data handling, hyperparameter search, or training schedule.
What would settle it
Re-train the eSEN-30M-MP baseline on exactly the same data splits, with the same optimizer schedule and data-augmentation choices used for DPA4-Air, then compare final validation errors and compute totals.
Figures
read the original abstract
Machine-learning interatomic potentials now approach quantum-mechanical accuracy on standard benchmarks, but the training cost of the most expressive equivariant architectures has become a serious bottleneck. We introduce DPA4, an SE(3)-equivariant interatomic-potential architecture with an EMFA (Edge-conditioned, Multi-Focus, Attention) SO(2)-equivariant convolution that combines a low-rank edge-node SO(2)-equivariant product, a multi-focus design for message nonlinearity, and envelope-gated attention for message aggregation. A Lebedev-grid projection further preserves SO(3)-equivariance in the nonlinearity to machine precision. A compiler-friendly conservative energy-gradient training path provides up to $\sim$3 times wall-clock speedup under torch compile. On the compliant Matbench Discovery benchmark, DPA4-Pro attains the best Combined Performance Score (CPS) on the leaderboard, while the 2.76M-parameter DPA4-Air exceeds the accuracy of the 30.1M-parameter eSEN-30M-MP baseline with 10.9$\times$ fewer parameters and 42.9$\times$ less training compute. On SPICE-MACE-OFF, the 5.4M-parameter DPA4-Plus lowers the aggregate molecular energy and force errors of the 6.5M-parameter eSEN baseline by 29% and 30%, while the 2.7M-parameter DPA4-Air still surpasses that baseline with $\sim$2.4$\times$ fewer parameters. Together these results place DPA4 on a new accuracy-cost Pareto frontier on Matbench Discovery and position it as a strong candidate backbone for future multi-task large atomistic model (LAM) pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DPA4, an SE(3)-equivariant interatomic-potential architecture featuring an EMFA (Edge-conditioned, Multi-Focus, Attention) SO(2)-equivariant convolution that incorporates a low-rank edge-node product, multi-focus message nonlinearity, envelope-gated attention, and a Lebedev-grid projection to enforce SO(3)-equivariance to machine precision. It also describes a compiler-friendly conservative energy-gradient training path. On the Matbench Discovery benchmark, DPA4-Pro is reported to achieve the best Combined Performance Score (CPS), while the 2.76M-parameter DPA4-Air variant surpasses the 30.1M-parameter eSEN-30M-MP baseline in accuracy with 10.9 imes fewer parameters and 42.9 imes less training compute; analogous gains are claimed on SPICE-MACE-OFF relative to an eSEN baseline.
Significance. If the reported gains can be attributed to the architectural components rather than uncontrolled variables, the work would meaningfully advance the accuracy-cost Pareto frontier for equivariant interatomic potentials and support future large-atomistic-model pretraining. The explicit focus on machine-precision equivariance and training efficiency is a constructive contribution. However, the absence of ablations, error bars, and controlled comparisons substantially weakens the ability to evaluate whether the central claims hold.
major comments (2)
- [Abstract] Abstract: The central performance claims (best CPS on Matbench Discovery; 10.9 imes parameter and 42.9 imes compute advantage of DPA4-Air over eSEN-30M-MP) are presented without error bars, ablation studies, verification of the machine-precision equivariance claim, or details on data splits, preventing full evaluation of whether the improvements arise from the EMFA SO(2) convolution, multi-focus design, or Lebedev projection.
- [Abstract] Abstract (results paragraph): The comparisons to external baselines (eSEN-30M-MP, eSEN) do not report controls for data handling, preprocessing, hyperparameter search effort, optimizer settings, or training duration; without such controls the attribution of the efficiency gains specifically to the EMFA SO(2) convolution and related design choices remains unverified and load-bearing for the paper's main claim.
minor comments (1)
- [Abstract] The term 'compliant Matbench Discovery benchmark' is used without a definition or reference to the precise compliance criteria applied.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on transparency and attribution. We address each major comment below, noting where the manuscript will be revised to improve clarity while maintaining the integrity of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (best CPS on Matbench Discovery; 10.9 imes parameter and 42.9 imes compute advantage of DPA4-Air over eSEN-30M-MP) are presented without error bars, ablation studies, verification of the machine-precision equivariance claim, or details on data splits, preventing full evaluation of whether the improvements arise from the EMFA SO(2) convolution, multi-focus design, or Lebedev projection.
Authors: The abstract is a concise summary; the full manuscript details the data splits and preprocessing in the Methods section, and the Lebedev-grid projection is constructed to enforce SO(3)-equivariance to machine precision (see Architecture section). Error bars are not included because the benchmark metrics derive from deterministic, single-run evaluations with fixed random seeds on public leaderboards. Ablation studies isolating every component are not present, as the work focuses on the integrated architecture and its end-to-end performance; component motivations are provided via theoretical derivation rather than exhaustive ablation. We will revise the abstract to cross-reference the relevant sections for these elements. revision: partial
-
Referee: [Abstract] Abstract (results paragraph): The comparisons to external baselines (eSEN-30M-MP, eSEN) do not report controls for data handling, preprocessing, hyperparameter search effort, optimizer settings, or training duration; without such controls the attribution of the efficiency gains specifically to the EMFA SO(2) convolution and related design choices remains unverified and load-bearing for the paper's main claim.
Authors: The eSEN baselines are reproduced using the identical data splits, preprocessing pipelines, and benchmark protocols published in the original eSEN works to ensure direct comparability. Hyperparameters for our models were tuned to match or exceed the reported baseline accuracies under the same optimizer and training-duration regimes where feasible. We will add a dedicated 'Experimental Controls and Reproducibility' subsection that explicitly documents these choices, data handling, and training settings to strengthen attribution. revision: yes
- Ablation studies that isolate the individual contributions of the low-rank edge-node product, multi-focus nonlinearity, envelope-gated attention, and Lebedev projection were not performed.
- Numerical verification experiments confirming machine-precision equivariance (separate from the theoretical construction) are not reported.
Circularity Check
No circularity: performance claims rest on external benchmark comparisons
full rationale
The paper presents an architecture (EMFA SO(2) convolution, Lebedev projection, etc.) and reports accuracy/cost results on public external benchmarks (Matbench Discovery, SPICE-MACE-OFF) against named external baselines (eSEN). No derivation chain, fitted parameter renamed as prediction, or self-citation load-bearing step is present in the provided text; the central claims are direct empirical comparisons that do not reduce to the paper's own inputs by construction. This is the normal non-circular outcome for an applied ML architecture paper.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Non-covalent Interactions at cm$^{-1}$ Accuracy: Data Efficient Physics-Informed Distillation for Machine Learning Interatomic Potentials
Physics-informed distillation from a universal MLIP plus limited CCSD(T) fine-tuning yields cm^{-1} accurate potentials for non-covalent interactions, with teacher choice strongly affecting accuracy on some systems.
Reference graph
Works this paper leans on
-
[1]
Materials Futures , volume =
Deep potentials for materials science , author =. Materials Futures , volume =. 2022 , publisher =
2022
-
[2]
arXiv preprint arXiv:2312.15211 , year =
MACE-OFF23: Transferable machine learning force fields for organic molecules , author =. arXiv preprint arXiv:2312.15211 , year =
-
[3]
CUDA-MACE: High-Performance GPU-Accelerated MACE Implementation , author =
-
[4]
Journal of Physics: Condensed Matter , volume =
Ask Hjorth Larsen and Jens Jørgen Mortensen and Jakob Blomqvist and Ivano E Castelli and Rune Christensen and Marcin Dułak and Jesper Friis and Michael N Groves and Bjørk Hammer and Cory Hargus and Eric D Hermes and Paul C Jennings and Peter Bjerre Jensen and James Kermode and John R Kitchin and Esben Leonhard Kolsbjerg and Joseph Kubal and Kristen Kaasbj...
2017
-
[5]
International conference on machine learning , pages =
E (n) equivariant graph neural networks , author =. International conference on machine learning , pages =. 2021 , organization =
2021
-
[6]
2022 , journal =
Ammonia Decomposition on Lithium Imide Surfaces: A New Paradigm in Heterogeneous Catalysis , author =. 2022 , journal =
2022
-
[7]
Journal of chemical theory and computation , volume =
Combined free-energy calculation and machine learning methods for understanding ligand unbinding kinetics , author =. Journal of chemical theory and computation , volume =. 2022 , publisher =
2022
-
[8]
Journal of Chemical Theory and Computation , volume =
QD : A quantum deep potential interaction model for drug discovery , author =. Journal of Chemical Theory and Computation , volume =. 2023 , publisher =
2023
-
[9]
The Journal of chemical physics , volume =
Active learning in Gaussian process interpolation of potential energy surfaces , author =. The Journal of chemical physics , volume =. 2018 , publisher =
2018
-
[10]
International conference on machine learning , pages =
Neural message passing for quantum chemistry , author =. International conference on machine learning , pages =. 2017 , organization =
2017
-
[11]
The Journal of chemical physics , volume =
Neural network models of potential energy surfaces , author =. The Journal of chemical physics , volume =. 1995 , publisher =
1995
-
[12]
Physical Chemistry Chemical Physics , volume =
Optimal construction of a fast and accurate polarisable water potential based on multipole moments trained by machine learning , author =. Physical Chemistry Chemical Physics , volume =. 2009 , publisher =
2009
-
[13]
Physical review letters , volume =
Generalized neural-network representation of high-dimensional potential-energy surfaces , author =. Physical review letters , volume =. 2007 , publisher =
2007
-
[14]
Physical review letters , volume =
Gaussian approximation potentials: The accuracy of quantum mechanics, without the electrons , author =. Physical review letters , volume =. 2010 , publisher =
2010
-
[15]
Nature communications , volume =
Quantum-chemical insights from deep tensor neural networks , author =. Nature communications , volume =. 2017 , publisher =
2017
-
[16]
Advances in neural information processing systems , volume =
Schnet: A continuous-filter convolutional neural network for modeling quantum interactions , author =. Advances in neural information processing systems , volume =
-
[17]
Science advances , volume =
Machine learning of accurate energy-conserving molecular force fields , author =. Science advances , volume =. 2017 , publisher =
2017
-
[18]
International Conference on Learning Representations , year =
Directional message passing for molecular graphs , author =. International Conference on Learning Representations , year =
-
[19]
Science advances , volume =
Machine learning unifies the modeling of materials and molecules , author =. Science advances , volume =. 2017 , publisher =
2017
-
[20]
Physical Review X , volume =
Machine learning a general-purpose interatomic potential for silicon , author =. Physical Review X , volume =. 2018 , publisher =
2018
-
[21]
Journal of chemical theory and computation , volume =
PhysNet: A neural network for predicting energies, forces, dipole moments, and partial charges , author =. Journal of chemical theory and computation , volume =. 2019 , publisher =
2019
-
[22]
arXiv preprint arXiv:2202.02541 , year =
TorchMD-NET: Equivariant Transformers for Neural Network based Molecular Potentials , author =. arXiv preprint arXiv:2202.02541 , year =
-
[23]
Journal of Computational Physics , volume =
Spectral neighbor analysis method for automated generation of quantum-accurate interatomic potentials , author =. Journal of Computational Physics , volume =. 2015 , publisher =
2015
-
[24]
Computer Physics Communications , volume =
DeePMD-kit: A deep learning package for many-body potential energy representation and molecular dynamics , author =. Computer Physics Communications , volume =. 2018 , publisher =
2018
-
[25]
arXiv preprint arXiv:1904.00360 , year =
Deep learning inter-atomic potential model for accurate irradiation damage simulations , author =. arXiv preprint arXiv:1904.00360 , year =
Pith/arXiv arXiv 1904
-
[26]
Advances in Neural Information Processing Systems , volume =
End-to-end symmetry preserving inter-atomic potential energy model for finite and extended systems , author =. Advances in Neural Information Processing Systems , volume =
-
[27]
The journal of physical chemistry letters , volume =
Embedded atom neural network potentials: Efficient and accurate machine learning with a physically inspired representation , author =. The journal of physical chemistry letters , volume =. 2019 , publisher =
2019
-
[28]
Physical Review B , volume =
Atomic cluster expansion for accurate and transferable interatomic potentials , author =. Physical Review B , volume =. 2019 , publisher =
2019
-
[29]
Nature Communications , volume =
Learning local equivariant representations for large-scale atomistic dynamics , author =. Nature Communications , volume =. 2023 , publisher =
2023
-
[30]
npj Computational Materials , volume =
Heterogeneous relational message passing networks for molecular dynamics simulations , author =. npj Computational Materials , volume =. 2022 , publisher =
2022
-
[31]
Advances in neural information processing systems , volume =
Attention is all you need , author =. Advances in neural information processing systems , volume =
-
[32]
International journal of computer vision , volume =
Imagenet large scale visual recognition challenge , author =. International journal of computer vision , volume =. 2015 , publisher =
2015
-
[33]
International Conference on Learning Representations , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations , year =
-
[34]
arXiv preprint arXiv:1810.04805 , year =
Bert: Pre-training of deep bidirectional transformers for language understanding , author =. arXiv preprint arXiv:1810.04805 , year =
-
[35]
Advances in neural information processing systems , volume =
Language models are few-shot learners , author =. Advances in neural information processing systems , volume =
-
[36]
Physical review , volume =
Inhomogeneous electron gas , author =. Physical review , volume =. 1964 , publisher =
1964
-
[37]
Physical review , volume =
Self-consistent equations including exchange and correlation effects , author =. Physical review , volume =. 1965 , publisher =
1965
-
[38]
Physical review letters , volume =
Unified approach for molecular dynamics and density-functional theory , author =. Physical review letters , volume =. 1985 , publisher =
1985
-
[39]
Studies in molecular dynamics. I. General method , author =. The Journal of Chemical Physics , volume =. 1959 , publisher =
1959
-
[40]
Computer Physics Communications , volume =
DP-GEN: A concurrent learning platform for the generation of reliable deep learning based potential energy models , author =. Computer Physics Communications , volume =. 2020 , publisher =
2020
-
[41]
Chinese Physics B , volume =
Accurate deep potential model for the Al--Cu--Mg alloy in the full concentration space , author =. Chinese Physics B , volume =. 2021 , publisher =
2021
-
[42]
Chemical science , volume =
ANI-1: an extensible neural network potential with DFT accuracy at force field computational cost , author =. Chemical science , volume =. 2017 , publisher =
2017
-
[43]
Chemical science , volume =
The TensorMol-0.1 model chemistry: a neural network augmented with long-range physics , author =. Chemical science , volume =. 2018 , publisher =
2018
-
[44]
Journal of Chemical Theory and Computation , volume =
Extending the applicability of the ANI deep learning molecular potential to sulfur and halogens , author =. Journal of Chemical Theory and Computation , volume =. 2020 , publisher =
2020
-
[45]
ACS Catalysis , volume =
Open catalyst 2020 (OC20) dataset and community challenges , author =. ACS Catalysis , volume =. 2021 , publisher =
2020
-
[46]
Computational Visual Media , pages =
Attention mechanisms in computer vision: A survey , author =. Computational Visual Media , pages =. 2022 , publisher =
2022
-
[47]
IEEE Transactions on Neural Networks and Learning Systems , volume =
Attention in natural language processing , author =. IEEE Transactions on Neural Networks and Learning Systems , volume =. 2020 , publisher =
2020
-
[48]
arXiv preprint arXiv:1412.6980 , year =
Adam: A method for stochastic optimization , author =. arXiv preprint arXiv:1412.6980 , year =
-
[49]
SC20: International conference for high performance computing, networking, storage and analysis , pages =
Pushing the limit of molecular dynamics with ab initio accuracy to 100 million atoms with machine learning , author =. SC20: International conference for high performance computing, networking, storage and analysis , pages =. 2020 , organization =
2020
-
[50]
Chemistry of Materials , volume =
First principles study of the Li10GeP2S12 lithium super ionic conductor material , author =. Chemistry of Materials , volume =. 2012 , publisher =
2012
-
[51]
Physical Review Materials , volume =
Ionic correlations and failure of Nernst-Einstein relation in solid-state electrolytes , author =. Physical Review Materials , volume =. 2017 , publisher =
2017
-
[52]
Physical Chemistry Chemical Physics , volume =
Single-crystal X-ray structure analysis of the superionic conductor Li 10 GeP 2 S 12 , author =. Physical Chemistry Chemical Physics , volume =. 2013 , publisher =
2013
-
[53]
The Journal of Chemical Physics , volume =
Deep potential generation scheme and simulation protocol for the Li10GeP2S12-type superionic conductors , author =. The Journal of Chemical Physics , volume =. 2021 , publisher =
2021
-
[54]
Jom , volume =
Materials design and discovery with high-throughput density functional theory: the open quantum materials database (OQMD) , author =. Jom , volume =. 2013 , publisher =
2013
-
[55]
APL materials , volume =
Commentary: The Materials Project: A materials genome approach to accelerating materials innovation , author =. APL materials , volume =. 2013 , publisher =
2013
-
[56]
arXiv preprint arXiv:2204.02782 , year =
How Do Graph Networks Generalize to Large and Diverse Molecular Systems? , author =. arXiv preprint arXiv:2204.02782 , year =
-
[57]
Nature Computational Science , volume =
A universal graph deep learning interatomic potential for the periodic table , author =. Nature Computational Science , volume =. 2022 , publisher =
2022
-
[58]
Computational Materials Science , volume =
Active learning of linearly parametrized interatomic potentials , author =. Computational Materials Science , volume =. 2017 , publisher =
2017
-
[59]
The Journal of chemical physics , volume =
Less is more: Sampling chemical space with active learning , author =. The Journal of chemical physics , volume =. 2018 , publisher =
2018
-
[60]
Physical Review Materials , volume =
Active learning of uniformly accurate interatomic potentials for materials simulation , author =. Physical Review Materials , volume =. 2019 , publisher =
2019
-
[61]
Nature communications , volume =
Approaching coupled cluster accuracy with a general-purpose neural network potential through transfer learning , author =. Nature communications , volume =. 2019 , publisher =
2019
-
[62]
ChemRxiv , year =
Uni-Mol: A Universal 3D Molecular Representation Learning Framework , author =. ChemRxiv , year =
-
[63]
Scientific data , volume =
Quantum chemistry structures and properties of 134 kilo molecules , author =. Scientific data , volume =. 2014 , publisher =
2014
-
[64]
arXiv e-prints , keywords =
-
[65]
Training multilayer perceptrons with the extended kalman algorithm , year =
-
[66]
, title =
Abdin, Osama and Wen, Han and Kim, Philip M. , title =. 2021 , type =
2021
-
[67]
Adjabi, Insaf and Ouahabi, Abdeldjalil and Benzaoui, Amir and Taleb-Ahmed, Abdelmalik , title =. Electronics , volume =. doi:10.3390/electronics9081188 , year =
-
[68]
and Khimulya, Grigory and Biswas, Surojit and Alquraishi, Mohammed and Church, George M
Alley, Ethan C. and Khimulya, Grigory and Biswas, Surojit and Alquraishi, Mohammed and Church, George M. , title =. Nature Methods , volume =. doi:10.1038/s41592-019-0598-1 , year =
-
[69]
and Ketchem, Randal R
Amimeur, Tileli and Shaver, Jeremy M. and Ketchem, Randal R. and Taylor, J. Alex and Clark, Rutilio H. and Smith, Josh and Van Citters, Danielle and Siska, Christine C. and Smidt, Pauline and Sprague, Megan and Kerwin, Bruce A. and Pettit, Dean , title =. 2020 , type =
2020
-
[70]
Baek, Minkyung and Dimaio, Frank and Anishchenko, Ivan and Dauparas, Justas and Ovchinnikov, Sergey and Lee, Gyu Rie and Wang, Jue and Cong, Qian and Kinch, Lisa N. and Schaeffer, R. Dustin and Millán, Claudia and Park, Hahnbeom and Adams, Carson and Glassman, Caleb R. and Degiovanni, Andy and Pereira, Jose H. and Rodrigues, Andria V. and Van Dijk, Alberd...
-
[71]
and Kelley, Kotaro and Brignole, Edward and Berger, Bonnie , title =
Bepler, Tristan and Zhong, Ellen D. and Kelley, Kotaro and Brignole, Edward and Berger, Bonnie , title =. 2019 , type =
2019
-
[72]
2020 , type =
Berthet, Quentin and Blondel, Mathieu and Teboul, Olivier and Cuturi, Marco and Vert, Jean-Philippe and Bach, Francis , title =. 2020 , type =
2020
-
[73]
2017 IEEE International Conference on Computer Vision (ICCV) , publisher =
Bulat, Adrian and Tzimiropoulos, Georgios , title =. 2017 IEEE International Conference on Computer Vision (ICCV) , publisher =. doi:10.1109/iccv.2017.116 , type =
-
[74]
2022 , type =
Chen, Chi and Ong, Shyue Ping , title =. 2022 , type =
2022
-
[75]
2021 , type =
Chen, Lele and Cao, Chen and Torre, Fernando De la and Saragih, Jason and Xu, Chenliang and Sheikh, Yaser , title =. 2021 , type =
2021
-
[76]
Chen, Muyuan and Ludtke, Steven J. , title =. Nature Methods , volume =. doi:10.1038/s41592-021-01220-5 , year =
-
[77]
Chen, Ricky T. Q. and Li, Xuechen and Grosse, Roger and Duvenaud, David , title =. 2019 , type =
2019
-
[78]
2021 , type =
Cho, Youngwoo , title =. 2021 , type =
2021
-
[79]
Cohen, Jonathan and Olano, Marc and Manocha, Dinesh , title =. Proceedings of the 25th annual conference on Computer graphics and interactive techniques - SIGGRAPH '98 , publisher =. doi:10.1145/280814.280832 , type =
-
[80]
2019 , type =
Deng, Jiankang and Guo, Jia and Zhou, Yuxiang and Yu, Jinke and Kotsia, Irene and Zafeiriou, Stefanos , title =. 2019 , type =
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.